Разработка конвертора из текстового формата nroff в гипертекстовый формат HTML
Задание.
Разработать транслятор документов из формата nroff в формат HTML.
1. Транслятор должен быть реализован средствами программ lex и yacc.
2. Трансляции подлежит обособленный документ. (Один файл –один документ).
3. В качестве тестовых примеров использовать документы из руководства ОС UNIX (man-файлы).
4. В качестве среду разработки использовать ОС UNIX.
Введение.
В настоящее время все большее распространение находит использование для доступа к RISC‑серверам, на которых работают наиболее мощные системы САПР, вместо X-терминалов более дешевых и при этом более универсальных персональных компьютеров.
Для связи между персональными компьютерами и RISC‑серверам используются программы, эмулирующие на персональном компьютере работу X-терминалов. При этом на персональном компьютере, работающем под управлением Windows, запускается UNIX‑сессия с графическим интерфейсом пользователя (GUI). В качестве графического интерфейса может использоваться как любой из доступных на сервере графический интерфейс, так и интерфейс Windows.
Объем данных, которыми обмениваются при этом персональный компьютер и RISC‑сервер, достаточно велик. Поэтому нередко возникает необходимость в том, чтобы выполнять часть задач не на удаленном сервере, а непосредственно на персональном компьютере. Особенно большое значение это имеет в ситуации, которая возникает в последние время все чаще - когда сервер и персональный компьютер находятся на большом удалении друг от друга и объединяются между собой не посредством прямого соединения, как это было в случае с X‑терминалом, и даже не посредством локальных сетей, а при помощи международной сети Internet.
Вместе с тем, следует определиться с тем, какие задачи имеет смысл переносить на персональный компьютер, а какие необходимо решать на сервере, чтобы повысить отдачу от системы в целом. Представляется, что одной из задач, перенос которой на персональный компьютер облегчит работу пользователя и сделает ее более удобной, может быть работа с документацией, существующей в системе UNIX.
Документация в системе UNIX представлена в виде так называемых ‘manual pages’. Она просматривается с помощью команды системы UNIX ‘man’. При этом вызывается файл, содержащий требуемую документацию. Файлы, используемые командой ‘man’ написаны в текстовом формате nroff, являющимся стандартным форматом текста системы UNIX. Для чтения этих файлов также можно применять команду UNIX ‘nroff’.
Реклама

Для чтения файлов, записанных в формате ‘nroff’, можно установить на персональном компьютере какую-либо из UNIX‑подобных систем и, скопировав документацию на персональный компьютер, читать ее с помощью средств системы. Но при этом теряется одно из важнейших преимуществ использования персонального компьютера – его универсальность, так как станет либо совершенно невозможно использование программ, работающих под управлением Windows (в случае полной замены операционной системы), либо для их использования потребуется перезагрузка компьютера (в случае установки двух операционных систем на одном компьютере).
Другой путь состоит в преобразовании файлов документации системы UNIX из формата nroff в какой-либо формат, чтение которого возможно на персональном компьютере. Возникает вопрос, какой формат выбрать. К этому формату предъявляются следующие требования:
· Тексты, записанные в выбранном формате, должны быть доступны для чтения, как минимум, на персональном компьютере под управлением Windows. Желательно также, чтобы эти тексты можно было просматривать и на сервере под управлением UNIX.
· Тексты должны сохранять форматирование, имеющееся в документах ‘manual pages’.
Представляется, что оптимальным будет выбор формата HTML. Этот формат просматривается с помощью программ, версии которых работают как под управлением Windows, так и под управлением UNIX. Формат HTML поддерживает широкие возможности форматирования. Кроме того, этот формат является стандартным форматом для документов во всемирной системе Internet, а, как уже говорилось, проблема, вызвавшая необходимость переноса части задач с сервера на персональный компьютер, приобретает наибольшую остроту именно при связи между сервером и рабочим местом пользователя посредством Internet. Используя формат HTML, можно сделать документацию, преобразованную из ‘manual pages’ UNIX, общедоступной, поместив ее в один из узлов сети Internet. И последнее – этот формат является открытым, в отличие от большинства форматов текста на персональных компьютерах под управлением Windows, таких как, например, формат тестового редактора Word, что делает его удобным для использования, так как тексты в открытых форматах легко создавать и редактировать при минимальной вероятности возникновения ошибки.
Реклама

Существует несколько путей решения проблемы. В настоящее время созданы программы-трансляторы из формата nroff в формат HTML. Все они имеют свои преимущества и недостатки.
Рассмотрим несколько существующих программ.
1.Программа "nroff2HTML" (автор - Р. Ричи).
Программа написана на языке "C", работает под управлением ОС "UNIX". При конвертации вставляет в текст конечного файла обязательные теги формата HTML (такие, как <HTML></html>, <HEAD></head>, <BODY></body>) и затем копирует предварительно отформатированный с помощью программы nroff текст, заключив его в пару тэгов <PRE></pre>.
2. Программа "man2html", входящая в GUI * "Gnome".
Программа написана на языке "C", работает под управлением ОС "Linux", тесно интегрирована с GUI (графический пользовательский интерфейс) "GNOME".
Данная программа работает не с реальными файлами, а выступает как фильтр при выводе текста с помощью программы man на экран компьютера, перенаправляя вывод в окно HTML-броузера и снабжая его при этом всеми командами, необходимыми для форматирования. Полученный на экране текст выглядит наилучшим образом, т.к. в нем сохраняются все необходимые виды форматирования и поддерживаются перекрестные ссылки. Но данная программа не может работать без пакета "GNOME", для работы которого, в свою очередь, необходима ОС "Linux".
Ни одна из этих программ не удовлетворяет нашим требованиям, так как, во-первых, нам необходимо сохранять максимально полный объем форматирования, добившись переносимости программы и максимальной ее независимости от наполнения операционной среды.
При создании проекта в первую очередь следует решить второй вопрос, и, затем, выбрав принципы реализации проекта, приступить к созданию программы, способной адекватно обработать, как минимум, весь объем стандартных команд и операций формата nroff.
Согласно условиям технического задания программа должна функционировать в вычислительных системах под управлением ОС "Unix" и совместимых с ней ("Linux"). Проблема состоит в том, что исполняемые файлы ОС "UNIX" могут быть неработоспособны в среде "Linux". В то же время, многие из UNIX-подобных систем поставляются пользователю в виде текстов исходных файлов (исходников), предназначенных для компилирования. Так же и в данном случае можно передавать программу в виде исходников, снабженных программой компиляции. Это, с одной стороны, повысит переносимость программы, а с другой - позволит вносить достаточно опытному пользователю необходимые поправки и корректировки, расширяя возможности транслятора в соответствии с потребностями пользователя. При этом необходимым условием становится написание программы при помощи таких средств, которые присутствовали бы в любой UNIX-подобной ОС.
Первым очевидным элементом, присутствующим во всех таких ОС, является компилятор языка "С", на котором, собственно, и написана ОС "UNIX". Но язык "С" является достаточно сложным языком и не все пользователи знакомы с ним. В то же время, в ОС "UNIX" существуют другие средства написания программ: это генераторы программ LEX и YACC. Описание их команд настолько просто и логично, что позволяет вносить коррективы в существующую программу не имея специальной подготовки, и, возможно, даже не будучи знакомым с описанием этих средств, имея только текст исходной программы.
Nroff.
Nroff используется для форматирования текста в операционной системе UNIX при выводе на экран монитора или на принтер. Имеет достаточно простые команды, которые и будут дальше рассмотрены.
Команды для управления шрифтом:
.bd - bold font
.ft имя_шрифта - устанавливает шрифт
.ps n - устанавливает размер символа
Команды управления страницами:
.bp - начать новую страницу
.pl - установить длину страницы
.pn - установить номер страницы
.rt - вертикальный возврат для столбцов
Команды управления текстом:
.ad l (r,c,b,n) - выравнивание текста влево (вправо, по центру, по ширине, без выравнивания).
.br - следующая строка
.ce - центрирование
.fi - заполнение
.na - нет управления текстом (no adjust)
.nf - нет заполнения (no fill)
Вертикальные пропуски:
.ls - пропуск строки
.sp - пространство
<blank line> - новая строка + пропуск
Управление строкой:
.in - отступ
.ll - длина строки
.ti - временный отступ
Уже установленные переменные:
% - номер страницы
dw - день недели (1-7)
dy - день месяца
mo - месяц
yr - год
ln - текущая строка
.c - текущая строка от ввода
.f - текущий шрифт
.i - текущий отступ
.j - текущая регулировка (adjustment) текста
.l - длина строки
Использование числовых переменных:
.nr R v [i] - присвоить числовой переменной R значение v с необязательным инкрементом i
.af R c - установить формат числовой переменной (1,01,i,I,a,A)
\nx -использовать регистр x
\n(xy - использовать регистр xy – две буквы
\n+x - добавить инкремент, а затем использовать
\n-(xy - вычесть инкремент, а затем использовать
Использование строковых переменных:
.ds R str - присвоить переменной R содержимое str
.as R str - дописать str в конец строковой переменной R
\*x - использовать регистр x
\*(xy - использовать регистр xy – две буквы
\w’string’ - размер строки
Комментарии:
\” комментарий
Макросы:
.de xx \” –начало определения макроса
Today is \ \$1 the \ \$2.
.. \” –конец определения макроса
Использование макроса:
.xx Monday 14th
Получится: Today is Monday the 14th
HTML.
Простота документов заключается в следующем: текст, который нужно обработать или применить к нему какое-то действие, находится между так называемыми тэгами, соответственно открывающим и закрывающим. Общий вид тэгов: <TAG_NAME> </tag_name>. Приведу основные тэги языка HTML. Поскольку обычно HTML-документ используется в качестве Web-страницы, то в дальнейшем вместо термина HTML-документ будет использоваться термин Web-страница.
<COMMENT> </comment> - текст комментария. Существует ограничение – внутри комментария не должны располагаться другие элементы. Текст комментария не выводится браузером на экран. Также комментарий можно выделять следующим образом <!-- comment -->.
<HTML> </html> - отличительный признак Web-страница. Имеет редко используемые атрибуты version, lang, dir. Этот тэг допускает вложение элементов HEAD, BODY, PLAINTEXT. Конечным тэгом </html> заканчиваются все гипертекстовые документы.
<HEAD> </head> - область заголовка Web-страницы, служит для формирования общей структуры документа. Этот элемент может иметь атрибуты lang, dir и допускает вложения элементов TITLE, ISINDEX, BASE, META, LINK, NEXTID.
<TITLE> </title> - элемент для размещения заголовка Web-страницы. Строка текста, расположенная внутри, отображается не в документе, а в заголовке окна броузера.
<STYLE> </style> - описание стиля некоторых элементов Web-страницы. Например, элемент <STYLE> H2 {font-family: Arial;} </style> определяет стиль шрифта в элементе H2.
<BODY> </body> - заключает в себе гипертекст, который собственно определяет Web-страницу, отображаемую броузером. Внутри этого элемента можно использовать все элементы, предназначенные для дизайна Web-страницы. Внутри стартового тэга можно располагать ряд атрибутов, обеспечивающих установки для всей страницы целиком. Атрибуты:
background=”Путь к файлу фона”
bgcolor=”#RRGGBB” – здесь три 2-разрядных 16-ричных числа, которые определяют интенсивность красного, зеленого и синего цветов.
text=”#RRGGBB” – цвет текста страницы
link=”#RRGGBB” – цвет гиперссылки
vlink=”#RRGGBB” – цвет использованных гиперссылок
alink=”#RRGGBB” – цвет последней выбранной пользователем ссылки
<H1> </h1> - элемент заголовка. Существует 6 уровней заголовков, которые обозначаются H1..H6. Заголовок уровня 1 – самый крупный, уровень 6 – самый маленький. Для этого элемента можно использовать атрибут, задающий выравнивание влево, по центру или вправо:
align=”left” (“center”, “right”).
<HR> - горизонтальная линия. Этот элемент не имеет конечного тэга, но допускает ряд атрибутов:
align=”left” (“center”, “right”, “justify”) – выравнивание влево, по центру, вправо, по ширине.
size=толщина в пикселях – толщина линии
width=длина в пикселях
width=длина в процентах%
color=”Цвет”
Варьируя параметры длины и толщины можно представлять линию в виде прямоугольника.
<A> </a> - гиперссылки. Частный случай – шаблон для создания меток: <A name=”Метка”></a>
<BASE> - элемент для создания базового адреса (UR) для ссылок.
Дальше рассмотрены элементы, относящиеся непосредственно к форматированию текста, то есть именно то, что будет необходимо для разработки программы-транслятора.
<P> </p> - элемент абзаца (paragraph). В принципе позволяет использовать только начальный тэг, так как следующий элемент Р обозначает конец предыдущего и начало следующего абзаца. Вместе с этим элементом используются атрибуты:
align=”left” (“center”, “right”)
<BR> - элемент, обеспечивающий принудительный переход на новую строку. Имеет только стартовый тэг. Строка заканчивается в месте его размещения.
<NOBR> </nobr> - элемент противоположный предыдущему. Текст, заключенный между его тэгами, будет выведен в одну строку. Если строка будет слишком длинна придется использовать горизонтальную полосу прокрутки броузера.
<PRE> </pre> - элемент для обозначения текста, отформатированного заранее (preformatted).
<BLOCKQUOTE> </blockquote> - обозначение цитаты. Этот элемент требует наличия конечного тэга. Текст не претерпевает никаких изменений, но абзац располагается с отступом. В настоящее время существует сокращенное написание этого элемента: BQ.
<CENTER> </center> - элемент для центрирования текста, а точнее любого содержимого. Принято, когда это возможно использовать вместо этого элемента атрибут align=”center”
<DIV> </div> - элемент, похожий на предыдущий, позволяет выравнивать содержимое по левому, правому краю или по центру. Для этого стартовый тэг должен содержать атрибут:
align=”left” (“center”, “right”)
<B> </b> - выделение текста полужирным шрифтом.
<BIG> </big> - увеличенный размер шрифта
<SMALL> </small> - уменьшенный размер шрифта
<I> </i> - выделение текста курсивом
<EM> </em> и <DFN> </dfn> - элементы, обозначающие выразительность (emphasis) фрагмента текста и определение чего-либо (definition). Оба элемента аналогичны по своему действию элементу I, то есть в большинстве случаев позволяют выделить текст курсивом. Они имеют смысл, когда необходимо одинаково выделить фрагменты текста в разных частях документа.
<TT> </tt> - элемент, обозначающий текст телетайпа (teletype).
<STRIKE> </strike> - элемент, создающий перечеркнутое начертание текста. В настоящее время его заменяют более простым <S> </s>.
<U> </u> - подчеркнутое начертание текста.
<STRONG> </strong> - элемент, отвечающий за выделение текста. Обычно его применение равносильно использование элемента для выделения полужирным <B>.
<SUB> </sub> - элемент, создающий эффект нижнего индекса (subscript).
