| Ростовский Государственный Университет
Кафедра радиофизики
Реферат на тему:
«Подсистема памяти современных компьютеров»
Студент: Илинич К.А.
Ростов-на-дону
2001 год
Содержание
:
1.
Иерархическая организация памяти..................................................... 3
a. Оперативная память........................................................................ 3
b. Дисковая память.............................................................................. 3
c. Память на внешних носителях....................................................... 3
d. Кэш-память....................................................................................... 3
e. Организация кэш-памяти............................................................... 4
I. Размещение блока в кэш-памяти....................................... 4
II. Поиск блока, находящегося в кэш-памяти....................... 5
III. Замещение блока кэш-памяти при промахе..................... 5
IV. Что происходит во время записи....................................... 6
2.
Динамическая память.............................................................................. 7
3.
Общий принцип доступа к данным........................................................ 8
4.
Традиционная память с асинхронным интерфейсом......................... 9
a. Традиционная память...................................................................... 9
b. Память FPM с быстрым страничным доступом .......................... 9
c. Память EDO, расширенный вывод данных................................. 9
d. Память BEDO, пакетная передача данных................................... 9
5.
Память с синхронным интерфейсом..................................................... 10
a. Синхронная динамическая память SDRAM................................. 10
b. Память DDR SDRAM, удвоенная скорость данных.................... 12
6.
Организация оперативной памяти......................................................... 12
a. Банки памяти................................................................................... 12
b. Чередование банков........................................................................ 13
c. Пути увеличение производительности......................................... 13
Реклама

7.
Память
Rambus DRAM............................................................................ 14
8.
Модули памяти.......................................................................................... 18
9.
Виртуальная память и организация защиты памяти....................... 19
a. Концепция виртуальной памяти................................................... 19
b. Страничная организация памяти................................................... 20
c. Сегментация памяти....................................................................... 21
10.
Терминология............................................................................................. 22
11.
Литература.................................................................................................. 26
Иерархическая организация памяти
Память компьютера имеет иерархическую структуру, центральным слоем которой является оперативная память
— ОЗУ или RAM (Random Access Memory — память с произвольным доступом). Оперативная память непосредственно доступна процессору: в ней хранится исполняемая в данный момент часть программного кода и данные, к которым процессор может обращаться с помощью одной из многих команд. Произвольность доступа подразумевает, что процессор в любой момент может считать или записать любой байт (слово, двойное слово...) из этой памяти. 32-разрядные процессоры x86 способны адресовать до 4 Гбайт физической памяти (кроме 386SX, урезанных до 16 Мбайт), а процессоры P6 (Pentium Pro, Pentium II и старше) в режиме расширения адреса — до 64 Гбайт. Из этого потенциально доступного пространства именно для оперативной памяти используется только часть: большинство системных плат пока ограничивают объем устанавливаемого ОЗУ на уровне 256 Мбайт–1 Гбайт. В этом же пространстве располагается и постоянная память — ПЗУ, или ROM (Read Only Memory), которая в обычной работе только читается. В ПЗУ располагается BIOS (базовая система ввода-вывода) компьютера и некоторые другие элементы.
Следующий уровень в иерархии — дисковая память
. В отличие от ОЗУ и ПЗУ, для обращения к любому элементу, хранящемуся в дисковой памяти, процессор должен выполнить некоторую процедуру или подпрограмму, код которой находится в оперативной или постоянной памяти. Дисковая память является блочной — процедура доступа к этой памяти оперирует блоками фиксированной длины (обычно это сектор с размером 512 байт). Процедура доступа способна лишь скопировать целое количество образов блоков из оперативной (или постоянной) памяти на диск или обратно. Дисковая память является основным хранилищем файлов с программами и данными. Кроме того, она используется и для организации виртуальной оперативной памяти: не используемый в данный момент блок информации (страница) из оперативной памяти выгружается на диск, а на его место с диска подкачивается страница, требуемая процессору для работы.
Реклама

Последняя ступень иерархии — память на внешних носителях
, или просто внешняя память. Она, так же, как и дисковая, является хранилищем файлов, и доступ к ней осуществляется поблочно.
Мы перечислили программно-видимую часть “айсберга” памяти — доступную произвольно или поблочно, прямо или последовательно. Есть еще и “подводная” часть — кэш-память
. Оперативная память по меркам современных процессоров обладает слишком низким быстродействием, и, обратившись за данными, процессор вынужден простаивать несколько тактов до готовности данных. Начиная с процессоров 80386, оперативную память стали кэшировать (эта идея использовалась и в “древних” больших машинах, где было СОЗУ — сверхоперативное ЗУ). Идея кэширования ОЗУ заключается в применении небольшого (по сравнению с ОЗУ) запоминающего устройства — кэш-памяти с более высоким быстродействием. Небольшого — потому, что по технико-экономическим причинам большой объем очень быстрой памяти обходится слишком дорого. В этой памяти хранится копия содержимого части ОЗУ, к которой в данный момент процессор наиболее интенсивно обращается. Определять, какую часть содержимого ОЗУ копировать в данный момент времени, должен контроллер кэша. Он это может делать, исходя из предположения о локальности обращений к данным и последовательности выборок команд. Кэш-память не дает дополнительного адресуемого пространства, ее присутствие для программы незаметно.
Организация кэш-памяти
Концепция кэш-памяти возникла достаточно рано и сегодня кэш-память имеется практически в любом классе компьютеров, а в некоторых компьютерах - во множественном числе.
Типовые значения ключевых параметров для кэш-памяти рабочих станций и серверов - типичный набор параметров, который используется для описания кэш-памяти :
| Размер блока (строки)
|
4-128 байт
|
| Время попадания (hit time)
|
1-4 такта синхронизации (обычно 1 такт)
|
| Потери при промахе (miss penalty)
(Время доступа - access time)
(Время пересылки - transfer time)
|
8-32 такта синхронизации
(6-10 тактов синхронизации)
(2-22 такта синхронизации)
|
| Доля промахов (miss rate)
|
1%-20%
|
| Размер кэш-памяти
|
4 Кбайт - 16 Мбайт
|
Рассмотрим организацию кэш-памяти более детально, отвечая на четыре вопроса об иерархии памяти.
Размещение блока в кэш-памяти
Принципы размещения блоков в кэш-памяти определяют три основных типа их организации:
Если каждый блок основной памяти имеет только одно фиксированное место, на котором он может появиться в кэш-памяти, то такая кэш-память называется кэшем с прямым отображением (direct mapped)
. Это наиболее простая организация кэш-памяти, при которой для отображение адресов блоков основной памяти на адреса кэш-памяти просто используются младшие разряды адреса блока. Таким образом, все блоки основной памяти, имеющие одинаковые младшие разряды в своем адресе, попадают в один блок кэш-памяти, т.е.
(адрес блока кэш-памяти) =
(адрес блока основной памяти) mod (число блоков в кэше)
Если некоторый блок основной памяти может располагаться на любом месте кэш-памяти, то кэш называется полностью ассоциативным (fully associative)
.
Если некоторый блок основной памяти может располагаться на ограниченном множестве мест в кэш-памяти, то кэш называется множественно-ассоциативным (set associative). Обычно множество представляет собой группу из двух или большего числа блоков в кэше. Если множество состоит из n блоков, то такое размещение называется множественно-ассоциативным с n каналами (n-way set associative). Для размещения блока прежде всего необходимо определить множество. Множество определяется младшими разрядами адреса блока памяти (индексом):
(адрес множества кэш-памяти) =
(адрес блока основной памяти) mod (число множеств в кэш-памяти)
Далее, блок может размещаться на любом месте данного множества.
Диапазон возможных организаций кэш-памяти очень широк: кэш-память с прямым отображением есть просто одноканальная множественно-ассоциативная кэш-память, а полностью ассоциативная кэш-память с m
блоками может быть названа m
-канальной множественно-ассоциативной. В современных процессорах как правило используется либо кэш-память с прямым отображением, либо двух- (четырех-) канальная множественно-ассоциативная кэш-память.
Поиск блока находящегося в кэш-памяти
У каждого блока в кэш-памяти имеется адресный тег, указывающий, какой блок в основной памяти данный блок кэш-памяти представляет. Эти теги обычно одновременно сравниваются с выработанным процессором адресом блока памяти.
Кроме того, необходим способ определения того, что блок кэш-памяти содержит достоверную или пригодную для использования информацию. Наиболее общим способом решения этой проблемы является добавление к тегу так называемого бита достоверности (valid bit).
Адресация множественно-ассоциативной кэш-памяти осуществляется путем деления адреса, поступающего из процессора, на три части: поле смещения используется для выбора байта внутри блока кэш-памяти, поле индекса определяет номер множества, а поле тега используется для сравнения. Если общий размер кэш-памяти зафиксировать, то увеличение степени ассоциативности приводит к увеличению количества блоков в множестве, при этом уменьшается размер индекса и увеличивается размер тега.
Замещение блока кэш-памяти при промахе
При возникновении промаха, контроллер кэш-памяти должен выбрать подлежащий замещению блок. Польза от использования организации с прямым отображением заключается в том, что аппаратные решения здесь наиболее простые. Выбирать просто нечего: на попадание проверяется только один блок и только этот блок может быть замещен. При полностью ассоциативной или множественно-ассоциативной организации кэш-памяти имеются несколько блоков, из которых надо выбрать кандидата в случае промаха. Как правило для замещения блоков применяются две основных стратегии: случайная и LRU.
В первом случае, чтобы иметь равномерное распределение, блоки-кандидаты выбираются случайно. В некоторых системах, чтобы получить воспроизводимое поведение, которое особенно полезно во время отладки аппаратуры, используют псевдослучайный алгоритм замещения.
