Введение
В
течение многих
лет приложения
на базе ОС реального
времени использовались
во встроенных
системах специального
назначения,
а с недавнего
времени они
стали применяться
повсюду, от
бортовых систем
управления
ЛА, до бытовых
приборов.
Разработка
многопроцессорных
вычислительных
систем (ВС) как
правило, имеет
своей целью
повышение либо
уровня надежности,
либо уровня
производительности
системы до
значений недоступных
или труднореализуемых
в традиционных
ЭВМ.
В
первом случае
на передний
план встает
вопрос о наличии
специальных
средств обеспечения
отказоустойчивости
вычислительных
систем, основной
особенностью
(и достоинством)
которых является
отсутствие
какого-либо
единственного
ресурса, выход
из строя которого
приводит к
фатальному
отказу всей
системы.
Таким
образом, объектом
исследования
в рамках сетевой
отказоустойчивой
технологии
становится
ОСРВ — управляющее
программное
обеспечение
особого типа,
которое используется
для организации
работы встроенных
приложений,
для которых
характерны
ограниченность
ресурсов памяти,
невысокая
производительность,
а также требования
гарантированного
времени отклика,
высокого уровня
готовности
и наличия средств
автомониторинга.
Данная
дипломная
работа посвящена
разработке
специализированной
распределенной
операционной
системы реального
времени для
отказоустойчивых
ВС с рангом
отказоустойчивости
N(N-1),
что означает
способность
системы функционировать
даже в том случае,
если произойдут
отказы всех
элементов
системы за
исключением
одного. Для
полного освещения
выбранной темы
были поставлены
следующие
задачи:
Провести
анализ существующих
операционных
систем реального
времени, выделить
основные
функциональные
требования
к ним, дать
сравнительную
характеристику.
Раскрыть
концепцию
построения
ОСРВ с рангом
отказоустойчивости
N-1, выделить
основные модули
операционной
системы, функциональные
требования
к ним и алгоритмы
работы.
Раскрыть
логику организации
отказоустойчивых
вычислений
на примере
конкретной
реализации.
Провести
анализ надежности
отказоустойчивой
ВС и дать рекомендации
по организации
ВС.
Создать
программную
модель вычислительной
системы с
распределенной
операционной
системой реального
времени и отработать
на ней различные
режимы работы.
Рассмотреть
возможность
портирования
(переноса) ОСРВ
на платформу
TMS320c30,
рассмотреть
специфические
проблемы и
сложности при
осуществлении
портации.
В
первой части
работы дано
краткое описание
известных ОСРВ,
описаны их
функциональные
возможности,
структура, их
направленность
(специфические
особенности).
Также приведена
сравнительная
характеристика
и отмечены те
решения, которые
можно было бы
использовать
для разработки
собственной
специализированной
ОСРВ.
Во
второй главе
описана концепция
построения
распределенной
ОСРВ, были
сформулированы
основные принципы
функционирования
перспективной
вычислительной
системы, включающие
в себя многопроцессорность,
обеспечение
живучести,
адаптацию к
изменениям
внутренних
условий среды,
поддержку
реального
масштаба времени,
мобильность
и открытость
программного
обеспечения.
Предложен
пример организации
отказоустойчивых
вычислений
на примере
пяти-узловой
полносвязной
сети ПЭ в условиях
постоянной
деградации
системы.
Далее
рассмотрена
программная
модель ВС и
операционной
системы, логика
работы и взаимосвязь
модулей.
В последней
главе рассматриваются
особенности
аппаратной
платформы
TMS320c30,
вопросы реализации
вышеприведенных
идей с помощью
этой платформы,
дополнение
ОС специфическими
для данной
архитектуры
модулями.
Специальная
часть
Операционные
системы реального
времени.
ОС
общего назначения,
особенно
многопользовательские,
ориентированы
на оптимальное
распределение
ресурсов компьютера
между пользователями
и задачами
(системы разделения
времени), В
операционных
системах реального
времени (ОСРВ),
подобная задача
отходит на
второй план
- все отступает
перед главной
задачей - успеть
среагировать
на события,
происходящие
на объекте.
Описание
и общие требования
к системам
реального
времени.
Применение
операционной
системы реального
времени всегда
связано с
аппаратурой,
с объектом, с
событиями,
происходящими
на объекте.
Система реального
времени, как
аппаратно-программный
комплекс, включает
в себя датчики,
регистрирующие
события на
объекте, модули
ввода-вывода,
преобразующие
показания
датчиков в
цифровой вид,
пригодный для
обработки этих
показаний на
компьютере,
и, наконец, компьютер
с программой,
реагирующей
на события,
происходящие
на объекте.
ОСРВ ориентирована
на обработку
внешних событий.
Именно это
приводит к
коренным отличиям
(по сравнению
с ОС общего
назначения)
в структуре
системы, в функциях
ядра, в построении
системы ввода-вывода.
ОСРВ может быть
похожа по
пользовательскому
интерфейсу
на ОС общего
назначения,
однако устроена
она совершенно
иначе - об этом
речь впереди.
Кроме
того, применение
ОСРВ всегда
конкретно. Если
ОС общего назначения
обычно воспринимается
пользователями
(не разработчиками)
как уже готовый
набор приложений,
то ОСРВ служит
только инструментом
для создания
конкретного
аппаратно -
программного
комплекса
реального
времени. И поэтому
наиболее широкий
класс пользователей
ОСРВ - разработчики
комплексов
реального
времени, люди
проектирующие
системы управления
и сбора данных.
Проектируя
и разрабатывая
конкретную
систему реального
времени, программист
всегда знает
точно, какие
события могут
произойти на
объекте, знает
критические
сроки обслуживания
каждого из этих
событий.
Назовем
системой реального
времени (СРВ)
аппаратно-программный
комплекс, реагирующий
в предсказуемые
времена на
непредсказуемый
поток внешних
событий.
Это
определение
означает, что:
Система
должна успеть
отреагировать
на событие,
произошедшее
на объекте, в
течение времени,
критического
для этого события.
Величина
критического
времени для
каждого события
определяется
объектом и
самим событием,
и, естественно,
может быть
разной, но время
реакции системы
должно быть
предсказано
(вычислено)
при создании
системы. Отсутствие
реакции в
предсказанное
время считается
ошибкой для
систем реального
времени.
Система
должна успевать
реагировать
на одновременно
происходящие
события. Даже
если два или
больше внешних
событий происходят
одновременно,
система должна
успеть среагировать
на каждое из
них в течение
интервалов
времени, критического
для этих событий.
Различают
системы реального
времени двух
типов - системы
жесткого реального
времени и системы
мягкого реального
времени.
Системы
жесткого реального
времени не
допускают
никаких задержек
реакции системы
ни при каких
условиях, так
как:
результаты
могут оказаться
бесполезны
в случае опоздания,
может
произойти
катастрофа
в случае задержки
реакции,
стоимость
опоздания
может оказаться
бесконечно
велика.
Примеры
систем жесткого
реального
времени - бортовые
системы управления,
системы аварийной
защиты, регистраторы
аварийных
событий.
Системы
мягкого реального
времени характеризуются
тем, что задержка
реакции не
критична, хотя
и может привести
к увеличению
стоимости
результатов
и снижению
производительности
системы в целом.
Основное
отличие между
системами
жесткого и
мягкого реального
времени можно
выразить так:
система жесткого
реального
времени никогда
не опоздает
с реакцией на
событие, система
мягкого реального
времени - не
должна опаздывать
с реакцией на
событие.
Тогда
операционная
система реального
времени - это
такая ОС, которая
может быть
использована
для построения
систем жесткого
реального
времени. Это
определение
выражает отношение
к ОСРВ как к
объекту, содержащему
необходимые
инструменты,
но также означает,
что этими
инструментами
еще необходимо
правильно
воспользоваться.
1.2. Параметры
ОСРВ
1.2.1.
Время реакции
системы
Почти
все производители
систем реального
времени приводят
такой параметр,
как время реакции
системы на
прерывание
(interrupt latency).
В
самом деле,
если главным
для системы
реального
времени является
ее способность
вовремя отреагировать
на внешние
события, то
такой параметр,
как время реакции
системы является
ключевым.
События,
происходящие
на объекте,
регистрируются
датчиками,
данные с датчиков
передаются
в модули ввода-вывода
(интерфейсы)
системы. Модули
ввода-вывода,
получив информацию
от датчиков
и преобразовав
ее, генерируют
запрос на прерывание
в управляющем
компьютере,
подавая ему
тем самым сигнал
о том, что на
объекте произошло
событие. Получив
сигнал от модуля
ввода-вывода,
система должна
запустить
программу
обработки этого
события.
Интервал
времени - от
события на
объекте и до
выполнения
первой инструкции
в программе
обработки этого
события и является
временем реакции
системы на
события.
Обычно
время реакции
систем на прерывание
составляет
порядка 4-10 мкс.
1.2.2.
Время переключения
контекста
В
операционные
системы реального
времени заложен
параллелизм,
возможность
одновременной
обработки
нескольких
событий, поэтому
все ОСРВ являются
многозадачными
(многопроцессными,
многонитиевыми).
Контекст
задачи это
набор данных,
задающих состояние
процессора
при выполнении
задачи. Обычно
совпадает с
набором регистров,
доступных для
изменения
прикладной
задаче.
При
переключении
задач (процессов)
необходимо:
корректно
остановить
работающую
задачу;
для
этого
а)
выполнить
инструкции
текущей задачи,
уже загруженные
в процессор,
но еще не выполненные;
б)
сохранить в
оперативной
памяти регистры
текущей задачи;
2.
найти, подготовить
и загрузить
затребованную
задачу;
3.
запустить новую
задачу, для
этого
а)
восстановить
из оперативной
памяти регистры
новой задачи
(сохраненные
ранее,
если
она до этого
уже работала);
б)
загрузить в
процессор
инструкции
новой задачи.
Каждая
из этих стадий
вносит свой
вклад в задержку
при переключении
контекста.
Поскольку любое
приложение
реального
времени должно
обеспечить
выдачу результата
в заданное
время, то эта
задержка должна
быть мала,
детерминирована
и известна. Это
число является
одной из важнейших
характеристик
ОСРВ. Обычно
время переключения
контекста в
ОСРВ составляет
10-20 мкс.
Размеры
системы
Для
систем реального
времени важным
параметром
является размер
системы исполнения,
а именно суммарный
размер минимально
необходимого
для работы
приложения
системного
набора (ядро,
системные
модули, драйверы
и т. д.). Хотя, надо
признать, что
с течением
времени значение
этого параметра
уменьшается,
тем не менее,
он остается
важным и производители
систем реального
времени стремятся
к тому, чтобы
размеры ядра
и обслуживающих
модулей системы
были невелики.
Механизмы
реального
времени
Важным
параметром
при оценке ОСРВ
является набор
инструментов,
механизмов
реального
времени, предоставляемых
системой.
1.3.1.
Система приоритетов
и алгоритмы
диспетчеризации
Базовыми
инструментами
разработки
сценария работы
системы являются
система приоритетов
процессов
(задач) и алгоритмы
планирования
(диспетчеризации)
ОСРВ.
В
многозадачных
ОС общего назначения
используются,
как правило,
различные
модификации
алгоритма
круговой
диспетчеризации,
основанные
на понятии
непрерывного
кванта времени
("time slice"), предоставляемого
процессу для
работы. Планировщик
по истечении
каждого кванта
времени просматривает
очередь активных
процессов и
принимает
решение, кому
передать управление,
основываясь
на приоритетах
процессов
(численных
значениях, им
присвоенных).
Приоритеты
могут быть
фиксированными
или меняться
со временем
- это зависит
от алгоритмов
планирования
в данной ОС, но
рано или поздно
процессорное
время получат
все процессы
в системе.
Алгоритмы
круговой
диспетчеризации
неприменимы
в чистом виде
в ОСРВ. Основной
недостаток
- непрерывный
квант времени,
в течение которого
процессором
владеет только
один процесс.
Планировщики
же ОСРВ имеют
возможность
сменить процесс
до истечения
"time slice", если в этом
возникла
необходимость.
Один из возможных
алгоритмов
планирования
при этом "приоритетный
с вытеснением".
Мир ОСРВ отличается
богатством
различных
алгоритмов
планирования:
динамические,
приоритетные,
монотонные,
адаптивные
и пр., цель же
всегда преследуется
одна - предоставить
инструмент,
позволяющий
в нужный момент
времени исполнять
именно тот
процесс, который
необходим.
1.3.2.
Механизмы
межзадачного
взаимодействия
Другой
набор механизмов
реального
времени относится
к средствам
синхронизации
процессов и
передачи данных
между ними. Для
ОСРВ характерна
развитость
этих механизмов.
К таким механизмам
относятся:
семафоры, мьютексы,
события, сигналы,
средства для
работы с разделяемой
памятью, каналы
данных (pipes), очереди
сообщений.
Многие из подобных
механизмов
используются
и в ОС общего
назначения,
но их реализация
в ОСРВ имеет
свои особенности
- время исполнения
системных
вызовов почти
не зависит от
состояния
системы, и в
каждой ОСРВ
есть по крайней
мере один быстрый
механизм передачи
данных от процесса
к процессу.
Средства
для работы с
таймерами
Такие
инструменты,
как средства
работы с таймерами,
необходимы
для систем с
жестким временным
регламентом,
поэтому развитость
средств работы
с таймерами
- необходимый
атрибут ОСРВ.
Эти средства,
как правило,
позволяют:
измерять
и задавать
различные
промежутки
времени (от 1
мкс и выше),
генерировать
прерывания
по истечении
временных
интервалов,
создавать
разовые и
циклические
будильники
Здесь
описаны только
базовые, обязательные
механизмы,
использующиеся
в ОСРВ. Кроме
того, почти в
каждой ОСРВ
можно найти
целый набор
дополнительных,
специфических
только для нее
механизмов,
касающийся
системы ввода-вывода,
управления
прерываниями,
работы с памятью.
Каждая система
содержит также
ряд средств,
обеспечивающих
ее надежность:
встроенные
механизмы
контроля целостности
кодов, инструменты
для работы с
таймерами.
Классы систем
реального
времени
Монолитная
архитектура
ОСРВ
с монолитной
архитектурой
можно представить
в виде (рис. 1.1)
системного
уровня: состоит
из монолитного
ядра операционной
системы, в котором
можно выделить
следующие
части: интерфейс
между приложениями
и ядром (API), собственно
ядро системы,
интерфейс
между ядром
и оборудованием
(драйверы
устройств).

Рис.
1.1. ОСРВ с монолитной
архитектурой
Интерфейс
в таких системах
играет двойную
роль:
1.
управление
взаимодействием
прикладных
процессов и
системы,
2.
обеспечение
непрерывности
выполнения
кода системы
(т.е. отсутствие
переключения
задач во время
исполнения
кода системы).
Основным
преимуществом
монолитной
архитектуры
является ее
относительная
быстрота работы
по сравнению
с другими
архитектурами.
Однако, достигается
это, в основном,
за счет написания
значительных
частей системы
на ассемблере.
Недостатки
монолитной
архитектуры.
1.
Системные
вызовы, требующие
переключения
уровней привилегий
(от пользовательской
задачи к ядру),
должны быть
реализованы
как прерывания
или специальный
тип исключений.
Это сильно
увеличивает
время их работы.
2.
Ядро не может
быть прервано
пользовательской
задачей (non-preemptable).
Это может приводить
к тому, что
высокоприоритетная
задача может
не получить
управления
из-за работы
низкоприоритетной.
3.
Сложность
переноса на
новые архитектуры
процессора
из-за значительных
ассемблерных
вставок.
4.
Негибкость
и сложность
развития: изменение
части ядра
системы требует
его полной
перекомпиляции.
Модульная
архитектура
(на основе микроядра)
Модульная
архитектура
появилась, как
попытка убрать
интерфейс между
приложениями
и ядром и облегчить
модернизацию
системы и перенос
ее на новые
процессоры.
Теперь
микроядро
играет двойную
роль(рис 1.2):
1.
управление
взаимодействием
частей системы
(например, менеджеров
процессов и
файлов),
обеспечение
непрерывности
выполнения
кода системы
(т.е. отсутствие
переключения
задач во время
исполнения
микроядра).
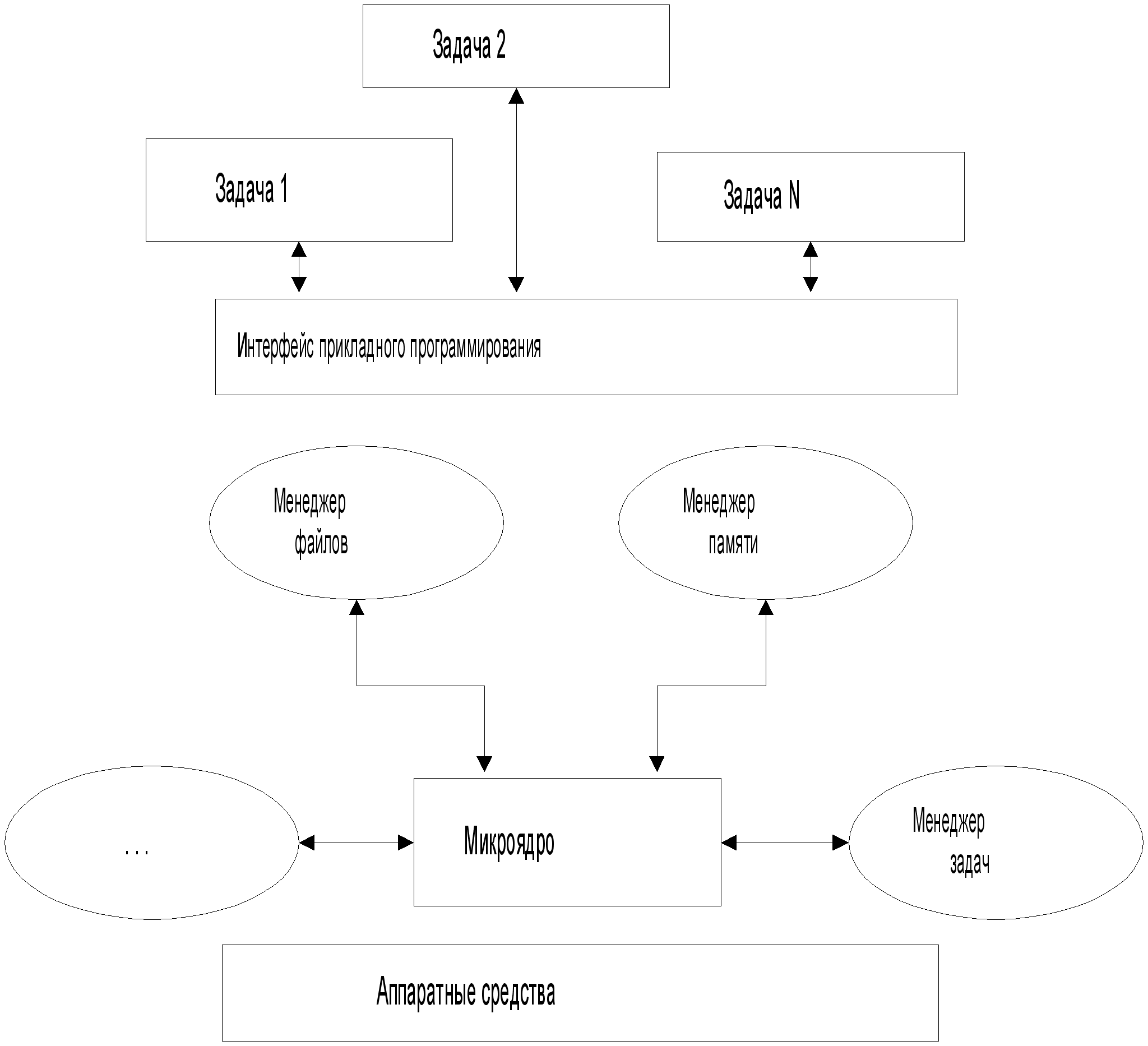
Рис.
1.2. ОСРВ на основе
микроядра
Недостатки
модульной
архитектуры
фактически
те же, что и у
монолитной.
Проблемы перешли
с уровня интерфейса
на уровень
микроядра.
Системный
интерфейс
по-прежнему
не допускает
переключения
задач во время
работы микроядра,
только сократилось
время пребывания
в этом состоянии,
проблемы с
переносимостью
микроядра
уменьшились
(в связи с сокращением
его размера),
но остались.
Объектная
архитектура
на основе
объектов-микроядер
В
этой архитектуре
интерфейс между
приложениями
и ядром отсутствует
вообще (рис.
1.3). Взаимодействие
между компонентами
системы (микроядрами)
и пользовательскими
процессами
осуществляется
посредством
обычного вызова
функций, поскольку
и система, и
приложения
написаны на
одном языке
(обычно C++). Это
обеспечивает
максимальную
скорость системных
вызовов.
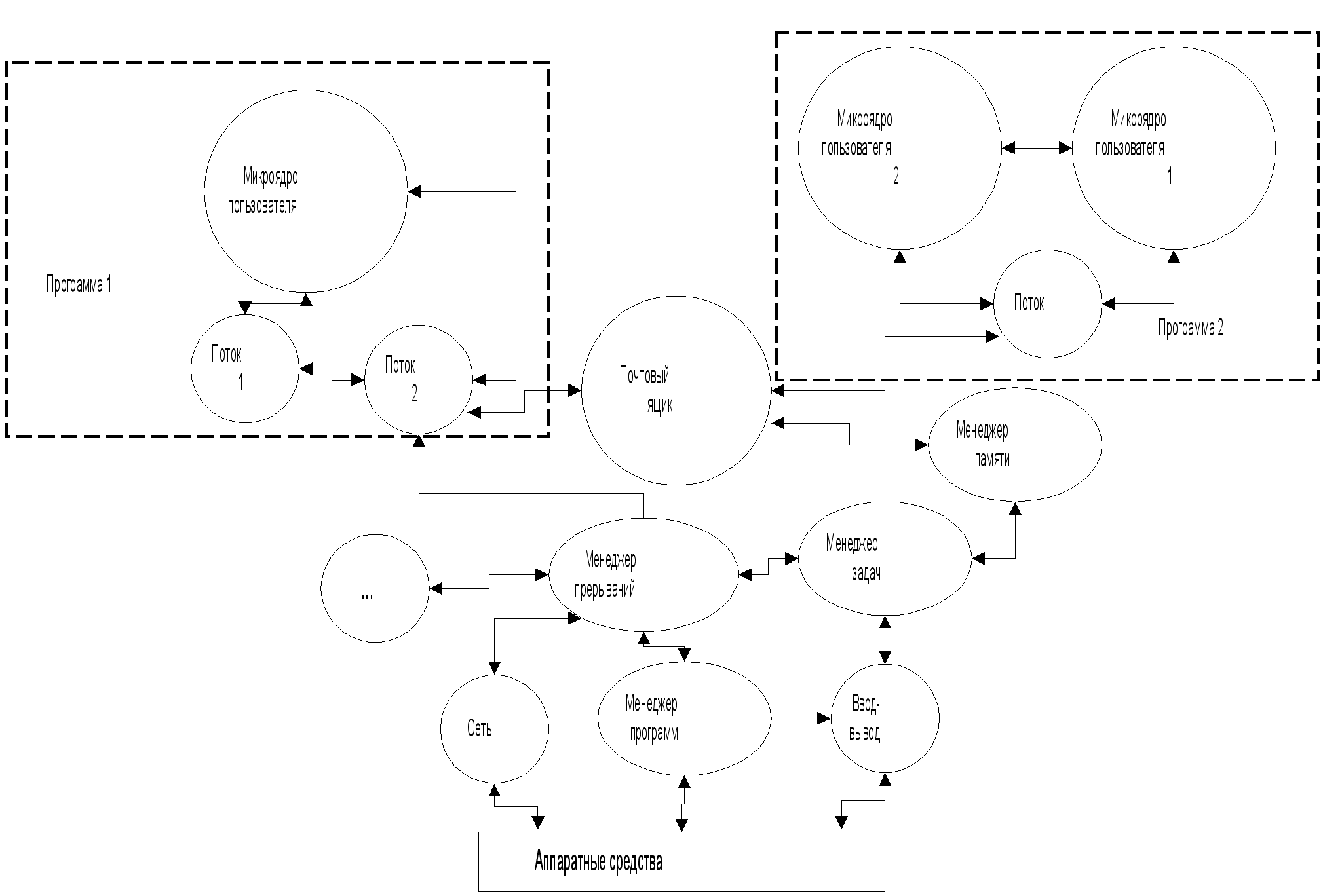
Рис.
1.3. Пример
объектно-ориентированной
ОСРВ
Фактическое
равноправие
всех компонент
системы обеспечивает
возможность
переключения
задач в любое
время. Объектно-ориентированный
подход обеспечивает
модульность,
безопасность,
легкость модернизации
и повторного
использования
кода.
В
отличие от
предыдущих
систем, не все
компоненты
самой операционной
системы должны
быть загружены
в оперативную
память. Если
микроядро уже
загружено для
другого приложения,
то оно повторно
не загружается,
а используется
код и данные
уже имеющегося
микроядра. Все
эти приемы
позволяют
сократить объем
требуемой
памяти. Поскольку
разные приложения
разделяют одни
микроядра, то
они должны
работать в
одном адресном
пространстве.
Следовательно,
система не
может использовать
виртуальную
память и тем
самым работает
быстрее (так
как исключаются
задержки на
трансляцию
виртуального
адреса в физический).
1.5. Обзор
некоторых
коммерческих
ОСРВ
Операционная
система OS-9
OS-9
фирмы Microware
относится к
классу UNIX-подобных
операционных
систем реального
времени. По
своей сути OS-9
является
многозадачной
ОС с вытесняющей
приоритетной
диспетчеризацией,
допускающая
возможность
многопользовательской
работы. Объектно-ориентированный
модульный
дизайн системы
позволяет
конфигурировать
систему в очень
широком диапазоне
от встраиваемых
систем до больших
сетевых приложений.
Согласно этой
концепции все
функциональные
компоненты
OS-9,
включая ядро,
иерархические
файловые менеджеры,
драйвера устройств
и т. д., реализованы
в виде независимых
модулей. Все
модули операционной
системы
позиционно-независимы
и могут быть
размещены в
ПЗУ, а также
могут удаляться
из системы в
процессе ее
функционирования
без какой-либо
повторной
инсталляции
или перекомпоновки.
На рисунке 1.4
приведена
упрощенная
структурная
схема операционной
системы.
Структура
операционной
системы OS-9
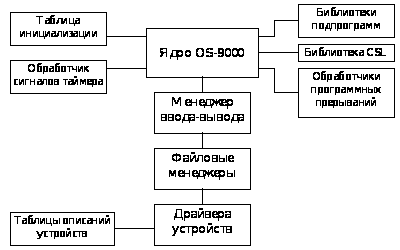
Рис.
1.4.
Структура
операционной
системы OS-9
Ядро
обеспечивает
основной системный
сервис, включая
управление
процессами
и распределение
ресурсов.
Основные
характеристики:
Архитектура:
на основе микроядра
Стандарт:
собственный,
вызовы похожи
на UNIX
Свойства
как ОСРВ:
Многопроцессорность:
да
Уровней
приоритетов:
65535
Время
реакции: 3 мкс
Планирование:
приоритетное,
FIFO, специальный
механизм
планирования;
preemptive ядро
ОС
разработки
(host): UNIX/Windows
Процессоры
(target): Motorola 68xxx, Intel 80x86, ARM, MIPS, PowerPC
Линии
связи host-target: последовательный
канал и ethernet
Минимальный
размер: 16Kb
Средства
синхронизации
и взаимодействия:
разделяемая
память, сигналы,
семафоры, события.
Операционная
система VxWorks
VxWorks
относится к
операционным
системам «жесткого»
реального
времени. Характерной
чертой этой
ОС является
то, благодаря
ее развитым
сетевым возможностям,
вся разработка
ПО ведется на
инструментальном
компьютере
(хост-системе)
с использованием
кросс-средств
для последующего
исполнения
на целевой
машине под
управлением
VxWorks.
Отличительная
черта системы
- возможность
управлять
работой сложных
комплексов
реального
времени и бортовых
устройств,
использующих
процессорные
элементы различных
поставщиков.
Три основных
компонента
данной ОС РВ
образуют единую
интегрированную
среду: собственно
ядро системы,
управляющее
процессором;
набор средств
межпроцессорного
взаимодействия;
комплект
коммуникационных
программ для
работы с Ethernet или
последовательными
каналами связи.
Основные
характеристики:
1.
Архитектура:
монолитная
2.
Стандарт: собственный
и POSIX 1003
3.
Свойства как
ОСРВ:
Многозадачность:
многопроцессность
и многозадачность
Многопроцессорность:
да
Уровней
приоритетов:
256
Время
реакции: 4 мкс
Время
переключения
контекста: 15
мкс
Планирование:
приоритетное;
preemptive ядро
4.
ОС
разработки
(host): UNIX/Windows
5.
Процессоры
(target): Motorola 68xxx, Intel 80x86, Intel 80960, PowerPC, SPARC,
Alpha, MIPS, ARM
6.
Линии связи
host-target:
последовательный
канал, ethernet,
шина VME
7.
Минимальный
размер: 22Kb
8.
Средства
синхронизации
и взаимодействия:
семафоры POSIX 1003,
очереди, сигналы…
Операционная
система QNX
Операционная
система QNX
канадской
компании QNX
Software
System
Ltd.
построена на
основе иерархической
микроядерной
архитектуры.
Упрощенная
структурная
схема этой ОС
приведена на
рисунке 1.5.