<SUP> </sup> - элемент, создающий эффект верхнего индекса (superscript).
<PLAINTEXT> </plaintext> - элемент, предназначенный для создания текста с конструкциями HTML, которые должны восприниматься именно как текст, а не как команды для броузера. Все тэги, заключенные в этот элемент, будут восприниматься только как произвольные символы.
<CODE> </code>, <SAMP> </samp> и <VAR> </var> - элементы, предназначенные для вывода фрагментов программ. CODE используется для форматирования текста программы. SAMP предполагается задействовать при иллюстрации примеров (sample) вывода данных на экран. VAR был создан для выделения переменных (variables).
<KBD> </kbd> - этот элемент предназначен для указания текста, который пользователь должен ввести с клавиатуры (keyboard).
<CITE> </cite> - предполагается, что этот элемент может быть использован для форматирования цитат и ссылок в обычном понимании этого слова. Текст, расположенный внутри него, выводится по умолчанию курсивом.
<ADDRESS> </address> - подобно предыдущему элементу, этот элемент отличается только предусмотренным содержанием.
<BASEFONT> - элемент, определяющий базовый (основной) размер шрифта. Внутри элемента необходимо указать атрибут:
size=Базовый размер шрифта – его величина может лежать в предела от 1 до 7. По умолчанию используется величина 3. Установка, выполняемая этим элементом, имеет значение для элемента FONT, который позволяет задавать относительный размер шрифта.
<FONT> </font> - определение типа, размера и цвета шрифта. Все эти характеристики определяются с помощью соответствующих атрибутов. Например, абсолютный размер шрифта задается с помощью атрибута:
size=абсолютный размер шрифта – этот атрибут может принимать значение от 1 до 7.
Также размер шрифта может задаваться относительно базового:
size=+число (-число)
Атрибут цвета:
color=”Цвет”
Тип шрифта:
face=”название шрифта”.
Также в HTML можно использовать таблицы, списки, ссылки, рисунки, различные формы, а также подключаемые апплеты и некоторые другие элементы. Но поскольку nroff не поддерживает подобные элементы, они не рассматриваются в данной работе. Более подробно узнать о них можно в литературе, посвященной HTML.
Вид документа в разных форматах.
Для наглядности приведу пример текстового документа с различными приемами форматирования текста, а затем представлю его в обоих рассматриваемых форматах (nroff и HTML).
Результирующий текст (тот, который мы хотим видеть на экране):
Это пример текстового документа
Здесь показаны некоторые возможности форматирования текста
Пропуск строки
Работа с расположением текста:
Выровнять по левому краю
Выровнять по центру
Выровнять по правому краю
Есть также команды, позволяющие работать со шрифтами:
Обычный шрифт
Другой (вызванный) шрифт
Подчеркнутый текст
Подчеркнутый отцентрированный текст
Представим теперь этот текст в формате nroff.
.ft Times New Roman
.ad l
.nf
Это пример текстового документа
.br
Здесь показаны некоторые возможности форматирования текста
.sp
Пропуск строки
.sp
Работа с расположением текста:
.ad l
Выровнять по левому краю
.ad c
Выровнять по центру
.ad r
Выровнять по правому краю
.br
Есть также команды, позволяющие работать со шрифтами:
.br
Обычный шрифт
.br
.ft Arial
Другой (вызванный) шрифт
.ft Times New Roman
.br
.ul 1
Подчеркнутый текст
.ce 1
.ul 1
Подчеркнутый отцентрированный текст
Как видно из примера, каждой строке предшествует определенная команда. Команда отсутствует в том случае, если над текстом не надо производить никаких дополнительных действий. Поясню некоторые команды.
.ft Times New Roman – установка для документа определенного шрифта (а позже его временная смена на шрифт Arial)
.ad l (c, r) – выравнивание текста по левому краю (центру, правому краю)
.sp – пропуск строки
.br – начало новой строки
.ul 1 – подчеркивание следующей (одной) строки
.ce 1 – центрирование следующей (одной) строки
Это простейший пример, в принципе, возможности формата nroff значительно шире. Используя весь набор команд nroff, можно достаточно полно применять разные способы и приемы форматирования текста.
А теперь представим тот же документ, но уже в формате HTML.
<HTML>
<BODY>
Это пример текстового документа<BR>
Здесь показаны некоторые возможности
форматирования текста <BR>
<BR>
Пропуск строки<BR>
<BR>
Работа с расположением текста:
<P align="left">Выровнять по левому краю
<P align="center">Выровнять по центру
<P align="right">Выровнять по правому краю</p>
<BR>
Есть также команды, позволяющие работать со
шрифтами:<BR>
Обычный шрифт<BR>
<FON T face="Arial">Другой(вызванный)шрифт
</font><BR>
<U>Подчеркнутый текст</u>
<P align="center"><U>Подчеркнутый
отцентрированный текст</u></p>
</body>
</html>
Также как и с предыдущим форматом, поясню некоторые команды и конструкции языка.
<HTML> … </html> - эти тэги говорят о том, что мы имеем дело с документом в формате HTML
<BODY> … </body> - между этими тэгами находятся все команды, а также текст HTML-документа.
<BR> - начало новой строки
<P> … </p> - начало и конец нового абзаца
align=”left” (center, right) – используется для указания типа выравнивания текста: по левому краю, центру или правому краю.
<FONT> … </font> - между этими тэгами текст выводится другим шрифтом, указанным в конструкции:
face=”font_name”
<U> … </u> - выводит подчеркнутый текст
Аналогично с форматом nroff, возможности HTML намного шире представленных в этом примере.
Стоит также отметить тот факт, что в целом формат HTML богаче формата nroff. В связи с этим при разработке программы-транслятора использовалась лишь та часть HTML, которая необходима для создания конструкций, аналогичных конструкциям созданным в формате nroff.
Контекстно-зависимые и контекстно-независимые грамматики.
Задача разработки транслятора соприкасается с дисциплиной, именуемой лингвистическое обеспечение САПР, некоторые положения которой мы и рассмотрим.
Прежде всего стоит отметить, что различают два основных типа грамматик: контекстно-зависимые и контекстно-независимые.
Если порождающее правило имеет следующий вид:
aAb ::= axb,
то порождающее правило называется контекстно-зависимым, то есть замена нетерминального символа A на последовательность x может иметь место только в контекстах a и b. Соответственно, и грамматика, содержащая подобное правило, называется контекстно-зависимой.
Если порождающее правило имеет вид:
A ::= x, где A – нетерминальный символ, а x - терминальный или нетерминальный. То есть, если левая часть порождающего правила состоит из одного нетерминального символа, который в итоге (через ряд промежуточных шагов) может заменяться на последовательность x, стоящую в правой части, независимо от контекста, в котором этот нетерминальный символ встречается, то такое правило и, соответственно, грамматика называются контекстно-независимыми.
В нашей задаче грамматика является контекстно-независимой (или как ее еще называют контекстно-свободной), поэтому более подробно стоит остановиться именно на ее описании.
Контекстно-свободные грамматики.
Существует несколько основополагающих терминов в теории грамматик. Нетерминальный символ (нетерминал) – описываемые элементы. Например, при определении языков программирования нетерминалами служат <оператор>, <арифметическое выражение> и т.п. В контекстно-свободной грамматике может быть любое конечное число нетерминалов.
Слова из словаря языка играют роль терминальных символов (терминалов). Контекстно-свободная грамматика может также содержать любое конечное число терминалов. В языках программирования терминалами являются фактически используемые в них слова и символы: do, else, + и т.п.
Правила грамматики иногда называются продукциями и в общем виде выглядят так:
Один_нетерминал à любая конечная цепочка из терминалов и нетерминалов.
При этом цепочка справа от стрелки может быть и пустой. Например,
<A> à x
Иногда подобные правила называют эпсилон-правилами. Контекстно-свободная грамматика может содержать любое конечное множество продукций. В качестве иллюстрации вернусь к описанию языка программирования. Продукция тогда выглядит так:
<оператор> à IF <логическое_выражение> THEN <оператор>
Один из нетерминалов выделен как начальный нетерминал или начальный символ, с которого должны начинаться выводы цепочек языка. Для языков программирования таким нетерминалом может быть <программа>. Обычно начальный символ обозначают <S>.
Итак, контекстно-свободная грамматика будет задаваться:
1) конечным множеством нетерминалов;
2) конечным множеством терминалов, которое не пересекается с множеством нетерминалов;
3) конечным множеством правил вида <A> à a, где A – нетерминал, а a - цепочка терминалов и нетерминалов (возможно, пустая); нетерминал <A> называется левой частью правила, а a - правой частью;
4) одним нетерминальным символом, выделенным в качестве начального.
Если множество правил приводится без специального указания множества терминальных и нетерминальных символов, то предполагается, что грамматика содержит в точности те терминалы и нетерминалы, которые встречаются в правилах.
Для описания грамматик очень часто используют способ записи, получивший название формы Бэкуса-Науэра или БНФ. Здесь символ à заменяется символом ::=, за которым может следовать любое число правых частей, разделенных вертикальной чертой |. Здесь также нетерминалы заключаются в угловые скобки.
Правила грамматики используют для того, чтобы задавать способы подстановки или замены цепочек. Подстановка осуществляется путем замены некоторого нетерминала в какой-нибудь заданной цепочке терминалов и нетерминалов на правую часть правила, левой частью которого является этот нетерминал. Иногда говорят, что в таком случае правило применяется к нетерминалу цепочки.
Последовательность некоторых подстановок называется выводом. Каждая цепочка, встречающаяся в выводе, называется промежуточной цепочкой этого вывода.
Множество терминальных цепочек, которые можно вывести из начального символа грамматики, называется языком. Говорят, что язык определяется, грамматикой, порождается ею или выводится в ней. Язык, порождаемый контекстно-свободной грамматикой, также называется контекстно-свободным языком.
В случае, когда на каждом шаге подстановок заменяется самый левый нетерминальный символ, такой вывод называется левосторонним или левым выводом. Для каждого дерева существует единственный левый вывод, так как благодаря условию выбора самого левого нетерминала место каждой подстановки устанавливается единственным образом. Аналогично, для дерева существует единственный правосторонний или правый вывод, который получается если заменять всегда самый правый нетерминал.
Дерево вывода цепочки контекстно-свободного языка сложно описать кратко, поэтому покажу пример подобного дерева.
Пусть дана следующая грамматика (начальный нетерминал <S>):
1. <S> à a<A><B>c
2. <S> à x
3. <A> à c<S><B>
4. <A> à <A>b
5. <B> à b<B>
6. <B> à a
Пусть дана цепочка: a<A><B>c, тогда вывод будет выглядеть следующим образом:
<S> (1) ==> a<A><B>c (2) ==> a<A>b<B>c (3) ==> ac<S><B>b<B>c (4) ==> ac<S>ab<B>c (5) ==> acab<B>c (6) ==> acabac (7).
Теперь для каждой из семи пронумерованных цепочек построю дерево.
(1) <S>
(2) <S>
a <A> <B> c
(3) <S>
a <A> <B> c
<A> b
(4) <S>
a <A> <B> c
<A> b
c <S> <B>
(5) <S>
a <A> <B> c
<A> b
c <S> <B>
a
(6) <S>
a <A> <B> c
<A> b
c <S> <B>
x a
(7) <S>
a <A> <B> c
<A> b a
c <S> <B>
x a
Окончательный вариант дерева называется деревом вывода терминальной цепочки acabac.
Когда одна цепочка может иметь несколько деревьев вывода, говорят, что соответствующая грамматика неоднозначна.
Таким образом, резюмируя вышесказанное, можно подытожить:
1. Каждой цепочке, выводимой в данной контекстно-свободной грамматике, соответствует одно или несколько деревьев вывода.
2. Каждому дереву соответствует один или более выводов.
3. Каждому дереву соответствует единственный правый и единственный левый выводы.
4. Если каждой цепочке, выводимой в данной контекстно-свободной грамматике, соответствует единственное дерево вывода, эта грамматика называется однозначной; в противном случае ее называют неоднозначной.
Для любого контекстно-свободного языка существует бесконечное число грамматик, порождающих этот язык. Хотя большинство этих грамматик чересчур сложны, на практике порой бывает полезно иметь для описания некоторого языка несколько разных грамматик.
Если правая часть каждого правила грамматики содержит не более одного нетерминала, причем этот нетерминал является самым правым символом правой части, грамматика называется праволинейной.
Нетерминалы, которые не порождают ни одной терминальной цепочки, называются бесплодными или мертвыми. Они могут быть исключены из грамматики со всеми правилами, в которые входят.
Нетерминалы, которые не появляются ни в одной цепочке, выводимой из начального символа, называются недостижимыми нетерминалами.
Нетерминалы, которые бесплодны или недостижимы называются бесполезными. При составлении грамматик велика вероятность появления бесполезных нетерминалов и загромождение грамматик лишними правилами. Для поиска подобных нетерминалов существует конкретная процедура, разбитая на две части: обнаружение бесплодных нетерминалов и обнаружение недостижимых нетерминалов. Сначала нужно выполнить процедуру для бесплодных нетерминалов, так как при их удалении из грамматик другие нетерминалы могут стать недостижимыми.
Терминальный символ называется продуктивным (или живым), если из него выводится какая-нибудь терминальная цепочка, то есть если он не является бесплодным нетерминалом. Процедура обнаружения бесплодных нетерминалов основана на следующем свойстве продуктивных символов:
Если все символы правой части правила продуктивны, то продуктивен и символ, стоящий в ее левой части.
Символ называется достижимым в грамматике, если он может появиться в какой-нибудь цепочке, выводимой из начального нетерминала, то есть если он не является недостижимым. Процедура обнаружения недостижимых символов грамматики основана на следующем свойстве достижимых символов:
Если нетерминал в левой части правила является достижимым, то достижимы и все символы правой части этого правила.
Свойства языка, которые в руководстве описываются грамматикой, принято называть синтаксическими или грамматическими свойствами, а свойства, которые грамматикой не описываются – семантическими свойствами. В руководстве по языку семантические свойства описываются обычно на естественном языке.
Создание программы-транслятора.
Для написания программы-транслятора файлов из формата nroff в файлы формата HTML мы будем использовать генератор программ lex, компилятор компиляторов yacc, а также стандартный компилятор языка Си cc.
Процедура создания программы следующая. Для начала нам необходимо описать лексические правила нашей конкретной задачи или, говоря другими словами, написать лексический анализатор. Получившийся файл, называющийся nroff2html.lex, мы пропускаем через lex в результате чего получаем на выходе файл с именем lex.yy.c (непосредственно лексический анализатор).
На следующем этапе создаем файл, описывающий грамматику нашей задачи, то есть пишем грамматический анализатор. Полученный файл, называющийся nroff2html.yacc, мы подаем в компилятор компиляторов yacc одновременно с файлом lex.yy.c. На выходе yacc мы получим два файла ytab.c (непосредственно грамматический анализатор) и y.output (структура правил грамматического анализатора).