Во втором случае, чтобы уменьшить вероятность выбрасывания информации, которая скоро может потребоваться, все обращения к блокам фиксируются. Заменяется тот блок, который не использовался дольше всех (LRU - Least-Recently Used).
Достоинство случайного способа заключается в том, что его проще реализовать в аппаратуре. Когда количество блоков для поддержания трассы увеличивается, алгоритм LRU становится все более дорогим и часто только приближенным.
Различия в долях промахов при использовании алгоритма замещения LRU
и случайного алгоритма (при нескольких размерах кэша и разных ассоциативностях при размере блока 16 байт):
| Ассоциативность:
|
2-канальная
|
4-канальная
|
8-канальная
|
| Размер кэш-памяти
|
LRU, Random
|
LRU, Random
|
LRU, Random
|
| 16 KB
|
5.18%, 5.69%
|
4.67%, 5.29%
|
4.39%, 4.96%
|
| 64 KB
|
1.88%, 2.01%
|
1.54%, 1.66%
|
1.39%, 1.53%
|
| 256 KB
|
1.15%, 1.17%
|
1.13%, 1.13%
|
1.12%, 1.12%
|
Что происходит во время записи
При обращениях к кэш-памяти на реальных программах преобладают обращения по чтению. Все обращения за командами являются обращениями по чтению и большинство команд не пишут в память. Обычно операции записи составляют менее 10% общего трафика памяти. Желание сделать общий случай более быстрым означает оптимизацию кэш-памяти для выполнения операций чтения, однако при реализации высокопроизводительной обработки данных нельзя пренебрегать и скоростью операций записи.
К счастью, общий случай является и более простым. Блок из кэш-памяти может быть прочитан в то же самое время, когда читается и сравнивается его тег. Таким образом, чтение блока начинается сразу как только становится доступным адрес блока. Если чтение происходит с попаданием, то блок немедленно направляется в процессор. Если же происходит промах, то от заранее считанного блока нет никакой пользы, правда нет и никакого вреда.
Однако при выполнении операции записи ситуация коренным образом меняется. Именно процессор определяет размер записи (обычно от 1 до 8 байтов) и только эта часть блока может быть изменена. В общем случае это подразумевает выполнение над блоком последовательности операций чтение-модификация-запись: чтение оригинала блока, модификацию его части и запись нового значения блока. Более того, модификация блока не может начинаться до тех пор, пока проверяется тег, чтобы убедиться в том, что обращение является попаданием. Поскольку проверка тегов не может выполняться параллельно с другой работой, то операции записи отнимают больше времени, чем операции чтения.
Очень часто организация кэш-памяти в разных машинах отличается именно стратегией выполнения записи. Когда выполняется запись в кэш-память имеются две базовые возможности:
сквозная запись (write through, store through)
- информация записывается в два места: в блок кэш-памяти и в блок более низкого уровня памяти.
запись с обратным копированием (write back, copy back, store in)
- информация записывается только в блок кэш-памяти. Модифицированный блок кэш-памяти записывается в основную память только когда он замещается. Для сокращения частоты копирования блоков при замещении обычно с каждым блоком кэш-памяти связывается так называемый бит модификации (dirty bit). Этот бит состояния показывает был ли модифицирован блок, находящийся в кэш-памяти. Если он не модифицировался, то обратное копирование отменяется, поскольку более низкий уровень содержит ту же самую информацию, что и кэш-память.
Оба подхода к организации записи имеют свои преимущества и недостатки. При записи с обратным копированием операции записи выполняются со скоростью кэш-памяти, и несколько записей в один и тот же блок требуют только одной записи в память более низкого уровня. Поскольку в этом случае обращения к основной памяти происходят реже, вообще говоря требуется меньшая полоса пропускания памяти, что очень привлекательно для мультипроцессорных систем. При сквозной записи промахи по чтению не влияют на записи в более высокий уровень, и, кроме того, сквозная запись проще для реализации, чем запись с обратным копированием. Сквозная запись имеет также преимущество в том, что основная память имеет наиболее свежую копию данных. Это важно в мультипроцессорных системах, а также для организации ввода/вывода.
Когда процессор ожидает завершения записи при выполнении сквозной записи, то говорят, что он приостанавливается для записи (write stall). Общий прием минимизации остановов по записи связан с использованием буфера записи (write buffer), который позволяет процессору продолжить выполнение команд во время обновления содержимого памяти. Следует отметить, что остановы по записи могут возникать и при наличии буфера записи.
При промахе во время записи имеются две дополнительные возможности:
разместить запись в кэш-памяти (write allocate)
(называется также выборкой при записи (fetch on write)). Блок загружается в кэш-память, вслед за чем выполняются действия аналогичные выполняющимся при выполнении записи с попаданием. Это похоже на промах при чтении.
не размещать запись в кэш-памяти
(называется также записью в окружение (write around)). Блок модифицируется на более низком уровне и не загружается в кэш-память.
Обычно в кэш-памяти, реализующей запись с обратным копированием, используется размещение записи в кэш-памяти (в надежде, что последующая запись в этот блок будет перехвачена), а в кэш-памяти со сквозной записью размещение записи в кэш-памяти часто не используется (поскольку последующая запись в этот блок все равно пойдет в память).
Вполне понятно, что производительность компьютера непосредственно зависит от производительности процессора и производительности оперативной памяти. Теоретическая производительность (пропускная способность) памяти пропорциональна разрядности и тактовой частоте шины и обратно пропорциональна суммарной длительности пакетного цикла. Для повышения этой производительности увеличивают разрядность шины (так, начиная с P5 32-разрядные процессоры имеют 64-разрядную системную шину), тактовую частоту (с 66 МГц наконец-то поднялись до 100 с прицелом на 133 МГц). При этом, естественно, стремятся и к уменьшению числа тактов в пакетном цикле. Кроме того, шина P6 позволяет процессору выставить до 16 запросов конкурирующих транзакций, так что у подсистемы памяти есть теоретическая возможность “многостаночной” работы.
Динамическая память
Теперь посмотрим на оперативную память изнутри. На протяжении уже трех десятилетий в качестве основной памяти используют массивы ячеек динамической памяти. Каждая ячейка содержит всего лишь один КМОП-транзистор (комплементарные полевые траезисторы), благодаря чему достигается высокая плотность упаковки ячеек при низкой цене. Запоминающим элементом у них является конденсатор (емкость затвора), и ячейка может помнить свое состояние недолго — всего десятки миллисекунд. Для длительного хранения требуется регенерация — регулярное “освежение” (refresh) памяти, за что эта память и получила название “динамическая” — DRAM (Dynamic RAM). Ячейки организуются в двумерные матрицы, и для обращения к ячейке требуется последовательно подать два выбирающих сигнала — RAS# (Row Access Strobe, строб строки) и CAS# (Column Access Strobe, строб столбца). Временная диаграмма циклов чтения традиционной динамической памяти приведена на рисунке (циклы записи для простоты здесь рассматривать не будем). Микросхемы динамической памяти традиционно имеют мультиплексированную шину адреса (MA). Во время действия RAS# на ней должен быть адрес строки, во время действия CAS# — адрес столбца. Информация на выходе шины данных относительно начала цикла (сигнала RAS#) появится не раньше, чем через интервал TRAC
, который называется временем доступа. Есть также минимальная задержка данных относительно импульса CAS# (TCAC
), и минимально необходимые интервалы пассивности сигналов RAS# и CAS# (времена предзаряда). Все эти параметры и определяют предел производительности памяти. Ключевой параметр микросхем — время доступа — за всю историю удалось улучшить всего на порядок — с сотен до нескольких десятков наносекунд. За меньший исторический период только тактовая частота процессоров x86 выросла на 2 порядка, так что разрыв между потребностями процессоров и возможностями ячеек памяти увеличивается. Для преодоления этого разрыва, во-первых, увеличивают разрядность данных памяти, а во-вторых, строят вокруг массивов ячеек памяти разные хитрые оболочки, ускоряющие процесс доступа к данным. Все, даже “самые модные”, типы памяти — SDRAM, DDR SDRAM и Rambus DRAM имеют запоминающее ядро, которое обслуживается описанным выше способом.
