| МОиПО
Рязанская Государственная Радиотехническая Академия
ФВТ Кафедра ЭВМ
Курсовой проект по АСВТ
На тему
“Новые технологии в организации PC”
Выполнил студент гр.742
Девяткин
Проверил
Локтюхин
Рязань, 2000
1. Типоразмеры (форм-факторы) материнских плат
На сегодняшний день существует четыре преобладающих типоразмера материнских плат – AT, ATX, LPX и NLX. Кроме того, есть уменьшенные варианты формата AT (Baby-AT), ATX (Mini-ATX, microATX) и NLX (microNLX). Более того, недавно выпущено расширение к спецификации microATX, добавляющее к этому списку новый форм-фактор – FlexATX. Все эти спецификации, определяющие форму и размеры материнских плат, а также расположение компонентов на них и особенности корпусов, и описаны ниже.
AT
Форм-фактор АТ делится на две, отличающиеся по размеру модификации - AT и Baby AT. Размер полноразмерной AT платы достигает до 12" в ширину, а это значит, что такая плата вряд ли поместится в большинство сегодняшних корпусов. Монтажу такой платы наверняка будет мешать отсек для дисководов и жестких дисков и блок питания. Кроме того, расположение компонентов платы на большом расстоянии друг от друга может вызывать некоторые проблемы при работе на больших тактовых частотах. Поэтому после материнских плат для процессора 386, такой размер уже не встречается.
Таким образом единственные материнские платы, выполненные в форм-факторе AT, доступные в широкой продаже, это платы соответствующие форматы Baby AT. Размер платы Baby AT 8.5" в ширину и 13" в длину. В принципе, некоторые производители могут уменьшать длину платы для экономии материала или по каким-то другим причинам. Для крепления платы в корпусе в плате сделаны три ряда отверстий.
Все AT платы имеют общие черты. Почти все имеют последовательные и параллельные порты, присоединяемые к материнской плате через соединительные планки. Они также имеют один разъем клавиатуры, впаянный на плату в задней части. Гнездо под процессор устанавливается на передней стороне платы. Слоты SIMM и DIMM находятся в различных местах, хотя почти всегда они расположены в верхней части материнской платы.
Сегодня этот формат плавно сходит со сцены. Часть фирм еще выпускает некоторые свои модели в двух вариантах – Baby AT и ATX, но это происходит все реже и реже. Тем более, что все больше новых возможностей, предоставляемых операционными системами, реализуются только на ATX материнских платах. Не говоря уже просто об удобстве работы – так, чаще всего на Baby AT платах все коннекторы собраны в одном месте, в результате чего либо кабели от коммуникационных портов тянутся практически через всю материнскую плату к задней части корпуса, либо от портов IDE и FDD – к передней. Гнезда для модулей памяти, заезжающие чуть ли не под блок питания. При ограниченности свободы действий внутри весьма небольшого пространства MiniTower, это, мягко говоря, неудобно. Вдобавок, неудачно решен вопрос с охлаждением – воздух не поступает напрямую к самой нуждающейся в охлаждении части системы – процессору.
Реклама

LPX
Еще до появления ATX, первым результатом попыток снизить стоимость PC стал форм-фактор LPX. Предназначался для использования в корпусах Slimline или Low-profile. Задача была решена путем новаторского предложения - введения стойки. Вместо того, чтобы вставлять карты расширения непосредственно в материнскую плату, в этом варианте они помешаются в подключаемую к плате вертикальную стойку, параллельно материнской плате. Это позволило заметно уменьшить высоту корпуса, поскольку обычно именно высота карт расширения влияет на этот параметр. Расплатой за компактность стало максимальное количество подключаемых карт - 2-3 штуки. Еще одно нововведение, начавшее широко применяться именно на платах LPX - это интегрированный на материнскую плату видеочип. Размер корпуса для LPX оставляет 9 х 13'', для Mini LPX - 8 x 10''.
После появления NLX, LPX начал вытесняться этим форм-фактором.