Следующим этапом будет создание исполняемого модуля. Производится совместное компилирование файлов lex.yy.c, y.tab.c и стандартных библиотек.
Порядок работы с программой-транслятором nroff2html таков: на вход программы подается текстовый файл в формате nroff, а на выходе получаем текстовый файл в формате HTML.
Конкретные шаги при разработке транслятора.
Для построения конвертора выбран следующий подход:
Сначала, с помощью генератора программ "Lex" строится лексический анализатор. В задачу лексического анализатора входит полное поглощение входного файла (потока) и передача в синтаксический анализатор найденных лексем, а также некоторых необходимых данных (например, может быть найдена лексема. NUMBER, а в качестве данных передается числовое значение найденного числа или цифры). Лексемы, содержащиеся в спецификации лексического анализатора должны полностью описывать все возможные наборы символов. Синтаксический же анализатор строится с помощью генератора программ YACC. В синтаксическом анализаторе с помощью высокоуровневых правил полностью описывается структура входного потока. Правила могут быть рекурсивными, то есть может существовать правило, элементом которого является оно само. Первым правилом синтаксического анализатора обычно выбирается такое, которое полностью описывает любой возможный входной файл.
При анализе входного текста лексическим анализатором приняты следующие предположения:
1. Предполагается, что все команды nroff начинаются с точки и содержат не более двух букв латинского алфавита.
2. Всякая строка, не имеющая в начале точки, является строкой текста.
3. Пустая строка (не содержащая никаких символов, кроме конца строки) означает команду "Перевод строки" и вывод пустой строки.
4. За командой может следовать один или более пробельный символ и аргумент.
5. После аргумента до конца строки может следовать ноль, один или более пробельный символ.
6. Аргумент может быть строкой, символом или цифрой.
Лексический анализатор разбирает входной поток следующим образом:
1. В начальном состоянии считывается первый символ из потока.
а) Если символ является точкой, то анализатор переходит в состояние ожидания команды.
б) Иначе предполагается, что взят первый символ из текстовой строки. Анализатор переходит в состояние приема текста, причем при последующем действии взятые из потока данные будут добавлены к символу, находящемуся в буфере – так обеспечивается целостность текста.
в) Если же символ взять не удалось - была встречена пустая строка – то синтаксическому анализатору передается лексема, означающая пустую строку.
2. В состоянии приема текста строка из потока принимается целиком, до символа конца строки. Лексический анализатор возвращает синтаксическому анализатору лексему, означающую текст, предварительно перейдя в начальное состояние.
3. В состоянии приема команды из потока принимается две латинских буквы, за которыми могут следовать один или более пробелов.
а) В соответствии с полученными символами выбирается лексема и передается синтаксическому анализатору.
б) Если полученные символы не подходят под шаблон ни одной из команд, то команда объявляется неизвестной. Перед возвращением лексемы в синтаксический анализатор, лексический анализатор переходит в состояние ожидания аргумента команды.
4. Предполагается, что аргументы команд могут быть трех типов – слово (например, название шрифта у команды .ft); символьный (например, тип выравнивания у команды .ad) или числовой (например, количество строк у команды .br). После определения лексемы, лексичепский анализатор переходит в начальное состояние и передает лексему синтаксическому анализатору.
а) Следует учитывать, что лексический анализатор, построенный с помощью генератора программ Lex, принимая символы, берет их не по порядку следования правил, а выбирает правило, удовлетворяющее наибольшей длине принимаемой строки. Поэтому лексический анализатор определит аргумент как символьный только в случае, если он действительно содержит только один символ.
б) В противоположном случае аргумент определяется как слово.
в) Если аргумент состоит из одной и более цифр, то он передается как число.
Для передачи данных (текст, содержащийся в строке; значение аргументов) используется текстовый буфер (массив символов yytext[]), в который записывает считанные из потока данные лексический анализатор, построенный при помощи lex и который может использоваться любой функцией, т.к. является внешней переменной.
Единственным условием, накладываемым на программы, созданные при помощи взаимодействия генераторов программ lex и yacc, является необходимость полного соответствия в названии лексем, возвращаемых лексическим анализатором, и описанных в разделе объявлений синтаксического анализатора директивой %token.
Пользователь не должен переопределять такие функции, как input(), output(c) и unput(c), т.к. они используются анализатором и их переопределение может привести к ошибке.
Правила синтаксического анализатора строятся так, чтобы они оказались вложенными друг в друга. Наиболее внешнее правило должно полностью описывать любой возможный файл, который может быть обработан данным анализатором. В правилах допускается рекурсия, т.е. правило может содержать элементы, при раскрытии которых будет вызвано оно само. В нашем случае наиболее общим правилом является описание входного файла как списка списков строк. Строки могут быть двух типов - команды и текст. Команды могут иметь аргумент либо не иметь аргумента. Текст может быть текстовой строкой и пустой строкой. Такие элементы, как команды, аргументы, текстовые и пустые строки представляют собой лексемы - минимальный объект, которым оперирует анализатор при синтаксическом анализе.
1. Если синтаксический анализатор получает от лексического анализатора лексему "текст", то он выводит в выходной поток содержимое буфера yytext.
2. Если получена лексема "пустая строка", то в выходной поток выводится тэг HTML <br>.
3. Если получена лексема, соответствующая одной из команд, то, возможно, запрашивается лексема аргумента и выполняются необходимые операции.
Так как во всех командах аргумент является вторым элементом правила, то для доступа к его значению всегда используется псевдопеременная $2.
Обработка большинства команд приводит к тому, что в выходной поток записывается открывающий тэг, возможно с теми или иными аргументами. Так как формат HTML требует закрытия тэга до его повторного открытия, то для контроля закрытия предусмотрены переменные-триггеры. Они принимают значение, равное единице, при выводе в выходной поток открывающего тэга и каждый раз перед выводом нового открывающего тэга проводится проверка на включение триггера. Если триггер включен, то перед выводом стартового тэга будет выведен закрывающий тэг.
В формате nroff принята такая система команд, при которой у большинства команд аргументом является количество строк, на которые будет распространятся действие этой команды. В HTML же область действия команды определяется местоположением открывающего и закрывающего тэгов. Для того, что бы определить место вывода закрывающего тэга, введены переменные-счетчики. В момент получения команды им присваивается значение аргумента, и затем оно уменьшается при выводе в выходной поток очередной порции текста. При достижении счетчиком значения "ноль", в выходной поток выводится закрывающий тэг. Если значение счетчика меньше нуля, то это значит, что он сейчас неактивен.
Для вывода в выходной поток тэга <br> - команда перевода строки – применяется специальная функция breakline(). Необходимость такого шага обусловлена тем, что в nroff существует команда ".ls", которая определяет, сколько пустых строк выводится по команде ".br" (аналогом которой является тег <br>). При поступлении лексемы, соответствующей команде ".ls" значение ее аргумента присваивается переменной LS, которая определяет сколько раз подряд выведется тэг <br> в выходной файл.
Особо надо оговорить обработку команды nroff ".ex". При получении лексемы, соответствующей этой команде, синтаксический анализатор завершает свою работу, возвращая в головную функцию значение "0", свидетельствующее о нормальном завершении работы.
LEX.
Lex(CP) - это генератор программ, предназначенных для лексической обработки входного потока символов. На вход подается высокоуровневая проблемно-ориентированная спецификация для выделения символьных строк, на выходе получается программа на языке Си для распознавания регулярных выражений. Регулярные выражения задаются пользователем во входной спецификации для построителя. Построенная с помощью lex программа ищет во входном потоке регулярные выражения и разбивает его на строки, удовлетворяющие спецификации. По завершении распознавания цепочки символов выполняются задаваемые пользователем фрагменты программы. В исходном файле для lex устанавливается связь между регулярными выражениями и фрагментами программного кода. При появлении на входе сгенерированной программы некоторого регулярного выражения выполняется соответствующий фрагмент.
Для полного оформления задачи пользователь задает дополнительные части программы, включая подготовленные другими генераторами. Программа-распознаватель генерируется в виде фрагментов программ на языке Си. lex не является законченным языком, это всего лишь генератор, дополняющий язык Си новыми возможностями.
Построитель преобразует спецификации и действия, задаваемые пользователем (в этой главе мы будем называть это исходным текстом), в программу на Си. Эта программа распознает во входном потоке регулярные выражения и при каждом обнаружении выполняет соответствующие действия.
Регулярные выражения.
Регулярное выражение определяет множество цепочек, удовлетворяющих некоторому условию. В него входят текстовые символы (совпадающие с символами в сравниваемых строках) и управляющие (определяющие повторение, выбор и прочие режимы).
К управляющим относятся следующие символы:
"\[]^?.*+|()$/{}%<>
Если какие-либо из перечисленных символов должны использоваться как обычные, их нужно экранировать либо индивидуально с помощью обратной дробной черты (\), либо в виде последовательности, заключая в кавычки. Кавычки указывают, что содержащаяся в них строка должна рассматриваться как текстовые символы. Экранироваться может и часть строки. Экранирование текстовых символов необязательно, хотя никакого вреда не приносит.
Механизм экранирования полезен и при необходимости вставки в регулярное выражение символа пробела. Обычно пробелы или табуляции завершают правила. Любые пробелы, не содержащиеся в скобках, должны
экранироваться. Распознаются также несколько специальных последовательностей языка Си:
\n перевод строки
\t табуляция
\b шаг назад
\\ обратная дробная черта
Так как в выражении перевод строки недопустим, он должен экранироваться. Заметьте, что любой символ всегда является текстовым. Исключение составляют пробелы, табуляции, переводы строки и приведенные выше управляющие символы.
Запуск программы.
При компиляции исходной программы можно выделить два шага. Во-первых, исходный файл должен быть преобразован в сгенерированную программу на языке высокого уровня. Затем эта программа компилируется и компонуется, обычно вместе с библиотекой подпрограмм lex. Сгенерированная программа помещается в файл lex.yy.c. В программе может использоваться стандартная библиотека ввода-вывода языка Си.
Результирующая программа помещается в файл a.out и может впоследствии быть выполнена.
Классы символов.
Классы символов задаются с помощью квадратных скобок. Конструкция:
[abc]
удовлетворяет одному символу из множества a, b, c. Внутри скобок большая часть операторов игнорируется. Специальными являются только три: обратная дробная черта (\), минус (-) и стрелка вверх (^). Минус определяет диапазон символов, например:
[a-z0-9<>_]
определяет класс символов, состоящий из строчных букв, цифр, угловых скобок и знака подчеркивания. Диапазоны могут задаваться в любом порядке.
Использование минуса между двумя символами, не являющимися только прописными, только строчными или только цифрами, зависит от реализации и приводит к выдаче предупреждающего сообщения. Если минус должен входить в определяемый класс, его нужно поместить или первым или последним. Таким образом
[-+0-9]
удовлетворяют всем цифрам и знакам плюс и минус.
При определении классов оператор ^ должен быть первым символом после открывающей скобки, он указывает, что полученная строка должна рассматриваться как исключение из всего множества символов ЭВМ. Таким образом
[^abc]
удовлетворяет всем символам, кроме a,b и с, включая все специальные и управляющие символы, а
[^a-zA-Z]
удовлетворяет любому символу, не являющемуся буквой. Обратная дробная черта играет роль экранирующей последовательности для любого символа в квадратных скобках, который, если перед ним стоит обратная дробная черта, рассматривается буквально.
Задание произвольных символов.
Для указания любого символа используется точка (.), удовлетворяющая всем символам, кроме перевода строки. Можно указывать восьмеричные коды, хотя данный способ немобилен. Например,
[40-176]
удовлетворяет всем печатаемым символам кода ASCII, от восьмеричного 40 (пробел) до 176 (черта сверху).
Задание вариантов.
Знак вопроса означает вариант в регулярном выражении. Например
ab?c
удовлетворяет либо ab или abc.
Указание повторений.
Повторяющиеся классы указываются операторами * и +. Например,
a*
удовлетворяет любому количеству (включая 0) последовательно идущих символов a, в то время, как
a+
удовлетворяет одному или нескольким символам. Например,
[a-z]+
удовлетворяет всем строкам из строчных букв, а
[A-Za-z][A-Za-z0-9]*
удовлетворяет всем алфавитно-цифровым строкам, начинающимся с буквы.
Альтернативы и группирование.
Вертикальная черта указывает альтернативы. Например,
(ab|cd)
удовлетворяет либо ab либо cd. Для группирования применяются скобки, хотя на верхнем уровне они не обязательны. Например
ab| cd
аналогично предыдущему примеру. Скобки используется для более сложных выражений, например
(ab|cd+)?(ef)*
удовлетворяет таким строкам, как abefef, efefef, cdef и cddd, но не abc, abcd или abcdef.
Чувствительность к контексту.
Lex распознает ограниченный объем окружающего контекста. Два простейших оператора - ^ и $. Если первым символом выражения указан ^, оно будет удовлетворяться при расположении в начале строки (после символа перевода строки или в начале входного потока). Такой смысл не противоречит значению этого символа при задании классов, так как в этом случае он указывается внутри квадратных скобок. Если последним символом выражения служит $, выражение будет удовлетворяться при нахождении в конце строки. Последний оператор - частный случай более общего оператора /, задающего правый контекст. Выражение
ab/cd
удовлетворяет строке ab только в том случае, если за ней следует cd. Таким образом
ab$
аналогично
ab/\n
Задание повторяющихся выражений.
Фигурные скобки задают либо повторение (если внутри цифры), либо определение подстановки (если внутри имя). Например
{digit}
ищет заранее определенную строку с именем digit и вставляет ее в заданной точке. А выражение
a{1,5}
ищет от одного до пяти вхождений символа a.
Задание определений.
Определения помещаются в первой части спецификации перед правилами и завершаются символом процента.
Задание действий.
Если выражение удовлетворяет некоторому фрагменту вводимого текста, lex выполняет соответствующее действие. В этом разделе описываются некоторые особенности, помогающие при написании действий. Существует действие по умолчанию, заключающееся в копировании входного потока в выходной. Копированию подвергаются строки, не удовлетворившие правилам. Таким образом, для поглощения всего входного потока нужно задать выражение, удовлетворяющее всем символам. При использовании lex совместно с yacc это считается нормальной ситуацией. Вы можете рассматривать копирование как некоторое действие, которое можно не указывать.
Одно из простейших действий - игнорирование входного потока. Это выполняется с помощью пустого оператора Си (;).
Еще один способ избежать задания действий - символ повторения (|), указывающий, что действие этого правила аналогично действию для последующего.
Иногда правила некорректно распознают символы на границах входного потока. Для этой ситуации удобны две функции. Yymore() указывает, что следующее входное выражение должно помещаться в конец только что найденного. Обычно следующее выражение затирает текущее содержимое yytext. Yyless(n) вызывается тогда, когда в данный момент нужны не все символы, удовлетворившие текущему правилу. Аргумент указывает количество символов, возвращаемых во входной поток. Это обеспечивает просмотр вперед, но в несколько иной форме, нежели при $.