Рис.
1.5. Микроядерная
структура QNX
Микроядро
QNX
выполняет
следующие
функции:
Основные
характеристики:
1.
Архитектура:
на основе микроядра
2.
Стандарт: POSIX 1003
3.
Свойства как
ОСРВ:
4.
Процессоры
(target): Intel 80x86
5.
Минимальный
размер: 60Kb
6.
Средства
синхронизации
и взаимодействия:
POSIX 1003 (семафоры,
mutex, condvar)
Операционная
система LynxOS
Система
LynxOS выпускается
фирмой Lynx Real Time Systems
(Los Gatos, USA). ОСРВ из клона
UNIX-систем, обеспечивающая
детерминированное
время отклика
по запросам.
Основные
характеристики:
1.
Архитектура:
на основе микроядра
2.
Стандарт: POSIX 1003
3.
Свойства как
ОСРВ:
4.
Процессоры
(target): Intel 80x86, Motorola 68xxx, SPARC, PowerPC
5.
Минимальный
размер:
полной
системы: 256Kb
усеченной
системы: 124Kb
только
ядра: 33Kb
Систему
можно записать
в ROM.
6.
Средства
синхронизации
и взаимодействия:
POSIX 1003 (семафоры,
mutex, condvar)
Операционная
система pSOS
Система
pSOS
выпускается
Integrated
Systems
(Santa
Clara,
USA).
Основные
характеристики:
1.
Архитектура:
на основе микроядра
2.
Стандарт: собственный
3.
Свойства как
ОСРВ:
4.
ОС
разработки
(host): UNIX/Windows
5.
Процессоры
(target): Motorola 68xxx, Intel 80x86, Intel 80960, ARM, MIPS,
PowerPC
6.
Минимальный
размер: 15Kb
Средства
синхронизации
и взаимодействия:
семафоры, mutex,
события, и тд.
1.6.
Выводы к главе
1
Основными
отличиями ОСРВ
от ОС общего
назначения
являются:
Ориентация
на обработку
внешних событий;
Детерминированное
время реакции
на внешнее
событие;
Модульная
организация;
Небольшой
размер системы.
В
главе были
рассмотрены
важнейшие
параметры и
механизмы ОСРВ,
такие как:
Классификация
ОСРВ позволяет
выделить наиболее
оптимальную
структуру
построения
ОСРВ. Очевидно,
что операционные
системы с монолитной
архитектурой,
вследствие
их направленности
на конкретные
процессорные
платформы и
характера
взаимодействия
с ядром, вряд
ли могут быть
использованы
в качестве
относительно
универсальных
ОСРВ для систем
высокой готовности.
ОСРВ на основе
микроядра
обладает рядом
преимуществ
по сравнению
с монолитной
архитектурой,
а комбинация
с объектно-ориентированным
подходом, позволит
системе стать
аппаратно-независимой
и обеспечить
быструю реакцию
на внешние
события.
В
заключении
были перечислены
основные свойства
некоторых
распространенных
ОСРВ. К
сожалению, ни
одну из рассмотренных
операционных
систем нельзя
назвать сетевой
в широком смысле
этого слова,
так как уровень
сетевого обмена,
заложенный
в многих из них
соответствует
уровню локальной
сети. Многопроцессорная
поддержка,
введенная в
VxWorks
ориентирована
только на системы
с общей памятью.
Отсутствие
механизма
отказоустойчивости,
допускающего
как отказы
соединений
(зачатки этого
есть в QNX),
так и отказы
процессорных
элементов,
необходимого
для отказоустойчивых
специализированных
вычислительных
систем, нет ни
в одной из этих
операционных
систем. Таким
образом, задачей
разработчиков
является добавление
таких модулей
существующим
ОСРВ, которые
позволили бы
обеспечить
отказоустойчивость
распределенных
вычислительных
систем.
2.
Поддержка
отказоустойчивости
вычислительных
систем средствами
операционных
систем реального
времени
Специфика
применения
некоторых
систем обусловливает
особые требования,
предъявляемые
к надежности
их функционирования.
Отказ или сбой
в их работе,
повлекшие за
собой неправильные
результаты
вычислений
(или полное их
отсутствие),
могут привести
к катастрофическим
последствиям.
Преимущества
использования
отказоустойчивых
вычислительных
систем непосредственно
вытекают из
необходимости
продолжительной
работы системы
в условиях,
когда техническое
обслуживание
(ремонт, замена
и тд.) невозможны,
труднореализуемы
или сопряжены
с большими
экономическими
затратами.
Поэтому ВС и
специализированные
операционные
системы разрабатываются
таким образом,
чтобы система
была толерантна
(терпима) к
возникающим
отказам. Особенно
это актуально
для автономных
ЛА (например,
космических
аппаратов).
Сложность
современных
вычислительных
средств такова,
что практически
невозможно
проверить
готовые изделия
при всех предполагаемых
условиях и
режимах их
работы. Поэтому
в вычислительных
системах могут
быть скрытые
– не проявившиеся
при проверке
– ошибки программного
обеспечения
и (или) неисправности
аппаратуры,
но благодаря
отказоустойчивости
сбой, отказ
отдельного
элемента как
правило не
приводят к
искажению
выходных данных.
В
отличие от
аппаратной
части вычислительной
системы появление
ошибок в программе
не связано с
физическими
процессами.
Получение
результатов,
отличных от
ожидаемых
происходит
в результате
выполнения
непроверенной
части программы
или в результате
ошибки в программе.
Таким
образом, получение
ответа, отличного
от ожидаемого,
в некоторый
момент времени
есть результат
выполнения
непроверенной
части программы,
содержащей
ошибку, задания
входных данных,
для которых
поведение
программы
неспецифицировано,
а также влияния
отказов в аппаратуре
на работу программы.
При
рассмотрении
надёжности
вычислительной
системы следует
иметь ввиду,
что она определяется
надёжностью
аппаратной
части и надёжностью
программного
обеспечения.
Однако, понятие
надёжности
программного
обеспечения
неконструктивно,
это означает,
что на этапе
тестирования
программы не
были выявлены
все ошибки. В
данной работе
считается, что
программа не
содержит ошибок,
и получение
результата,
отличных от
ожидаемого
зависит от
сбоев или отказов
аппаратной
части или иных
факторов (например,
влияние ЭМИ
на содержание
оперативной
памяти), а потому
вопрос о надёжности
программного
обеспечения
не ставится.
Таким образом,
надёжность
вычислительной
системы определяется
надёжностью
аппаратуры
и влиянием
отказов в ней
на отказы в
вычислительной
системе в целом.
Предварительные
исследования
показали, что
для элементной
базы среднего
качества (надежность
0.999 - “три девятки
после запятой”)
при оптимальном
сочетании
скорости получения
результата
на его надежность
в вычислительной
среде теоретически
достижима
достоверность
получения
правильных
результатов
машинного счета
в “двести девяток
после запятой”
при замедлении
темпа их получения
в 300-400 раз [1], что
эквивалентно
увеличению
надежности
до 200 порядков
величины при
введении сравнительно
небольшой
вычислительной
избыточности,
приводящей
к потере производительности
не более чем
на 2-3 порядка,
что уже на
современном
уровне может
компенсироваться
подбором компьютеров
требуемой
производительности.
Понятие
отказоустойчивости
ВС.
Отказоустойчивостью
будем называть
свойство системы,
позволяющее
продолжить
выполнение
заданных программой
действий после
возникновения
одного или
нескольких
сбоев или отказов
компонентов
ВС.
Отказом
называется
событие, заключающееся
в нарушении
работоспособности
компонента
системы. Последствия
отказа могут
быть различными.
Отказ системы
может быть
вызван отказом
(неверным
срабатыванием)
каких-то ее
компонентов
(процессор,
память, устройства
ввода/вывода,
линии связи,
или программное
обеспечение).
Отказ компонента
может быть
вызван ошибками
при конструировании,
при производстве
или программировании.
Он может быть
также вызван
физическим
повреждением,
изнашиванием
оборудования,
некорректными
входными данными,
и многими другими
причинами.
Отказы
могут быть
случайными,
периодическими
или постоянными.
Случайные
отказы (сбои)
при повторении
операции исчезают.
Причиной такого
сбоя может
служить, например,
электромагнитная
помеха. Другой
пример - редкая
ситуация в
последовательности
обращений к
операционной
системе от
разных задач.
Периодические
отказы повторяются
часто в течение
какого-то времени,
а затем могут
долго не происходить.
Примеры - плохой
контакт, некорректная
работа ОС после
обработки
аварийного
завершения
задачи. Постоянные
(устойчивые)
отказы не
прекращаются
до устранения
их причины -
разрушения
диска, выхода
из строя микросхемы
или ошибки в
программе.
2.2.
Причины и
классификация
отказов и сбоев
Отказы
по характеру
своего проявления
подразделяются
на византийские
(система активна
и может проявлять
себя по-разному,
даже злонамеренно)
и пропажа признаков
жизни (частичная
или полная).
Первые распознать
гораздо сложнее,
чем вторые.
Аппаратная
реализация узлов
(процессорных модулей)
позволяет
выделить основные
классы отказов
аппаратуры:
-
отказ процессора
(центральной
части ПЭ);
-
отказ линка
- связи между
ПЭ;
Идентификация
отказа процессора
какого-либо
узла сети
классифицируется,
как отказ всего
узла: он изолируется
от остальной
сети на логическом
уровне и при
наличии соответствующей
поддержки
отключается
на аппаратном
уровне (выключается
питание).
Идентификация
отказа линка
(связи) приводит
лишь к уменьшению
степени связности
узлов сети.
Отказавший
линк изолируется
на логическом
уровне путем
изменения
маршрутов
передачи сообщений
между узлами
сети.
Отказ
при исполнении
функционального
программного
обеспечения
может проявиться
вследствие:
нарушения
кодов записи
программ в
памяти команд;
стирания
или искажения
данных в оперативной
или долговременной
памяти;
нарушения
нормального
хода вычислительного
процесса.
Перечисленные
искажения могут
действовать
совместно.
Отказ может
проявляться
в виде программного
останова или
зацикливания,
систематического
пропуска исполнения
некоторой
группы команд,
однократного
или систематического
искажения
данных и тд.
Программные
отказы приводят
к прекращению
выдачи абонентам
информации
и управляющих
воздействий
или к значительному
искажению ее
содержания
и темпа выдачи,
соответствующих
нарушению
работоспособности.
Основная
особенность
(и достоинство)
сетевой отказоустойчивой
технологии
- отсутствие
какого-либо
(даже самого
незначительного)
единственного
компонента
(ресурса), выход
из строя которого
приводит к
фатальному
отказу всей
системы. Такая
система не
может содержать
какого-либо
"центрального"
(главного) узла,
размещенного
в одном из
процессорных
элементов
системы, она
может состоять
только из
"равноправных"
частей, размещенных
в каждом узле
сети. Таким
образом можно
говорить лишь
о деградации
качества системы
при отказе
одного или
более ее элементов.
В такой системе
полный отказ
наступает после
выхода из строя
только определенного
количества
ресурсов,
определенного
на этапе проектирования.
- Методы
и средства
обеспечения
отказоустойчивости
Для
обеспечения
надежного
решения задач
в условиях
отказов системы
применяются
два принципиально
различающихся
подхода - восстановление
решения после
отказа системы
(или ее компонента)
и предотвращение
отказа системы
(отказоустойчивость).
Восстановление
может быть
прямым (без
возврата к
прошлому состоянию)
и возвратное.
Прямое
восстановление
основано на
своевременном
обнаружении
сбоя и ликвидации
его последствий
путем приведения
некорректного
состояния
системы в корректное.
Такое восстановление
возможно только
для определенного
набора заранее
предусмотренных
сбоев.
При
возвратном
восстановлении
происходит
возврат процесса
(или системы)
из некорректного
состояния в
некоторое из
предшествующих
корректных
состояний. При
этом возникают
следующие
проблемы:
Потери
производительности,
вызванные
запоминанием
состояний,
восстановлением
запомненного
состояния и
повторением
ранее выполненной
работы, могут
быть слишком
высоки.
Нет
гарантии, что
сбой снова не
повторится
после восстановления.
Для
некоторых
компонентов
системы восстановление
в предшествующее
состояние
может быть
невозможно
(торговый автомат).
Для
восстановления
состояния в
традиционных
ЭВМ применяются
два метода (и
их комбинация),
основанные
на промежуточной
фиксации состояния
либо ведении
журнала выполняемых
операций. Они
различаются
объемом запоминаемой
информацией
и временем,
требуемым для
восстановления.
Применение
подобных методов
в распределенных
системах
наталкивается
на следующие
трудности:
Чтобы
избежать эти
неприятности,
создают системы,
устойчивые
к отказам. Такие
системы либо
маскируют
отказы, либо
ведут себя в
случае отказа
заранее определенным
образом.
По
мере того как
операционные
системы реального
времени и встроенные
компьютеры
все чаще используются
в критически
важных приложениях,
разработчики
создают новые
ОС реального
времени высокой
готовности.
Эти продукты
включают в себя
специальные
программные
компоненты,
которые инициируют
предупреждения,
запускают
системную
диагностику
для того, чтобы
помочь выявить
проблему, или
автоматически
переключаются
на резервную
систему.
Обеспечение
живучести –
это использование
специальных
средств, позволяющих
системе продолжать
правильное
функционирование
при возникновении
отказов ее
программных
и аппаратных
компонентов
с возможностью
деградации
качества
функционирования
[2]. В отличие от
отказоустойчивости,
где с отказом
не связано
качество работы
ВС, сравнительно
сложные средства
обеспечения
живучести
позволяют более
рационально
расходовать
вычислительные
ресурсы и увеличивать
среднее время
наработки до
наступления
фатального
отказа. Обеспечение
живучести
обычно включает
три основные
функции: диагностика
возникновения
отказа, локализация
неисправности
и перестройка
системы. В основе
толерантности
лежит избыточность
как аппаратного,
так и программного
обеспечения.
Поэтому многопроцессорные
системы с присущей
им аппаратной
избыточностью
потенциально
позволяют
создавать не
только высокопроизводительные,
но и высоконадежные
системы.
Другим
основополагающим
требованием
является наличие
механизма,
позволяющего
агентам в каждом
устройстве
обмениваться
топологической
информацией
со своими соседями
посредством
эффективных
протоколов,
не перегружающих
сеть широковещательным
управляющим
трафиком. Каждый
управляющий
агент должен
поддерживать
таблицу с локальной
топологической
информацией.
Кроме того,
должен предоставляться
механизм, практически
в реальном
времени модифицирующий
содержимое
базы данных
и обеспечивающий
правильное
отображение
топологических
изменений,
вызванных
установкой
новых устройств
либо реконфигурацией
или отказом
существующих
узлов сети.
Для
обеспечения
защиты вычислительного
процесса программными
методами используется
программная,
информационная
и временная
избыточности.
Под
временной
избыточностью
понимается
использование
части производительности
для получения
диагностической
информации
о состоянии
системы. Программная
избыточность
используется
для контроля
и обеспечения
достоверности
важных решений
по управлению
и обработке
информации.
Она заключается
в применении
нескольких
вариантов
программ в
каждом узле
системы (так
называемое
N-версионное
программирование).
Сопоставление
результатов
независимых
решений одного
и того же фрагмента
задачи называют
элементарной
проверкой, а
совокупность
всех проверок
образует систему
голосования,
которое является
основным источником
диагностической
информации
о состоянии
аппаратной
части системы
и вычислительного
процесса в
каждом активном
узле системы.
Два механизма
широко используются
при обеспечении
отказоустойчивости
- протоколы
голосования
и протоколы
принятия
коллективного
решения.
Протоколы
голосования
служат для
маскирования
отказов (выбирается
правильный
результат,
полученный
всеми исправными
исполнителями).
Протоколы
принятия
коллективного
решения подразделяются
на два класса.
Во-первых, протоколы
принятия единого
решения,
в которых все
исполнители
являются исправными
и должны либо
все принять,
либо все не
принять заранее
предусмотренное
решение. Примерами
такого решения
являются решение
о завершении
итерационного
цикла при достижении
всеми необходимой
точности, решение
о реакции на
отказ. Во-вторых,
протоколы
принятия
согласованных
решений
на основе полученных
друг от друга
данных. При
этом необходимо
всем исправным
исполнителям
получить достоверные
данные от остальных
исправных
исполнителей,
а данные от
неисправных
исполнителей
проигнорировать
Однако
для систем на
последней
стадии их деградации
(при отказе
предпоследнего
узла сети) на
первый план
в качестве
диагностической
информации
выходят признаки
исправности-неисправности,
формируемые
различными
программно-аппаратными
средствами
контроля, такими
как:
функциональный
контроль вычислений
с помощью
специальных
контрольных
операторов
и нескольких
версий программ;
функциональный
контроль входной
и выходной
информации;
контроль
входной информации
по специальным
признакам и
контрольным
суммам;
контроль
выходной информации
по квитанции
от приемника
- абонента
системного
интерфейса;
контрольный
тест аппаратуры
процессора;
контрольные
тесты аппаратуры
внешнего и
внутреннего
интерфейсов.
встроенные
аппаратные
средства контроля
процессорных
элементов и
контроллеров
системного
интерфейса.
Информационная
избыточность
состоит в
дублировании
исходных и
промежуточных
данных, обрабатываемых
комплексом
программ.
Часто
для обнаружения
состояния
отказа используются
тайм-ауты. В
обычных системах
исполнения
предусматривается
три различных
вида обслуживания.
Неблокирующее
обслуживание
всегда возвращает
управление
немедленно
вместе с достоверным
кодом возврата
(успех или неудача),
однако, в случае
отсутствия
данного вида
обслуживания,
обратившаяся
к нему задача
может попасть
в бесконечный
цикл опроса.
Блокирующее
обслуживание
избегает такого
опроса путём
исключения
вызывающей
задачи из процесса
диспетчеризации
до тех пор, пока
данный сервис
не станет доступным.
Если этого не
произойдет,
то задача рискует
навсегда остаться
заблокированной.
Механизм же
таймаутов
позволяет
возвращать
управление
задаче, даже
в случае, если
указанный
сервис не
предоставляется
ей в течение
определенного
периода времени.
Концепция
построения
и работы системы
с рангом
отказоустойчивости
N-1.
В
отказоустойчивых
системах, построенных
на N
процессорных
элементах,
рангом
отказоустойчивости
будем называть
максимальное
количество
отказов функциональных
элементов (ПЭ),
после возникновения
которых система
продолжает
свое функционирование.
Введем обозначение
- N(m),
которое означает,
что система
содержит N
узлов (ПЭ) и «держит»
m
отказов, т.е.
нормально
функционируют
до тех пор, пока
остаются исправными
(N-m) узлов. Следует
заметить, что
системы класса
N(0)
– относятся
к самым быстродействующим
системам, а
N(N-1)
– к самым отказоустойчивым.
В
дальнейшем
в работе будем
рассматривать
концепции
построения
и работы именно
отказоустойчивых
систем класса
N(N-1).
Данное ограничение
означает, что
в каждом ПЭ
системы должен
присутствовать
весь набор
функционального
программного
обеспечения,
то есть каждый
цикл ПЭ осуществляет
полную обработку
входных данных
без участия
других ПЭ.
Таким
образом, специализированные
операционные
системы, поддерживающие
свойство
отказоустойчивости
для данного
класса ВС, должны
обладать следующими
свойствами:
1.
ОС представляет
собой совокупность
информационно
взаимосвязанных
и согласовано
функционирующих
операционных
систем каждого
отдельного
узла сети ВС.
Информационная
взаимосвязанность
операционных
систем узлов
между собой
обеспечивается
за счет передачи
каждой ОС всем
остальным
следующей
информации:
результатов
«голосования»
(сравнения)
поступающей
в данный ПЭ
функциональной
информации;
результатов
оценки поступившей
от других ОС
узлов;
«результатов
голосования»
(т.е. «вывод»
данного ПЭ о
состоянии
других ПЭ).
Все
операционные
системы узла
идентичны и
отличаются
друг от друга
лишь своим
номером и содержанием
системных
таблиц.
2.
Внутренняя
структура
распределенной
ОСРВ представляет
собой иерархию
уровней в которой
каждый уровень
использует
функциональные
возможности
предыдущего.
Добавление
или удаление
модулей позволяет
создавать
системы различных
конфигураций.
Кроме того,
данный принцип
построения
ОСРВ позволяет
осуществлять
ее расширение
путем добавления
новых модулей,
а расширение
с минимальными
изменениями
подразумевает
открытость
системы.
3.
ОС должна обладать
возможностью
использования
на различных
аппаратных
платформах
с минимальными
модификациями
соответствующих
программ, то
есть обладать
свойством
переносимости.
4.
ОС должна обладать
свойством
масштабируемости,
что в узком
смысле означает
обеспечение
ее настраиваемости
на поддержку
функционирования
сетевых ВС
различной
размерности
N (для реальных
систем в пределах
3
N
10). Причем правая
граница изменения
N (Nmax = 10) выбрана из
практических
соображений
построения
ВС с высокой
степенью связности
узлов сети при
использовании
конкретных
процессорных
модулей количеством
линков (L) не более
шести (L6).
При L=6 семиузловая
сеть является
полносвязанной
и по мере увеличения
N степень связности
узлов сети
уменьшается.
5.
Времени для
выполнения
всех необходимых
действий должно
хватать с запасом
20-30% с учетом
производительности
аппаратной
платформы.
С
учетом этого
факта (достаточности
ресурса производительности)
диспетчеризация
вычислений
сводится к
поддержке
следующих
процедур:
синхронизация
вычислений
- по циклам выдачи
управляющих
сигналов (команд),
задаваемых
таймером ведущего
узла (с меньшим
номером среди
активных узлов);
полная
обработка
функциональной
задачи в пределах
одного цикла;
использование
сторожевого
таймера во
всех активных
узлах сети как
средства защиты
от зацикливания
(зависания)
вычислительного
процесса;
разделение
цикла работы
системы на
следующие
периоды: ввод
данных, решение
ФЗ, обмен функциональными
данными (ФД),
обмен результатами
голосования
ФД, обмен предварительными
выводами о
состоянии
системы, принятие
консолидированного
решения (КР) о
состоянии
системы, реконфигурация
системы при
обнаружении
в рамках КР
отказа части
системы.
В
дальнейшем
этот перечень
требований
к ОСРВ будет
продолжен и
детализирован.
Рассмотрим
общую концепцию
работы такой
системы. После
получения
результатов
расчета на
очередном
цикле, система
должна получить
информацию
о своем состоянии,
для чего осуществляется
обмен результатами
с остальными
ПЭ системы. При
этом следует
отметить, что
обмен результатами
счета со всеми
узлами ВС в
некоторой мере
избыточен, так
как для выявления
некорректного
результата
достаточно
двух верных
(в предположении
об ординарности
потока отказов).
Таким образом,
протокол голосования
может быть
построен так,
что результаты
счета отдельного
ПЭ в ВС троируются,
т.е. могут не
присутствовать
в некоторых
узлах системы.
Во
время сравнения
ПЭ делает вывод
о нормальном
или неправильном
функционировании
доступной ей
подсистемы
и выявляет ее
причину. Результатами
сравнения ПЭ
обменивается
со всеми узлами
системы, и они
принимают
консолидированное
решение об
отказе того
или иного элемента
или делают
заключение
о нормальной
работе системы.
В
случае обнаружения
отказа, на выход
выдаются результаты,
признанные
верными при
голосовании.
Отказавшему
элементу
предоставляется
возможность
«исправиться»
в течение следующих
трех циклов.
При этом сбойному
ПЭ передается
контекст верно
функционирующей
задачи. Тройная
попытка самоустранить
сбой этого
узла, должна
практически
исключать
возможность
отключения
работоспособного
ресурса системы.
Если сбои в
этом элементе
повторились,
система считает
элемент отказавшим,
после чего
производится
подключение
к работе резервного
ПЭ (если он
предусмотрен
изначальной
топологией
сети) с передачей
текущего контекста
функциональных
задач. При отказе
связей передача
данных производится
через транзитные
связи. Если
элемент утратил
все свои связи
(линки), то он
изолируется
на логическом
или, если это
возможно – на
физическом
уровне (отключение
питания).
В
настоящее время
существуют
различные ОСРВ,
призванные
решать задачи
организации
вычислений
в системах РВ.
Однако ни одна
из них не удовлетворяет
поставленным
требованиям
в полной мере.
Поэтому встает
вопрос о необходимости
расширения
существующих
ОСРВ или разработки
новой ОС, удовлетворяющей
им. Поскольку
создание ОС
с удобными
средствами
создания и
отладки прикладного
программного
обеспечения
- длительный
и трудоемкий
процесс, единственным
выходом является
доработка
существующих
ОС.
В
качестве основного
подхода к обеспечению
отказоустойчивости
предлагается
использовать
избыточность
аппаратных
и программных
компонент
системы. Данный
подход предполагает
решение следующих
вопросов:
дополнение
ОС высокоуровневыми
функциями
обмена. Используемые
в большинстве
ОС стандартные
средства обмена
данными, определенные
стандартом
POSIX
(каналы, сигналы,
разделяемая
память, семафоры),
имеют ограниченные
возможности
при взаимодействии
процессов, не
имеющих родственных
связей. Организация
межпроцессного
взаимодействия
с помощью механизма
сокетов неудобна
из-за необходимости
привязки к
конкретной
сетевой информации
(IP-
адрес узла,
номер порта
приложения)
и своей ориентированностью
на модель
клиент-сервер.
введение
приоритета
для передаваемых
сообщений.
Важность сообщений,
передаваемых
по сети, неодинакова.
Например, сообщения
об отказе какой-либо
компоненты
системы должны
иметь наивысший
приоритет для
того, чтобы
оповестить
узлы сети в
кратчайшие
сроки.
выбор
и реализация
механизма
голосования.
При этом механизм
передачи/приема
данных и голосования
должен быть
по возможности
скрыт от прикладного
программиста.
Такая
концепция
построения
операционной
системы предусматривает
наличие специальных
средств обеспечения
быстрого реагирования
на отказ и
реконфигурации
системы. Ими
являются модуль
маршрутизации,
обеспечивающий
оптимальные
маршруты для
передачи
функциональной
и системной
информации
как на начальном
этапе инициализации
системы, так
и в процессе
ее функционирования
при отказе тех
или иных элементов
и при подключении
резервных,
модуль реконфигурации,
служащий для
перестройки
системных
таблиц при
отказах и
восстановлении
работоспособности
системы, модуль
межпроцессорного
обмена, для
передачи
информационных
и системных
пакетов данных.
Рассмотрим
их структуру
и назначение
подробнее.
2.4.1.
Описание системных
таблиц
Основная
информация
о функционировании
операционной
системы на
данном ПЭ размещена
в системных
таблицах.
Граф
информационной
связности
процессорных
элементов
задаётся в виде
модифицированной
матрицы связности.
Отличие от
стандартной
матрицы связности
заключается
в том, что в рамках
одной строки,
описывающей
связность
данного ПЭ с
другими, используется
число «-1» в случае,
если этот
процессорный
элемент не
связан с ПЭ,
задаваемом
столбцом, и
номер канала
связи (линка)
по которому
осуществляется
эта связность
в противном
случае, причем
нумерацию
линков для
удобства можно
начинать c
m+1
узла, то есть
для узла m
связь с узлом
m+1
будет осуществляться
линком с наименьшим
номером.
Таблица
2.1
Пример
таблицы связности
для полносвязной
сети ПЭ
|
№/№
|
1
|
2
|
3
|
4
|
… |
N
|
|
1
|
-1
|
0
|
1
|
2
|
… |
N-2
|
|
2
|
N-2
|
-1
|
0
|
1
|
… |
N-3
|
|
3
|
N-3
|
N-2
|
-1
|
1
|
… |
N-4
|
|
4
|
N-4
|
N-3
|
N-2
|
-1
|
… |
N-5
|
| … |
… |
… |
… |
… |
… |
… |
|
N
|
0
|
1
|
2
|
3
|
… |
-1
|
В
дополнение
к таблице связности,
должна существовать
таблица рассылки,
в которой каждому
ПЭ сопоставлен
номер канала
связи, по которому
надо передать
пакет дальше,
чтобы он в конечном
счете дошёл
до адресата.
Для полносвязной
сети такая
информация
может показаться
избыточной,
однако если
сеть неполносвязная
или в ней произошли
отказы связей,
то таблица
рассылки, формируемая
на этапе инициализации
и реконфигурации
системы, позволит
экономить время
при обмене
информацией
или результатами
голосования
на каждом цикле.
Составлением
таблиц рассылки
занимается
модуль маршрутизации,
структура и
алгоритм работы
которого будет
рассмотрена
ниже.
Приведем
пример таблиц
рассылки. Для
наглядности
возьмем сеть
из четырех ПЭ,
представленную
на рисунке 2.1.