ATX
Неудивительно, что форм-фактор ATX во всех его модификациях становится все более популярным. В особенности это касается плат для процессоров на шине P6. Так, к примеру, из готовящихся к выпуску в этом году материнских плат LuckyStar для этих процессоров 4 будут исполнены в формате Mini-ATX, 3 – ATX, и всего лишь одна – Baby AT. А если еще учесть, что материнских плат для Socket7 сегодня делается гораздо меньше, хотя бы по причине куда меньшего числа новых чипсетов для этой платформы, то ATX одерживает убедительную победу. И никто не может сказать, что она необоснованна. Спецификация ATX, предложенная Intel еще в 1995 году, нацелена как раз на исправление всех тех недостатков, что выявились со временем у форм-фактора AT. А решение, по сути, было очень простым – повернуть Baby AT плату на 90 градусов, и внести соответствующие поправки в конструкцию. К тому моменту у Intel уже был опыт работы в этой области – форм-фактор LPX. В ATX как раз воплотились лучшие стороны и Baby AT и LPX: от Baby AT была взята расширяемость, а от LPX – высокая интеграция компонентов. Вот что получилось в результате:
Реклама

· Интегрированные разъемы портов ввода-вывода. На всех современных платах коннекторы портов ввода-вывода присутствуют на плате, поэтому вполне естественным выглядит решение расположить на ней и их разъемы, что приводит к довольно значительному снижению количества соединительных проводов внутри корпуса. К тому же, заодно среди традиционных параллельного и последовательного портов, разъема для клавиатуры, нашлось место и для портов PS/2 и USB. Кроме всего, в результате несколько снизилась стоимость материнской платы, за счет уменьшения кабелей в комплекте.
· Значительно увеличившееся удобство доступа к модулям памяти. В результате всех изменений гнезда для модулей памяти переехали дальше от слотов для материнских плат, от процессора и блока питания. В результате наращивание памяти стало в любом случае минутным делом, тогда как на Baby AT материнских платах порой приходится браться за отвертку.
· Уменьшенное расстояние между платой и дисками. Разъемы контроллеров IDE и FDD переместились практически вплотную к подсоединяемым к ним устройствам. Это позволяет сократить длину используемых кабелей, тем самым повысив надежность системы.
· Разнесение процессора и слотов для плат расширения. Гнездо процессора перемещено с передней части платы на заднюю, рядом с блоком питания. Это позволяет устанавливать в слоты расширения полноразмерные платы - процессор им не мешает. К тому же, решилась проблема с охлаждением - теперь воздух, засасываемый блоком питания, обдувает непосредственно процессор.
· Улучшено взаимодействие с блоком питания. Теперь используется один 20-контактный разъем, вместо двух, как на AT платах. Кроме того добавлена возможность управления материнской платой блоком питания – включение в нужное время или по наступлению определенного события, возможность включения с клавиатуры, отключение операционной системой, и т.д.
· Напряжение 3.3 В. Теперь напряжение питания 3.3 В, весьма широко используемое современными компонентами системы, (взять хотя бы карты PCI!) поступает из блока питания. В AT-платах для его получения использовался стабилизатор, установленный на материнской плате. В ATX-платах необходимость в нем отпадает.
Конкретный размер материнских плат описан в спецификации во многом исходя из удобства разработчиков – из стандартной пластины (24 х 18’’) получается либо две платы ATX (12 x 9.6’’), либо четыре – Mini-ATX (11.2 х 8.2’’). Кстати, учитывалась и совместимость со старыми корпусами - максимальная ширина ATX платы, 12’’, практически идентична длине плат AT, чтобы была возможность без особых усилий использовать ATX плату в AT корпусе. Однако, сегодня это больше относится к области чистой теории – AT корпус еще надо умудриться найти. Также, по мере возможности крепежные отверстия в плате ATX полностью соответствуют форматам AT и Baby AT.
microATX
Форм-фактор ATX разрабатывался еще в пору расцвета Socket 7 систем, и многое в нем сегодня несколько не соответствует времени. Например, типичная комбинация слотов, из расчета на которую составлялась спецификация, выглядела как 3 ISA/3 PCI/1 смежный. Несколько неактуально не сегодняшний день, не так ли? ISA, отсутствие AGP, AMR, и т.д. Опять же, в любом случае, 7 слотов не используются в 99 процентах случаев, особенно сегодня, с такими чипсетами как MVP4, SiS 620, i810, и прочими готовящимися к выпуску подобными продуктами. В общем, для дешевых PC ATX – пустая трата ресурсов. Исходя из подобных соображений в декабре 1997 года и была представлена спецификация формата microATX, модификация ATX платы, рассчитанная на 4 слота для плат расширения.
