| Министерство
культуры Российской Федерации
Восточно-Сибирская государственная академия культуры и искусств
Факультет менеджмента информационных технологий
Кафедра автоматизированных информационных систем
УДК 002.53:681.3.016
ОРГАНИЗАЦИЯ ДОСТУПА К БАЗАМ ДАННЫХ
ВСГАКиИ В ИНТЕРНЕТ
Дипломная работа
Исполнитель: Фомин Евгений Игоревич
студент заочного отделения группы 453
Научный руководитель: Баторов А.Р.,к.т.н., доцент.
__________________________________________
И.о.зав.кафедрой: Батуева Э.Б., к.п.н., доцент.
__________________________________________
Дата допуска к защите: _____ 06.2001
Улан-Удэ
2001
Оглавление
Введение. 3
1. Internet – технология работы с базами данных.. 5
1.1 Реализация доступа к базе данных. 6
1.1.1. Однократное или периодическое преобразование содержимого БД в статические документы.. 7
1.1.2. Динамическое создание гипертекстовых документов на основе содержимого БД.. 7
1.1.3. Создание информационного хранилища на основе высокопроизводительной СУБД с языком запросов SQL. Периодическая загрузка данных в хранилище из основных СУБД.. 8
1.2. Обзор технологий.. 9
1.2.1. WWW - сервер NCSA HTTPD.. 9
1.2.2 WWW - сервер Apache c поддержкой Java Servlet. 9
1.2.3. SQL - сервер фирмы Oracle. 11
1.2.4. Язык программирования Perl. 11
1.2.5. Язык программирования Java.. 12
1.2.6 Java servlets. 12
1.2.7. Пакет Web - Oracle - Web. 15
1.2.8. Пакет Cold Fusion фирмы Allaire Corp. 15
1.3. Оценка трудоемкости обеспечения WWW доступа.. 15
2. Практическая часть.. 17
2.1 ОБЩАЯ ЧАСТЬ.. 18
2.1.1. Назначение WWW - сервера. Общая схема работы. Определение. 18
2.1.2 Непосредственные функции сервера. Базовые определения. 20
2.1.3 Протокол MIME.. 21
2.1.4 Протокол HTTP. 22
2.1.5 Интерфейс CGI. 23
2.2. Web-сервера Apache. 23
2.2.1 Установка WEB-сервера Apache. 25
2.2.2 Настройка WEB-сервера Apache. 26
2.4. Использование языка Perl. 33
2.5 Использование языка Java.. 34
2.5.1 Основные особенности.. 34
2.5.2. Взаимодействие с СУБД.. 38
2.6. Реализация доступа к базе данных.. 39
2.6.1. Общее описание. 39
2.6.2. Описание алгоритма.. 39
Заключение.. 49
Литература.. 50
Приложение 1
Спецификация формата RUSMARC.. 51
Приложение 2
Спецификация языка Java.. 90
Приложение 3
Листинг программы – SearchEngein.java.. 103
Реклама

Приложение 4
Результаты тестирования программы... 111
Введение.
Многие организации используют электронные базы данных (БД) для поддержки своих рабочих процессов. Часто это системы на одного - двух пользователей, выполненные с использованием dbf - ориентированных средств разработки: Clipper, Dbase, FoxPro, Paradox, Access. Обычно используется ряд таких баз, независимых друг от друга. Если информация, хранимая в таких БД, представляет интерес не только для непосредственных пользователей, то для ее дальнейшего распространения используются бумажные отчеты и справки, созданные базой данных.
С появлением локальных сетей, подключением таких сетей к Интернет, созданием внутрикорпоративных, сетей, появляется возможность с любого рабочего места организации получить доступ к информационному ресурсу сети. Однако, при попытке использовать существующие БД возникают проблемы связанные с требованием к однородности рабочих мест (для запуска "родных" интерфейсов), сильнейшим трафиком в сети (доступ идет напрямую к файлам БД), загрузкой файлового сервера и невозможностью удаленной работы (например, командированных сотрудников). Решением проблемы могло бы стать использование унифицированного интерфейса WWW для доступа к ресурсам организации.
Технология World Wide Web, в переводе "Всемирная паутина", получила столь широкое распространение из-за простоты своих пользовательских интерфейсов. Принцип "жми на то, что интересно", лежащий в основе гипертекста, интуитивно понятен. В технологиях WWW все ключевые понятия просматриваемого документа: слова, картинки - имеют возможность "раскрыться" новым документом, развивающим это понятие. Такой способ представления информации называется "гипертекстом", а документы, представленные в таком виде - "гипертекстовыми документами". Для описания этих документов используется специальный язык - язык описания гипертекстовых документов или HTML (англ. вариант HyperText Markup Language).
Из этих предпосылок возникает задача преобразования накопленных данных в гипертекстовые документы WWW, задача поддержки актуальности преобразованной структуры. Другими словами, задача предоставления WWW - доступа к существующим базам данных.
Цель данной дипломной работы, создать интерфейс к файлам БД Библиотеки 5.0 которые имеют формат RUSMARC (см. прил. 1), так же можно обратиться за информацией по этому формату на сайт РОССИЙСКОЙ БИБЛИОТЕЧНОЙ АССОЦИАЦИИ
(12,11) .
Реклама

Для реализации поставленной задачи был выбран язык программирования JavaTM
Дипломная работа состоит из 2-х глав и 4 приложений.
В первой главе Internet – технология работы с базами данных,
рассматриваются имеющиеся на данный момент времени технологии по организации доступа к базам данных пользователей Интренет.
Во второй главе Практическая часть
поэтапно описывается технология организации доступа к базе данных в формате RUSMARC в частности:
· настройка WEB-сервера Apache;
· настройка Java Server для WEB-сервера Apache;
· выбор инструментария для реализации программы:
· описание алгоритма.
Первое приложение содержит полное описание спецификации формата RUSMARC с детальным описанием всех полей и подполей и возможных их значении.
Во втором приложении приведены ключевые моменты спецификации языка программирования Java.
Третье приложение содержит листинг программы с включенными в него комментариями.
В четвертом приложении приведены результаты проведенного теста на реальных массивах данных.
1.
Internet – технология работы с базами данных
1.1
Реализация доступа к базе данных.
Использование технологий WWW для обеспечения доступа к каким-либо информационным ресурсам подразумевает существование следующих компонент.
1. IP - сети с поддержкой базового набора услуг по передаче данных с единой политикой нумерации и маршрутизации, работающим сервисом имен DNS.
2. Выделенного информационного сервера - WWW-сервера, обеспечивающего предоставление гипертекстовых документов через IP - сеть в ответ на запросы WWW – клиентов (см. рис. 1).
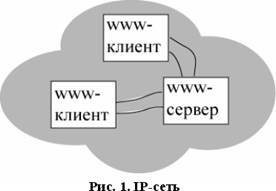
Передаваемые гипертекстовые документы оформляются в стандарте HTML - языке описания гипертекстовых документов. Эти документы могут либо храниться в статическом виде (совокупность файлов на диске), либо динамически компоноваться в зависимости от параметров запроса специальным программным обеспечением. Для динамической компоновки HTML-документов, WWW-сервер использует специальным образом оформленные программы- CGI- или Java-программы.
В состав специфики конкретной БД входят как технологические основы, такие как тип СУБД, вид интерфейсов, связи между таблицами, ограничения целостности, так и организационные решения, связанные с поддержкой актуальности баз данных и обеспечением доступа к ней (3).
При обеспечении WWW-доступа к существующим БД, возможен ряд путей - комплексов технологических и организационных решений. Практика использования WWW-технологии для доступа к существующим БД предоставляет широкий спектр технологических решений, по-разному связанных между собой - перекрывающих, взаимодействующих и т.д. Выбор конкретных решений при обеспечении доступа зависит от специфики конкретной СУБД и от ряда других факторов, как то: наличие специалистов, способных с минимальными издержками освоить определенную ветвь технологических решений, существование других БД, WWW-доступ к которым должен осуществляться с минимальными дополнительными затратами и т.д.
WWW - доступ к существующим базам данных может осуществляться по одному из трех основных сценариев. Ниже дается их краткое описание и основные характеристики.
В этом варианте содержимое БД просматривает специальная программа, создающая множество файлов - связных HTML-документов (см.рис.2). Полученные файлы могут быть перенесены на один или несколько WWW-серверов. Доступ к ним будет осуществляться как к статическим гипертекстовым документам сервера.
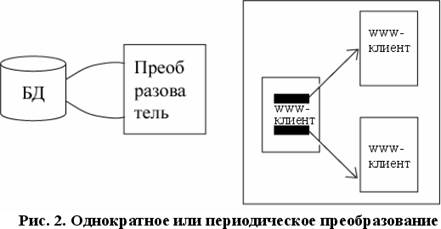
Этот вариант характеризуется минимальными начальными расходами. Он эффективен на небольших массивах данных простой структуры и редким обновлением, а также при пониженных требованиях к актуальности данных, предоставляемых через WWW. Кроме этого, очевидно полное отсутствие механизма поиска, хотя возможно развитое индексирование.
В качестве преобразователя может выступать программный комплекс, автоматически или полуавтоматически генерирующий статические документы. Программа-преобразователь может являться самостоятельно разработанной программой либо быть интегрированным средством класса генераторов отчетов.
В этом варианте доступ к БД осуществляется специальной CGI-программой, запускаемой WWW-сервером в ответ на запрос WWW - клиента. Эта программа, обрабатывая запрос, просматривает содержимое БД и создает выходной HTML-документ, возвращаемый клиенту. (см. рис. 3)

Это решение эффективно для больших баз данных со сложной структурой и при необходимости поддержки операций поиска. Показаниями также являются частое обновление и невозможность синхронизации преобразования БД в статические документы с обновлением содержимого. В этом варианте, возможно, осуществлять изменение БД из WWW-интерфейсов.
К недостаткам этого метода можно отнести большое время обработки запросов, необходимость постоянного доступа к основной базе данных, дополнительную загрузку средств поддержки БД, связанную с обработкой запросов от WWW - сервера.
Для реализации такой технологии необходимо использовать взаимодействие WWW-сервера с запускаемыми программами CGI - Common Gateway Interface. Выбор программных средств достаточно широк - языки программирования, интегрированные средства типа генераторов отчетов. Для СУБД с внутренними языками программирования существуют варианты использования этого языка для генерации документов.
В этом варианте предлагается использование технологии, получившей название "информационного хранилища" (ИХ). Для обработки разнообразных запросов, в том числе и от WWW-сервера, используется промежуточная БД высокой производительности. Информационное наполнение промежуточной БД осуществляется специализированным программным обеспечением на основе содержимого основных баз данных.
Этап 1 - перегрузка данных;
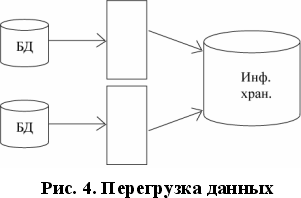
Этап 2 - обработка запросов.

Данный вариант свободен ото всех недостатков предыдущей схемы. Более того, после установления синхронизации данных информационного хранилища с основными БД возможен перенос пользовательских интерфейсов на информационное хранилище, что существенно повысит надежность и производительность, позволит организовать распределенные рабочие места.
Несмотря на кажущуюся громоздкость такой схемы, для задач обеспечения WWW-доступа к содержимому нескольких баз данных накладные расходы существенно уменьшаются.
Основой повышения производительности обработки WWW-запросов и резкого увеличения скорости разработки WWW-интерфейсов является использование внутренних языков СУБД информационного хранилища для создания гипертекстовых документов.
Для загрузки содержимого основной БД в информационное хранилище могут использоваться все перечисленные решения (языки программирования, интегрированные средства), а также специализированные средства перегрузки, поставляемые с SQL-сервером и продукты поддержки информационных хранилищ.
1.2. Обзор технологий
Как было сказано ранее, одним из ключевых элементов технологии WWW является WWW-сервер. Стандартом де-факто для Unix-систем стало программное обеспечение (ПО) WWW-сервера Национального Центра по Суперкомпьютерным Приложениям (NCSA) Иллинойского Университета. Все вновь создаваемые продукты поддерживают полную совместимость с ПО NCSA по режимам работы и форматом данных. Сервер NCSA является постоянно совершенствуемым продуктом, отражающим последние веяния WWW-технологии. Созданная относительно недавно "Apache Group" разрабатывает свое программное обеспечение WWW - сервера на базе продукта NCSA HTTPD. Описание WWW-сервера Apache в следующем пункте.
Самый распространенный Web-сервер в мире - это Apache . По данным компании Netcraft (15) общее число Web-узлов, работающих под его управлением, к концу 1998 г. достигло 2 млн. (55% общего числа узлов) и постоянно растет. Для сравнения: на долю серверов Microsoft приходится 25%, Netscape -7%. Будучи бесплатной открытой программой, предназначенной для бесплатных же Unix-систем (FreeBSD, Linux и др.), Apache по функциональным возможностям и надежности не уступает коммерческим серверам, а широкие возможности конфигурирования позволяют настроить его для работы практически с любой конкретной системой. Существуют локализации сервера для различных языков, в том числе и для русского.
Исторически сложилось так, что русские тексты в Internet могут быть представлены в разных кодировках, из которых наиболее распространены koi8-r (или просто koi8) и Windows-1251: с первой работает большинство серверов и рабочих станций под управлением Unix, вторая является стандартной для всех версий Windows. Поскольку кодировка Windows-1251, естественно, применяется на подавляющем большинстве клиентских машин, доля тех, кто путешествует по русской части WWW, используя koi8, не превышает сейчас 5%. Однако в этой кодировке хранятся документы на многих Unix-серверах, в ней чаще всего передаются почтовые сообщения и практически всегда - письма в телеконференции, с ней же работают многие русскоязычные каналы IRC (кстати, аббревиатура КОИ расшифровывается как "код обмена информацией"). Чтобы решить проблемы, возникающие при несовпадении кодировок текста на сервере и клиентской машине, и был создан русский модуль Apache -RUS для Web-сервера Apache .
Для тех, кто имеет дело с различными компьютерными платформами и стремится к универсализму, выбор Apache HTTP-сервера является, пожалуй, самым подходящим. Разве плохо, когда написанные модули могут работать и на ПК и на многопроцессорных высокопроизводительных системах, причем инсталляция и компоновка рабочих программ, как правило, не требуется, дело сводится к простому копированию. Можно, не выходя из офиса, перемещать рабочие программы в специальные каталоги Web-сервера, находящегося за тридевять земель, и они мгновенно могут быть востребованы десятками пользователей, которым нет необходимости загружать их на свои компьютеры. До недавнего времени все Web-серверы могли вызывать на выполнение только три типа процессов: CGI, ISAPI или NSAPI, причем два последних чаще всего были реализованы на Wintel-платформе. Так, с появлением Delphi-3 многие стали предлагать свои разработки в виде Web-модулей, но аппетиты пользователей умерялись разработчиками, которые могли предложить только вариант Web, работающий под Windows-95/NT, и для связи с СУБД на больших машинах приходилось применять некое подобие Gateway-ODBC. Такой вариант не всегда оказывался эффективным, тем более что протокол HTTP при каждом новом запросе требовал перезагрузки модуля Применение сервлетов в связке с СУБД решает эту проблему. Для Apache существует специальный программный компонент JServ, который также как и сам сервер в исходных кодах распространяется совершенно бесплатно. При запуске Apache автоматически стартует Java-обработчик, которому и будут передаваться на исполнение все запросы, связанные с запуском Java-программ. Наоборот, весь вывод из Java переадресуется непосредственно в Web, который аккуратным образом передает его, запросившему браузеру. Скорость выполнения Java-приложений зависит от производительности компьютера, на котором сконфигурирован Web-сервер Apache. Если это, к примеру, UltraSparc-3000 c Java-виртуальной машиной HotSpot, то скорость может быть очень большой, в десятки, а то и в сотни раз быстрее, чем на обычной NT-машине. Apache, в отличие от браузеров не имеет собственной виртуальной машины Java, а настраивается на ту, которая сгенерирована для данной платформы. Такой подход чрезвычайно гибок, ибо позволяет постоянно обновлять Java-среду, наращивать библиотеку классов и ничего не изменять в настройках Apache. Впрочем, и в самих конфигурационных файлах Apache для программистов имеется масса полезных вещей, они свободно корректируются, открыты для добавлений и предоставляют гораздо больше простора для маневра по сравнению с жестко запрограммированными системами для администрирования Web-узлов, такими как Fastrack, или Java Web Server. Для того чтобы использовать Apache во взаимодействии с Java, необходимо инсталлировать продукт Jserv, содержащий необходимые библиотеки Java-классов, затем изменить конфигурационный файл Apache Configuration, добавив в него строку:
Module jserv_module mod_jserv.o -для Unix-система.
Более подробно описание подключения Jserv`а рассмотрено в практической части.
При реализации сценария 3 встает вопрос о выборе качественной платформы для создания информационного хранилища. Реляционная система управления базами данных фирмы Oracle является лидером на рынке СУБД. По производительности, надежности хранения данных, развитию семейства интерфейсов, объему серверных платформ продукты Oracle возглавляют многочисленные рейтинги. Гибкость использования, развитые средства управления доступом и распределенная архитектура делают сервер Oracle чрезвычайно привлекательным для технологии информационных хранилищ, а возможность работы на свободно - распространяемых Unix-платформах расширяет его возможности в некоммерческой среде.
Существенным ограничением использование Oracle в сфере науки и образования является достаточно высокая цена и низкое бюджетное финансирование. Однако с 1996 года фирма Oracle объявила о специальной программе для российских университетов, что позволяет за относительно небольшие деньги приобрести любой набор продуктов Oracle.
Язык Perl был создан для повышения эффективности обработки текстовых документов. Он ориентирован на обработку строк. В настоящее время язык получил большое распространение как инструмент создания исполняемых модулей WWW-сервера. Существующие пакеты расширения обеспечивают доступ к SQL-серверам непосредственно из Perl-программы. Это позволяет использовать его для решения всех задач, возникающих при обеспечении WWW-доступа к базам данных. Perl эффективен также при обработке произвольных структур данных: существующих отчетов, списков, карточек в электронном виде().
Java – это простой, объектно-ориентированный, распределенный, интерпретирующий, живучий, безопасный, архитектурно-нейтральный, переносимый, высокопроизводительный, многопоточный и производимый язык.
Компилятор Java читает исходные файлы и превращает их в байт-код (byte-code). Байт-код представляет собой промежуточную стадию между исходным кодом и машинным кодом, как можно более близкую к машинному коду. Но близкую не настолько, чтобы стать платформо-зависимой. Если точнее, то байт-код является машинным кодом, но не для какой-нибудь физически существующей машины, а для Java Virtual Machine – мифической машины, чье поведение в точности определено Sun Microsystems. Спецификации Java Virtual Machine (JVM) описывают поведение, ожидаемое от любой физической машины, которая выполняет любой заданный байт-код. Подчинение спецификациям JVM – вот что обеспечивает переносимость программ Java.
Сервлеты - это высокопроизводительные платформо-независимые server-side-пpиложения, написанные на Java и составляющие реальную конкуренцию таким технологиям, как CGI, PHP3, Perl, и уж конечно ASP.
К преимуществам сервлетов можно отнести:
Исключительно высокая скорость работы.
Быстpодействие сервлетов объясняется тем, что они, во-пеpвых, пpедставляют собою уже скомпилиpованный и оптимизиpованный код (а в случае с JIT-ом - ещё и пpеобpазованный в машинный) и, во-втоpых, выполняются в единожды загpуженной и инициализиpованной Java-машине.
Таким образом, экономятся ресурсы на запуск обработчика/паpсеpа скpипта, необходимые, например, для Perl или PHP3 (в некоторых ОС, в частности, в OS/2 - это очень серьезная экономия), и ресурсы (как память, так и время), затрачиваемые на непосредственно предкомпиляцию (интерпретацию) кода (что необходимо для тех же Perl, PHP, REXX).
Реально обе этих проблемы сразу не решаются, практически, нигде. Hаибольший эффект даёт, пожалуй, внедрение транслятора скpиптового языка непосредственно в веб-сеpвеp, например, пресловутые .asp-скpипты в серверах от Microsoft, или модули mod_perl
или mod_php
для apache. (Последний вариант - PHP3, внедренный в апач - является, наверное, самым производительным из всего вышеперечисленного).
Переносимость.
В данном случае принцип "write once run everywhere" действует безотказно. Сервлеты, написанные в соответствии со спецификацией от Sun и не использующие какие-то особенности конкретного веб-сервера, работают безо всякой переделки или перекомпиляции под любыми, порой весьма далёкими друг от друга платформами, будь то Solaris, FreeBSD или OS/2. В связи с этим разработчик может совершенно свободно выбирать, в какой системе ему удобнее работать - он ни коим образом не привязан ни к серверу, ни к будущей целевой платформе.
Удобство кодирования и инструментарий разработчика.
Не знаю, как другим, а мне Java как язык программирования нравится неизмеримо больше, чем тот же Perl или чрезвычайно быстрый, но, несколько убогий PHP3. Более того, даже некоторые мелочи в C++ начинают раздражать после долгой практики кодирования на Java. (Должен заметить, что я ничего не имею против перечисленных выше языков, отношусь к ним с должным уважением и использую их в своей работе.)
Кроме того, на рынке присутствует немалое количество мощнейших инструментов для разработчиков приложений на Java. Например, тот же VisualAge for Java 2.0 содержит средства визуального создания сервлетов - по сути, этакий WYSIWYG-pедактоp веб-страниц, создающий вместо HTML-документов сеpвлеты, генеpиpующие эти документы на лету.
Работа с базами данных.
Работа с реляционными СУБД из Java унифицирована (для этого существует специальный пакет java.sql
), удобна и отвязана от специфичных для конкретной СУБД тонкостей. Всё, что Вам нужно - это найти для своей СУБД JDBC-дpайвеpы (а они сейчас существуют практически для всех совpеменных баз данных, зачастую даже по нескольку pазновидностей), и далее можно пользоваться совеpшенно стандаpтными механизмами.
А при переходе на другую СУБД, например, c MySQL на Oracle, достаточно будет просто добавить в CLASSPATH новый драйвер и поменять URL для подключения к другой базе. Ни одного изменения в коде
Перспективность, современность технологий.
Конечно, есть у этой технологии и недостатки. Как технические: например, высокие требования к системным ресурсам - в основном, к памяти (под OS/2, например, запущенная Java-машина занимает 15-20 мегабайт оперативной памяти) или необходимсть в качественной устойчивой реализации Java для выбранной платформы, так и иного плана: такие как отсутствие должной квалификации как у разработчиков, так и, зачастую, у тех, кто принимает решения, их устоявшиеся предубеждения и многое другое...
Итак, как же работают сервлеты. Рассмотрим это на примере модуля JServ к веб-серверу apache.
В момент старта сервера вместе с ним стартует и ява-машина с так называемым servlet-wrapper'ом или средой, в которой в дальнейшем и предстоит исполняться сервлетам. Строго говоря, JServ - это и есть та самая среда. Он целиком написан на Java и занимается непосредственно загрузкой и исполнением сервлетов, следуя спецификации Sun, а также обменом данными с собственно веб-сервером. В последнем для этого должен присутствовать специальный модуль mod_jserv (его необходимо добавить при компиляции и сборке apache, или подключить в виде внешнего модуля).
При получении запроса на документ, приходящийся на специально оговоренный URL или каталог (обычно это что-нибудь вроде /servlets/), apache с помощью модуля mod_jserv передает этот запрос JServ'у, который определяет, какой сервлет должен этот запрос обработать, загружает этот сервлет (если он ещё не был загружен) и затем возвращает веб-серверу тот текст или поток данных, который был сформирован в результате работы сервлета.
Изначально сервер "пуст" - при его старте сервлеты обычно не загружаются (хотя есть возможность принудительно инициализировать нужные сервлеты при старте сервера). При появлении запроса нужный сервлет ищется в списке уже загруженных и, при необходимости, стартуется и инициализируется. После этого он остается постоянно загруженным в Java-машине (и предкомпилированным, если Java-машина содержит JIT) и при последующих запросах просто вызывается соответствующий его метод для их обработки. Преимущества такой идеологии очевидны. Функционально это аналогично вызову простой подпрограммы внутри обычного сервера и проиходит очень быстро и эффективно. Кроме того, заметный выигрыш дают такие вещи, как единожды проведенная инициализация, возможность хранения глобальных данных или поддержка множественных клиентских сессий, ведущаяся самим сеpвеpом
(а не сеpвлетами, pазpаботчики котоpых в значительной степени избавлены от изобpетания велосипедов). Например, можно установить одно единственное соединение с базой данных, и пользоваться им при обработке запросов - немалая экономия, учитывая то, что из тех же скриптов на perl или php приходится каждый раз создавать новое соединение, восстанавливать параметры сессии и т.п.
Конечно же, существует возможность принудительной выгрузки
отдельных сервлетов из памяти в случае необходимости, а также возможность автоматического распознавания изменения сервлетов и их перезагрузки. Иными словами, при обновлении того или иного сервлета нет необходимости перезагружать весь веб-сервер или JServ, достаточно просто положить новую версию на место старой, и она будет автоматически загружена в память при следующем запросе (естественно, при этом будет сначала произведено корректное завершение работы старой версии, путём вызова специального метода, а затем загрузка и инициализация новой).