Можно пользоваться и внутренними функциями ввода-вывода. К ним относятся:
1. input() следующий символ из потока;
2. output(c) вывод символа в поток;
3. unput(c) возврат символа в поток.
По умолчанию эти функции определены как макросы, но пользователь может вместо них использовать собственные функции. Эти функции определяют взаимосвязь между внешними файлами и внутренним представлением символов, поэтому их модификация должна быть согласованной и непротиворечивой. Они могут переопределяться для ввода и вывода во внутреннюю память или в другие процессы, но набор символов должен быть единым, нулевой значение, возвращаемое input(), должно означать конец файла, взаимосвязь между input и unput должна быть сохранена, иначе не будет работать просмотр вперед.
Lex не использует без надобности просмотр вперед, но к нему приводят правила, содержащие /, или заканчивающиеся на один из следующих символов:
+ * ? $
Просмотр вперед также необходим при обработке выражения, служащего префиксом другого выражения.
Еще одна функция, которую иногда переопределяют, - yywrap. Она вызывается при достижении конца файла. Если она возвращает 1, выполняется нормальное завершение работы. Иногда бывает удобно организовать дополнительный ввод из другого источника. В этом случае пользователь пишет свою версию этой функции, которая выполняет новый ввод и возвращает 0. Это приводит к продолжению обработки. По умолчанию yywrap всегда возвращает 1.
Эта функция - удобный момент для организации вывода таблиц, итоговых справок и пр. по достижении конца программы. Обратите внимание, что написать обычное правило, распознающее конец файла, невозможно, единственный способ - функция yywrap. Кстати, без переделки функции input() невозможно обработать файл, содержащий нули, так как возвращаемый этой функцией 0 служит признаком конца файла.
Обработка неоднозначных правил.
Lex может обрабатывать неоднозначные правила. Когда вводимая строка удовлетворяет более, чем одному выражению, осуществляется следующий выбор:
* Выбирается самая длинная последовательность.
* Из всех подходящих правил выбирается первое.
Входной поток обычно разбивается на части так, что lex не ищет все возможные вхождения всех выражений. Каждый символ считается один и только один раз.
Иногда это неприемлемо. Действие REJECT означает переход к следующей альтернативе. Оно приводит к выполнению правила, которое было бы следующим. Позиция указателя во входном потоке устанавливается соответствующим образом. В общем случае, действие REJECT полезно, когда задачей служит не разбиение входного потока, а обнаружение всех вхождений некоторого выражения (иногда перекрывающихся) во входном потоке. REJECT не осуществляет повторного просмотра. Вместо этого запоминается результат предыдущего просмотра. Это означает, что если найдено правило с правым контекстом и выполнено действие REJECT, запрещается использовать unput для изменения символов, поступающих из входного потока. Это единственное ограничение, накладываемое на манипуляции еще не обработанной входной информацией.
Чувствительность к левому контексту.
Иногда желательно иметь несколько наборов лексических правил, в разное время применяемых ко входному потоку. Например, препроцессор компилятора должен выделять директивы препроцессора и анализировать их иначе, чем операторы языка. Это требует чувствительности к предыдущему контексту. Существует несколько способов решения данной проблемы. Оператор ^ распознает непосредственно предшествующий левый контекст, так же, как и $ распознает непосредственно следующий правый контекст. Непосредственно примыкающий левый контекст мог бы быть расширен по аналогии с правым, но вряд ли это будет полезным, так как требуемый левый контекст часто находится немного раньше, например, в начале строки.
Существует три способа обработки, используемые в различных условиях:
1. Применение флагов (при изменении условий правила меняются незначительно).
2. Использование начальных состояний.
3. Использование нескольких лексических анализаторов, работающих одновременно.
В любом случае, существуют правила, распознающие необходимость изменения условий, в которых будет анализироваться текст, и устанавливающие ряд параметров для фиксации измененных условий. Это может быть, например, флаг, проверяемый в пользовательских действиях. Это самый простой способ решения задачи, так как lex здесь вообще не участвует. Может оказаться удобным запомнить флаги в качестве начальных состояний правил. С начальным состоянием может быть связано любое правило. Оно будет применяться только в том случае, когда lex находится в этом состоянии. Текущее начальное состояние может быть изменено в любое время. И наконец, если наборы правил для различных состояний сильно отличаются, более ясным подходом было бы написание нескольких отдельных анализаторов, переключаемых при необходимости.
Задание определений.
Рассмотрим общий формат входной спецификации:
{определения}
%%
{правила}
%%
{программы пользователя}
К настоящему моменту мы описали только правила. Необходимо также определить переменные как для программы, так и для lex. Это можно сделать как в разделе определений, так и в разделе правил.
Правила превращаются в программу. Любой фрагмент входной спецификации, не интерпретируемый lex, копируется в генерируемую программу. Эти фрагменты можно разделить на три класса:
1. Любая строка, не являющаяся частью правила или действия, и начинающаяся с пробела или табуляции, копируется в генерируемую программу. Если строки находятся перед первым символом %%, они будут внешними по отношению к любой функции. Если они находятся в разделе правил, они будут относиться к сгенерированной функции. Строки должны выглядеть как фрагменты программы и помещаться до начала описания правил.
Побочным эффектом является копирование строк, начинающихся с табуляции или пробела и содержащих комментарий. Эту особенность можно использовать для включения комментариев в генерируемую программу или спецификации. Комментарии должны оформляться в соответствии с правилами языка Си.
2. Весь текст между символами %{ и %} также копируется. Ограничители отбрасываются. Этот формат позволяет вводить операторы препроцессора, начинающиеся в первой позиции, а также строки, мало напоминающие программный код.
3. Весь текст после третьего ограничителя %% копируется в генерируемую программу.
Определения, предназначенные для lex, помещаются перед первым ограничителем %%. Любая строка этого раздела, не находящаяся внутри %{ %} и начинающаяся с позиции 1, считается строкой подстановки. Ее формат следующий:
имя подстановка
Цепочкам из части подстановки присваивается имя. Имя и подстановка должны разделяться как минимум одним пробелом и имя должно начинаться с буквы. Подстановка вызывается в правиле с помощью конструкции {имя}.
Сгенерированные программы выполняют ввод-вывод символов только с помощью функций input(), output() и unput(). Используемое в этих функциях представление символов воспринимается lex и передается как возвращаемое значение в массиве yytext. При внутреннем употреблении символ представлен небольшим целым числом, и при использовании стандартной библиотеки ввода-вывода его значение равно целому, соответствующему набору битов для этого символа в ЭВМ. Обычно символ a представлен так же, как и символьная константа:
'a'
Если это представление меняется с помощью функций ввода-вывода, выполняющих трансляцию, lex должен быть извещен об этом посредством таблицы трансляции. Эта таблица должна находиться в разделе определений и ограничиваться строками, содержащими только %T. Таблица содержит строки следующего формата:
{целое} {символьная строка}
Строки связывают с символом соответствующее значение.
Формат входного текста.
Общий формат входного текста следующий:
{определения}
%%
{правила}
%%
{подпрограммы пользователя}
Раздел определений может содержать следующую информацию:
1. Определения в виде "имя пробел значение".
2. Включаемый фрагмент в виде "пробел фрагмент".
3. Включаемый фрагмент в виде
%{
фрагмент
%}
4. Начальные состояния в виде
%S имя1 имя2 имя3 ...
5. Таблицы наборов символов в виде
%T
число пробел строка символов
%T
6. Модификация размеров внутренних таблиц в виде
%x nnn
где nnn - десятичное число, соответствующее размеру массива, а x - параметр следующего вида:
Символ Параметр
p позиции
n состояния
e узлы дерева
a переходы
k упакованные символьные классы
o размер выходного массива
Строки в разделе правил имеют следующий формат:
выражение действие
Действие может продолжаться на следующих строка, его ограничивают фигурные скобки.
В регулярных выражениях допустимы следующие операторы:
x Символ x.
x Всегда x, даже если это оператор.
\x Всегда x, даже если это оператор
[xy] Символы x или y.
[x-z] СИмволы x, y или z.
[^x} Любой символ кроме x.
. Любой символ кроме перевода строки.
^x Символ x в начале строки.
<y>x Символ x, если lex находится в состоянии <y>.
x$ Символ x в конце строки.
x? Необязательный x.
x* 0, 1, 2 ... вхождений x.
x+ 1, 2, 3 ... вхождений x.
x|y x или y.
(x) x.
x/y x за которым следует y.
{xx} Подстановка xx из раздела определений.
x{m,n} Число вхождений x - от m до n.
YACC.
Обычно входная информация, читаемая программой, всегда обладает некоторой структурой. И про любую программу, читающую входной поток мы можем сказать, что она задает некоторый входной язык. Входной язык может быть либо сложным, как язык программирования, либо простым, выглядящим как последовательность чисел. Но, к сожалению, обычные средства ввода ограничены по возможностям, трудны в использовании и зачастую не содержат механизмов проверки корректности.
Yacc(CP) представляет собой универсальный инструмент для описания входного потока программ. Это имя является сокращением фразы «yet another compiler compiler» («еще один компилятор компиляторов»). Пользователь задает как структуру входного потока, так и фрагменты программ, вызываемых при распознавании объектов в потоке. Компилятор компиляторов (или генератор программ синтаксического разбора, далее просто генератор) переводит спецификацию в некоторую подпрограмму, управляющую процессом ввода. Часто оказывается удобным осуществлять управление пользовательской задачей с помощью этой подпрограммы.
Подпрограмма, построенная генератором, для чтения базовой входной лексемы вызывает предоставляемую пользователем функцию. Таким образом, пользователь может описывать входной поток либо в терминах отдельных символов, либо более высокоуровневыми конструкциями (именами, числами). Пользовательская функция может обрабатывать и некоторые особенности входного потока, такие, как комментарии и соглашения о продолжении, что обычно облегчает грамматическую спецификацию.
Генератор используется как для разработки компиляторов широко распространенных языков (языки Си, Паскаль и пр.), так и для нетрадиционных приложений (язык управления фотонаборной установкой, языки настольных калькуляторов, система доступа к документам, отладчик Фортрана).
Генератор предоставляет широкие возможности для задания структуры входного потока программы. Пользователь yacc задает спецификацию, управляющую процессом ввода, к которой относятся правила для описания структуры потока, фрагменты программ, вызываемые при распознавании этих правил, низкоуровневые функции для выполнения первичного ввода. По этой спецификации генератор строит функцию, управляющую процессом ввода. Эта функция, называемая синтаксическим анализатором, вызывает низкоуровневую пользовательскую подпрограмму (лексический анализатор), для выделения базовых элементов (лексем) из входного потока. Лексемы обрабатываются в соответствии с правилами, описывающими входной поток (грамматическими правилами). При распознавании такого правила вызывается соответствующий фрагмент пользовательской программы. Обратите внимание, что при этом можно возвращать значения, которые могут применяться в других фрагментах.
Сам генератор написан на мобильном диалекте языка Си, все действия и генерируемые подпрограммы также записываются на Си. Более того, большинство синтаксических соглашений также соответствуют языку Си.
Спецификации
для синтаксического анализатора yacc.
К нетерминальным символам или лексемам обращаются по именам. Yacc требует непосредственного объявления имен лексем. В дополнение, по причинам, объясняемым ниже, часто желательно включение лексического анализатора как части файла спецификации. Может оказаться полезным и включения ряда других программ. Таким образом, любой файл спецификации состоит из трех частей: объявлений, правил и программ. Части (или разделы) разделяются двойным знаком процента (%%). (Символ процента часто применяется в спецификациях в виде специального символа.)
Другими словами, полная спецификация может быть записана следующим образом:
объявления
%%
правила
%%
программы
Раздел объявлений может быть пустым. Более того, если опускается раздел программ, то второй разделитель %% можно не указывать. Тогда минимальная спецификация выглядит как
%%
правила
Пробелы, табуляции и переводы строк игнорируются. Они также не могут появляться в именах или многолитерных зарезервированных символах. Комментарии могут появляться в любой позиции имени, их синтаксис совпадает с синтаксисом комментариев в Си.
Раздел правил состоит из одного или более грамматических правил. Грамматическое правило записывается в формате
A : BODY ;
A представляет собой нетерминальное имя, BODY - последовательность имен и литералов (возможно пустую).
Имена могут быть произвольной длины и составляются из букв, точки, подчеркивания и цифр. Цифры в начале имени не допускаются. Прописные и строчные буквы считаются различными. Имена, используемые в теле грамматического правила, могут являться как лексемами, так и нетерминальными символами.
Литерал представляет собой символ, заключенный в апострофы. Так же, как и в Си, обратная дробная черта служит механизмом экранирования внутри литералов, распознаются все специальные последовательности языка Си:
\n Перевод строки
\r Возврат каретки
\' Апостроф
\ Обратная дробная черта
\t Табуляция
\b Шаг назад
\f Перевод формата
\xxx Восьмеричное число xxx
По ряду причин символ NUL (ПУС, \0 или 0) никогда не должен использоваться в грамматических правилах.
Если у нескольких правил одинаковая левая часть, во избежание ее повторения может применяться символ |. Точка с запятой в конце правила перед вертикальной чертой может опускаться. Таким образом, следующие правила:
A:B C D;
A:E F ;
A:G ;
могут быть записаны как:
A:B C D;
|E F
|G;
Хотя и необязательно, чтобы все правила с одинаковой левой частью находились рядом, это делает спецификации более читаемыми и облегчает внесение изменений.
Если нетерминальный символ соответствует пустой строке, можно записать следующую конструкцию:
empty:;
Имена, представляющие лексемы, должны объявляться явно. Это можно сделать в разделе объявлений:
%token name1 name2 ...
Из всех нетерминальных символов один, называемый начальным, играет особую роль. Анализатор строится так, чтобы распознавать начальный символ; таким образом, он должен описывать самую большую, наиболее общую структуру, представляемую грамматическими правилами. По умолчанию, начальным символом считается левая часть первого грамматического правила в разделе правил. Возможно и желательно явно объявить начальный символ в разделе объявлений с помощью ключевого слова %start:
%start list
Конец ввода анализатора отмечается специальной лексемой, называемой конечным маркером. Если лексемы вплоть до конечного маркера (но не включая его) образуют структуру, удовлетворяющую определению начального символа, функция анализатора возвращает управление вызывающей программе. Если конечный маркер распознается в другом контексте, это считается ошибкой.
Возврат конечного маркера - задача разрабатываемой пользователем функции лексического анализа. Обычно конечный маркер соответствует некоторому очевидному состоянию ввода-вывода: концу файла или концу записи.
Действия.
С каждым правилом может быть связано действие, выполняемое при распознавании во входном потоке объекта, удовлетворяющего правилу. Эти действия могут возвращать значения и воспринимать значения, возвращаемые другими действиями. Более того, при желании лексический анализатор может возвращать значения для выделяемых лексем.