По сути, изменения, по сравнению с ATX, оказались минимальными. До 9.6 x 9.6’’ уменьшился размер платы, так что она стала полностью квадратной, уменьшился размер блока питания. Блок разъемов ввода/вывода остался неизменным, так что microATX плата может быть с минимальными доработками использована в ATX 2.01 корпусе.
NLX

Со временем, спецификация LPX, подобно Baby AT, перестала удовлетворять требованиям времени. Выходили новые процессоры, появлялись новые технологии. И она уже не была в состоянии обеспечивать приемлемые пространственные и тепловые условия для новых низкопрофильных систем. В результате, подобно тому, как на смену Baby AT пришел ATX, так же в 1997 году, как развитие идеи LPX, учитывающее появление новых технологий, появилась спецификация форм-фактора NLX. Формата, нацеленного на применение в низкопрофильных корпусах. При ее создании брались во внимание как технические факторы (например, появление AGP и модулей DIMM, интеграция аудио/видео компонентов на материнской плате), так и необходимость обеспечить большее удобство в обслуживании. Так, для сборки/разборки многих систем на базе этого форм-фактора отвертка не требуется вообще.
основные черты материнской платы NLX, это:
· Стойка для карт расширения, находящаяся на правом краю платы. Причем материнская плата свободно отсоединяется от стойки и выдвигается из корпуса, например, для замены процессора или памяти.
· Процессор, расположенный в левом переднем углу платы, прямо напротив вентилятора.
· Вообще, группировка высоких компонентов, вроде процессора и памяти, в левом конце платы, чтобы позволить размещение на стойке полноразмерных карт расширения.
· Нахождение на заднем конце платы блоков разъемов ввода/вывода одинарной (в области плат расширения) и двойной высоты, для размещения максимального количества коннекторов.
Вообще, стойка – очень интересная вещь. Фактически, это одна материнская плата, разделенная на две части – часть, где находятся собственно системные компоненты, и подсоединенная к ней через 340 контактный разъем под углом в 90 градусов часть, где находятся всевозможные компоненты ввода/вывода – карты расширения, коннекторы портов, накопителей данных, куда подключается питание. Таким образом, во первых повышается удобство обслуживания - нет необходимости получать доступ к ненужным в данный момент компонентам. Во вторых, производители в результате имеют большую гибкость – делается одна модель основной платы, и стойка под каждого конкретного заказчика, с интеграцией на ней необходимых компонентов.
Вообще, вам это описание ничего не напоминает? Стойка, крепящаяся на материнскую плату, на которую выносятся некие компоненты ввода/вывода, вместо того, чтобы быть интегрированными на материнскую плату, и все это служит для упрощения обслуживания, придания большей гибкости производителям, и т.д.? Правильно, через некоторое время после выхода спецификации NLX появилась спецификация AMR, описывающая подобную же идеологию для ATX плат.
В отличие от довольно строгих прочих спецификаций, NLX обеспечивает производителям куда большую свободу в принятии решений. Размеры материнской платы NLX колеблются от 8 х 10’’ до 9 х 13.6’’. NLX корпус должен уметь управляться как с этими двумя форматами, так и со всеми промежуточными. Обычно платы, вписывающиеся в минимальные размеры, обозначаются как Mini NLX. Стоит также упомянуть небезынтересную подробность: у NLX корпуса порты USB располагаются на передней панели – очень удобно для идентификационных решений типа e.Token.
Осталось только добавить, что по спецификации некоторые места на плате обязаны оставаться свободными, обеспечивая возможности для расширения функций, которые появятся в будущих версиях спецификации. Например, для создания на базе форм-фактора NLX материнских плат для серверов и рабочих станций.