Рис.
2.1. Пример
неполносвязной
сети
Цифры
в окружностях
– номера процессорных
элементов, вне
– номера линков
(физических
каналов связи).
Таким образом
таблица связности
имеет вид (таблица
2.2).
Таблица
2.2
Таблица
связности для
примера на
рисунке 2.1
|
№/№
|
1
|
2
|
3
|
4
|
|
1
|
-1
|
0
|
-1
|
1
|
|
2
|
1
|
-1
|
0
|
-1
|
|
3
|
1
|
-1
|
-1
|
0
|
|
4
|
0
|
-1
|
1
|
-1
|
Таблицы
рассылки для
каждого ПЭ
могут иметь
вид (см. Таблицу
2.3, 2.4, 2.5, 2.6).
Таблица
2.3
Таблица
рассылки для
ПЭ №1
|
№
ПЭ
|
1
|
2
|
3
|
4
|
|
№
Линка
|
-1
|
0
|
0
|
1
|
Таблица
2.4
Таблица
рассылки для
ПЭ №2
|
№
ПЭ
|
1
|
2
|
3
|
4
|
|
№
Линка
|
1
|
-1
|
0
|
0
|
Таблица
2.5
Таблица
рассылки для
ПЭ №3
|
№
ПЭ
|
1
|
2
|
3
|
4
|
|
№
Линка
|
0
|
1
|
-1
|
0
|
Таблица
2.6
Таблица
рассылки для
ПЭ №4
|
№
ПЭ
|
1
|
2
|
3
|
4
|
|
№
Линка
|
0
|
0
|
1
|
-1
|
2.4.2.
Модуль маршрутизатора
Как
уже отмечалось
в подразделе
2.4.1 маршрутизатор
выполняет
следующие
функции:
хранение
текущей топологии
многопроцессорной
системы;
установление
оптимальных
статических
маршрутов
передач данных
в системе и
таблиц рассылки;
обработка
сигналов изменения
топологии
системы от
реконфигуратора.
При
инициализации
требуется
исходная топология
системы. Таким
образом, модуль
маршрутизации
можно представить
в виде следующей
упрощенной
схемы:

Рис.
2.2. Модуль маршрутизации
Во
время инициализации,
для каждого
ПЭ составляется
список текущих
соседних узлов
системы для
обмена результатами
счета так, чтобы
данные каждого
ПЭ присутствовали
в тройном экземпляре
в ВС.
Таблицы
рассылки, в
которой каждому
ПЭ сопоставлен
номер канала
связи, по которому
надо передать
пакет дальше,
формируются
методом волны
на основе таблиц
связности ПЭ.
Маршрут выбирается
минимальным
по количеству
рёбер графа
сети, с учетом
загрузки связей.
Так как операционные
системы узлов
идентичны, то
пакеты, проходящие
через их связи
можно считать
одинаковыми.
Загрузка связи
определяется
по числу возможных
транзитных
передач через
эту связь, и
транзитные
передачи равномерно
распределяются
по узлам сети
без потерь на
длине маршрута.
Алгоритм
определения
статических
маршрутов и
заполнения
таблицы рассылки:
Заполняем
таблицу рассылки
в соотвествие
со строкой с
номером, равным
номеру процессорного
элемента. Заполняем
соответствующую
таблицу расстояний
единицами
(счетчик длины
маршрута) в
тех ячейках,
где есть прямая
связь в
таблице связности
(>0).
Если
обработаны
все ПЭ, закончить.
Увеличиваем
счетчик длины
маршрута на
1 единицу (передачу).
По
таблице рассылки
находим очередной
ПЭ, не имеющий
связи с локальным.
Если таких
больше нет,
шаг 8.
Среди
имеющих связь
ПЭ ищем по таблице
расстояний
того, у кторого
маршрут был
определен на
предыдущем
цикле. Если
таких больше
нет, шаг 7.
Если
он имеет связь
с нужным ПЭ,
запоминаем
номер линка
для связи его
с локальным
ПЭ и загрузку
линка. Шаг 5.
Сортируем
найденные
линки по наменьшей
загруженности
и заносим его
в таблицу рассылки
и таблицу
расстояний.
Если
обработаны
все ПЭ, закончить,
иначе шаг 3.
2.4.3.
Модуль реконфигурации
Модуль
реконфигурации
активизируется
и выполняет
перестройку
системных
таблиц ОС на
основе информации
о конкретном
отказе. Рассмотрим
обработку
отказа функциональной
задачи, отказа
канала связи
и отказа процессора
целиком.
При
этом приостановки
работы системы
в общем случае
не должно происходить
из-за возможной
необходимости
в выдачи управляющих
воздействий
в жестком цикле
работы системы.
Резервы времени
должны предусматриваться
на этапе проектирования
в зависимости
от вычислительных
ресурсов элементов
системы. Таким
образом, реконфигурация
должна быть
выполнена до
начала выдачи
результатов
контроллерам
приемников
управляющей
информации.
Отказ
канала связи.
Первоначально
корректируется
матрица связности
ПЭ. При этом
определяется,
имеет ли отказавший
канал связи
отношение к
данному процессорному
элементу. В
случае, если
после отказа
канала связи,
какой-либо
процессор
оказывается
изолированным,
выполняется
отключение
процессорного
элемента.
Отказ
процессорного
элемента.
Обработка
отказа всего
процессорного
элемента выполняется
посредством
коррекции
матрицы связности
ПЭ, удаление
всех каналов
связи.
Отказ
функциональной
задачи
трактуется
так же, как и
отказ процессорного
элемента.
Реконфигуратор
тесно связан
с модулем
маршрутизации
и обращается
к нему сразу
после изменения
системных
таблиц для
коррекции
таблиц рассылки
и определения
активных элементов
системы. Обобщенная
модель реконфигуратора
может быть
представлена
на следующей
схеме:

Рис.
2.3. Модуль
реконфигурации
После
отказа функционального
элемента, процесс
реконфигурации
осуществляется
по следующей
схеме:
В
таблице связности
отказавший
линк или линки
отказавшего
ПЭ помечаются
как недоступные.
Проверяется,
не остались
ли изолированными
оставшиеся
узлы, если да,
то они отключаются.
По
таблице связности
определяется
новый список
соседних узлов
системы, определяется
ПЭ, которого
(которых) необходимо
вывести из
резерва.
Производится
активизация
резервного
ПЭ путем передачи
ему кода активизации,
текущей таблицы
связности и
контекста
задачи от старшего
ПЭ в ВС (например,
от ПЭ с младшим
номером).
2.4.4.
Модуль коммуникации
Основной
задачей этого
модуля является
организация
информационного
обмена между
процессами
в системе, то
есть передача
информационных
сообщений между
функциональными
задачами и
системных
сообщений между
операционными
системами
разных ПЭ.
Таким
образом, модуль
коммуникации
обеспечивает:
получение
запроса на
прием/передачу
данных от
функциональной
задачи;
установление
соответствия
между передатчиком
и приемником
данных;
передача
сообщения и
идентификаторов
адресатов
модулю пересылки
информации;
хранение
принимаемых
данных;
проверка
согласованности
данных от
резервированных
источников
(голосование);
выявление
в результате
голосования
отказа компонент
системы и посылка
соответствующего
сигнала модулю
реконфигурации;
передача
согласованных
данных ФЗ;
передача/прием
системных
сообщений.
Модуль
пересылки
информации:
формирование
формата передаваемого
сообщения;
идентификация
принимаемых
сообщений;
диагностика
целостности
принимаемых
сообщений
(проверка
контрольной
суммы);
определение
отказов физической
среды передачи
данных (проверка
подтверждений
приема данных
– “квитанций”);
формирование
сигнала модулю
ОС – реконфигуратору
о неисправности
среды передачи.
В
своей работе
модуль опирается
на функции
ввода-вывода
нижележащего
модуля пересылки
информации.
Поскольку
распределенная
ОСРВ является
надстройкой
над базовой
ОС нижнего
уровня, она не
имеет доступа
к аппаратуре
ПЭ и не может
осуществлять
ввод-вывод на
основе обработки
прерываний.
Общая структура
взаимодействия
модулей представлена
на рис. 1.3:

Рис.
2.4. Структура
модулей коммуникации
В
связи с этим
для обеспечения
приёма и передачи
информации
по каналам
связи, для
обслуживания
каждого из них
создаётся
задача прослушивания.
Прослушивание
каналов связи
осуществляется
после отработки
задачи на очередном
цикле. При этом
должна происходить
проверка, не
является ли
сообщение
транзитным,
и в случае транзитной
передачи, немедленно
осуществлять
отсылку по
нужному каналу
связи из таблицы
рассылки.
Формат
посылки состоит
из заголовка
и самого тела
посылки. В заголовке
используются
следующие поля:
Получатель
(номер ПЭ);
Отправитель;
Тип
посылки (информационная
или системная);
Размер
информационной
части посылки
(может быть
нулевой);
Контрольная
сумма пакета.
Передача
информации
происходит
сразу после
завершения
функциональной
задачей процедуры
расчета, и управление
передается
задаче прослушивания
(модулю пересылки),
причем на это
отводится
фиксированное
время (включается
сторожевой
таймер), равное
максимальному
периоду обмена
между процессорными
элементами
в активной
тройке. Максимальным
временем в
данном случае
будет время
с учетом транзитных
передач через
узлы ВС при
отказе связей,
которое может
составлять
до N-1 периодов
записи.
2.4.5.
Процедура
голосования
Под
голосованием
будем понимать
совокупность
элементарных
проверок
(сопоставлений
результатов)
независимых
решений одного
и того же фрагмента
задачи.
По
результатам
сравнения
формируется
вектор промежуточного
состояния
(предварительный
вывод о состоянии
системы). Например,
вектор может
состоять из
0, если соответствующий
узел исправен
по результатам
сравнения или
–1, при расхождении
результатов
сравнения. При
этом, если данные
текущего узла
не совпадают
с одинаковыми
результатами
соседних ПЭ,
то текущий узел
может прогнозировать
собственный
сбой.
Далее
следует обмен
результатами
сравнения по
описанной выше
схеме. Голосование
проводится
сравнением
векторов
промежуточного
состояния всех
активных ПЭ.
Вывод о сбое
или отказе того
или иного узла
делается при
совпадении
хотя бы двух
промежуточных
результатов.
Несовпадение
результатов
сравнения может
быть вызвано
сбоем или отказом
физического
канала связи.
Этому может
предшествовать
сигнал о неисправности
канала связи
от модуля
коммуникации.
В противном
случае (при
отсутствии
сигнала), сбой
в линии связи
может быть
определен по
полученным
векторам состояния.
Например ПЭ
получены следующие
вектора: (0,-1,0),
(-1,0,0), (0,0,0), где каждому
вектору и каждому
элементу вектора
поставлен в
соответствие
номер ПЭ (то
есть ПЭ1, ПЭ2, ПЭ3).
Анализ сравнения
этих промежуточных
результатов
может сказать
о неисправности
канала связи
между ПЭ1 и ПЭ2.
При
таком построении
системы сделано
неявное допущение
о том, что на
протяжении
одного цикла
может отказать
не более одного
элемента системы,
иначе поведение
её в таком случае
строго говоря
недетерминировано.
Впрочем данное
допущение может
быть аргументировано
тем, что время
наработки на
отказ отдельного
элемента системы
составляет
по крайней мере
несколько тысяч
часов, и считая
возникновения
отказов независимыми
событиями,
вероятность
отказа одновременно
двух элементов
на протяжении
цикла (порядка
10 - 100 мс) величина
порядка 10-17
- 10-18.
Однако
при возникновении
такой ситуации
выходом может
быть применение
методов помехоустойчивого
статистического
оценивания
результатов
расчета [10], проведение
диагностических
тестов и тд.
для выбора
корректного
результата
и принятия
решения о выдаче
того или иного
управляющего
воздействия
на текущем
цикле.
2.5. Организация
отказоустойчивых
вычислений
В
данном разделе
примем во внимание
введенное ранее
предположение
об ординарности
потока отказов,
то есть на протяжении
одного цикла
(такта) работы
системы множественные
отказы не возникают.
Отметим,
что реакция
систем диагностирования
отказов такова:
Несовпадение
данных при
элементарной
проверке (сравнении)
результатов
счета на очередном
цикле диагностируется,
как отказ ПЭ
или канала
связи этого
ПЭ.
При
несовпадении
данных при
элементарной
проверке результатов
счета, полученных
с использованием
транзитной
передачи, под
сомнение ставится
вся цепочка,
задействованная
при передаче.
При
несовпадении
ни одного результата
счета под сомнение
ставится все
участвовавшие
в обмене ПЭ и
связи.
Несовпадение
контрольной
суммы или тайм-аут
при приеме
данных трактуется
как сбой ПЭ
или канала
связи ПЭ.
Отсутствие
квитанции
трактуется
как сбой ПЭ
или канала
связи ПЭ.
Неверный
код квитанции
трактуется
как сбой канала
связи ПЭ.
Напомним,
что идея организации
отказоустойчивых
вычислений
основана на
использовании
трех типов
избыточности:
аппаратной,
программной
и информационной.
Т.е. заданная
задача реализуется
на более чем
трех процессорных
элементах сети.
Рабочая конфигурация
сети состоит
из трех ПЭ,
результаты
счета копия
задачи отсылает
в пределах
рабочей конфигурации.
На основании
результатов
голосования
формируется
информация
о ходе вычислительного
процесса и о
состоянии
аппаратуры
(исправна -
неисправна)
ВС. Этой информации
достаточно
(как правило
с большей
избыточностью)
для принятия
решения о перестройке
(реконфигурации)
сети при возникновении
отказов аппаратуры
ВС.
Все
копии функциональной
задачи решаются
с одинаковыми
наборами входных
параметров
и поэтому (при
отсутствии
неисправностей)
формируют
одинаковые
результаты
(голосование
по совпадению
кодов). Проблемы
ввода и вывода
внешней по
отношению к
ВС информации
не рассматриваются,
при этом предполагается,
что достоверная
внешняя информация
поступает в
соответствующие
узлы сети на
входы копий
задачи - приемников
входной информации.
2.5.1
Пример организации
отказоустойчивых
вычислений
В
рамках этих
предположений,
рассмотрим
пример реализации
отказоустойчивых
вычислений
на ВС (граф см.
на рис 2.5), состоящей
из пяти узлов.
Каждый узел
изначально
отличается
от остальных
только своим
номером в таблице
связности.

