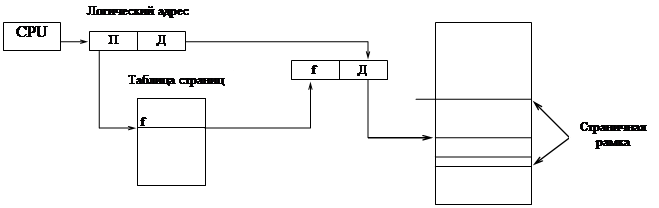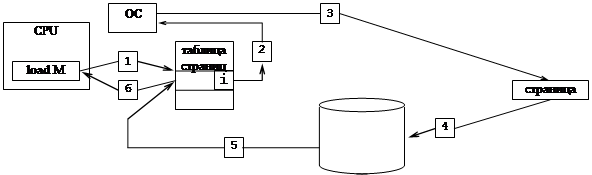| Дагестанский государственный университет.
Математический факультет.
Кафедра информатики и вычислительной техники.
Дипломная работа
на тему
«Разработка
операционных систем».
Руководитель:
Ханикалов Х.Б.
Выполнил:
студент 5 к. 4 гр.
Атаян А.П.
Махачкала 2000 г.
План работы:
Введение.
1. Управление процессами.
1.1. Понятие Процесс. Состояния процесса.
1.2. Планирование процессов. Понятие очереди.
1.3. Взаимодействие процессов. Пользовательский уровень.
2. Планирование процессора.
2.1. Критерии планирования процессора.
2.2. Стратегии планирования процессора.
2.2.1.Первый пришел - первый обслуживается FIFO. First come - first served (FCFS).
2.2.2. Стратегия - наиболее короткая работа! SJF.
2.2.3. Приоритетное планирование.
2.2.4. “Карусельная” стратегия планирования. RR-Round Robin.
2.2.5. Планирование с использованием многоуровневой очереди.(Multilevel queue scheduling).
2.2.6. Программирование с использованием многоуровневой очереди с обратными связями (multilevel feedback queue sheduling).
3. Управление невиртуальной памятью.
3.1. Своппинг. (swapping).
3.2. Смежное размещение процессов.
3.2.1. Однопрограммный режим.
3.2.2 Мультипрограммный режим с фиксированными границами.
3.2.3. Мультипрограммирование с переменными разделами. (multiprogramming with a variable number of tasks (MVT).
3.2.4. Мультипрограммирование с переменными разделами и уплотнением памяти.
3.2.5. Основные стратегии заполнения свободного раздела.
3.3. Страничная организация памяти.
3.3.1. Базовый метод.
3.3.2. Аппаратная поддержка страничной организации памяти.
3.4. Сегментная организация памяти.
3.4.1. Базовый метод сегментной организации памяти.
3.4.2. Разделение сегмента между несколькими процессами.
3.4.3. Фрагментация.
4. Управление виртуальной памятью.
4.1. Страничирование по запросу (demand paging).
4.2. Замещение страниц.
4.2.1. FIFO.
4.2.2. Оптимальный алгоритм.
4.2.3. LRU — алгоритм (least recently used).
5. Общие сведения.
5.1. Управление памятью.
5.2. Файловая система.
5.3. Управление процессами.
5.4. Межпроцессное взаимодействие.
5.5. Графический интерфейс пользователя.
5.6. Объектно-ориентированное ориентирование и операционные системы.
Заключение.
ВВЕДЕНИЕ.
Операционные системы, развиваясь вместе с ЭВМ, прошли длинный путь от простейших программ в машинных кодах длинной в несколько килобайт до монстров, написанных на языках высокого уровня, размер которых исчисляется десятками мегабайт. Такой значительный рост размера операционных систем обусловлен, главным образом, стремлением разработчиков ’украсить’ операционную систему, расширить ее возможности, добавить возможности, изначально несвойственные операционным системам, а также сделать интерфейс пользователя интуитивным. Все эти попытки дали свои результаты, и положительные, и отрицательные (усложнение настройки и программного интерфейса при упрощении пользовательского).
Реклама

На сегодняшний день на рынке программного обеспечения для IBM PC-совместимых компьютеров сосуществуют несколько семейств операционных систем. Однозадачные однопользовательские ОС MS-DOS и PC-DOS являются самыми распространенными ввиду своей простоты и ’неприхотливости’, большую роль здесь играет и то, что подавляющее большинство программ работает именно под их управлением. MS-DOS и PC-DOS характеризуются минимальным пользовательским и программным интерфейсами, в тоже время, работая со всевозможными программными оболочками, интегрированными средами (такими как Microsoft Windows или DESQview), создают комфортабельную среду для пользователя и программы.
ОС Microsoft Windows NT, ориентированная на работу в разнородных сетях, высоконадежна, однако, это достигнуто за счет частичной потери совместимости с MS-DOS.
Операционная система OS/2 стоит особняком: будучи полноправной многозадачной операционной системой со своим оригинальным графическим пользовательским и программным интерфейсами, она сохраняет совместимость с MS-DOS и PC-DOS (начиная с версии WARP 3.0 и с Microsoft Windows).
ОС UNIX - одна из старейших и наиболее простых операционных систем, изначально была рассчитана на разработку программ (для нее самой и не только) на мини-ЭВМ и позволяла без больших затрат труда программиста переносить программу из одной системы ЭВМ на другую. Неудивительно, что сейчас продается много различных вариантов мобильной операционной системы UNIX, таких как XENIX, UNIXWARE, SUN-OS, LINUX, BSD.
Теоретически все эти ОС работают примерно одинаково. Рассмотрим теорию операционных систем.
Операционная система - это программа, которая выполняет функции посредника между пользователем и компьютером.
ОС, выполняя роль посредника, служит двум целям:
1. эффективно использовать компьютерные ресурсы.
Реклама

2. создавать условия для эффективной работы пользователя
В качестве ресурсов компьютера обычно рассматривают:
1. время работы процессора
2. адресное пространство основной памяти
3. оборудование ввода – вывода
4. файлы, хранящиеся во внешней памяти
На рисунке приведены основные компоненты ОС как системы разделения ресурсов.
Таким образом, основные компоненты ОС:
1. управление процессами (распределяет ресурс - процессорное время);
2. управление памятью (распределяет ресурс - адресное пространство основной памяти);
3. управление устройствами (распределяет ресурсы) - оборудование ввода-вывода;
4. управление данными (распределяет ресурс - данные или файлы).
Функционирование компьютера после включения питания начинается с запуска программы первоначальной загрузки - Boot Track. Программа Boot Track инициализирует основные аппаратные блоки компьютера и регистры процессора (CPU), накопитель памяти, контроллеры периферийного оборудования. Затем загружается ядро ОС, то есть Operating System Kernel. Дальнейшее функционирование ОС осуществляется как реакция на события, происходящие в компьютере. Наступление того или иного события сигнализируется прерываниями - Interrupt. Источниками прерываний могут быть как аппаратура (HardWare), так и программы (SoftWare).
Аппаратура “сообщает” о прерывании асинхронно (в любой момент времени) путем пересылки в CPU через общую шину сигналов прерываний. Программа “сообщает” о прерывании путем выполнения операции System Call. Примеры событий, вызывающих прерывания:
1. попытка деления на 0
2. запрос на системное обслуживание
3. завершение операции ввода - вывода
4. неправильное обращение к памяти
Каждое прерывание обрабатывается соответственно обработчиком прерываний (Interrupt handler), входящим в состав ОС.
Главные функции механизма прерываний — это:
1. распознавание или классификация прерываний
2. передача управления соответственно обработчику прерываний
3. корректное возвращение к прерванной программе
Переход от прерываемой программы к обработчику и обратно должен выполняться как можно быстрей. Одним из быстрых методов является использование таблицы, содержащей перечень всех допустимых для компьютера прерываний и адреса соответствующих обработчиков. Такая таблица называется вектором прерываний (Interrupt vector) и хранится в начале адресного пространства основной памяти (UNIX/MS DOS).
Для корректного возвращения к прерванной программе перед передачей управления обработчику прерываний, содержимое регистров процессора запоминается либо в памяти с прямым доступом либо в системном стеке — System Stack.
Обычно запрещаются прерывания обработчика прерываний. Однако, в некоторых ОС прерывания снабжаются приоритетами, то есть работа обработчика прерывания с более низким приоритетом может быть прервана, если произошло прерывание с более высоким приоритетом.
1. Управление процессами.