WTX
Рисунок1 Рисунок 2
Однако, с другого стороны, мощные рабочие станции и серверы спецификации AT и ATX тоже не вполне устраивают. Там свои проблемы, где стоимость играет не самую главную роль. На передний план выходят обеспечение нормального охлаждения, размещение больших объемов памяти, удобная поддержка многопроцессорных конфигураций, большая мощность блока питания, размещение большего количество портов контроллеров накопителей данных и портов ввода/вывода. Так в 1998 году родилась спецификация WTX. Ориентированная на поддержку двухпроцессорных материнских плат любых конфигураций, поддержку сегодняшних и завтрашних технологий видеокарт и памяти.
Особое внимание, пожалуй, стоит уделить двум новым компонентам - Board Adapter Plate (BAP)и Flex Slot.
В этой спецификации разработчики попытались отойти от привычной модели, когда материнская плата крепится к корпусу посредством расположенных в определенных местах крепежных отверстий. Здесь она крепится к BAP, причем способ крепления оставлен на совести производителя платы, а стандартный BAP крепится к корпусу.
Помимо обычных вещей, вроде размеров платы (14 х 16.75''), характеристик блока питания (до 850 Вт), и т.д., спецификация WTX описывает архитектуру Flex Slot - в каком-то смысле, AMR для рабочих станций. Flex Slot предназначен для улучшения удобства обслуживания, придания дополнительной гибкости разработчикам, сокращению выхода материнской платы на рынок. Выглядит Flex Slot карта примерно так: рис. 2
На подобных картах могут размещаться любые PCI, SCSI или IEEE 1394 контроллеры, звук, сетевой интерфейс, параллельные и последовательные порты, USB, средства для контроля за состоянием системы.
Образцы WTX плат должны появиться в районе июня, а серийные образцы - в третьем квартале 1999 года.
FlexATX
И наконец, подобно тому, как из идей, заложенных в Baby AT и LPX появился ATX, так же развитием спецификаций microATX и NPX стало появление форм-фактора FlexATX. Это даже не отдельная спецификация, а всего лишь дополнение к спецификации microATX. Глядя на успех iMac, в котором, по сути, ничего нового кроме внешнего вида и не было, производители PC решили также пойти по этому пути. И первым стал как раз Intel, в феврале на Intel Developer Forum объявивший FlexATX – материнскую плату, по площади процентов на 25-30 меньшую, чем microATX.
Теоретически, с некоторыми доработками, FlexATX плата может быть использована в корпусах, соответствующих спецификациям ATX 2.03 или microATX 1.0. Но для сегодняшних корпусов плат хватает и без этого, речь шла как раз о вычурных пластиковых конструкциях, где и нужна такая компактность. Там, на IDF, Intel и продемонстрировал несколько возможных вариантов подобных корпусов. Фантазия дизайнеров разгулялась на славу – вазы, пирамиды, деревья, спирали, каких только не было предложено. Несколько оборотов из спецификации, чтобы углубить впечатление: «эстетическое значение», «большее удовлетворение от владения системой». Неплохо для описания форм-фактора материнской платы PC?
Flex – на то он и flex. Спецификация чрезвычайна гибка, и оставляет на усмотрение производителя множество вещей, которые прежде строго описывались. Так, производитель сам будет определять размер и размещение блока питания, конструкцию карты ввода/вывода, переход на новые процессорные технологии методы достижения низкопрофильного дизайна. Практически, более-менее четко определены только габариты – 9 х 7.5''. Кстати, по поводу новых процессорных технологий – Intel на IDF демонстрировал систему на FlexATX плате с Pentium III, который вплоть до осени пока заявлен только как Slot-1, в спецификации подчеркивается, что FlexATX платы только для Socket процессоров...
2. Шина AGP (Accelerated Graphic Port)
Появление разных там 3D ускорителей привело к тому, что ребром встал вопрос: что делать? Либо увеличивать количество дорогой памяти непосредственно на видеокарте, либо хранить часть информации в дешевой системной памяти, но при этом каким-нибудь образом организовать к ней быстрый доступ.