Действие - это произвольный оператор языка Си. В нем можно выполнять ввод-вывод, вызывать подпрограммы и изменять внешние переменные или массивы. Действие указывается как один или несколько операторов в фигурных скобках.
Для упрощения связи между действиями и анализатором операторы действий слегка изменяются. В качестве механизма сигнализации в этом контексте используется знак доллара.
Для возврата значения действие обычно присваивает псевдопеременной $$ какое-либо значение. Например, действие, которое ничего не выполняет кроме возврата 1:
{$$=1;}
Для получения значений, возвращаемых предыдущими действиями и лексическим анализатором, действие может пользоваться псевдопеременными $1, $2, ..., которые соответствуют значениям, возвращаемым правой частью правила, слева направо. Тогда, если правило выглядит как
A:B C D ;
то $2 - значение, возвращаемое C, $3 - значение, возвращаемое D.
Лексический анализ.
Для чтения входного потока и передачи лексем (при необходимости, со значениями) программе разбора пользователь должен разработать лексический анализатор. Лексический анализатор - функция, возвращающая целое, с именем yylex. Функция возвращает целое число, называемое номером лексемы, которое обозначает тип прочитанной лексемы. Если с лексемой связано значение, оно должно присваиваться внешней переменной yylval.
Для нормального взаимодействия между программой разбора и синтаксическим анализатором номера лексем должны быть согласованы. Номера выбираются либо yacc, либо пользователем.
Этот механизм ведет к построению легко понимаемых и модифицируемых лексических анализаторов. Единственное ограничение состоит в необходимости избегать имен лексем, совпадающих с зарезервированными словами языка Си или анализатора. Например, использование лексем if или while наверняка приведет к серьезным трудностям при компиляции. Лексема error зарезервирована для обработки ошибок и должна применяться осознанно.
Как уже упоминалось, номера лексем могут выбираться либо самим построителем, либо пользователем. По умолчанию они выбираются построителем. Номер по умолчанию для литерального символа - числовое значение его кода в наборе символов. Другие имена получают номера, начиная с 257.
Для явного присвоения лексеме номера после первого вхождения имени в разделе определений необходимо указать неотрицательное целое число. Это число считается номером имени или литерала. Имена или литералы, не затронутые этим механизмом, сохраняют значения по умолчанию. Важно отметить, что все номера должны быть различными.
По историческим причинам, конечный маркер должен нумероваться либо нулем, либо отрицательным числом. Этот номер не должен переопределяться пользователем. Таким образом, все лексические анализаторы должны при достижении конца входного потока возвращать либо 0, либо отрицательное число в качестве номера лексемы.
Как работает построитель.
Yacc переводит спецификацию в программу на Си, которая и обрабатывает входной поток в соответствии с заданными правилами. Алгоритм получения программы разбора по спецификации довольно сложен и здесь рассматриваться не будет. Сама же программа разбора относительно несложна, и понимание принципов ее работы хотя и не обязательно, может существенно облегчить процедуру построения функций обработки ошибок и анализ возможных неоднозначностей.
Получаемая программа разбора является стековым конечным автоматом. Также существует возможность чтения и запоминания следующей входной лексемы, называемой очередной. Текущее состояние всегда находится в вершине стека. Состояниям конечного автомата присвоены метки в виде небольших целых чисел. В начале работы автомат находится в состоянии 0 и стек содержит только метку 0; очередная лексема не прочитана.
Автомат может выполнять четыре типа действий: сдвиг, свертка, ввод и ошибка. Операция программы разбора выполняется следующим образом:
1. Основываясь на текущем состоянии, программа разбора определяет, нужна ли для выполняемого действия очередная лексема. Если да, а она не прочитана, для ее ввода вызывается функция yylex.
2. Используя текущее состояние и, при необходимости, очередную лексему, программа разбора определяет следующее действие и выполняет его. Это может привести к помещению состояний в стек или их извлечению из стека, а также к обработке или обходу очередной лексемы.
Наиболее распространенным действием служит сдвиг. Для этого действия всегда нужна очередная лексема. Например, в состоянии 56 может выполняться следующее действие:
IF shift 34
Это означает, что если очередная лексема есть IF, состояние 56 заталкивается в стек, а текущим состоянием (верхушка стека) становится 34. Очередная лексема обнуляется.
Свертка нужна для ограничения роста стека. Это действие уместно при обнаружении правой части грамматического правила и подготовке к замене ее левой частью. Иногда для выяснения необходимости свертки нужно проверить очередную лексему, но чаще всего без этого можно обойтись. Фактически, действием по умолчанию (обозначаемым символом `.') обычно служит свертка.
Свертка часто связывается с отдельными грамматическими правилами. Эти правилам также присваиваются небольшие целые числа, что ведет к путанице. Действие
. reduce 18
ссылается на правило 18, а действие
IF shift 34
ссылается на состояние 34.
Предположим, что свертываемое правило выглядит следующим образом:
A: x y z;
Свертка зависит от символа в левой части (в данном случае A) и количества символов в правой части (в данном случае три). Для свертки из стека выталкиваются три состояния. (В общем случае, количество выталкиваемых состояний равно количеству символов в правой части.) Фактически, эти действия были помещены в стек при распознавании x, y и z и больше они не нужны. После этого текущим состоянием становится состояние, в котором находился распознаватель перед обработкой правила. С помощью этого состояния и символа в левой части правила выполним сдвиг A. Полученное новое состояние помещается в стек, и разбор продолжается. Однако, существуют значительные различия между обработкой символа в левой части и обычным сдвигом лексемы, поэтому это действие называется переходом. В частности, очередная лексема при сдвиге очищается, а при переходе нет. В любом случае новое состояние содержит строку вида:
A goto 20
вследствие чего состояние 20 помещается в стек и становится текущим.
Фактически, свертка переводит стрелку часов распознавателя назад, выталкивая состояния из стека и приводя его к моменту первого обнаружения правой части правила. Распознаватель введет себя так, как если бы он впервые увидел левую часть правила. Если правая часть правила пуста, состояния из стека не выталкиваются, выявленное состояние становится текущим.
Свертка также существенна при обработке задаваемых пользователем значений и действий. При свертывании правила программный фрагмент, связанный с ним, выполняется перед выравниваем стека. В дополнение к стеку, содержащему состояния, существует стек, в котором содержатся значения, возвращаемые лексическим анализатором и действиями. При сдвиге ввнешняя переменная yylval копируется в стек значений. Свертка выполняется после возврата из пользовательского фрагмента. При переходе в стек значений копируется внешняя переменная yyval. К стеку значений можно обращаться по именам псевдопеременных $1, $2 и т.д.
Два других действия распознавателя значительно проще. Ввод означает, что распознана входная информация, удовлетворяющая спецификации. Это действие выполняется только если очередная лексема является конечным маркером, и означает успешное завершение работы. Действие по ошибке, напротив, сигнализирует, что распознаватель больше не может продолжать обработку спецификации. Входная лексема вместе с очередной не удовлетворяют ни одному правилу. Распознаватель сообщает об ошибке и пытается возобновить работу.
По умолчанию применяются два правила однозначности:
1. В конфликте сдвиг-свертка предпочтение отдается сдвигу.
2. В конфликте свертка-свертка предпочтение отдается первой встреченной свертке.
Первое правило говорит о том, что применение свертки откладывается в пользу сдвига. Правило 2 дает пользователю негибкий метод управления, поэтому рекомендуется избегать подобных конфликтов.
Конфликты могут возникать либо вследствие ошибок во входной спецификации, либо потому, что для обработки корректных правил нужен распознаватель более сложный, нежели генерируемый yacc.
Обработка ошибок.
Обработка ошибок довольно сложное дело, так как большинство ситуаций связано с семантикой. При обнаружении ошибок может понадобиться, например, освободить память для дерева разбора, удалить или изменить строки в таблице символов и, что чаще всего, установить некоторые флаги для подавления генерации выходной информации.
При обнаружении ошибок прекращение обработки обычно неприемлемо. Более полезным является продолжение просмотра для обнаружения возможных ошибок. Это ведет к необходимости повторного запуска распознавателя после ошибки. Существует общий класс алгоритмов для этих действий, который включает в себя отбрасывание из входной строки ряда лексем и попытки изменить состояние распознавателя для продолжения обработки.
Для того, чтобы пользователь мог управлять этим процессом, yacc предоставляет простое, но достаточно универсальное средство. Для обработки ошибок зарезервирована лексема с именем error. Это имя может использоваться в грамматических правилах: им отмечаются места, где может встретиться ошибка и где необходимо провести восстановление. Распознаватель выталкивает состояния из стека до тех пор, пока не найдет состояние, в котором error допустимо. Далее считается что error - очередная лексема, и выполняются соответствующие действия. Затем значение очередной лексемы устанавливается равным лексеме, вызвавшей ошибку. Если никаких других правил не указано, при обнаружении ошибки обработка прекращается.
Среда выполнения yacc.
Если на вход yacc подать спецификацию, на выходе получается файл с программой на Си, чаще всего называемый y.tab.c. В нем содержится функция, возвращающая целое, по имени yyparse(). Для получения входных лексем эта функция вызывает функцию лексического анализатора yyerror(). Далее, либо будет обнаружена ошибка и в этом случае (если не задано действий по обработке ошибок) yyparse() вернет 1, либо лексический анализатор вернет конечный маркер и распознаватель завершит обработку возвратом 0.
Для получения работающей программы пользователь должен снабдить распознаватель некоторой средой выполнения. Например, как у любой программы на Си должна существовать функция main, всегда вызывающая yyparse(). Далее. для печати сообщений об ошибках должна вызываться функция yyerror().
Эти функции в той или иной форме должны задаваться пользователями.
Аргументом функции yyerror() служит строка, содержащая сообщение об ошибке. Прикладная программа наверняка должна выводить некоторую конкретную фразу. Обычно отслеживаются номера строк и при ошибке выводится номер строки ошибочного оператора. Во внешней переменной yychar хранится номер очередной лексемы в момент обнаружения ошибки. Это может помочь при выдаче полезной диагностики.
Lex и yacc.
lex может использоваться как самостоятельно для несложных преобразований, так и как средство анализа и сбора статистики на лексическом уровне. Он также может применяться для построения программ лексического анализа, они особенно хорошо стыкуются с программами, сгенерированными yacc. Программы lex распознают только регулярные выражения, а программы, построенные yacc, воспринимают довольно широкий класс контекстно-свободных грамматик, но требуют анализатора низкого уровня для распознавания входных лексем. Таким образом, сочетание yacc и lex часто оказывается весьма неплохим решением. Если lex используется как препроцессор к программе разбора, он разбивает входной поток на фрагменты, которым программа синтаксического разбора ставит в соответствие некоторые структуры. К программам, построенным с помощью lex, несложно добавить программы, построенные другими генераторами или написанными вручную. Пользователи yacc заметят, что имя программы yylex совпадает с именем программы входного разбора, которое требует yacc. Это облегчает взаимодействие двух генераторов.
Из регулярных выражений, задаваемых во входной спецификации lex строит детерминированный конечный автомат. Для экономии памяти автомат не компилируется, а интерпретируется. Несмотря на это анализатор все же остается достаточно быстрым. В частности, время, необходимое для распознавания и разбора входного потока, пропорционально его длине. При определении скорости количество и сложность входных правил не имеют значения, если только правила с правым контекстом не требуют значительного объема повторных просмотров. Количество и сложность правил увеличивают размер конечного автомата, а, следовательно, и размер генерируемой программы.
Если вы хотите использовать эти две программы совместно, обратите внимание, что lex называет свою программу yylex, то есть именем, которое требует yacc для своего анализатора. Обычно это функцию вызывает головная программа по умолчанию (main) из библиотеки lex, но если используется также и yacc со своей головной программой, функцию будет вызывать он. В этом случае каждое правило должно заканчиваться
return (token);
возвращая соответствующую лексему. Несложный способ получения доступа к именам лексем yacc - включение выходного файла lex как части выходного файла yacc с помощью строки:
#include "lex.yy.c"
Соответствие команд nroff и HTML, а также их внутреннее представление.
.br BREAKLINE <BR> (LS раз)
.sp argument SPACE <SPACER
type=vertical
size=argument*30>
.bd argument BOLD <B> (Действует на
argument строк)
.ul argument UNDERLINE <U> (Действует на
argument строк)
.cu SUNDERLINE <U> (Действует на
одну строку)
.ce SCENTER <CENTER> (Действует
на одну строку)
.ft argument FONT <FONT
face=argument>
.ps argument SIZE <FONT
size=argument>
.ad argument ADJUST <DIV
align=argument>
.na NOADJUST <PRE>
.fi FILL tFILL=1
.nf NOFILL tFILL=0
.ls argument LINESPACE LS=argument
.ll LINELENGTH Команда поглоща-
ется, но игнорируется
.in argument IN cIN=argument
.ti argument TIN cTIN=argument
.ex EXIT Завершение работы
Описание файлов системы разработки транслятора.
Описание файла nroff2html.lex.
Лексический анализатор lex обрабатывает входной файл. В данном случае производится «механическая» обработка, то есть lex просто распознает лексемы, но не предпринимает никаких действий по отношению к ним, а передает это право yacc’у.
Считывание идет посимвольное, при этом если первый символ в строке не является ‘.’ или символом перевода строки, то строка распознается как текст, то есть в yacc передается соответствующее предупреждение.
Если первый символ в строке – ‘.’, то за ним следует команда. Следующие два символа сравниваются с командами, имеющимися в банке данных, и при идентификации имя опознанной команды передается в yacc. В случае, если команда неизвестна (то есть за точкой идут два символа и пробел либо символ табуляции, но она не совпадает ни с одной из имеющихся в БД), то сама команда поглощается при выводе (не выводится), а текст, к которому эта команда относится, выводится в HTML-файл соответственно с предыдущими установками.
Comarg – аргумент команды. В данной программе различаются четыре варианта аргумента: либо пустой, либо цифровой (darg), либо символьный – единственный символ - (char), либо строка (символ и еще один или несколько символов, кроме пробела и табуляции). Различие символьного и строкового аргумента заключается в особенности lex’а – если какая-то лексема удовлетворяет нескольким правилам, то выбирается то правило, которое представляет лексему большей длины.
В файле есть функция Dlex(T) – выполняющая роль «монитора» при отладке программы.
При компиляции этого файла в результирующий файл будут включены стандартные библиотеки math.h, stdio.h, которые обеспечат поддержку математических операций и стандартного ввода/вывода.
Описание файла nroff2html.yacc.
В этом файле содержится описание действий, сопоставляющихся команде, передаваемой из lex’а.
В начальном разделе этого файла должны быть описаны ВСЕ лексемы-команды, которые могут быть переданы из lex’а.
Помимо этого в файле есть несколько функций.
Dyacc – аналог такой же функции в .lex-файле – выполняет роль «монитора», выдавая дебагговские сообщения при отладке.