Процесс — это программный модуль, выполняемый в CPU. Операционная система контролирует следующую деятельность, связанную с процессами:
1. создание и удаление процессов
2. планирование процессов
3. синхронизация процессов
4. коммуникация процессов
5. разрешение тупиковых ситуаций
1.1 Понятие Процесс. Состояния процесса.
Не следует смешивать понятия процесс и программа. Программа - это план действий, а процесс — это само действие. Понятие процесс включает:
1. программный код
2. данные
3. содержимое стека
4. содержимое адресного и других регистров CPU.
Таким образом, для одной программы могут быть созданы несколько процессов, в том случае, если с помощью одной программы в компьютере выполняется несколько несовпадающих последовательностей команд. За время существования процесс многократно изменяет свое состояние.
Различают следующие состояния процесса:
1. новый (new, процесс только что создан)
2. выполняемый (running, команды программы выполняются в CPU)
3. ожидающий (waiting, процесс ожидает завершения некоторого события, чаще всего операции ввода - вывода)
4. готовый (ready, процесс ожидает освобождения CPU)
5. завершенный (terminated, процесс завершил свою работу)
Переход из одного состояния в другое не может выполняться произвольным образом. На рисунке приведена типовая диаграмма переходов для состояний процессора.
| Выполняемый
|
ожидаемый, готовый
|
Выполняемый
|
| 
| прерывание.
сохраняется состояние П1
в PCB1
, активизируется PCB2
|
|
  |
|  готовый готовый
|
Выполняемый
|
готовый
|
| прерывание.
сохраняется состояние П3
в PCB3
, активизируется PCB1
|
|
| прерывание.
сохраняется состояние П2
в PCB2
, активизируется PCB3
|
|
|
| ожидаемый, готовый
|
Выполняемый
|
ожидаемый
|
| 
|
time
|
Каждый процесс представлен в операционной системе набором данных, называемых process control block . В process control block процесс описывается набором значений, параметров, характеризующих его текущее состояние и используемых операционной системой для управления прохождением процесса через компьютер.
На рисунке схематически показано, каким образом операционная система использует process control block для переключения процессора с одного процесса на другой.
| Заголовок
|
|    Процессы Процессы
|
первый
|
PCB7
|
PCB8
|
| в состоянии
|
|  “готовый” “готовый”
|
последний
|
| 
|
|  Очередь к Очередь к
|
первый
|
| магнитной
|
|  ленте ленте
|
последний
|
|   Очередь Очередь
|
первый
|
PCB3
|
PCB14
|
PCB6
|
| к
|
|  диску №1 диску №1
|
последний
|
| 
|
|    Очередь к Очередь к
|
первый
|
PCB5
|
| терминалу
|
| № 1
|
последний
|
1.2. Планирование процессов. Понятие очереди.
Система управления процессами обеспечивает прохождение процесса через компьютер. В зависимости от состояния процесса ему должен быть предоставить тот или иной ресурс. Например, новый процесс необходимо разместить в основной памяти, следовательно, ему необходимо выделить часть адресного пространства. Процессу в состоянии готовый должно быть предоставлено процессорное время. Выполняемый процесс может потребовать оборудование ввода - вывода и доступ к файлу.
Распределение процессов между имеющимися ресурсами носит название планирование процессов
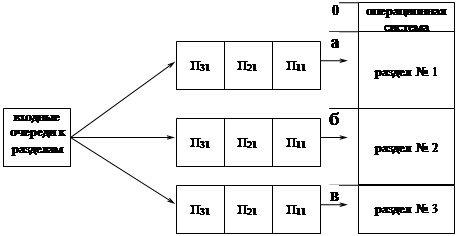
. Одним из методом планирования процессов, ориентированных на эффективную загрузку ресурсов, является метод очередей ресурсов. Новые процессы находятся во входной очереди, часто называемой очередью работ - заданий (job queue).
Входная очередь располагается во внешней памяти, во входной очереди процессы ожидают освобождения ресурса — адресного пространства основной памяти.
Готовые к выполнению процессы располагаются в основной памяти и связаны очередью готовых процессов или ready queue. Процессы в этой очереди ожидают освобождения ресурса процессорное время.
Процесс в состоянии ожидания завершения операции ввода - вывода находится в одной из очередей к оборудованию ввода - вывода, которая носит название devices queue.
При прохождении через компьютер процесс мигрирует между различными очередями под управлением программы, которая называется планировщик. (scheduler) Операционная система, обеспечивающая режим мультипрограммирования, обычно включает два планировщика — долгосрочный (long term scheduler) и краткосрочный (short term scheduler/CPU scheduler).
Основное отличие между долгосрочным и краткосрочным планировщиками заключается в частоте запуска, например: краткосрочный планировщик может запускаться каждые 100 мс, долгосрочный — один раз за несколько минут.
Долгосрочный планировщик решает, какой из процессов, находящихся во входной очереди, должен быть переведен в очередь готовых процессов в случае освобождения ресурсов памяти.
Долгосрочный планировщик выбирает процесс из входной очереди с целью создания неоднородной мультипрограммной смеси. Это означает, что в очереди готовых процессов должны находиться в разной пропорции как процессы, ориентированные на ввод - вывод, так и процессы, ориентированные на преимущественную работу с CPU.
Краткосрочный планировщик решает, какой из процессов, находящихся в очереди готовых процессов, должен быть передан на выполнение в CPU. В некоторых операционных системах долгосрочный планировщик может отсутствовать. Например, в системах разделения времени (time sharing system), каждый новый процесс сразу же помещается в основную память.
1.3. Взаимодействие процессов. Пользовательский уровень.
Совместно выполняемые процессы могут быть либо независимыми (independed processes), либо взаимодействующими (cooperating processes). Взаимодействие процессов часто понимается в смысле взаимного обмена данными через общий буфер данных.
Взаимодействие процессов удобно рассматривать в схеме производитель - потребитель (produces - consumer). Например, программа вывода на печать производит последовательность символов, которые потребляются драйвером принтера или компилятор производит ассемблерный текст, который затем потребляется ассемблером.
Для того чтобы процесс - производитель и процесс - потребитель могли заполнять совместно необходимый буфер, заполняемый процессом - производителем и потребляемым процессом - потребителем.
Буфер имеет фиксированные размеры, и, следовательно процессы могут находиться в состоянии ожидания, когда:
· буфер заполнен; ожидает процесс - производитель
· буфер пуст; ожидает процесс - потребитель
Буфер может предоставляться и поддерживаться самой ОС, например с помощью средств коммуникации процессов (IPC — Inter Process Communication), либо организовать прикладным программистом. При этом оба процесса используют общий участок памяти, например процесс - производитель и процесс - потребитель могут использовать следующие переменные:
Var n;
type item=...;
Var buffer:array[0..n-1] of item;
in, out:0..n-1
; где n - количество адресуемых элементов буфера, Item - имя типа элементов буфера, in, out - указатели, характеризующие заполнение буфера.
Буфер представлен в виде циклически связанного массива адресуемых элементов с двумя указателями - in, out. Указатель in содержит номер первого свободного элемента буфера, а out - первого занятого элемента буфера.
1. Пуст. in=out
. Очевидно, что буфер пуст в том случае, если выполняется это условие.
2. Буфер будет полностью заполнен, если выполняется условие
(in+1) mod n = out
Процесс - производитель должен выполнять процедуру записи в буфер типа
Repeat
...
продуцируется очередной элемент в Next p
...
while
(in+1) mod
n = out do
no_op;
buffer (in):=next p;
in:=(in+1) mod
n;
until
false
где Next p
- локальная переменная процесса - производителя, в которой хранится очередной продуцируемый элемент
no_op
- пустой оператор
Процесс - потребитель должен выполнять процедуру чтения из буфера типа
Repeat
while
in = out do
no_op;
next p := buffer (out);
out:=(out+1) mod
n;
...
потребляется очередной элемент из Next
...
until
false
2. Планирование процессора.
Краткосрочный планировщик выбирает процессы из очереди готовых процессов и передает их на выполнение в CPU. Существуют различные алгоритмы или стратегии решения этой задачи, отличающиеся отношением к критериям планирования.
2.1. Критерии планирования процессора.
Используются следующие критерии, позволяющие сравнивать алгоритмы краткосрочных планировщиков:
1. утилизация CPU (использование) CPU utilization. Утилизация CPU теоретически может находиться пределах от 0 до 100%. В реальных системах утилизация CPU колеблется в пределах 40% для легко загруженного CPU, 90% для тяжело загруженного CPU.
2. пропускная способность CPU throughput. Пропускная способность CPU может измеряться количеством процессов, которые выполняются в единицу времени.