Как это практически всегда бывает в компьютерной индустрии, вопрос решен не был. Казалось бы, вот вам простейшее решение: переходите на 66-мегагерцовую 64-разрядную шину PCI с огромной пропускной способностью, так нет же. Intel на базе того же стандарта PCI R2.1 разрабатывает новую шину - AGP (R1.0, затем 2.0), которая отличается от своего "родителя" в следующем:
1. шина способна передавать два блока данных за один 66 MHz цикл (AGP 2x);
2. устранена мультиплексированность линий адреса и данных (напомню, что в PCI для удешевления конструкции адрес и данные передавались по одним и тем же линиям);
3. дальнейшая конвейеризация операций чтения/записи, по мнению разработчиков, позволяет устранить влияние задержек в модулях памяти на скорость выполнения этих операций.
В результате пропускная способность шины была оценена в 500 МВ/сек, и предназначалась она для того, чтобы видеокарты хранили текстуры в системной памяти, соответственно имели меньше памяти на плате, и, соответственно, дешевели.
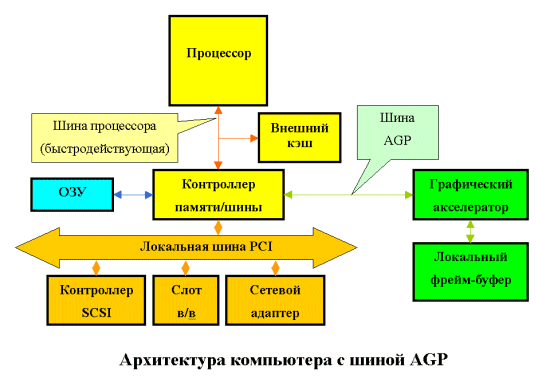
Парадокс в том, что видеокарты все-таки предпочитают иметь БОЛЬШЕ памяти, и ПОЧТИ НИКТО не хранит текстуры в системной памяти, поскольку текстур такого объема пока (подчеркиваю - пока) практически нет. При этом в силу удешевления памяти вообще, карты особенно и не дорожают. Однако практически все считают, что будущее - за AGP, а бурное развитие мультимедиа-приложений (в особенности - игр) может скоро привести к тому, что текстуры перестанут влезать и в системную память. Поэтому имеет смысл, особо не вдаваясь в технические подробности, рассказать, как же это все работает.
Итак, начнем с начала, то есть с AGP 1.0. Шина имеет два основных режима работы: Execute и DMA. В режиме DMA основной памятью является память карты. Текстуры хранятся в системной памяти, но перед использованием (тот самый execute) копируются в локальную память карты. Таким образом, AGP действует в качестве "тыловой структуры", обеспечивающей своевременную "доставку патронов" (текстур) на передний край (в локальную память). Обмен ведется большими последовательными пакетами.
В режиме Execute локальная и системная память для видеокарты логически равноправны. Текстуры не копируются в локальную память, а выбираются непосредственно из системной. Таким образом, приходится выбирать из памяти относительно малые случайно расположенные куски. Поскольку системная память выделяется динамически, блоками по 4К, в этом режиме для обеспечения приемлемого быстродействия необходимо предусмотреть механизм, отображающий последовательные адреса на реальные адреса 4-х килобайтных блоков в системной памяти. Эта нелегкая задача выполняется с использованием специальной таблицы (Graphic Address Re-mapping Table или GART), расположенной в памяти.
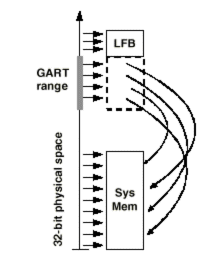
При этом адреса, не попадающие в диапазон GART (GART range), не изменяются и непосредственно отображаются на системную память или область памяти устройства (device specific range). На рисунке в качестве такой области показан локальный фрейм-буфер карты (Local Frame Buffer или LFB). Точный вид и функционирование GART не определены и зависят от управляющей логики карты.
Шина AGP полностью поддерживает операции шины PCI, поэтому AGP-траффик может представлять из себя смесь чередующихся AGP и PCI операций чтения/записи. Операции шины AGP являются раздельными (split). Это означает, что запрос на проведение операции отделен от собственно пересылки данных.