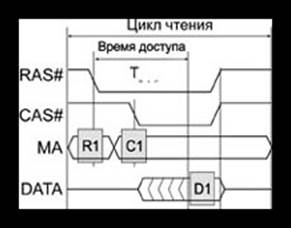
Временная диаграмма чтения динамической памяти
Общий принцип доступа к данным
Массив данных представляет собой некое подобие координатной сетки, где есть положения по горизонтали (адрес строки) и по вертикали (адрес столбца). На пересечении каждого конкретного адреса строки и столбца находится единичный «строительный элемент» памяти – ячейка, которая представляет собой ключ (транзистор) и запоминающий элемент (конденсатор). Например, для чтения или записи одной ячейки памяти необходимо пять тактов. Сначала на шину выставляется адрес строки. Затем подается сигнал RAS#, который является своего рода контрольным сигналом, передающим полученный адрес для записи в специально отведенное место – регистр микросхемы памяти. После этого передается сигнал столбца, следующим тактом за которым идет сигнал подтверждения принимаемого адреса, но уже для столбца – CAS#. И, наконец следует операция чтения-записи в/из ячейки, контролируемая сигналом разрешения – WE#. Однако, если считываются соседние ячейки, то тогда нет необходимости передавать каждый раз адрес строки или столбца – процессор «надеется», что считываемые данные расположены по соседству. Поэтому, на считывание каждой последующей ячейки понадобится уже 3 такта системной шины. Отсюда и берут свое начало существование определенных схем функционирования (тайминги) отдельно взятой разновидности памяти: x-yyy-yyyy-..., где "x" – количество тактов шины, необходимое для чтение первого бита, а у – для всех последующих. Так, цикл доступа процессора к памяти состоит из двух фаз: запроса (Request) и ответа (Response). Фаза запроса состоит из трех действий: подача адреса, подача запроса (чтения-записи) и подтверждение (необязательно). В фазу ответа входит выдача запрашиваемых данных и подтверждение приема. Довольно часто происходит чтение четырех смежных ячеек, поэтому многие типы памяти специально оптимизированы для данного режима работы, и в сравнительных характеристиках быстродействия обычно приводится только количество циклов, необходимое для чтения первых четырех ячеек. Здесь речь идет о пакетной передаче, которая подразумевает подачу одного начального адреса и дальнейшую выборку по ячейкам в установленном порядке. Такого рода передача улучшает скорость доступа к участкам памяти с заранее определенными последовательными адресами. Обычно процессор вырабатывает адресные пакеты на четыре передачи данных по шине, поскольку предполагается, что система автоматически возвратит данные из указанной ячейки и трех следующих за ней. Преимущество такой схемы очевидно – на передачу четырех порций данных требуется всего одна фаза запроса. Например, для памяти типа FPM DRAM применяется самая простая схема 5-333-3333-... Для памяти типа EDO DRAM после первого считывания блока данных, увеличивается время доступности данных того ряда, к которому происходит доступ в настоящий момент, при этом уменьшая время получения пакета данных, и память уже может работать по схеме 5-222-2222-... Синхронная память типа SDRAM, в отличие от асинхронной (FPM и EDO), «свободна» от передачи в процессор сигнала подтверждения, и выдает и принимает данные в строго определенные моменты времени (только совместно с сигналом синхронизации системной шины), что исключает несогласованность между отдельными компонентами, упрощает систему управления и дает возможность перейти на более «короткую» схему работы: 5-111-1111-... Поэтому в рассматриваемом пункте меню настройки можно встретить варианты допустимых значений для циклов обращения к памяти: x333 или x444 – оптимально подходит для FPM DRAM, x222 или x333 – для EDO DRAM, и x111 или x222 – для SDRAM.
Традиционная память с асинхронным интерфейсом
В традиционной памяти
сигналы RAS# и CAS#, обслуживающие запоминающие ячейки, вводятся непосредственно по соответствующим линиям интерфейса. Вся последовательность процессов в памяти привязывается именно к этим внешним сигналам. Данных при чтении будут готовы через время TCAC
после сигнала RAS#, но не раньше, чем через TRAC
после сигнала RAS#.
На основе стандартных ячеек строится память с быстрым страничным доступом
— FPM (Fast Page Mode)
DRAM. Здесь для доступа к ячейкам, расположенным в разных колонках одной строки, используется всего один импульс RAS#, во время которого выполняется серия обращений с помощью только импульсов CAS#. Нетрудно догадаться, что в пакетных циклах доступа получается выигрыш во времени (пакеты укладываются в страницы “естественным” образом). Так, память FPM со временем доступа 60–70 нс при частоте шины 66 МГц может обеспечить цикл чтения 5-3-3-3.
Следующим шагом стала память EDO (Extended Data Out, расширенный вывод данных
) DRAM. Здесь в микросхемы памяти ввели регистры-защелки, и считываемые данные присутствуют на выходе даже после подъема CAS#. Благодаря этому можно сократить время действия CAS# и не дожидаясь, пока внешняя схема примет данные, приступить к предзаряду линии CAS#. Таким образом можно ускорить передачу данных внутри пакета и на тех же ячейках памяти получить цикл 5-2-2-2 (60 нс, 66 МГц). Эффект полученного ускорения компьютера, полученного довольно простым способом, был эквивалентен введению вторичного кэша, что и послужило поводом для мифа о том, что “в EDO встроен кэш”. Страничный цикл для памяти EDO называют и “гиперстраничным”, так что второе название у этой памяти — HPM (Hyper Page Mode) DRAM. Регистр-защелка ввел в микросхему памяти элемент конвейера — импульс CAS# передает данные на эту ступень, а пока внешняя схема считывает их, линия CAS# готовится к следующему импульсу.
Память BEDO (Burst EDO, пакетная EDO)
DRAM ориентирована на пакетную передачу. Здесь полный адрес (со стробами RAS# и CAS#) подается только в начале пакетного цикла; последующие импульсы CAS# адрес не стробируют, а только выводят данные — память уже “знает”, какие следующие адреса потребуются в пакете. Результат — при тех же условиях цикл 5-1-1-1.
Память EDO появилась во времена Pentium и стала применяться также в системах на 486. Она вытеснила память FPM и даже стала ее дешевле. Память BEDO широкого распространения не получила, поскольку ей уже “наступала на пятки” синхронная динамическая память.
Вышеперечисленные типы памяти являются асинхронными по отношению к тактированию системной шины компьютера. Это означает, что все процессы инициируются только импульсами RAS# и CAS#, а завершаются через какой-то определенный (для данных микросхем) интервал. На время этих процессоров шина памяти оказывается занятой, причем, в основном, ожиданием данных.
Память с синхронным интерфейсом — SDRAM и DDR SDRAM
Для вычислительного конвейера, в котором могут параллельно выполняться несколько процессов и запросов к данным, гораздо удобнее синхронный интерфейс. В этом случае все события привязываются к фронтам общего сигнала синхронизации, и система четко “знает”, что, выставив запрос на данные в таком-то такте, она получит их через определенное число тактов. А между этими событиями на шину памяти можно выставить и другой запрос, и если он адресован к свободному банку памяти, начнется скрытая (latency) фаза его обработки. Таким образом удается повысить производительность подсистемы памяти и ее шины, причем не за счет безумного увеличения числа проводов (увеличения разрядности и числа независимых банков, о чем будет сказано позже).
Микросхемы синхронной динамической памяти SDRAM (Synchronous DRAM)
представляет собой конвейеризированные устройства, которые на основе вполне обычных ячеек (время доступа — 50–70 нс) обеспечивают цикл 5-1-1-1, но уже при частоте шины 100 МГц и выше. По составу сигналов интерфейс SDRAM близок к обычной динамической памяти: кроме входов синхронизации, здесь есть мультиплексированная шина адреса, линии RAS#, CAS#, WE (разрешение записи) и CS (выбор микросхемы) и, конечно же, линии данных. Все сигналы стробируются по положительному перепаду синхроимпульсов, комбинация управляющих сигналов в каждом такте кодирует определенную команду. С помощью этих команд организуется та же последовательность внутренних сигналов RAS# и CAS#, которая рассматривалась и для памяти FPM.
Каждая микросхема внутренне может быть организована как набор из 4 банков с собственными независимыми линиями RAS#. Для начала любого цикла обращения к памяти требуется подать команду ACT, которая запускает внутренний формирователь RAS# для требуемой строки выбранного банка. Спустя некоторое количество тактов можно вводить команду чтения RD или записи WR, в которой передается номер столбца первого цикла пакета. По этой команде запускается внутренний формирователь CAS#. Передача данных для циклов записи и чтения различается. Данные для первой передачи пакета записи устанавливаются вместе с командой WR. В следующих тактах подаются данные для остальных передач пакета. Первые данные пакета чтения появляются на шине через определенное количество тактов после команды. Это число, называемое CAS# Latency (CL), определяется временем доступа TCAC
и тактовой частотой. В последующих тактах будут выданы остальные данные пакета. После обращения необходимо деактивировать банк — перевести внутренний сигнал RAS# в пассивное состояние, то есть произвести предзаряд (precharge). Это может быть сделано либо явно командой PRE, либо автоматически (как модифицированный вариант команд RD или WR. Внутренние сигналы CAS# формируются автоматически по командам обращения и дополнительных забот не требуют.
Регенерация выполняется по команде REF, за заданный период регенерации (стандартный 64 мс) должно быть выполнено 4096 или 8192 (в зависимости от объема микросхемы) команд REF.
На первый взгляд из этого описания не видно никаких особых преимуществ SDRAM по сравнению с BEDO. Однако синхронный интерфейс в сочетании с внутренней мультибанковой организацией обеспечивает возможность повышения производительности памяти при множественных обращениях. Здесь имеется в виду способность современных процессоров формировать следующие запросы к памяти, не дожидаясь результатов выполнения предыдущих. В SDRAM после выбора строки (активации банка) ее можно закрывать не сразу, а после выполнения серии обращений к ее элементам, причем как по записи, так и по чтению. Эти обращения будут выполняться быстрее, поскольку для них не требуется подачи команды активации и выжидания TRCD
. Максимальное время удержания строки открытой ограничивается периодом регенерации. Возможность работы с открытой строкой была использована уже в FPM DRAM. Однако в SDRAM можно активировать строки в нескольких банках — каждую своей командой ACT, эта особенность и стоит за словами “Single-pulsed RAS# interface” в перечислении ключевых особенностей SDRAM. Активировать строку можно во время выполнения любой операции с другим банком. Обращение к открытой строке требуемого банка выполняется по командам RD и WR, у которых в качестве параметров кроме адреса столбца фигурирует и номер банка. Таким образом можно так спланировать транзакции, что шина данных в каждом такте будет нести очередную порцию данных, и такой поток будет продолжаться не только в пределах одного пакета, но и для серии обращений к разным областям памяти. Кстати, держать открытыми можно и строки в банках разных микросхем, объединенных общей шиной памяти.