3. время оборота (turnaround time) для некоторых процессов важным критерием является полное время выполнения, то есть интервал от момента появления процесса во входной очереди до момента его завершения. Это время названо временем оборота и включает время ожидания во входной очереди, время ожидания в очереди готовых процессов, время ожидания в очередях к оборудованию, время выполнения в процессоре и время ввода - вывода.
4. время ожидания (waiting time). Под временем ожидания понимается суммарное время нахождения процесса в очереди готовых процессов.
5. время отклика (response time) для сугубо интерактивных программ важным показателем является время отклика или время, прошедшее от момента попадания процесса во входную очередь до момента первого обращения к терминалу.
Очевидно, что простейшая стратегия краткосрочного планировщика должна быть направлена на максимизацию средних значений загруженности и пропускной способности, времени ожидания и времени отклика.
В ряде случаев используются сложные критерии, например, так называемый минимаксный критерий, то есть вместо простого критерия минимум среднего времени отклика используется следующий — минимум максимального времени отклика.
2.2. Стратегии планирования процессора.
2.2.1.Первый пришел - первый обслуживается FIFO. first come - first served (FCFS).
На рисунке схематически показано, каким образом операционная система использует process control block для переключения процессора с одного процесса на другой.
FCFS является наиболее простой стратегией планирования процессов и заключается в том, что процессор передается тому процессу, который раньше всех других его запросил.
Когда процесс попадает в очередь готовых процессов, process control block присоединяется к хвосту очереди.
Среднее время ожидания для стратегии FCFS часто весьма велико и зависит от порядка поступления процессов в очередь готовых процессов.
Пример № 1
Пусть три процесса попадают в очередь одновременно в момент 0 и имеют следующие значения времени последующего обслуживания в CPU.
вариант 1:
П1(24 мс)
П2(3 мс)
П3(3 мс)
вариант 2:
П2(3 мс)
П3(3 мс)
П1(24 мс)
На рисунке приведены диаграммы Ганга очереди готовых процессов
вариант 1:
| П1
|
П2
|
П3
|
WT=17 мс
|
| WT1
=0 мс
|
WT2
=24 мс
|
WT3
=27 мс
|
вариант 2:
| П2
|
П3
|
П1
|
WT=3 мс
|
| WT2
=0 мс
|
WT3
=3 мс
|
WT1
=6 мс
|
Стратегии FCFS присущ так называемый “эффект конвоя”. В том случае, когда в компьютере имеется один большой процесс и несколько малых, то все процессы собираются в начале очереди готовых процессов, а затем в очереди к оборудованию. Таким образом, “эффект конвоя” приводит к снижению загруженности как процессора, так и периферийного оборудования.
2.2.2. Стратегия - наиболее короткая работа! SJF.
SJF — Shortest Job First. Одним из методов борьбы с “эффектом конвоя” является стратегия, позволяющая процессу из очереди выполняться первым.
Пример № 2
Пусть четыре процесса одновременно попадают в очередь готовых процессов и имеют следующие значения времени последующего обслуживания
П1(6 мс)
П2(8 мс)
П3(7 мс)
П4(3 мс)
| П4
|
П1
|
П3
|
П2
|
WT=7 мс
|
| WT4
=0 мс
|
WT1
=3 мс
|
WT3
=9 мс
|
WT2
=16 мс
|
На рисунке приведена диаграмма Ганга, построенная в соответствии со стратегией SJF.
Легко посчитать, что при использовании FCFS - стратегии среднее время ожидания для тех же процессов равно 10.25 мс, таким образом стратегия SJF снижает время ожидания очереди. Наибольшая трудность в практической реализации SJF заключается в невозможности заранее определить величину времени последующего обслуживания.
Поэтому стратегия SJF часто применяется в долгосрочных планировщиках, обслуживающих пакетный режим. В этом случае вместо величины времени последующего обслуживания используется допустимое максимальное время выполнения задания, которое программист должен специфицировать перед отправкой задания в пакет.
2.2.3. Приоритетное планирование.
Описанные ранее стратегии могут рассматриваться как частные случаи стратегии приоритетного планирования. Эта стратегия предполагает, что каждому процессу приписывается приоритет, определяющий очередность предоставления ему CPU. Например, стратегия FCFS предполагает, что все процессы предполагает, что все процессы имеют одинаковые приоритеты, а стратегия SJF предполагает, что приоритет есть величина, обратная времени последующего обслуживания.
Приоритет — это целое положительное число, находящееся в некотором диапазоне, например от 0 до 7, от 0 до 4095. Будем считать, что чем меньше значение числа, тем выше приоритет процесса.
| Пример №3.
|
приоритет
|
| П1(10 мс)
|
3
|
| П2(1 мс)
|
1
|
| П3(2 мс)
|
3
|
| П4(1 мс)
|
4
|
| П5(5 мс)
|
2
|
На рисунке приведена диаграмма Ганга, располагающая процессы в очереди в соответствии со стратегией приоритетного планирования
| П2
|
П5
|
П1
|
П3
|
П4
|
| WT2
=0 мс
|
WT5
=1 мс
|
WT1
=6 мс
|
WT3
=16 мс
|
WT4
=18 мс
|
Приоритеты определяются исходя из совокупности внутренних и внешних по отношению к операционной системе факторов.
Внутренние факторы:
1. требования к памяти
2. количество открытых файлов
3. отношение среднего времени ввода - вывода к среднему времени CPU и так далее
Внешние факторы:
1. важность процесса
2. тип и величина файлов, используемых для оплаты
3. отделение, выполняющее работы и так далее
Внутренние факторы могут использоваться для автоматического назначения приоритетов самой операционной системой, а внешние для принудительного, с помощью оператора.
Главный недостаток приоритетного планирования заключается в возможности блокирования на неопределенно долгое время низкоприоритетных процессов.
Известен случай, когда в 1973 году в Массачусетском технологическом институте MIT при остановке компьютера IBM 7094 в очереди готовых процессов были обнаружены процессы, представленные в 1967 и все еще не выполненные.
Для устранения отмеченного недостатка используются следующие методы: процессы, время ожидания которых превышает фиксированную величину, например 15 минут, автоматически получают единичное приращение приоритета.
2.2.4. “Карусельная” стратегия планирования. RR-Round Robin.
Round Robin стратегия применяется в системах разделения времени. Определяется небольшой отрезок времени, названный квантом времени (10..100 мс). Очередь готовых процессов рассматривается как кольцевая. Процессы циклически перемещаются по очереди, получая CPU на время, равное одному кванту. Новый процесс добавляется в хвост очереди. Если процесс не завершился в пределах выделенного ему кванта времени, его работа принудительно прерывается, и он перемещается в хвост очереди.
Пример 4
П1(24 мс)
П2(3 мс)
П3(3 мс)
q=4 мс.
Диаграмма Ганга соответственно Round Robin стратегии для этого случая имеет вид:
| П1
|
П2
|
П3
|
П1
|
П1
|
П1
|
П1
|
П1
|
| WT1
=0 мс
|
7
|
10
|
14
|
18
|
22
|
26
|
30
|
Свойства Round Robin стратегии сильно зависят от величины временного кванта q. Чем больше временной квант, тем дольше Round Robin стратегия приближается к FCFS стратегии (для рассмотренного примера, если q>24 мс, то -> FCFS). При очень малых значениях временного кванта Round Robin стратегия называют разделением процессора — processor sharing. Теоретически это означает, что каждый из N процессов работает со своим собственным процессором, производительность процессора равна 1/N от производительности физического процессора.
2.2.5. ПЛАНИРОВАНИЕ с использованием многоуровневой очереди.(Multilevel queue scheduling).
Эта стратегия разработана для ситуации, когда процессы могут быть легко классифицированы на несколько групп, например, часто процессы разделяют на две группы: интерактивные (процессы переднего плана) и пакетные (фоновые).
Интерактивные и пакетные процессы имеют различные требования к краткосрочному планировщику, например по отношению ко времени отклика.
Стратегия многоуровневой очереди разделяет очередь готовых процессов на несколько очередей, в каждой из которых находятся процессы с одинаковыми свойствами, и каждый из которых может планироваться индивидуальной стратегией, например Round Robin стратегия для интерактивных процессов и FCFS для пакетных процессов.
Взаимодействие очередей осуществляется по следующим правилам: ни один процесс с более низким приоритетом не может быть запущен, пока не выполнятся процессы во всех очередях с более высоким приоритетом.
Работа процесса из очереди с более низким приоритетом может быть приостановлена, если в одной из очередей с более высоким приоритетом появился процесс.