Пакет WOW является свободно-распространяемым программным средством, предназначенным для создания интерактивных WWW-интерфейсов с СУБД Oracle. Пакет WOW был первым и наиболее простым средством, выпущенным фирмой Oracle. В настоящее время существует набор продуктов, развивающих функциональность WOW'а - Oracle Web Server версий 1, 2, Oracle Web Arcitecture.
Все перечисленные продукты позволяют использовать процедурное расширение языка SQL - PL/SQL, разработанное фирмой Oracle для динамического создания гипертекстовых документов. Высокая скорость разработки достигается за счет резкого упрощения доступа к БД - программы на PL/SQL исполняются самим сервером Oracle. Предлагаемый пакет WOW был переработан в Новосибирском областном центре НИТ с целью поддержки нескольких русскоязычных кодировок.
Основной областью использования WOW является обработка запросов от WWW-сервера к SQL-серверу Oracle в среде Unix. В предложенных сценариях пакет WOW позволит организовать эффективный WWW доступ к информационному хранилищу, построенному на базе сервера баз данных Oracle (сценарий 3).
Пакет предназначен для использования под ОС Windows и позволяет обращаться к различным базам данных, поддерживающим интерфейс ODBC через WWW-интерфейсы. Пакет имеет коммерческий статус, его "evaluation copy" является свободно-распространяемой. Для доступа к базам данных используются конструкции языка DBML - расширения языка HTML, дополненного средствами доступа к БД через ODBC. Документы на языке DBML обрабатываются на серверной части, в результате чего создается HTML-документ. Полноценная версия пакета, вместе с WWW - сервером стоит $486.
Пакет может эффективно использоваться в качестве обработчика запросов WWW к исходным базам данных или информационному хранилищу (сценарии 2,3)
1.3. Оценка трудоемкости обеспечения WWW доступа
Трудоемкость обеспечения WWW-доступа к базам данных, очевидно, складывается из трудоемкости работ при реализации одного из вышеприведенных сценариев. Реализация первого сценария связана с последовательным преобразованием всех данных, находящихся в исходной БД. Разработка средств вывода содержимого таблицы в формате HTML с необходимым форматированием и текстовым сопровождением будет занимать порядка 1-3-х дней для одного разработчика. Разработка средств построения индексной структуры к выводимым данным является более творческой работой и может занять 1-3 недели для одного разработчика.
Трудоемкость построения интерфейсов для сценариев 2, 3, в общем случае, эквивалентна трудоемкости построения этих интерфейсов при создании исходной информационной системы (т.е. той, для которой обеспечивается WWW-доступ) с использованием традиционных средств разработки (не-CASE). В третьем сценарии дополнительные трудозатраты пойдут на перегрузку данных в иформационное хранилище. При перегрузке данных без изменения структуры и имен можно исходить из оценки трудозатрат: 1-2 таблицы в 1-2 дня для одного разработчика, в зависимости от сложности и объема таблиц, при условии отладки технологии перегрузки.
При использовании различных средств разработки интерфейсов к БД, представленных в отчете, трудозатраты могут существенно различаться.
2. Практическая часть
Широкие возможности WWW - технологии по представлению пользователям Internet информации, включая текст, картинки, графики, видео и звуковые дорожки, обусловили процесс бурного роста сети WWW - серверов и Internet в целом. Целью данной дипломной работы является освещение технологии организации доступа к БД в формате RUS-MARC, посредствам выбранного инстрементария в данном случае это язык Java .
2.1 ОБЩАЯ ЧАСТЬ
WWW сервер - это такая часть глобальной или внутрикорпоративной сети, которая дает возможность пользователям сети получать доступ к гипертекстовым документам, расположенным на данном сервере. Для взаимодействия с WWW сервером пользователь сети должен использовать специализированное программное обеспечение - браузер (от англ. browser), другое название - программа просмотра.
Схема работы
Рассмотрим более подробно, чем в предыдущих главах, схему работы WWW-сервера. В общем виде она выглядит так:
1. Пользователь сети запускает пакет программного обеспечения, называемый браузером, в функции которого входит
o Установление связи с сервером
o Получение требуемого документа
o Отображение полученного документа
o Реагирование на действия пользователя - доступ к новому документу
o После запуска браузер по команде пользователя или автоматически устанавливает связь с заданным WWW - сервером и передает ему запрос на получение заданного документа
2. WWW сервер ищет запрашиваемый документ и возвращает результаты браузеру
3. Браузер, получив документ, отображает его пользователю и ожидает его реакции.
o Возможные варианты:
o Ввод адреса нового документа
o Печать, поиск, другие операции над текущим документом
o Активизация (нажатие) специальных зон полученного документа, называемых связями (link) и ассоциироваными с адресом нового документа.
o В первом и третьем случае происходит обращение за новым документом.
Адрес
Адрес документа указывается в виде специальной строки, называемой URL. Для протокола HTTP, используемого при взаимодействии WWW клиента и WWW сервера, URL состоит из следующих компонент:
1) Наименование протокола, по которому работает сервер (http).
2) Имя машины - сервера в Internet или ее IP - номер.
3) Порт TCP, обращение к которому обрабатывает сервер.
4) Место (путь) документа на машине - сервере.
Например:
http://www.cnit.nsu.ru:80/welcome.html
Здесь http означает протокол работы с WWW - сервером
o ':
' - разделитель
o "www.cnit.nsu.ru
" - имя машины - сервера в Internet
o "80
" - номер tcp - порта
o /welcome.html
- путь до документа на машине - сервере
Из общей схемы работы видно, что функции WWW сервера заключаются в следующем:
1) Установление соединения с клиентским ПО по протоколу tcp.
2) Принятие запроса на документ по протоколу http.
3) Поиск документа в локальных ресурсах.
4) Возврат результатов поиска по протоколу http.
В общем случае, WWW - сервером будем называть программно - аппаратный комплекс, предназначенный для выполнения вышеперечисленных действий.
Среда работы сервера
В настоящее время все известные WWW - серверы представляют собой компьютер общего назначения с многозадачной операционной системой. Один или несколько процессов такой системы отвечают за поддержку специфических для WWW - сервера функций. Другие процессы ОС отвечают за обеспечение других функций, не обязательно связанных с поддержкой технологии WWW.
Такая структура приводит к тому, что под WWW сервером начинают подразумевать только часть программного обеспечения, единственными функциями которой являются функции WWW сервера, а остальную часть - компьютер, операционную систему, другие процессы, сетевую структуру называют средой работы WWW сервера или платформой (см. таблица 1).
Наиболее распространенных платформ для WWW – сервера. Таблица 1
| Компьютер
|
Операционная Система
|
| IBM PC
|
o Unix (UnixWare, Open Server, Solaris, BSD, Linux и т.д.)
o Microsoft Windows NT/2000
o IBM OS/2
o Novell NetWare
|
| Sun SparcStation и SparcServer
|
o SunOS
o Solaris
|
| Silicon Graphics серверы и рабочие станции
|
o IRIS
|
В простейшем случае гипертекстовый документ представляет собой совокупность файлов. Представление этих файлов как единого документа производится браузером. По каждому файлу документа браузер делает запрос к WWW - серверу. Таким образом, сервер не имеет представления о структуре и составе документов, он отвечает только за выдачу локальных файлов по запросам. На различных платформах, в различных операционных системах пути файлов выглядят по разному.
Например:
D:\WWW\INDEX.HTM
- в Windows,
/u/data/www/html/index.html
- в Unix - системах,
USR:WWW/HTML
- в NetWare и т.д.
Путь файла, указываемый в URL, имеет стандартный вид:
/<имя_каталога>/ ... /<имя_каталога>/<имя_файла>
Таким образом, в функции WWW - сервера входит преобразование адреса из внешнего единого формата в платформенно ориентированный внутренний формат. Появляется ряд понятий, специфичных для такого преобразования, необходимых для него.
Исходный каталог документов
Это каталог реальной файловой системы сервера, от которого идет вычисление пути, указанного в URL. Например, если исходным каталогом документов является D:\WWW\
, то на запрос к этому серверу документа по URL
http://<имя_сервера>/index.htm
будет возвращен файл
D:\WWW\index.htm
Синонимы
В случае, когда необходимо осуществить обращение к конкретному каталогу или файлу, находящемуся вне иерархии Исходного каталога документов, используется механизм синонимов. Синоним позволяет явно определить соответствие между путем, указанным в URL, и путем локальной файловой системы.
Например:
Синонимом для /Harvest
объявляется /projects/www/harvest
или
синонимом для /test/myfile.html
объявляется C:\MYDIR\FILE.HTM
В первом случае все обращения к файлам каталога /Harvest будут обрабатываться в каталоге /projects/www/harvest
. Второй пример показывает работу синонима с конкретным файлом файловой системы.
Индексный файл
Для каждого сервера определено имя так называемого индексного файла. Обычно этот файл содержит ссылки на другие файлы данного каталога. Содержимое индексного файла выдается сервером в случае, если в URL указан каталог без конкретного файла.
Пользовательский раздел
Для многопользовательских операционных систем (таких как Unix) ПО WWW - сервера позволяет каждому пользователю предоставлять доступ к своему собственному набору гипертекстовых документов вне основной иерархии (Исходного каталога документов, Синонимов и т.д.). Этот набор документов должен находиться в собственном (т.н. "домашнем") каталоге пользователя. Для доступа к таким документам в URL перед путем ставится знак тильда и имя пользователя: ~<имя_пользователя>.
Например:
На сервере Indy.cnit.nsu.ru создан пользователь с именем fancy и "домашним" каталогом /home/fancy
. Собственные гипертекстовые документы он хранит в каталоге /home/fancy/public_html
. При обращении по URL http://Indy.cnit.nsu.ru/~fancy/start.html
, WWW - сервер будет искать документ start.html в каталоге /home/fancy/public_html
.
Протокол MIME - многоцелевое расширение электронной почты, был создан как способ передачи нетекстовой информации: изображений, звука, видео в письмах электронной почты. Механизм оказался удачным, и его перенесли и в on-line сервисы, в том числе WWW. Здесь MIME используется для передачи документов от сервера к клиенту.
В общем виде MIME основывается на передаче вместе с основными данными дополнительной информации, описывающей что это и в каком виде передается. Эта дополнительная информация называется заголовок MIME. Базовой частью заголовка является строка, описывающая тип передаваемого сообщения. Формат строки:
Content-Type: <тип_MIME>
Перечень типов MIME (т.е. видов передаваемых данных) постоянно пополняется и может быть дополнен даже пользователем для описания своего собственного вида данных. Формат типа MIME:
<Тип> / <Подтип> [ ; <параметры> ]
Где <Тип> - определяет общий тип данных:
Audio - для звуковых данных
Application - данные, являющиеся входными для какого-либо приложения (программы)
Image - для графических образов
Message - для сообщения, которое само по себе является MIME - документом
Multipart - для сообщения, состоящего из нескольких MIME - документов
Text - для текстовых данных в различном виде
Video - для видеоданных.
<Подтип> - указывает на специфический формат данных типа <Тип>
Например:
text/html - текстовые данные в формате HTML
image/giff - графические данные в формате gifF
<Параметры> - список параметров, необходимых для интерпретации данных.
Для ведения специфичной обработки файлов различных типов и форматов на клиентской и серверной частях поддерживаются списки соответствий типов MIME и расширений файлов. Формат записи такого списка:
<Тип>/<Подтип> <расширение1> ... <расширениеN>
Эти списки сопоставляют всем файлам, имеющим определенные расширения, определенные типы MIME.
Например:
image/giff gif giff
text/html html htm
В первой строке всем файлам с расширением gif и giff приписывается тип содержимого image/giff. Если для типа содержимого image/giff определены специальные правила обработки (например, отображение на экране в определенной области), то так будут обрабатываться все файлы с расширениями gif и giff.
Протокол HTTP определяет язык запросов от WWW - клиента к WWW - серверу. Сам запрос состоит из следующих компонент:
<Заголовок>
<Метод> <Источник / Данные>
где
Заголовок - определяет версию протокола HTTP и другие служебные параметры;
Метод - одно из ключевых слов:
GET - для передачи запросов на выдачу документов
PUT, POST - для передачи данных от клиента к серверу (например, из форм)
Пример запроса:
HTTP/1.1
GET /index.html
Описывает запрос на получение файла index.html из корневого каталога документов сервера.
Помимо доступа к статическим документам сервера существует возможность получения документов как результата выполнения прикладной программы. Такая возможность реализуется на сервере WWW благодаря использованию интерфейса CGI (Common Gateway Interface). Спецификация CGI описывает формат и правила обмена данными между ПО WWW сервера и запускаемой программой.
Для инициирования CGI необходимо, чтобы в запрашиваемом URL был указан путь до запускаемой программы. ПО WWW сервера исполняет эту программу, передает ей входные параметры и возвращает результаты ее работы, как результат обработки запроса, клиенту. CGI - программой может являться любая программа локальной операционной системы сервера - в двоичном виде или в виде программы для интерпретатора (Basic, SH, Perl и т.д.).
С целью облегчения администрирования CGI - программ, а также для удовлетворения требованиям безопасности CGI - программы группируются в одном или нескольких явно указанных серверу каталогах. По умолчанию это каталог cgi-bin в иерархии серверных каталогов, однако, его имя и положение могут отличаться.
Например:
клиент, обращающийся к CGI - программе test-query, будет использовать URL http://<имя_сервера>/cgi-bin/test-query
Интерфейс CGI позволяет расширить границы применения WWW - технологии. CGI - программа может обрабатывать сигналы с датчиков установок, взаимодействовать с мощным сервером баз данных, переводить и т.п. Полное описание интерфейса и требований к приложениям, использующих его, приведены в главе 4 настоящего отчета.
2.2. Web-сервера Apache
Apache - самый распространенный Web-сервер в мире. По данным компании Netcraft (15) общее число Web-узлов, работающих под его управлением, к концу 1998 г. достигло 2 млн. (55% общего числа узлов) и постоянно растет. Для сравнения: на долю серверов Microsoft приходится 25%, Netscape - 7%. Будучи бесплатной открытой программой, предназначенной для бесплатных же Unix-систем (FreeBCD, Linux и др.), Apache по функциональным возможностям и надежности не уступает коммерческим серверам, а широкие возможности конфигурирования позволяют настроить его для работы практически с любой конкретной системой. Существуют локализации сервера для различных языков, в том числе и для русского.
Сервер Apache имеет небольшой, но представительный набор примеров приложений, однако в его составе отсутствует хорошая документация. Продукт Apache обладает многими встроенными функциями, но поскольку объем его документации невелик, понять, как им пользоваться довольно трудно. Вследствие этого работа с сервером требует больших дополнительных затрат: получаемый бесплатно, он становится дорогим, когда вы хотите раздвинуть границы его применения.
Характеристика
Компания - The Apache Group
Продукт - Apache Web Server 1.3.14
Операционная система - OS/2, Unix, Windows, BeOS
Тип процессора - Alpha, Intel 80486, Pentium, Pentium Pro, PowerPC
Требования к памяти - ОЗУ 32 МБ
Функции регистрации:
формат CERN - нет
формат NCSA - есть
автоматическое архивирование - нет
регистрация производительности - есть
использование браузеров - есть
отчеты об использовании - нет
Защита - SHTTP, SSL
API и средства написания сценариев - Basic, CGI, JavaScript API, Java (если при компиляции были внесены изменения и добавлены модули продукта JServ )
Специальные функции:
SMP - есть
конференцсвязь - есть
передача полномочий другому Web-серверу - есть
сервер новостей - нет.
Многие Web-мастера и сетевые администраторы настроили серверы Apache под свои нужды благодаря их преимуществу - сравнительно простой архитектуре.
Начнем с того, что серверов существует множество - плохие и хорошие, медленные и быстрые... Я же выбрал сервер, подходящий под последние две категории, - Apache. Самое главное то, что это чуть ли не единственный сервер, который позволяет работать в Windows 95/98/NT с технологиями PHP, CGI и Perl-скриптами одновременно так же просто и непринужденно, как будто он стоит на Unix.
Итак, установить на компьютер Apache для Windows 95/98/NT довольно просто при наличии дистрибутива сервера. В противном случае следует запастись терпением и скачать дистрибутив сервера - файл apache_1_3_14_win32_r2.exe (3 176 975 байт) (13). Теперь самое интересное - настройка Apache.
Важно: просьба в точности выполнять перечисленные ниже шаги, не пропуская и не откладывая ни одного из действий. В этом случае все заработает - это проверено.
Этап первый - установка
Нужно определиться с директорией, в которую будете устанавливать Apache. Все дальнейшие рассуждения основаны на том, что выбран для этой цели такой каталог: f:\usr\local\apache . Если диска F: нет, или если неохота его захламлять, советую сделать одно из трех:
1) Создайте диск F: с помощью какой-нибудь программы для виртуальных разделов (например, с помощью встроенной в Windows 95/98 программы DriveSpace). Это самое лучшее решение, и с точки зрения экономии памяти, и с точки зрения быстродействия. Ведь что такое Web-сайт, как не набор очень небольших файлов? А DriveSpace как раз и оптимизирует работу с такими файлами.
2) Сделайте виртуальный диск F:. Для этого нужно создайть где-нибудь на любом диске директорию, которая в будущем будет являться корневой для диска F:. Предположим, выбран C:\INTERNET. Далее, в начале файла c:\autoexec.bat в нем прописывается такая строка:
subst f: C:\INTERNET
и после чего нужно перезагрузить компьютер. Должен появиться виртуальный пустой диск F:.
ВНИМАНИЕ: имеются сведения, что в Windows 95/98 есть ошибка, в результате которой иногда subst-пути "сами по себе" преобразуются в абсолютные. То есть, например, иногда в рассмотренном выше примере команды f: cd \ cd \ dir
(а точнее, команда dir в своем заголовке) ошибочно выведут, что текущая директория C:\ (а не F:\, как это должно быть). Указанная ошибка чаще всего проявляется в неработоспособности Perl-транслятора. Так что лично я не рекомендую использовать subst. Вместо этого воспользоваться пунктом 1.
3) Наконец, можно всего этого не делать и поставить Apache на любой другой диск, только тогда придется немного тяжелее при выполнении всех остальных действий. Нужно будет все указываемые пути заменять на собственные, а это крайне неприятно. Еще раз настоятельно рекомендую воспользоваться диском F:.
Рекомендую все же разместить Apache в указанном в начале каталоге.
Запускаем только что скачанный файл. В появившемся диалоге нажимаем кнопку Yes, а затем - кнопку Next.
Теперь нужно вручную задать директорию для установки: f:\usr\local\apache и нажимаем кнопку OK.
Выбираем тип установки - Сustom и убираем флажок Source Code (если, конечно, не хотите посмотреть исходные тексты Apache). Этим можно сэкономить себе 3 Мбайта.
Нажимаем Next и ждем, пока будут копироваться файлы Apache.
На запрос о перезагрузке компьютера нужно ответить утвердительно "Перезагрузить".
После всех манипуляций можно вздохнуть с облегчением - Apache установлен! Ну после этого самое неприятное - его настройка.
Настройка файла конфигурации Apache mime.types
Для этого нужно открыть директорию f:\usr\local\apache\conf. Открыть для редактирования находящийся там файл mime.types.
Найти в нем такую строчку:
text/html html htm
Изменить ее на
text/html html htm shtml shtm sht
Следует заметить, что если по каким-то причинам не нужно портить файл mime.types, то можно вместо этого прописать в файле httpd.conf (см. ниже) строки вида
AddType text/html html htm shtml shtm sht
Этап третий - настройка файла httpd.conf
Внимание! Это - самый ответственный момент установки. Просьба соблюдать инструкции БУКВАЛЬНО.
Откройте директорию f:\usr\local\apache\conf. Откройте находящийся там файл httpd.conf. Это - единственный файл, который осталось настроить. Предстоит найти и изменить в нем некоторые строки, а именно те, о которых упоминается далее. Во избежание недоразумений не нужно трогать все остальное. Следует заметить, что в нем каждый параметр сопровождается несколькими строками комментариев, разобраться в которых с первого раза довольно тяжело. Поэтому на них можно не обращать внимание.
В поле ServerAdmin нужно указать E-mail адрес, который будет показываться в сообщениях об ошибке сервера. Например:
ServerAdmin my@email.com
В поле ServerName нужно указать имя сервера, например:
ServerName www.real.ulan-ude.ru
И обязательно нужно раскомментировать поле ServerName, то есть убрать символ "#" перед этим параметром (по умолчанию он закомментирован)!
В поле DocumentRoot указывается директория, в которой будут храниться html-файлы, например:
DocumentRoot f:/www
Разумеется, можно указать и любую другую директорию. В любом случае, ее нужно создать, лучше сделайте это прямо сейчас!
Далее нужно найти блок, начинающийся строкой <Directory /> и заканчивающийся </Directory> (вообще, такие блоки обозначают установки для заданной директории и всех ее поддиректорий). Его нужно изменить на:
<Directory />
Options Indexes Includes
AllowOverride All
</Directory>
Дириктивы, примененные в секции<Directory>, имеют следующее значение:
Optinos [options...]
Возможное значение параметров:
ExecCGI - разрешить выполнение CGI-сценариев в данном катологе и его подкаталогах;
FollowSymLinks - разрешить переход по символическим ссылкам (созданным командой lh);
Include - разрешить SSI (Server Side Includes);
Indexes - разрешить выдачу листинга каталога, если в нем нет файла index.html (или файла индекса, заданного дериктивой DirectoryIndex);
MultiVews - разрешить поддержку многих языков; по умолчанию она отключена, и включать ее, как правило, не нужно; поддержка перекодирования "на лету" для русского языка устанавливается с помощью других директив;
All - установить сразу все перечисленные режимы кроме MultiViews.
AllowOverride [options...]
Параметры могут быть указаны следующие:
AuthConfig - разрешить установку авторизации по имени пользователя и паролю;
FileInfo - разрешить директивы, отвечающие за типы документов;
Indexes - резрешить директивы, связанные с листингом каталогов;
Limit - разрешить команды allow и deny, которые ограничивают доступ к файлам в зависимости от адреса клиентского компьютера;
Options - разрешить описанные выше директивы Options.
Таким образом, в этом блоке будут храниться установки для всех директорий по умолчанию (т.к. это - корневая директория).
После чего нужно найти аналогичный блок, начинающийся <Directory "f:/usr/local/apache/htdocs"> и заканчивающийся </Directory>. Там будет много комментариев, на них можно не обращать внимание. Этот блок следует заменить на:
<Directory "f:/www">
Options Indexes Includes
AllowOverride All
Order allow,deny
Allow from all
</Directory>
Это - установки для директории с html-документами. Можно, конечно, установить другую директорию, главное, чтобы она совпадала с той, которая прописана в параметре DocumentRoot
Идем дальше. Установим UserDir, например так:
UserDir f:/www/users
Это будет директория, в которой будут храниться домашние страницы пользователей, а также корневые каталоги виртуальных хостов (см. ниже).
DirectoryIndex устанавливается так:
DirectoryIndex index.htm index.html
Это - так называемые файлы индекса, которые автоматически выдаются сервером при обращении к какой-либо директории, если не указано имя html-документа. В принципе, можно добавить сюда и другие имена, например, index.phtml, если вы будете работать с PHP и т.д.
Найдите и пропишите такой параметр:
ScriptAlias /cgi-bin/ "f:/www/cgi-bin/"
Да, именно так, с двумя слэшами. Это будет та директория, в которой должны храниться CGI-скрипты. Если хотите, можете задать другое имя, например:
ScriptAlias /mycgi/ "f:/mycgidir/"
Подобный параметр говорит Apache о том, что, если будет указан путь вида http://www.real.ulan-ude.ru/cgi-bin, то на самом деле следует обратиться к директории f:/www/cgi-bin.
Теперь следует найти и настроить блок параметров, начинающийся с <Directory "f:/www/cgi-bin"> и заканчивающийся </Directory>. Это - установки для CGI-директории (если был установлен для нее другой путь на предыдущем шаге, соответственно модифицируйте путь). Там должно быть:
<Directory "f:/www/cgi-bin">
AllowOverride All
Options ExecCGI
</Directory>
Настройте следующий параметр:
AddHandler cgi-script .bat .exe
Это говорит Apache о том, что файлы с расширением .exe и .bat нужно рассматривать как CGI-скрипты.
И последнее - установите:
AddHandler server-parsed .shtml .shtm .sht
Или, если Вы хотите, чтобы и обычные файлы html обрабатывались SSI, напишите так:
AddHandler server-parsed .shtml .shtm .sht .html .htm
Настройка Apache завершена, и он должен уже работать! Для запуска сервера нужно нажать Пуск->Программы->Apache Web Server->Start Apache, при этом появится окно, очень похожее на Сеанс MS-DOS, и ничего больше не произойдет. Не закрывайте его и не трогайте до конца работы с Apache.