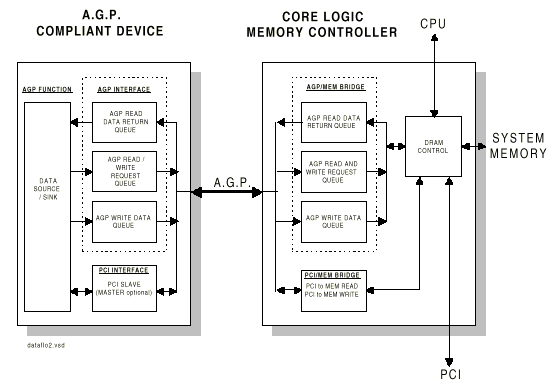
Такой подход позволяет AGP-устройству генерировать очередь запросов, не дожидаясь завершения текущей операции, что также повышает быстродействие шины.
В 1998 году спецификация шины AGP получила дальнейшее развитие - вышел Revision 2.0. В результате использования новых низковольтных электрических спецификаций появилась возможность осуществлять 4 транзакции (пересылки блока данных) за один 66-мегагерцовый такт (AGP 4x), что означает пропускную способность шины в 1GB/сек! Единственное, чего не хватает для полного счастья, так это чтобы устройство могло динамически переключаться между режимами 1х, 2х и 4х, но с другой стороны, это никому и не нужно.
Однако потребности и запросы в области обработки видеосигналов все возрастают, и Intel готовит новую спецификацию - AGP Pro (в настоящее время доступен Revision 0.9) - направленную на удовлетворение потребностей высокопроизводительных графических станций. Новый стандарт не видоизменяет шину AGP. Основное направление - увеличение энергоснабжения графических карт. С этой целью в разъем AGP Pro добавлены новые линии питания.
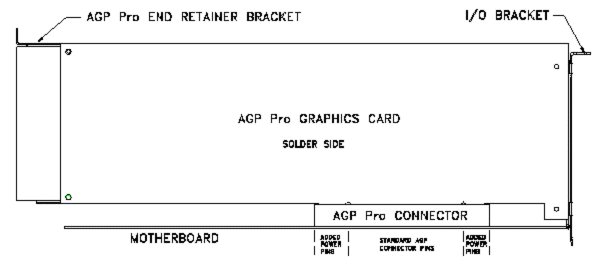
Предполагается, что будет существовать два типа карт AGP Pro - High Power и Low Power. Карты High Power могут потреблять от 50 до 110W. Естественно, такие карты нуждаются в хорошем охлаждении. С этой целью спецификация требует наличия двух свободных слотов PCI с component side (стороны, на которой размещены основные чипы) карты.
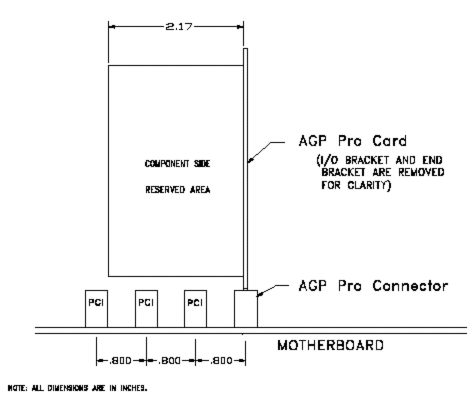
При этом данные слоты могут использоваться картой как дополнительные крепления, для подвода дополнительного питания и даже для обмена по шине PCI! При этом на использование этих слотов накладываются лишь незначительные ограничения.
При использовании слотов для подвода дополнительного питания:
· Не использовать для питания линии V I/O;
· Не устанавливать линию M66EN (контакт 49В) в GND (что вполне естественно, так как это переводит шину PCI в режим 33 MHz).
При использовании слота для обмена по шине:
· Подсистема PCI I/O должна разрабатываться под напряжение 3.3V c возможностью функционирования при 5 V.
Поддержка 64-разрядного или 66 MHz режимов не требуется.
Карты Low Power могут потреблять 25-50W, поэтому для обеспечения охлаждения спецификация требует наличия одного свободного слота PCI.