Рис
2.5. Топология
ВС
Физическая
связь (линк)
под номером
4 используется
каждым ПЭ для
обмена с объектом
управления
и приема данных
функциональной
задачей для
расчета на
очередном
цикле. В данной
главе аспекты
использования
и надежности
этих связей
не рассматриваются,
анализу подвергается
только внутренняя
структура ВС.
2.5.1.
Инициализация
Для
инициализации
работы процессорных
элементов
используются
конфигурационные
файлы, содержащие
номер ПЭ и таблицу
связности
(таблица 2.8).
Таблица 2.8
-
|
№/№
|
1
|
2
|
3
|
4
|
5
|
|
1
|
-1
|
0
|
1
|
2
|
3
|
|
2
|
3
|
-1
|
0
|
1
|
2
|
|
3
|
2
|
3
|
-1
|
0
|
1
|
|
4
|
1
|
2
|
3
|
-1
|
0
|
|
5
|
0
|
1
|
2
|
3
|
-1
|
На
основе анализа
таблицы связности
определяется
статические
маршруты каждого
ПЭ и текущая
рабочая конфигурация
каждого ПЭ по
критерию связности,
в данном случае
обмен результатами
счета осуществляется
следующим
образом :
ПЭ1
-> ПЭ2 и ПЭ3;
ПЭ2
-> ПЭ3 и ПЭ4;
ПЭ3
-> ПЭ4 и ПЭ5;
ПЭ4
-> ПЭ5 и ПЭ1;
ПЭ5
-> ПЭ1 и ПЭ2;
В штатном
режиме функционирования
ВС (при отсутствии
неисправностей)
на выходе каждой
копии функциональной
задачи (т.е. в
5-и точках) путем
голосования
на совпадение
результатов
подтверждается
правильность
реализации
вычислительного
процесса подсистемы.
Представим
теперь, что
произошел
первый отказ
аппаратуры.
Пусть отказал
канал связи
между ПЭ1 и ПЭ3.
Если при
каком-либо
отказе процессорный
элемент вообще
не выдает результаты
счета, то голосование
осуществляется
с использованием
соответствующих
результатов
систем диагностирования
(проверка КС,
квитанций).
Таким
образом, в результате
в узлах сети
фиксируются
следующие факты
несовпадения
результатов
счета, представленные,
для наглядности,
в виде таблицы
2.9, в которой каждый
линк обозначен
с помощью двух
цифр - номеров
связываемых
им процессорных
элементов.
Таблица
2.9
| № ПЭ |
Получены
данные от ПЭ
№ |
Данные
от
ПЭ №
|
Не совпадают
с данными от
ПЭ № |
Возможная
причина:
Неисправность
ПЭ №
или Линк №
|
|
1
|
4
, 5
|
|
|
Нет
неисправности |
|
2
|
5 , 1 |
|
|
Нет
неисправности |
|
3
|
1 , 2 |
1 |
2 , 3 |
1
1-3 |
|
4
|
2 , 3 |
|
|
Нет
неисправности |
|
5
|
3 , 4 |
|
|
Нет
неисправности |
После
обмена результатами
голосования,
в узлах может
оказаться
противоречивая
информация,
представленная
таблицей 2.10.
Следует уточнить,
что на каждом
новом такте
область памяти
зарезервированная
под результаты
голосования
соседних ПЭ
переинициализируется,
то есть содержит
«мусор» до
занесения вновь
обновленной
информации.
Анализ
информации
ПЭ1 позволяет
сделать вывод
о работоспособности
ПЭ3, поскольку
сообщение о
его неисправности
не подтвердили
ПЭ4 и ПЭ5, и выявить
сбой в канале
связи 3-1. Анализ
ПЭ2, ПЭ3, ПЭ4, ПЭ5
полученной
информации
показывает
на неисправность
линка 3-1, поскольку
работоспособность
ПЭ1 подтверждается
узлом ПЭ2 и наличием
в памяти достоверной
информации
о состоявшемся
сеансе связи
с ПЭ1.
Таблица
2.10
|
ПЭ№
|
Данные
голосования
от ПЭ №
|
Возможная
причина неисправности
ПЭ № или Линк
№
|
Вывод
|
Консолидированное
решение
|
|
1
|
Нет
неисправности
|
|
|
|
2
|
Нет
неисправности
|
|
|
|
1
|
3
|
"мусор"
|
Неисправен
Линк 3-1
|
|
|
4
|
Нет
неисправности
|
|
|
|
5
|
Нет
неисправности
|
|
|
|
1
|
Нет
неисправности
|
|
|
|
2
|
Нет
неисправности
|
|
|
|
2
|
3
|
1
1-3
|
Неисправен
Линк 3-1
|
|
|
4
|
Нет
неисправности
|
|
|
|
5
|
Нет
неисправности
|
|
|
|
1
|
"мусор"
|
|
|
|
2
|
Нет
неисправности
|
|
|
|
3
|
3
|
1
1-3
|
Неисправен
Линк 3-1
|
Неисправен
Линк 3-1
|
|
4
|
Нет
неисправности
|
|
|
|
5
|
Нет
неисправности
|
|
|
|
1
|
Нет
неисправности
|
|
|
|
2
|
Нет
неисправности
|
|
|
|
4
|
3
|
1
1-3
|
Неисправен
Линк 3-1
|
|
|
4
|
Нет
неисправности
|
|
|
|
5
|
Нет
неисправности
|
|
|
|
1
|
Нет
неисправности
|
|
|
|
2
|
Нет
неисправности
|
|
|
|
5
|
3
|
1
1-3
|
Неисправен
Линк 3-1
|
|
|
4
|
Нет
неисправности
|
|
|
|
5
|
Нет
неисправности
|
|
|
При
появлении такой
ситуации могут
возникнуть
следующие
трудности:
1.
Недостоверность
переданной
информации
была вызвана
кратковременным
сбоем, при этом
ПЭ1 получил
достоверные
результаты
счета, а ПЭ3 –
недостоверные.
Решение:
отключении
канала связи
3-1 происходит
только при
троекратном
повторении
сбоя.
2.
Сбой возник
на этапе обмена
результатами
голосования.
Решение:
сбой фиксируется
наличием “мусора”
вместо стандартных
значений, но
«полноценное»
обнаружение
сбоя (если он
повторится)
произойдет
на следующем
такте.
В
любом случае
следует проводить
еще один обмен
в рабочей сети,
для аккумуляции
решений всех
ПЭ, и определения
достоверного
вывода путем
их сравнения.
После
принятия
окончательного
решения об
отказе связи
3-1, инициируется
реконфигуратор,
вносящий
соответствующие
изменения в
таблицу связности
(см таблицу
2.11).
Таблица 2.11
|
№/№
|
1
|
2
|
3
|
4
|
5
|
|
1
|
-1
|
0
|
-1
|
2
|
3
|
|
2
|
3
|
-1
|
0
|
1
|
2
|
|
3
|
-1
|
3
|
-1
|
0
|
1
|
|
4
|
1
|
2
|
3
|
-1
|
0
|
|
5
|
0
|
1
|
2
|
3
|
-1
|
Далее
реконфигуратор
проводит проверку
на нарушение
связности в
рабочей сети.
В данном случае
изменяются
статические
маршруты ПЭ
и связь между
ПЭ1 и ПЭ3 осуществляется
через ПЭ2.
Предположим
теперь, что
отказал ПЭ4.
При этом ПЭ4
может вести
себя двояко:
либо наступил
фатальный отказ
и ПЭ не выдает
результатов,
либо выдает
искаженные
результаты.
Во втором случае
так же может
быть два варианта:
ПЭ сохраняет
способность
правильно
осуществлять
обмен и голосование.
В этом случае
ПЭ способен
диагностировать
собственную
ошибку. В противном
случае считается,
что сбойный
узел выдает
результаты,
не несущие
информативной
нагрузки (“мусор”).
Проиллюстрируем
все случаи.
После
этапа сравнения
информации,
в системе может
оказаться
следующая
информация
(таблица 2.12).
Таблица
2.12
| № ПЭ |
Получены
данные от ПЭ
№ |
Данные
от
ПЭ
№
|
Не
совпадают с
данными от
ПЭ № |
Возможная
причина:
Неисправность
ПЭ
№ или Линк №
|
|
1
|
4
, 5 |
4 |
1
, 5 |
4
1-4 |
|
2
|
5
, 1 |
|
|
Нет
неисправности |
|
3
|
1
, 2 |
|
|
Нет
неисправности |
|
4
Вариант
1
|
2
, 3 |
|
|
«мусор» |
|
4
Вариант
2
|
2
, 3
|
4 |
2
, 3 |
4
4-3 , 4-2 |
|
5
|
3
, 4 |
4 |
3
, 5 |
4
5-4 |
После
обмена результатами
голосования,
во всех узлах
может оказаться
информация,
представленная
таблицей 2.13.
Таблица
2.13
|
Данные
голосования
от ПЭ №
|
Возможная
причина неисправности
ПЭ № или Линк
№
|
Вывод
|
Консолидированное
решение
|
|
1
|
4
4-1
|
|
|
|
2
|
Нет
неисправности
|
|
|
|
3
|
Нет
неисправности
|
|
|
|
4
Вариант 1
|
«мусор»
|
Неисправность
ПЭ4
|
Неисправность
ПЭ4
|
|
4
Вариант 2
|
4
4-3 , 4-2
|
|
|
|
5
|
4
5-4
|
|
|
Вариант
1:
Сообщение от
ПЭ4, содержит
«мусор», что
говорит о
неисправности
ПЭ4 или его каналов
связи. Однако
ПЭ1 и ПЭ5 приняли
решение о
неисправности
ПЭ4 или каналов
связи 5-4, 4-1. Поскольку
отказ сразу
всех каналов
связи ПЭ4 и отказ
ПЭ4 события
равнозначные,
принимается
решение об
неисправности
ПЭ4.
Вариант
2:
Сообщение ПЭ4
подтверждает
результаты
голосования
в тройке ПЭ4,
ПЭ5, ПЭ1 и принимается
решение об
отказе ПЭ4.
После
двух отказов
(линка 3-1 и ПЭ4) ВС
имеет вид (рис.
2.6)

Рис.2.6.
Топология ВС
после 2-х отказов
Таблица
связности,
измененная
реконфигуратором,
представлена
таблицей 2.14. Обмен
результатами
счета теперь
осуществляется
следующим
образом:
ПЭ1
-> ПЭ2 и ПЭ3;
ПЭ2
-> ПЭ3 и ПЭ5;
ПЭ3
-> ПЭ5 и ПЭ1;
ПЭ5
-> ПЭ1 и ПЭ2;
Таблица
2.14
Обновленная
таблица связности
|
№/№
|
1
|
2
|
3
|
4
|
5
|
|
1
|
-1
|
0
|
-1
|
-1
|
3
|
|
2
|
3
|
-1
|
0
|
-1
|
2
|
|
3
|
-1
|
3
|
-1
|
-1
|
1
|
|
4
|
-1
|
-1
|
-1
|
-1
|
-1
|
|
5
|
0
|
1
|
2
|
-1
|
-1
|
Рассмотрим
дальнейший
процесс деградации
системы. Отказ
ПЭ5 аналогично
легко диагностируется,
благодаря
связям с каждым
ПЭ в системе.
Предположим
теперь, что
произошел отказ
канала связи
2-3. Напомним, что
связь ПЭ1 и ПЭ3
осуществляется
через ПЭ2.
Таким
образом, в результате
в узлах сети
фиксируются
следующие факты
несовпадения
результатов
счета, представленные
в таблице 2.15.
Таблица
2.15
| № ПЭ |
Получены
данные от ПЭ
№ |
Данные
от
ПЭ №
|
Не совпадают
с данными от
ПЭ № |
Возможная
причина:
Неисправность
ПЭ №
или Линк №
|
|
1
|
3,5 |
3 |
1 , 5 |
2 или 3 2-1
или 2-3 |
|
2
|
1,5 |
|
|
Нет
неисправности |
|
3
|
1,2 |
|
Нет
совпадений |
Недостаточно
данных |
|
5
|
2,3 |
|
|
Нет
неисправности |
После
обмена результатами
голосования,
в узлах может
оказаться
информация,
представленная
таблицей 2.16.
Таблица
2.16
|
ПЭ№
|
Данные
голосования
от ПЭ №
|
Возможная
причина неисправности
ПЭ № или Линк
№
|
Вывод
|
Консолидированное
решение
|
|
1
|
2
или 3 2-1 или 2-3
|
|
|
|
2
|
Нет
неисправности
|
|
|
|
1
|
3
|
"мусор"
|
Неисправен
Линк 2-3
|
|
|
5
|
Нет
неисправности
|
|
|
|
1
|
2
или 3 2-1 или 2-3
|
|
|
|
2
|
Нет
неисправности
|
|
|
|
2
|
3
|
"мусор"
|
Неисправен
Линк 2-3
|
|
|
5
|
Нет
неисправности
|
|
Неисправен
Линк 2-3
|
|
1
|
"мусор"
|
|
|
|
2
|
"мусор"
|
|
|
|
3
|
3
|
Недостаточно
данных |
Неисправен
Линк 2-3
|
|
|
5
|
Нет
неисправности
|
|
|
|
1
|
2
или 3 2-1 или 2-3
|
|
|
|
2
|
Нет
неисправности
|
|
|
|
5
|
3
|
Недостаточно
данных
|
Неисправен
Линк 2-3
|
|
|
5
|
Нет
неисправности
|
|
|
Анализ
ПЭ1, ПЭ2 и ПЭ5 возможных
причин неисправности,
показывает:
Результаты
голосования
от ПЭ2 подтверждают
работоспособность
ПЭ1, ПЭ5, каналов
2-1 и 2-5.
Результаты
голосования
от ПЭ5 подтверждают
работоспособность
ПЭ3, ПЭ2, каналов
3-5 и 2-5.
Данные
ПЭ5 от ПЭ3 говорят
о исправности
канала связи
3-5.
Таким
образом ПЭ1,ПЭ2
и ПЭ5 делают
вывод о неисправности
канала 2-3, маскируя
неисправности
по данным от
ПЭ1.
Анализ
ПЭ3 возможных
причин неисправности,
показывает:
Результаты
голосования
от ПЭ5 подтверждают
работоспособность
ПЭ3, ПЭ2, каналов
3-5 и 2-5.
“Мусор”
от ПЭ1 может
означать, что
неисправен
ПЭ1 или ПЭ2, или
канал 1-2, или канал
2-3.
“Мусор”
от ПЭ2 может
означать
неисправность
ПЭ2 или канала
2-3.
Из
условия ординарности
потока отказов,
одновременная
неисправность
ПЭ1 и ПЭ2 невозможна,
как невозможно
и сочетание
1-2 и 2-3. Таким образом
из пунктов 2 и
3 следует отказ
либо ПЭ2, либо
канала 2-3. Пункт
1 опровергает
отказ ПЭ2. Делается
вывод об отказе
канала 2-3.
Конфигурация,
изображенная
на рис. 2.6 является
в какой-то мере
критичной,
поскольку
используется
транзитная
связь через
ПЭ2. Рассмотрим
отказ ПЭ2 в этой
же топологии.
При этом, интерфейс
обмена таков,
что ПЭ2 в случае
фатального
отказа не передаст
транзитную
информацию
(передаст «мусор»),
в противном
случае передаст
ее без изменений.
В
результате
обмена результатами
счета, в узлах
сети могут
фиксироваться
следующие факты
несовпадения,
представленные
в таблице 2.17.
Таблица
2.17
| № ПЭ |
Получены
данные от ПЭ
№ |
Данные
от
ПЭ
№
|
Не
совпадают с
данными от
ПЭ № |
Возможная
причина:
Неисправность
ПЭ
№ или Линк №
|
|
1
Вариант
1
|
3,5 |
3 |
1
, 5 |
2
или 3 2-1 или 2-3 |
|
1
Вариант
2
|
3,5 |
|
|
Нет
неисправности |
|
2
Вариант
1
|
1,5 |
|
|
«мусор» |
|
2
Вариант
2
|
1,5 |
2 |
1
, 5 |
2
1-2, 1-5 |
|
3
Вариант
1
|
1,2 |
|
Нет
совпадений |
Недостаточно
данных |
|
3
Вариант
2
|
1,2 |
2 |
1
, 3 |
2
2-3 |
|
5
|
2,3 |
2 |
3
, 5 |
2
2-5 |
После
обмена результатами
голосования
в зависимости
от степени
отказа ПЭ2, в
работоспособных
узлах может
оказаться
информация,
представленная
таблицей 2.18.
Таблица
2.18
|
ПЭ№
|
Данные
голосования
от ПЭ №
|
Возможная
причина неисправности
ПЭ № или Линк
№
|
Вывод
|
Консолидированное
решение
|
|
1
|
2
или 3 2-1 или 2-3
|
|
|
|
1
Вариант 1
|
2 |
"мусор"
|
|
|
|
3 |
"мусор"
|
|
|
|
5 |
2
2-5
|
|
|
|
1
|
Нет
неисправности
|
Неисправен
ПЭ2
|
|
|
1
Вариант 2
|
2
|
2
1-2, 2-5
|
|
|
|
3
|
2
2-3
|
|
|
|
5
|
2
2-5
|
|
|
|
1
|
"мусор"
|
|
|
|
3
Вариант 1
|
2 |
"мусор"
|
|
|
|
3 |
Недостаточно
данных
|
|
|
|
5 |
2
2-5
|
|
Неисправен
ПЭ2
|
|
1
|
Нет
неисправности
|
Неисправен
ПЭ2
|
|
|
3
Вариант 2
|
2
|
2
1-2, 2-5
|
|
|
|
3
|
2
2-3
|
|
|
|
5
|
2
2-5
|
|
|
|
1
|
2
или 3 2-1 или 2-3
|
|
|
|
5
Вариант 1
|
2 |
"мусор"
|
|
|
|
3 |
Недостаточно
данных
|
|
|
|
5 |
2
2-5
|
|
|
|
1
|
Нет
неисправности
|
|
|
|
5
Вариант 2
|
2
|
2
1-2, 2-5
|
Неисправен
ПЭ2
|
|
|
3
|
2
2-3
|
|
|
|
5
|
2
2-5
|
|
|
Рассмотрим
процесс принятия
решения ПЭ1:
Вариант
1:
«Мусор» от ПЭ3
и данные ПЭ2
говорят о
неисправности
ПЭ2 или линка
2-1. Диагноз ПЭ5
подтверждает
неисправность
ПЭ2. Таким образом
каждая запись
в ПЭ1 прямо или
косвенно говорит
о неисправности
ПЭ2 или его связей.
В силу ординарности
потока отказов
принимается
решение об
отказе ПЭ2.
Вариант
2:
Один противоречивый
результат
маскируется
тремя подтверждениями
неисправности
ПЭ2, так как
одновременный
отказ всех
линков трактутся
также как и
отказ всего
ПЭ2.
Аналогично
в ПЭ3 и ПЭ5 в любом
случае оказывается
минимум два
сообщения об
отказе ПЭ2 или
его связей. Как
было отмечено
выше вероятность
отказа одновременно
нескольких
каналов связи
существенно
меньше вероятности
отказа ПЭ, и
вследствие
предположения
об ординарности
потока отказов,
делается вывод
об отказе ПЭ2.
Рассмотрим
деградацию
системы после
отказа линка
2-3. Топология
системы представлена
на рис. 2.7.