Переменные:
c… - счетчики для подсчета строк. Три состояния: -1 – счетчик выключен, >0 – счетчик включен, =0 – счетчик сработал, пора выводить закрывающий тэг.
t… - триггеры, используются при использовании различных шрифтов. Связано с некоторым различием: в nroff вызов нового шрифта автоматически прекращает действие предыдущего, а в HTML необходим закрывающий тэг.
tFILL – есть заполнение или нет
cIN – отступ (число пропусков)
cTIN – временный отступ
Отличие отступа от временного отступа в формате nroff заключается в следующем: временный отступ действует лишь на одну строку и является «вложенным» по отношению к общему отступу. Временный отступ отмеряется от общего и может быть положительным (сдвиг вправо) и отрицательным (сдвиг влево). Счетчику присваивается значение, соответствующее количеству строк, на которое действует правило, а потом идет декрементирование до нуля, когда включается закрывающий тэг. Временный отступ отключается командой .in с нулевым аргументом (то есть отступ равен нулю).
LS – количество строк в пустом пробеле (действует на весь текст). В nroff команда .ls задает пробел между выводимыми строками.
nhtext[YYLMAX] – массив символов. Из lex в yacc передается через yylval(int) – рабочая переменная, в которой хранится значение команды; или через yytext([char]) – хранится то, что взял lex, то есть непосредственно лексема.
$$ - внутренняя псевдопеременная yacc.
Правила в yacc имеют структуру дерева, где корнем является правило list – список строк, описывающий весь входной файл. Далее идет детализация правил, спускаясь к лексемам.
Схема действия проста: lex опознает лексему и передает соответствующую команду в yacc, а далее yacc запрашивает lex на предмет опознания аргумента.
Существует функция breakline – она призвана для реализации команды .ls. Breakline вставляет в результирующий HTML-файл столько тэгов <BR> (перенос строки), сколько было передано в качестве аргумента командой .ls.
Если yacc встречает неизвестную команду, то текст выводится в соответствии с предыдущими настройками, а в поток ошибок выдается соответствующее сообщение.
В файл y.tab.c после компиляции включается в исходном виде все, что в файле nroff2html.yacc заключено между %{ и %} (в разделе объявлений), в том числе файл lex.yy.c, полученный при компиляции nroff2html.lex.
Описание файла nroff2html.c.
nroff2html.c – исходный текст головной программы, при компиляции этого файла образуется исполняемый модуль.
При компиляции включается файл y.tab.c, то есть все вышеперечисленные файлы.
Формат запуска исполняемого модуля таков:
nroff2html input_file output_file
При этом оба аргумента могут быть опушены, и в этом случае роли входного и выходного файлов выполняют соответственно стандартный вход (клавиатура) и стандартный выход (дисплей).
Если же есть аргументы, то программа переходит к имени входного файла и открывает свое устройство (yyin) для чтения. Далее переход ко второму аргументу и открытие соответствующего устройства (yyout) для записи.
Далее в результирующий файл записываются стандартные открывающие тэги для HTML-файла (<HTML>, <HEAD>, <TITLE>, </title>, </head>, <BODY>).
Функция yyparse() обращается к части, образованной из nroff2html.yacc – содержит описание того как yacc обрабатывает файл (включая ошибки). Для получения входных лексем эта функция вызывает функцию лексического анализатора yyerror(). Далее, либо будет обнаружена ошибка и в этом случае (если не задано действий по обработке ошибок) yyparse() вернет 1, либо лексический анализатор вернет конечный маркер и распознаватель завершит обработку возвратом 0.
По окончании отработки своего функцией yyparse(), программа nroff2html.c вписывает закрывающие основные тэги HTML-файла: </body> и </html>.
Описание файла y.output.
Этот файл подробно показывает КАК реально все выполняется и когда какое правило применяется. Файл представляет из себя набор состояний для yacc’а. При этом показывается какие правила и как в этих состояниях выполняются.
Поясню лишь некоторые функции:
goto – безусловный переход к состоянию.
reduce i – заносит текущее состояние в стек и переход к i.
shift – замена состояния в стеке.
Строка $accept : _list $end – означает взять весь файл.
Описание команд.
SPACE .sp - (с аргументом) SPACER
LINESPACE .ls - (с аргументом) определяет LS, используется при выводе разрывов строки в HTML.
BOLD .bd - (с аргументом) включает триггер, вставляет <B>, включает счетчик.
UNDERLINE .ul - аналогично с BOLD
SUNDERLINE .cu - (без аргумента) подчеркнуть одну строку. Счетчик = 1.
SCENTER .ce - (без аргумента) Центрирование одной строки. Счетчик = 1.
BREAKLINE .br - вызывается функция вставки breakline, если LS, то соответствующее число раз.
FONT .ft - (с аргументом) если триггер включен, то закрывает существующий font, выводит тэг <FONT face= “имя_аргумента”.
SIZE .ps - аналогично с FONT, но передает размер.
ADJUST .ad - если включен триггер преформатирования, то она его отключает, если было другое форматирование – отключаем его, включаем триггер, тэг <DIV align= соответствующее_выравнивание.
NOADJUST .na - дальше идет уже отформатированный текст. Отключаются предыдущие установки.
LINELENGTH .ll - обрабатывается (берется), но просто игнорируется, так как в HTML в отличие от nroff существует горизонтальная полоса прокрутки.
IN .in - отступ
TIN .ti - временный отступ
FILL .fi - заполнение (растягивание текста от края до края). Если уже есть ADJUST, то FILL игнорируется.
NOFILL .nf - отключает FILL.
UNKNOW - неизвестная команда.
EXIT .ex - возвращает 0 (завершает работу).
Определение команд для HTML-файла.
SPACE - вставка свободного пространства. Используется команда SPACER – высота пробела высчитывается по формуле: количество_строк*30, так как в spacer передается в качестве аргумента количество пикселей.
LINESPACE - определяет переменную LS.
BOLD - для соответствующего текста вставляет тэг <B>.
UNDERLINE - для соответствующего текста вставляет тэг <U>.
SUNDERLINE - для соответствующего текста вставляет тэг <U>.
Примечание: эти две команды аналогичны, но в SUNDERLINE действие производится лишь над одной строкой.
SCENTER - для соответствующего текста вставляет тэг <CENTER>.
BREAKLINE - вызывает функцию breakline.
FONT - если уже было открытие какого-то шрифта, то сначала вставляет тэг </font>, затем для соответствующего текста вставляет тэг <FONT face=имя_аргумента>.
SIZE - так же как и FONT, но в качестве аргумента передается не имя шрифта, а его размер.
ADJUST - если уже было открыто преформатирование или выравнивание, то сначала оно закрывается соответствующими тэгами (</pre>, </div>), а затем для соответствующего текста вставляет тэг <DIV align=соответствующий_тип_выравнивания>
NOADJUST - если уже было открыто преформатирование или выравнивание, то сначала оно закрывается соответствующими тэгами (</pre>, </div>), а затем для соответствующего текста вставляет тэг <PRE>.
LINELENGTH - игнорируется, благодаря горизонтальной полосе прокрутки, существующей в браузерах.
IN - соответствующей переменной присваивается значение, передаваемое аргументом.
TIN - соответствующей переменной присваивается значение, передаваемое аргументом.
FILL - соответствующей переменной присваивается значение 1.
NOFILL - соответствующей переменной присваивается значение 1.
UNKNOW - есть два варианта: с аргументом и без него. Выдается (в поток ошибок) сообщение о неизвестной команде.
EXIT - завершение работы.
Когда встречаются аргументы, их преобразуют соответствующим образом в переменные (численные, символьные или строковые).
Если встречается текстовая строка, то действия предпринимаются следующие:
если включен временный отступ, то в выходной HTML-файл вводится соответствующее количество символов непереносимого пробела ( );
если включен общий отступ, выполняется аналогичная операция.
Далее выводится сама текстовая строка, после чего идет серия декрементирования и проверок счетчиков, относящихся к выделению, подчеркиванию, центрированию и т.п., и если какой-то счетчик сработал, то есть действие его уже выполнено на необходимое количество строк, то выводится соответствующий закрывающий тэг (</b>, </u>, </center>).
Ну и, наконец, если встречается просто пустая строка, то транслятор просто передает в выходной файл функцию breakline (то есть вставку тэга <BR>).
Экономическое обоснование разработки НИОКР.
1. РАСЧЕТ ЗАТРАТ ВРЕМЕНИ НА РАЗРАБОТКУ ТРАНСЛЯТОРА.
1.1. Для начала необходимо определить продолжительность создания транслятора. Определим весь перечень работ по всем этапам разработки информационной системы.
Этапы создания транслятора:
Этап 1
Техническое задание.
Получение задания, его обработка, а также согласование задания и его деталей с консультантом.
Этап 2
Техническое предложение.
Изучение ОС Linux и ее компонент – lex, yacc.
Этап 3
Эскизное проектирование.
Изучение подходов к написанию трансляторов.
Этап 4
Техническое проектирование.
Разработка алгоритмов решения задачи.
Этап 5
Рабочий проект.
Разработка структуры программного обеспечения.
Этап 6
Изготовление опытного образца.
Непосредственно программирование.
Этап 7
Испытание опытного образца.
Отладка программы.
Этап 8
Оформление документации.
По формуле 1.1 рассчитывается ожидаемое время выполнения каждой работы  . .
 , где (1.1) , где (1.1)
 - минимальная продолжительность работы, т.е. время, необходимое для выполнения работы при наиболее благоприятном стечении обстоятельств ( час, дни, недели и т.д. ); - минимальная продолжительность работы, т.е. время, необходимое для выполнения работы при наиболее благоприятном стечении обстоятельств ( час, дни, недели и т.д. );
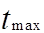 - максимальная продолжительность работы т.е. время, необходимое для выполнения работы при наиболее неблагоприятном стечении обстоятельств (час, дни, недели и т.д. ) - максимальная продолжительность работы т.е. время, необходимое для выполнения работы при наиболее неблагоприятном стечении обстоятельств (час, дни, недели и т.д. )
Для определения возможного разброса ожидаемого времени определяется дисперсия (рассеивание) 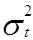
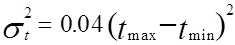 (1.2) (1.2)
Составим таблицу значений по каждой работе каждого этапа:
Таблица 1.1.
| Этапы
|
|
|
|
|
| 1
|
5
|
10
|
7
|
1
|
| 2
|
40
|
50
|
44
|
4
|
| 3
|
4
|
5
|
4.4
|
0.04
|
| 4
|
5
|
8
|
6.2
|
0.36
|
| 5
|
4
|
6
|
4.8
|
0.16
|
| 6
|
50
|
60
|
54
|
4
|
| 7
|
17
|
21
|
18.6
|
0.64
|
| 8
|
6
|
7
|
6.4
|
0.04
|
1.2. Исполнителем каждого этапа является студент-дипломник, т.е. возможно только последовательное выполнение всех работ.
2. РАСЧЕТ СТОИМОСТИ ОСНОВНЫХ ФОНДОВ, ИСПОЛЬЗУЕМЫХ ДЛЯ РАЗРАБОТКИ ТРАНСЛЯТОРА.
Первоначальная (балансовая) стоимость складывается из всех затрат, связанных с приобретением, сооружением и строительством основных производственных фондов.
К основным фондам при разработке транслятора можно отнести то оборудование, на котором выполнялась данная разработка:
Таблица 2.1
| Оборудование
|
Стоимость в $
|
| Компьютер
|
Процессор
|
150
|
| Материнская плата
|
120
|
| Оперативная память
|
160
|
| Видеокарта
|
35
|
| Модем
|
165
|
| Винчестер
|
200
|
| CD-rom
|
110
|
| Дисковод
|
25
|
| Корпус
|
36
|
| Клавиатура
|
12
|
| Мышь
|
7
|
| Принтер
|
300
|
| Монитор
|
480
|
Первоначальная (балансовая) стоимость основных фондов в соответствии с данными, приведенными в таблице 2.1, составит 1800$ или 45000 рублей (по курсу 1$ Þ 25 руб. – на апрель 1999 г.).
Первоначальная (остаточная) стоимость характеризует оценку основных производственных фондов по первоначальной (балансовой) стоимости за минусом общей суммы амортизационных отчислений на данный момент.
Общую сумму амортизационных отчислений на время начала выполнения дипломного проекта определим по формуле:
K*Ha
*t
 A = (2.1) A = (2.1)
Фд
где
K
- первоначальная балансовая стоимость основных фондов, руб.;
Ha
- норма годовых амортизационных отчислений, % (таблица 2.2.);
t
- реально использованное машинное время, час.;
Фд
- действительный фонд времени работы оборудования за год, час.
Таблица 2.2
Нормы амортизационных отчислений по отдельным видам
спец. оборудования (% от балансовой стоимости).
| НАИМЕНОВАНИЕ ОБОРУДОВАНИЯ
|
Норма амортиза-ционных отчислений
|
| Физико-термическое оборудование для производства изделий микроэлектроники и полупроводниковых приборов
|
28.2
|
| Контрольно-измерительное и испытательно-тренировочное оборудование для производства электронной техники
|
27.5
|
| Оборудование для измерения электрофизических параметров полупроводниковых приборов
|
27.3
|
| Оборудование для механической обработки полупроводниковых материалов
|
23.9
|
| Вакуумное технологическое оборудование для нанесения тонких пленок
|
24.3
|
| Оборудование для производства фотошаблонов
|
23.4
|
| Сборочное оборудование для производства полупроводниковых и электровакуумных приборов
|
23.8
|
| Электронные генераторы, стабилизированные источники питания, тиристорные выпрямители, регуляторы напряжения
|
15.5
|
| Прочее спецтехнологическое оборудование для производства изделий электронной техники
|
13.1
|
| Контрольно-измерительная и испытательная аппаратура связи, сигнализации и блокировки:
|
| Переносная
|
14.2
|
| Стационарная
|
8.5
|
| Лабораторное оборудование и приборы
|
20.0
|
| Электронные цифровые вычислительные машины общего назначения, специализированные и управляющие
|
12.0
|
Сумма амортизационных отчислений составит:
45000* 0.12* 1000
 A
= = 2288 руб. A
= = 2288 руб.
2360
Первоначальная (остаточная) стоимость составит:
45000 - 2288 = 42712 руб.
В начале каждого года все основные фонды должны пройти переоценку. Для этого вначале определяется первоначальная (остаточная) стоимость основных фондов, а затем полученная разность между первоначальной (балансовой) стоимостью и суммой амортизации, умножается на коэффициент пересчета. Полученное произведение будет называться первоначальной стоимостью основных производственных фондов на начало года. Коэффициент пересчета первоначальной стоимости основных фондов на 01.01.99 составлял 1.1 раза.
Первоначальная стоимость основных фондов для разработки транслятора на начало 1999 года составит:
Кп.с.