Несколько слов о том, как можно упростить запуск и завершение сервера. В Windows можно назначить любому ярлыку функциональную комбинацию клавиш, нажав которые, запустится этот ярлык. Так что щелкните правой кнопкой на панели задач, в контекстном меню выберите Свойства, затем Настройка меню и кнопку Дополнительно. В открывшемся Проводнике назначьте ярлыку Start Apache комбинацию Ctrl+Alt+A, а ярлыку Shutdown Apache - Ctrl+Alt+S
Вот шаги, которые можно проделать для проверки работоспособности сервера:
Проверка html: в директории f:/www с html-документами Apache создайте файл index.html. Теперь запустите браузер и наберите:
http://www.real.ulan-ude.ru/index.html
или просто
http://www.real.ulan-ude.ru/
Загрузится Ваш файл.
Проверка CGI: в директории f:/www/cgi-bin для CGI-скриптов создайте файл test.bat с таким содержанием:
@echo off
echo Content-type: text/html
echo.
echo.
dir
Теперь в браузере наберите:
http://www.real.ulan-ude.ru/cgi-bin/test.bat
В окне отобразится результат команды DOS dir.
Проверка SSI: аналогична проверке html. Используйте, например, директиву
<!--#exec cgi="/cgi-bin/test.bat"-->
Итак, Apache установлен. Получена, таким образом, директория f:/www для хранения документов и f:/www/cgi-bin для CGI. Но вот беда: в Интернете нужно осуществить поддержку нескольких серверов, а Apache создал для вас только один. Конечно, можно структуру этих нескольких серверов хранить на одном сервере, однако проще и удобнее было бы создать несколько виртуальных хостов с помощью Apache, например, один с именем serv1 и адресом 195.161.69.170, а другой - с именем serv2 и адресом 195.161.69.171. (Конечно, вместо "serv1" и "serv2" нужно будет указать желаемые имена виртуальных хостов.)
Как это принято в Unix, каждый сервер будет представлен своим каталогом в директории f:/home с именем, совпадающим с именем сервера. Например, сервер serv1 будет храниться в директории f:/home/serv1, которую необходимо создать прямо сейчас. В этой директории будут находиться:
файл access.log с журналом доступа к виртуальному серверу.
файл errors.log с журналом ошибок сервера.
директория www, где будут храниться html-документы.
директория cgi для хранения CGI-программ.
Последние две директории (www и cgi) тоже необходимо создать прямо сейчас.
Далее, для установки виртуального хоста необходимо сделать некоторые изменения в файле конфигурации Apache httpd.conf (см. выше), а также в некоторых файлах Windows. Вот необходимые действия:
Откройте директорию f:\usr\local\apache\conf. Откройте находящийся там файл httpd.conf. Перейдите в его конец, Вам предстоит добавить туда несколько строк.
Пропишите следующие строки в конце файла после всех комментариев:
#----serv1
<VirtualHost 195.161.69.170>
ServerAdmin webmaster@serv1.ru
ServerName serv1
DocumentRoot "f:/home/serv1/www"
ScriptAlias /cgi/ "f:/home/serv1/www/cgi/"
ErrorLog f:/home/serv1/log/error.log
CustomLog f:/home/serv1/log/access.log common
</VirtualHost>
При желании можно добавить и другие параметры (например, DirectoryIndex и т.д.) Вообще, не переопределенные параметры наследуются виртуальным хостом от главного.
Теперь надо немного подправить системный файл hosts, который находится в C:\WINDOWS\hosts (такого файла может не быть по умолчанию - в этом случае его надо создать). hosts - обычный текстовый файл, и в нем обычно заранее прописана только одна строка:
195.161.69.169 www.real.ulan-ude.ru
именно эта строка и задает соответствие имени localhost адресу 127.0.0.1. (Ради справедливости следует сказать, что имя localhost работает и без указанной выше строки. Ну и выдумщики же эти парни из фирмы Microsoft!) Для нашего виртуального хоста надо добавить соответствующую строчку, чтобы файл выглядел так:
195.161.69.170 www.real.ulan-ude.ru
195.161.69.171 www.real2.ulan-ude.ru
Этим Вы создадите виртуальных хост со следующими свойствами:
Имя - serv1
Доступен по адресу http://serv1 (или http://195.161.69.171).
Расположен, соответственно, в директории f:/home/serv1.
Директория для хранения документов - f:/home/serv1/www, доступная по адресу http://serv1.
Директория для CGI - f:/home/serv1/www/cgi, доступная по адресу http://serv1/cgi/
Файлы журналов хранятся в f:/home/serv1/log
Ну вот, мы создали один виртуальный хост! Если будет необходимо сделать второй, нужно просто проделать аналогичные действия, заменив параметры, связанные с расположением хоста на диске. Главное, не забудьте в этом случае указать другой IP-адрес (лучше всего указывать их последовательно, начиная с 195.161.69.170, затем 195.161.69.171 и т.д. - в этом случае все работает корректно). Желательно также для этих целей не указывать IP-адрес http://195.161.69.169, так как это - адрес главного сервера.
Кстати, необходимо заметить, что главный хост (невиртуальный, тот, который мы создали в разделах 1 и 2) по-прежнему доступен по адресу http://195.161.69.169 или http://www.real.ulan-ude.ru. Более того, его директория cgi-bin "видна" всем созданным виртуальным хостам, так что Вы можете ее использовать.
Это совсем просто, за исключением, может быть, выбора директории для Perl. А именно, Вы ДОЛЖНЫ разместить Perl. Замечу, что это очень важно, так как Perl требует, чтобы в каждом скрипте первой строкой стоял путь к Perl-интерпретатору; например, эта строка может выглядеть так:
#!/usr/local/bin/perl
Эту же строку можно было бы написать и так:
#!/usr/local/bin/perl.exe
или даже так:
#!f:\usr\local\bin\perl.exe
Это заставляет искать Perl-интерпретатор в директории f:/usr/local/bin/ (если диск f: не указан, это означает, что он совпадает с диском, на котором расположен Apache). Ясно, что если установить Perl не в такую же директорию, Вам придется каждый раз менять эту самую первую строку во всех скриптах при закачке их на сервер. Итак, далее буду считать, что эта директория такова, как на большинстве Apache-серверов:
f:/usr/local/bin
ВНИМАНИЕ: очень распространенной ошибкой является установка Perl не в ту директорию или не на тот диск. Еще раз обращаю внимание на то, где должен быть расположен транслятор.
Если все же по какой-то необъяснимой причине не придерживаетесь моего совета, то проверьте первую строку в скрипте. Она должна указывать не на директорию с Perl, а на исполнимый файл perl.exe. Напоминаю, что #!/usr/local/bin/perl заставляет искать Perl-интерпретатор perl.exe в директории f:/usr/local/bin/, а не в f:/usr/local/bin/perl
Если все же установлен путь неправильно, Apache выдаст непонятное сообщение об ошибке, а в errors.log появится сообщение: couldn't spawn child process.
Вот шаги, приводящие к цели:
Первым делом создайте директорию
f:/usr/local/bin
Затем скачайте дистрибутив Perl - файл с именем perl_setup.exe (436.137 байт), желательно в только что созданную директорию. Это саморазворачивающийся архив, Вам нужно будет просто его запустить, чтобы разархивировать в текущую директорию.
Теперь настроим сервер. Найдите в файле конфигурации Apache conf/httpd.conf строчку
AddHandler cgi-script .bat .exe
Замените ее на
AddHandler cgi-script .bat .exe .pl .cgi
Как это ни странно, но эту директиву AddHandler иногда указывать не обязательно. Однако лучше перестраховаться...
Вот, собственно, и все. Можете пользоваться Perl-транслятором. Для проверки его работоспособности используйте такой скрипт (помещенный, разумеется, в директорию cgi-bin или аналогичную):
#!/usr/local/bin/perl
print "Content-type: text/html\n\n";
print "It works!<br>\n";
system("dir");
Устанвка
Установка Jserv также проста как и установкм самого веб-сервера Apache. Для это нужно естественно имет файл установки ApacheJServ-1.1.2-2.exe (14).
Запустив файл установки нужно указать дирикторию куда будет установлены все нужные файлы для работы Jserv`а. После чего программа установки попрости указать путь до виртуальной машины Java, она должна быть уже установлена.
Виртуальная машина Java можно скачать с веб сайта фирмы Microsoft - SDKJava40.exe. Поле того как программе установки будет указан правельный путь до JVM, он попросит указать путь до Java Servlet Devolopment Kit 2 (JSDK), после чего будет запрошен путь до конфигурационного файла httpd.conf веб-сервера. Вот собственно и вся установка.
Настройка
А теперь нужно рассказать про настройку Jserv`а что бы он мог работать вместе с веб-сервером. Для того что бы Jserv запускался вместе с веб-сервером нужно все что находится в файле jserv.conf перенести в файл настройка веб-сервера Apache httpd.conf, желательно в конец.
Разберем синтаксис. Первый параметр это LoadModule.
Его синтаксис очень прост LoadModule [имя модуля в нашем случае это - jserv_module] [путь до модуля "./ApacheModuleJServ.dll"]. В конечном итоге эта строчка должна выглядить так: LoadModule jserv_module "./ApacheModuleJServ.dll"
Следующая интересующий нас параметр это - ApJServManual он говорит веб-серверу о том как запускать Jserv on=вручную off=автозапуск.
Далее идет параметр ApJServProperties "./conf/jserv.properties" это путь до файла настроек Jservs.
2.4. Использование языка Perl
Perl - интерпретируемый язык, приспособленный для обработки произвольных текстовых файлов, извлечения из них необходимой информации и выдачи сообщений. Perl также удобен для написания различных системных программ. Этот язык прост в использовании, эффективен, но про него трудно сказать, что он элегантен и компактен. Perl сочитает в себе лучшие черты C, shell, sed и awk, поэтому для тех, кто знаком с ними, изучение Perl-а не представит особого труда. Cинтаксис выражений Perl-а близок к синтаксису C. В отличие от большинства утилит ОС UNIX Perl не ставит ограничений на объем обрабатываемых данных и если хватает ресурсов, то весь файл обрабатывается как одна строка. Рекурсия может быть произвольной глубины. Хотя Perl приспособлен для обработки текстовых файлов, он может обрабатывать так же двоичные данные и создавать .dbm файлы, подобные ассоциативным массивам. Perl позволяет использовать регулярные выражения, создавать объекты, вставлять в программу на С или C++ куски кода на Perl-е, а также позволяет осуществлять доступ к базам данных, в том числе Oracle.
Этот язык часто используется для написания CGI-модулей, которые, в свою очередь, могут обращаться к базам данных. Таким образом может осуществляться доступ к базам данных через WWW.(5,6)
2.5 Использование языка Java
Развитие Internet и World Wide Web заставляет совершенно по-новому рассматривать процессы разработки и распределения программного обеспечения. Для того, чтобы выжить в мире электронного бизнеса и распространения данных, язык Java должен быть
- безопасным,
- высокопроизводительным,
- надежным.
Работа на различных платформах гетерогенных сетей отбрасывает традиционную схему распределения ПО, версий ПО, модификации ПО, объединения ПО и т.д. Для решения проблем гетерогенных сред язык должен быть
- нейтральным к архитектуре,
- переносимым,
- динамически подстраиваемым.
Разработчики Java с самого начала хорошо понимали, что язык, предназначенный для решения проблем гетерогенных сред, также должен быть
- простым - его должны с легкостью использовать все разработчики
- ясным - разработчики должны без больших усилий выучить Java
- объектно-ориентированным - он использует все преимущества современных методологий разработки ПО и подходит для написания распределенных клиент-серверных приложений
- многопоточным - для обеспечения высокой производительности приложений, выполняющих одновременно много действий (например, в мультимедийных системах)
- интерпретируемым - для переносимости и большей динамичности
Необходимо более подробно рассмотреть перечисленные характеристики Java.
Простота
Простота языка входит в ключевые характеристики Java: разработчик не должен длительное время изучать язык, прежде чем он сможет на нем программировать. Фундаментальные концепции языка Java быстро схватываются и программисты с самого начала могут вести продуктивную работу. Разработчиками Java было принято во внимание, что многие программисты хорошо знакомы с языком С++, поэтому Java, насколько это возможно, приближен к С++.
В Java не включены некоторые редко используемые, плохо понимаемые и усложняющие работу возможности С++, которые приносят больше проблем, чем преимуществ. Пришлось отказаться от
- перегрузки операторов (но перегрузка методов в Java осталась),
- множественного наследования,
- автоматического расширяющего приведения типов.
Добавилась автоматическая сборка мусора, упрощающая процесс программирования, но несколько усложняющая систему в целом. В С и С++ управление памятью вызывало всегда массу проблем, теперь же об этом не придется много заботиться.
Объектно-ориентированность
Язык Java с самого начала проектировался как объектно-ориентированный. Задачам распределенных систем клиент-сервер отвечает объектно-ориентированная парадигма: использование концепций инкапсуляции, наследования и полиморфизма. Java предоставляет ясную и действенную объектно-ориентированную платформу разработки.
Программисты на Java могут использовать стандартные библиотеки объектов, обеспечивающие работу с устройствами ввода/вывода, сетевые функции, методы создания графических пользовательских интерфейсов. Функциональность объектов этих библиотек может быть расширена.
Надежность
Платформа Java разработана для создания высоконадежного прикладного программного обеспечения. Большое внимание уделено проверке программ на этапе компиляции, за которой следует второй уровень - динамическая проверка (на этапе выполнения).
Модель управления памятью предельно проста: объекты создаются с помощью оператора new. В Java, в отличие от С++, механизм указателей исключает возможность прямой записи в память и порчи данных: при работе с указателями операции строго типизированы, отсутствуют арифметические операции над указателями. Работа с массивами находится под контролем управляющей системы. Существует автоматическая сборка мусора.
Данная модель управления памятью исключает целый класс ошибок, так часто возникающих у программистов на С и С++. Программы на Java можно писать, будучи уверенным в том, что машина не "повиснет" из-за ошибок при работе с динамически выделенной памятью.
Безопасность
Java разработана для оперирования в распределенных средах, это означает, что на первом плане должны стоять вопросы безопасности. Средства безопасности, встроенные в язык, и система исполнения Java позволяют создавать приложения, на которые невозможно "напасть" извне. В сетевых средах приложения, написанные на Java, защищены от вторжения неавторизованного кода, пытающегося внедрить вирус или разрушить файловую систему.
Независимость от архитектуры
Java разработан для поддержки приложений, внедряемых в гетерогенные сетевые среды. В подобных средах приложения должны исполняться на различных аппаратных архитектурах, под управлением различных операционных систем и во взаимодействии с интерфейсами различных языков программирования. Для обеспечения платформо-независимости программ компилятор Java генерирует байт-код - архитектурно-нейтральный промежуточный формат программы, создаваемый для эффективной передачи кода на различные аппаратные и программные платформы. При выполнении программы байт-код интерпретируется исполняющей машиной Java. Один и тот же Java-байткод будет исполняться на любой платформе.
Переносимость
Архитектурная независимость - лишь составная часть переносимости. В отличие от С или С++ в Java не существует понятия "зависимости от реализации", когда речь идет о размерности базовых типов. Форматы типов данных и операции над ними четко определены. Тем самым, программы остаются неизменными на любой платформе - не существует несовместимости типов данных на аппаратных и программных архитектурах.
Архитектурная независимость и переносимость программного обеспечения Java обеспечивается виртуальной машиной Java (Java Virtual Mashine - JVM) - абстрактной машиной, для которой компилятор Java генерирует код. Специальные реализации JVM для конкретных аппаратных и программных платформ предоставляют уже конкретную виртуальную машину. JVM базируется на стандарте интерфейса переносимых операционных систем (POSIX).
Высокая производительность
Производительность всегда заслуживает особого внимания. Java достигает высокой производительности благодаря специально оптимизированному байт-коду, легко переводимому в машинный код. Автоматическая сборка мусора выполняется как фоновый поток с низким приоритетом, обеспечивая высокую вероятность доступности требуемой памяти, что ведет к увеличению производительности. Приложения, требующие больших вычислительных ресурсов, могут быть спроектированы так, чтобы те части, которые требуют интенсивных вычислений, были написаны на языке ассемблера и взаимодействовали с Java платформой. В основном, пользователи ощущают, что приложения взаимодействуют быстро, несмотря на то, что они являются интерпретируемыми.
Интерпретируемость
Java-интерпретатор может выполнять Java байт-код на любой машине, на которой установлен интерпретатор и система выполнения. На интерпретирующей платформе фаза сборки программы является простой и пошаговой, поэтому процесс разработки существенно ускоряется и упрощается, отсутствуют традиционные трудные этапы компиляции, сборки, тестирования.
Многопоточность
Большинству современных сетевых приложений обычно необходимо осуществлять несколько действий одновременно. В Java реализован механизм поддержки легковесных процессов-потоков (нитей). Многопоточность Java предоставляет средства создания приложений с множеством одновременно активных потоков.
Для эффективной работы с потоками в Java реализован механизм семафоров и средств синхронизации потоков: библиотека языка предоставляет класс Thread, а система выполнения предоставляет средства диспетчеризации и средства, реализующие семафоры. Важно, что работа параллельных потоков с высокоуровневыми системными библиотеками Java не вызовет конфликтов: функции, предоставляемые библиотеками, доступны любым выполняющимся потокам.
Динамичность
По ряду соображений Java более динамичный язык, чем С++. Он был разработан специально для подстройки под изменяющееся окружение. В то время как компилятор Java на этапе компиляции и статических проверок не допускает никаких отклонений, процесс сборки и выполнения сугубо динамический. Классы связываются только тогда, когда в этом есть необходимость. Новые программные модули могут подключаться из любых источников, в том числе, поставляться по сети. В случае с браузером HotJava и другими подобными приложениями интерактивный выполняемый код может быть загружен откуда угодно, что позволяет производить прозрачные модификации приложений. В результате возможно создание интерактивных служб, безболезненно модифицируемых, обслуживающих большое количество клиентов и обеспечивающих развитие электронного бизнеса через Internet.
Вывод
Если описанные выше характеристики рассматривать по отдельности, то их можно найти во многих программных платформах. Радикальное новшество заключается в способе, предлагаемом Java и системой выполнения, который сочетает в себе все характеристики для предоставления гибкой и мощной системы программирования.
Разработка приложений на Java приводит к получению программного обеспечения, которое:
- переносимо на разные архитектуры, операционные системы и графические пользовательские интерфейсы
- безопасно
- высокопроизводительно
Благодаря Java работа по разработке программного обеспечения значительно упрощается, все старания направлены на достижение конечной цели: вовремя получить передовой продукт, опирающийся на солидную основу Java. За более полной информацией об языке можно обратится на сайт разработчиков (9,10) .
Платформа Java с ее принципом "Write Once, Run AnywhereТМ
" ("Пишем один раз - используем везде") представляет собой безопасное гибкое многоплатформное решение для разработки мощных Java-приложений, работающих в Интернет и внутрикорпоративных интрасетях. Открытые расширяемые интерфейсы прикладного программирования (Java Platform API) позволяют разработчикам создавать приложения и апплеты Java. Набор интерфейсов для предприятия Java Enterprise API позволяет поддерживать единообразное, стандартное, беспрепятственное сопряжение и взаимодействие с информационными массивами предприятия.
Сопряжение Java с базами данных (Java Database Connectivity - JDBCТМ
) представляет собой платформно-независимый промышленный стандарт совместимости Java с самыми разными базами данных. JDBC поддерживает интерфейс API на уровне вызовов для доступа к базам данных, работающим с языком SQL. JDBC позволяет разработчикам Java использовать принцип "Пишем один раз - используем везде" в приложениях, требующих доступа к корпоративным данным (7).
2.6. Реализация доступа к базе данных
Поисковая программа (SearchEngein.class
) написана на языке Java с использованием технологии Java servlets (17) на базе веб сервера Apache (16). Чтобы программа работала в системе, под управлением операционной системой Windows NT должны присутствовать следующие компанеты приведенные в списке:
1. Веб сервер Apache, по архитектуру Win32;
2. Apache Java server, так же под архитектуру Win32;
3. Виртуальная Java машина (JVM) также под архитектуру Win32;
4. Java Servlet Development Kit (JSDK) 2.0
Настройка и установка этих команентов была описана выше. Тонкости настройки для правильной работы программы буду описаны ниже.
Ограничении по применению программы практически не существует кроме аппаратного обеспечения, минимальная конфигурация системы должна быть такой:
Процессор с тактовой чистатой 266 или выше.
Память не меньше 64 мегабайт, чем больше, тем лучше.
Жесткий диск любой.
Остальное оборудование по усмотрению администратора сервера.
Выше было сказано, что ограничений нет, уточняю почему, так как программа откомпилирована в аппаратно-независимый код (байт-код) оно с легкостью может быть перенесена на другую платформу MacOS или Unix-система. Нужно будет всего лишь переписать файлы классы на диск, естественно настроив систему соответствующим образом.
Алгоритм основан на методе перебора каждой записи всего массива и сравнении введенной строки запроса с полями записи прочитанной из массива. После того как запись и запрос совпали запить выдается в нужном формате для отображения в браузере. Пока весь массив не будет прочитан последовательно, сессия с пользователем не будет закончена.
А теперь более детально остановимся на алгоритме, ниже приведен формат одной отдельно взятой записи из базы данных в формате RUSMARC (см. Приложение 1).
00878nam 22002537 45000010000000330050003300172450005002442600029400153000030900096500031800636500038
10045653004260024653004500019653004690016020004850010091004950008092005030017090005200008852005280022852005500011040005610014041005750008008005830041 BOOK00000876 BOOK00000001 ‑19981027165203.0 ‑00aАктуальные вопросы преподавания хореографического искусстваnВып. 7bМатериалы межвуз. науч.-метод. конф. "Современные технологии обучения в гуманитарном вузе"cСанкт-Петербургский гуманитарный ун-т профсоюзов; Редкол. А.С.Запесоцкий и др. ‑0 aСПб.c1994 ‑ a22с.‑ aВысшая школаxМетодика преподаванияxМатериалы конференции‑ aХореографическое искусствоxПреподавание‑ aТехнологии обучения‑ aФормы обучения‑ aКонференция‑ c2.100‑ aЩ32‑ a14.35.09a18‑ cЩ32‑ bч/зt2hЩ32iА437‑ bаб.t3‑ aВСГАКИ-10‑ arus‑950614s1990 rur 00000 rus d‑
А теперь этаже запись только уже с пояснениями:
00878nam 22002537 4500 – Маркер 24 символа
– словарь 12 символов 1) Метка поля – 3 символа полный список всех меток приведен в Приложении 1.
2) Начальная позиция относительна начала записи -5 символов
3) Размер поля – 4 символа
1 - 001 00000 0033
2 - 005 00033 0017
3 - 245 00050 0244
4 - 260 00294 0015
5 - 300 00309 0009
6 - 650 00318 0063
7 - 650 00381 0045
8 - 653 00426 0024
9 - 653 00450 0019
10- 653 00469 0016
11- 020 00485 0010
12- 091 00495 0008
13- 092 00503 0017
14- 090 00520 0008
15- 852 00528 0022
16- 852 00550 0011
17- 040 00561 0014
18- 041 00575 0008
19- 008 00583 0041
Поля с данными
1 - ‑ BOOK00000876 BOOK00000001
2 - ‑19981027165203.0
3 - ‑00aАктуальные вопросы преподавания хореографического искусстваnВып. 7bМатериалы межвуз. науч.-метод. конф. "Современные технологии обучения в гуманитарном вузе"cСанкт-Петербургский гуманитарный ун-т профсоюзов; Редкол. А.С.Запесоцкий и др.
4 - ‑0 aСПб.c1994
5 - ‑ a22с.
6 - ‑ aВысшая школаxМетодика преподаванияxМатериалы конференции
7 - ‑ aХореографическое искусствоxПреподавание
8 - ‑ aТехнологии обучения
9 - ‑ aФормы обучения
10- ‑ aКонференция
11- ‑ c2.100
12- ‑ aЩ32
13- ‑ a14.35.09a18
14- ‑ cЩ32
15- ‑ bч/зt2hЩ32iА437
16- ‑ bаб.t3
17- ‑ aВСГАКИ-10
18- ‑ arus
19- ‑950614s1990 rur 00000 rus d
‑
Программа начинает работать после того когда от клиента приходит запрос на страницу по определенному URL (например: http://www.real.ulan-.ude.ru/serv/SearchEngein), для выполнения запроса пользователя веб-сервер запускает JServ, который в свою очередь обрабатывает запрос и определяет какой именно сервлет требуется запустить и в какой зоне он находится. Информацию о зонах размещения всех сервлетов Jserv считывает из файла настройки. Чтобы сервлет начал выполняться JServ предварительно запускает виртуальную Java машину и только после этого начинает работать сервлет это значит что запрос пользователя будет обработан и пользователь получит запрошенную страничку. Что же происходит на стороне сервера в этот момент когда пользователь ждет пока загрузится страница. А происходит вот что, управление по отображению всей информации в окне браучера переходит сервлету, программе написанной на Java. Рассмотрим это более детально. Сервлет инициализируется и начинает передачу данных в формате HTML пользователю. Первое что увидит пользователь это будет поисковая форма (см. рис. 6) .