Рис.
2.7. Топология
ВС после отказа
линка 2-3.
Маршрутизатором
были определены
новые статические
маршруты, для
связи ПЭ1 и ПЭ3
и ПЭ2 через ПЭ5.
В данном случае
отказ ПЭ3 или
линка 3-5 обнаруживается
легко с помощью
ПЭ5. Аналогично
обнаруживаются
отказы ПЭ1 и
ПЭ2.
Рассмотрим
отказ ПЭ5. В
результате
обмена результатами
счета, в узлах
сети могут
фиксироваться
следующие факты
несовпадения,
представленные
в таблице 2.19.
Таблица
2.19
| № ПЭ |
Получены
данные от ПЭ
№ |
Данные
от
ПЭ
№
|
Не
совпадают с
данными от
ПЭ № |
Возможная
причина:
Неисправность
ПЭ
№ или Линк №
|
|
1
Вариант
1
|
3,5 |
5 |
1
, 3 |
5
1-5 |
|
1
Вариант
2
|
3,5 |
|
Нет
совпадений |
Недостаточно
данных |
|
2
|
1,5 |
5 |
1
, 2 |
5
2-5 |
|
3
Вариант
1
|
1,2 |
|
|
Нет
неисправности
|
|
3
Вариант
2
|
1,2 |
|
Нет
совпадений |
Недостаточно
данных |
|
5
Вариант
1
|
2,3 |
5 |
2
, 3
|
5
1-5, 3-5 |
|
5
Вариант
2
|
2,3 |
|
|
“мусор” |
После
обмена результатами
голосования
в зависимости
от степени
отказа ПЭ5, в
работоспособных
узлах может
оказаться
информация,
представленная
таблицей 2.20.
Таблица
2.20
|
ПЭ№
|
Данные
голосования
от ПЭ №
|
Возможная
причина неисправности
ПЭ № или Линк
№
|
Вывод
|
Консолидированное
решение
|
|
1
|
Недостаточно
данных
|
|
|
|
1
Вариант 1
|
2 |
5
2-5 |
|
|
|
3 |
"мусор"
|
|
|
|
5 |
"мусор"
|
|
|
|
1
|
5
1-5 |
Неисправен
ПЭ5
|
|
|
1
Вариант 2
|
2
|
5
2-5 |
|
|
|
3
|
Нет
неисправности
|
|
|
|
5
|
5
1-5, 3-5 |
|
|
|
1
|
Недостаточно
данных |
|
|
|
2
Вариант 1
|
2 |
5
2-5 |
|
|
|
3 |
"мусор"
|
|
|
|
5 |
"мусор"
|
|
Неисправен
ПЭ5
|
|
1
|
5
1-5 |
Неисправен
ПЭ5
|
|
|
2
Вариант 2
|
2
|
5
2-5 |
|
|
|
3
|
Нет
неисправности
|
|
|
|
5
|
5
1-5, 3-5 |
|
|
|
1
|
"мусор"
|
|
|
|
3
Вариант 1
|
2 |
"мусор"
|
Недостаточно
|
|
|
3 |
Недостаточно
данных
|
данных
|
|
|
5 |
"мусор"
|
|
|
|
1
|
5
1-5 |
|
|
|
3
Вариант 2
|
2
|
5
2-5 |
Неисправен
ПЭ5
|
|
|
3
|
Нет
неисправности
|
|
|
|
5
|
5
1-5, 3-5 |
|
|
Анализ
работоспособными
узлами причин
отказа показывает:
При
полном отказе
ПЭ5:
Анализ
ПЭ1 и ПЭ2: “мусор”
от ПЭ3 и ПЭ5 говорит
о неисправности
ПЭ5 или канала
1-5, а данные ПЭ2
однозначно
говорят об
отказе ПЭ5.
Анализ
ПЭ3: “мусор”
от ПЭ2, ПЭ3 и ПЭ5
говорит о
неисправности
ПЭ5 или канала
3-5. В данном случае
это уже не важно,
так как результатами
голосования
ПЭ3 обменяться
ни с кем не сможет.
В случае возникновения
такой ситуации
ПЭ анализирует
– сколько узлов
остается в
системе, кроме
него самого.
Если больше
двух, то он
самостоятельно
прекращает
выдачу данных.
При
отказе ПЭ5, с
сохранением
способности
обмена, информации
для его диагностирования
хватает с избытком.
После
обмена окончательными
выводами ПЭ1
и ПЭ2 принимают
решение об
отключении
ПЭ5. После реконфигурации,
маршрутизатор
обнаруживает
изолированность
ПЭ3 и посылает
сигнал реконфигуратору
об отключении
ПЭ3.
Рассмотрим
теперь функционирование
ВС в составе
трех ПЭ. Пусть
остались
функционировать
ПЭ1, ПЭ2 и ПЭ5.

Рассмотрим
отказ связи
2-5. В результате
в узлах сети
фиксируются
следующие факты
несовпадения
результатов
счета, представленные
в таблице 2.21.
Таблица
2.21
| № ПЭ |
Получены
данные от ПЭ
№ |
Данные
от
ПЭ
№
|
Не
совпадают с
данными от
ПЭ № |
Возможная
причина:
Неисправность
ПЭ
№ или Линк №
|
|
1
|
2,5 |
|
|
Нет
неисправности |
|
2
|
1,5 |
5 |
1
, 2 |
5
2-5
|
|
5
|
1,2 |
2 |
1
, 5 |
2
2-5 |
После
обмена результатами
голосования,
в узлах может
оказаться
информация,
представленная
таблицей 2.22.
Таблица
2.22
|
ПЭ№
|
Данные
голосования
от ПЭ №
|
Возможная
причина неисправности
ПЭ № или Линк
№
|
Вывод
|
Консолидированное
решение
|
|
1
|
Нет
неисправности |
|
|
|
1
|
2 |
5
2-5 |
Неисправен
2-5
|
|
|
5 |
2
2-5 |
|
|
|
1
|
Нет
неисправности |
|
|
|
2
|
2
|
5
2-5
|
Неисправен
2-5
|
Неисправен
2-5
|
|
5
|
"мусор"
|
|
|
|
1
|
Нет
неисправности |
|
|
|
5
|
2 |
"мусор"
|
Неисправен
2-5
|
|
|
5 |
2
2-5 |
|
|
Анализ
ПЭ1 предварительной
информации
подтверждает
отказ линка
2-5, так как исправность
ПЭ2 и ПЭ5 подтверждается
информацией
от ПЭ1.
Анализ
ПЭ2 и ПЭ3 поступившей
информации
говорит о
неисправности
линка 2-5, в силу
того, что ПЭ1
подтверждает
правильность
результатов
ПЭ2 и ПЭ5.
Рассмотрим
дальнейшее
функционирование
системы (рис.
2.9).
Отказ
ПЭ5 и ПЭ2 диагностируется
также, как было
показано выше,
так как не нарушается
связность между
двумя ПЭ. Отказ
связи 1-5 воспринимается
ПЭ1 и ПЭ2, как отказ
ПЭ5. Аналогично,
отказ связи
1-2 равносилен
отказу ПЭ2.
В
процессе
функционирования
в системе всегда
существует
старший ПЭ,
который выдает
объекту управления
согласованные
данные. Если
после принятия
консолидированного
решения, обнаруживается
сбой в старшем
элементе, то
старшим назначается
другой ПЭ, имеющий
максимальное
количество
связей или
младший номер,
если количество
связей у всех
ПЭ одинаково.
В предыдущум
примере (при
изоляции ПЭ3)
этот прием
позволяет
прекратить
выдачу данных
с изолированного
ПЭ.
В
данном варианте
может возникнуть
ситуация, когда
ПЭ2 при отказе
линка 1-2 принимает
решение об
отказе ПЭ1 и
становится
старшим элементом,
как ПЭ с младшим
номером. При
этом он принимает
решение об
отключении
ПЭ5. Одновременно
ПЭ1 и ПЭ5 принимают
решение об
отказе ПЭ2 и в
свою очередь
исключают его
из текущей
конфигурации.
Тогда наступает
ситуация, когда
одновременно
на выход подаются
два, возможно
и разных варианта.
Чтобы избежать
такой ситуации,
необходимы
спецальные
аппаратные
или программно-аппаратные
средства, которые
в рамках данной
работы не
рассматриваются.
Если
сделать предположение
о равновероятности
отказов в системе,
изображенной
на рис.2.9, то вероятность
отказа линка
2-1, приводящая
к неопределенности
в системе, равна
0.2. Однако в реальных
ВС вероятность
отказа канала
связи считается
величиной на
порядок меньшей,
чем вероятность
отказа ПЭ за
этот же период
времени.
Отказ
канала 1-5 не
приведет к
неопределенности.
ПЭ5 не станет
старшим в любом
случае и будет
отключен. Отказ
ПЭ1 также не
приведет к
неопределенности,
управление
возьмет на себя
ПЭ2.
На
предпоследнем
этапе деградации
системы в системе
остается 2 исправных
ПЭ, соединенных
одним каналом
связи. При на
первый план
в качестве
диагностической
информации
выходят признаки
исправности/неисправности,
формируемые
различными
программно-аппаратными
средствами
контроля, такими
как функциональный
контроль вычислений
с помощью специальных
контрольных
операторов,
контроль входной
информации
по специальным
признакам и
контрольным
суммам, контроль
выходной информации
по квитанции
от приемника
и тд.
Следует
отметить, что
«жесткое»
использование
признаков
неисправности,
вырабатываемых
контрольными
тестами аппаратуры,
может привести
к появлению
ошибок второго
рода («ложная
тревога») и
исключению
из вычислительного
процесса
функционально-пригодной
аппаратуры.
Это приводит
к необходимое
применения
гибких моделей
совместного
использования
результатов
голосования
и признаков
контрольных
средств.
2.5.2.
Методика анализа
отказов
Исходя
из этого примера,
помимо модуля
голосования
систему необходимо
дополнить
гибким механизмом
анализа отказов.
Подсистема
анализа отказов
должна инициироваться
модулем коммуникации,
по завершению
обмена результатами
голосования,
и оперировать
следующей
информацией:
Результатами
голосования
(предварительными
выводами по
результатам
сравнения)
функциональной
информации;
Сигналами
модуля коммуникации
о неверной
контрольной
сумме пакета,
о тайм-ауте
при приеме
пакета, об
отсутствии
или неверном
коде квитанции.
Логика
выводов при
анализе данных
голосования
и информации
от модуля
коммуникации
такова:
Несовпадение
данных при
элементарной
проверке результатов
счета на очередном
цикле диагностируется,
как отказ ПЭ
или канала
связи этого
ПЭ, при этом
голосование
проводится
каждым ПЭ (с
номером m)
по результатам
от ПЭ с номерами
(m-1)
mod N
и (m-2)
mod N.
При
несовпадении
данных при
элементарной
проверке результатов
счета, полученных
с использованием
транзитной
передачи, под
сомнение ставится
вся цепочка,
задействованная
при передаче.
При
несовпадении
ни одного результата
счета под сомнение
ставится все
участвовавшие
в обмене ПЭ и
связи.
Несовпадение
контрольной
суммы или тайм-аут
при приеме
данных трактуется
как сбой ПЭ
или канала
связи ПЭ.
Отсутствие
квитанции
трактуется
как сбой ПЭ
или канала
связи ПЭ.
Неверный
код квитанции
трактуется
как сбой канала
связи ПЭ.
Для
принятия решения
об отказе (сбое)
того или иного
элемента ВС
(ПЭ, канала связи)
по набору выводов
от каждого узла
сети, был предложен
следующий
эвристический
алгоритм, при
выполнении
условия об
ординарности
потока отказов:
Создается
матрица состояния
ВС, которая
размерностью
идентична
модифицированной
матрице связности
ПЭ, но по главной
диагонали
находятся
данные о ПЭ, а
в ячейках матрицы
– о каналах
связи.
Матрица
состояния ВС
инициализируется
единицами.
После
обмена предварительными
результатами
голосования,
у каждого ПЭ
оказывается
результаты
голосования
от всех ПЭ ВС
и диагностическая
информация
от модуля
коммуникации.
Последовательно,
в соответствии
с логикой,
изложенной
выше, делается
вывод по каждой
записи, и очередное
предположение
заносится в
матрицу состояния
ВС путем вычитания
единицы из
ячейки, соответствующей
элементу ВС,
не в пользу
которого делается
это предположение.
Если
выводом по
очередной
записи становится
отсутствие
отказов по
определенным
элементам, то
это предположение
заносится в
матрицу состояния
ВС путем инкрементирования
ячейки, соответствующей
элементу ВС,
в пользу которого
делается это
предположение.
После
обработки всех
записей, матрица
состояний ВС
просматривается
на предмет
поиска минимального
отрицательного
значения.
Если
такое значение
есть, то соответствующий
элемент признается
отказавшим,
иначе принимается
решение об
отсутствии
оказов.
Данный
алгоритм создан
так, что в матрице
состояний после
его завершения,
не окажется
больше двух
минимальных
отрицательных
значений, причем
эти значения
не будут принадлежать
одинаковым
функциональным
элементам (то
есть одновременно
2-м ПЭ или 2-м каналам
связи). В случае
присутствия
одинаковых
минимальных
значений, делается
выбор в пользу
отказа канала
связи.
Проиллюстрируем
его на примере
ВС, изображенной
на рис. 2.7, и отказа
ПЭ5 в этой конфигурации.
Обмен для голосования
в сети осуществляется
следующим
образом:
ПЭ1->ПЭ2,
ПЭ3;
ПЭ2->ПЭ3,
ПЭ5;
ПЭ3->ПЭ5,
ПЭ1;
ПЭ5->ПЭ1,
ПЭ2.
Обмен
результатами
голосования
для принятия
консолидированного
решения – по
всей ВС. Приведем
логику анализа
неисправности
с точки зрения
выбранной
эвристики.
Вариант
1:
ПЭ5
продолжает
функционирование,
обмен и голосование,
но функциональная
задача выполняется
неверно. Таким
образом, сигналов
о неисправности
от модулей
коммуникации
ПЭ сети поступать
не будет.
В
таблице 2.23 представлены
записи от всех
ПЭ, расшифрованные
в соответствии
с выбранной
логикой.
Таблица
2.23
|
ПЭ№
|
Данные
голосования
от ПЭ №
|
Информация
от модуля
коммуникации
|
Возможная
причина неисправности
ПЭ № или Линк
№
|
Вывод
|
|
1
|
Нет |
5
1-5 |
|
|
1
|
2
|
Нет |
5
2-5 |
Неисправен
ПЭ5
|
|
3
|
Нет |
Нет
неисправности
|
|
|
5
|
Нет |
5
1-5, 3-5 |
|
|
1
|
Нет |
5
1-5 |
|
|
2
|
2
|
Нет |
5
2-5
|
Неисправен
ПЭ5
|
|
3
|
Нет |
Нет
неисправности
|
|
|
5
|
Нет |
5
1-5, 3-5 |
|
|
1
|
Нет |
5
1-5 |
|
|
3
|
2
|
Нет |
5
2-5 |
Неисправен
ПЭ5
|
|
3
|
Нет
|
Нет
неисправности
|
|
|
5
|
Нет |
5
1-5, 3-5 |
|
Составим
матрицу состояния
ВС, получившуюся
у ПЭ1 (см. таблицу
2.24).
Таблица
2.24
|
№/№
|
1
|
2
|
3
|
5
|
|
1
|
2
|
1
|
2
|
-1
|
|
2
|
1
|
2
|
2
|
0
|
|
3
|
2
|
2
|
2
|
0
|
|
5
|
-1
|
0
|
0
|
-2
|
Таким
образом, делается
вывод о неисправности
ПЭ5. Аналогичный
вывод, судя по
таблице 1, делают
и ПЭ1 и ПЭ2.
Вариант
2:
Наступил фатальный
отказ ПЭ5, при
котором он
прекращает
обмен с ВС, либо
выдает неинформативные
данные.
Таблица
2.25 содержит
расшифровку
записей всех
ПЭ в этом случае.
Таблица
2.25
|
ПЭ№
|
Данные
голосования
от ПЭ №
|
Информация
от модуля
коммуникации
|
Возможная
причина неисправности
ПЭ № или Линк
№
|
Вывод
|
|
1
|
Нет |
1
или 3 или 5 3-5 или
1-5
|
|
|
1
|
2
|
Нет |
5
2-5 |
Неисправен
ПЭ5
|
|
3
|
Тайм-аут
или КС |
3 или
5 3-5 или 1-5 |
|
|
5
|
Тайм-аут
или КС |
5
1-5
|
|
|
1
|
Нет |
1
или 3 или 5 3-5 или
1-5
|
|
|
2
|
2
|
Нет |
5
2-5 |
Неисправен
ПЭ5
|
|
3
|
Тайм-аут
или КС |
3 или
5 3-5 или 2-5 |
|
|
5
|
Тайм-аут
или КС |
5
2-5 |
|
|
1
|
Тайм-аут
или КС |
1 или
5 3-5 или 1-5 |
|
|
3
|
2
|
Тайм-аут
или КС |
2 или
5 3-5 или 2-5 |
Неисправен
3-5
|
|
3
|
Нет
|
1 или
2 или 3 или 5 3-5 или
1-5 или 2-5 |
|
|
5
|
Тайм-аут
или КС |
5
3-5 |
|
Таким
образом :
В
ПЭ1 оказывается
4 голоса против
ПЭ5 и 3 голоса
против канала
связи 1-5. Решение
– отказ ПЭ5.
В
ПЭ2 оказывается
4 голоса против
ПЭ5 и 3 голоса
против канала
связи 2-5. Решение
– отказ ПЭ5.
В
ПЭ3 оказывается
4 голоса против
ПЭ5 и 4 голоса
против канала
связи 3-5. Решение
– отказ канала
связи 3-5.
Ситуация,
аналогичная
наступившей
в ПЭ3, возникает,
когда у ПЭ остается
лишь один канал
связи. После
его утраты ПЭ
становится
изолированным
и отключается.
2.6.
Оценка надежностных
характеристик
отказоустойчивой
ВС
Выбранная
концепция
построения
специализированной
распределенной
операционной
системы реального
времени позволит
однородной
системе функционировать
при возникновении
N
-1 отказа ПЭ в
системе.
Если
не учитывать
вероятность
отключения
работоспособных
процессорных
модулей, то
можно провести
оптимистическую
оценку вероятности
отказа всей
системы за
определенный
период функционирования
и среднего
времени наработки
на отказ системы.
Будем
предполагать,
что поток отказов
в каждом узле
системы является
простейшим,
т.е. стационарным,
ординарным
и без последствия,
с показательным
законом распределения
длины интервала
между соседними
событиями
(отказами):
 (1)
(1)
где:
 - вероятность
того, что за
время t произойдет
ровно “K” событий
(отказов);
- вероятность
того, что за
время t произойдет
ровно “K” событий
(отказов);
l
- параметр потока,
интенсивность
потока отказов;
T0
– математическое
ожидание длины
интервала между
соседними
событиями –
среднее время
наработки на
отказ;
P0(t)
– вероятность
того, что за
время t не произойдет
ни одного события
(отказа), вероятность
безотказной
работы.
Обозначим
через
 –
среднее время
наработки на
отказ одного
узла системы.
Для отказоустойчивых
систем под
состоянием
отказа будем
понимать состояние
фатального
отказа, т.е. для
ОС-N(m), это состояние,
при котором
произошел отказ
более чем “m”
узлов системы
(m+1, m+2, …). –
среднее время
наработки на
отказ одного
узла системы.
Для отказоустойчивых
систем под
состоянием
отказа будем
понимать состояние
фатального
отказа, т.е. для
ОС-N(m), это состояние,
при котором
произошел отказ
более чем “m”
узлов системы
(m+1, m+2, …).
В
произвольный
момент времени
t мы можем застать
систему в одном
из двух состояний:
работоспособном,
с вероятностью
R(t),
в
состоянии
фатального
отказа, с вероятностью
P(t).
Если
взглянуть на
систему с учетом
состояний
работоспособности
каждого из N ее
элементов
(узлов), то в
произвольный
момент времени
t мы можем застать
систему в одном
из 2N
состояний (см.
рис. 2.10).

Рис
2.10. Состояния
N-узловой системы
Если
поставить в
соответствие
каждому узлу
системы разряд
двоичного N
разрядного
числа (0 – узел
работает, 1 –
узел отказал),
то каждому
такому состоянию
системы можно
поставить в
соответствие
свой номер,
равный значению
введенного
двоичного N
разрядного
числа и каждому
такому состоянию
соответствует
некоторая
вероятность
нахождения
системы в момент
времени t в этом
состоянии.
Все
2N
состояний
системы можно
разбить на
несколько групп
состояний,
каждое из которых
отличается
от других количеством
отказавших
узлов. Нулевая
группа (группа
с номером 0) содержит
одно состояние
(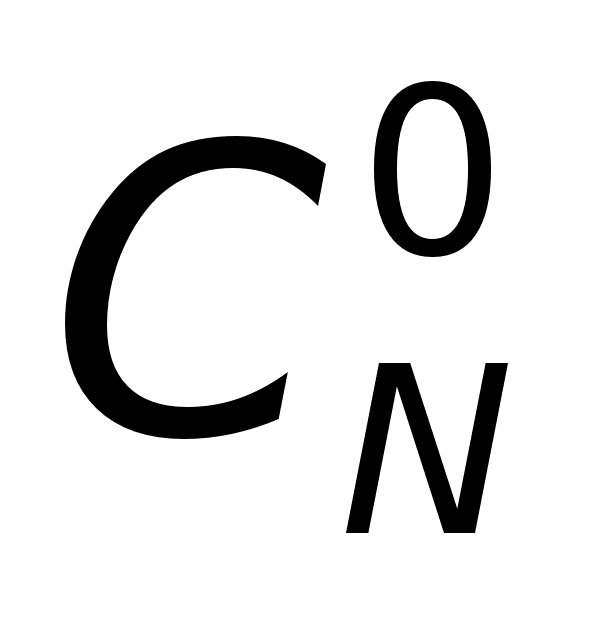 =
1), в котором все
узлы системы
находятся в
состоянии
работоспособности,
т.е. имеется
ровно 0 отказавших
элементов.
Первая группа
включает в себя
все состояния,
в которых отказал
ровно один узел
(двоичные номера
этих состояний
содержат лишь
одну единицу
в N разрядном
двоичном коде).
Количество
состояний,
входящих в
первую группу
равно =
1), в котором все
узлы системы
находятся в
состоянии
работоспособности,
т.е. имеется
ровно 0 отказавших
элементов.
Первая группа
включает в себя
все состояния,
в которых отказал
ровно один узел
(двоичные номера
этих состояний
содержат лишь
одну единицу
в N разрядном
двоичном коде).
Количество
состояний,
входящих в
первую группу
равно
 =N
– числу сочетаний
из N по 1 ( =N
– числу сочетаний
из N по 1 ( ). ).
Вторую
группу составляют
состояния, в
которых в системе
имеется два
отказавших
элемента, таких
состояний ровно
 и т.д.
и т.д.
В
i-ю группу включаются
все состояния,
в которых в
системе отказало
ровно i узлов,
таких состояний
 . .
Предпоследняя
(N-1) –я группа
включает в себя
 состояний,
т.е. N состояний. состояний,
т.е. N состояний.
Последняя
N-я группа содержит
одно состояние
( =1),
в котором отказали
все N узлов системы. =1),
в котором отказали
все N узлов системы.
Т.к.
в произвольный
момент времени
система может
находится
только в одном
из всех 2N
состояний, то
эти события
являются
несовместными.
Поэтому вероятность
нахождения
системы в любом
из состояний,
относящихся
к одной из упомянутых
выше групп
можно получить
как сумму
вероятностей
нахождения
системы во всех
состояниях
данной группы.
А если учесть,
что внутри
каждой i-й группы
все состояния
характеризуются
наличием ровно
i отказавших
узлов, то вероятности
для всех состояний
одной группы
равны между
собой, поэтому:
 (2)
(2)
где:
Pi
– вероятность
нахождения
системы (в
произвольный
момент времени
t) в любом из
состояний,
отнесенных
к i-й группе;
 -
вероятность
нахождения
системы в одном
конкретном
состоянии,
отнесенном
к i-й группе. -
вероятность
нахождения
системы в одном
конкретном
состоянии,
отнесенном
к i-й группе.
Все
состояния,
отнесенные
к i-й группе
характеризуются
наличием в
системе (в
произвольный
момент времени
t) ровно i отказавших
узлов и ровно
(N-i)
исправных
узлов.
В
соответствии
с введенным
выше предположением
о простейшем
потоке отказов
(1) вероятность
можно
оценить следующим
образом:
 (3)
(3)
где
первая скобка
соответствует
тому, что (N-i) элементов
находятся в
работоспособном
состоянии, а
вторая тому,
что i элементов
отказали. Подставляя
(3) в (2) можно получить
выражение для
вычисления
вероятностей
Pi.
Очевидно,
что для системы
ОС-N(m) (N узловой
системы с рангом
отказоустойчивости
m) все состояния
системы, входящие
в группы 0,1,2,…m
относятся к
тем состояниям,
в которых система
нормально
функционирует.
В этой связи
вероятность
R(t) можно оценить
следующим
образом:
 (4)
(4)
Вероятность
фатального
отказа системы
ОС – N(m) можно
оценить как
сумму вероятностей
нахождения
системы в состояниях,
отнесенных
к группам m+1, m+2, …
N-1, N:
 (5)
(5)
Критерием
правильности
предложенной
методики является
выполнение
условия R(t)+P(t)=1 для
любых систем
и любых значений
t.
Объединяя
выражения (2)
(3) (4) и (5), получим
окончательные
формулы для
вычисления
вероятностей
безотказной
работы – RN(m)(t)
и фатального
отказа –PN(m)(t)
систем ОС-N(m) для
произвольного
момента времени
t:
 (6)
(6)
Для
практических
расчетов
целесообразно
использовать
одну из этих
формул, а именно
ту, у которой
(в зависимости
от значений
N и m) меньше суммируемых
членов, т.е. при
 целесообразно
использовать
формулу PN(m)(t)
в противном
случае – формулу
RN(m)(t).
При этом второй
параметр получается
из соотношения
RN(m)(t)+PN(m)(t)=1.
целесообразно
использовать
формулу PN(m)(t)
в противном
случае – формулу
RN(m)(t).
При этом второй
параметр получается
из соотношения
RN(m)(t)+PN(m)(t)=1.
Таким
образом для
систем типа
N(N-1)
выражения (6)
принимают вид:
 (6а) (6а)
Рассмотрим
теперь определение
среднего времени
наработки на
отказ T0N(m)
отказоустойчивых
систем ОС-N(m).
Невосстанавливаемая
N-узловая отказоустойчивая
система m-го
ранга (ОС-N(m)) может
быть представлена
марковской
моделью с количеством
состояний
(N+1):