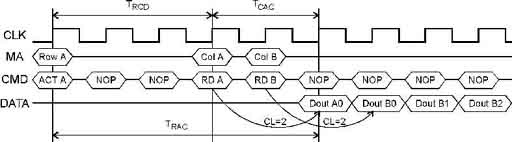
Временная диаграмма чтения SDRAM
Микросхемы SDRAM оптимизированы для пакетной передачи. У них при инициализации программируется длина пакета и операционный режим. Пакетный режим может включаться как для всех операций (normal), так и только для чтения (Multiple Burst with Single Write). Этот выбор позволяет оптимизировать память для работы либо с WB, либо с WT-кэшем. Обратим внимание, что внутренний счетчик адреса работает по модулю, равному запрограммированной длине пакетного цикла (например, при длине пакета 4 он не позволяет перейти границу обычного четырехэлементного пакетного цикла).
Пакетные циклы могут прерываться (принудительно завершаться) последующими командами, при этом оставшиеся адреса отбрасываются. На рисунке приведен пример прерывания команды чтения по адресу A командой чтения по адресу B (подразумевается, что для адреса B строка уже открыта). В случае прерываний пакетов, как и при полных пакетах, шина данных при активированных банках может быть полезно нагруженной в каждом такте, за исключением случая чтения, следующего за записью. При этом шина будет простаивать CL тактов. В команде WR имеется возможность блокирования записи данных любого элемента пакета — для этого достаточно в его такте установить высокий уровень сигнала маскирования.
Микросхемы SDRAM имеют средства энергосбережения. В режиме саморегенерации Self Refresh микросхемы периодически выполняют циклы регенерации по внутреннему таймеру, в этом режиме они не реагируют на внешние сигналы и внешняя синхронизация может быть остановлена. В режиме пониженного потребления Power Down микросхема не воспринимает команды и регенерация не выполняется, поэтому длительность пребывания в нем ограничена периодом регенерации.
Синхронный интерфейс позволяет довольно эффективно использовать шину и обеспечить на частоте 100 МГц пиковую производительность 100 Мбит/пин (на 1 вывод шины данных). SDRAM используют в составе модулей DIMM с 8-байтной разрядностью, что дает производительность 800 Мбайт/с. Однако эта теоретическая производительность не учитывает накладные расходы на регенерацию и подразумевает, что требуемые страницы уже открыты. Из-за указанных выше ограничений на реальном произвольном потоке запросов производительность, конечно же, будет ниже. Потенциальные возможности почти одновременного обслуживания множества запросов, предоставляемая микросхемами SDRAM, будут реализованы лишь при достаточно “умном” контроллере памяти. От его предусмотрительности эффективность памяти зависит, пожалуй, больше, чем у простых FPM и EDO DRAM.
Память DDR SDRAM (Dual Data Rate — удвоенная скорость данных)
представляет собой дальнейшее развитие SDRAM. Как и следует из названия, у микросхем DDR SDRAM данные внутри пакета передаются с удвоенной скоростью — они переключаются по обоим фронтам синхроимпульсов. На частоте 100 МГц DDR SDRAM имеет пиковую производительность 200 Мбит/пин, что в составе 8-байтных модулей DIMM дает производительность 1600 Мбайт/с. На высоких тактовых частотах (100 МГц) двойная синхронизация предъявляет очень высокие требования к точности выдерживания временных диаграмм. Для повышения точности синхронизации предпринят ряд мер.
Сигнал синхронизации микросхемы подается в дифференциальной форме, что позволяет снизить влияние смещения уровней на точность синхронизации.
Для синхронизации данных в интерфейс введен новый двунаправленный стробирующий сигнал DQS. Стробы генерируются источником данных: при операциях чтения DQS генерируется микросхемой памяти, при записи — контроллером памяти (чипсетом).
Для синхронизации DQS с системной тактовой частотой (CLK) микросхемы имеют встроенные схемы DLL (Delay Locked Loop) для автоподстройки задержки сигнала DQS относительно CLK. Эта схема работает наподобие фазовой автоподстройки (PLL) и способна выполнять синхронизацию (обеспечивать совпадение фронтов DQS и CLK) лишь в некотором ограниченном диапазоне частот синхронизации.
В отличие от обычных SDRAM, у которых данные для записи передаются одновременно с командой, в DDR SDRAM данные для записи (и маски DQM) подаются с задержкой на один такт (write latency). Значение CAS# Latency может быть и дробным (CL=2, 2.5, 3). Микросхемы SDRAM до “штатного” использования должны быть инициализированы — кроме предзаряда банков у них должны быть запрограммированы параметры конфигурирования. В DDR SDRAM из-за необходимости настройки цепей DLL программирование несколько сложнее.
Организация оперативной памяти
Теперь, имея общее представление о работе разных типов динамической памяти, обсудим варианты построения модулей памяти и “организационные” способы повышения производительности.
Микросхемы DRAM выпускают с разрядностью данных 1, 4, 8/9, 16/18 бит. Минимальной единицей упаковки, которая воспринимается системной платой компьютера, является банк памяти
. Банк представляет собой объединение микросхем, обеспечивающее разрядность данных шины памяти. Так, для 386SX банк имеет разрядность 16 бит, для 386DX-486 — 32 бита, а для P5–P6 — 64 бита (8 байт). В банке все одноименные адресные входы микросхем и линии RAS# соединяются параллельно. Каждый банк выбирается своим сигналом RAS#. Линии CAS# или (и) WE должны быть индивидуальными для каждого байта, чтобы обеспечить возможность индивидуальной записи в любой байт банка. Микросхемы собираются в модули разрядностью 1 (SIMM-30, SIPP), 4 (SIMM-72) или 8 байт (DIMM). Модули могут содержать один или два банка микросхем (двусторонние модули). Однако полный банк памяти для машин с процессорами P5–P6 набирается парой модулей SIMM-72 или одним DIMM. Количество банков на системной плате ограничивается возможностями чипсета (количеством линий RAS#) или (и) количеством слотов для памяти. Первое ограничение является причиной известной проблемы с “двусторонними” модулями — в ряде плат установка такого модуля в один слот не позволяет использовать еще один слот. Увеличению числа слотов препятствует ограниченная нагрузочная способность шины памяти — каждый слот (тем более, с модулем) вносит паразитную емкость и индуктивность, ограничивающие быстродействие шины. Из-за влияния этой нагрузки для работы модулей SDRAM на частоте шины 100 МГц была разработана спецификация PC100, в которой кроме требований к быстродействию микросхем памяти задаются и правила разводки сигнальных и питающих проводников и прочие конструктивные нюансы. Теперь появляется и аналогичная спецификация PC133 — для частоты шины 133 МГц. Однако повышение тактовой частоты традиционной шины памяти технически сложно из-за большого числа сигнальных проводников. Популярные ныне модули DIMM SDRAM используют 32 адресных и управляющих линии и 64 (72 или 80 с контрольными) линии данных, при этом каждый дополнительный слот памяти требует еще несколько управляющих линий. На высоких частотах приходится учитывать задержки распространения сигналов в проводниках, и что самое неприятное — неодинаковость этих задержек, или перекос (skew).
Установка более одного банка памяти дает потенциальную возможность повышения производительности памяти за счет организации чередования банков (bank interleaving)
. Идею чередования проще пояснить на примере двух банков. Адресация памяти организуется так, чтобы ячейки, передаваемые в соседних тактах пакетного цикла, располагались в разных банках (сделать это несложно, поскольку пакеты выравниваются по границам строк кэша, которые фиксированы). Теперь контроллер памяти при передаче пакета будет обращаться к банкам поочередно, в результате чего частота передачи данных в такой системе может быть удвоенной по отношению к максимальной частоте работы отдельного банка. В чередовании может участвовать и большее число банков. Из разбиения на мелкие банки можно извлечь и другую выгоду. Поскольку современные процессоры способны параллельно выставлять несколько запросов на транзакции с памятью, скрытые фазы обработки запросов, обусловленные необходимым временем доступа, относящихся к разным банкам, могут выполняться одновременно. Однако это требует некоторого усложнения контроллера памяти и обеспечения независимости банков
(возможности активации одного банка до предзаряда предыдущего). Независимость банков для асинхронной памяти достигается сугубо экстенсивным способом — увеличением числа линий интерфейса. Микросхемы SDRAM могут иметь внутреннюю 4-банковую организацию, независимость банков поддерживается синхронным интерфейсом. Чем больше будет независимых банков в ОЗУ, тем больше вероятность возможности их одновременного использования при обслуживании произвольных конкурирующих запросов.
 |
Итак, подведем итоги развития, считая отправной точкой память FPM. Для повышения производительности
: 1.
Повышают быстродействие ядра (запоминающих ячеек) — пока остановились на 40 нс.
2.
Применяют конвейеризацию (внешнюю — память EDO, внутреннюю — BEDO и SDRAM).
3.
Увеличивают количество независимых банков (в SDRAM — внутренне до четырех).
4.
Увеличивают разрядность данных, для процессоров P5–P6 до 8 байт.
5.
Повышают скорость передачи данных по интерфейсу памяти — в SDRAM частота “схода с конвейера” до 100–133 МГц, в DDR SDRAM — 2 х 100=200 МГц.
Пункты 3 и 4 сильно мешают прогрессу по п. 5 — 96 цепей к одному модулю развести без “перекосов” довольно сложно. Широкая разрядность интерфейса сковывает и масштабируемость памяти: нельзя увеличить объем ОЗУ, добавляя по одной микросхеме — можно только по четыре (а чаще по восемь).