2.2.6. Программирование с использованием многоуровневой очереди с обратными связями (multilevel feedback queue sheduling).
Обычная многоуровневая очередь не допускает перемещения процессов между очередями. Многоуровневая очередь с обратными связями предполагает, что процессы при определенных условиях могут перемещаться между очередями.
Процессы первоначально попадают в очередь 0, где каждому из них предоставляется квант времени, равный 8 мс. Те процессы, которые не успели выполниться в течение этого времени, перемещаются в очередь 1. Процессы из очереди 1 начинают обрабатываться только тогда, когда очередь 0 становиться пустой. Те процессы, которые не выполнились в очереди 1 (q=16 мс) перемещаются в очередь 2. Процессы из очереди 2 будут обрабатываться только в том случае, если становятся пустыми очереди 0 и 1.
Рассмотренная стратегия является наиболее универсальной и сочетает в себе свойства всех рассмотренных раньше стратегий.
1. FCFS
2. SJF
3. приоритетная
4. Round Robin
5. многоуровневая очередь
3. Управление невиртуальной памятью.
3.1. Своппинг. (swapping).
Своппингом называется метод управления памятью, основанный на том, что все процессы, участвующие в мультипрограммной обработке, хранятся во внешней памяти.
Процесс, которому выделен CPU, временно перемещается в основную память (swap in/roll in).
В случае прерывания работы процесса он перемещается обратно во внешнюю память (swap out/roll out).
Замечание: при своппинге из основной памяти во внешнюю (и обратно) перемещается вся программа, а не её отдельная часть.
Своппинг иногда используют при приоритетном планировании CPU. В этом случае с целью освобождения памяти для высокоприоритетных процессов, низкоприоритетные процессы перемещаются во внешнюю память.
Основное применение своппинг находит в системах разделения времени, где он используется одновременно с Round Robin стратегией планирования CPU.
В начале каждого временного кванта блок управления памятью выгружает из основной памяти процесс, работа которого была только что прервана, и загружает очередной выполненный процесс.
Метод своппинга влияет на величину временного кванта Round Robin стратегии.
Пример.
1. пусть очередной загружаемый в память процесс имеет размер 100Кб.
2. диск позволяет читать данные со скоростью 1 Мб в секунду
3. следовательно, 100 Кб могут быть загружены за 100 мс.
4. будем считать, что для первоначального подвода головки чтения - записи потребуется 8 мс
5. таким образом, операция своппинг займет 108 мс, а общее время своппинга - 216 мс.
Для эффективной загруженности процессора время своппинга должно быть существенно меньше времени счета. Следовательно, для рассмотренного примера квант времени должен быть существенно больше, чем 216 мс. Ясно, что это число значительно увеличится, если перемещаемый процесс имеет размер, например, 1 Мб.
Недостаток “чистого” своппинга в больших потерях времени на загрузку или выгрузку процессов. Поэтому в современных операционных системах используется модифицированные варианты своппинга.
Так, например, во многих версиях операционной системы UNIX своппинг включается только в том случае, когда количество процессов в памяти становится слишком большим.
3.2. Смежное размещение процессов.
Методы размещения процессов в основной памяти по отношению к расположению участков памяти, выделенных для одной и той же программы делят на два класса. Первый — метод смежного размещения, а второй — метод несмежного размещения.
Смежное размещение является простейшим и предполагает, что в памяти, начиная с некоторого начального адреса выделяется один непрерывный участок адресного пространства.
при несмежном размещении программа разбивается на множество частей, которые располагаются в различных, необязательно смежных участках адресного пространства.
3.2.1. Однопрограммный режим.
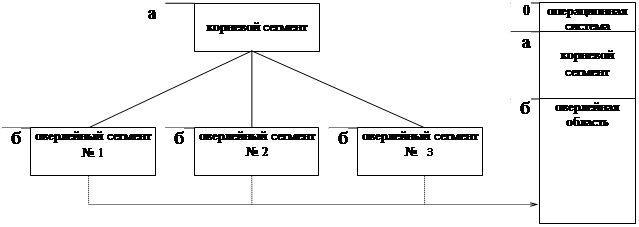
Рисунок иллюстрирует смежное размещение (contiguous allocation) одной программы в основной памяти.
При смежном размещении размер загружаемой программы ограничивается размером накопителя. Для того чтобы при смежном размещении загружать программы, размеры которых превышают размеры накопителя, используют метод оверлейных сегментов (overlay segments).
В программе, имеющей древовидную структуру, модули второго уровня работают сугубо последовательно, поэтому в памяти может находиться только один из них.
Оверлейную структуру программы и последовательность загрузки оверлейных сегментов планирует сам программист.
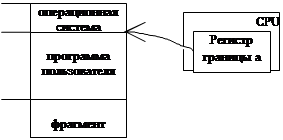
В процессе выполнения программы все её адреса не должны быть меньше числа а. В противном случае возможна запись какого-либо результата работы программы (поверх операционной системы) и уничтожение некоторых её частей. Защиту операционной системы в случае смежного размещения при однопрограммном режиме можно осуществить с помощью регистра границы.
Во время работы прикладной программы все адреса, генерируемые CPU, сравниваются с содержимым регистра границы. Если генерируется адрес меньше числа а, работа программы прерывается.
3.2.2 Мультипрограммный режим с ФИКСИРОВАННЫМИ границами.
Мультипрограммирование с фиксированными разделами (Multiprogramming with a fixed number of tasks) предполагает разделение адресного пространства на ряд разделов фиксированного раздела. В каждом разделе размещается один процесс.
Наиболее простой и наименее эффективный режим MFT соответствует случаю, когда трансляция программ осуществляется в абсолютных адресах для соответствующего раздела.
В этом случае, если соответствующий раздел занят, то процесс остается в очереди во внешней памяти даже в том случае, когда другие разделы свободны.
Уменьшить фрагментацию при мультипрограммировании с фиксированными разделами можно, если загрузочные модули получать в перемещаемых адресах. Такой модуль может быть загружен в любой свободный раздел после соответствующей настройки.
При мультипрограммировании с трансляцией в перемещаемых адресах имеются две причины фрагментации. Первая — размер загруженного процесса меньше размера, занимаемого разделом (внутренняя фрагментация), вторая — размер процесса в очереди больше размера свободного раздела, и этот раздел остается свободным (внешняя фрагментация).
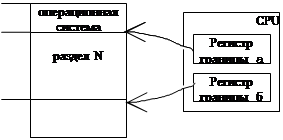
Для защиты памяти при мультипрограммировании с фиксированным разделами необходимы два регистра. Первый — регистр верхней границы (наименьший адрес), второй — регистр нижней границы (наибольший адрес).
Прежде чем программа в разделе N начнет выполняться, ее граничные адреса загружаются в соответствующие регистры. В процессе работы программы все формируемые ею адреса контролируются на удовлетворение неравенства
а < Адр. < б
При выходе любого адреса программы за отведенные ей границы, работа программы прерывается.
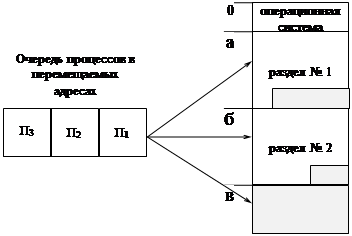
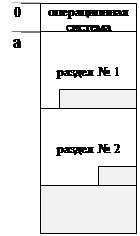
3.2.3. Мультипрограммирование с переменными разделами. (multiprogramming with a variable number of tasks (MVT).
Метод Multiprogramming with a Variable number of Tasks предполагает разделение памяти на разделы и использование загрузочных модулей в перемещаемых адресах, однако, границы разделов не фиксируются.
| 0
|
ОС
|
|  90 Кб 90 Кб
|
а
|
Раздел 1
|
|    П5 П5
|
П4
|
П3
|
П2
|
П1
|
Раздел 2
|
| 
|
Раздел 3
|
| Раздел 4
|
| 80 Кб
|
Как следует из рисунка, в начальной фазе отсутствует фрагментация, связанная с тем, что размер очередного процесса меньше размера, занимаемого этим процессом раздела. На этой фазе причиной фрагментации является несоответствие размера очередного процесса и оставшегося участка памяти. По мере завершения работы программы освобождаются отдельные разделы. В том случае, когда освобождаются смежные разделы, границы между ними удаляются и разделы объединяются.
| 0
|
ОС
|
| 90 Кб
|
а
|
Раздел 1
|
|  П7 П7
|
П6
|
П5
|
100 Кб
|
| Раздел 4
|
За счет объединения или слияния смежных разделов образуются большие фрагменты, в которых можно разместить большие программы из очереди.