где:
0 – состояние,
в котором ни
один узел системы
не отказал;
1
– состояние
(объединяющее
группу из
 состояний
системы – см.
рис. 2.4), в котором
отказал ровно
1 узел;
состояний
системы – см.
рис. 2.4), в котором
отказал ровно
1 узел;
2
– состояние
(объединяющее
группу из
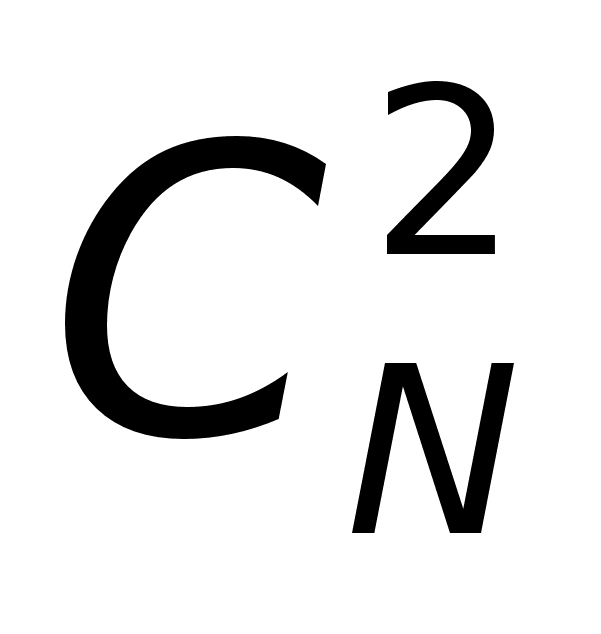 состояний
системы), в котором
отказали ровно
2 узла;
состояний
системы), в котором
отказали ровно
2 узла;
m
– состояние
(объединяющее
группу из
 состояний
системы), в котором
отказало ровно
m узлов и т.д.
состояний
системы), в котором
отказало ровно
m узлов и т.д.
Переход
из одного состояния
в другое (по
мере постепенной
деградации
системы) определяется
интенсивностью
потока отказов,
воздействующих
на систему,
находящуюся
в соответствующем
состоянии.
Интенсивность
потока отказов,
воздействующих
на систему,
находящуюся
в i-м состоянии,
определяется
количеством
работоспособных
узлов (N-i). Т.о. среднее
время нахождения
системы в i-м
состоянии
определяется
следующим
образом:
 (7)
(7)
где:
 -
интенсивность
потока отказов
одного узла
системы. -
интенсивность
потока отказов
одного узла
системы.
Фатальный
отказ системы
ОС-N(m) произойдет
только при
переходе системы
из состояния
m в состояние
m+1, поэтому среднее
время наработки
системы ОС-N(m)
на отказ равно
среднему времени
последовательного
нахождения
системы в состояниях
0,1,2….m:
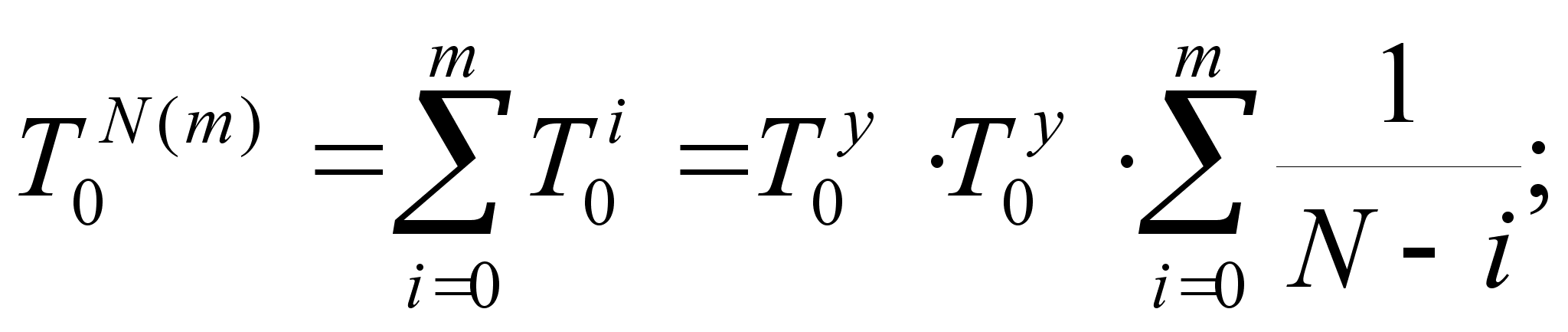 (8)
(8)
Выражение
(8) получено на
основании
одного фундаментального
свойства
показательного
закона распределения:
«если промежуток
времени, распределенный
по показательному
закону, уже
длился некоторое
время t, то это
никак не влияет
на закон распределения
оставшейся
части промежутка:
он будет таким
же, как и закон
распределения
всего промежутка»[12].
Это свойство
показательного
закона представляет
собой, по существу,
одну из формулировок
для «отсутствия
последействия»,
которое является
основным свойством
простейшего
потока, принятого
нами в качестве
модели потока
отказов.
Если
ввести обозначение:
 (8а)
(8а)
то
этот «коэффициент
надежности»
в соответствии
с (8) представляет
собой отношение
T0N(m)
к T0y:
 , ,
и
показывает,
во сколько раз
по сравнению
с T0y
– средним временем
наработки на
отказ одного
узла, изменилось
среднее время
наработки на
отказ системы
ОС-N(m) в целом.
Используя
формулы (6а) и
(8а) можно производить
оценку надежностных
характеристик
отказоустойчивых
систем типа
N(N-1).
Примем среднее
время наработки
на отказ узла
=105
часов. В таблице
2.26
приведены
характеристики,
рассчитанные
по формулам
(6а) и (8а).
Таблица
2.26
Харктиристики
отказоустойчивых
систем типа
N(N-1)
|
№№ п/п
|
N(N-1)
– тип системы
/ Характеристика
|
1(0)
|
3(2)
|
4(3)
|
5(4)
|
6(5)
|
7(6)
|
8(7)
|
9(8)
|
10(9)
|
|
 1 1
|
|
4
часа
|
4∙10-5
|
6,4∙10-14
|
2,56∙10-18
|
1,0∙10-22
|
4,1∙10-27
|
1,6∙10-31
|
6,5∙10-36
|
2,62∙10-40
|
1,05∙10-44
|
|
2
|
24
часа
|
2.4∙10-4
|
1,38∙10-11
|
3,31∙10-15
|
8,0∙10-19
|
1,9∙10-22
|
4,6∙10-26
|
1,1∙10-29
|
2,64∙10-33
|
6,3∙10-37
|
|
3
|
1год=
|
0.084
|
5,91∙10-4
|
4,96∙10-5
|
4,2∙10-6
|
3,5∙10-7
|
2,9∙10-8
|
2,46∙10-9
|
2∙10-10
|
1,7∙10-11
|
|
8766
час
|
|
|
4
|
5лет=
|
0.355
|
0,047
|
1,586∙10-2
|
5,6∙10-3
|
2∙10-3
|
7,1∙10-4
|
2,5∙10-4
|
8,9∙10-5
|
3,16∙10-5
|
|
43830
час
|
|
|
5
|
10лет=
|
0.584
|
0,2
|
0,116
|
0,068
|
0,04
|
0,023
|
0,0135
|
7,9∙10-3
|
4,6∙10-3
|
|
87660час
|
|
|
6
|
11,4г.=
|
0.632
|
0,252
|
0,16
|
0,1
|
0,064
|
0,04
|
0,025
|
0,016
|
0,01
|
|
105час
|
|
|
7
|
15лет=
|
0.73
|
0,391
|
0,286
|
0,21
|
0,153
|
0,11
|
0,082
|
0,06
|
0,044
|
|
131490час
|
|
|
8
|
KN(N-1)
|
1
|
1,83
|
2,08
|
2,28
|
2,45
|
2,59
|
2,72
|
2,82
|
2,92
|
Для
упрощения
анализа таблицы
построим два
графика, отражающих
увеличение
надежности
системы с
наращиванием
аппаратной
части (рис. 2.10 и
рис. 2.11).

Рис.
2.10. Коэффициент
надежности.

Рис
2.11. Вероятность
отказа ВС типа
N(N-1)
за 10 лет.
Анализ
кривых показывает,
что среднее
время безотказной
работы увеличивается
в 2-3 раза по сравнению
со средним
временем безотказной
работы одного
ПЭ при наращивании
вычислительных
ресурсов в 5-7
раз и далее
стабилизируется
и возрастает
незначительно.
Вероятность
отказа систем
с рангом отказоустойчивости
N(N-1)
резко уменьшается
при рассмотрении
ВС типа 5(4) – 7(6) и
далее ее снижение
незначительно.
Таким
образом, при
построении
отказоустойчивых
вычислительных
систем рекомендуется
выбирать системы
с характеристиками
5(4) – 7(6), с учетом
ограничения
массы, энергопотребления
и др. характеристик.
2.7.
Выводы к главе
2
Подводя
итог, стоит еще
раз отметить,
что надежность
ВС в процессе
эксплуатации
складывается
из надежности
аппаратной
и программной
компонент
системы. В связи
с этим были
рассмотрены
виды и причины
отказов при
работе ВС, причем
особое внимание
уделялось
возникновению
ошибок вследствие
неисправностей
аппаратных
компонент
системы, так
как ошибки
программного
обеспечения
означают, что
они не были
выявлены на
этапе тестирования.
Для
обеспечения
надежного
решения задач
в условиях
отказов применяются
два подхода
– восстановление
и предотвращение
отказа системы
(отказоустойчивость).
При создании
специализированной
ОСРВ, предпочтение
отдано второму
подходу, поскольку
восстановление
в ряде случаев
может быть
связано со
значительными
затратами
процессорного
времени и (или)
прерыванием
вычислительного
процесса. В
связи с этим
рассмотрены
механизмы
обеспечения
отказоустойчивости,
основными из
которых являются
протоколы
голосования
и принятия
коллективного
решения.
Введено
понятие ранга
отказоустойчивости,
описана структура
ОСРВ и концепция
работы системы
с рангом отказоустойчивости
N(N-1).
Дано описание
системных
таблиц, структуры
и взаимодействия
модулей ОСРВ
таких как
маршрутиатор,
реконфигуратор,
модуль коммункации,
голосования
и анализа отказов.
Рассмотрен
пример организации
отказоустойчивых
вычислений
на примере
пятиузловой
полносвязной
ВС в условиях
постоянной
деградации,
приведена
логика анализа
отказа в условиях
ординарного
потока отказов.
В
заключении
произведена
оценка надежностных
характеристик
ВС с рангом
отказоустйчивости
N(N-1)
и рассчитаны
характеристики
систем 1(0) – 10(9). Анализ
характеристик
выявил значительне
увеличение
времени безотказной
работы системы
с увеличением
числа ПЭ и уменьшение
вероятности
отказа всей
системы. Например,
вроятность
отказа системы
5(4) за 10 лет с временем
безотказной
работы одного
ПЭ 10000 часов составила
0,068, что меньше
вероятности
отказа одного
ПЭ за тот же
период в 8,5 раз.
Исходя из этих
результатов
были сделаны
рекомендации
по выбору типа
ВС при ее проектировании.
3.
Программное
обеспечение
модели отказоустойчивой
ВС
Основными
задачами при
разработке
программной
модели отказоустойчивой
ВС, функционирующей
под управлением
распределенной
ОСРВ, стали
следующие:
Реализовать
аппаратно-независимые
модули обеспечения
отказоустойчивости
ОСРВ.
Моделировать
ВС любой топологии
(3-10 ПЭ).
Возможность
обеспечить
логику проверки
модулей ОСРВ
с помощью команд
оператора.
Обеспечить
работу модели
в условиях
«мягкого»
реального
времени.
Таким
образом, программное
обеспечение
было разбито
на две части:
ПО
узла ВС Proc.
ПО
подсистемы
проверки Host.
3.1 Программное
обеспечение
модели узла
ВС
Структура
программного
обеспечения
модели узла
ВС представлена
на рис 3.1. В общем
виде функционирование
ПО узла ВС
осуществляется
по графу управления
(циклограмме),
представленной
на рис. 6.3 технологической
части, а логика
работы подробно
описана в главе
2.
Для
реализации
модели была
выбрана ОС
Windows
98/2000, так как на
данном этапе
не ставилась
задача тестирования
ПО ВС в условиях
жесткого реального
времени, а
семантически
механизмы
обеспечения
многопроцессности,
синхронизации,
ввода-вывода
практически
идентичны
механизмам
большинства
ОСРВ.

Рис.
3.1. Взаимодействие
модулей узла
ВС
ПО
узла ВС разбито
на модули, структура
которых представлена
в таблице 3.1.
Описание функций,
реализующих
данные модули,
представлено
в таблицах 3.2,
3.3, 3.4, 3.5.
Таблица
3.1
Описание
составляющих
модулей текстового
редактора
|
Модуль
|
Описание
|
|
Main.cpp
|
Центральный
модуль. Запуск
инициализации
системы. Запуск
маршрутизатора.
Запуск модуля
эмуляции каналов
связи. Запуск
ФЗ.
|
|
Router.cpp
|
Функции
маршрутизатора
|
|
Commun.cpp
|
Функции
модуля коммуникации
|
|
Vote.cpp
|
Функции
голосования
и анализатора
отказов.
|
|
task.cpp
|
Функциональная
задача.
|
Таблица
3.2
Функции,
реализующие
маршрутизатор
Имя
|
Описание
|
|
void
router()
|
Формирование
таблиц рассылки
методом волны
|
|
void
GetRoute(int
CpuNum)
|
Поиск
всех кратчайших
по числу транзитных
передач путей
в графе ВС до
узла CpuNum.
|
Таблица
3.3
Функции,
реализующие
модуль коммуникации
Имя
|
Описание
|
|
int
InitLinkEmul
(const char *IniFile)
|
Инициализация
модуля эмуляции
каналов связи
по файлу инициализации
IniFile,
выделение
буферов приема
информации
для каждого
канала, создание
и соединение
каналов связи
(неименованные
каналы или
сокеты).
Возвращает
0 в случае успеха,
-1 – в случае
ошибки в файле
IniFile.
|
|
void
FinishLinkEmul (void)
|
Завершение
работы модуля
эмуляции каналов
связи.
|
|
static
SOCKET ConnectServerSocket (const char *ServName, int Port)
|
Создание
клиентского
сокета номером
Port и соединение
его с сервером.
|
|
static
SOCKET CreateServerSocket (SOCKET *PrimSock, int Port)
|
Создание
серверного
сокета номером
Port и ожидание
соединения
с клиентом.
|
|
static
int CreatePipeServer (int Port, HANDLE *pipeRead, HANDLE
*pipeWrite)
|
Создание
серверного
неименованного
канала с номером
Port. По указателям
pipeRead и
pipeWrite
возвращаются
файловые
дескрипторы
на чтение и
запись.
|
|
static
int CreatePipeClient (int Port, HANDLE *pipeRead, HANDLE
*pipeWrite)
|
Создание
клиентского
неименованного
канала с номером
Port. По указателям
pipeRead и
pipeWrite
возвращаются
файловые
дескрипторы
на чтение и
запись.
|
|
int
LinkOut (int Link, void *Addr, int Length)
|
Посылка
данных по
заданному
каналу связи
Link,
начиная
с адреса Addr,
Length байт
с приемом
квитанции от
адресата.
|
|
int
LinkIn (int Link,
void *Addr, int Length)
|
Прием
данных по
заданному
каналу связи
Link,
в
буфер начиная
с адреса Addr,
Length байт
с контролем
целостности
пакета и отправкой
квитанции.
|
|
int
Receive (int Chan, int From, void *DataAddr, int DataLength)
|
Выборка
данных из
канального
буфера Chan,
пришедших от
ПЭ From, начиная
с адреса Addr,
Length байт.
|
|
int
Send (int Chan, void *DataAddr, int DataLength)
|
Посылка
данных по каналу
Chan, начиная с
адреса DataAddr, длиной
DataLength байт.
|
|
static
DWORD WINAPI LinkThreadFunc (LPVOID
lpvThreadParm)
|
Задача
прослушивания
канала связи
lpvThreadParm в фоновом
режиме, расшифровка
заголовка
пакета, прием
информационных
частей посылки,
запись в канальный
буфер, выдача
сигнала о приходе
данных.
|
Таблица
3.4
Функции,
реализующие
модуль голосования
и анализатора
отказов
Имя
|
Описание
|
|
void
InitializeVoteBuffers()
|
Переинициализация
буферов голосования
|
|
void
RestoreCpuFault()
|
Сброс
информации
о накопленных
отказах ПЭ
|
|
void
RestoreLinkFault()
|
Сброс
информации
о накопленных
отказах каналов
связей
|
|
int
compare(struct BUFFER b1,struct BUFFER b2)
|
Провести
элементарную
проверку
(сравнение)
буферов функциональной
информации
|
|
int
TrippleFault()
|
Определение
сбоя одного
и того же элемента
ВС на протяжении
трех циклов.
|
|
void
consolidate()
|
Функция
анализа отказов,
принятие
консолидированного
решения, активизации
реконфигуратора.
|
|
void
VoteThread()
|
Задача
голосования,
активизирующаяся
по заполнению
канальных
буферов, активизирующая
обмен в сети
результатами
голосования
и передающая
управление
анализатору
отказов.
|
Таблица
3.5
Функции,
реализующие
реконфигуратор
Имя
|
Описание
|
|
static
int CheckCpuLinks (int Cpu)
|
Проверка
изолированности
ПЭ Cpu.
|
|
void
reconfig(struct SYSTEM* M)
|
Процедура
реконфигурации,
путем изменения
системных
таблиц по
информации
об отказе.
Активизация
маршрутизатора
для перестройки
системных
таблиц.
|
Таблица
3.6
Функции,
реализующие
функциональную
задачу
Имя
|
Описание
|
|
void
TaskLoop()
|
Функция
исполнения
ФЗ (на данном
этапе ФЗ – набор
последовательных
простейших
операторов)
по информации
от объекта
управления.
Завершается
отсылкой
результатов
для голосования
другим ПЭ и
передачей
управления
задачам прослушивания
и голосования.
|
Дополнительные
функции, обеспечивающие
моделирование
отказов в рамках
своего ПЭ,
представлены
в таблице 3.7.
Таблица
3.7
Функции,
реализующие
моделирование
отказа
Имя
|
Описание
|
|
void
KillCpu( int Cpu, int type )
|
type=1
–
фатальный
отказ ПЭ, приостановка
всех канальных
потоков и ФЗ.
type=0
–
отказ ФЗ, внесение
искажений
при вычислении
ФЗ.
|
|
void
KillLink(
int
Link, int type )
|
Завершает
соответствующий
канальный
поток, в случае
фатального
отказа (type=0),
или дает указание
модулю коммуникации
отсылать ошибочные
пакеты (type=1).
|
Диспетчеризация
процессов в
ПЭ происходит
на уровне
операционной
системы, передача
управления
происходит
с помощью таких
механизмов,
как семафоры
и события. Во
время ожидания
на прием управления
задачи находятся
в спячке, почти
не занимая
процессорного
времени. Процесс
передачи управления
приведен на
рис. 3.2. При этом:
Процесс
1: Функциональная
задача;
Процесс
2: Прослушивание
канала связи
с ОУ;
Процесс
3: Процесс голосования
и анализа отказов;
Процесс
4: Реконфигурация;
Процесс
5: Отправка
согласованных
данных;
Процесс
6 .. N+6:
Прослушивание
N
каналов связи
с ПЭ ВС;

Рис.
3.2.
Диспетчеризация
процессов.
Поскольку
используются
функции блокирующего
ввода-вывода
базовой ОС, в
случае отсутствия
данных на входе
задача прослушивания
канала связи
помещается
в состояние
спячки, практически
не занимая при
этом процессорного
времени, и
активизируется
только по приходу
данных. После
этого загружается
тело посылки.
Далее определяется
адресат, и если
посылка предназначена
другому ПЭ, то
посылка передаётся
дальше по информации
от маршрутизатора,
в противном
случае производится
контроль заголовка
(ошибочные
посылки игнорируются).
При наличии
места данные
попадают в
соответствующий
буфер. При наличии
данных во всех
предварительных
буферах, производится
голосование
и запись результата
во входной
буфер канала.
3.2 Программное
обеспечение
подсистемы
проверки
Данный
модуль призван
обеспечить
следующие
функции:
Отображение
текущей топологической
информации
ВС.
Отображение
вычислительного
процесса в ВС.
Возможность
моделирования
различных
отказов ВС.
Для
обеспечения
удобного интерфейса,
приложение
было сделано
в виде диалогового
окна с помощью
библиотеки
классов Windows
MFC (Microsoft
Foundation Classes).