Память Rambus DRAM
Память RDRAM (Rambus DRAM) имеет интерфейс, существенным образом отличающийся от традиционного и синхронного интерфейса. Запоминающее ядро этой памяти построено все на тех же КМОП-ячейках динамической памяти, но пути повышения производительности интерфейса совершенно иные. Первые микросхемы RDRAM применялись в некоторых моделях видеокарт и игровых приставок. Дальнейшим развитием интерфейса стал фирменный (Rambus) стандарт DRDRAM (Direct Rambus DRAM), обеспечивающий производительность 1600 Мбайт/с на двухбайтной шине данных при частоте 400 МГц. Стандарт DRDRAM поддержан множеством производителей микросхем и модулей памяти, он претендует на роль основного высокопроизводительного стандарта для памяти компьютеров любого размера. Подсистема памяти (ОЗУ) DRDRAM состоит из контроллера памяти, канала и собственно микросхем памяти. По сравнению с DDR SDRAM при той же производительности DRDRAM имеет более компактный интерфейс и гибкую масштабируемость. Разрядность ОЗУ DRDRAM (16 байт) не зависит от числа установленных микросхем, а число банков, доступных контроллеру, и объем памяти суммируется по всем микросхемам канала. При этом в канале могут присутствовать микросхемы разной емкости в любых сочетаниях.
Запоминающее ядро микросхем имеет многобанковую организацию — 64-мбитные микросхемы имеют 8 банков, 256-мбитные — 32 банка. Каждый банк имеет свои усилители считывания, благодаря чему в микросхеме может быть активировано несколько банков. Разрядность ядра 16 байт — 128 или 144 (с контрольными разрядами) бит. Ядро работает на 1/8 частоты канала, взаимодействие с ядром осуществляется по внутренним сигналам RAS и CAS. В современных DRDRAM применяются ячейки памяти с временем доступа 40–53 нс.
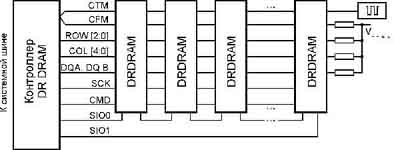
Память Direct RDRAM
Канал DRDRAM (Rambus Channel) представляет собой синхронную последовательно-параллельную шину. Такой подход позволил ограничить количество линий интерфейса, что позволяет упорядочить разводку проводников ради повышения частоты передачи сигналов. Небольшое количество сигналов позволяет при разумной цене применить сверхбыстродействующие интерфейсные схемы. Тактовая частота канала — 400 МГц, стробирование информации осуществляется по обоим фронтам синхросигнала. Таким образом, пропускная способность одной линии составляет 800 Мбит/с. Канал состоит из 30 основных линий с интерфейсом RSL (Rambus System Logic) и 4 вспомогательных линий КМОП, используемых для инициализации микросхем. Стандарт требует соблюдения топологических правил, структура подсистемы памяти приведена на рисунке. Все основные интерфейсные линии, кроме линий синхронизации, начинаются от интерфейсной микросхемы контроллера памяти и заканчиваются терминаторами на противоположном конце канала. Терминаторы не позволяют сигналам отражаться от конца канала. Микросхемы памяти подключаются к каналу без T-образных ответвлений проводников, что облегчается их упаковкой в корпуса BGA (Ball Grid Array — матрица шариковых выводов). Интерфейсные линии должны идти строго параллельно друг другу с тем, чтобы задержки распространения сигналов по разным линиям совпадали. В канале может быть установлено до 32 микросхем, и все они соединены параллельно. Для того, чтобы контроллер мог адресоваться к определенной микросхеме, каждой из них назначается свой уникальный адрес DEVID. Нумерация микросхем (Device Enumeration) осуществляется в процессе инициализации, который выполняется с использованием вспомогательного последовательного КМОП-интерфейса.
Синхросигнал вводится в канал с дальнего конца и распространяется в сторону контроллера по линии CTM (Clock To Master). По этому сигналу микросхемы памяти стробируют данные, посылаемые к контроллеру (при чтении). Распространяясь по каналу, эти данные будут сохранять свою привязку к синхроимпульсам до самого контроллера. Дойдя до контроллера, синхросигнал выходит на линию CFM (Clock From Master) и идет по каналу до терминатора, установленного на конце.
По этой линии синхронизируется информация, посылаемая от контроллера к микросхемам памяти, и ее привязка к синхросигналу так же будет сохраняться в любом месте канала. Для самой дальней микросхемы время прохождения сигнала синхронизации от CTM до CFM не должно превышать 5 тактов (12,5 нс). Микросхемы привязывают данные чтения к синхросигналу с помощью встроенных схем DLL (Delay Locked Loop) для автоподстройки задержки сигнала DQS относительно CLK. Для повышения точности сигнал синхронизации передается в дифференциальной форме.
Физический уровень интерфейса учитывает волновой характер процессов распространения сигналов в канале. Передатчики микросхем памяти формируют сигналы с половинной амплитудой. Эти сигналы распространяются по шине в обе стороны, и на конце терминатора полностью поглощаются (отражения нет). На конце контроллера импеданс приемников высокий (терминаторов нет), и амплитуда сигнала из-за отражения удваивается. Таким образом приемник контроллера принимает сигнал полной амплитуды. Отраженный от контроллера сигнал дойдет до терминатора и поглотится им. По пути он никому не помешает, поскольку сигнал, передаваемый микросхемой памяти, “интересен” только контроллеру. Контроллер генерирует сигналы полной амплитуды, и по пути к терминаторам они в таком виде пройдут по всем микросхемам памяти.
Канал разделен на три независимые шины: 3-битная шина строк ROW[2:0], 5-битная шина колонок COL[4:0] и двухбайтная (2 х 9 бит) шина данных DQA[8:0] и DQB[8:0]. Дополнительный бит байта данных (имеется не у всех микросхем DRDRAM) может использоваться для контроля достоверности. По каждой шине информация передается пакетами, занимающими 4 такта (8 интервалов) синхронизации (10 нс). Пакет содержит 8 элементов, пакет строк имеет емкость 24 бит, колонок — 40 бит и данных — 16 байт по 8 или 9 бит.
По линиям ROW передаются пакеты для подачи команды активации (вызывает начало формирования внутреннего сигнала RAS), предзаряда (возврат его в исходное состояние), регенерации, управления энергопотреблением и термокалибровкой. По линиям COL могут передаваться пакеты команд чтения, записи и дополнительных команд, а также масок записи (может предотвращаться запись любых из 16 байт данных). По шине данных передаются пакеты данных для записи и чтения от памяти.
Высокая производительность шины управления (строк и колонок) позволяет отказаться от пакетных (в терминологии BEDO и SDRAM) передач и упростить протокол шины. Память может одновременно обслуживать до четырех транзакций на полной скорости передачи данных.
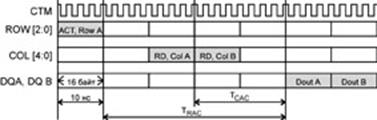
Транзакции чтения приведены на рисунке, по виду они аналогичны транзакциям SDRAM с тем лишь отличием, что вместо одного такта (SDRAM) за то же время передается пакет. Пакет ROW для второй транзакции пропущен, поскольку страницу оставили открытой. Транзакция чтения со стороны контроллера представляет собой петлю: он посылает пакеты команд, которые за некоторое время достигают целевой микросхемы и ею обрабатываются за время TCAC
. Далее микросхема отвечает пакетом данных, которому для достижения контроллера также требуется некоторое время. Пакетам к и от дальних микросхем требуется для путешествий больше времени, чем ближним, и эта разница оказывается большей, чем длительность периода синхронизации. Для того, чтобы контроллер получал ответ на транзакцию чтения от любой микросхемы через одно и то же число тактов, у микросхем памяти устанавливают разную задержку данных относительно пакетов команд чтения. Группы соседних микросхем, у которых программируется одинаковая задержка, называют доменами синхронизации. В канале может быть несколько доменов синхронизации.
Транзакции записи являются однонаправленными, и для них таких проблем синхронизации не возникает. В отличие от стандартных DRAM и SDRAM, где данные для записи передаются одновременно с адресом колонки, в RDRAM данные задерживают относительно командного пакета. Эта задержка соответствует задержке между командами и данными при чтении (на стороне контроллера). Задержка записи позволяет сократить вынужденные простои шины данных при переключении с записи на чтение (в SDRAM они равны CAS Latency и длятся 2–3 такта по 10 нс). Контроллер может посылать данные для записи уже в такте, следующим за последними данными предыдущей транзакции чтения. Однако если за записью следует чтение, то на шине данных будет вынужденная пауза в 1–5 тактов (коротких, по 2,5 нс!), в зависимости от длины канала. За это время последние данные записи дойдут от контроллера до самой дальней микросхемы памяти.
В микросхемах DRDRAM применяется механизм отложенной, или буферированной записи. Данные для записи сначала помещаются в буфер, из которого они выгружаются в усилители считывания-записи несколько позже по явной команде выгрузки (retire) или автоматически. Буфер записи хранит сами данные, а также номер банка и адрес столбца (но не строки). Выгрузка буфера производится по приему следующего командного пакета. Буферизация записи позволяет контроллеру посылать команду записи раньше, что повышает коэффициент использования шины. Автоматическую выгрузку вызывает любая команда, за исключением команды чтения, обращенной к той же микросхеме. Эта оптимизация чтения имеет некоторые побочные эффекты. Если за записью следует чтение той же микросхемы, то выгрузка буфера будет ожидать подходящего командного пакета. Выгрузка возможна только в активированный банк, у которого открыта именно та строка, для которой предназначалась запись. Приход новых данных записи в невыгруженный буфер приводит к потере предыдущей записи. Если за командой записи сразу же следует чтение по тому же адресу, то считаны будут старые данные (новые еще в буфере). Все это должен учитывать контроллер памяти — в некоторых случаях ему придется специально вводить пустые команды (перед предзарядом, при цепочке WR-RD-WR к одной микросхеме), а чтение по адресу предыдущей записи он может “спрямлять” и через собственный буфер. Предзаряд имеют три механизма запуска: явный, автоматический и альтернативный.