Рис. 6
Поисковая форма
Программный код поисковой формы выглядит так:
out.println("<form method=\"get\" action=\"/serv/SearchEngein\">"+
"<table width=\"461\" border=\"0\" cellpadding=\"0\" cellspacing=\"0\">"+
"<tr bgcolor=\"#3399FF\"> "+
"<td width=\"266\" class=\"text\"> Запрос</td>"+
"<td width=\"135\" class=\"text\"> Каталог</td> "+
"<td width=\"207\"> </td>"+
"</tr>"+
"<tr>"+
"<td width=\"266\" valign=\"top\"> "+
"<input type=\"text\" name=\"Query\" maxlength=\"100\" size=\"38\" value=\"\">"+
"</td>"+
"<td width=\"135\" valign=\"top\"> "+
"<select name=\"select\" size=\"1\">"+
"<option value=\"MARCFILE.Book\" selected>"+ConvertISO(getINIVar("KATALOG.Book"))+"</option>"+
"<option value=\"MARCFILE.Stat\">"+ConvertISO(getINIVar("KATALOG.Stat"))+"</option>"+
"<option value=\"MARCFILE.Periud\">"+ConvertISO(getINIVar("KATALOG.Periud"))+"</option>"+
"<option value=\"MARCFILE.Podpis\">"+ConvertISO(getINIVar("KATALOG.Podpis"))+"</option>"+
"<option value=\"MARCFILE.Ucheb\">"+ConvertISO(getINIVar("KATALOG.Ucheb"))+"</option>"+
"</select>"+
"</td>"+
"<td width=\"207\" valign=\"top\"> "+
"<input type=\"submit\" name=\"Start\" value=\"Поиск\">"+
"</td>"+
"</tr>"+
"</table>"+
"</form>");
Рассмотрим код более пристально.
В тэге <form> присутствуют параметры metod и action.
1) метод (metod) говорит браузеру о том что данные(запрос) будет отправлены серверу;
2) действие (action) – в этом параметре находится путь к программе на старое сервера которая примет отправленный запрос для обработки.
Следующий интересующий нас неотъемлемый компонент это тэг <input>, который тоже имеет несколько параметров type, name, value. Этот тэг является строкой ввода, рассмотрим его параметры.
1) тип (type) равный “text” говорит о том что это строка ввода;
2) имя (name) название запроса т.е. имя которое присваивается тексту введенному в строку ввода, в моей программе это Query;
3) значение (value) значение строки по умолчанию при начальной загрузке.
Еще один значимый тэг формы <select> - это список для выбора базы в которой будет производится поиск. Данный тэг имеет свое имя которое указано в параметре name. Сам же список последовательно указан в тэге <option> относящимся к тэгу <select>. Каждая из строк начинающихся тэгом <option> является элементом списка для выбора. У тэга <option> есть параметр value в котором указан псевдоним выбранного пункта из списка – это нужно для определения какой пункт из списка выбран.
И наконец последний значимый тэг <input>, в отличии от первого тэга <input> у этого тэга параметр тип(type) равен “submit” - это значит что это кнопка отправки запроса обработчику который указан в тэге <form>. У кнопки тоже есть имя (name) и значение (value) кнопка называется Start. Последним тэгом, всегда является закрывающий тэг </form>.
После того как пользователь ввел запрос и нажал на кнопку “Поиск” в адресная строка браузера приобретет примерно вид :
http://localhost/serv/SearchEngein?Query=%E1%A8%E1%E2%A5%AC%A0&select=MARCFILE.Stat&Start=%8F%AE%A8%E1%AA
К ссылке на сервлет прибавилось три параметра отделенные от адреса сервлета вопросительным знаком первый параметр это Query (запрос), второй select говорящий сервлету в какой базе производить поиск.
Первое что делает программа - это считывает файл настройки db.ini – который находится в папке c:\www\db. В данном файле находятся данные о место нахождении интересующей базы данных или говоря проще локальный путь к базе данных. Определив интересующую базу данных и установив ее место нахождения, программа начинает процесс поиска всех удовлетворяющих запросу данных (библиографических описаний).
Программа считывает всю запись в массив, после чего начинается определение места нахождения полей и их длинны. Разберем код процедуры.
public void dbFileRead(String dbNamePath, PrintStream out, String query) {
Сперва производится инициализация всех переменных используемых при работе процедуры.
Первый блок. Переменные для занесения значений полей
String mAvtor = null; // 100
String msAvtor = null; // 700
String mName = null; // 245
String mPrinter = null; // 260
String mSize = null; // 300
String mKey = null; // 653
String mSeria = null; // 490
String mRubrika = null; // 650
String mBBK = null; // 91
String mKaIndex = null; // 90
Второй блок. Файловые переменные для перемещения по файлу
long fPosMarker = 0, // Позиция относительно начала
fPosData = 0; // Начальная позиция данных
boolean done = false;
Третий блок. Перемнный для работы с данными
int mC =0, // Счетчик прочитанных записей
mE =0; // Счетчик найденых соответствий
byte Jumper[] = new byte[5]; // Размер запяси - символьный
int JIndex = 0, // Размер запяси - числовой
JTemp = 0, // Размер данных + словарь
MIndex = 0, // Счетчик для массива
MTemp = 0; // Счетчик полей
Начало выполнени поика. Сперва проверяется имеет ли запрос query занчение неравное пусто, если условие выполняется и запрос имеет не нуливое занчение устанавливается связь с файлом данных. Начальная позиция чтения равна нулю.
if (query != null){
try { RandomAccessFile dbfile = new RandomAccessFile(dbNamePath,"r");
// Цикл чтения файла по маркерам
while (fPosMarker != dbfile.length()) {
try { mC++;
dbfile.seek(fPosMarker);
dbfile.read(Jumper);
String jBuf = new String(Jumper);
JIndex = Integer.parseInt(jBuf,10);
int b = 0;
Прочитав начальный блок из 5 символов говорящий о длине записи он преобразуется из символьного значенья в числовое. Затем определяется длинная словаря которая равна 12*n, где n – равно количеству заполненных полей в одной записи.
// Поиск конца словаря
while ( b != MD){
dbfile.seek(fPosMarker+24+MIndex);
b = dbfile.read();
MTemp++;
MIndex = MTemp;
}
MTemp= MTemp - 1;
Определив конечную позицию словаря производится считывание в массив блока состоящего из данных - метка поля; начальная позиция поля, относительно конца словаря; длинная поля и символах.
// чтение Словаря из файла в отдельный массив
byte Dic[] = new byte[MTemp];
dbfile.seek(fPosMarker+24);
dbfile.read(Dic);
// чтение полей данных из файла в массив
fPosData = fPosMarker+24+MTemp;
String sDic = new String(Dic);
int DI2 = 0,
DI3 = 0,
DI4 = 0,
DI5 = 0,
PNum = 0, // Номер поля числовой
PLength = 0, // Длинна поля числовая
PStart = 0; // Начальная позиция поля чиловая
Получив данные в результате преобразований, это строка, начинается последовательное вычитание метки поля, начальной позиции, размера поля.
// сканирование номеров полей
while ( DI2 != MTemp){
DI3=DI2+3;
String DStr = sDic.substring(DI2,DI3);// Номер поля
DI4=DI3+5;
String DStr2 = sDic.substring(DI3,DI4);// Начальная позиция
DI5=DI4+4;
String DStr3 = sDic.substring(DI4,DI5);// Длинна поля
DI2=DI2+12;
PLength = Integer.parseInt(DStr3,10);// Узнаем длинну поля
PStart = Integer.parseInt(DStr2,10);// Узнаем начало поля
PNum = Integer.parseInt(DStr,10);// Код
byte Pole[] = new byte[PLength];
Как только первая запись о первом поле разобрана на составляющие проверяется его метка , которая говорить относится или нет, поле к тому списку полей который нас интересует. Если да то производится считывание его из файла. После того как поле считано над значением поля производится ряд преобразований, таких как, вычитание из поля служебной информации относящейся к формату MARC.
// Чтение поля из файла
switch (PNum) {
case 100 : {
dbfile.seek(fPosData+PStart);
dbfile.read(Pole);
String Pol = new String(Pole);
if (Pol == null) Pol=" ";
mAvtor = TagRemove(Pol.substring(5));break;}
case 700 : {
dbfile.seek(fPosData+PStart);
dbfile.read(Pole);
String Pol = new String(Pole);
if (Pol == null) Pol=" ";
msAvtor = TagRemove(Pol.substring(5));break;}
case 245 : {
dbfile.seek(fPosData+PStart);
dbfile.read(Pole);
String Pol = new String(Pole);
if (Pol == null) Pol=" ";
mName = TagRemove(Pol.substring(5));break;}
case 490 : {
dbfile.seek(fPosData+PStart);
dbfile.read(Pole);
String Pol = new String(Pole);
if (Pol == null) Pol=" ";
mSeria = TagRemove(Pol.substring(5));break;}
case 91 : {
dbfile.seek(fPosData+PStart);
dbfile.read(Pole);
String Pol = new String(Pole);
if (Pol == null) Pol=" ";
mBBK = TagRemove(Pol.substring(5));break;}
case 90 : {
dbfile.seek(fPosData+PStart);
dbfile.read(Pole);
String Pol = new String(Pole);
if (Pol == null) Pol=" ";
mKaIndex = TagRemove(Pol.substring(5));break;}
case 260 : {
dbfile.seek(fPosData+PStart);
dbfile.read(Pole);
String Pol = new String(Pole);
if (Pol == null) Pol=" ";
mPrinter = TagRemove(Pol.substring(5));break;}
case 300 : {
dbfile.seek(fPosData+PStart);
dbfile.read(Pole);
String Pol = new String(Pole);
if (Pol == null) Pol=" ";
mSize = TagRemove(Pol.substring(5));break;}
case 653 : {
dbfile.seek(fPosData+PStart);
dbfile.read(Pole);
String Pol = new String(Pole);
if (Pol == null) Pol=" ";
mKey = TagRemove(Pol.substring(5));break;}
default : {}
}// switch
}// конец проверки полей
Получив все данные которые нас интересовали, создается запись состоящая из нескольких полей.
if ( mAvtor == null) mAvtor=" ";
if ( msAvtor == null) msAvtor=" ";
if ( mName == null) mName=" ";
if ( mPrinter == null) mPrinter=" ";
if ( mSize == null) mSize=" ";
if ( mKey == null) mKey=" ";
if ( mKaIndex == null) mKaIndex=" ";
if ( mBBK == null) mBBK=" ";
if ( mSeria == null) mSeria=" ";
Это собственно самая запись
MarcRecord Rec = new MarcRecord( mAvtor,
msAvtor,
mName,
mPrinter,
mSize,
mKey,
mSeria,
mBBK,
mKaIndex);
Данные которые занесены в запись теперь осуществляется сравнивание их с запросом. Сравнение осуществляется после преобразование к одному регистру, это нужно для того чтобы найти полный список всех имеющихся записей относящихся к веденному запросу.
String q = toLow(query);
String p01 = toLow(Rec.rAvtor);
String p02 = toLow(Rec.rsAvtor);
String p03 = toLow(Rec.rName);
String p04 = toLow(Rec.rKey);
Затем распознанные данные сравниваются с запросом, сравнивание производится только с несколькими полями. Список полей приведен ниже:
100 – Автор
700 – Второй автор
245 – Название произведения
653 – Ключевые слова
if ( p01.indexOf(q) != -1 ||
p02.indexOf(q) != -1 ||
p03.indexOf(q) != -1 ||
p04.indexOf(q) != -1)
{ mE++;
При совпадении запись сразу же отправляется браузеру для отображения в читабельной для пользователя форме.
out.println("<table width=\"461\" border=\"0\" cellpadding=\"0\" cellspacing=\"0\">"+
"<tr bgcolor=\"#3399FF\">"+
"<td colspan=\"3\" class=\"text\"> Автор: "+
"<font color=\"#000000\">"+
Rec.rAvtor+" "+
Rec.rsAvtor+
"</font></td></tr><tr>"+
"<td colspan=\"3\" valign=\"top\" class=\"bodytext\">"+mE+". "+mC+
" <b>Название:</b> "+
Rec.rName+"<br>"+
Rec.rPrinter+" "+
Rec.rSize+"<br>"+
Rec.rBBK+" "+
Rec.rKaIndex+" "+
Rec.rSeria+
"</td></tr></table>");
}
В конце обработки одной записи независимо соответствовала она запросу или нет производится переход к следующей записи.
fPosMarker = fPosMarker+JIndex;
MTemp = 0;
MIndex = 0;
}
В случае ошибки (исключительной ситуации) цыкал обработки записи, прерывается и выдается сообщение об ошибки.
catch (IOException e) {
out.println("Ошибка!!!"+"<br>");
done=true; }
}
}
Если же файл отсутствует то программа выдаст сообщение о том что файл базы данных отсутствует на сервере.
catch (IOException e) { out.println("Ошибка доступа к "+dbNamePath); }
}
if (mE == 0) {
out.println("Запос: "+query+" не найден");
} // end If
}
После того как проведено сравнение запроса и данных имеющихся в поле, при совпадении запись преобразуются в формат HTML. Преобразуются только несколько полей, список полей которые выдаются по запросу в случае совпадений приведен ниже:
100 – Автор
700 – Второй автор
245 – Название произведения
490 – Серия
91 – Индекс ББК
90 – Каталожный индекс
260 - Издательство
300 – Объем, размер
653 – Ключевые слова
Код вывода в HTML формате выглядит так:
out.println("<table width=\"461\" border=\"0\" cellpadding=\"0\" cellspacing=\"0\">"+
"<tr bgcolor=\"#3399FF\">"+
"<td colspan=\"3\" class=\"text\"> Автор: "+
"<font color=\"#000000\">"+
Rec.rAvtor+" "+
Rec.rsAvtor+
"</font></td></tr><tr>"+
"<td colspan=\"3\" valign=\"top\" class=\"bodytext\">"+mE+". "+mC+
" <b>Название:</b> "+
Rec.rName+"<br>"+
Rec.rPrinter+" "+
Rec.rSize+"<br>"+
Rec.rBBK+" "+
Rec.rKaIndex+" "+
Rec.rSeria+
"</td></tr></table>");
После чего программа производит считывание и обработку следующей записи. Более детально алгоритм расписан в листинге программы (см. прил.3), а результаты теста программы (см. прил. 4)
Заключение
Глобальная информатизация общества приводит к тому, что потребность в информации, растет с каждым новым пользователем сети. При этом задачей специалистов в области информационных технологий обеспечить пользователей полной и достоверной информацией путем простого и удобного для пользователей доступа к накопленным массивам данных.
Главной задачей данной дипломной работы было создание программного интерфейса к существующей библиографической базе данных. Применение передовых технологии программирования позволили разработать программу, позволяющую производить поиск интересующей информации в базе данных не только по отдельно взятым ключевым словам, но и полному названию документа. Тестирование программы на массиве из 8366 записей показало, что поиск документа в конце массива занимает 2 минуты 16 секунд. Естественно, что при увеличении количества записей время обработки также будет увеличиваться. Массив данных, на котором проводилось тестирование, является реальной базой данных библиотеки ВСГАКиИ. Для того чтобы программа могла работать стабильно и с минимальными затратами времени на обработку запроса, нужно использовать ее на машине, обладающей большим быстродействием. Тестирование производилось на компьютере с такой конфигурацией: AMD K6-233, ОЗУ 64 Mb, Жесткий диск 2 Gb, под управлением операционной системы Windows NT 4.0 с установленным SP6a. Развитие направления связанного с поиском информации в массивах данных библиотек очень эффективно, так как потребность в этой информации через сеть Интернет возрастает с каждым новым пользователем.
Практическая реализация поставленной задачи показала правильность выбранного подхода. Тем не менее, работа требует дальнейше доработаки для организации постоянного доступа читателей к библиографическим ресурсам библиотекам города через Интернет.
Литератур
а
1. Глушаков С.В., Ломотьков Д.В. Базы данных: Учебный курс. – К.: Абрис, 2000. -504с.
2. Джейсон Мейнджер. Java: основы программирования :Пер. с англ. - К.: Издательская группа BHV,1997.-320с.
3. Пригорьев Ю.А. Проблемы выбора доступа к данным при проектировании информационных систем на основе СУБД//Информационные технологии. - 1999 - №5. С. 4-10.
4. Симкин Стив, Бартлет Нейл, Лесли Алекс. Программирование на Java. Путеводитель :Пер. с англ. – К. НИПФ «ДиаСофт Лтд», 1996. 736 с.
5. Кристиансен Т., Торкингтон Н. Perl: Библиотека программиста :Пер. с англ.- СПб.: Издательство «Питер», 2000. – 736с.: ил.
6. Холзнер Стивен. Perl: специальный справочник :Пер. с анг. – СПб.: Питер, 2000. – 496с.: ил.
7. Хейл, Бернард Ван. JDBC: Java и базы данных :Пер. с англ. М.,1999.-320с.
8. Эферган М. Java: справочник. – СПб.: Питер, 1998. -448с.: ил.
9. http://www.java.sun.com
10. http://www.sun.ru/java/start/intro/history.html
11. http://www.logos.com/marc/
12. http://www.rba.ru:8101/rusmarc/
13. http://httpd.apache.org/dist/httpd/binaries/win32/old/apache_1_3_14_win32_r2.exe
14. http://java.apache.org/jserv/dist/ApacheJServ-1.1.2-2.exe
15. http://www.netcraft.com/Survey
16. http://www.apache.org
17. http://java.apache.org
18. http://www.ruslibnet.ru/
Приложение 1
Спецификация формата RUSMARC
РОССИЙСКИЙ КОММУНИКАТИВНЫЙ ФОРМАТ
ОФИЦИАЛЬНАЯ ИНФОРМАЦИЯ
Российский коммуникативный формат официально включен Постоянным комитетом по формату UNIMARC в список национальных адаптаций формата UNIMARC(11). Международный код Российского коммуникативного формата: RUSMARC(12).
Российский коммуникативный формат разработан по заказу Министерства культуры в рамках программы LIBNET (18) под эгидой Российской Библиотечной ассоциации. Утвержден Приказом Министра Культуры РФ № 45 от 27.01.98 в качестве обязательного формата при обмене библиографическими записями среди библиотек сети Министерства Культуры.
Формат предназначен быть посредником при осуществлении обмена библиографическими записями и способствовать решению следующих задач:
а. Улучшению доступности библиографической информации
б. Созданию сводных каталогов
в. Сокращению затрат при каталогизации
А теперь перейдем к самому формату.
Определение
Область записи, содержащая данные о записи, необходимые системе для обработки записи. Маркер записи формируется в соответствии с положениями стандарта ISO 2709 и располагается в начале каждой записи.
Наличие
Является обязательным.
Не повторяется.
Метка, индикаторы и подполя
Маркер записи не имеет метки, индикаторов и идентификаторов подполей.
Элементы данных фиксированной длины
Маркер записи представляет собой набор элементов данных фиксированной длины. Элементы данных идентифицируются позицией внутри маркера. Маркер имеет длину в 24 символа. Позиции символов нумеруются от 0 до 23:
Маркер записи. Таблица 2.
| |
Наименование элемента данных
|
Кол-во символов
|
Позиции символов
|
| (1)
|
Длина записи
|
5
|
0-4
|
| (2)
|
Статус записи
|
1
|
5
|
| (3)
|
Коды применения
|
4
|
6-9
|
| (4)
|
Длина индикатора
|
1
|
10
|
| (5)
|
Длина идентификатора подполя
|
1
|
11
|
| (6)
|
Базовый адрес данных
|
5
|
12-16
|
| (7)
|
Дополнительное определение записи
|
3
|
17-19
|
| (8)
|
План справочника
|
4
|
20-23
|
(1) Длина записи (позиции символов 0-4)
Длина записи - количество символов в записи, включая маркер записи, справочник, поля переменной длины, разделитель записи. Выражается десятичным числом из пяти цифр, при необходимости выравниваемых вправо ведущими нулями (не 546, а 00546). Определяется автоматически, когда запись окончательно сформирована для обмена.
(2) Статус записи (позиция символа 5)
Используются следующие коды, обозначающие статус обработки записи:
n - новая запись
Запись, подготовленная для использования в библиографирующем учреждении-создателе записи или для обмена.
d - исключенная запись
Запись, участвующая в обмене для указания, что другая запись (авторитетная / нормативная, ссылочная или справочная запись), имеющая соответствующий контрольный номер, не действительна. Для авторитетной / нормативной записи это означает следующее: запись удалена из файла в связи с тем, что заголовок, записанный в поле блока 2--, решено в дальнейшем не использовать - вместо него решено использовать другой заголовок (заголовки), новый или уже существовавший в системе, для которого существовала или создается отдельная авторитетная / нормативная запись. Заголовок исключенной записи может включаться в поля блока 4-- в запись (записи) для заголовка (заголовков), которые решено использовать вместо исключенного.
Запись может содержать только маркер, справочник и поле 001 (контрольный номер записи) или может содержать все поля в записи. В любом случае поле 830 "Общее примечание каталогизатора" может использоваться для объяснения причины исключения записи.
с - откорректированная запись
Запись, участвующая в обмене для указания, что данная запись должна заместить другую, имеющую соответствующий контрольный номер. Запись вводит дополнительно и (или) заменяет, и (или) исключает некоторые элементы данных в ранее введенной записи. При этом имеются в виду любые исправления - любая редакция любого поля записи (соответственно меняется идентификатор версии в поле 005). Исправления могут быть связаны или не связаны с изменением уровня кодирования с частичной на полную запись.
(3) Коды применения (позиции символов 6-9):
Коды в позициях 6-9 определяются не стандартом ISO 2709, а особенностями конкрет-ного применения формата.
(а) Тип записи (позиция символа 6)
Используются следующие коды, обозначающие тип записи:
x = авторитетная / нормативная запись
y = ссылочная запись
z = справочная запись
(б) Не определено (позиции символов 7-9). Три пробела (###).
(4) Длина индикатора (позиция символа 10)
Одна десятичная цифра.
Содержит 2.
(5) Длина идентификатора подполя (позиция символа 11)
Одна десятичная цифра.
Содержит 2.
(6) Базовый адрес данных (позиции символов 12-16)
Пять десятичных цифр, выровненных вправо ведущими нулями (не 546, а 00546), указы-вающие начальную символьную позицию первого поля данных относительно начала за-писи. Это число включает общее количество символов в маркере и справочнике записи, включая разделитель поля в конце справочника. В справочнике начальная позиция сим-волов для каждого поля задается относительно первого символа первого поля данных, которое является полем 001, а не от начала записи. Генерируется системой.
(7) Дополнительное определение записи (позиции символов 17-19)
Три позиции символов, содержащие коды, которые дают дополнительные сведения, не-обходимые для обработки записи:
(а) Уровень кодирования (позиция символа 17)
Односимвольный код, указывающий степень полноты машиночитаемой записи.
# (пробел) = полная запись
Запись содержит все необходимые данные, включая ссылки, правила их формирования и примечания (если правила формирования ссылок и примечания необходимы). Запись подготовлена для использования в библиографирующем учреждении или для обмена. В записи заполнены все поля и подполя со статусом обязательный и условно-обязательный.
3 = частичная
Запись содержит не все данные, т.к. не выполнена необходимая справочная работа и по-сле ее выполнения, в случае необходимости, могут быть дополнены ссылки "см." и "см. также" и справочные примечания.
Примечание:
(1) Уровень кодирования не связан с кодом статуса заголовка (100/8). И полная, и частичная запись могут содержать в поле блока 2-- как нормативный заголовок (код статуса a - нормативный), так и заголовок предварительный (код статуса c - предварительный), т.е. заголовок, который не принят в качестве нор-мативного и может быть пересмотрен. Различие между полной и частичной за-писями связано с тем, насколько полно в записи представлена необходимая ин-формация, связанная с заголовком.
(2) После того, как уровень кодирования приобретает значение # (пробел - полная запись), даты всех последующих модификаций (изменений) записи фикси-руются в поле 801 со значением второго индикатора 2 (организация модифици-рующая).
(б) Не определено (позиции символов 18-19). Два пробела (##).
(8) План справочника (позиции символов 20-23).
(а) Длина компонента "Длина поля" каждой статьи справочника(позиция символа 20).
Одна десятичная цифра. Значение - 4.
(б) Длина компонента "позиция начального символа" каждой статьи справочника (позиция символа 20).
Одна десятичная цифра. Значение - 5.
(в) Не определено (позиции символов 22-23). Два пробела (##).
Определение
Справочник записи состоит из набора элементов данных фиксированной длины - статей справочника. Каждая статья справочника определяет одно поле (в случае повторяющихся полей - одно повторение поля) записи. Статьи справочника формируются в соответствии со стандартом ISO 2709 и состоят из трех компонентов: метка поля, длина поля, позиция начального символа. Количество символов в компонентах "длина поля" и "позиция начального символа" определяется в маркере (позиции 20 и 21 соответственно). Справочник включается в запись непосредственно после маркера, начиная с позиции 24. Статьи справочника располагаются в порядке возрастания метки поля.
Наличие
Обязательное.