Таким образом, на фазе повторного размещения действуют те же причины фрагментации, что и для метода MFT.
3.2.4. Мультипрограммирование с переменными разделами и уплотнением памяти.
Ясно, что метод Multiprogramming with a Variable number of Tasks порождает в памяти множество малых фрагментов, каждый из которых может быть недостаточен для размещения очередного процесса, однако суммарный размер фрагментов превышает размер этого процесса.
Уплотнением памяти называется перемещение всех занятых разделов по адресному пространству памяти. Таким образом, чтобы свободный фрагмент занимал одну связную область.
 На практике реализация уплотнения памяти сопряжена с усложнением операционной системы и обладает следующими недостатками: На практике реализация уплотнения памяти сопряжена с усложнением операционной системы и обладает следующими недостатками:
1. в тех случаях, когда мультипрограммная смесь неоднородна по отношению к размерам программ, возникает необходимость в частом уплотнении, что расходует ресурс процессорное время и компенсирует экономию ресурса памяти.
2. во время уплотнения все прикладные программы переводятся в состояние “ожидание”, что приводит к невозможности выполнения программ в реальном масштабе времени.
3.2.5. Основные стратегии заполнения свободного раздела.
Рассмотренные методы мультипрограммирования предполагают наличие входной очереди/очередей к разделам основной памяти.
В том случае, когда освобождается очередной раздел, операционная система должна выбрать один из процессов для размещения его в памяти. Алгоритм выбора может использовать одну из следующих трех стратегий:
1. стратегия наиболее подходящего (best fit strategy) выбирает процесс, которому в освободившемся разделе наиболее тесно (выигрыш в памяти).
2. стратегия первого подходящего (first fit strategy) выбирает первый процесс, который может разместить в освободившемся разделе.
3. стратегия наименее подходящего (last fit strategy) выбирает процесс, которому в освободившемся разделе наиболее свободно (в этом случае остающийся фрагмент часто достаточен для размещения еще одного процесса).
3.3. Страничная организация памяти.
Страничная организация памяти (paging) относится к методам несмежного размещения процессов в основной памяти.
Основное достоинство страничной организации памяти заключается в том, что она позволяет свести к минимуму общую фрагментацию за счет полного устранения внешней фрагментации и минимизации внутренней фрагментации.
3.3.1. Базовый метод.
Адресное пространство основной и внешней памяти разбивают на блоки фиксированного размера, называемые страничные рамки (frames). Логическое адресное пространство программы также разбивается на блоки фиксированного размера, называемых страницами (pages). Размеры страничных рамок и страниц совпадают. Процесс загружается в память постранично, причем каждая страница помещается в любую свободную страничную рамку основной памяти.
Каждый адрес, генерируемый процессором, состоит из двух частей: П - номер страницы (page number) и Д - смещение в пределах страницы (off set). Номер страницы может использоваться как индекс для таблицы страниц (page table).
 Таблица страниц содержит начальные адреса f всех страничных рамок, в которых размещена программа. Физический адрес определяется путем сложения начального адреса страничной рамки f и смещения Д. Таблица страниц содержит начальные адреса f всех страничных рамок, в которых размещена программа. Физический адрес определяется путем сложения начального адреса страничной рамки f и смещения Д.
| Вторичная память
|
Таблица
страниц
|
Основная память
|
| программы А
|
0.
|
| стр. 0
|
0.
|
1
|
1.
|
стр. 0
|
| программа
|
стр. 1
|
1.
|
3
|
2.
|
| А
|
стр. 2
|
2.
|
4
|
3.
|
стр. 1
|
| стр. 3
|
0.
|
7
|
0.
|
стр. 2
|
|  
|
0.
|
|
|
1.
|
| 2.
|
стр. 3
|
Рисунок показывает, что страничная организация памяти полностью исключает внешнюю фрагментацию. Внутренняя фрагментация не превышает величины page_size-Q_Elem, где page_size — размер страничной рамки, а Q_Elem — минимальный адресуемый элемент основной памяти.
Для ускорения вычисления физического адреса операцию суммирования заменяют операцией конкатенации.
| старшие разряды
|
младшие разряды
|
| 2n+1
|
2n
|
f
|
| 2n-1
|
2n
|
Д
|
На рисунке заштрихованы незаполненные нулевые разряды. Для того чтобы операция конкатенации была возможна, необходимо, чтобы базовые адреса страничных рамок располагались только в старших разрядах (2n+1
), а следующие — только младших разрядов (20
, 21
, 22
).
Например, при n=9 базовые адреса страничных рамок — это следующий ряд: 512, 1024, 1536. Следовательно, размер страничной рамки равен 512 байт.
В современных операционных системах типичный размер страницы составляет 2 Кб или 4 Кб.
Каждая операционная система поддерживает свой собственный метод работы с таблице страниц. Обычно за каждым процессом, находящимся в основной памяти, закреплена отдельная таблица страниц. В этом случае указатель на таблицу страниц хранится в PCB соответствующего процесса.
3.3.2. Аппаратная поддержка страничной организации памяти.
Преобразование логического адреса в физические осуществляется для каждого адреса, генерируемого процессором, поэтому часто для ускорения этого процесса применяются аппаратные методы. На рисунке приведена схема, иллюстрирующая метод, использующий ассоциативные регистры (associative registers).
Каждый ассоциативный регистр кроме операций чтения - записи может обрабатывать операцию сравнения кода, поступающего на его вход с частью кода, хранимого в регистре. Матрица ассоциативных регистров хранит часть таблицы страниц. Номер страницы П подается одновременно на входы всех ассоциативных регистров, которые параллельно выполняют операцию сравнения. На выходе матрицы ассоциативных регистров образуется начальный адрес страничной рамки f того регистра, в котором про-
изошло совпадение кода.
В том случае, если требуемый номер страницы находится в таблице страниц, то есть ни в одном из ассоциативных регистров не произошло совпадение, происходит обращение к таблице страниц, находится искомый
номер страничной рамки, а найденная строка таблицы страниц переписывается в один из ассоциативных регистров.
Защита страничной памяти основана на контроле уровня доступа к каждой странице, возможны следующие уровни доступа:
1. только чтение
2. и чтение и запись
3. только выполнение
В этом случае каждая страница снабжается трехбитным кодом уровня доступа. При трансформации логического адреса в физический сравнивается значение кода разрешенного уровня доступа с фактически требуемым. При их несовпадении работа программы прерывается.
3.4. Сегментная организация памяти.
Страничная организация памяти предполагает, что разделение программы на страницы осуществляет операционная система и это невидимо для прикладного программиста. Большинство технологий программирования также предполагает разделение программы на множество логических частей — подпрограммы, процедуры, модули и так далее.
Сегментная организация памяти представляет собой метод несмежного размещения, при котором программа разбивается на части (сегменты) на этапе программирования. Отдельный сегмент хранит отдельную логическую часть программы: программный модуль или структуру данных (массив), стек, таблица и так далее.
3.4.1. Базовый метод сегментной организации памяти.
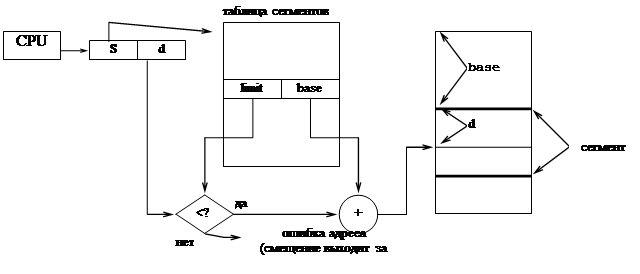
Обычно сегменты формируются компилятором, а на этапе загрузки им присваиваются идентифицирующие номера. Таким образом, логический адрес при сегментной организации памяти состоит из двух частей: S и d, где S — номер сегмента, а d — смещение в пределах сегмента.
Трансформация логического адреса в физический осуществляется с помощью таблицы сегментов (segment table).
Количество строк таблицы сегментов равно количеству сегментов программы: S, limit, base. Limit — размер сегмента, base — начальный адрес сегмента в памяти.
Номер сегмента S используется в качестве индекса для таблицы сегментов. С помощью таблицы сегментов определяется его начальный адрес base в основной памяти. Значение limit используется для защиты памяти. Смещение d должно удовлетворять неравенству 0<d<limit. В случае выхода смещения за границы сегмента работа программы прерывается. Физический адрес определяется как сумма начального адреса base и смещения d. В том случае, если таблица сегментов имеет значительные размеры, она располагается в основной памяти, а её начальный адрес и длина хранятся в специальных регистрах STBR (segment table base register), STLR (segment table length register). Для ускорения трансформации логического адреса в физический операция суммирования часто заменяется операцией конкатенации (для этого необходимо, чтобы начальные адреса сегментов были кратны некоторому числу 2n
).Таблица сегментов (или её часть) располагается в ассоциативной памяти.