= 42712 * 1.1 = 46983,2 руб.
3. РАСЧЕТ ЗАТРАТ НА РАЗРАБОТКУ ТРАНСЛЯТОРА.
3.1. Расчет затрат на разработку транслятора.
Таблица 3.1
| Материальные ресурсы
|
Цена, руб.
|
| Книги
|
| "LINUX"
|
120
|
| HTML
|
15
|
| DEMOS32
|
50
|
| Программное обеспечение
|
| ОС Windows 95
|
625
|
| OS LINUX
|
190
|
Суммарные затраты составляют 1000 руб.
3.2. Заработная плата.
К основной зарплате при выполнении НИОКР относятся зарплата научных, инженерно-технических работников и рабочих НИИ и КБ. Их зарплата определяется по формуле 3.1.
 , где (3.1) , где (3.1)
 - тарифная ставка работника I-ого разряда - тарифная ставка работника I-ого разряда
= 83,49 руб;
 - тарифный коэффициент работника соответствующего разряда (таблица 3.2.); - тарифный коэффициент работника соответствующего разряда (таблица 3.2.);
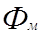 - месячный фонд времени, рабочие дни, = 21.8 дня; - месячный фонд времени, рабочие дни, = 21.8 дня;
 - фактически отработанное работником время, чел-дни. - фактически отработанное работником время, чел-дни.
Таблица 3.2.
Единая тарифная сетка по оплате труда работников бюджетной сферы.
| Разряды оплаты труда
|
Тарифные коэффициенты
|
Разряды оплаты труда
|
Тарифные коэффициенты
|
| 1
|
1.00
|
10
|
2.98
|
| 2
|
1.12
|
11
|
3.37
|
| 3
|
1.27
|
12
|
3.38
|
| 4
|
1.44
|
13
|
4.31
|
| 5
|
1.62
|
14
|
4.81
|
| 6
|
1.83
|
15
|
5.50
|
| 7
|
2.07
|
16
|
6.11
|
| 8
|
2.34
|
17
|
6.78
|
| 9
|
2.64
|
18
|
7.54
|
83,49 * 1.62 * 110
 Из.п.
= = 682.5 руб. Из.п.
= = 682.5 руб.
21.8
3.3. Дополнительная заработная плата составляет 10-20% от основной. Дополнительная зарплата с основной зарплатой образуют фонд оплаты труда.
Дополнительная заработная плата составит:
0.2 * 682.5 = 136.5 руб.
Фонд оплаты труда составит:
682.5 + 136.5 = 819 руб.
3.4. Амортизационные отчисления (без учета амортизационных отчислений на полное восстановление) определяются по формуле 3.2.
 , где (3.2.) , где (3.2.)
 - первоначальная (балансовая) стоимость основных фондов на начало года, руб.; - первоначальная (балансовая) стоимость основных фондов на начало года, руб.;
 - норма годовых амортизационных отчислений, % (таблица 2.2); - норма годовых амортизационных отчислений, % (таблица 2.2);
 - машинное время, необходимое для выполнения НИОКР, час.; - машинное время, необходимое для выполнения НИОКР, час.;
 - действительный фонд времени работы оборудования за год, час. - действительный фонд времени работы оборудования за год, час.
Амортизационные отчисления составят:
46983,2 * 0.12 * 400
 АНИОКР
= = 955,59 руб. АНИОКР
= = 955,59 руб.
2360
3.5. Косвенные расходы.
Косвенные расходы составляют 50-100% от фонда оплаты труда.
Косвенные расходы составят:
0.7 * 819 = 573.3 руб.
3.6. Расчет налогов.
Обязательные отчисления в государственные внебюджетные фонды
Таблица 3.3
| п/п
|
Наименование фонда
|
Ставка налога (%)
|
Объект налогообложения
|
| 1
|
Пенсионный фонд
|
28.0
|
Фонд оплаты труда и другие выплаты
|
| 1.0
|
Зарплата работающих
|
| 2
|
Фонд обязательного медицинского страхования
|
3.6
|
Фонд оплаты труда
|
| 3
|
Государственный фонд занятости
|
1.5
|
Фонд оплаты труда
|
| 4
|
Фонд социального страхования
|
5.40
|
Фонд оплаты труда, доходы от ценных бумаг и банковских вкладов. Добровольные взносы граждан и юридических лиц, ассигнования из бюджета РФ на пособия, компенсации
|
Учитывая, что фонд оплаты труда составляет 819 руб., зарплата работающих составляет 682.5 имеем следующие отчисления в государственные внебюджетные фонды:
Таблица 3.4
| п/п
|
Наименование фонда
|
Ставка
налога (%)
|
Отчисления
Руб.
|
| 1
|
Пенсионный фонд
|
28.0
1.0
|
229.32
6.83
|
| 2
|
Фонд обязательного медицинского страхования
|
3.6
|
29.48
|
| 3
|
Государственный фонд занятости
|
1.5
|
12.29
|
| 4
|
Фонд социального страхования
|
5.40
|
44.23
|
Суммарный налог в государственные внебюджетные фонды составит:
229.36 + 29.48 + 44.23 = 303.07 руб.
4.ФОРМИРОВАНИЕ РАСЧЕТНОЙ (ОСТАТОЧНОЙ) ПРИБЫЛИ ПРЕДПРИЯТИЯ И ОПРЕДЕЛЕНИЕ ЭФФЕКТИВНОСТИ ПРОИЗВЕДЕННЫХ ЗАТРАТ НА РАЗРАБОТКУ ТРАНСЛЯТОРА.
Для оценки и анализа эффективности произведенных затрат используется следующие показатели:
· договорная цена;
· доход (выручка) предприятия;
· прибыль;
· срок окупаемости затрат;
· коэффициент эффективности (рентабельность).
Договорная цена НИОКР - цена, устанавливаемая непосредственно предприятием-исполнителем по договоренности с предприятием-потребителем с учетом конъюнктуры рынка на основе сложившегося спроса и предложения.
Формируют договорную цену НИОКР затраты на их выполнение и прибыль, величина которой определяется исполнителем.
Установим договорную цену на разработанный транслятор в размере 1250 руб. Предположим, что доход (выручка) от реализации данного транслятора составила 1250*30=37500 руб.
Из дохода изымаются налоги на содержание жил. фонда и объектов соц.-культурной сферы, на имущество и на цели образования. Ставки данных налогов приведены в таблице 4.1.
Таблица 4.1.
Налоги.
| п/п
|
Вид налога
|
Ставка налога (%)
|
Объект налогообложения
|
| 1
|
Налог на прибыль предприятий
|
35.0
|
Балансовая прибыль
|
| 2
|
Налог на прибыль от посреднических операций предприятий
|
38.0
|
Прибыль от посреднических операций
|
| 3
|
Налог на имущество
|
2.0
|
Основные фонды, материальные активы
|
| 4
|
Налог на цели образования
|
1.0
|
Фонд оплаты труда
|
| 5
|
Налог на содержание жилищного фонда и объектов социально-культурной сферы
|
1.5
|
Объем реализации товаров и услуг
|
Учитывая, что стоимость основных фондов составляет 46983,2 руб., фонд оплаты труда – 819 руб., объем реализации - 37500 руб., имеем:
Таблица 4.2.
| Вид налога
|
Ставка
налога (%)
|
Величина
Налога
|
| 1.Налог на имущество
|
2.0
|
939,66
|
| 2.Налог на цели образования
|
1.0
|
8.19
|
| 3. Налог на содержание жилищного фонда и объектов социально-культурной сферы
|
1.5
|
562.5
|
Доход за вычетом налогов составляет:
37500 – ( 939,66 + 8.19 + 562.5 ) – 303.07 = 35686.58 руб.
Выручка от реализации транслятора за вычетом его себестоимости и всех вышеперечисленных налогов образуют балансовую прибыль.
Себестоимость складывается из материальных затрат, заработной платы, амортизационных отчислений и косвенных расходов. Себестоимость транслятора составляет:
С
= 1000 + 682.5 + 955,59 + 573.3 + 303,07 = 3514.46 руб.
Балансовая прибыль составляет:
37500 – 3514.46 = 33985.54 руб.
Балансовая прибыль, уменьшенная на налог на прибыль, образует расчетную (остаточную) прибыл. Ставка налога на прибыль составляет 35%:
 = 33985,54 - 0,35*33985,54 – 939,66 – 8,19 – 562,5 – 12,29 = 20567.96 руб. = 33985,54 - 0,35*33985,54 – 939,66 – 8,19 – 562,5 – 12,29 = 20567.96 руб.
Срок окупаемости затрат на выполнение НИОКР определяется по формуле:
 (лет) , где (4.1.) (лет) , где (4.1.)
 - себестоимость НИОКР, руб.; - себестоимость НИОКР, руб.;
- расчетная прибыль, руб.
Срок окупаемости транслятора составит:
tок
=
3514,46 / 20567,96 = 0.17 года
Коэффициент эффективности произведенных затрат на выполнение НИОКР определяется по формуле 4.2.
 (4.2.) (4.2.)
Коэффициент эффективности произведенных затрат на разработку транслятора:
1
 Кэф-ти
= *100% = 588 % Кэф-ти
= *100% = 588 %
0.17
5. ОЦЕНКА ЗНАЧИМОСТИ РАЗРАБОТКИ ТРАНСЛЯТОРА.
Для оценки значимости выполненной работы можно воспользоваться оценочными коэффициентами, учитывающими степень положительного эффекта от выполнения дипломного проекта:
* объем выполненных исследований,
* сложность решения задачи,
* уровень технической подготовки студента
* полноту использования современных методов выполнения исследований и разработок.
Значимость выполненных исследований и разработок можно выразить через коэффициент значимости Dзн, который определяется по формуле:
å Ki
Dзн = ¾¾¾ , (*)
å Kmax
где i=1,2,3,4; å Kmax = 40,0.
Величина коэффициента исследования или разработки изменяется в пределах от 0,1 до 1, т.е. 0,1≤ Dзн ≤1
Чем ближе к единице значение Dзн , тем более весома выполненная работа.
Определим значение коэффициента значимости дипломной работы.
1) В ходе работы над дипломным проектом разработан транслятор. Проблема создания такого транслятора является очень актуальной, т.к. многим пользователям ОС LINUX необходимо переводить свои рабочие файлы в более распространенный формат HTML. Поэтому степень положительного эффекта от выполнения дипломного проекта научно-исследовательского характера K1=6.5.
2) В ходе работы над дипломным проектом была освоена возможность создания программ-трансляторов с помощью LINUX-программ lex и yacc. Это можно считать выполнением основной части исследования. Таким образом объем выполненных исследований и разработок K2=4,0.
3) Cложность решения задачи в дипломной работе научно-исследовательского характера K3=7,0.
4) В ходе работы над дипломным проектом использовались современные средства электронно-вычислительой техники (персональный компьютер Pentium 120 с операционной системой Windows-95). Поэтому уровень научно-технической подготовки студента K4=6,0.
Коэффициент значимости равен :
å KI 6,5 + 4,0 + 7,0 + 6,0
Dзн = ¾¾¾ = ¾¾¾¾¾¾¾¾¾¾ = 0,59
å Kmax 40,0
Полученный коэффициент значимости указывает на достаточно высокий уровень выполненных исследований и разработок.
Промышленная экология и безопасность. Общие положения.
1.1.Характеристика условий труда оператора ЭВМ
Условия труда оператора характеризуются возможностью воздействия на них комплекса опасных и вредных факторов: шума, тепловыделений, вредных веществ, радиоактивных, электромагнитных излучений, недостаточной или избыточной освещенности рабочих мест, высокого напряжения, давлений, существенно отличных от атмосферного, нервно-психические перегрузки (умственное перенапряжение, перенапряжение анализаторов, эмоциональные перегрузки) и т.д. Вредные факторы могут влиять на оператора не только непосредственно, вызывая функциональные изменения в организме и, как следствие, профессиональные заболевания, но и воздействуют опосредованно на психику человека, снижая скорость реакции, ухудшая внимание: шум снижает концентрацию внимания, оказывает эмоциональное воздействие, вибрации вызывают уменьшение разрешающей способности и остроты зрения...
1.1.1.Требования к защите от шума и вибраций
1.1.1.1.Фоновый уровень шума не должен превышать 40 дБА, (при работе систем воздушного отопления, вентиляции и кондиционирования - 35 дБА), а во время работы на ПЭВМ 50 дБА (таблица 10) (см. [5],[6],[7]). Нормативные уровни шума обеспечиваются использованием малошумного оборудования, применением звукопоглощающих материалов для облицовки помещений, а также различных звукоизолирующих устройств.
Таблица 1.
Допустимые уровни звука, эквивалентные уровни звука и уровни звукового давления в октавных полосах частот при работе на ПЭВМ
| Уровни звукового давления, дБ
|
Среднегеометрические частоты октавных полос, Гц
|
Уровни звука, эквивалентные уровни звука, дБА
|
| 86
|
31.5
|
| 71
|
63
|
| 61
|
125
|
50
|
| 54
|
500
|
| 49
|
1000
|
| 45
|
2000
|
| 40
|
4000
|
| 38
|
8000
|
50
|
1.1.1.2. Время реверберации в помещениях с ПЭВМ не должно быть более 1 с. Частотная характеристика времени реверберации в диапазоне частот 250-4000 Гц должна быть ровной, а на частоте 125 Гц спад времени реверберации должен составлять не более 15%.
1.1.1.3. Вибрация не должна превышать нормируемых значений (таблица 11) (см.[7] п.5.4).
Таблица 2.
Допустимые нормы вибрации на рабочих местах с ПЭВМ.
| Среднегеометрические частоты октавных полос, Гц
|
Допустимые значения
|
| по виброскорости
|
по виброускорению
|
| м/с2
|
дБ
|
м/с
|
дБ
|
| 2
|
5,3´10
|
25
|
4,5´10
|
79
|
| 4
|
5,3´10
|
25
|
2,2´10
|
73
|
| 8
|
5,3´10
|
25
|
1,1´10
|
67
|
| 16
|
1,1´10
|
31
|
1,1´10
|
67
|
| 31.5
|
2,1´10
|
37
|
1,1´10
|
67
|
| 63
|
4,2´10
|
43
|
1,1´10
|
67
|
1.1.2.Требования к микроклимату, содержанию аэроионов и вредных химических веществ в воздухе помещений эксплуатации ПЭВМ
1.1.2.1. В производственных помещениях, в которых работа на ПЭВМ является основной (диспетчерские, операторские, расчетные, кабины и посты управления, залы вычислительной техники и др.), должны обеспечиваться оптимальные параметры микроклимата (таблица 12) (см.[9] п.4.1). Интенсивность теплового облучения оператора от осветительных приборов, инсоляции на постоянных и непостоянных рабочих местах не должна превышать 35Вт/м2
при облучении 50% поверхности тела и более , 70Вт/м2
при облучении от 25 до 50% и 100Вт/м2
- при облучении не более 25% поверхности тела. Тепловыделение регулируется устройством эффективных систем вентиляции и кондиционирования.