Рис.
3.3. Диалоговое
окно программы
Host.
Функциональное
назначение
элементов
диалогового
окна представлено
в таблице 3.6.
Таблица
3.6
Назначение
и функции элементов
диалога
Элемент
|
Описание
|
|
Панель
«Отказ линка»
|
Содержит
три связанных
элемента:
Переключатели
(Radio
Group)
задания вида
отказа линка,
при этом «Фатальный
отказ» означает
полное прекращение
передачи
информации,
а «Некорректная
передача» -
искажение
передаваемых
пакетов.
Поля
«ПЭ» и «Линк»
задают номер
ПЭ и номер канала
связи для
моделирования
отказа.
Кнопка
«Задать»
активизирует
передачу
управляющей
информации
заданному
ПЭ.
|
|
Панель
«Отказ ПЭ»
|
Содержит
два связанных
элемента:
Переключатели
задания вида
отказа ПЭ, при
этом «Фатальный
отказ» означает
полное прекращение
функционирования
(например
зависание),
а «Отказ ФЗ»
- неправильный
расчет ФЗ, с
сохранением
функций обмена
и голосования.
Поле
«ПЭ» задает
номер ПЭ для
моделирования
отказа.
Кнопка
«Задать»
активизирует
передачу
управляющей
информации
заданному
ПЭ.
|
|
Поле
вывода (Rich
Edit)
«Топология»
|
Обеспечивает
отображение
текущей топологической
информации
в виде модифицированной
матрицы связности
(текстовый
вид), обновляющейся
на каждом такте
работы ВС.
|
|
Поле
вывода «Процесс»
|
Обеспечивает
вывод в текстовом
или графическом
виде согласованных
результатов
счета ФЗ.
|
|
Кнопка
«ПУСК»
|
По
нажатию обеспечивает
создание
конфигурационных
файлов для
каждого ПЭ,
запуск процессов,
моделирующих
ВС, связывание
каналов связи
с каждым ПЭ
и вывод из спячки
канальных
потоков прослушивания.
|
|
Кнопка
«Выход»
|
Обеспечивает
освобождение
памяти, уничтожения
потоков исполнения,
завершение
программы.
|
Для
каждой кнопки
диалогового
окна существует
свой обработчик,
выполняющий
вышеописанные
функции. Помимо
этого функция
InitInstance(), инициализирующая
работу диалога,
выполняет
анализ топологии
ВС, создает
приостановленные
потоки прослушивания
каналов для
связи с каждым
ПЭ, аналогичные
описанным в
таблице 3.3. Модуль
коммуникации
выполнен так
же, как и модуль
коммуникации
ПЭ ВС.
При
работе с интерфейсом
задания отказа,
канальные
потоки прослушивания
приостанавливаются,
и возобновляются
после отсылки
информации
ВС. На каждом
цикле модуль
коммуникации
обеспечивает
прием текущей
топологии ВС,
согласованные
результаты
счета ФЗ и передает
их на отображение
в соответствующие
поля вывода.
Представленное
программное
обеспечение
позволяет
моделировать
произвольную
ВС, заданную
матрицей связности,
проводить
проверку
функционирования
модулей ОСРВ,
обеспечивающих
отказоустойчивость,
проводить
комплексную
отладку ПО.
4.
Портирование
ОСРВ на платформу
TMS320C30
Под
портированием
(от англ. porting)
понимается
изменение
программного
обеспечения
для функционирования
в услвиях разных
архитектур
процессорных
элементов.
4.1
Основные
характиристики
и область применения
процессора
TMS320C30
Унивеpсальность
и pабота в pеальном
масштабе вpемени
пpоцессоpов
семейства
TMS320 позволяют
использовать
их в шиpоком
кpуге pазpаботок,
таких как:
ЦОС
ОБЩЕГО НАЗНАЧЕНИЯ:
цифpовая
фильтpация;
свертка;
коppеляция;
пpеобpазование
Гильбеpта;
быстpое
пpеобpазование
Фуpье;
адаптивная
фильтpация и
др.
ИНСТРУМЕНТАЛЬНЫЕ
СРЕДСТВА :
ВОЕННАЯ
ТЕХНИКА, управляющие
системы и др.
Поддеpжка
языков высокого
уpовня легко
pеализуется
благодаpя
использованию
основанной
на pегистpах
аpхитектуpы,
большому адpесному
пpостpанству,
мощной системе
адpесации, гибкому
набоpу команд
и поддеpжке
аpифметики с
плавающей
точкой.
Ниже
пеpечислены
основные параметры
TMS320C30:
Блок
ПЗУ 4К х 32 двойного
доступа без
такта ожидания
Два
блока ОЗУ 1К х
32 двойного доступа
без такта ожидания
Кэш-память
команд 64 х 32
32-pазpядные
слова данных
и команд, 24-pазpядный
адpес
40/32-бит
плавающая
точка/целые
числа умножитель
и АЛУ
32-pазpядный
кольцевой
сдвиговый
pегистp
Восемь
pегистpов pасшиpенной
точности
(аккумулятоpы)
Два
адpесных генеpатоpа
с восемью
вспомогательными
pегистpами и
два аpифметических
блока вспомогательных
pегистpов
Внутpикpистальный
контpоллеp пpямого
доступа в память
(DMA) для независимых
опеpаций ввода/вывода
и центpального
пpоцессоpного
блока
Целочисленные,
с плавающей
точкой и логические
опеpации
Двух-
и тpехопеpандные
команды
Паpаллельная
pабота АЛУ и
умножителя
в одном такте
Возможность
повтоpения
блоков команд
Циклы
с нулевыми
непроизводительными
издержками
и пеpеходы за
один цикл
Условные
переходы и
возвраты
Команды
для поддеpжки
мультипpоцессоpной
pаботы
Два
последовательных
порта для обмена
8/16/32 - pазpядными
сообщениями
Два
32-pазpядных таймера
Два
внешних флага
общего назначения,
четыре внешних
прерывания
4.2
Обзор базовых
ОСРВ для платформы
TMS320C30
Для
построения
отказоустойчивой
системы реального
времени на базе
процессора
TMS320C30
необходимы
базовые механизмы
и средства,
которые были
перечислены
в главе 1. В настоящее
время существует
достаточно
много базовых
ОСРВ для процессоров
серии TMS320.
Качественно
они мало чем
отличаются
друг от друга,
различия могут
возникать из-за
специфики
применения
этих ОСРВ. Приведем
характеристики
одной из самых
известных ОСРВ,
переносимых
на TMS320C30.
Операционная
система SPOX.
SPOX
поддерживает
несколько
различных
вариантов
архитектур:
дополнительные
вычислительные
среды для рабочих
станций;
однородные
встраиваемые
системы;
неоднородные
встраиваемые
системы;
персональные
компьютеры
с процессором
Intel
Pentium
под управлением
Microsoft
Windows
95.
Среда
SPOX
состоит из
четырех основных
компонентов
(рис. 4.1):
ядро
SPOX
(SPOX-KNL)
обеспечивает
вытесняющую
приоритетную
многозадачность,
высокоскоростную
обработку
прерываний,
распределение
памяти, различные
механизмы
межзадачного
обмена информацией
и синхронизации,
а также независимый
от устройств
ввод-вывод.
Результатами
тестирования
SPOX-KNL
стали следующие
цифры:
Время
захвата семафора
– 7.9 мкс;
Время
переключения
задач одинакового
приоритета
– 15 мкс;
Время
реакции на
прерывание
– 33 мкс;
Время
завершения
прерывания
– 1.4 мкс;
Задержка
диспетчеризации
(время вытеснения
задачи с большим
приоритетом
задачу с меньшим)
– 12.24 мкс;
Время
переключения
контекста –
7 мкс;
Минимальный
размер системы
1532 слова.
модуль
SPOX-LINK
поддерживает
«прозрачное»
взаимодействие
между целевой
платформой
и хост-системой
и дающее доступ
к основным
ресурсам
хост-машины,
таким как консоли,
файловые системы
и сети;
библиотека
(SPOX-MATH)
содержит свыше
175 математических
функций;
высокоуровневый
отладчик SPOX-DBUG.

Рис.
4.1. Структурная
схема ОС SPOX
Все
четыре подсистемы
реализованы
как библиотеки
C-вызываемых
перемещаемых
модулей. При
этом системные
функции SPOX
подключаются
к объектному
коду приложения
на этапе связывания.
С
помощью дополнительного
модуля SPOX-MP
становится
возможной
многопроцессорная
обработка
сигналов. Настройка
на конкретную
конфигурацию
сети процессорных
элементов
задается в
конфигурационном
файле, что позволяет
не привязываться
к конкретной
топологии в
процессе разработки
приложения.
SPOX-MP
обеспечивает
динамическую
передачу данных
и сообщений
по сети процессорных
элементов,
глобальное
пространство
имен, а также
лавинообразную
первоначальную
загрузку сети.
Таким
образом ОСРВ
SPOX
имеет необходимые
механизмы для
создания
отказоустойчивой
распределенной
операционной
системы реального
времени, концепция
построения
которой описана
в главе 2.
4.3
Аппаратно-зависимые
компоненты
ОСРВ
Модули
маршрутизации,
реконфигурации,
голосования
реализованы
как аппаратно-независимые
процедуры
операционной
системы. Модули
оперируют
данными, заданными
в конфигурационном
файле, что не
привязывает
их к конкретной
топологии.
Реализованные
методом структурного
программирования
на языке Си,
модули могут
быть перенесены
на большинство
платформ, включая
и TMS320C30.
Модуль
коммуникации
оперирует
высокоуровневыми
функциями
обмена, опирающимися
на драйвера
операционной
системы. Обмен
данными осуществляется
через последовательные
порты с помощью
встроенных
механизмов
передачи маркера
между соседними
процессорными
элементами.
Зависимость
программного
обеспечения
в рамках рассматриваемой
операционной
системы возникает
на этапе
самодиагностирования
процессора
с целью получения
информации
о своем состоянии.
4.3.1.
Модуль диагностики
ПЭ
Модуль
диагностики,
реализованный
в виде набора
функций, возвращающих
код ошибки,
призван решать
следующие
задачи:
На
этапе инициализации:
Тестирование
регистров
общего назначения
процессора;
Проверка
правильности
выполнения
арифметических,
логических
и др. операций;
Занесение
в соответствующую
таблицу контрольных
сумм неизменных
во время выполнения
программ областей
памяти (исполняемый
код, константы),
размещение
которых в памяти
проводится
на этапе сборки
рабочего кода
в соответствии
с картой памяти;
Во
время рабочего
цикла, тестирование
может проводиться
как с прерыванием
вычислений
функциональных
задач, так и
непосредственно
во время их
выполнения,
если предусмотрено
процессорное
время на выполнение
этих тестов.
При этом может
осуществляться:
Тестирование
регистров
общего назначение;
Проверка
правильности
выполнения
арифметических,
логических
и др. операций;
Вычисление
контрольных
сумм указанных
областей памяти
и сопоставление
их с вычисленными
на этапе инициализации.
4.3.1.1.
Тестирование
регистров
общего назначения
Этот
тест выполняется
первым для
проверки регистров
повышенной
точности (R0-R7)
и вспомогательных
регистров
(АR0-АR7).
Тестирование
сводится к
проверке регистров
на запись/чтение
из памяти/в
память и проверке
правильности
перемещения
данных из регистра
в регистр. Тест
разбивается
на два этапа:
Инициализировать
две целочисленные
переменные
начальным и
ожидаемым
значением
тестирования;
Загрузить
начальное
значение в
регистры (АR0-АR7).
Произвести
операцию сложения
так, что в каждом
последующем
регистре оказалась
сумма предыдущих.
Запись
в стек модифицированных
регистров.
Произвести
операцию сдвига
влево содержимого
стека на N
разрядов в
соответствии
с номером
записанного
регистра.
Записать
данные из стека
в регистры.
Произвести
операцию сложения
так, что в каждом
последующем
регистре оказалась
сумма предыдущих.
Сравнить
содержимое
регистра АR7
с ожидаемым,
заранее рассчитанным
значением.
Функция
register_test
реализована
на языке Ассемблер
в соответствии
с архитектурой
и системой
команд TMS320C30.
4.3.1.2.
Проверка правильности
выполнения
арифметических,
логических
и др. операций
Данный
тест разделен
на три различных
модуля. Вместе
они проверяют
следующие
числовые операции:
1.
Логические,
сдвиг, циклический
сдвиг.
2.
Операции с
плавающей
запятой, выполненные
над одним значением
и соответствующие
параллельные
команды.
3.
Операции с
плавающей
запятой и
целочисленные,
выполняющие
сложение, вычитание,
и умножение
и соответствующие
параллельные
команды.
В
тестах проверяются
команды, перечисленные
в Таблице 4.1.
Таблица
4.1
Перечень
тестируемых
команд
|
Тест
|
Команды
|
|
1
|
2
|
|
Тест
1
|
ROL
– циклический
сдвиг влево,
ROLC
– циклический
сдвиг влево
через перенос,
ROR
– циклический
сдвиг вправо,
RORC
– циклический
сдвиг вправо
через перенос,
AND3
|| STI – поразрядное
логическое
И с сохранением,
LSH3
|| STI – логический
сдвиг с сохранением,
NOT
|| STI – дополнение
с сохранением,
OR3
|| STI – поразрядное
логическое
ИЛИ с сохранением,
XOR3
|| STI – поразрядное
исключающее
ИЛИ с сохранением,
ABSI
|| STI – абсолютное
значение целого
с сохранением,
NEGI
|| STI – отрицание
целого с сохранением,
ASH3
|| STI – арифметический
сдвиг с сохранением,
|
|
1
|
2
|
|
NOT
– поразрядное
логическое
дополнение,
ABSI
– абсолютное
значение целого
числа,
NEGB
– отрицание
целого с заемом,
ASH
– арифметический
сдвиг,
NEGI
– отрицание
целого,
TSTB3
– проверка
битовых полей,
CMPI3
– сравнение
целых,
STI
|| STI – сохранение
целых,
LDI
|| LDI – загрузка
целых,
XOR
– поразрядное
исключающее
ИЛИ.
|
|
Тест
2
|
STF
– сохранить
значение с
плавающей
точкой,
LDF
– загрузить
значение с
плавающей
точкой,
LDE
– загрузка
значения
экспоненты
с плавающей
точкой,
LDM
– загрузка
значения мантиссы
с плавающей
точкой,
FIX
– преобразование
в целое,
FLOAT
– преобразование
в значение с
плавающей
точкой,
ABSF
– абсолютное
значение числа
с плавающей
точкой,
NEGF
– отрицание
значения с
плавающей
точкой,
NORM
– нормирование
значения с
плавающей
точкой,
RND
– округление
значения с
плавающей
точкой,
POPF
– выталкивание
значения с
плавающей
точкой из стека,
PUSHF
– загрузка в
стек значения
с плавающей
точкой,
ABSF
|| STF – абсолютное
значение числа
с плавающей
точкой с сохранением
значения с
плавающей
точкой,
FIX
|| STI – преобразование
в целое с сохранением,
FLOAT
|| STF – преобразование
в значение с
плавающей
точкой с сохранением
значения с
плавающей
точкой,
PUSH
– загрузка
целого в стек,
POP
– выталкивание
целого из стека,
LDF
|| STF – загрузить
значение с
плавающей
точкой с сохранением
значения с
плавающей
точкой,
|
|
1
|
2
|
|
NEGF
|| STF – отрицание
значения с
плавающей
точкой с сохранением
значения с
плавающей
точкой,
STF
|| STF – сохранения
значений с
плавающей
точкой,
LDF
|| LDF – загрузка
значений с
плавающей
точкой.
|
|
Тест
3
|
SUBF3
– вычитание
значений с
плавающей
точкой,
SUBF3
|| STF – значения
с плавающей
точкой с сохранением
значения с
плавающей
точкой,
SUBB
– вычитание
целых с заемом,
SUBC
– условное
вычитание
целых,
SUBF
– вычитание
значений с
плавающей
точкой,
SUBRB
– вычитание
целых в обратном
порядке с заемом,
SUBRF
- вычитание
с плавающей
точкой в обратном
порядке,
SUBI3
|| STI – вычитание
целых с сохранением,
ADDC
– сложение
целых с переносом,
ADDF
– сложение
значений с
плавающей
точкой,
ADDF3
– сложение
значений с
плавающей
точкой,
ADDF3
|| STF – значений
с плавающей
точкой с сохранением
значения с
плавающей
точкой,
ADDI3
|| STI – сложение
целых с сохранением,
MPYF-
умножение
значений с
плавающей
точкой,
MPYF3
– умножение
значений с
плавающей
точкой,
MPYI
– умножение
целых,
MPYF3
|| STF – умножение
значений с
плавающей
точкой с сохранением
значения с
плавающей
точкой,
MPYF3
|| ADDF3 – умножение
и сложение с
плавающей
точкой,
MPYF3
|| SUBF3 умножение
и вычитание
с плавающей
точкой,
MPYI3
|| STI – умножение
целых с сохранением,
MPYI3
|| ADDI3 – умножение
и сложение
целых,
MPYI3
|| SUBI3 – умножение
и вычитание
целых,
CMPF
– сравнение
значений с
плавающей
точкой,
CMPF3
- сравнение
значений с
плавающей
точкой.
|
Проверка
осуществляется
с помощью
фиксированного
набора значений
с целью тестирования
команд в различных
пределах. Вывод
о успехе/неуспехе
делается на
основе контрольного
суммирования
результатов
и сопоставления
с ожидаемым
значением.
4.3.1.3.
Проверка содержимого
памяти
Данный
тест формирует
по одному из
самых простых
алгоритмов
так называемый
CRC
(Cyclic Redundancy Check) блока памяти,
указанный в
параметрах
теста. Правильный
(ожидаемый) CRC
подтверждает
правильность
данных (кода)
в указанной,
неизменной
(nonvolatile)
в процессе
исполнения
задач области
памяти.
Формирование
CRC
происходит
по следующему
алгоритму:
Инициализация
начального
значения CRC
нулем; маска
контрольных
битов выбирается
произвольно,
например -
80200003(Н).
Наложить
маску на CRC
и суммировать
по модулю два
значения контрольных
битов.
Сдвинуть
CRC
влево на 1 разряд
и прибавить
результат шага
2.
Сложить
результат с
очередным
словом блока
тестируемых
данных.
Если
блок закончился
шаг 6, иначе шаг
2.
Сравнить
полученный
CRC
с ожидаемым.
Ожидаемые
значения могут
быть получены
на этапе инициализации.
Функция crc_test
реализована
на языке Ассемблер
в соответствии
с архитектурой
и системой
команд TMS320C30.
5.
Перспективы
развития
специализированных
отказоустойчивых
ОСРВ
Предложенная
в работе концепция
организации
отказоустойчивых
вычислений,
является лишь
первым шагом
в создании
универсальной,
аппаратно-независимой,
многофункциональной
распределенной
ОСРВ.
Очевидно,
что создание
отказоустойчивых,
адаптивных
систем необходимо
для надежного
функционирования
критически
важных приложений
множества
различных
управляющих
систем. Однако
усложнение
структуры
вычислительных
систем, а соответственно
и алгоритмов
поддержки
отказоустойчивости
(а в общем случае
и живучести),
ведет к увеличению
размера ОС и
ее времени
реакции. Поэтому,
следует по-прежнему
придерживаться
структурного
подхода при
проектировании
управляющих
систем и использовать
заранее определенные
функции ОСРВ,
характерные
для данного
вида систем
управления.
Дальнейшее
наращивание
функций ОСРВ
может вестись
в нескольких
направлениях:
Голосование,
проводимое
на уровне
элементарной
проверки, в
общем случае
может не удовлетворять
условиям
функционирования
управляющих
систем вследствие
погрешностей
и возможного
отличия функциональной
информации,
поступающей
на обработку
в ФЗ разных
ПЭ. Поэтому
при голосовании,
особенно на
последних
стадиях деградации
целесообразно
применять
помехоустойчивое
оценивание,
например методом
наименьших
квадратов
(МНК).
Основные
трудности
связаны с ошибочными
измерениями
или неверным
результатом
ФЗ при вызывающей
сбой комбинации
входных данных.
Применение
методов устойчивого
оценивания
к решению этой
проблемы поможет
избежать потерь
времени на
повторные
измерения и
расчет ФЗ, а
также поможет
внести определенность
при несогласованности
данных в процессе
голосования.
Усовершенствование
подсистемы
сбора и анализа
отказов для
диагностирования
множественных
отказов на
одном такте
работы системы.
Однако, следует
учесть, что
обнаружение
большего числа
отказов требует
пропорциональное
увеличение
числа обменов
между модулями
голосования,
а также числа
процессорных
элементов,
участвующих
при голосовании.
Расширить
возможности
самодиагностирования
ПЭ подсистемой
промежуточных
тестов ввода-вывода,
тестом таймеров
и др.
Предусмотреть
возможности
резервирования
ФЗ или отдельных
ее частей для
программного
обнаружения
отказа, локализации
и передачи
управления
дублирующему
фрагменту ФЗ.
Представленный
в работе материал
является попыткой
систематизировать
и реализовать
основные принципы
разработки
системного
программного
обеспечения
для отказоустойчивых
вычислительных
систем. Частично
или полностью,
эти принципы
реализуются
разработчиками
ОСРВ для обеспечения
отказоустойчивости
сетевых приложений.
Дальнейшее
развитие
реализованных
в представленной
работе принципов
в еще более
сложные системы
позволит решать
еще более широкий
круг задач в
рамках обеспечения
надежности
вычислительных
систем.
Заключение
В
рамках решения
поставленной
задачи, по
результатам
аналитических
исследований,
были выделены
основные свойства
и механизмы
распределенных
операционных
систем реального
времени, необходимых
для работы
критически
важных приложений.
Это:
Время
реакции системы;
Время
переключения
контекста;
Наличие
средств диспетчеризации;
Наличие
средств синхронизации,
межзадачного
и межпроцессорного
взаимодействия;
Однако
требования,
предъявляемые
к надежности
вычислительных
систем, таковы,
что этих средств
зачастую оказывается
недостаточно.
В ходе аналитической
работы, была
доказана
необходимость
и описана структура
таких встроенных
механизмов
обеспечения
отказоустойчивости
ОСРВ, как:
Средства
маршрутизации
пакетов данных
в сети ПЭ;
Средства
высокоуровневого
межпроцессорного
обмена;
Протокол
голосования,
анализа отказов
в ВС, и принятия
консолидированного
решения;
Средства
реконфигурации
ВС.
В
ходе дальнейших
исследований,
был рассмотрен
пример организации
отказоустойчивых
вычислений,
и на основе
логики принятия
консолидированного
решения, предложен
эвристический
алгоритм анализа
результатов
голосования
узлов (ПЭ) ВС
и средств
диагностики.
Далее
была предложена
вероятностная
модель отказоустойчивой
ВС, рассчитаны
ее надежностные
характеристики,
показавшие
увеличение
среднего времени
наработки ВС
на отказ в 2,5 –
3,5 раз с расширением
ВС до 5-7 узлов,
даны рекомендации
по выбору типа
ВС при ее проектировании.
В
ходе практической
реализации
свойств отказоустойчивости,
была создана
программная
модель, имитирующая
многопроцессорную
ВС, управляемую
распределенной
ОСРВ. Структура
ПО модели включает
в себя ПО узла
ВС и ПО системы
контроля и
диалога с
пользователем.
Модель позволила
отработать
логику организации
отказоустойчивых
вычислений
и проверить
ее в различных
ситуациях.
Реализация
модели позволила
выделить ключевые
особенности
системного
ПО, характерного
для организации
отказоустойчивых
вычислений
в целом:
Наличие
глобального
системного
цикла, задаваемого
организацией
внешних устройств
или объекта
управления.
Использование
механизмов
межзадачного
взаимодействия
(семафоры, события,
мьютексы) для
организации
циклов и передачи
управления
и диспетчеризации
процессов.
Использование
сторожевых
таймеров во
всех активных
модулях ПО,
для предотвращения
зависания
вычислительного
процесса и
межпроцессорного
обмена.
Наличие
иерархической
структуры
функций межпроцессорного
обмена, опирающихся
на драйвера
базовой операционной
системы.
Наличие
в системном
ПО различного
рода контейнерных
классов, а именно:
массивов, очередей,
списков которые
активно используются
для хранения
и передачи
системной
информации,
диспетчеризации
событий или
сообщений.
Даны
рекомендации
по портированию
системного
ПО на платфртму
TMS320C30.
Выбор платформы
осуществлялся
по таким критериям,
как: наличие
широкого спектра
совместимых
базовых ОСРВ,
оптимизация
микропроцессора
под задачи
управления,
тактовая частота
микропроцессора,
объем оперативной
памяти, наличие
сред разработки
и отладки и
т.д. Реализованы
аппаратно-зависимые
модули ПО в
части процедур
самодиагностики
процессора
и памяти.
В
заключение,
перечислены
основные перспективы
наращивания
возможностей
системного
ПО и усложнения
принципов его
работы.
Дальнейшее
развитие
реализованных
в представленной
работе принципов
в еще более
сложные системы
позволит решать
еще более широкий
круг задач в
рамках обеспечения
надежности
вычислительных
систем.
Технологическая
часть
6.Технологическая
часть
Данная
глава посвящена
технологии
разработки
программного
обепечения
модели отказоустойчивой
распределенной
вычислительной
системы и переносу
(портированию)
основных модулей
отказоустойчивой
ОСРВ на платформу
TMS320C30.
Программное
обеспечение
модели ВС состоит
из двух частей,
разработанных
для функционирования
на базе персонального
компьютера
с процессором
Pentium-100
и выше с операционной
системой Windows
98 и
выше. Первая
часть предназначена
для генерации
системных
файлов процессорных
элементов ВС
на основе заданной
топологии,
запуска модели
ВС, имитации
объекта управления
и генерации
системной
информации
о сбоях ВС. Вторая
часть предназначена
для моделирования
узла ВС.
Программное
обеспечение,
переносимое
на платформу
TMS320C30, на данном
этапе состоит
из набора функций,
которые являются
надстройкой
над базовой
ОСРВ.
6.1.
Системные
исследования
В
ходе системных
исследований
проводился
анализ системы,
в которой будет
использоваться
разрабатываемая
ОСРВ, и были
выделены основные
надстройки
над базовой
ОСРВ для поддержания
свойств системы
в процессе ее
работы.
Общая
структура
системы, моделируемая
разрабатываемым
программным
продуктом,
представлена
на рис. 6.1.
Таким
образом, программное
обеспечение
модели системы
разбивается
на две части.
Первая – это
ПО, в задачи
которой входит:
моделирование
объекта управления
(обмен информацией
с ВС), инициализация
ВС на основе
заданной
топологической
информации,
моделирование
сбоев и отказов
элементов ВС
для отладки
модулей обеспечения
отказоустойчивости
ВС.