Защита сегментной памяти основана на контроле уровня доступа к каждому сегменту. Например, сегменты, содержащие только код, могут быть помещены как доступные только для чтения или выполнения, а сегменты, содержащие данные, помечают как доступные для чтения и записи.
3.4.2. Разделение сегмента между НЕСКОЛЬКИМИ процессами.
Поскольку сегмент является логически завершенным программным модулем, он может использоваться различными процессами. Сегмент называется разделяемым, когда его начальный адрес и размер указаны в двух и более таблицах сегментов. Например, два процесса могут использовать подпрограмму Sqrt, которая хранится в виде одной физической копии.
На рисунке приведен пример, иллюстрирующий использование разделяемого текстового редактора.
| таблица сегментов процесса 1
|
основная память
|
| limit
|
base
|
| 0. 
|
25286
|
43062
|
43062
|
| 1.  
|
4425
|
68348
|
68348
|
редактор
|
| 2.
|
данные
|
| 72773
|
1
|
| 
|
таблица сегментов процесса 2
|
90003
|
| limit
|
base
|
данные
|
| 0.
|
25286
|
43062
|
98553
|
2
|
| 1.
|
8550
|
90003
|
| 2.
|
3.4.3. Фрагментация.
Программа во входной очереди загружается в память посегментно в любые свободные разделы основной памяти. При этом, как правило, используются стратегии best fit и first fit. Сегментной организации памяти присущи как внутренняя, так и внешняя фрагментации. Внутренняя фрагментация образуется вследствие того, что размер загружаемого сегмента меньше размера имеющегося свободного раздела, а внешняя вследствие того, что отсутствует участок памяти подходящего размера. Внешняя фрагментация означает, что часть процесса остается незагруженной, и его выполнение в какой–то момент времени должно быть приостановлено.
Очень часто сегментация комбинируется со страничированием. Это позволяет сочетать преимущества обоих методов. Низкая фрагментация при страничной организации и естественное расчленение программы по сегментам.
Сегментация и страничирование используется об операционных системах OS/2 для управления компьютерами.
4. Управление виртуальной памятью.
Все методы управления памятью имеют одну и ту же цель — хранить в памяти мультипрограммную смесь, необходимую для мультипрограммирования. Рассмотренные ранее методы предполагали, что вся программа перед выполнением должна быть размещена в основной памяти. Виртуальная память — это технология, которая позволяет выполнять процесс, который может только частично располагаться в основной памяти. Таким образом, виртуальная память позволяет выполнять программы, размеры которых превышают размеры физического адресного пространства.
4.1. Страничирование по запросу (demand paging).
Виртуальная память чаще всего реализуется на базе страничной организации памяти, совмещенной со своппингом страниц.
Своппингу подвергаются только те страницы, которые необходимы процессору. Таким образом, страничирование по запросу означает
1. программа может выполняться CPU, когда часть страниц находится в основной памяти, а часть — во внешней.
2. в процессе выполнения новая страница не перемещается в основную память до тех пор, пока в ней не возникла необходимость.
| логическая
|
таблица
|
физическая
|
вторичная
|
| память
|
страниц
|
память
|
память
|
| 0.
|
A.
|
0.
|
4
|
v
|
0
|
| 1.
|
B.
|
1.
|
i
|
1
|
A.
|
| 2.
|
C.
|
2.
|
6
|
v
|
2
|
B.
|
| 3.
|
D.
|
3.
|
i
|
3
|
C.
|
| 4.
|
E.
|
4.
|
i
|
4
|
A
|
D.
|
| 5.
|
F.
|
5.
|
8
|
v
|
5
|
E.
|
| 6.
|
G.
|
6.
|
i
|
6
|
C
|
F.
|
| 7.
|
H.
|
7.
|
i
|
7
|
| 8
|
F
|
| 15
|
Для учёта распределения страниц между внешней и основной памятью каждая строка таблицы страниц дополняется битом местонахождения страницы. Valid/invalid bit.
В том случае, если процессор пытается использовать страницу, помеченную значением invalid, возникает событие, называемое страничная недостаточность (paging fault).
Страничная недостаточность вызывает прерывание выполнения программы и передачу управления операционной системе. Реакция операционной системы на страничную недостаточность заключается в том, что необходимая страница загружается в основную память.
На рисунке показаны основные этапы обработки события «страничная недостаточность».
1. процессор, прежде чем осуществлять преобразование логического адреса в физический, проверяет значение бита местонахождения необходимой страницы*
.
2. если значение бита invalid, то процесс прерывается и управление передается операционной системе для обработки события страничная недостаточность.
3. разыскивается необходимая страница во вторичной памяти и свободная страничная рамка в основной**
.
4. требуемая страница загружается в выбранную страничную рамку.
5. после завершения операции загрузки редактируется соответствующая строка таблицы страниц, в которую вносится базовый адрес и valid значение бита местонахождения.
6. управление передается прерванному процессу
4.2. Замещение страниц.
В процессе обработки страничной недостаточности операционная система может обнаружить, что все страничные рамки основной памяти заняты, и, следовательно, невозможно загрузить требуемую страницу. В этом случае возможны следующие режимы: приостановка прерванного процесса, уменьшение на единицу количества процессов мультипрограммной смеси для освобождения всех ею занимаемых страничных рамок, использование метода замещения страниц.
Метод замещения страниц означает, что в основной памяти выбирается наименее важная/используемая страница, называется страница — жертва (victim page), которая временно перемещается в swap space, а на её место загружается страница, вызываемая страничной недостаточностью.
Обработка страничной недостаточности с учетом замещения осуществляется по следующему алгоритму:
1. определяется местонахождение страницы путем анализа бита местонахождения
2. если значение бита invalid, то разыскивается свободная страничная рамка.
2.1.если имеется свободная страничная рамка, то она используется.
2.2.если свободной страничной рамки нет, то используется алгоритм замещения, который выбирает страницу — жертву.
2.3.страница — жертва перемещается в swap space и редактируется таблица страниц.
3. требуемая страница загружается на место страницы — жертвы и соответствующим образом редактируется таблица страниц.
Управление передается прерванному процессу. Приведенный алгоритм замещения требует двухстраничных перемещений.
1. страница - жертва перемещается в swap space.
2. требуемая страница перемещается в освободившуюся страничную рамку.
Страницу - жертву можно не копировать в swap space в том случае, если за время, прошедшее от последнего перемещения её содержимое не модифицировалось. В этом случае время замещения уменьшается примерно вдвое.
Для учета факта модификации страницы в таблицу страниц вводится дополнительный бит, который меняет своё значение на противоположное в том случае, если содержимое страницы изменилось.
Для практического использования метода страничирования по запросу необходимо разработать два алгоритма.
1. алгоритм распределения страничных рамок (from allocation algorithm).
2. алгоритм замещения страниц (page replacement algorithm).
Алгоритм распределения страничных рамок решает, сколько страничных рамок в основной памяти выделить каждому из процессов мультипрограммной смеси.
Алгоритм замещения страниц решает, какую из страниц выбрать в качестве жертвы.
4.2.1. FIFO.
Наиболее простым алгоритмом замещения страниц является алгоритм FIFO. Этот алгоритм ассоциирует с каждой страницей время, когда эта страница была помещена в память. Для замещения выбирается наиболее старая страница.
|
|
| 7
|
0
|
1
|
2
|
0
|
3
|
0
|
4
|
2
|
3
|
0
|
3
|
2
|
1
|
| 7
|
7
|
7
|
2
|
2
|
2
|
2
|
4
|
4
|
4
|
0
|
0
|
0
|
0
|
| 0
|
0
|
0
|
0
|
3
|
3
|
3
|
2
|
2
|
2
|
2
|
2
|
1
|
| 1
|
1
|
1
|
1
|
0
|
0
|
0
|
3
|
3
|
3
|
3
|
3
|
| страничные рамки. 11 замещений, 14 ссылок
|
|
|
Учет времени необязателен, когда все страницы в памяти связаны в FIFO-очередь, а каждая помещаемая в память страница добавляется в хвост очереди.
Алгоритм учитывает только время нахождения страницы в памяти, но не учитывает используемость страницы. Например, первые страницы программы могут содержать переменные, используемые на протяжении работы всей программы. Это приводит к немедленному возвращению к только что замещенной странице.