Не повторяется.
Метка, индикаторы и подполя
Метка, индикаторы и подполя отсутствуют.
Компоненты статьи справочника
(1) Метка поля (позиции 0-2)
Метка поля - три последовательных символа, идентифицирующих поля.
(2) Длина поля (позиции 3-6)
Четыре цифры, указывающие длину поля, определяемого данной статьей справочника. Длина поля определяется с учетом индикаторов, идентификаторов подполей, данных, разделителя поля. В случае, если длина поля меньше четырех цифр, длина поля выравнивается вправо с добавлением ведущих нулей.
(3) Позиция начального символа (позиции 7-11)
Пять цифр, определяющие позицию первого символа поля, определяемого данной статьей справочника, относительно базового адреса данных (маркер, позиции 12-16). В случае, если позиция начального символа меньше пяти цифр, позиция начального символа выравнивается вправо с добавлением ведущих нулей.
Блок содержит номера, идентифицирующие запись и / или содержащиеся в ней данные. Поля блока идентификации заполняются автоматически.
Определены следующие поля:
001 Идентификатор записи
005 Идентификатор версии
015 Международный стандартный номер авторитетных/нормативных записей (зарезервировано)
001 ИДЕНТИФИКАТОР ЗАПИСИ
Определение
Поле содержит набор символов, однозначно идентифицирующий запись, а именно контрольный номер записи, присвоенный учреждением, подготовившим запись.
Наличие
Обязательное.
Не повторяется.
Индикаторы
Индикаторы отсутствуют.
Примечание к содержанию поля
Решение о форме идентификатора записи принимается библиографирующим учреждением, создающимей запись.
005 ИДЕНТИФИКАТОР ВЕРСИИ
Определение
Поле содержит 16 символов, указывающих дату и время последней редакции записи (4 символа обозначают год, 2 символа - месяц, 2 - день, 2 - час, 2 - минуты, 2 - секунды, 2 - десятые доли секунды, включая точку).
Наличие
Обязательное.
Не повторяется.
Индикаторы
Индикаторы отсутствуют.
Взаимосвязанные поля
100 ДАННЫЕ ОБЩЕЙ ОБРАБОТКИ (позиции 0-7)
015 МЕЖДУНАРОДНЫЙ СТАНДАРТНЫЙ НОМЕР АВТОРИТЕТНЫХ / НОРМАТИВНЫХ ДАННЫХ (ISADN)
Необходим для идентификации авторитетных/нормативных данных, созданных различными библиографирующими учреждениями (зарезервировано для ISADN).
Блок содержит заголовки, для которых создаются записи. В авторитетной / нормативной записи это - принятый заголовок, в ссылочной или справочной - вариантный заголовок.
Поля блока 2-- могут повторяться для варианта заголовка этого блока в иной графике. Если для заголовка в альтернативной графике создается самостоятельная авторитетная / нормативная запись, альтернативная форма заголовков должна приводиться не в повторяющихся полях блока 2--, а в поле блока связанных заголовков 7--.
Подполя, перечисленные в полях блока 2--, используются также в полях заголовков блока 4-, 5--, 7--.
Из контрольных подполей в полях блока 2-- используются подполя $7 Графика и $8 Язык заголовка.
В некоторых полях блока 2-- кроме контрольных подполей может использоваться подполе $4 Код отношений. Подполе $4 может включаться в поля имен для использования в заголовках имя / заглавие. Используемые коды - см. Приложение С к Российскому коммуникативному формату .
Определены следующие поля:
200 Заголовок - Имя лица
210 Заголовок - Наименование организации
215 Заголовок - Географическое название
220 Заголовок - Родовое имя
230 Заголовок - Унифицированное заглавие
235 Заголовок - Обобщающее унифицированное заглавие
240 Заголовок - Имя / Заглавие
245 Заголовок - Имя / Обобщающее унифицированное заглавие
250 Заголовок - Тематическая предметная рубрика
200 ЗАГОЛОВОК - ИМЯ ЛИЦА
Определение
Поле содержит заголовок, представляющий собой имя лица. Имя лица может быть приведено в форме личного имени, фамилии, имени и отчества, в инициальной или полной форме. К имени лица могут быть добавлены идентифицирующие признаки - титулы, эпитеты, звания и т.д. Если заголовок-имя лица используется как предметная рубрика, к нему добавляются тематические, географические, хронологические подзаголовки, а также подзаголовки формы.Поле 200 в формате авторитетных / нормативных данных соответствует полям 600, 700, 701, 702 формата для библиографических данных (см. таблицу соответствия в разделе Руководство по применению). Перечень видов интеллектуальной ответственности, которую могут иметь лица, определяются в соответствии с перечнем, приведенным в Приложение C к Российскому коммуникативному формату.
Поле 200 может использоваться в качестве элемента имени в полях Имя / Заглавие (240, 245).
Наличие
Факультативное.
Повторяется для заголовка в альтернативной графике.
Индикаторы:
Первый - не определен, проставляется пробел (#).
Второй - определяет способ ввода имени лица:
0 - Имя лица вводится под личным именем или в прямом порядке
1 - Имя лица вводится под фамилией
Подполя Таблица 3
| Идентификатор подполя
|
Подполе
|
Примечание
|
| $a
|
Начальный элемент ввода
|
НП
|
| $b
|
Часть имени, кроме начального элемента ввода
|
НП
|
| $c
|
Идентифицирующие признаки (кроме дат)
|
П
|
| $d
|
Римские цифры
|
НП
|
| $f
|
Даты
|
НП
|
| $g
|
Раскрытие инициалов имени лица
|
НП
|
| $4
|
Код отношений
|
П
|
| $x
|
Тематический подзаголовок
|
П
|
| $y
|
Географический подзаголовок
|
П
|
| $z
|
Хронологический подзаголовок
|
П
|
| $j
|
Подзаголовок формы
|
П
|
| Контрольные подполя:
|
| $7
|
Графика
|
П
|
| $8
|
Язык заголовка
|
П
|
$a начальный элемент ввода
Часть имени лица, используемая при формировании упорядоченных списков (для сортировки записей).
Таблица 4
| Индикатор 2
|
$a
|
| 0
|
начальная часть имени
|
| 1
|
фамилия
|
Подполе не повторяется. Обязательно должно присутствовать, если присутствует поле 200.
Предлоги, артикли, частицы, участвующие в сортировке записей (стоящие перед фамилией или личным именем в начальном элементе ввода), включаются в подполе $a. Предлоги, частицы, артикли, не участвующие в сортировке записей (стоящие до или после фамилии или личного имени и написанные со строчной буквы), рекомендуется включать в подполе $b.
$b часть имени, отличная от начального элемента ввода (инициалы)
Остаток имени от начального элемента ввода - фамилии или родового имени. Содержит личные имена (не фамилии) и другие присвоенные имена в инициальной форме. При использовании подполя индикатор формы представления имени должен быть 1 (имя лица вводится под фамилией). Предназначенные для печати раскрытые инициалы записываются в $g.
Не повторяется.
Расшифровка Таблица 5
| Индикатор 2
|
$b
|
| 0
|
не используется
|
| 1
|
оставшаяся часть имени лица:
- инициалы
- предлоги, частицы, артикли, не участвующие в сортировке записей (стоящие после фамилии или личного имени и написанные со строчной буквы)
|
$c идентифицирующий признак
Любые дополнения к имени (кроме дат), которые не являются неотъемлемой частью имени (титулы, эпитеты, названия должностей, профессий, т.д.), например: князь, протопоп, иранский шах, врач, снайпер и т.д.)
Повторяется.
$d римские цифры
В подполе вводятся римские цифры, ассоциирующиеся с именами (римских пап, членов королевских семей, священнослужителей, т.д.). Используется только при значении индикатора формы представления имени = 0.
Не повторяется.
Расшифровка Таблица 6
| Индикатор 2
|
$d
|
| 0
|
римские цифры
|
| 1
|
не используется
|
$f даты
В подполе записываются любые типы дат (даты рождения, смерти, правления и т.д.). В случае необходимости дата может уточняться в полной или сокращенной форме (т.е. жил, род., умер).
Не повторяется.
$g раскрытие инициалов имени лица
В подполе вносится раскрытая форма имени лица, инициалы которого записаны в подполе $b. Подполе используется только при значении второго индикатора 1 (имя лица вводится под фамилией).
Подполе не обязательно, заполняется только в том случае, если необходимо иметь в записи и краткую, и полную форму имени.
Не повторяется.
Расшифровка Таблица 7
| Индикатор 2
|
$d
|
| 0
|
не используется
|
| 1
|
раскрытая форма личного имени
|
$4 код отношений
Включается в поле 200 для использования в некоторых случаях в заголовках Имя / Заглавие (240, 245). Используются коды из Приложение С к Российскому коммуникативному формату.
Повторяется.
$x тематический подзаголовок
В подполе вносится слово или словосочетание, детализирующее тематический аспект заголовка предметной рубрики, представленного именем лица, либо другого подзаголовка.
Повторяется.
$y географический подзаголовок
В подполе вносится слово или словосочетание, детализирующее географический аспект заголовка предметной рубрики, представленного именем лица, либо другого подзаголовка.
Повторяется.
$z хронологический подзаголовок
В подполе вносится слово или словосочетание, детализирующее хронологический аспект заголовка предметной рубрики, представленного именем лица, либо другого подзаголовка (кроме дат, включаемых в подполе $f).
Повторяется.
$j подзаголовок формы
В подполе вносится слово или словосочетание, добавляемое к предметной рубрике для отражения формы или вида издания, целевого и читательского назначения.
Повторяется.
Взаимосвязанные поля и подполя
240 ЗАГОЛОВОК - ИМЯ / ЗАГЛАВИЕ
245 ЗАГОЛОВОК - ИМЯ / ОБОБЩАЮЩЕЕ УНИФИЦИРОВАННОЕ ЗАГЛАВИЕ
$4 КОД ОТНОШЕНИЙ
210 ЗАГОЛОВОК - НАИМЕНОВАНИЕ ОРГАНИЗАЦИИ
Определение
Поле содержит заголовок, представляющий собой наименование организации (постоянной или временной).
Название административно-территориальной единицы, за которой как составная часть заголовка следует наименование организации, рассматривается как наименование организации (поле 210). Название административно-территориальной единицы как таковой или сопровождаемое предметными подзаголовками рассматривается как географическое название (поле 215).
Поле 210 в формате авторитетных / нормативных данных соответствует полям 601, 710, 711, 712 формата для библиографических данных (см. таблицу соответствия в разделе Руководство по применению).
Наличие
Факультативное.
Повторяется для заголовков в альтернативной графике.
Индикаторы
Первый индикатор определяет тип организации:
0 наименование постоянной организации
1 наименование временной организации
Второй индикатор определяет способ ввода наименования:
0 наименование в инверсированной форме
1 наименование, введенное под местонахождением или административно - территориальной единицей
2 наименование в прямой форме
Для записей типов y и z в позиции второго индикатора проставляется символ-заполнитель (|).
Подполя Таблица 8
| Идентификатор подполя
|
Подполя данных
|
Примечание
|
| $a
|
Начальный элемент ввода
|
НП
|
| $b
|
Структурное подразделение
|
П
|
| $c
|
Идентифицирующий признак
|
П
|
| $d
|
Номер временной организации (мероприятия) и/или номер ее части
|
П
|
| $e
|
Место проведения временной организации (мероприятия)
|
НП
|
| $f
|
Дата проведения временной организации (мероприятия)
|
НП
|
| $g
|
Инверсированный элемент
|
НП
|
| $h
|
Часть наименования, отличная от начального элемента ввода и инверсированного элемента
|
П
|
| $4
|
Код отношений
|
П
|
| $х
|
Тематический подзаголовок
|
П
|
| $y
|
Географический подзаголовок
|
П
|
| $z
|
Хронологический подзаголовок
|
П
|
| $j
|
Подзаголовок формы
|
П
|
| Контрольные подполя:
|
| $7
|
Графика заголовка
|
П
|
| $8
|
Язык заголовка
|
П
|
$a начальный элемент ввода
В подполе вводится наименование организации (простой заголовок), если наименование состоит из одного звена, или его часть (сложный заголовок), если наименование организации состоит из двух и более звеньев, либо название страны или иной юрисдикции, предшествующее наименованию организации.
Подполе не повторяется. Обязательное.
$b структурное подразделение
Часть наименования организации, содержащая наименование подведомственного коллектива или структурного подразделения при иерархической структуре наименования организации. Также в подполе вносится часть наименования коллектива, следующая после наименования страны или иной административно-территориальной единицы , в заголовках под названием административно-территориальной единицы.
Повторяется для каждого последующего иерархического уровня.
$c идентифицирующий признак
Дополнение или уточнение к наименованию организации, за исключением порядкового номера, даты и места проведения временной организации. Может включать: географические названия, даты, номера.
Повторяется для каждого из перечисленных идентифицирующих признаков (в случае их сочетания).
$d порядковый номер временной организации и/или номер ее части
Указывается арабскими цифрами без наращения окончания.
Повторяется.
$e место проведения временной организации
Может представлять собой название страны, города или любой другой местности, где проходила временная организация.
Не повторяется.
$f дата проведения временной организации
В подполе заносятся даты, относящиеся к данной временной организации.
Не повторяется.
$g инверсированный элемент
В подполе вводится часть наименования организации, записанного в инверсированной форме, - часть наименования, перенесенная с начала наименования (инициалы или имя и отчество, записанные после фамилии в заголовках, представляющих персональные выставки, магазины частных владельцев и т.д.).
В соответствии с общей методикой предметизации заголовки, представляющие персональные выставки, не рассматриваются как заголовки организации. В таких случаях заголовок предметной рубрики представляется именем лица.
Не повторяется.
$h часть наименования, отличная от начального элемента ввода и инверсированного элемента
В инверсированном заголовке - часть наименования, следующая за инверсией.
Повторяется.
$4 код отношений
Включается в поле 210 для использования в некоторых случаях в заголовках Имя / Заглавие (240, 245).
Повторяется.
$x тематический подзаголовок
В подполе вносится слово или словосочетание, детализирующее тематический аспект заголовка предметной рубрики, представленной наименованием организации, или других подзаголовков.
Повторяется.
$y географический подзаголовок
В подполе вносится слово или словосочетание, детализирующее географический аспект заголовка предметной рубрики, представленной наименованием организации, или других подзаголовков.
Повторяется.
$z хронологический подзаголовок
В подполе вносится слово или словосочетание, детализирующее хронологический аспект заголовка предметной рубрики, представленной наименованием организации, или других подзаголовков (кроме дат, включаемых в подполе $f).
Повторяется.
$j подзаголовок формы
В подполе вносится слово или словосочетание, добавляемое к предметной рубрике для отражения формы или вида издания, целевого и читательского назначения.
Повторяется.
Взаимосвязанные поля
150 ПОЛЕ КОДИРОВАННЫХ ДАННЫХ ДЛЯ НАИМЕНОВАНИЙ ОРГАНИЗАЦИЙ
160 КОД ГЕОГРАФИЧЕСКОГО РЕГИОНА
215 ЗАГОЛОВОК - ГЕОГРАФИЧЕСКОЕ НАЗВАНИЕ
240 ЗАГОЛОВОК - ИМЯ / ЗАГЛАВИЕ
245 ЗАГОЛОВОК - ИМЯ / ОБОБЩАЮЩЕЕ УНИФИЦИРОВАННОЕ ЗАГЛАВИЕ
215 ЗАГОЛОВОК - ГЕОГРАФИЧЕСКОЕ НАЗВАНИЕ
Определение
Поле содержит заголовок, представляющий собой географическое название. Название административно-территориальной единицы, за которой как составная часть заголовка следует наименование организации, рассматривается как наименование организации (поле 210). Название административно-территориальной единицы как таковой или сопровождаемое предметными подзаголовками рассматривается как географическое название (поле 215).
Поле 215 в формате авторитетных / нормативных данных соответствует полям 601, 607, 710, 711, 712 формата для библиографических данных (см. таблицу соответствия в разделе Руководство по применению).
Наличие
Факультативное.
Повторяется для заголовков в альтернативной графике.
Индикаторы
Не определены, проставляются пробелы (##).
Подполя Таблица 9
| Идентификатор подполя
|
Подполе
|
Примечание
|
| $a
|
Начальный элемент ввода
|
НП
|
| $х
|
Тематический подзаголовок
|
П
|
| $y
|
Географический подзаголовок
|
П
|
| $z
|
Хронологический подзаголовок
|
П
|
| $j
|
Подзаголовок формы
|
П
|
| Контрольные подполя
|
| $7
|
Графика
|
П
|
| $8
|
Язык заголовка
|
П
|
$a начальный элемент ввода
В подполе вводится заголовок-географическое название.
Не повторяется.
$x тематический подзаголовок
В подполе вносится слово или словосочетание, детализирующее тематический аспект заголовка предметной рубрики, представленной географическим названием, или других подзаголовков.
Повторяется.
$y географический подзаголовок
В подполе вносится слово или словосочетание, детализирующее географический аспект заголовка предметной рубрики, представленной географическим названием, или других подзаголовков.
Повторяется.
$z хронологический подзаголовок
В подполе вносится слово или словосочетание, детализирующее хронологический аспект заголовка предметной рубрики, представленной географическим названием, или других подзаголовков.
Повторяется.
$j подзаголовок формы
В подполе вносятся термины, добавляемые к предметной рубрике для отражения формы и вида издания, целевого и читательского назначения.
Повторяется.
Взаимосвязанные поля
160 КОД ГЕОГРАФИЧЕСКОГО РЕГИОНА
210 ЗАГОЛОВОК - НАИМЕНОВАНИЕ ОРГАНИЗАЦИИ
240 ЗАГОЛОВОК - ИМЯ / ЗАГЛАВИЕ
245 ЗАГОЛОВОК - ИМЯ / ОБОБЩАЮЩЕЕ УНИФИЦИРОВАННОЕ ЗАГЛАВИЕ
220 ЗАГОЛОВОК - РОДОВОЕ ИМЯ
Определение
Поле содержит заголовок, представляющий собой родовое имя (имя семьи, рода, династии, клана и других подобных групп).
Поле 220 в формате авторитетных / нормативных данных соответствует полям 602, 720, 721, 722 формата для библиографических данных (см. таблицу соответствия в разделе Руководство по применению).
Наличие
Факультативное.
Повторяется для заголовков в альтернативной графике.
Индикаторы
Индикаторы не определены, проставляются пробелы (##).
Подполя Таблица 10
| Идентификатор подполя
|
Подполе
|
Примечание
|
| $a
|
Начальный элемент ввода
|
НП
|
| $f
|
Даты
|
НП
|
| $4
|
Код отношений
|
П
|
| $x
|
Тематический подзаголовок
|
П
|
| $y
|
Географический подзаголовок
|
П
|
| $z
|
Хронологический подзаголовок
|
П
|
| $j
|
Подзаголовок формы
|
П
|
| Контрольные подполя
|
| $7
|
Графика
|
П
|
| $8
|
Язык заголовка
|
П
|
$a начальный элемент ввода
В подполе вводятся все данные, формирующие заголовок, кроме дат. При этом любое дополнение записывается в круглых скобках для отделения его от имени.
Не повторяется.
$f даты
В подполе вводятся даты, относящиеся к родовым именам, когда эти даты необходимы как часть заголовка.
Не повторяется.
$4 код отношений
Включается в поле 220 для использования в некоторых случаях в заголовках Имя / Заглавие (240, 245). Используются коды из Приложения С к Российскому коммуникативному формату.
Повторяется.
$x тематический подзаголовок
В подполе вносится слово или словосочетание, детализирующее тематический аспект заголовка предметной рубрики, представленной родовым именем, или других подзаголовков.
Повторяется.
$y географический подзаголовок
В подполе вносится слово или словосочетание, детализирующее географический аспект заголовка предметной рубрики, представленной родовым именем, или других подзаголовков.
Повторяется.
$z хронологический подзаголовок
В подполе вносится слово или словосочетание, детализирующее хронологический аспект заголовка предметной рубрики, представленной родовым именем, или других подзаголовков (кроме дат, включаемых в подполе $f).
Повторяется.
$j подзаголовок формы
В подполе вносится слово или словосочетание, добавляемое к заголовку предметной рубрики для отражения формы и вида издания, целевого и читательского назначения.
Повторяется.
Взаимосвязанные поля и подполя
240 ЗАГОЛОВОК - ИМЯ / ЗАГЛАВИЕ
245 ЗАГОЛОВОК - ИМЯ / ОБОБЩАЮЩЕЕ УНИФИЦИРОВАННОЕ ЗАГЛАВИЕ
$4 КОД ОТНОШЕНИЙ
Поля блока используются в авторитетной / нормативной записи для представления исторической справки или иной дополнительной информации, связанной с заголовком, когда связи между заголовками не могут быть адекватно и в полном объеме раскрыты через поля блоков 4-- и 5--. Справки или примечания поясняют связи между вариантным и соответствующим(и) принятым(и) заголовком(ами). В справочных записях справки и примечания включают сведения о формировании или сортировке тех типов принятых заголовков, поиск которых может осуществляться в форме, представленной в пояснительном заголовке.
Все справки и примечания приводятся в виде текста, предназначенного для вывода на экран дисплея непосредственно для пользователя. Примечания, предназначенные для сотрудников библиографирующего учреждения, приводятся в блоке 8--- Источник информации.
В полях блока 3-- могут использоваться только следующие контрольные подполя:
$6 Данные для связи полей
$7 Графика
Определены следующие поля справок и примечаний:
300 Справочное примечание
305 Ссылочное примечание "см.также"
310 Ссылочное примечание "см."
320 Общее справочное примечание
330 Примечание об области применения
Индикаторы в блоке 3-- определяют тип примечания, за исключением поля 320, в котором индикаторы не определены.
300 СПРАВОЧНОЕ ПРИМЕЧАНИЕ
Определение
Поле применяется в авторитетной / нормативной или ссылочной записи для пояснения связей между заголовком в поле блока 2-- и другими заголовками. Поле используется также для исторической справки о заголовке.
Наличие
Факультативное.
Повторяется.
Индикаторы
Первый индикатор определяет тип примечания:
0 Примечание об использовании имени или заглавия в качестве заголовка (не в качестве предметной рубрики)
1 Примечание об использовании любого заголовка блока 2-- в качестве предметной рубрики
Второй индикатор не определен, проставляется пробел (#).
Подполя. Таблица 11
| Идентификатор подполя
|
Подполе
|
Примечание
|
| $a
|
Текст справки
|
НП
|
| Контрольные подполя
|
| $6
|
Данные для связи полей
|
НП
|
| $7
|
Графика
|
НП
|
Примечание к содержанию поля
Для заголовков-наименований организации поле 300 может использоваться для сведений об основании организации и т.п., а также сведений о других наименованиях данной организации при отсутствии в библиографирующем учреждении документов под этим наименованием.
В авторитетных / нормативных и ссылочных записях для предметных рубрик это поле может использоваться, в частности, для исторической справки о предметной рубрике. Исторической справкой о предметной рубрике предлагается считать любую пояснительную информацию (в том числе и исторического характера) о любом заголовке, используемом в качестве заголовка предметной рубрики. Подобная информация может быть полезна для пользователя, поэтому справочное примечание выводится на экран. Информация, приведенная в поле 300 записи, не требует приведения соответствующих ссылок в полях блока 5--.
Поле 300 приводится в записи вместе с полями 305 и 510, если необходимо соединить два или более принятых заголовка справкой, в которой содержатся историческое обоснование связи между заголовками и инструктивные указания для поиска необходимого заголовка. Историческое обоснование при этом может вводиться в 300 поле, инструктивная часть - в 305 (см. примеры к 305 полю).
Взаимосвязанные поля и подполя
$0 ПОЯСНИТЕЛЬНЫЙ ТЕКСТ
305 ССЫЛОЧНОЕ ПРИМЕЧАНИЕ "СМ. ТАКЖЕ"
820 ИНФОРМАЦИЯ ОБ ИСПОЛЬЗОВАНИИ ЗАГОЛОВКА В ПОЛЕ 2--
830 ОБЩЕЕ ПРИМЕЧАНИЕ КАТАЛОГИЗАТОРА
305 ССЫЛОЧНОЕ ПРИМЕЧАНИЕ "СМ. ТАКЖЕ"
Определение
Поле 305 приводится в авторитетной / нормативной записи (тип записи x) для пояснения связи между заголовком в поле блока 2-- и связанными заголовками в полях блока 5--, если ссылка "см. также" не может быть адекватно сформирована только из содержания полей блока 5--.
Принятый заголовок, от которого делается ссылка, является заголовком из блока 2-- авторитетной / нормативной записи. Каждый принятый заголовок, к которому делается ссылка, и текст "см. также" (или подобный) приводятся в поле 305.
Примечание обычно используется в записях для связанных заголовков в дополнение, а не вместо ссылок "см. также" блока 5--. Это означает, что заголовки, приведенные в подполе $b поля 305, должны также быть приведены в соответствующих полях блока 5--.