Рис.
6.1. Структура
ВС
Вторая
часть служит
для моделирования
ПЭ системы и
предназначена
для отработки
алгоритмов
обеспечения
отказоустойчивости
в процессе
непрерывного
функционирования
ВС.
Анализ
требований
к функционированию
ВС предопределил
структуру
распределенной
операционной
системы ВС,
которая состоит
из идентичных
операционных
систем узлов
сети, отличных
друг от друга
лишь своим
номером и содержанием
системных
таблиц, обусловленных
размещением
узла в сети ПЭ.
Структура
распределенной
ОС представлена
на рис. 6.2.
 Рис.
6.2. Структура
распределенной
ОС Рис.
6.2. Структура
распределенной
ОС
Задачей
ПО является
обеспечение
обмена между
объектом управления
и ПЭ, обмена
функциональной
и системной
информацией
внутри ВС, выполнение
функциональной
задачи согласно
информации
от объекта
управления,
реакции на сбои
и отказы в системе,
выявление и
локализации
отказавших
участков ВС
консолидированным
решением рабочей
конфигурацией
сети, реконфигурация
системы в реальном
времени в
соответствии
с принятым
решением.
Платформа
TMS320C30,
для реализации
выбранной
концепции
построения
ОСРВ, была выбрана,
исходя из аппаратных
характеристик,
наличия большого
класса базовых
ОСРВ, совместимых
с данной платформой,
удобных средств
разработки
и отладки.
6.2. Разработка
спецификации
Разработка
спецификации
служит для
более четкой
формализации
требований
к программному
обеспечению,
полученных
на этапе системных
исследований.
6.2.1.
Требования
к ПО управляющей
части
Программное
обеспечение
служит для
инициализации
работы ВС, имитации
объекта управления,
демонстрации
работы ВС в
условиях
возникновения
отказов и должно
состоять из
модулей, обеспечивающих:
Анализ
топологии
моделируемой
ВС:
Запуск
системы;
Обмен
функциональной
информацией
с ВС:
Моделирование
отказов и сбоев
компонент ВС:
формирование
сигнала на
полный отказ
определенного
канала связи
ПЭ (прекращение
функционирования);
формирование
сигнала на
сбой определенного
канала связи
ПЭ (искажение
информации
при передаче);
формирование
сигнала на
полный отказ
ПЭ (прекращение
функционирования,
“зависание”);
формирование
сигнала на
сбой ПЭ (неверный
расчет функциональной
задачи).
6.2.2. Требования
к ПО узлов сети
В
распределенной
операционной
системе организация
программного
обеспечения
следующая.
Каждый модуль
содержит копию
ОС, которая
спроектировано
так, чтобы обеспечить
стандартный
интерфейс с
другими модулями
в системе. Прикладное
программное
обеспечение
распределенной
ОС выступает
как набор параллельно
взаимодействующих
процессов, а
ОС узла обеспечивает
высокоуровневую
структуру для
обслуживания
межпроцессорных
связей, а также
содержит процедуры
диагностики
и локализации
отказов, реконфигурации
и замены отказавшего
элемента.
Таким
образом, ПО
узла должно
обеспечивать:
Определение
статических
маршрутов
передачи информации
в ВС, исходя
из текущей
топологии ВС;
Расчет
функциональной
задачи на очередном
цикле;
Обмен
функциональной
и системной
информацией
внутри ВС:
прием
и передача
функциональной
информации
после завершения
расчета функциональной
задачей;
прием
и передача
информации
о результатах
элементарных
проверок
функциональной
информации;
прием
и передача
информации
о результатах
голосования
(консолидированного
решения).
прием
и передача
информации
инициализации
при замене
отказавшего
элемента;
обеспечение
транзитной
передачи информации
при отказе
канала связи.
Сравнение
поступающей
функциональной
информации
(элементарная
проверка) и
формирование
промежуточного
решения о состоянии
системы.
Голосование
и принятие
консолидированного
решения о наличии
(отсутствия)
отказов в системе.
Реконфигурацию
ВС в соответствии
с результатами
голосования.
Синхронизацию
работы ВС.
Обмен
информацией
с объектом
управления:
прием
функциональной
информации
от объекта
управления
в начале очередного
цикла;
выдачу
функциональной
информации
в конце очередного
цикла;
прием
управляющего
сигнала на
моделирование
отказа ПЭ или
одного изи
каналов связи;
Диагностирование
состояния ПЭ.
6.3. Разработка
алгоритмов
Разработка
алгоритмов
велась с учетом
построенной
на этапе системных
исследований
структурой
ПО (см. рис. 6.2) и
требований
к нему.
Наибольшее
применение
к настоящему
времени получил
структурный
подход к технологии
программирования,
предполагающий
нисходящую
разработку,
структурное
программирование
и сквозной
структурный
контроль. При
нисходящей
разработке
проектирование
и программирование
ведутся сверху
вниз. Для восходящего
подхода характерен
ряд трудностей,
которых можно
избежать при
нисходящем
подходе:
каждый элементарный
модуль может
правильно
работать со
своей отладочной
программой,
но все модули
вместе могут
и не работать
вследствие
несогласованности
или различной
интерпретации
спецификаций
каждого модуля.
6.3.1. Структура
программы
Разработка
структуры ПО
отказоустойчивой
ВС проводилась
с помощью комбинации
нисходящего
и восходящего
подходов. Сначала
был выделен
общий принцип
работы ВС в
целом, который
можно представить
в виде следующего
графа управления
(см. рис. 6.3).

Исходя
из графа управления,
общая структура
программного
продукта была
разбита на две
части, а они в
свою очередь
- на модули по
технологии
сверху вниз
методом декомпозиции.
Далее, в пределах
некоторых
модулей применялся
подход снизу
вверх с применением
структурного
программирования
для подключения
новых функций
модуля, удовлетворяющих
спецификации.
Структура
распределенной
ОСРВ диктовалась
независимостью
узлов сети от
ПО других
составляющих
сети и возможностью
подключения
или изменения
пользователем
тех или иных
функций ОСРВ
без изменения
других составляющих
и общей концепции
построения
системы.
Внутренняя
структура
модулей проектировалась
структурировано,
по критерию
минимизации
межмодульных
связей и циклов.
Модули оперируют
системной
информацией
независимо
от характера
выходных данных
предыдущих
модулей.
Алгоритмы
и функционирование
модулей ОСРВ
детально рассмотрены
в главе 2 и 3.
ПО
имитации объекта
управления
и задания отказов
имело свое
назначение,
как отладочный
механизм демонстрации
принципов
отказоустойчивости
специализированных
ВС. Назначение
его модулей
формулировались
на этапе системного
анализа и составления
спецификации
на системное
ПО узлов сети.
Конечным фрагментом
разработки
данного ПО
является возможность
полной проверки
отказоустойчивости
ВС.
В
процессе дальнейших
исследований
предполагается
дальнейшее
наращивание
функций отладочного
механизма по
технологии
снизу вверх.
6.4.
Кодирование
Выбор
языка программирования
определяется,
с одной стороны,
требованиями
к программному
обеспечению
(например, размер
и скорость
исполнения
кода), с другой
стороны, наличием
сред разработки,
компиляторов,
отладчиков
и других инструментов
разработчика.
Для
реализации
модели отказоустойчивой
ВС использовался
язык С и среда
разработки
Microsoft Visual С++ 6.0. Выбор
среды разработки
обусловлен
наличием у нее
широких возможностей
по использованию
механизмов
Windows 98/2000 в качестве
поддержки
базовых функций
ОСРВ. Windows 98/2000 не
является операционной
системой реального
времени, однако
имеет достаточно
мощные механизмы
(pipes – обмен
данными между
процессами,
многозадачность
и многопоточность,
средства
синхронизации
– семафоры,
мьютексы, события,
таймеры) во
многом схожие
с механизмами
ОСРВ, и достаточные
для реализации
модели.
Язык
С, поддерживаемый
большинством
сред разработки
и трансляторов
различных ОСРВ,
используемый
при разработке
модели, позволяет
создавать
аппаратно и
операционно-независимые
фрагменты
программ, не
привязанных
к механизмам
Windows.
Выбор
языка С был
обусловлен
также следующими
факторами:
повсеместным
применением
языка С для
аппаратного
программирования,
так как он обладает
хорошей оптимизируемостью
кода, и эффективностью,
сравнимым с
Ассемблером.
наличием
больших библиотек,
поставляемых
вместе со средствами
разработки,
которые значительно
облегчают и
оптимизируют
труд разработчиков.
навыками
разработчиков.
Для
программирования
платформы
TMS320C30 использовалась
среда разработки
Code Composer 3.0 с транслятором
языка С, во
многом напоминающая
Visual C++. Выбор
данной среды
разработки
был обусловлен
следующими
фактороми:
сочетание
интегрированной
среды разработки
с симулятором
и мощной системой
отладки;
Windows-интерфейс;
большой
набор настроек
проекта, в том
числе настройка
карт памяти;
симулятор
с широким набором
возможностей;
наличие
мощной системы
отладки.
Для
реализации
аппаратно-зависимых
участков программ,
используется
Ассемблер
данной архитектурной
группы.
6.5.
Тестирование
и отладка
На
этапе разработки
и программирования
были выбраны
следующие
методы и средства
тестирования
и отладки:
встроенный
отладчик
интегрированной
среды разработки
Visual C++ 6.0;
отладочно-демонстрационная
программа
моделирования
отказов ВС;
сквозной
структурный
контроль на
всем этапе
программирования.
встроенный
отладчик
интегрированной
среды разработки
Соde Composer 3.0;
6.5.1.
Метод сквозного
структурного
контроля
Основная
идея сквозного
структурного
контроля -
регулярная
взаимная проверка
программных
модулей на
этапе программирования.
Такой контроль
необходим для
обнаружения
и исправления
ошибок как
можно раньше,
пока стоимость
исправления
ошибок минимальна.
При отладки
написанных
программ важно
тщательно
провести тестирование
программного
продукта. Цель
тестирования
состоит в том,
чтобы убедиться,
что программа
решает действительно
ту задачу, для
которой предназначена,
и выдает правильный
результат при
любых условиях.
6.5.2.
Встроенный
отладчик
интегрированной
среды разработки
Microsoft
Visual C++ 6.0
Встроенный
отладчик
предоставляет
следующие
возможности:
Возможность
пошагового
исполнения
программы,
Возможность
установки
брейкпоинтов
(точек
останова программы)
в необходимых
местах,
Возможность
просмотра и
изменения
значений переменных,
Возможность
приостановки
и запуска процессов
и др.
С
его помощью
отслеживалась
правильность
выполнения
различных
функций в составе
ПО, вложенных
вызовов, достоверность
передачи информации
внутри сложных
функций, правильность
преобразования
типов и т.п.
Встроенный
отладчик
использовался
на промежуточных
этапах разработки
ПО, главным
образом для
отладки отдельных
модулей в составе
модели ВС.
6.5.3.
Встроенный
отладчик
интегрированной
среды разработки
Code
Composer 3.0
Встроенный
отладчик
предоставляет
следующие
возможности:
Возможность
пошагового
исполнения
программы,
Возможность
установки
брейкпоинтов;
просмотр
состояния
процессора
(содержимое
регистров и
флагов, сегменты
кода и данных);
просмотр
значений локальных
и глобальных
переменных;
просмотр
содержимого
стека и истории
вызовов;
дизассемблирование
программы;
возможность
подключения
в ключевых
точках программы
ввода-вывода
с помощью текстовых
файлов, таким
образом симулируется
трансфер данных
через память
процессора;
возможность
подключения
графического
аппарата,
представленного
4-мя различными
вариантами
диаграмм для
построения
графиков различной
сложности и
отслеживания
сигналов реального
времени;
наличие
профайлера,
позволяющего
производить
замер производительности
процессора
на критических
участках кода
и др.
С
его помощью
отслеживалась
правильность
выполнения
модулей ОСРВ,
переносимых
на платформу
TMS320C30,
и процедуры
аппаратно-зависимой
диагностики.
6.5.4.
Отладочная
программа
Отладочная
программа была
написана для
проверки работы
модулей, обеспечивающих
системе свойства
отказоустойчивости,
в комплексной
форме, то есть
при одновременной
параллельной
работе нескольких
ПЭ вычислительной
системы.
С
помощью отладочной
программы
проводилось
следующее
тестирование:
проверка
правильности
реакции системы
на отказ или
сбой каналов
связи;
проверка
правильности
реакции системы
на отказ или
сбой ПЭ;
проверка
правильности
перестройки
(реконфигурации)
системы после
отказа;
проверка
правильности
выдаваемых
системой результатов
в условиях
постоянной
деградации
системы.
6.5.5.
Отладка и
тестирование
модулей ОСРВ
На
первом этапе
для всех модулей
тестировались
все разветвления
на графе управления
программой
как с помощью
встроенного
отладчика
(правильная
обработка всех
команд), так и
стохастически,
то есть с помощью
генерации
различной
последовательности
входных данных,
и проверки
результатов
сравнением
с эталонными
значениями.
Далее проверка
производилась
комплексно,
исследовалась
реакция и
взаимодействие
модулей.
Приведем
описание процесса
тестирования
для некоторых
модулей.
Модуль
маршрутизации:
Отладка и
тестирование
этого модуля
проводилась
сначала с помощью
отладчика, на
вход подавалась
простейшая
топология сети,
при этом отслеживалось
правильное
выполнение
статических
команд и команд
перехода и
ветвления.
После получения
удовлетворительных
результатов,
тестирование
продолжалось
стохастически,
проверкой
модуля на различных
входных топологиях.
Дальнейшее
тестирование
проводилось
комплексно,
с подключением
модуля реконфигурации.
Модуль
реконфигурации:
Проверка выполнения
всех ветвей
проводилась
с помощью отладчика,
на вход алгоритма
подавались
нужные значения
и с помощью
трассировки
проверялась
правильность
выбора и выполнения
нужной ветви.
Дальнейшая
стохастическая
отладка модуля
проводилась
как с использованием
отладчика, так
и отладочной
программы, с
помощью генерации
различного
рода информации
об отказах и
проверкой
результатов
работы данного
модуля сравнением
с ожидаемым
результатом.
Отладка
и тестирование
других модулей
проводилась
по той же схеме,
причем особое
внимание уделялось
комплексной
отладке программы.
Комплексная
отладка модулей
проводилась
организацией
взаимодействия
модулей в
соответствии
с логикой работы
ВС, отслеживались
данные межзадачного
взаимодействия,
синхронизация,
и последовательность
действий с
помощью специально
вводимых текстовых
сообщений в
ключевых узлах
программ.
Список литературы
1.
Затуливетер
Ю.С. Введение
в проблему
параметризованного
синтеза программ
для параллельных
компьютеров.
-М., 1993 (Препринт/Институт
проблем управления).
2.
Харченко В.С.,
Лысенко И.В.,
Мельников В.А.
Оценка и обеспечение
живучести
информационно-вычислительных
и управляющих
систем технических
комплексов
критического
использования.
Зарубежная
радиоэлектроника.
1996. №1.
3.
Э.В. Евреинов.
Однородные
вычислительные
системы и среды.
–М. Радио и связь,
1981.
4.
А. Вильямс. Системное
программирование
в Windows
2000.
–СПб. Питер,
2001.
5.
С. Кейслер.
Проектирование
операционных
систем для
малых ЭВМ,-М.,
Мир, 1986.
6. А. Шоу.
Логическое
проектирование
операционных
систем.-М.,Мир,
1981.
7.
К.А.
Иыуду, С.А. Кривощеков,
Математические
модели отказоустойчивых
ВС. –М., МАИ, 1989.
8.
К.А. Иыуду. Надежность,
контроль и
диагностика
вычислительных
машин и систем.
-М., Высшая школа,1989.
9.
Л.П.
Глазунов и др.
Основы теории
надежности
автоматических
систем управления.
-М.,Энергоатомиздат,
1984.
10.
Р.Л. Лонер, Г.Н.
Уилкинсон,
Устойчивые
статистические
методы оценки
данных: Москва,
Машиностроение,
1984
11.
Артамонов Г.Т.,
Тюрин В.Д. Топология
сетей ЭВМ и
многопроцессорных
систем. — М.: Радио
и связь, 1991.
12.
Е.С. Вентцель,
Теория вероятностей.
М. НАУКА, 1969.
13.
В.Н. Агафонов.
Спецификация
программ. –М.,
Наука, 1987.
14.
А. Мешков, Ю.
Тихомиров.
Visual
C++ и
MFC.
–СПб. БХВ-Санкт-Петербург,
2001.
15.
Л.Б. Богуславский.
Управление
потоками данных
в сетях ЭВМ.
-М., Энергоатомиздат,
1984.
16.
В.И. Матов и др.
Теория проектирования
вычислительных
машин систем
и сетей. –М., МАИ,
1999.
17.
В.В. Липаев.
Надежность
программного
обеспечения
АСУ. -М., Энергоиздат,
1981.
17.
Д.И.
Козлов и др.,
Управление
космическими
аппаратами
зондирования
земли. – М.:
Машиностроение,
1998.
18.
Б. Страуструп.
Язык
программирования
С++. – Киев. ДиаСофт,
1993.
19.
А.Г. Додонов и
др. Введение
в теорию живучести
вычислительных
систем. – Киев,
Наук. Думка,
1990.
20.
Э.М. Мамедли,
Р.Я. Самедов,
Методы восстановления
вычислительного
процесса в
отказоустойчивых
цифровых систем
управления
реального
времени, Препринт
Института
Проблем Управления
Российской
Академии Наук,
Москва, 1998.
21.
Гуляев В.А., Додонов
А.Г. , Пелехов
С.Л. Организация
живучих вычислительных
структур.- Киев.:
Наукова Думка
, 1987
22.
Гришин Ю.П.,
Казаринов Ю.М.
Динамические
системы, устойчивые
к отказам.- М.:
Радио и связь,
1985.
23.
Транспьютеры.
Архитектура
и программное
обеспечение:
Пер. с англ. Под
ред. Г.Харпа.-М.:
Радио и связь,
1993
24.
TMS320C3x User's Guide, Texas Instruments, Inc., Dallas, Texas, 1994
25.
Дейтел Г., Введение
в операционные
системы. М, Мир,
1987.
26.
Дансмур М., Дейвис
Г. Операционная
система UNIX и
программирование
на языке Си. М.
"Радио и связь".
1989.
27.
К.Ю.
Богачев.
Операционные
системы реального
времени.
М.
2001.
28.
Артамонов Г.Т.
Топология
регулярных
вычислительных
сетей и сред.
— М.: Радио и связь,
1985.
29.
Мартин
Дж. Программирование
для вычислительных
систем реального
времени. – М.:
Наука, 1975.
Экономическое
обоснование
дипломных
проектов.
Методическое
пособие. –М.,
МАИ, 1991.
Руководство
Р2.2.013-94 Гигиенические
критерии оценки
условий труда
по показателям
вредности и
опасности
факторов
производственной
среды, тяжести
и напряженности
трудового
процесса.
Юдин
Е.Я., Белов С.В.
и др. Охрана
труда в машиностроении.
М.:
Машиностроение,
1983, 432с.
ГОСТ
27954 - 88 Видеомониторы
персональных
электронных
вычислительных
машины. Типы,
основные параметры,
общие технические
требования.
СаНПин
2.2.2.542-96. Гигиенические
требования
к видеодисплейным
терминалам
(ВДТ). персональным
электронно-вычислительным
машинам (ПЭВМ)
и организации
работы. М.:
Информационно-издательский
центр Госкомэпиднадзора
России, 1996. 65 с.
ГОСТ
12.1.006 - 84 Электромагнитные
поля радиочастот.
Допустимые
уровни на рабочих
местах и требования
к проведению
контроля. Изменение
к ГОСТ.
ГОСТ
12.1.005-88. Воздух рабочей
зоны. Общие
санитарно -
гигиенические
требования.
М.: Изд-во стандартов,
1990. 14 с.
СНиП
23-05-95 Естественное
и искусственное
освещение.
www.pcweek.ru
www.osp.ru
www.realtime-info.be
www.rtsoft-training.ru
www.ti.com
www.windriver.com
www.eonic.com
|