4.2.2. Оптимальный алгоритм.
Этот алгоритм имеет наилучшее соотношение количества замещенных страниц к количеству ссылок. Алгоритм строится по следующему принципу: замещается та страница, на которую нет ссылки на протяжении наиболее длительного периода времени. Для реализации этого алгоритма необходимо каждый раз сканировать весь поток ссылок, поэтому он нереализуем на практике и используется для оценки реально работающих алгоритмов.
4.2.3. LRU — алгоритм (least recently used).
Алгоритм выбирает для замещения ту страницу, на которую не было ссылки на протяжении наиболее длинного периода времени. Least recently used ассоциирует с каждой страницей время последнего использования этой страницы. Для замещения выбирается та страница, которая дольше всех не использовалась. Этот алгоритм наиболее часто используется в системах страничирования по запросу. Обычно применяется два подхода при внедрении этого алгоритма.
1. подход на основе логических часов (счетчика)
2. подход на основе стека номеров страниц
1. ассоциируют с каждой строкой таблицы поле “время использования” а в CPU добавляются логические часы. Логические часы увеличивают своё значение при каждом обращении к памяти. Каждый раз, когда осуществляется ссылка на страницу, значение регистра логических часов копируется в поле “время использования”. Заменяется страница с наименьшим значением в отмеченном поле путем сканирования всей таблицы страниц. Сканирование отсутствует при использовании подхода на основе стека.
2. стек номеров страниц хранит номера страниц, упорядоченных в соответствии с историей их использования, на вершине стека располагается только что использованная страница, а на дне least recently used страница. Как только осуществляется ссылка на страницу, она перемещается на вершину стека, а номера всех страниц сдвигаются вниз.
5. ОБЩИЕ СВЕДЕНИЯ
Теперь, после ознакомления с теорией операционных систем, рассмотрим вкратце каждую из выше перечисленных*
. Все эти операционные системы работают в многозадачном однопользовательском режиме работы (UNIX также поддерживает и многопользовательский режим); поддерживают иерархическую файловую систему, межпроцессное взаимодействие, встроенные средства отладки программ, стандартизируют программный интерфейс для многих внешних устройств, обычно трактуя их как файлы с последовательным доступом.
5.1. УПРАВЛЕНИЕ ПАМЯТЬЮ.
Все рассматриваемые операционные системы обеспечивают выделение участка памяти для нужд программы, изменение его размера и освобождение. По-разному поддерживается концепция виртуальной памяти.
Операционная система OS/2 использует страничную модель памяти, то есть программа получает память порциями по 4 кб; подкачка также осуществляется порциями по 4 кб. Программа не может управлять процессом подкачки.
Важной особенностью OS/2 является возможность создания специальных разделяемых областей памяти, которые могут использоваться для межпроцессного взаимодействия (см. гл. межпроцессное взаимодействие).
Microsoft Windows использует сегментированную модель память. Исторически сложилось так, что ОС (а, точнее, программная оболочка) Microsoft Windows до разработки процессора 80386 работала в реальном режиме (’real mode’) и защищенном режиме 80286-го процессора (’standart mode’). В реальном режиме механизм подкачки не использовался; при наличии 286-го процессора ОС позволяла выгружать на диск только MS-DOS-освские программы. С появлением процессора 80386 и использованием его защищенного режима, возможности использования виртуальной памяти резко расширились: появилась возможность выгрузить на диск любой сегмент памяти компьютера. С помощью системных вызовов, программа пользователя может управлять многими нюансами распределения памяти: разрешением на выгрузку страницы, сборкой мусора, перемещением объектов в памяти.
5.2. ФАЙЛОВАЯ СИСТЕМА.
Все системы поддерживают следующие элементы иерархических файловых систем: обычные файлы, каталоги, специальные байт-ориентированные и блок-ориентированные файлы. Файл является массивом байтов (блоков фиксированной длины). Каталоги обеспечивают связь между именами файлов и собственно файлами. Каждый элемент каталога содержит имя файла и ссылку на конкретный файл. Для именования файлов используются корневой и текущий каталоги. Имя файла состоит из последовательности компонентов - локальных имен, разделенных символами '\' (В операционной системе UNIX - '/').
ОС UNIX характеризуется единственной однородной файловой системой на один или несколько компьютеров. В Microsoft Windows и OS/2 файловые системы ассоциируются с носителями (посредством логических имен - букв латинского алфавита).
Операционная система OS/2, кроме того, поддерживает свою файловую систему - HPFS (High Performance File System - высокопроизводительная файловая система), характеризующаяся хранением имен файлов и каталогов в виде B-дерева.
Внешние устройства (такие как терминал, принтер) так же часто представляются как файлы для упрощения работы с ними.
Операционные системы предоставляют следующие системные вызовы: запрос на смену и получение имени текущего каталога; создание, открытие, закрытие, удаление, переименование и получение информации о файле или каталоге, позиционирование в них.
Все рассматриваемые операционные системы поддерживают операции блокировки файла для защиты доступа к нему со стороны других процессов в многозадачной среде.
5.3. УПРАВЛЕНИЕ ПРОЦЕССАМИ.
Единицей управления и потребления ресурсов в многозадачной системе является процесс. В частности, ввод-вывод выполняется синхронно, и процесс приостанавливается до его завершения. Если требуется продолжить выполнение процесса параллельно с инициированным им вводом-выводом, нужно предварительно породить другой процесс для реализации ввода-вывода. Microsoft Windows, OS/2 и UNIX предоставляют сходные системные вызовы для обслуживания и управления процессами ('сессия' в OS/2): порождение, уничтожение.
OS/2 предоставляет гораздо более широкий спектр системных вызовов для управления процессами. В OS/2 существуют три вида процессов: нити (цепи или треды), 'настоящие' процессы и экранные группы. Экранные группы - наиболее независимый тип процессов. Каждая экранная группа имеет свою собственную виртуальную консоль, адресное пространство, открытые файлы, очереди и каналы (см. ниже). Внутри экранной группы могут находится один или более 'настоящих' процессов, у каждого из которых могут быть свои открытые файлы и свое адресное пространство. Нити - самый простой класс процессов, они имеют только свое собственное адресное пространство, а все остальные ресурсы наследуют от породившего их 'настоящего' процесса.
В операционной системе OS/2 планировщик задач может выделять 'настоящим' процессам кванты времени по двум алгоритмам: динамического и абсолютного приоритетов. Алгоритм динамического приоритета выражается: система подсчитывает интенсивность операций ввода-вывода, использования процессорного времени, и по ним определяет количество квантов времени, предоставляемых процессу. При использовании абсолютных приоритетов ОС распределяет кванты времени согласно числовым значениям, заданным при старте процесса. Процесс может изменять свой приоритет в небольших пределах с помощью системной функции.
В Microsoft Windows планировщика задач распределяет кванты процессорного времени аналогично алгоритму абсолютных приоритетов в операционной системе OS/2. Программа никак не может повлиять на количество предоставляемого ей процессорного времени.
В операционной системе UNIX алгоритм работы планировщика задач зависит от реализации.
5.4. МЕЖПРОЦЕССНОЕ ВЗАИМОДЕЙСТВИЕ.
Операционные системы используют разные термины для определения способов межпроцессного взаимодействия.
Единственным видом межпроцессного взаимодействия в ОС UNIX является сигнальный механизм. Посредством сигналов передается информация о необходимости завершения процесса, об ошибке в программе пользователя, об исключительных ситуациях или завершении порожденного процесса. Сигнал генерируется, когда происходит событие, вызывающее данный сигнал. Одно и то же событие может вызвать посылку сигнала нескольким процессорам. На каждый сигнал, определенный в системе, процесс должен иметь реакцию - действие, которое он выполняет при получении сигнала.
Операционная система OS/2 предоставляет три типа межпроцессного взаимодействия: каналы, очереди и семафоры.
Канал представляет собой кольцевой буфер с двумя указателями - начала и конца; используется для перенаправления ввода-вывода и стандартных файлов между процессами. Только два процесса могут читать или писать в канал - сервер и клиент.
Очередь - это упорядоченный список из 32-битных значений, интерпретируемых процессом по контексту (это может быть целое, указатель на общую область памяти или просто флаг). Любой процесс может прочесть информацию из канала в любом порядке или записать туда любую информацию.
Семафор - это объект, имеющий два устойчивых состояния (рабочее и нерабочее) и используемый для синхронизации исполнения процессов. Существует несколько видов семафоров: семафор событий, взаимного исключения, взаимного ожидания и именованный.