Таблица 3.
Оптимальные нормы микроклимата для помещений с ПЭВМ.
| Период года
|
Категория работ
|
Температура воздуха, о
С
не более
|
Относительная влажность воздуха, %
|
Скорость движения воздуха, м/с
|
| Холодный
|
легкая-1а
легкая-1б
|
22-24
21-23
|
40-60
40-60
|
0,1
0,1
|
| Теплый
|
легкая-1а
легкая-1б
|
23-25
22-24
|
40-60
40-60
|
0,1
0,2
|
Примечания: к категории 1а относятся работы, производимые сидя и не требующие физического напряжения, при которых расход энергии составляет до 120 ккал/ч; к категории 1б относятся работы, производимые сидя, стоя или связанные с ходьбой и сопровождающиеся некоторым физическим напряжением, при которых расход энергии составляет от 120 до 150 ккал/ч.
1.1.2.2. Уровни положительных и отрицательных аэроионов в воздухе помещений с ПЭВМ должны соответствовать нормам, приведенным в таблице 13.
Таблица 4.
Уровни ионизации воздуха помещений при работе на ПЭВМ
| Уровни
|
Число ионов в 1 см воздуха
|
| n+
|
n-
|
| Минимально необходимые
|
400
|
600
|
| Оптимальные
|
1500-3000
|
3000-5000
|
| Максимально допустимые
|
50000
|
5000
|
1.1.2.3. Содержание вредных химических веществ в производственных помещениях, работа на ПЭВМ в которых является основной (диспетчерские, операторские, расчетные, кабины и посты управления, залы вычислительной техники и др.), не должно превышать" Предельно допустимых концентраций загрязняющих веществ в атмосферном воздухе населенных мест" (см.[10] п.4.7.). В качестве средств защиты используется рациональная система вентиляции рабочих мест, дополненная очистными устройствами.
1.1.3.Требования к интенсивности электромагнитных полей, рентгеновского, видимого, ультрафиолетового и инфракрасного излучений (см.[11],[12])
1.1.3.1.Мощность экспозиционной дозы рентгеновского излучения в любой точке на расстоянии 0.05м от экрана и корпуса ПЭВМ при любых положениях регулировочных устройств не должна превышать 7.74*10-12
А/кг, что соответствует эквивалентной дозе, равной 0.1 мбэр/час.
1.1.3.2.Уровень ультрафиолетового излучения на рабочем месте пользователя в длинноволновой области (400-315 нм) должен быть не более 10 Вт/м, в средневолновой области (315-280 нм) не более 0,01Вт/м и отсутствовать в коротковолновой области (280-200 нм).
1.1.3.3.Предельно допустимые уровни напряженности электромагнитного поля на рабочем месте пользователя по электрической составляющей в диапазоне до 300 МГц должны быть не более 50 В/м и по магнитной составляющей не более 5 А/м.
На частотах более высокого диапазона (300МГц...300ГГц) устанавливаются предельно допустимые значения плотности потока энергии электромагнитного поля. Максимальное значение ППЭПДУ
не должно превышать 10 Вт/м2
.
1.1.3.4.Напряженность электростатических полей на поверхностях ПЭВМ не более 20 кВ/м.
1.1.4.Требования к освещению помещений и рабочих мест с ПЭВМ (см.[13] стр.71-73)
Нормативным документом в качестве основных параметров, регламентирующих световую среду, определяются для естественного освещения коэффициент естественного освещения е.
и для искусственного - освещенность рабочего места оператора Ер.м.
, лк.
1.1.4.1.Естественное освещение должно осуществляться через светопроемы, ориентированные преимущественно на север и северо-восток и обеспечивать коэффициент естественной освещенности (КЕО) не ниже 1.2% в зонах с устойчивым снежным покровом и не ниже 1.5% на остальной территории. Указанные значения КЕО нормируются для зданий, расположенных в III климатическом поясе. Для внутренней отделки интерьера помещений с ПЭВМ должны использоваться диффузно-отражающие материалы с коэффициентом отражения для потолка - 0.7-0.8; для стен - 0.5-0.6; для пола - 0.3-0.5.
1.1.4.2.Искусственное освещение в помещениях эксплуатации ПЭВМ должно осуществляться системой общего равномерного освещения и обеспечивать освещенность не ниже нормируемых значений (таблица 14).
Таблица 5.
Нормы освещенности в помещениях с ПЭВМ
| Характеристика работы
|
Рабочая поверхность
|
Плоскость
|
Освещенность, лк
|
| Работа преимущественно с ПЭВМ (50% и более рабочего времени)
|
экран
клавиатура
документ
стол
|
В
Г
Г
Г
|
200
400
400
400
|
| Работа преимущественно с документами, с и ПЭВМ (менее 50% рабочего времени)
|
экран
клавиатура
документ
стол
|
В
Г
Г
Г
|
200
400
500*
500*
|
Примечание: В - вертикальная плоскость, Г - горизонтальная плоскость;
* - допускается установка светильников местного освещения для подсветки документов; местное освещение не должно создавать бликов на поверхности экрана и увеличивать освещенность экрана более 300 лк.
1.1.4.3.Яркость светящихся поверхностей (окна, светильники и др.), находящихся в поле зрения, должна быть не более 200 кд/м.
1.1.4.4.Следует ограничивать отраженную блескость на рабочих поверхностях (экран, стол, клавиатура и др.) за счет правильного выбора типов светильников и расположения рабочих мест по отношению к источникам естественного и искусственного освещения, при этом яркость бликов на экране ПЭВМ не должна превышать 40 кд/м и яркость потолка, при применении системы отраженного освещения, не должна превышать 200 кд/м.
1.1.4.5.Показатель ослепленности для источников общего искусственного освещения в производственных помещениях должен быть не более 20, показатель дискомфорта в административно-общественных помещениях не более 40.
1.1.4.6.Соотношение яркости между рабочими поверхностями не должно превышать 3:1-5:1, а между рабочими поверхностями и поверхностями стен и
оборудования 10:1.
1.1.4.7.Яркость светильников общего освещения в зоне углов излучения от 50 град. до 90 град. с вертикалью в продольной и поперечной плоскостях должна составлять не более 200 кд/м, защитный угол светильников должен быть не менее 40 град.
1.1.4.8.Светильники местного освещения должны иметь не просвечивающий отражатель с защитным углом не менее 40град.
1.1.4.9.Коэффициент запаса (Кз) для осветительных установок общего освещения должен приниматься равным 1.4.
1.1.4.10.Величина коэффициента пульсации не должна превышать 5%, что должно обеспечиваться применением газоразрядных ламп в светильниках общего и местного освещения с высокочастотными пускорегулирующими аппаратами (ВЧ ПРА). При отсутствии светильников с ВЧ ПРА лампы многоламповых светильников или рядом расположенные светильники общего освещения следует включать на разные фазы трехфазной сети и использовать преимущественно люминесцентные лампы типа ЛБ.
Для того, чтобы удовлетворить приведенным требованиям по шуму, вибрациям и т.п., рекомендовано проводить закупки оборудования с небольшой вибрацией, пониженным шумом и так далее. В качестве конкретных мер можно предложить пользоваться не матричными принтерами, а систему вентиляции, снабдив звукопоглощателями и, по возможности, виброгасителями, вынести за пределы рабочего помещения.
Расчет освещенности рабочего места программиста.
При любом виде освещения необходимо следить за равномерностью освещения рабочего места. В противном случае, при неравномерном освещении, перевод взгляда с более освещенного в менее освещенное, или наоборот, будет вызывать у пользователя сужение и расширение зрачка. Это, в свою очередь, повлечет напряжение глазных мышц и общую усталость.
Освещение рабочего места обеспечивается за счет применения общего искусственного освещения помещения и местного освещения рабочего места (система комбинированного освещения) — не ниже 750 лк (СН 4559-88). Источники общего и местного освещения — люминесцентные лампы. Нормированные значения освещенности в помещении представлены в таблице 1 :
Таблица 1
| Плоскость, в которой нормируется освещение
|
Разряд и подразряд зрительных работ по СН и П 23.05.95
|
Освещенность, лк (комбинированное освещение)
|
Коэффициент пульсации,
КЕО %
|
| Горизонтальная
|
1 Г
|
всего
|
от общего
|
КП % не
|
| 1500
|
300
|
более 20/10
|
Оптимальный уровень яркости, отображаемой на экране дисплея информации, должен лежать в пределах от десятка до сотен Кд/м2
. Размер объекта различения не менее 0.6 мм (тип монитора - VGA). Контрастность изображения (объект/фон) не менее 0.8. Низкочастотное дрожание изображения на экране монитора должно находиться в пределах 0.1 мм. ( требования к вычислительной технике по СН 4559-88). Время непрерывной работы с экраном в большинстве случаев не должно превышать 1.5 — 2 часа, длительность перерывов для отдыха должна составлять 5 — 15 мин.
Расчет общего искусственного освещения помещения.
Выбор источников освещения.
Для освещения помещения искусственным светом из всех существующих источников света, наиболее целесообразно использовать люминесцентные лампы (лампы дневного света), так как они экономичны, и их спектр близок к дневному свету.
Расположение источников света.
Общее освещение реализуется с помощью простых и распространенных светильников таких, как открытые двухламповые светильники УСП35. Они используются для освещения нормальных помещений с отражением потолка и стен, а также при умеренной влажности и запыленности. При выборе расположения светильников необходимо руководствоваться двумя критериями:
1) обеспечение высокого качества освещения, ограничения ослепляемости и необходимой направленности света на рабочее место;
2) наиболее экономичное создание нормированной освещенности.
Характеристики помещения:
· высота помещения H = 3.0 м;
· длина помещения l = 4.8 м;
· ширина помещения a = 3.5 м.
Для рабочего стола пользователя уровень рабочей поверхности над полом составляет 0.7 м. Тогда:
h = H - 0.7 = 2.3 м.
У светильников УСП35 коэффициент запаса kз
= 1.3 . Отсюда расстояние между светильниками L:
L = kз
* h = 1.3 * 2.3 = 2.99 м » 3.0 м.
Располагаем светильники вдоль стороны помещения с окном. Расстояние между стенами и крайним рядом светильников считаем по формуле:
Lст = 0.3 * L = 0.3 * 3.0 = 0.897 м » 0.9 м.
Для равномерного общего освещения светильники располагаются рядами, параллельными стенам с окнами. Количество светильников в одном ряду равно 2.
Расчет светового потока.
Расчет требуемого светового потока F производится по формуле:
F = En * S * z * kз
/ (n * N), где:
Eн — нормированная минимальная освещенность, лк;
S — площадь освещаемого помещения;
z — коэффициент минимальной освещенности, равный отношению средней освещенности к минимальной. При использовании люминесцентных ламп z = 1.1;
kз
— коэффициент запаса, учитывающий запыление светильников и износ источников света. Для помещений ВЦ, освещенных люминесцентными лампами, kз
= 1.4.
N — число светильников;
n — коэффициент использования светового потока, который показывает, какая часть от общего светового потока приходится на рассчитываемую плоскость. Он зависит от типа светильников, коэффициентов отражения светового потока от стен Qс, потолка Qп, пола Qпола, геометрических размеров помещения и высоты подвеса светильников, что учитывается индексом помещения i:
i = S / ( h * ( l + a ) ) = 17.5 / ( 2.3 * ( 4.8 + 3.5 ) ) = 0.92.
С учетом отражения стен и потолка выбираем n = 0.5.
Итак, Ен = 300 лк; S = 16.8 м2
; kз
= 1.4; z = 1.1; N = 4; n = 0.5. Тогда, F = 300 * 16.8 * 1.4 * 1.1 / (0.5 * 4) = 3881 лм. Учитывая, что расчёт производится для двухлампового светильника, выбираем лампы ЛБ 30, которые имеют: световой поток Ел = 2100 лм, потребляемая мощность Pпот
= 30 Вт.
Рассчитаем общую потребляемую мощность системы освещения и минимальную освещённость, которые вычисляются по формулам:
Ре
= Pпот
* N = 2 * 30 * 4 = 240 Вт,
Еmin
= Eн
* (Fвыбр
/ Fрасч
) = 300 * (4200 / 3881) = 325 лк,
Схема размещения светильников приведена на рис 1.
Рис 1
 Схема размещения светильников в рабочем помещении. Схема размещения светильников в рабочем помещении.
Заключение.
Дипломный проект посвящен транслированию текстовых файлов из формата nroff, распространенного в ОС UNIX, в формат HTML, получивший широкое применение в различных ОС. Поскольку формат nroff используется в файлах описания ОС UNIX (т.н. man-файлах), то необходимость в нем возникает очень часто. Однако, в связи с проблемами переноса файлов в другие ОС, особо остро встает проблема транслирования документов в один из наиболее распространенных форматов.
В проекте транслятор реализуется на основе генератора программ lex и компилятора компиляторов yacc.
Данный проект может являться базой для дальнейшей проработки и развития транслятора. В частности, можно добавлять неохваченные команды nroff. Неоспоримым достоинством является то, что основные блоки транслятора реализованы на языке C, что обеспечивает корректную компиляцию в разных версиях UNIX и LINUX.
Список литературы:
1. «HTML в примерах». А. Гончаров. Питер, 1997.
2. «LINUX. Полное руководство». Р. Петерсен. Киев, BHV, 1998.
3. «Генератор программ lex». Разработка кафедры САПР. 1998.
4. «Компилятор компиляторов yacc». Разработка каф. САПР. 1998
5. «Теоретические основы проектирования компиляторов». Ф. Льюис,
Д. Розенкранц, Р. Стирнз. Москва, Мир, 1979.
6. «ОС Демос». Тихомиров, Давидов.
7. «Технико-экономическое обоснование эффективности НИОКР».
Э. Н. Сванидзе, Москва, 1998.
8. ГОСТ 12.1.045-84. Электрические поля. Допустимые уровни на рабочих местах и требования к проведению контроля. — М.: “Стандарты”, 1978.
9. ГОСТ 21889-76 СЧМ. Кресло человека-оператора. Общие эргономические требования. — М.: “Стандарты”, 1978.
10. ГОСТ 23000-78 СЧМ. Пульты управления. Общие эргономические требования. — М.: “Стандарты”, 1978.
11. Охрана труда в машиностроении. Под ред. Юдина Е.Я., Белова С.В. — М.: “Машиностроение”, 1983.
12. Строкин А. А., Кирикова О. В. Эргонометрические основы охраны труда операторов и экологической безопасности системы "Человек - Машина - Среда обитания ". — М.: МГТУ, 1994.
13. ГОСТ 12.2.032-78 ССБТ. Рабочее место при выполнении работ сидя. Общие эргономические требования. — M.: “Стандарты”, 1978.
ГОСТ 12.1.003-83 ССБТ. Шум. Общие требования безопасности. — M.: “Стандарты”, 1978
|