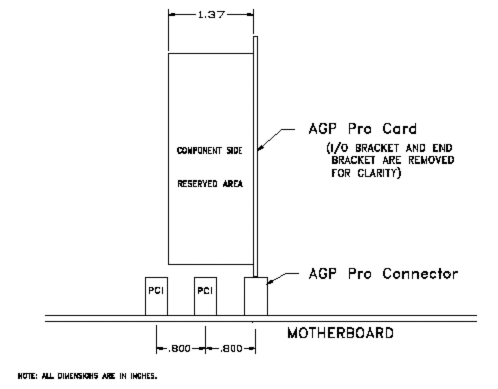
При этом все retail-карты AGP Pro должны иметь специальную накладку шириной соответственно в 3 или 2 слота, при этом карта приобретает вид достаточно устрашающий.
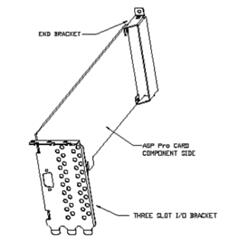
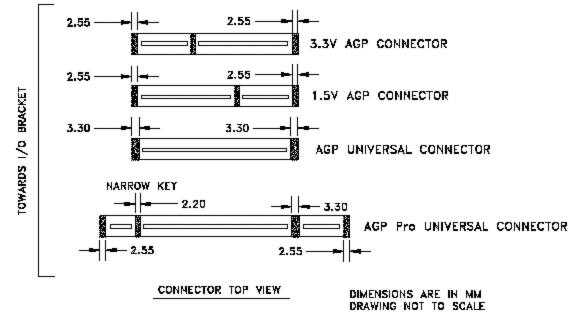
При этом в разъем AGP Pro можно устанавливать и карты AGP.
3. Registered DIMM SDRAM
Я думаю, что все знают, что модули оперативной памяти обычного компьютера вставлена в разьёмы SIMM или DIMM. Есть также ещё пока мало распространённые RIMM, ну а про RDIMM совсем мало, что слышно.
Для начала надо сказать, что разработчиком памяти стандарта RDIMM являются IBM и Intel. Модули памяти для RDIMM SDRAM поддерживаются чипсетом BX, соответсвуют спецификации PC-100 и являются усовершенствованными, а точнее Регистровыми (Registered) DIMM SDRAM . Основное отличие RDIMM от обычных DIMM SDRAM заключается в пропускной способности (bandwith): 800 и 1600 Мбайт/сек (последняя цифра особенно нравится, так как первой уже наступают на пятки мощные 3D-приложения) и называются соответсвенно SDR (Single Data Rate) и DDR (Dual Data Rate) RDIMM SDRAM. Не путать DDR SDRAM с DR DRAM (отличается работой на чаcтототе до 800 MHz, выйдет во 2 квартале и будет дороже за счёт обязательного лицензирования).
Итак, IBM анонсировала модули такой памяти обьёмом 256 Мбайт, сделанной по технологии 0.20 мкм и имеющие плотность чипов в 4 раза больше, чем у обычных, что сделало возможным создание буферизированного 256 Мбайтного модуля памяти. Кстати, по заявлению той же IBM нет никаких преград для увеличения плотности записи в 8 раз выше обычной, а значит, есть теоритическая возможность создания буферизированных 512 Мбайтных модулей.
Теперь рассмотрим архитектуру DDR RDIMM SDRAM на примере 64 Мбайтных модулей. Для осуществления эффективного ввода/вывода данных устанавливаются конденсаторы (рядом с каждым чипом). Эти конденсаторы сделаны из новейших диэллектрических материалов. Сама IBM уже применяет модули RDIMM 64-256 Мбайт, а также небуферизированные модули обьемом 512 Мбайт в своих Hi-End системах серии Netfiniti.