Конвейерное выполнение операций DRDRAM обеспечивается многобанковой организацией с отдельными усилителями считывания. Пакеты команд по линиям ROW и COL могут идти сплошным потоком, при этом на шине может присутствовать до четырех транзакций. При произвольных обращениях увеличению производительности способствует большое количество банков, практически недостижимое в памяти на SDRAM. Банковые зависимости обращений приводят к необходимости “лишних” предзарядов. Чем больше независимых банков, тем, в принципе, больше вероятность попадания соседних запросов в разные банки. При последовательных обращениях чтения (RD) или записи (WR) к ячейкам, расположенным в различных (несмежных) банках, эффективность использования полосы шины данных (1600 Мбайт/с) достигает 100%. При цепочке обращений RD-RD-WR-WR к несмежным банкам одной микросхемы эффективность будет 76%, а при обращениях к разным микросхемам канала она достигнет 94%.
Регенерация осуществляется по команде, адресуемой к определенному банку одной или всех микросхем. За период регенерации TREF
(32 мс) должны быть перебраны все строки всех банков. В режимах пониженного потребления микросхемы осуществляют саморегенерацию.
Средства управления энергопотреблением отключают питание неиспользуемых узлов. В самом экономичном состоянии — PDN (Power Down) — микросхемы потребляют мощность в 110 раз меньшую, чем в состоянии STBY (Standby) — состоянии полной готовности к восприятию пакетов. При этом время доступа к данным по чтению в состоянии PDN в 250 раз больше, чем в STBY. Есть еще энергосберегающее состояние NAP, выход из него происходит быстрее, чем из PDN, но потребление больше.
Микросхемы DRDRAM требуют периодической (раз в 100 мс) подстройки выходного тока и термокалибровки. Для этих целей имеются специальные команды, во время которых микросхемы способны сообщать о своем перегреве.
Вспомогательная шина с КМОП-сигналами SCK, CMD и SIO служит для обмена данными с управляющими регистрами и вывода микросхем из состояний пониженного потребления (PDN и NAP). Информация по этой шине тоже передается пакетами.
Управляющие регистры хранят информацию об адресе микросхемы, управляют работой микросхемы в различных режимах, содержат счетчики регенерации для банков и строк, параметры настройки временных циклов. В них же можно прочитать информацию о конкретной микросхеме — организацию, версию протокола и т.п. В составе управляющих есть и тестовые регистры.
Инициализация памяти включает определения наличия микросхем на шине, назначение им идентификаторов и программирование их параметров. После сброса микросхемы не имеют собственных адресов, они назначаются с помощью специального алгоритма серией обменов по последовательной шине. После завершения этого “переучета” включается нормальная синхронизация и дается время для установления режима схем DLL. После двукратной активации и предзаряда каждого банка каждой микросхемы память готова к определению доменов синхронизации и назначению каждой микросхеме соответствующих параметров задержек.
Контроллер памяти является обязательным “фирменным” компонентом ОЗУ на DRDRAM. В его задачу входит обслуживание микросхем памяти, установленных в канале, по запросам, поступающим со стороны интерфейса системной шины компьютера. Часть контроллера, обращенная к каналу, инвариантна к архитектуре компьютера. Именно она “знает” протокол DRDRAM и является продуктом фирмы Rambus. Контроллер DRDRAM будет встраиваться в чипсеты для процессоров P6 (например, i820) и других архитектурных линий.
Модули памяти:
SIMM,
DIMM,
RIMM...
“Ветераны компьютерного движения” помнят, как приходилось поштучно устанавливать микросхемы в IBM PC/XT или AT-286. Вскоре их догадались собирать на модулях со штырьковыми выводами — SIPP, а потом перешли на более удобные SIMM-30. Для совместимости с SIPP иногда SIMM-30 продавали даже с комплектом штырьков: припаял — и вставляй в гнезда. Модули SIMM-30, они же “короткие”, имели разрядность 1 байт и содержали 1 банк (реже — 2) микросхем. Их комплектовали микросхемами FPM DRAM со временем доступа от 300 до 70 нс. Эти модули “дожили” до 486-х компьютеров, где их приходилось ставить четверками.
“Длинные” модули SIMM-72 имеют 4-байтную организацию: для 486 достаточно одного, а для P5–P6 их уже приходится ставить парами. Двусторонние модули имеют 2 банка микросхем, но и в этом случае разрядность данных — 4 байта. Модули могут иметь дополнительные разряды для контроля четности (Parity) или ECC-контроля, при этом их организация различается. У модулей с паритетом каждый контрольный разряд по записи привязывается к своему байту (здесь допускается побайтная запись). При ECC-контроле побайтная запись не производится, и все контрольные биты могут быть объединены. Но и здесь нет однозначности организации, и не каждый ECC-модуль будет работать в конкретной ECC-системе. Правда, в массовых компьютерах от контроля памяти отказались (ее надежность к тому времени уже достигла значительных высот). Модули комплектуются микросхемами FPM (уже редкость) и EDO (больше всех), память с BEDO распространения не получила. Время доступа — от 80 до 40 нс, объем — 1, 2, 4, 8, 16, 32 и 64 Мбайта. Модули SIMM-72 в новых системных платах не используются, но их часто применяют для расширения памяти лазерных принтеров.
Модули DIMM имеют 8-байтную организацию — для P5–P6 достаточно одного модуля в системе. Свое название они получили за то, что используют ламели контактов с двух сторон (у SIMM ламели с противоположных сторон объединены). По организации контрольных бит (если они есть) вариации те же (в “Энциклопедии” приведено 8 вариантов). Объем — 8, 16, 32, 64, 128, 256 Мбайт. Модули имеют 168 выводов, их первое поколение до нас практически не дошло. Модули второго поколения могут комплектоваться как EDO DRAM (время доступа — от 70 до 40 нс), так и SDRAM. Для SDRAM быстродействие указывают иначе — здесь указывают либо время цикла, либо тактовую частоту (это взаимообратные величины), а время доступа скрывается за параметром CAS Latency при определенной частоте. Для обеспечения стабильной работы на частоте 100 МГц была принята спецификация PC100, которая кроме ограничений на время цикла для применяемых микросхем регламентирует и правила разводки проводников. Разрабатывается и спецификация PC133, в которой будут предъявлены архитектурные требования. Надо заметить, что на частоте 100 МГц могут работать и “обычные” модули с подходящим быстродействием микросхем, но проблемы могут появиться при установке в систему нескольких модулей. Есть еще модули RDIMM SDRAM (Registered DIMM) — разновидность DIMM-168, их особенность заключается в наличии регистров-защелок в адресных и управляющих цепях. При этом на 1 такт удлиняется конвейер, но повышается надежность работы на высоких частотах и допускается установка большего числа модулей.
Новинка — модули RIMM (Rambus Interface Memory Module). Эти модули, на вид похожие на обычные модули памяти, специально предназначены для памяти DRDRAM. У них 30-проводная шина проходит вдоль модуля слева направо, и на эту шину без ответвлений напаиваются микросхемы DRDRAM. Сигналы интерфейса модуля соответствуют сигналам канала Rambus, но в их названии имеется еще приставка L (Left) и R (Right) для левого и правого вывода шины соответственно. В одном канале может быть до трех слотов под RIMM, и интерфейсные линии соединяются змейкой. В слоты могут устанавливаться RIMM различной емкости (сейчас они выпускаются на 64, 128 и 256 Мбайт). В отличие от SIMM и DIMM, у которых объем памяти кратен степени числа 2, модули RIMM могут иметь более плавный ряд объемов — в канал RDRAM память можно добавлять хоть по одной микросхеме. Теперь в памяти появился новый элемент-пустышка Continuity module. Это как бы модуль RIMM, но без микросхем памяти, и нужен он для того, чтобы замыкать цепь канала Rambus. Такая “затычка” должна устанавливаться во все слоты канала, не занятые под модули RIMM. Если используются не все слоты, то память выгоднее ставить ближе к контроллеру — она будет работать быстрее (см. предыдущий параграф).
Для малогабаритных систем имеются и малогабаритные модули SO DIMM (Small Outline DIMM). По организации SO DIMM-72 близки к SIMM-72, SO DIMM-144 — к DIMM-168, а SO RIMM — это миниатюрный вариант памяти Rambus.
Кроме собственно памяти на модулях DIMM и RIMM устанавливают и средства идентификации — маленькие микросхемы энергонезависимой памяти EEPROM с последовательным интерфейсом I2C. По этому интерфейсу чипсет может считать из EEPROM, что за модуль установлен и каких он требует параметров. Однако не всякой версии BIOS это интересно знать — через чипсет BIOS может определить многие параметры своими методами тестирования. Но некоторые системы отказываются воспринимать модули памяти “без чипа”, так что мелкая экономия может обернуться проблемами.
Виртуальная память и организация защиты памяти
Концепция виртуальной памяти.
Общепринятая в настоящее время концепция виртуальной памяти появилась достаточно давно. Она позволила решить целый ряд актуальных вопросов организации вычислений. Прежде всего к числу таких вопросов относится обеспечение надежного функционирования мультипрограммных систем.
В любой момент времени компьютер выполняет множество процессов или задач, каждая из которых располагает своим адресным пространством. Было бы слишком накладно отдавать всю физическую память какой-то одной задаче тем более, что многие задачи реально используют только небольшую часть своего адресного пространства. Поэтому необходим механизм разделения небольшой физической памяти между различными задачами. Виртуальная память является одним из способов реализации такой возможности. Она делит физическую память на блоки и распределяет их между различными задачами. При этом она предусматривает также некоторую схему защиты, которая ограничивает задачу теми блоками, которые ей принадлежат. Большинство типов виртуальной памяти сокращают также время начального запуска программы на процессоре, поскольку не весь программный код и данные требуются ей в физической памяти, чтобы начать выполнение.