В авторитетной / нормативной записи для каждого заголовка, к которому делается ссылка в поле 305, принятый заголовок из поля блока заголовков 2-- приводится в полях блока 5--. Если в указанном примечании нет ссылки к другим принятым заголовкам, а содержатся только примеры, соответствующие поля блока 5-- не формируются. Примеры для каждого заголовка должны дополнительно приводиться в авторитетной / нормативной записи в поле 825 Пример, приведенный в примечании.
Примечание: В случае предметных рубрик рекомендуется использовать поле 305 только для сводных ссылок.
Наличие
Факультативное.
Повторяется.
Индикаторы
Первый индикатор определяет тип примечания:
0 Примечание об использовании имени или заглавия в качестве заголовка (не в качестве предметной рубрики)
1 Примечание об использовании любого заголовка блока 2-- в качестве предметной рубрики
Второй индикатор не определен, проставляется пробел (#).
Подполя. Таблица 12
| Идентификатор подполя
|
Подполе
|
Примечание
|
| $a
|
Текст примечания
|
П
|
| $b
|
Заголовок, к которому делается ссылка
|
П
|
| Контрольные подполя
|
| $6
|
Данные для связи полей
|
НП
|
| $7
|
Графика
|
НП
|
Взаимосвязанные поля и подполя
$0 ПОЯСНИТЕЛЬНЫЙ ТЕКСТ
$5 УПРАВЛЕНИЕ ФОРМИРОВАНИЕМ ССЫЛКИ (КОНТРОЛЬ ТРАССИРОВКИ)
300 СПРАВОЧНОЕ ПРИМЕЧАНИЕ
820 ИНФОРМАЦИЯ ОБ ИСПОЛЬЗОВАНИИ ЗАГОЛОВКА В ПОЛЕ БЛОКА 2--
830 ОБЩЕЕ ПРИМЕЧАНИЕ КАТАЛОГИЗАТОРА
310 ССЫЛОЧНОЕ ПРИМЕЧАНИЕ "СМ."
Определение
Поле 310 приводится в ссылочной записи (тип записи y) для пояснения связи между вариантным заголовком в поле блока 2-- и принятым заголовком, который приводится в поле 310, если ссылка "см." не может быть адекватно сформирована только из содержания полей блока 4--.
Принятый заголовок, к которому делается ссылка, и текст "см." (или подобный) приводятся в поле 310 ссылочной записи. В авторитетной / нормативной записи для принятого заголовка, к которому делается ссылка, в соответствующем поле блока 4-, содержащем вариантный заголовок, указывается код подавления ссылки в подполе $5.
Заголовок в поле блока 2-- ссылочной записи приводится в авторитетной / нормативной записи в поле блока 4-- для каждого заголовка, к которому делается ссылка в поле 310, за исключением тех случаев, когда примечание содержит только примеры. Тогда авторитетная / нормативная запись для каждого заголовка будет содержать поле 825 Пример, приведенный в примечании.
Примечание: В случае предметных рубрик рекомендуется использовать поле 310 только для сводных ссылок.
Наличие
Обязательное для записи типа y.
Поле повторяется.
Индикаторы
Первый индикатор определяет тип примечания:
0 Примечание об использовании имени или заглавия в качестве заголовка (не в качестве предметной рубрики)
1 Примечание об использовании любого заголовка блока 2-- в качестве предметной рубрики
Второй индикатор не определен, проставляется пробел (#).
Подполя. Таблица 13
| Идентификатор подполя
|
Подполе
|
Примечание
|
| $a
|
Текст примечания
|
П
|
| $b
|
Заголовок, к которому делается ссылка
|
П
|
| Контрольные подполя
|
| $6
|
Данные для связи полей
|
НП
|
| $7
|
Графика
|
НП
|
Взаимосвязанные поля
300 СПРАВОЧНОЕ ПРИМЕЧАНИЕ
820 ИНФОРМАЦИЯ ОБ ИСПОЛЬЗОВАНИИ ЗАГОЛОВКА В ПОЛЕ 2--
825 ПРИМЕР, ПРИВЕДЕННЫЙ В ПРИМЕЧАНИИ
830 ОБЩЕЕ ПРИМЕЧАНИЕ КАТАЛОГИЗАТОРА
835 ИНФОРМАЦИЯ ОБ ИСКЛЮЧЕННОМ ЗАГОЛОВКЕ
320 ОБЩЕЕ СПРАВОЧНОЕ ПРИМЕЧАНИЕ
Определение
Поле используется в справочной записи (тип записи z) для организации поиска данных. Поле содержит информацию о правилах формулировки заголовков той или иной группы, для указания типичных форм заголовков. Поле может применяется для расшифровки типовых аббревиатур. Слово или фраза, к которым даются указанные пояснения, приводятся в поле блока 2-- справочной записи, а сами пояснения - в поле 320.
Наличие
Обязательное для записи типа z.
Не повторяется.
Индикаторы
Индикаторы не определены, проставляются пробелы (##).
Подполя. Таблица 14
| Идентификатор подполя
|
Подполе
|
Примечание
|
| $a
|
Текст примечание
|
П
|
| Контрольные подполя
|
| $6
|
Данные для связи полей
|
НП
|
| $7
|
Графика
|
НП
|
Взаимосвязанные поля
300 СПРАВОЧНОЕ ПРИМЕЧАНИЕ
820 ИНФОРМАЦИЯ ОБ ИСПОЛЬЗОВАНИИ ЗАГОЛОВКА В ПОЛЕ 2--
825 ПРИМЕР, ПРИВЕДЕННЫЙ В ПРИМЕЧАНИИ
830 ОБЩЕЕ ПРИМЕЧАНИЕ КАТАЛОГИЗАТОРА
330 ПРИМЕЧАНИЕ ОБ ОБЛАСТИ ПРИМЕНЕНИЯ
Определение
Поле используется в авторитетной / нормативной записи для описания области применения заголовка из поля блока 2--. Эта информация может обеспечить точное определение потенциально неоднозначного термина, пояснить различия использования сходных терминов, предоставить пользователям дополнительную информацию и т.д.
Наличие
Факультативное.
Поле повторяется.
Индикаторы
Первый индикатор определяет тип примечания:
0 Примечание об использовании имени или заглавия в качестве заголовка (не в качестве предметной рубрики)
1 Примечание об использовании любого заголовка блока 2-- в качестве предметной рубрики
Второй индикатор не определен, проставляется пробел (#).
Подполя. Таблица 15
| Идентификатор подполя
|
Подполе
|
Примечание
|
| $a
|
Примечание об области применения
|
НП
|
| Контрольные подполя
|
| $6
|
Данные для связи полей
|
НП
|
| $7
|
Графика
|
НП
|
Взаимосвязанные поля
300 СПРАВОЧНОЕ ПРИМЕЧАНИЕ
305 ССЫЛОЧНОЕ ПРИМЕЧАНИЕ "СМ. ТАКЖЕ"
820 ИНФОРМАЦИЯ ОБ ИСПОЛЬЗОВАНИИ ЗАГОЛОВКА В ПОЛЕ 2--
825 ПРИМЕР, ПРИВЕДЕННЫЙ В ПРИМЕЧАНИИ
830 ОБЩЕЕ ПРИМЕЧАНИЕ КАТАЛОГИЗАТОРА
4-- и 5-- БЛОКИ ФОРМИРОВАНИЯ (ТРАССИРОВКИ) ССЫЛОК "СМ." И "СМ. ТАКЖЕ"
Блоки содержат поля формирования (трассировки) ссылок (отсылок) "см." и "см. также" для заголовка в поле блока 2--.
Поля для блоков 2--, 4-- и 5-- имеют одни и те же индикаторы и идентификаторы подполей.
Наиболее существенное отличие полей блоков 4-- и 5--- заключается в том, что поле 5-- для некоторого заголовка в поле 2-- можно формировать только при том условии, что содержимое формируемого поля присутствует в поле 2-- какой-либо другой авторитетной / нормативной (записи, т.е. выступает в качестве принятого заголовка.
4-- БЛОК ФОРМИРОВАНИЯ (ТРАССИРОВКИ) ССЫЛОК "СМ."
Блок содержит поля формирования ссылок (отсылок) "см." от вариантного заголовка, приведенного в поле блока 4--, к принятому заголовку в поле блока 2-- той же записи. Имена, заглавия и тематические предметные рубрики, приведенные в полях блока 4--, не могут быть заголовками других авторитетных / нормативных записей.
В авторитетной / нормативной записи допускается использование ссылок (отсылок) только между заголовками одной категории (от имени лица к имени лица, от тематической предметной рубрики - к тематической предметной рубрике и т.д.).
В случаях, когда запись содержит ссылку (отсылку) к заголовку другой категории (например, Болотников Иван см. Крестьянская война под руководством Болотникова), следует использовать поля блока 5--.
В полях блока 4-- могут использоваться контрольные подполя:
$0 Пояснительный текст
$2 Код системы предметизации
$3 Номер записи
$5 Управление формированием ссылок (контроль трассировки)
$6 Данные для связи полей
$7 Графика
$8 Язык заголовка
Определены следующие поля:
400 Формирование ссылки "см." - Имя лица
410 Формирование ссылки "см." - Наименование организации
415 Формирование ссылки "см." - Географическое название
420 Формирование ссылки "см." - Родовое имя
430 Формирование ссылки "см." - Унифицированное заглавие
440 Формирование ссылки "см." - Имя / Заглавие
445 Формирование ссылки "см." - Имя / Обобщающее унифицированное заглавие
450 Формирование ссылки "см." - Тематическая предметная рубрика
400 ФОРМИРОВАНИЕ ССЫЛКИ "СМ." - ИМЯ ЛИЦА
Определение
Поле содержит вариантный заголовок имени лица, от которого формируется ссылка "см." к принятому заголовку в поле 200 для вывода на экран, а также указания о типе связи и необходимости такого вывода или его блокировки в подполе $5. Если не должна устанавливаться особая связь и ссылка не блокируется, подполе $5 не используется.
Наличие
Факультативное.
Повторяется.
Индикаторы и подполя
Индикаторы и подполя определены в описании поля 200.
410 ФОРМИРОВАНИЕ ССЫЛКИ “СМ.” - НАИМЕНОВАНИЕ ОРГАНИЗАЦИИ
Определение
Поле содержит вариантный заголовок наименования организации, от которого формируется ссылка “см.” к принятому заголовку в поле 210 для вывода на экран, а также указания о типе связи и необходимости такого вывода или его блокировки в подполе $5. Если не должна устанавливаться особая связь и ссылка не блокируется, подполе $5 не используется.
Название административно-территориальной единицы, за которой как составная часть заголовка следует наименование организации, рассматривается как наименование организации (поле 410). Название административно-территориальной единицы как таковой или сопровождаемое предметными подзаголовками рассматривается как географическое название (поле 415).
Наличие
Факультативное.
Поле повторяется.
Индикаторы и подполя
Индикаторы и подполя определены в описании поля 210.
Для сокращенного наименования коллектива в позиции второго индикатора проставляется символ-заполнитель (см. пример 5, 7, 12, 14).
415 ФОРМИРОВАНИЕ ССЫЛКИ “СМ.” - ЗАГОЛОВОК - ГЕОГРАФИЧЕСКОЕ НАЗВАНИЕ
Определение
Поле содержит вариантный заголовок географического названия, от которого формируется ссылка “см.” к принятому заголовку в поле 215 для вывода на экран, а также указания о типе связи и необходимости такого вывода или его блокировки в подполе $5. Если не должна устанавливаться особая связь и ссылка не блокируется, подполе $5 не используется.
Название административно-территориальной единицы как таковой или сопровождаемое предметными подзаголовками рассматривается как географическое название (поле 415). Название административно-территориальной единицы, за которой как составная часть заголовка следует наименование организации, рассматривается как наименование организации (поле 410).
Наличие
Факультативное.
Повторяется.
Индикаторы и подполя
Индикаторы и подполя определены в описании поля 215.
420 ФОРМИРОВАНИЕ ССЫЛКИ “СМ.” - РОДОВОЕ ИМЯ
Определение
Поле содержит вариантный заголовок родового имени, от которого формируется ссылка “см.” к принятому заголовку в поле 220 для вывода на экран, а также указания о типе связи и необходимости такого вывода или его блокировки в подполе $5. Если не должна устанавливаться особая связь и ссылка не блокируется, подполе $5 не используется.
Наличие
Факультативное.
Повторяется.
Индикаторы и подполя
Индикаторы и подполя определены в описании поля 220.
430 ФОРМИРОВАНИЕ ССЫЛКИ “СМ.” - УНИФИЦИРОВАННОЕ ЗАГЛАВИЕ
Определение
Поле содержит вариантный заголовок унифицированного заглавия, тематического заглавия, а также заглавия серии, от которого формируется ссылка “см.” к принятому заголовку в поле 230 для вывода на экран, а также указания о типе связи и необходимости такого вывода или его блокировки в подполе $5. Если не должна устанавливаться особая связь и ссылка не блокируется, подполе $5 не используется. Кроме того, поле может содержать рукописи самой рукописи, от которого формируется ссылка к унифицированному заглавию рукописи, принятому в науке, приведенному в поле 230.
Наличие
Факультативное.
Повторяется.
Индикаторы и подполя
Индикаторы и подполя определены в описании поля 230.
440 ФОРМИРОВАНИЕ ССЫЛКИ “СМ.” - ИМЯ / ЗАГЛАВИЕ
Определение
Поле содержит вариантный заголовок Имя / Заглавие, от которого формируется ссылка “см.” к принятому заголовку в поле 240 для вывода на экран, а также указания о типе связи и необходимости такого вывода или его блокировки в подполе $5. Если не должна устанавливаться особая связь и ссылка не блокируется, подполе $5 не используется. Структура поля аналогична структуре поля 240. Данные приводятся в соответствующих полях блока 2--, встроенных в поле 440 по правилам, описанным в поле 240.
Наличие
Факультативное.
Повторяется.
Индикаторы и подполя
Индикаторы и подполя определены в описании поля 240.
445 ФОРМИРОВАНИЕ ССЫЛКИ “СМ.” - ИМЯ / ОБОБЩАЮЩЕЕ УНИФИЦИРОВАННОЕ ЗАГЛАВИЕ
Определение
Поле содержит вариантный заголовок Имя / Обобщающее унифицированное заглавие, от которого формируется ссылка “см.” к принятому заголовку в поле 245 для вывода на экран, а также указания о типе связи и необходимости такого вывода или его блокировки в подполе $5. Если не должна устанавливаться особая связь и ссылка не блокируется, подполе $5 не используется. Структура поля аналогична структуре поля 245. Данные приводятся в соответствующих полях блока 2--, встроенных в поле 445 по правилам, описанным в поле 245.
Наличие
Факультативное.
Повторяется.
Индикаторы и подполя
Индикаторы и подполя определены в описании поля 245.
450 ФОРМИРОВАНИЕ ССЫЛКИ “СМ.” - ТЕМАТИЧЕСКАЯ ПРЕДМЕТНАЯ РУБРИКА
Определение
Поле содержит вариантный заголовок - тематическую предметную рубрику (простую или сложную), от которой формируется ссылка “см.” к принятому заголовку в поле 250 для вывода на экран, а также указания о типе связи и необходимости такого вывода или его блокировки в подполе $5. Если не должна устанавливаться особая связь и ссылка не блокируется, подполе $5 не используется.
Наличие
Факультативное.
Повторяется.
Индикаторы и подполя
Индикаторы и подполя определены в описании поля 250.
Блок содержит поля формирования ссылок "см. также" от связанного принятого заголовка (кроме параллельного заголовка или заголовка в альтернативной графике), приведенного в поле блока 5--, к принятому заголовку в поле блока 2-- той же записи. Имена, заглавия и тематические предметные рубрики, приведенные в полях блока 5--, обязательно должны быть заголовками других авторитетных / нормативных записей.
В частности, поля блока 5-- могут использоваться для связи заголовков разных категорий, например: Болотников Иван см. также Крестьянская война под руководством Болотникова.
В полях блока 5-- могут использоваться контрольные подполя:
$0 Пояснительный текст
$2 Код системы предметизации
$3 Номер записи
$5 Управление формированием ссылок (контроль трассировки)
$6 Данные для связи полей
$7 Графика
$8 Язык заголовка
Определены следующие поля:
500 Формирование ссылки "см. также" - Имя лица
510 Формирование ссылки "см. также" - Наименование организации
515 Формирование ссылки "см. также" - Географическое название
520 Формирование ссылки "см. также" - Родовое имя
530 Формирование ссылки "см. также" - Унифицированное заглавие
540 Формирование ссылки "см. также" - Имя / Заглавие
545 Формирование ссылки "см. также"- Имя / Обобщающее унифицированное заглавие
550 Формирование ссылки "см. также" - Тематическая предметная рубрика
500 ФОРМИРОВАНИЕ ССЫЛКИ "СМ. ТАКЖЕ" - ИМЯ ЛИЦА
Определение
Поле содержит принятый заголовок имени лица, от которого устанавливается связь с принятым заголовком в поле блока 2-- для вывода ее на экран, а также указания о типе связи и необходимости такого вывода или его блокировки в подполе $5. Если не должна устанавливаться особая связь и ссылка не блокируется, подполе $5 не используется.
Наличие
Факультативное.
Повторяется.
Индикаторы и подполя
Индикаторы и подполя определены в описании поля 200.
510 ФОРМИРОВАНИЕ ССЫЛКИ "СМ. ТАКЖЕ" - НАИМЕНОВАНИЕ ОРГАНИЗАЦИИ
Определение
Поле содержит принятый заголовок - наименование организации, от которого устанавливается связь с принятым заголовком в поле блока 2-- для вывода ее на экран, а также указания о типе связи и необходимости такого вывода или его блокировки в подполе $5. Если не должна устанавливаться особая связь и ссылка не блокируется, подполе $5 не используется.
Название административно-территориальной единицы, за которой как составная часть заголовка следует наименование организации, рассматривается как наименование организации (поле 510). Название административно-территориальной единицы как таковой или сопровождаемое предметными подзаголовками рассматривается как географическое название (поле 515).
Наличие
Факультативное.
Повторяется.
Индикаторы и подполя
Индикаторы и подполя определены в описании поля 210.
515 ФОРМИРОВАНИЕ ССЫЛКИ "СМ. ТАКЖЕ" - ГЕОГРАФИЧЕСКОЕ НАЗВАНИЕ
Определение
Поле содержит принятый заголовок - географическое название организации, от которого устанавливается связь с принятым заголовком в поле блока 2-- для вывода ее на экран, а также указания о типе связи и необходимости такого вывода или его блокировки в подполе $5. Если не должна устанавливаться особая связь и ссылка не блокируется, подполе $5 не используется.
Название административно-территориальной единицы как таковой или сопровождаемое предметными подзаголовками рассматривается как географическое название (поле 515). Название административно-территориальной единицы, за которой как составная часть заголовка следует наименование организации, рассматривается как наименование организации (поле 510).
Наличие
Факультативное.
Повторяется.
Индикаторы и подполя
Индикаторы и подполя определены в описании поля 215.
520 ФОРМИРОВАНИЕ ССЫЛКИ "СМ. ТАКЖЕ" - РОДОВОЕ ИМЯ
Определение
Поле содержит принятый заголовок родового имени, от которого устанавливается связь с принятым заголовком в поле блока 2-- для вывода ее на экран, а также указания о типе связи и необходимости такого вывода или его блокировки в подполе $5. Если не должна устанавливаться особая связь и ссылка не блокируется, подполе $5 не используется.
Наличие
Факультативное.
Повторяется.
Индикаторы и подполя
Индикаторы и подполя определены в описании поля 220.
530 ФОРМИРОВАНИЕ ССЫЛКИ "СМ. ТАКЖЕ" - УНИФИЦИРОВАННОЕ ЗАГЛАВИЕ
Определение
Поле содержит принятый заголовок унифицированного заглавия, тематического заглавия, самоназвания рукописи, а также заглавия серии, от которого устанавливается связь с принятым заголовком в поле блока 2-- для вывода ее на экран, а также указания о типе связи и необходимости такого вывода или его блокировки в подполе $5. Если не должна устанавливаться особая связь и ссылка не блокируется, подполе $5 не используется.
Наличие
Факультативное.
Повторяется.
Индикаторы и подполя
Индикаторы и подполя определены в описании поля 230.
540 ФОРМИРОВАНИЕ ССЫЛКИ "СМ. ТАКЖЕ" - ИМЯ / ЗАГЛАВИЕ
Определение
Поле содержит принятый заголовок Имя / Заглавие, от которого устанавливается связь с принятым заголовком в поле блока 2-- для вывода ее на экран, а также указания о типе связи и необходимости такого вывода или его блокировки в подполе $5. Если не должна устанавливаться особая связь и ссылка не блокируется, подполе $5 не используется. Структура поля аналогична структуре поля 240. Данные приводятся в соответствующих полях блока 2--, встроенных в поле 540 по правилам, описанным в поле 240.
Наличие
Факультативное.
Повторяется.
Индикаторы и подполя
Индикаторы и подполя определены в описании поля 240.
545 ФОРМИРОВАНИЕ ССЫЛКИ "СМ.ТАКЖЕ" - ИМЯ / ОБОБЩАЮЩЕЕ УНИФИЦИРОВАННОЕ ЗАГЛАВИЕ
Определение
Поле содержит принятый заголовок Имя / Обобщающее унифицированное заглавие, от которого устанавливается связь с принятым заголовком в поле блока 2-- для вывода ее на экран, а также указания о типе связи и необходимости такого вывода или его блокировки в подполе $5. Если не должна устанавливаться особая связь и ссылка не блокируется, подполе $5 не используется. Структура поля аналогична структуре поля 245. Данные приводятся в соответствующих полях блока 2--, встроенных в поле 545 по правилам, описанным в поле 245.
Наличие
Факультативное.
Повторяется.
Индикаторы и подполя
Индикаторы и подполя определены в описании поля 245.
550 ФОРМИРОВАНИЕ ССЫЛКИ "СМ. ТАКЖЕ" - ТЕМАТИЧЕСКАЯ ПРЕДМЕТНАЯ РУБРИКА
Определение
Поле содержит принятый заголовок - простую или сложную тематическую предметную рубрику, от которого устанавливается связь с принятым заголовком в поле блока 2-- для вывода ее на экран, а также указания о типе связи и необходимости такого вывода или его блокировки в подполе $5. Если не должна устанавливаться особая связь и ссылка не блокируется, подполе $5 не используется.
Наличие
Факультативное.
Повторяется.
Индикаторы и подполя
Индикаторы и подполя определены в описании поля 250.
Блок содержит поля для классификационных индексов, соответствующих тематике заголовка записи в поле блока 2--. Тематика может быть выражена одним или несколькими классификационными индексами. Допускается использование текстовых пояснений к индексам (например, ввод словесной формулировки индексов).
Определены следующие поля:
675 Универсальная десятичная классификация (УДК)
676 Десятичная классификация Дьюи (ДК Дьюи)
680 Классификация Библиотеки Конгресса (КБК)
686 Индексы других классификаций
689 Библиотечно-библиографическая классификация (ББК)
675 УНИВЕРСАЛЬНАЯ ДЕСЯТИЧНАЯ КЛАССИФИКАЦИЯ (УДК)
Определение
Поле содержит индекс(ы) УДК, соответствующий(ие) заголовку авторитетной / нормативной записи в поле блока 2--. Индекс УДК может сопровождаться поясняющими его словами.
Наличие
Факультативное.
Повторяется.
Индикаторы
Индикаторы не определены, проставляются пробелы (##).
Подполя. Таблица 16
| Идентификатор подполя
|
Подполе
|
Примечание
|
| $a
|
Индекс УДК, отдельный или начальный в ряду
|
НП
|
| $b
|
Индексы УДК, последний в ряду
|
НП
|
| $c
|
Поясняющие слова
|
П
|
| $v
|
Сведения об изданиях УДК
|
НП
|
| $z
|
Язык издания
|
П
|
676 ДЕСЯТИЧНАЯ КЛАССИФИКАЦИЯ ДЬЮИ (ДК ДЬЮИ)
Определение
Поле содержит индекс(ы) Десятичной классификации Дьюи, соответствующий(ие) заголовку записи в поле блока 2--. Индекс Дьюи может сопровождаться поясняющими его словами.
Наличие
Факультативное.
Повторяется.
Индикаторы
Индикаторы не определены, проставляются пробелы (##).
Подполя. Таблица 17
| Идентификатор подполя
|
Подполе
|
Примечание
|
| $a
|
Индекс ДК Дьюи, отдельный или начальный в ряду
|
НП
|
| $b
|
Индекс ДК Дьюи, конечный в ряду
|
НП
|
| $c
|
Поясняющие слова
|
П
|
| $v
|
Сведения об изданиях Десятичной классификации Дьюи
|
НП
|
| $z
|
Язык издания
|
П
|
680 КЛАССИФИКАЦИЯ БИБЛИОТЕКИ КОНГРЕССА (КБК)
Определение
Поле содержит индекс(ы) КБК, соответствующий(ие) заголовку авторитетной / нормативной записи в поле блока 2--. Индекс КБК может сопровождаться поясняющими его словами.
Наличие
Факультативное.
Повторяется.