Когда семафор событий находится в нерабочем состоянии, операционная система блокирует исполнение всех процессов, которые запрашивают состояние семафора.
Семафоры взаимного исключения предотвращают возникновение тупиков при обращении к разделяемым ресурсам. Операционная система блокирует доступ к разделяемому ресурсу до тех пор, пока соответствующий семафор не будет свободен. При использовании разделяемого ресурса система устанавливает значение семафора в рабочее состояние, показывая тем самым, что ресурс занят.
Семафор взаимного ожидания представляет собой пакет из семафоров взаимного исключения или семафоров событий. Система может приостановить процесс до тех пор, пока один или все семафоры внутри именованного семафора не окажутся в состоянии 'свободен'(в зависимости от потребности процесса).
Реакция на именованный семафор зависит от процессов, совместно использующих его.
В операционных системах OS/2 и Microsoft Windows существует специальный механизм для взаимодействия процессов в реальном масштабе времени. Этот механизм называется DDE (Dynamic Data Exchange - динамический обмен данными). Он стандартизирует процесс обмена командами, сообщениями и объектами для обработки между задачами. Наиболее распространенные действия, для которых используются DDE - печать.
Другим интерфейсом для обмена данными является OLE (Object Linking and Embedding - объектное связывание со встраиванием). Этот интерфейс позволяет хранить объекты, созданные одной программой, в объектах, созданных другой программой, а также редактировать (печатать) их без нарушения целостности информации и связей.
Одним из наиболее простых, удобных и интуитивных интерфейсов межпрограммного взаимодействия является буфер обмена - Clipboard. Буфер обмена может содержать в себе один информационный объект - кусок текста, картинку и т.д. С помощью системного вызова процесс может получить копию информации, содержащейся в буфере обмена или сам поместить объект в буфер, при этом старое содержимое буфера теряется. Таким образом программы получают простой, но эффективный способ обмена информацией в процессе своей работы.
Операционная система UNIX не предоставляет этого способа обмена информацией, Microsoft Windows же позволяет задачам обмениваться информацией таким образом, даже в DOS-сессиях.
5.5. ГРАФИЧЕСКИЙ ИНТЕРФЕЙС ПОЛЬЗОВАТЕЛЯ.
Графический интерфейс пользователя изначально был несвойственен неигровым программам, однако будучи призванным облегчить общение пользователя с компьютером и программой, хорошо прижился на IBM PC и стал неотъемлемой частью любой уважающей себя операционной системы.
Оболочка Microsoft Windows не была изначально операционной системой, да и сейчас не может считаться в полноценной операционной системой, так как она существует ’поверх’ операционной системы типа MS-DOS. Она возникла в виде стандартизатора графического интерфейса и прижилась исключительно потому, что пользователь хотел видеть программу, с которой ему часто приходится работать красивой, практичной, удобной и легкой в освоении и использовании.
Для ОС UNIX также был создан специальный графический интерфейс - X-Windows; промышленный гигант - фирма IBM выпустила вместе с операционной системой OS/2 свой вариант графического интерфейса пользователя (GUI - Graphics User Interface) - Presentation Manager.
Функции, используемые программой пользователя при работе с графическим пользовательским интерфейсом схожи, как и сами интерфейсы.
После запуска программа обычно создает одно окно, с которым она ассоциируется и работает. Пользователь, работая с окном и находящимися в нем объектами, заставляет операционную систему (или программную оболочку) посылать программе сообщения, активизирующие необходимые пользователю возможности программы. В процессе работы программа также может создавать другие окна (выбора, диалога, обрабатываемого файла и др.) и получать от них сообщения, таким образом стандартизируется часто используемые элементы диалога с пользователем.
Операционная система (оболочка), ориентированная на графический интерфейс пользователя, предоставляет не только функции, поддерживающие ввод-вывод, но и широкий спектр системных вызовов, позволяющих использовать различные графические примитивы: от самых простых (точки, линии, дуги) до самых сложных (области, окна, курсоры). Основным преимуществом использования графического интерфейса операционной системы является то, что с помощью него программа может создавать графические изображения, которые будут выглядеть одинаково на всех устройствах, поддерживаемых операционной системой (принцип What We See Is What We Get - что видим, то и получаем).
Большое внимание в графическом интерфейсе операционной системы обычно уделяется шрифтам. Исторически сложилось так, что первыми и долгое время единственными шрифтами для компьютеров оставались растровые (точечно-матричные) шрифты. Такие шрифты занимали малый объем памяти, однако, их невозможно было вращать, наклонять, уменьшать, без искажений, а увеличивать можно было только в целое число раз. С появлением графического интерфейса, операционные системы стали предоставлять системные вызовы для поддержки использования векторных шрифтов, которые не только легко масштабируются, меняют наклон и толщину, но и выглядят одинаково на всех устройствах, поддерживаемых операционной системой. Каждая операционная система поддерживает свой стандарт векторных шрифтов (TrueType для Microsoft Windows; Adobe Type Manager для OS/2; GhostScript для LINUX).
5.6. ОБЪЕКТНО-ОРИЕНТИРОВАННОЕ ПРОГРАММИРОВАНИЕ И ОПЕРАЦИОННЫЕ СИСТЕМЫ.
Использование объектно-ориентированного подхода к разработке программ не могло не оказать своего влияния на операционную систему. Графический интерфейс пользователя и программный интерфейс операционной системы начали также использовать объектно-ориентированный подход.
Наиболее развитый объектно-ориентированный программный интерфейс имеет операционная система OS/2. Все графические и программные примитивы представляются в ней в виде объектов (память, дисплей, принтер, папка, звуковая карта, дисковод - все это - объекты).Однако, объектно-ориентированный подход неэффективно использует ресурсы памяти, поэтому использование операционной системы OS/2 на компьютерах с 4 мб памяти (на одном из таких писался данный реферат) затруднительно.
ЗАКЛЮЧЕНИЕ.
Современная операционная система - сложный комплекс программных средств, предоставляющих пользователю не только стандартизированный ввод-вывод и управление программами, но и упрощающий работу с компьютером. Программный интерфейс операционных систем позволяет уменьшить размер конкретной программы, упростить ее работу со всеми компонентами вычислительной системы.
Любая фирма, планирующая разработать удобную, мощную и популярную операционную систему должна исходить из всех необходимых факторов. Перечислю лишь некоторые из них:
- ОС, отвечающая требованиям современной аппаратуры.
- ОС, совместимая с другими операционными системами.
- Многозадачная (мультизадачная) ОС.
- Неплохо защищённая ОС.
- Удобная и надёжная ОС.
Операционная система, кроме того, должна управлять электропитанием процессора, а также периферийных устройств, подключенных к системе. Функционирование ОС должно быть прозрачным для пользователя, а также легко позволять пользователю подключать или отключать периферию и приложения так, чтобы это не приводило к сбою системы.
Производители не торопятся разработать легкую в работе операционную среду, позволяющую устранять неполадки без какой-либо серьезной подготовки. А потребителям вовсе не хочется изучать толстые тома документаций, отыскивая приемы устранения той или иной проблемы.
Одно из возможных решений данной задачи состоит в том, что при разработке новых ОС станут использоваться системы, предназначенные для компьютерных игр. Они позволяют работать быстро и эффективно, а, кроме того, разобраться в их принципе довольно просто.
СПИСОК ЛИТЕРАТУРЫ:
1. Еженедельник «ComputerWeek Moscow», № 10-11, 1998 г.
2. Журнал «PC Magazine”, № 8, 1998 г.
3. Кузнецов Ю.В. «Теория операционных систем», С-Пб., 1999 г.
4. Р.Петерсен "Linux. Руководство по операционной системе", BHV, 1997 г.
5. Рон Кук «Время новой настольной ОС», Изд. /Питер Паблишинг/ С-Пб., 1997 г.
6. Журнал «Network Client Business Group», январь 1997
Интернет: http://www.fbr.ru/
http://t37.nevod.perm.su/
http://www.students.ru/
http://www.aha.ru/~agb/
http://www.linux.org.ru/
http://www.dic.mimem.odu.ru/
*
Замечание 1: метод страничирования по запросу позволяет начать выполнение процесса даже в том случае, когда ни одна страница этого процесса не загружена в основную память.
**
Замечание 2: вторичная память, используемая при страничировании по запросу — это высокоскоростное дисковое устройство, часто называемое swap — оборудованием (device), а часть используемого дискового пространства — swap — пространство (swap space).
*
Стр.3 этой дипломной работы.
|