Другой вопрос, тесно связанный с реализацией концепции виртуальной памяти, касается организации вычислений на компьютере задач очень большого объема. Если программа становилась слишком большой для физической памяти, часть ее необходимо было хранить во внешней памяти (на диске) и задача приспособить ее для решения на компьютере ложилась на программиста. Программисты делили программы на части и затем определяли те из них, которые можно было бы выполнять независимо, организуя оверлейные структуры, которые загружались в основную память и выгружались из нее под управлением программы пользователя. Программист должен был следить за тем, чтобы программа не обращалась вне отведенного ей пространства физической памяти. Виртуальная память освободила программистов от этого бремени. Она автоматически управляет двумя уровнями иерархии памяти: основной памятью и внешней (дисковой) памятью.
Кроме того, виртуальная память упрощает также загрузку программ, обеспечивая механизм автоматического перемещения программ, позволяющий выполнять одну и ту же программу в произвольном месте физической памяти.
Системы виртуальной памяти можно разделить на два класса: системы с фиксированным размером блоков, называемых страницами, и системы с переменным размером блоков, называемых сегментами. Ниже рассмотрены оба типа организации виртуальной памяти.
Страничная организация памяти. В системах со страничной организацией основная и внешняя память (главным образом дисковое пространство) делятся на блоки или страницы фиксированной длины. Каждому пользователю предоставляется некоторая часть адресного пространства, которая может превышать основную память компьютера и которая ограничена только возможностями адресации, заложенными в системе команд. Эта часть адресного пространства называется виртуальной памятью пользователя. Каждое слово в виртуальной памяти пользователя определяется виртуальным адресом, состоящим из двух частей: старшие разряды адреса рассматриваются как номер страницы, а младшие - как номер слова (или байта) внутри страницы.
Управление различными уровнями памяти осуществляется программами ядра операционной системы, которые следят за распределением страниц и оптимизируют обмены между этими уровнями. При страничной организации памяти смежные виртуальные страницы не обязательно должны размещаться на смежных страницах основной физической памяти. Для указания соответствия между виртуальными страницами и страницами основной памяти операционная система должна сформировать таблицу страниц для каждой программы и разместить ее в основной памяти машины. При этом каждой странице программы, независимо от того находится ли она в основной памяти или нет, ставится в соответствие некоторый элемент таблицы страниц. Каждый элемент таблицы страниц содержит номер физической страницы основной памяти и специальный индикатор. Единичное состояние этого индикатора свидетельствует о наличии этой страницы в основной памяти. Нулевое состояние индикатора означает отсутствие страницы в оперативной памяти.
Для увеличения эффективности такого типа схем в процессорах используется специальная полностью ассоциативная кэш-память, которая также называется буфером преобразования адресов (TLB translation-lookaside buffer). Хотя наличие TLB не меняет принципа построения схемы страничной организации, с точки зрения защиты памяти, необходимо предусмотреть возможность очистки его при переключении с одной программы на другую.
Поиск в таблицах страниц, расположенных в основной памяти, и загрузка TLB может осуществляться либо программным способом, либо специальными аппаратными средствами. В последнем случае для того, чтобы предотвратить возможность обращения пользовательской программы к таблицам страниц, с которыми она не связана, предусмотрены специальные меры. С этой целью в процессоре предусматривается дополнительный регистр защиты, содержащий описатель (дескриптор) таблицы страниц или базово-граничную пару. База определяет адрес начала таблицы страниц в основной памяти, а граница - длину таблицы страниц соответствующей программы. Загрузка этого регистра защиты разрешена только в привилегированном режиме. Для каждой программы операционная система хранит дескриптор таблицы страниц и устанавливает его в регистр защиты процессора перед запуском соответствующей программы.
Отметим некоторые особенности, присущие простым схемам со страничной организацией памяти. Наиболее важной из них является то, что все программы, которые должны непосредственно связываться друг с другом без вмешательства операционной системы, должны использовать общее пространство виртуальных адресов. Это относится и к самой операционной системе, которая, вообще говоря, должна работать в режиме динамического распределения памяти. Поэтому в некоторых системах пространство виртуальных адресов пользователя укорачивается на размер общих процедур, к которым программы пользователей желают иметь доступ. Общим процедурам должен быть отведен определенный объем пространства виртуальных адресов всех пользователей, чтобы они имели постоянное место в таблицах страниц всех пользователей. В этом случае для обеспечения целостности, секретности и взаимной изоляции выполняющихся программ должны быть предусмотрены различные режимы доступа к страницам, которые реализуются с помощью специальных индикаторов доступа в элементах таблиц страниц.
Следствием такого использования является значительный рост таблиц страниц каждого пользователя. Одно из решений проблемы сокращения длины таблиц основано на введении многоуровневой организации таблиц. Частным случаем многоуровневой организации таблиц является сегментация при страничной организации памяти. Необходимость увеличения адресного пространства пользователя объясняется желанием избежать необходимости перемещения частей программ и данных в пределах адресного пространства, которые обычно приводят к проблемам переименования и серьезным затруднениям в разделении общей информации между многими задачами.
Сегментация памяти.
Другой подход к организации памяти опирается на тот факт, что программы обычно разделяются на отдельные области-сегменты. Каждый сегмент представляет собой отдельную логическую единицу информации, содержащую совокупность данных или программ и расположенную в адресном пространстве пользователя. Сегменты создаются пользователями, которые могут обращаться к ним по символическому имени. В каждом сегменте устанавливается своя собственная нумерация слов, начиная с нуля.
Обычно в подобных системах обмен информацией между пользователями строится на базе сегментов. Поэтому сегменты являются отдельными логическими единицами информации, которые необходимо защищать, и именно на этом уровне вводятся различные режимы доступа к сегментам. Можно выделить два основных типа сегментов: программные сегменты и сегменты данных (сегменты стека являются частным случаем сегментов данных). Поскольку общие программы должны обладать свойством повторной входимости, то из программных сегментов допускается только выборка команд и чтение констант. Запись в программные сегменты может рассматриваться как незаконная и запрещаться системой. Выборка команд из сегментов данных также может считаться незаконной и любой сегмент данных может быть защищен от обращений по записи или по чтению.
Для реализации сегментации было предложено несколько схем, которые отличаются деталями реализации, но основаны на одних и тех же принципах.
В системах с сегментацией памяти каждое слово в адресном пространстве пользователя определяется виртуальным адресом, состоящим из двух частей: старшие разряды адреса рассматриваются как номер сегмента, а младшие - как номер слова внутри сегмента. Наряду с сегментацией может также использоваться страничная организация памяти. В этом случае виртуальный адрес слова состоит из трех частей: старшие разряды адреса определяют номер сегмента, средние - номер страницы внутри сегмента, а младшие - номер слова внутри страницы.
Как и в случае страничной организации, необходимо обеспечить преобразование виртуального адреса в реальный физический адрес основной памяти. С этой целью для каждого пользователя операционная система должна сформировать таблицу сегментов. Каждый элемент таблицы сегментов содержит описатель (дескриптор) сегмента (поля базы, границы и индикаторов режима доступа). При отсутствии страничной организации поле базы определяет адрес начала сегмента в основной памяти, а граница - длину сегмента. При наличии страничной организации поле базы определяет адрес начала таблицы страниц данного сегмента, а граница - число страниц в сегменте. Поле индикаторов режима доступа представляет собой некоторую комбинацию признаков блокировки чтения, записи и выполнения.
Таблицы сегментов различных пользователей операционная система хранит в основной памяти. Для определения расположения таблицы сегментов выполняющейся программы используется специальный регистр защиты, который загружается операционной системой перед началом ее выполнения. Этот регистр содержит дескриптор таблицы сегментов (базу и границу), причем база содержит адрес начала таблицы сегментов выполняющейся программы, а граница - длину этой таблицы сегментов. Разряды номера сегмента виртуального адреса используются в качестве индекса для поиска в таблице сегментов. Таким образом, наличие базово-граничных пар в дескрипторе таблицы сегментов и элементах таблицы сегментов предотвращает возможность обращения программы пользователя к таблицам сегментов и страниц, с которыми она не связана. Наличие в элементах таблицы сегментов индикаторов режима доступа позволяет осуществить необходимый режим доступа к сегменту со стороны данной программы. Для повышения эффективности схемы используется ассоциативная кэш-память.
Терминология
access cycle
- цикл обращения - последовательность (иногда ее длительность) операций устройства памяти между двумя последовательными актами чтения либо записи. Включает в себя, в частности, все операции, связанные с указанием адреса информации.
access time
- время доступа (иногда ошибочно именуется скоростью) - время, необходимое на полный цикл обращения к информации, хранящейся по случайному адресу в чипе или модуле. Нужно иметь в виду, что в реальных условиях обращение чаще всего происходит не по случайному адресу, что позволяет использовать сокращенный цикл.
bank – банк
. Группа модулей памяти одинаковой емкости, которые должны быть установлены одновременно, чтобы система могла работать. Количество модулей равняется отношению ширины системной шины к ширине шины модуля (умноженному на коэффициент interleave). Некоторые компьютеры способны работать с неполным банком памяти, но ценой значительного падения быстродействия.
bus - шина
. Совокупность линий ввода-вывода, по которым информация передается одновременно. Ширина и частота шины естественным образом влияет на пропускную способность. Под главной, или системной шиной понимается шина между процессором и подсистемой памяти.
cache – кэш.
Буфер обмена между медленным устройством хранения данных и более быстрым. Принцип его действия основан на том, что простой более быстрого устройства сильно влияет на суммарную производительность, а также - что с наибольшей вероятностью запрашиваются данные, сохраненные сравнительно недавно. Поэтому между устройствами помещают небольшой (по сравнению со всеми хранимыми данными) буфер быстрой памяти, что позволяет снизить потери быстрого устройства как на записи, так и на чтении
CAS (Column Access Strobe) - регистр обращения к столбцу.