Индикаторы
Индикаторы не определены, проставляются пробелы (##).
Подполя. Таблица 18
| Идентификатор подполя
|
Подполе
|
Примечание
|
| $a
|
Индекс КБК, отдельный или начальный в ряду
|
НП
|
| $b
|
Индексы КБК, последний в ряду
|
НП
|
| $c
|
Поясняющие слова
|
П
|
686 ИНДЕКСЫ ДРУГИХ КЛАССИФИКАЦИЙ
Определение
Поле содержит индекс или ряд индексов общеизвестных систем классификации, обычно не применяемых в международной практике. Индекс(ы) соответствует заголовку авторитетной / нормативной записи. Система классификации идентифицируется в подполе $2. Коды системы классификации см. Приложение G к Российскому коммуникативному формату.
Наличие
Факультативное.
Повторяется.
Индикаторы
Индикаторы не определены, проставляются пробелы (##).
Подполяю Таблица 19
| Идентификатор подполя
|
Подполе
|
Примечание
|
| $a
|
Индекс, отдельный или начальный в ряду
|
НП
|
| $b
|
Индекс, конечный в последовательности
|
НП
|
| $c
|
Поясняющие слова
|
П
|
| $2
|
Код системы предметизации
|
НП
|
Взаимосвязанные документы
РОССИЙСКИЙ КОММУНИКАТИВНЫЙ ФОРМАТ ПРИЛОЖЕНИЕ G :"КОДЫ СИСТЕМ"
689 БИБЛИОТЕЧНО-БИБЛИОГРАФИЧЕСКАЯ КЛАССИФИКАЦИЯ (ББК) (предварительное)
Определение
Поле содержит классификационный индекс / индексы Библиотечно-библиографической классификации, соответствующие тематике заголовка в поле блока 2--.
Наличие
Факультативное.
Повторяется для составных индексов (соединенных знаком "+").
Индикаторы
Индикаторы не определены, проставляются пробелы (##).
Подполя. Таблица 20
| Идентификатор подполя
|
Подполе
|
Примечание
|
| $a
|
Индекс ББК, отдельный или начальный в последовательности
|
НП
|
| $b
|
Индекс ББК, конечный в последовательности
|
НП
|
| $c
|
Поясняющие слова
|
П
|
| $v
|
Сведения об изданиях ББК
|
НП
|
$a индекс ББК, отдельный или начальный в последовательности
В подполе вносится простой индекс, сложный индекс (т.е. индекс, состоящий из комбинации индекса основных таблиц классификации с одним или несколькими индексами вспомогательных таблиц ББК) или начальная часть составного индекса, представляющего собой комбинацию индексов основных таблиц, соединенных знаком " : " (до знака " : ").
Не повторяется.
$b индекс ББК, конечный в последовательности
В подполе вносится заключительная часть составного индекса, представляющего собой комбинацию индексов основных таблиц, соединенных знаком " :" (после знака " : ").
Повторяется.
$c поясняющие слова
В подполе вносится слово или словосочетание, поясняющие наполнение классификационного индекса в подполях $a и $b. Как правило, это слово или словосочетание используется для дифференциации двух или более классификационных индексов, ассоциирующихся с заголовком в поле блока 2--.
Повторяется.
$v сведения об изданиях ББК
В подполе вносится название выпуска таблиц ББК, на основании которых построен классификационный индекс, записанный в подполях $a и $b (выпуск для научных библиотек, для массовых библиотек и т.д.). Название выпуска может вноситься либо полностью, либо в кодированной форме.
Не повторяется.
Примечание к содержанию поля
Составные индексы, представляющие собой комбинацию индексов, соединенных знаком "+", в поле не включаются. В случае, если содержанию заголовка соответствует такой составной индекс, каждая составная часть составного индекса записывается в отдельное повторение поля
Для дополнительной информации о заголовках в поле блока 2--, о справках и примечаниях в блоке 3--, для пояснений связей между принятыми заголовками или между принятым и отвергнутым заголовками, используются следующие подполя:
$0 Пояснительный текст
$2 Код системы предметизации
$3 Номер авторитетной / нормативной записи
$5 Управление формированием ссылок (контроль трассировки)
$6 Данные для связи полей
$7 Графика
$8 Язык заголовка
Эти подполя определены для всех полей блока заголовков 2--, блоков формирования ссылок 4-- и 5--, блока 7--, но их использование обусловлено определенными правилами. Никогда не приводятся в полях некоторых блоков. Отдельные подполя могут применяться также в полях блока примечаний 3--. Поскольку некоторые из контрольных подполей $0, $2, $3, $5, $6, $7, $8 в отдельных блоках не применяются, во вводных разделах к блокам указывается, какие контрольные подполя могут быть использованы. Эти подполя предшествуют всем другим подполям в поле.
$0 ПОЯСНИТЕЛЬНЫЙ ТЕКСТ
Определение
Подполе $0 содержит специальную текстовую информацию (хронологический аспект, др.), которая может выводиться на дисплей или печать ссылки. Пояснительный текст служит для представления заголовка поля блока 2-- в ссылке, генерируемой из полей блоков 4-- и 5--.
Пояснительный текст приводится в случае, если связь между заголовков в поле, содержащем $0, и полем блока 2-- не является одной из связей, значения которых определены для кода связи в подполе $5, и требуется дополнительная пояснительная информация о связи.
Пояснительный текст не заменяет функции блока 3--.
Примечание: Пояснительный текст служит для представления заголовка из поля блока 2-- в автоматически формируемой ссылке.
$2 КОД СИСТЕМЫ ПРЕДМЕТИЗАЦИИ
Определение
Подполе идентифицирует систему предметизации, к которой относится заголовок в поле блока 4-- или 5--, если она отличается от системы предметизации, указанной в поле 152 $b.
Как правило, предметная рубрика (в поле блока 2--) и ссылка (в полях блоков 4-- или 5--) являются частью системы предметизации, определяемой в поле 152 $b; в тех случаях, когда предметные рубрики взяты из других систем предметизации, предметные рубрики могут использоваться для обеспечения связи между системами.
Используется буквенный код переменной длины. Максимальная длина - 7 символов.
Код системы предметизации может использоваться в полях блоков 4--, 5--.
$3 НОМЕР ЗАПИСИ
Определение
Подполе идентифицирует запись, заголовок которой приведен в поле, к которому относится данное подполе. Подполе может использоваться в полях блоков 4-- и 5--, блока связанных заголовков 7--. Подполе $3 может использоваться также в поле блока 4--, когда оно содержит подполе $5, в первой позиции которого (код блокировки ссылки) приводится значение 0 - блокированная ссылка.
$5 УПРАВЛЕНИЕ ФОРМИРОВАНИЕМ ССЫЛОК (контроль трассировки)
Определение
Подполе содержит кодированные данные, относящиеся к использованию или выводу на экран дисплея или печать ссылок блоков 4-- и 5--, т.е. связи между принятыми или между принятым и вариантными заголовками. Данные приводятся в фиксированных позициях. Если заголовок в поле, к которому относится подполе $5, не нуждается в дополнительных инструкциях, подполе $5 не применяется.
Элементы данных. Таблица 21
| |
Наименование элемента данных
|
Кол-во символов
|
Позиции символов
|
| 1
|
Код связи
|
1
|
0
|
| 2
|
Код блокировки ссылки
|
1
|
1
|
· если требуется только указание связи, подполе $5 содержит лишь одну позицию символа (позиция 0), позиция 1 может опускаться
· если требуется только указание кода блокировки ссылки, в позиции 1 указывается код блокировки ссылки, а в позиции 0 содержится символ-заполнитель
· если требуются оба элемента - соответствующие значения приводятся в позициях 0 и 1
(1) Код связи (обязательный) (позиция символа 0)
Односимвольный буквенный код определяет связь между заголовком из полей блока 4-- или 5-- и заголовком в поле блока 2--. Код связи используется для автоматического генерирования пояснительного текста при выводе ссылки на экран дисплея или печать в соответствии с нижеприведенной таблицей.
Вывод пояснительного текста на экран дисплея не обязателен. Допустимо использование вместо него специальных знаков (см. п.11 Вывод на экран дисплея авторитетных / нормативных и ссылочных записей).
Код связи может применяться в полях ссылок блоков 4-- и 5--.
Определены следующие коды и их значения:
a = предыдущий заголовок (связанный заголовок, принятый до определенного времени)
b = последующий заголовок (связанный заголовок, принятый с определенного времени)
d = сокращение (сокращенное наименование или аббревиатура)
e = псевдоним
f = подлинное имя
g = более широкое понятие
h = более узкое понятие
z = другое (связь, не определяемая никаким из перечисленных выше кодов, например, от светской фамилии духовного лица, от девичьей фамилии, для заголовков коллективного автора: ссылка от города, ссылка от структурного подразделения, ссылки от других наименований коллектива и т.д.)
c = ассоциативное понятие (предварительный)
s = синоним (предварительный)
Примечание: коды c и s соответствуют коду z UNIMARC / AUTHORITIES
Пример пояснительного текста, генерируемого с помощью кодов связи. Таблица 22
| Код связи и его значение
|
Пояснительный текст для ссылки из поля блока 4--
|
Пояснительный текст для ссылки из поля блока 5--
|
| a = предыдущий заголовок
|
см. последующий заголовок
|
см. также последующий заголовок
|
| b = последующий заголовок
|
см. предыдущий заголовок
|
см. также предыдущий заголовок
|
| d = сокращение
|
см. несокращенную форму
|
см. также несокращенную форму
|
| e = псевдоним
|
см. подлинное имя
|
см. также подлинное имя
|
| f = подлинное имя
|
см. псевдоним
|
см. также псевдоним
|
| g = более широкое понятие
|
см. более узкое понятие
|
см. также более узкое понятие
|
| h = более узкое понятие
|
см. более широкое понятие
|
см. также более широкое понятие
|
| z = другое
|
см.
|
см. также
|
| c = ассоциативное понятие
|
см. также ассоциативное понятие
|
| s = синоним
|
см. дескриптор
|
(2) Код блокировки ссылки
Односимвольный цифровой код, указывающий, что ссылка от вариантного заголовка не должна автоматически генерироваться из заголовков полей блока формирования ссылок "см." 4-- (т.к. существует самостоятельная ссылочная запись типа "y", включающая поле 310 ссылочное примечание "см.") и блока формирования ссылок "см. также" 5-- (т.к. существует примечание в поле 305, содержащее этот заголовок). В этих случаях предполагается, что при выводе на экран дисплея ссылка представлена только в форме примечания.
0 = блокированная ссылка
$6 ДАННЫЕ ДЛЯ СВЯЗИ ПОЛЕЙ
Определение
Подполе содержит информацию, позволяющую при обработке записи связывать одно поле с другими полями (например, с различной графикой). Предназначено для связи полей в одной записи. Два поля, между которыми устанавливается связь, должны содержать подполе $6 в соответствии с правилами, приведенными ниже. Подполе содержит также код мотивации связи. При использовании этого подполя первые два элемента приводятся всегда, третий элемент является факультативным. Подполе может использоваться в полях блока справок и примечаний 3-- и блоков формирования ссылок 4--, 5--.
Подполе может использоваться в полях блока информационных примечаний 3-- и блоков формирования ссылок 4--, 5--.
Для подполя $6 определены следующие элементы данных:
Элементы данных. Таблица 22
| |
Наименование элемента данных
|
Кол-во символов
|
Позиции символов
|
| 1
|
Код мотивации связи - обязат
.
|
1
|
0
|
| 2
|
Номер связи - обязат.
|
2
|
1-2
|
| 3
|
Метка связываемого поля
|
3
|
3-5
|
(1) Код мотивации связи (позиция символа 0)
Код определяет мотивацию связи полей.
a = альтернативная графика
z = другое
(2) Номер связи (позиции символов 1-2)
Номер каждой связываемой группы полей, состоит из двух цифр и приводится в подполе $6 каждого из связываемых полей. Функцией номера является обеспечение связи между связываемыми полями. Он не предназначен для использования в качестве номера, устанавливающего последовательность или месторасположение поля в записи. Номер связи может присваиваться произвольно, он должен лишь быть идентичным в каждом из связываемых полей и не дублировать номер, используемый для других групп полей в записи.
(3) Метка связываемого поля (позиции символов 3-5)
Этот элемент данных представляет собой метку поля, с которым осуществляется связь. Элемент является факультативным. Если метка поля, с которым осуществляется связь, идентична метке исходного поля, элемент обычно опускается.
$7 ГРАФИКА
Определение
Подполе идентифицирует графику данных в поле, когда она отличается от графики, указанной в поле 100 (позиции символов 21-22).
Подполе может использоваться в полях блока заголовков 2--, блока справок и примечаний 3--, блоков формирования ссылок 4-- и 5--, блока 7--. В записи может приводиться более одного заголовка блока 2-- в повторяющихся полях. В этом случае поле блока 2-- для заголовка в альтернативной графике должно содержать подполе $7. Подробнее о методах обработки альтернативных график см. раздел Данные в альтернативной графике.
Наличие
Повторяется для заголовков, содержащих данные в различных графиках.
Двухсимвольный буквенный код определяет графику заголовка, если идентичный заголовок приводится в записи в иной графике.
Используются следующие значения кода:
· ba = латинская графика
· ca = кириллица
· da = японская - неопределенная графика
· db = японская - каньи
· dc = японская - кана
· ea = китайская
· fa = арабская
· ga = греческая
· ha = древнееврейская
· ia = тайская
· ja = деванагари
· ka = корейская
· la = тамильская
· zz = другая
Если различные графики относятся к разным языкам, применяются правила обработки параллельных данных.
$8 ЯЗЫК ЗАГОЛОВКА
Определение
Подполе идентифицирует язык заголовка, если он (язык) отличается от языка каталогизации (языка ссылок, примечаний и т.д.), указанного в поле 100 (позиции 9-11). Подполе может использоваться в полях блоков заголовков 2--, блоков формирования ссылок 4-- и 5-- и блока связанных заголовков 7--. Если в подполе код языка не указывается, то по умолчанию считается, что язык заголовка, содержащегося в подполе $a данного поля, соответствует коду, приведенному в позициях 21-22 поля 100 данной записи.
Подробнее о языке заголовка см. раздел Параллельные данные.
Наличие
Повторяется для заголовка, содержащего данные на разных языках.
Для обозначения языка заголовка используется трехсимвольный код.
Приложение
2
Спецификация языка Java
П2.1 Основные особенности
Язык хорош для сетей. Известно, что даже бытовую технику объединяют/подключают в(к) сети - "сетевой" язык очень полезен. На Java удобно писать сетевые программки. Язык придумали в фирме Sun не на пустом месте. (см также на их сайт (9) или русcкоязычный ресурс (10)). Итак Sun сделали интерпретируемую версию C++ под названием Oak - для видеомагнитофонов, микроволновых печей и проч.. Программы для такой техники не должны зависать (ТВ или печь не должна виснуть). Потому в синтаксис заложена надежность и безопасность программок. Язык JavaTM
компании Sun Microsystems решает эти проблемы.
- Java является объектно-ориентированным и одновременно простым языком программирования.
- Цикл разработки программных средств с использованием Java значительно сокращается в силу того, что Java - интерпретируемый язык. Процесс компиляции-сборки-загрузки устарел - теперь программу надо только откомпилировать и сразу запускать.
- Приложения переносимы на многие платформы. Однажды написанное приложение не придется модифицировать под другие платформы: оно будет работать без каких-либо изменений на различных операционных системах и аппаратных архитектурах.
- Приложения надежны: Java контролирует обращения к памяти.
- Приложения высокопроизводительны: несмотря на то, что язык Java - интерпретируемый, код Java программы оптимизируется до фазы исполнения.
- Поддержка системы многопоточности позволяет создавать параллельно исполняемые взаимодействующие легковесные процессы.
- Приложения настраиваемы под изменяющееся окружение: возможна динамическая загрузка программных модулей из любого места в сети.
- Пользователи могут быть уверены в безопасности приложений, даже если в них загружен программный код из любого места в Internet. Исполняющая система Java имеет встроенную защиту от вирусов и попыток взлома.
П2.2 Синтаксис Java
// это однострочный комментарий
/* это многострочный
комментарий */
(или можно посреди строки /* кусок программки */ при отладке так вот закомментировать)
/** это особый комментарий */ для создания документации при помощи утилиты javadoc. Она кое-что понимает и создает документацию в виде HTML-страницы. Например комментарий относится к введенной следом переменной в программке. Тогда в HTML-странице будет мой комментарий и следом - та самая переменная указана. Посмотрите в Документацию Java! Полезно документацией уметь пользоваться. Ее очень много и все запомнить нереально. (и, как уже было сказано, в печатаных книгах за Sun не поспевают.. Реплика из зала: есть книжка, морально старая, но хорошо написанная - 2 тома - P.Norton "программирование на Java".
целочисленные = для хранения целых чисел
byte (8 bit) : -128 - +127
short = 2 byte : -32768 .. +32767
int = 4 byte : -... +2147483647
long = 8 byte : много-много ( 10**19 степени)
Много разных типов? Это сделано для экономии места в оперативной памяти. Если есть куча *небольших* чисел, то мне незачем отводить на них *большие* куски памяти. На использование int рассчитаны все функции. Если переполняется предусмотренная под тот или иной тип ячейка памяти - данные просто теряются. Но такие ошибки надо предусматривать и перехватывать механизмом перехвата исключительных ситуаций.
float : 4 byte : min=+/-1,4*10**-45 max=+/-3,4*10**+38
double : 8 byte : max=+/-2*10**-308 max=+/-1.7*10**+308
Символьные
char : 2 byte (чтобы туда влазила кодировка unicode - см www.unicode.org - 65 000 символов на всех языках и еще место осталось). В Win окне или в DOS-окне не сработает, но в бродилках все ОК
boolean : thrue/false (нельзя как в других языках понимать это как 0 или 1)
Что такое "простые типы" ? Это значит отвели память и никак ее не структурировали. А еще существуют сложные типы данных - объекты. Об них позднее. Теперь о них упоминаю, чтоб вас не пугало отсутствие строкового типа string. Объекты - это современно и здорово. Это нужно освоить. Это несложно и удобно... Но пока закончим разговор про простые типы.
int a; // мы сделали переменную имя а для хранения целого числа.
// в конце оператора ставят ; и пробелов, табуляций.. может
// быть много (не то что в Бейсике)
Память не только выделилась, но и заполнилась. В других языках надо инициализировать переменную - назначить ей некоторое значение, "ноль" например, иначе там будет вредный мусор. А в java переменная сама собой заполняется нулями. Вещественная переменная заполнилась бы 0,0 ; Символьная заполнится нулевым символом кодировки unicode (т.е. 0000 ), boolean - false ; (хотя лучше все же инициализировать явно, по старинке)
Вводить переменные можно в любом месте до их использования. А не только в начале.
Имена как и в других языках - состоят из букв, цифр (но с цифры имя нельзя чтоб начиналось), символа подчеркивания. (это правило полезно использовать и в именах файлов)
a = 5 ; // в объявленную ранее переменную занесли 5
Можно эти операции объединить вот так:
int a = 5 ;
Примеры для переменных других простых типов:
float c = 7.2 ;
boolean d = true ;
char e = 'M' ; // только в одинарные кавычки
Спецсимволы - как и в C - например:
\n enter=newline \t = tab \r = enter \f = newpagetoprint \b backspace
Использование числовых значений кодировки unicode:
\u0037 = это то же самое, что символ '7' (цифры десятичные)
Расшифровка символов есть на сайте Unicode и на
розданном CD есть расшифровка для русского языка.
Чтобы спецсимвол не работал как спецсимвол, ставят косую черту:
char c = '\'' ; // тут в "c" поместили символ "одиночная кавычка"
Экзотика: Можно использовать и 8 и 16-ричную форму записи, например так:
a = 0x7B // записано 16-ричное число 7B
a = 0175 // записано 8-ричное число 175
---
Какие преобразования типов данных возможны?:
int x; // 4 byte длиной
byte y; // 1 byte длиной
x=y; // более короткое число "y 1 byte длиной" положили в место
// для длинного "x 4 byte длиной"
Наоборот тоже возможно, но компилятор будет ругаться.
Еще можно явно преобразовывать типы:
y=(byte)x; // сделать из 4-байтового числа "x" 1-байтовое
Аналогичные штуки работают для вещественных чисел.
double z = 7.8; Превратим вещ. z в целое
x=(int)z; // сработает, но пропадет хвостик 0.8
А если попытаться написать x=z; то компилирование не произойдет и байт-код не получиться. Наоборот, преобразование с удлинением места в памяти не обязательно указывать во что преобразовываем. То есть при таком безопасном преобразовании можно применить неявную форму записи преобразования. То есть в примере выше можно написать z=x;
(кто не знает что такое % - это есть вычисление остатка от
целочисленного деления, например
10 % 3 -> получится 1 ,
10,2 % 3 -> тоже 1)
увеличить на число и результат положить в ту же ячейку-переменную, откуда брали. Сокращают запись:
а=а+5; то же самое что а+=5;
Аналогично пишут для - % * /
Инкремент, например а=а+1;
++а = сначала увеличиваем переменную, потом можем
воспользоваться хранящимся в ней значением.
а++ = наоборот, сначала можем воспользоваться хранящимся
в переменной значением, потом увеличиваем ее на единицу;
Пример:
int a=5, b;
b=++a; // это значит в b попала шестерка
// (сначала к 5 прибавилась 1, потом ее
// использовали для занесения в ячейку "6")
Аналогично есть "декремент"
--а или а--
(это все не сложно, нужно лишь привыкнуть и запомнить разные разности)
(результат будет булевского типа)
< > =< >= ==
!= не равно
Пример
int a = 5;
int b = 6;
boolean c
c = а == b // в "с" будет-запишется false
|| или
! не
&& и
исчерпывающие примеры
true && true = true
true && false = false
false && true = false
false && false = false
true || true = true
true || false = true
false || true = true
false || false = false
!true = false
!false = true
Зачем это нужно? Для написания всяких сложных условий типа "если переменная А меньше того-то, но больше сего-то , тогда
Прежде чем погибнуть по причине ошибки, программа создает "исключения". Это объекты - экземпляры какого-нибудь класса из подклассов java.lang.Throwable Класс Throwable содержит строку сообщения String. Много стандартных классов-наследников у Throwable.
Их (объекты-"исключения") можно перехватывать и обрабатывать, не давая совершиться чему-то страшному. Например вводим буквы вместо цифр в калькулятор. "Обработать искл.сит.", - значит понять что случилось, остановить программу и выдать сообщение, "не цифра!" например. Применяется конструкция
try{
тут кусок программы способный
привести к ошибкам
}catch(Exception e){
тут кусок программы "что делать"
когда ошибка произошла
}finally{
что делать дальше независимо от результатов обработки в catch
надеюсь далее будет пример
}
Имя "Exception" означает на самом деле ту самую искл. сит., которая произошла в классе, который мы вызвали из раздела Try{"тут кусок программы способный привести к ошибкам"}. Компилятор помнит, откуда был сделан вызов метода, далее в том же блоке try-catch приведшего к исключению, поэтому собственное имя искл.сит. не требуется, вполне годится общестандартное имя "Exception". Экземпляр класса Exception будет создан.
Исключительные ситуации можно создавать и искусственно. Для проверки неких условий. (оператор throw new "имя_Exception" <-[внутри try - catch]). Тут уже Исключ.сит. - это некий объект некоего нами названного класса (наследника класса "Exception"). И тут уже он (объект нашего класса-наследника) имеет собственное имя!
П2.3 Языковые конструкции Java
с предусловием
while (condition) {
do-some-actions; // if condition=false, ни разу действие не сделается
}
с после условием
do{
do-some-actions; // at least it'll be done once
} while (condition a verifier);
с перечислением
for (intitialisation; condition; modification){
do-some-actions;
}
Пример:
for (int i = 0; i < 7; i++){
можно на самом деле инициализировать одну переменную, а наращивать другую и проверять третью, а можно и вообще какое-то условие пропустить (но обязательно его указать пустым местом, то есть поставить соответствующую ему точку с запятой!. Как вы помните, i++ означает i=i+1
Еще можно перечислять несколько переменных в каждом разделе for оператор break можно использовать во всех этих циклах (его пишут предварив его if(условие) тогда break
Еще есть оператор continue - пропускает текущую итерацию и продолжает цикл. Пример
Пример:
for (int i=-3; i<3; i++){
if (i==0) continue; // нельзя делить на ноль
float a = 5/i; // вообще-то если в Java делить на ноль,
} // получиться спец_значение inf (некая константа
// равная самому большому числу из возможных
// вещественных чисел
Тут i живет только внутри цикла, а вот а - видна снаружи и после завершения цикла не пропадает. Пример однако глупый, потому что промежуточные значения а нигде не останутся.. но это только пример на циклы.
Все программерство стоит на условных переходах вроде такого "если условие верно, то делай это, если нет - делай то" Короче говоря "Если.. то.." Или по иностранному (все как в языке C)
if (условие) {
действие; // действие м/б одно или куча
... // если действие одно, фигурные скобки можно не писать
действие;
}
Если действие одно-единственное, фигурные скобки можно не писать.
if (проверяемое условие или логическая переменная){
действие;
...