Сигнал, поданный на линию CAS чипа, означает, что через адресные линии вводится адрес столбца.
chipset - чипсет
, набор микросхем материнской платы, реализующих архитектуру компьютера. Как правило, контроллер памяти входит в состав чипсета, поэтому зная, какой именно чипсет применен в компьютере, можно сделать выводы о применяемой памяти.
DDR (Double Data Rate) = SDRAM II
DIMM (Dual In-Line Memory Module)
- наиболее современная разновидность форм-фактора модулей памяти. Отличается от SIMM тем, что контакты с двух сторон модуля независимы (dual), что позволяет увеличить соотношение ширины шины к геометрическим размерам модуля. Наиболее распространены 168-контактные DIMM (ширина шины 64 бит), устанавливаемые в разъем вертикально и фиксируемые защелками. В портативных устройствах широко применяются SO DIMM.
DIP (Dual In-line Package)
- микросхемы с двумя рядами контактов, расположенными вдоль длинных сторон чипа и загнутых "вниз". Чрезвычайно распространенная упаковка во времена "до" модулей памяти.
DRAM (Dynamic RAM)
- динамическая память - разновидность RAM, единичная ячейка которой представляет собой конденсатор с диодной конструкцией. Наличие или отсутствие заряда конденсатора соответствует единице или нулю. Основной вид, применяемый для оперативной памяти, видеопамяти, а также различных буферов и кэшей более медленных устройств. По сравнению со SRAM заметно более дешевая, хотя и более медленная по двум причинам - емкость заряжается не мгновенно, и, кроме того, имеет ток утечки, что делает необходимой периодическую подзарядку.
DRAM module - модуль памяти
- устройство, представляющее собой печатную плату с контактами, на которой расположены чипы памяти (иногда заключенное в корпус), и представляющее собой единую логическую схему. Помимо чипов памяти может содержать и другие микросхемы, в том числе шунтирующие резисторы и конденсаторы, буферы, logic parity и т.п.
ECC (Error Checking and Correction)
- выявление и исправление ошибок (возможны другие дешифровки того же смысла) - алгоритм, пришедший на смену "контролю четности". В отличие от последнего каждый бит входит более чем в одну контрольную сумму, что позволяет в случае возникновения ошибки в одном бите восстановить адрес ошибки и исправить ее. Как правило, ошибки в двух битах также детектируются, хотя и не исправляются. ECC поддерживают практически все современные серверы, а также некоторые чипсеты "общего назначения". Надо отметить, что ECC не является панацеей от дефективной памяти и применяется для исправления случайных ошибок.
EDO (Extended Data Out)
- разновидность асинхронной DRAM, очень широко применявшаяся в последние 2 года. Представляет собой дальнейшее развитие метода fast page по "конвейерной" схеме - линии ввода-вывода остаются какое-то время открытыми для чтения данных в процессе обращения к следующему адресу, что позволяет организовать цикл доступа более оптимально.
fast page - дословно быстрый страничный (режим).
Очень старая схема оптимизации работы памяти, которая основана на предположении, что доступ, как правило, осуществляется по последовательным адресам. Позволяет наряду с обычным циклом (RAS, затем CAS), использовать сокращенный, при котором RAS фиксирован, и соответственно его зарядка не требует времени. На сегодняшний день fast page - наиболее медленная из реально применяемых организаций памяти, однако еще сравнительно недавно это был единственный выбор для систем с контролем четности.
interleave - чередование
- способ ускорения работы подсистемы памяти, основанный, как и многие другие, на предположении, что доступ происходит к последовательным адресам. Реализуется аппаратно на уровне контроллера и требует организации банка памяти таким образом, что суммарная ширина шины модулей превосходит ширину системной шины в k=2n раз (это число называется коэффициентом interleave и иногда записывается в виде k:1). Таким образом, каждый банк состоит из k "нормальных" банков. Контроллер распределяет "нормальное" адресное пространство подсистемы так, что каждый из k последовательных адресов физически находится в разном банке. Обращение к банкам организовано со сдвигом по фазе (напомним, что отдельный цикл обращения может требовать 5 тактов шины и более). В результате при последовательном обращении к данным за один обычный цикл обращения можно получить до k обращений в режиме interleave. Реальный выигрыш, разумеется, меньше, кроме того, interleave заметно увеличивает минимальный размер банка (как в числе модулей, так и в емкости). В SDRAM interleave реализован на уровне чипа.
MDRAM (Multibank DRAM) - многобанковая DRAM
- разновидность DRAM с interleave, организованным на уровне чипа, применяется преимущественно в графических подсистемах.
Rambus DRAM - технология DRAM
, разработанная компанией Rambus и позволяющая создавать память с высокой пропускной способностью (несколько сотен Mb/сек). Поскольку технология официально поддержана компанией Intel, высока вероятность того, что эта память будет основной в компьютерах будущего. Тем не менее, поскольку стандарт не является открытым, а защищен патентом и как следствие подлежит лицензированию, консорциум major-производителей ведет разработку конкурирующего стандарта SLDRAM. В настоящее время уже применяется в видеоподсистемах высокого уровня.
RAM (Random Access Memory)
- память со случайным доступом.
Любое устройство памяти, для которого время доступа по случайному адресу равняется времени доступа по последовательным адресам. В этом смысле термин практически утратил свое значение, так как современные технологии RAM используют методы оптимизации последовательного доступа, но в прошлом это действительно было критерием для отличения устройств, предназначенных для оперативного хранения небольших объемов данных (в русской традиции - оперативное запоминающее устройство, ОЗУ) от устройств для постоянного хранения больших массивов (постоянное или программное ЗУ, ПЗУ).
RAS (
Row
Access
Strobe) - регистр обращения к строке.
Сигнал, поданный на линию RAS чипа, означает, что через адресные линии вводится адрес строки.
RDRAM = Rambus DRAM
ROM (Read-Only Memory) - память без перезаписи
- вообще говоря, любое запоминающее устройство, перезапись информации на котором невозможна в принципе. В настоящее время термин самостоятельной ценности не имеет, применяясь иногда в аббревиатурах (CD-ROM), в том числе и для описания устройств, допускающих перезапись, хотя в основном предназначенных для чтения (EEPROM).
refresh - подзарядка
. Как известно, состоянием ячейки памяти DRAM является наличие/отсутствие заряда на конденсаторе. Этот заряд подвержен утечке, поэтому для сохранения данных конденсатор необходимо время от времени подзаряжать. Это достигается подачей на него время от времени напряжения (несложная диодная конструкция обеспечивает refresh только тех конденсаторов, на которых уже есть заряд).
SDRAM (Synchronous DRAM) - синхронная DRAM
- название синхронной памяти "первого поколения", широко применяющейся в настоящее время и имеющей пропускную способность порядка 100Mb/сек.
SDRAM II
- находящийся в стадии разработки SDRAM следующего поколения, который должен будет поддерживать вдвое большую (200Mb/сек) пропускную способность.
SGRAM (Synchronous Graphic RAM) -
разновидность синхронной видеопамяти.
SIMM (Single In-line Memory Module)
- наиболее распространенный в течение долгого времени форм-фактор для модулей памяти. Представляет собой прямоугольную плату с контактной полосой вдоль одной из сторон, фиксируется в разъеме поворотом с помощью защелок. Контакты с двух сторон платы на деле являются одним и тем же контактом (single). Наиболее распространены 30- и 72-контактные SIMM (ширина шины 8 и 32 бит соответственно).
SIP (Single In-Line Package)
- разновидность форм-фактора модулей памяти, вытеснены SIMM и в настоящее время почти не встречаются. Проще всего описать их как SIMM, у которого контакты не "наклеены" на плату, а имеют форму иголок (pin в первоначальном значении этого слова) и торчат в виде гребенки.
SLDRAM (SyncLink DRAM)
- условное название высокоскоростной памяти, разрабатываемой консорциумом производителей в качестве открытого стандарта в противовес Rambus DRAM.
SRAM (Static RAM) - статическая память
- разновидность RAM, единицей хранения информации в которой является состояние "открыто-закрыто" в транзисторной сборке. Используется приемущественно в качестве кэш-памяти 2-го уровня. Ячейка SRAM более сложна по сравнению с ячейкой DRAM, поэтому более высокое быстродействие SRAM компенсируется высокой ценой. Несмотря на низкое энергопотребление, является энергозависимой.
timing diagram - временная диаграмма
- количества тактов системной шины, необходимых для доступа к случайно выбранному адресу и следующим за ним адресам. Характерные диаграммы для разных типов памяти (в предположении, что они достаточно быстры, чтобы оптимально взаимодействовать с шиной) - 5-3-3-3 (fast page), 5-2-2-2 (EDO), 5-1-1-1 (SDRAM).
Литература
«Компьютер-ИНФО» № 17(159) 21 мая 1999 года
«Компьютер-ИНФО» № 18(160) 28 мая 1999 года
«Компьютер-ИНФО» № 20(162) 11 июня 1999 года
«Компьютер-ИНФО» № 21(163) 18 июня 1999 года
«Компьютер-ИНФО» № 23(165) 2 июля 1999 года
Справочные материалы с интернет-сайта
http://
www.
ixbt.
ru
Статья «Серверы корпоративных баз данных» с интернет – сайта
http://hackers.webservis.ru/dse/corp_db/contents.htm
Статья «BIOS Setup: настраиваем подсистему памяти» с интернет-сайта
http://www.fcenter.ru/fc-articles/Technical/fc-articles-2000/20001012-biossetup.htm
|