действие;
}else{
действие;
...
действие; // вместо действия могут быть вложенные if
}
Конструкция switch - выбор значений переменной из списка вариантов
switch (value){
case value1 : do_this;
break; // срочный выход из цикла
case value2 : do_this;
case value3 : разные операторы;
default : еще операторы ;
}
Это тоже объекты. В отличие от других типов, в библиотеке явно нет стандартного класса от Sun, из которых они создаются. Но оператор new используется и все делается похоже на создание других объектов.
1) Указывается тип данных которые будут храниться в ячейках массива и в ячейках можно будет хранить данные только одного этого типа.
int a[];
int[] a;
2) выделить память и указать сколько ячеек в массиве:
a=new int[5] ;
Все ячейки пронумерованы начиная с нуля. Обращаться к каждой можно используя квадратные скобки. А что тут объектного? Вот что: у объекта "массив" есть одно-единственное свойство length - длина массива в ячейках. Ее читают соответствующим методом-функцией. Длина обозначена числом типа int (long нельзя).
Массивы только одномерные. Подобие многомерности получается путем создания массива из массивов. В ячейке массива сидит массив (причем они разномерные и более того..)
Все массивы "динамические". Значит ли это, что они могут менять свою длину в процессе работы? НЕТ! Массив после создания можно только уничтожить (длина станет null). Слово "динамический" означает, что память под массив можно выделить в любом месте программы (а не заранее!) и память только в том месте программы - на том этапе работы программы - и выделится. Удобно вообще-то: если у вас огромный массив, то память он начнет загромождать не заранее, а только когда он понадобится.
Как еще можно создавать массивы? Можно сразу ему присвоить начальное значение. Длина будет такая, сколько значений указали:
int a[] = {7, 21, 85}; // слово new тут не нужнО
Многомерные массивы :
Объявим "массив с цифрами float в ячейках"
float a[][];
Инициализируем его:
float a[][] = new float [4][2]; // матрица 4 х 2
Разномерный массив:
float a[][] = new float [4][];
Не сказано какой длины будут висеть наборы ячеек из каждой из 4-х ячеек "первого" массива (массива массивов). Это первое new не выделяет память, а только создает некие указатели. Далее нужно написать для выделения памяти :
a[0] = new float[3]; - в первую ячейку положили массив длиной "три"...
Про массивы все. Очень нехарактерно для Java то, что в классе массив есть всего один метод. Есть еще класс Вектор, там методов полно, но есть и расплата - вектор медленно работает. Обычно в классах по не одному десятку методов.
Все. Зачем все вышеназванное нужно? Все оно используется не само по себе, а внутри функций. ФУНКЦИЯ - группа операторов под общим ИМЕНЕМ. Обращаясь к ней по имени мы их все вызываем к работе. Может понятнее было бы назвать ПОДПРОГРАММОЙ. Отработав, операторы дают некий результат своей работы - его "функция" возвращает.
Чтобы вернуть результат, нужно указать заранее его тип. Итак функции пишут так:
data_type FunctionName (тип_арг1 имя_арг1, тип_арг2 имя_арг2, ... тип_аргN имя_аргN){
перечень действий-операторов, составляющих;
подпрограмму-функцию;
return(результат); // спец_оператор для возврата результата работы функции-подпрограммы
// return результат; - еще вариант записи оператора "возврат результата"
// этот оператор еще по совместительству завершает функцию (работу подпрограммы)
}
Результатов возвращаются не более одного. Бывает, что функция не должна ничего возвращать. Тогда используют специальный тип - void ;
Перед типом результата иногда пишут так наз. описание доступа (спецификатор доступа) - указывают кто может использовать данную. функцию. Об этом позже.
ПРИМЕР - некая функция для суммирования целых чисел.
int Sum(int x, int y){
return (x+y);
}
Аргументы простых типов передаются "по значению". Это значит, что внутри подпрограммы создаются копии переданных туда в качестве аргументов переменных, а сами эти переменные не изменяются. (((Если бы внутри функции использовались указатели - это было бы "по ссылке" .. На самом деле передача внутрь функции объектов производится "по ссылке" - об этом позднее. Еще раз: Объекты передаются по ссылке! (нужно внутрь некоторого объекта, в его функцию, передать посторонний объект со всеми его переменными=полями и их значениями... Передается лишь ссылка на этот объект. Внутри области нашего первого объекта НЕ выделяется память, не создается в ней копия постороннего передаваемого объекта.)))
Внутри функции-подпрограммы можно объявлять переменные - они есть "локальные". Когда функция начала работать, этим переменным отведется место в памяти компутера, но как только она перестанет работать (завершится), то эта переменная из памяти уничтожится. И вне функции она будет не видна все время работы функции.
В обычном программировании вы еще слышали "глобальную" переменную. Тут этого термина нет, но считайте что все переменные объявленные вне функции - "глобальные". Они называются на самом деле "полями" - об этом позднее!
int Sum(int x, int y){
int rez; // локальная
rez = x + y;
return (rez);
}
ПЕРЕГРУЗКА функции
Это просто. В программе можно объявить несколько функций с одинаковыми именами, различающиеся только списком аргументов. Этот список должен быть разным обязательно. Разница м/б как в количестве, так и в их типе. Очень популярный механизм. Буквально каждая функция имеет несколько однофамильцев. Например мы хотим суммировать не только целые, но и вещественные числа. А язык-то жестко типизированный. Вот и пригодится перегрузка:
float Sum(float x, float y){
return (x+y);
}
Если при вызове функции я указал вещественное, то вызовется Sum-вещественная, а если целые - Sum-цел.
float a=Sum(5, 6);
a = Sum(5,2, 6);
Пример не ахти какой, так как возможно безопасное преобразование типов... Но идея ясна. Очень это распространено, среди матем. библ. функций..
Функции не живут сами по себе в java-программировании. Они живут внутри КЛАССОВ.
П2.4. Объектно-ориентированное программирование (ООП).
Зачем нужно? Чтобы экономит силы и использовать объектный код, сочиненный другими людьми. Сама Java -программа - это некий объект. Главное понятие в ООП - понятие класса. Это структура (сложный тип данных), объединяющая переменные и функции для работы с ними.
Класс "мыша"
Mouse{
x // переменные внутри класса - "поля" или
y // "свойства"
draw() // функция внутри класса = "метод"
}
Формальное описание синтаксиса класса:
class Name {
int x, y;
тело класса;
int Sum (int a, int b){} // описание функций
float z; // в любом порядке описание переменных и функций..
// хотя для читабельности все лучше по порядку
}
Класс не похож на функцию, не возвращает никакого значения.
Тут используют описания доступа к переменным (полям то есть) класса и к его функциям (методам то есть). По умолчанию переменные и функции доступны для своего класса и всех его соседей в той же папке.
По сути класс - что это? Это сложная структура в памяти. Выделяем 4 байта для целого, 4 байта для вещественного, и описываем структуру функции для работы с ними. Но это лишь описание - реально память не выделена. Память выделяется реально - создается объект. То есть конкретный экземпляр класса. Я месяца три после процедурного программирования не мог привыкнуть к терминологии и не мог понять, зачем же это нужно! Попытаюсь вам объяснить все же побыстрее :-)
Класс "люди"
голова
руки
метод_думать (увеличивает значение голова на 1)
метод хватать (увеличивает значение рук на 1)
все
Мы все - объекты=экземпляры этого класса. Нам выделено место на земле чтобы жить, хватать и думать.
Внутри класса помимо всего прочего существует специальная функция - "конструктор" - называется функция тем же именем, что и класс (в этом примере - "люди"). Она может существовать или не существовать. Она не возвращает никакого результата и void к конструктору не надо приписывать. Она - функция-конструктор - нужна для некоторых начальных (инициализирующих) действий при создании объекта. Какие действия? Разные..
В нашем примере: конструктор присвоит головам и рукам значение "десять". Это я придумываю сам. Пусть будет так. Или пример с мышой: пусть мыша будет при инициализации располагаться в центре экрана. Кто-то должен вычислить координаты центра экрана и вызвать функцию рисования чтобы там мыша была нарисована.
Когда объект создается (человек рождается), то вызывается один-единственный раз конструктор. Если я не описал спец. конструктор, то что по умолчанию? Обычно ничего. Но если и ничего, все же по умолчанию конструктор есть. Хотя по умолчанию он ничего не совершает, ничего не возвращает, никаких аргументов не получает.
Вернемся к примеру Люди: создаем объект Миша класса Люди -
1) объявили переменную сложного типа "Люди" (так как мы писали int a;
при объявлении переменной простого типа)
Люди Миша; // никакая память не выделилась, переменной
// спец_типа Люди - нет, ее "значение" - null
// в отличие от случая простой переменной - она то
// "инициализируется" автоматически
2) выделили оперативную память для объекта Миша:
Миша=new Люди();
Теперь возник кусок выделенной памяти - конструктор там создал структуру для хранения переменных руки, голова, функций-методов.
Разница с обычным программированием: функция делается менее универсальной. Она может работать только над данными данного объекта! Нельзя заставить функцию-метод объекта взять переменную другого объекта. (можно ей передать извне эти переменные-поля как аргументы). Зато (выигрыш) все это дело увязано в одну взаимосвязанную структуру. Еще раз: даже если метод-функцию вызвать снаружи, она чужие данные не сможет взять. А как же передают данные внутрь переменных-полей объекта? Прямой записью в поле или передачей данных внутрь через функцию-метод, ему эти данные дают в качестве аргумента.
Уничтожение объектов. В отличие от Си++ в Java нет Деструктора. Я пишу
Миша = null;
Объект "Миша" не сразу убивается-освобождает память. Он просто лежит тут, ненужный Миша. А потом, в момент регулярной чистки памяти, его уберут. Java -машина чистит память регулярно.
Приложение
3
Листинг программы – SearchEngein.java
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
import java.net.*;
import java.util.*;
import java.lang.*;
// Класс Интерфейс
public class SearchEngein extends HttpServlet {
// Объявление глобальных переменных
Properties INIProperties = new Properties();
String query = null, // Запрос
value = null; // Запрос в нужной кодировке
String dbname, // Имя базы
dbpath; // Путь к базе
String dbselect; //
byte MD = 30, // Код разделителя
MD2 = 31; // Код разделителя
String RusDos = new String("Cp866"); // Кодировка дос
String RusWin = new String("windows-1251"); // Кодировка Виндовс
String iso = new String("8859_1"); // Кодировка Сервлета
String RusIso = new String("8859-5"); // Кодировка Исо
// конвертор кодировки из ИСО В Виндовс
private String ConvertISO(String Str) {
try {
Str = new String( Str.getBytes(iso),RusWin);}
catch( java.io.UnsupportedEncodingException e ) { return Str;}
return Str;
}
public String getServletInfo() {
return "Поиск в базе данных ";
}
private String RemoveTrash(String str){
return new String(str);
}
// преобразование в нижний регистр
public String toLow(String str){
char old[] = str.toCharArray();
char news[] = new char[str.length()];
char c;
for (int i =0; i<str.length(); i++){
c = old[i];
switch (c) {
case 'А' : {c = 'а';break;}
case 'Б' : {c = 'б';break;}
case 'В' : {c = 'в';break;}
case 'Г' : {c = 'г';break;}
case 'Д' : {c = 'д';break;}
case 'Е' : {c = 'е';break;}
case 'Ё' : {c = 'ё';break;}
case 'Ж' : {c = 'ж';break;}
case 'З' : {c = 'з';break;}
case 'И' : {c = 'и';break;}
case 'Й' : {c = 'й';break;}
case 'К' : {c = 'к';break;}
case 'Л' : {c = 'л';break;}
case 'М' : {c = 'м';break;}
case 'Н' : {c = 'н';break;}
case 'О' : {c = 'о';break;}
case 'П' : {c = 'п';break;}
case 'Р' : {c = 'р';break;}
case 'С' : {c = 'с';break;}
case 'Т' : {c = 'т';break;}
case 'У' : {c = 'у';break;}
case 'Ф' : {c = 'ф';break;}
case 'Х' : {c = 'х';break;}
case 'Ц' : {c = 'ц';break;}
case 'Ч' : {c = 'ч';break;}
case 'Ш' : {c = 'ш';break;}
case 'Щ' : {c = 'щ';break;}
case 'Ъ' : {c = 'ъ';break;}
case 'Ы' : {c = 'ы';break;}
case 'Ь' : {c = 'ь';break;}
case 'Э' : {c = 'э';break;}
case 'Ю' : {c = 'ю';break;}
case 'Я' : {c = 'я';break;}
default : {news[i]=c;}
}// switch
news[i] = c;
}
return new String(news);
}
//
private String TagRemove(String s){
boolean inTag = false;
boolean tag = false;
int sn = 0;
char c;
int m = s.length();
char[] cd = new char[m];
char[] old = s.toCharArray();
char cMD = (char) MD2;
for (int i=0; i<m; i++)
{c=old[i];
if (tag) { c=' '; tag = false; }
else if ( c == cMD ) { c=' '; tag = true;}
cd[i] = c;
}
return new String(cd);
}
//
public void dbFileRead(String dbNamePath, PrintStream out, String query) {
String mAvtor = null; // 100
String msAvtor = null; // 700
String mName = null; // 245
String mPrinter = null; // 260
String mSize = null; // 300
String mKey = null; // 653
String mSeria = null; // 490
String mBBK = null; // 91
String mKaIndex = null; // 90
long fPosMarker = 0, // Позиция относительно начала
fPosData = 0; //
boolean done = false,
Avtor = false;
int mC =0,
mE =0; // Счетчик
byte Jumper[] = new byte[5]; // Размер запяси - символьный
int JIndex = 0, // Размер запяси - числовой
JTemp = 0, // Размер данных + словарь
MIndex = 0, // Счетчик для массива
MTemp = 0; // Счетчик полей
if (query != null){
try { RandomAccessFile dbfile = new RandomAccessFile(dbNamePath,"r");
// Цикл чтения файла по маркерам
while (fPosMarker != dbfile.length()) {
try { mC++;
dbfile.seek(fPosMarker);
dbfile.read(Jumper);
String jBuf = new String(Jumper);
JIndex = Integer.parseInt(jBuf,10);
int b = 0;
// Поиск конца словаря
while ( b != MD){
dbfile.seek(fPosMarker+24+MIndex);
b = dbfile.read();
MTemp++;
MIndex = MTemp;
}
MTemp= MTemp - 1;
// чтение Словаря из файла в отдельный массив
byte Dic[] = new byte[MTemp];
dbfile.seek(fPosMarker+24);
dbfile.read(Dic);
// чтение полей данных из файла в массив
fPosData = fPosMarker+24+MTemp;
String sDic = new String(Dic);
byte MarcRec[] = new byte[JIndex-24-MTemp];
dbfile.seek(fPosData);
dbfile.read(MarcRec);
int DI2 = 0,
DI3 = 0,
DI4 = 0,
DI5 = 0,
PNum = 0, // Номер поля числовой
PLength = 0, // Длинна поля числовая
PStart = 0; // Начальная позиция поля чиловая
// сканирование номеров полей
while ( DI2 != MTemp){
DI3=DI2+3;
String DStr = sDic.substring(DI2,DI3);// Номер поля
DI4=DI3+5;
String DStr2 = sDic.substring(DI3,DI4);// Начальная позиция
DI5=DI4+4;
String DStr3 = sDic.substring(DI4,DI5);// Длинна поля
DI2=DI2+12;
PLength = Integer.parseInt(DStr3,10);// Узнаем длинну поля
PStart = Integer.parseInt(DStr2,10);// Узнаем начало поля
PNum = Integer.parseInt(DStr,10);// Код
byte Pole[] = new byte[PLength];
// Чтение поля из файла
for (int PIndex = 0; PIndex < PLength; PIndex++) {
Pole[PIndex] = MarcRec[PStart+PIndex];
}
String Pol = new String(Pole);
if (Pol == null) Pol=" ";
switch (PNum) {
case 100 : { mAvtor = TagRemove(Pol.substring(5));break;}
case 700 : { msAvtor = TagRemove(Pol.substring(5));break;}
case 245 : { mName = TagRemove(Pol.substring(5));break;}
case 490 : { mSeria = TagRemove(Pol.substring(5));break;}
case 91 : { mBBK = TagRemove(Pol.substring(5));break;}
case 90 : { mKaIndex = TagRemove(Pol.substring(5));break;}
case 260 : { mPrinter = TagRemove(Pol.substring(5));break;}
case 300 : { mSize = TagRemove(Pol.substring(5));break;}
case 653 : { mKey = TagRemove(Pol.substring(5));break;}
default : {}
}// switch
}// конец проверки полей
if ( mAvtor == null) mAvtor=" ";
if ( msAvtor == null) msAvtor=" ";
if ( mName == null) mName=" ";
if ( mPrinter == null) mPrinter=" ";
if ( mSize == null) mSize=" ";
if ( mKey == null) mKey=" ";
MarcRecord Rec = new MarcRecord( mAvtor,
msAvtor,
mName,
mPrinter,
mSize,
mKey,
mSeria,
mBBK,
mKaIndex);
if ( Rec.rAvtor.indexOf(query) != -1 ||
Rec.rsAvtor.indexOf(query) != -1 ||
Rec.rName.indexOf(query) != -1 ||
Rec.rKey.indexOf(query) != -1)
{ mE++;
out.println("<table width=\"461\" border=\"0\" cellpadding=\"0\" cellspacing=\"0\">"+
"<tr bgcolor=\"#3399FF\">"+
"<td colspan=\"3\" class=\"text\"> Автор: "+
"<font color=\"#000000\">"+
Rec.rAvtor+" "+
Rec.rsAvtor+
"</font></td></tr><tr>"+
"<td colspan=\"3\" valign=\"top\" class=\"bodytext\">"+mE+". "+mC+
" <b>Название:</b> "+
Rec.rName+"<br>"+
Rec.rPrinter+" "+
Rec.rSize+"<br>"+
Rec.rBBK+" "+
Rec.rKaIndex+" "+
Rec.rSeria+
"</td></tr></table>");
}
fPosMarker = fPosMarker+JIndex;
MTemp = 0;
MIndex = 0;
}
catch (IOException e) {
out.println("Ошибка!!!"+"<br>");
done=true; }
}
}
catch (IOException e) { out.println("Ошибка доступа к "+dbNamePath); }
if (mE == 0) {
out.println("Запос: "+query+" не найден");
}
} // end If
}
// Ридер файла настройки
public void INIFile(String filename, String directory, PrintStream out) {
DataInputStream inifile = null;
String path = null,
iniRecord = null,
section = null,
vname = null,
vvalue = null;
boolean done = false;
int equalIndex = 0;
//
if (filename.length() == 0) {
out.println("IOError ");
System.exit(0);
}
if (directory.length() == 0) { directory = new String("c:\\www\\db"); }
if (filename.indexOf(".") < 0) { filename = new String(filename+".ini"); }
path = new String(directory+System.getProperty("file.separator")+filename);
// открытие файла
try { inifile = new DataInputStream(new FileInputStream(path)); }
catch(FileNotFoundException e) {
out.println(filename+"not found");
System.exit(0);
}
// чтение файла
try { iniRecord = inifile.readLine(); }
catch (IOException e) { done=true; }
while (!done && iniRecord != null)
{ if (iniRecord.startsWith("["))
{ section = iniRecord.substring(1,iniRecord.lastIndexOf("]"));}
else if (!iniRecord.startsWith(";"))
{ equalIndex = iniRecord.indexOf("=");
if (equalIndex > 0)
{ //Имя ключа => Раздел.ключ
vname = new String(section+"."+iniRecord.substring(0,equalIndex));
vvalue = new String(iniRecord.substring(equalIndex+1));
INIProperties.put(vname, vvalue);
}
}
try { iniRecord = inifile.readLine(); }
catch (IOException e) { done=true; }
}
}
// извлечь значение
public String getINIVar(String key, String defValue) {
return INIProperties.getProperty(key, defValue);
}
// извлечь значение
public String getINIVar(String key) {
return INIProperties.getProperty(key);
}
public void init(ServletConfig conf) throws ServletException {
super.init(conf);
}
public void service(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException
{
PrintStream out;
out = new PrintStream(res.getOutputStream());
res.setContentType("text/html; charset=Cp866");
// Печать заголовка
printPageHeader(out);
INIFile("db.ini","c:\\www\\db",out);
// Определяем кодировку
String requestEnc = req.getCharacterEncoding();
String clientEnc = requestEnc;
if ( requestEnc==null ) requestEnc=iso;
requestEnc=iso;
// Тело
out.println("<body bgcolor=\"#FFFFFF\">");
out.println("<form method=\"get\" action=\"/serv/SearchEngein\">");
out.println(" <table width=\"461\" border=\"0\" cellpadding=\"0\" cellspacing=\"0\">");
out.println(" <tr bgcolor=\"#3399FF\"> ");
out.println(" <td width=\"266\" class=\"text\"> Запрос</td>");
out.println(" <td width=\"135\" class=\"text\"> Каталог</td> ");
out.println(" <td width=\"207\"> </td>");
out.println(" </tr>");
out.println(" <tr>");
out.println(" <td width=\"266\" valign=\"top\"> ");
out.println(" <input type=\"text\" name=\"Query\" maxlength=\"100\" size=\"38\" value=\"\">");
out.println(" </td>");
out.println(" <td width=\"135\" valign=\"top\"> ");
out.println(" <select name=\"select\" size=\"1\">");
out.println(" <option value=\"MARCFILE.Book\" selected>"+ConvertISO(getINIVar("KATALOG.Book"))+"</option>");
out.println(" <option value=\"MARCFILE.Stat\">"+ConvertISO(getINIVar("KATALOG.Stat"))+"</option>");
out.println(" <option value=\"MARCFILE.Periud\">"+ConvertISO(getINIVar("KATALOG.Periud"))+"</option>");
out.println(" <option value=\"MARCFILE.Podpis\">"+ConvertISO(getINIVar("KATALOG.Podpis"))+"</option>");
out.println(" <option value=\"MARCFILE.Ucheb\">"+ConvertISO(getINIVar("KATALOG.Ucheb"))+"</option>");
out.println(" </select>");
out.println(" </td>");
out.println(" <td width=\"207\" valign=\"top\"> ");
out.println(" <input type=\"submit\" name=\"Start\" value=\"Поиск\">");
out.println(" </td>");
out.println(" </tr>");
out.println(" </table>");
out.println(" </form>");
// Конец тела
// Взять текст из строки
query = req.getParameter("Query");
if (query == null || query.length()<1)
{
printPageFooter(out);
return;
}
dbselect = req.getParameter("select");
value = new String(ConvertISO(query));
// Чтение файла
dbFileRead(getINIVar(dbselect), out, value);
// Распечатка результата
printPageFooter(out);
query = null;
value = null;
}
// Вывод заголовка документа
private void printPageHeader(PrintStream out) {
out.println("<html>");
out.println("<head>");
out.println("<meta http-equiv=\"Content-Type\" content=\"text/html; charset=Cp866\">");
out.println("<style type=\"text/css\">");
out.println("<!--");
out.println(".text { font: bold 12px Arial, Helvetica, sans-serif; color: #0000FF; text-decoration: none; text-align: left; }");
out.println(".bodytext { font: 12px Arial, Helvetica, sans-serif; color: #000000; text-decoration: none; text-align: left; }");
out.println("-->");
out.println("</style>");
out.println("</head>");
}
private void printPageFooter(PrintStream out) {
out.println("</body>");
out.println("</html>");
out.flush();
}
}
// Класс Запясь для хранения данных считаных из запяси
class MarcRecord {
protected String rAvtor; // Поле автор
protected String rsAvtor; // Поле соавтор
protected String rName; // Поле название произведения
protected String rPrinter; // Поле издатель
protected String rSize; // Поле Объем издания
protected String rKey; // Поле ключевые слова
protected String rSeria;
protected String rBBK;
protected String rKaIndex;
MarcRecord( String r1,
String r2,
String r3,
String r4,
String r5,
String r6,
String r8,
String r11,
String r12) {
rAvtor = r1;
rsAvtor = r2;
rName = r3;
rPrinter = r4;
rSize = r5;
rKey = r6;
rSeria = r8;
rBBK = r11;
rKaIndex = r12;
}
}
Приложение 4
Результаты тестирования программы
Тестирование программы проводилось на 4 массивах данных размером 1000, 5000, 8366, 10000 записей. Метод тестирования заключался в поиске последней записи массива по уникальному названию, чтобы определить время поиска по всему массиву. Полученные данные приведены в таблице и на основе данных построен график (см. график).
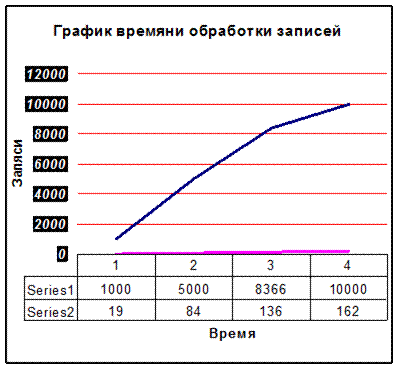
График
|