| <TBODY>
|
SDR RDIMM
|
DDR RDIMM
|
| Время прерывания (циклов) (Burst length )
|
2, 4, 8
|
2, 4, 8
|
| Тип прерывания (Burst type)
|
Последовательное чередование (sequential interleave)
|
последовательное чередование (sequential interleave)
|
| Число тактов для работы с памятью (CAS latency)
|
2, 3, 4
|
2, 2.5, 3
|
| Режим работы
|
Нормальный, Режим записи (single write), Режим тестирования (test mode)
|
Нормальный, Режим сброса операций DLL, Режим тестирования (test mode), Режим расширенного регистрирования (Extended register mode set), Включение/выключение операций DLL</TBODY>
|
Из таблицы мы видим, что SDR является упрощенным вариантом DDR RDIMM SDRAM. Особенности DDR заключаются в следующем:
· Работа на частоте 125, 133 и 143 MHz за 2, 2,5 и 3 такта (CAS latency = 3), в зависимости от разновидности модулей
· Однотактовое формирование сигнала RAS (Signal-pulsed RAS interface)
· Встроенный блок DLL (Delay Locked Loop), который синхронизирует вывод информации с частотой ее ввода
· Возможность отключения блока DLL через функцию расширенного режима регистрирования (например для экономии питания)
· Удвоенная скорость обмена данных (DDR)
· Двунаправленный поток данных
· Полная синхронизация
· Программируемый тип и длина прерываний
· Прерывание операций чтения (специальной командой прерывания) и записи. Смена операций осуществляется последовательно
· Четыре банка (Bank) памяти
· Способность работы при пониженном потреблении питания
· Операции чтения и записи выполняются за 4 и 8 циклов (соответственно), операция контроля затрачивает удвоенное количество циклов на соответствующую операцию
· Произвольный доступ к столбцам (в памяти)
· Ждущий режим и режим пониженного питания
· 4096/8192 циклов обновления для 64 и 256 мб модулей
· Автоматические, контролируемые команды дозарядки (Automatic and controlled precharge command). Энергия, подаваемая на модуль памяти может быть неодинаковой.
· Вольтаж: 3,3В
Данный набор характеристик не является окончательным перечнем характеристик DDR SDRAM для RDIMM, а потому может быть модифицирован в будущих стандартных DDR SDRAM, однако благодаря таким нововведения получаем: проускная способность на пин составляет 200 Мбайт (200Мбайт/пин).
4. Новые технологии памяти: DDR SDRAM
Уже давно, еще со времен 486 процессоров, отставание скорости системной шины PC от скорости убыстряющихся CPU все более увеличивалось. Именно тогда Intel впервые отказался от частоты процессоров, синхронной с частотой системной шины, и применил технологию умножения частоты FSB. Этот факт отразился даже в названии - 486DX2. Хотя частота системной шины осталась той же, несмотря на название, производительность процессора выросла почти вдвое.
В дальнейшем разброд в тактовой частоте различных системных компонентов только увеличивался: в то время, как частота системной шины выросла сначала до 66 МГц, а затем и до 100, шина PCI осталась все на тех же давних 33 МГц, для AGP стандартной является 66 МГц и т.д. Шина памяти же до самого последнего времени оставалась синхронной с системной шиной (название обязывает - Synchronous DRAM, SDRAM). - Так появились спецификации PC66, затем PC100, потом, с несколько большими организационными усилиями, PC133 SDRAM.
Однако за то время, за которое частота шины памяти увеличилась на треть и, соответственно, на столько же возросла ее пропускная способность (с 800 Мбайт/с до 1,064 Мбайт/с), частота процессоров увеличилась в два с половиной раза - с 400 МГц до 1 ГГц. Наблюдается некоторый дисбаланс, не так ли? Пропускная способность PC133 SDRAM составляет лишь 1,064 Мбайт/с, тогда как сегодняшним PC требуется по крайней мере: 1 Гбайт/с для процессора с частотой системной шины 133 МГц, столько же - для графической шины AGP 4X, 132 Мбайт/с для 33 МГц шины PCI. То есть, около 2.1 Гбайт/с - как и говорилось только что, дисбаланс более чем в два раза.
Однако дальнейшее увеличение частоты SDRAM при современном техническом уровне оснащения ее производителей невозможно: уже 166 МГц SDRAM получается слишком дорогой, особенно с учетом сегодняшних объемов оперативной памяти в PC. Этот момент сыграл не слишком приятную шутку с Direct Rambus DRAM. В то же время отказываться от синхронизации шины памяти с системной шиной по ряду причин не хотелось бы.
Технологии, пытающиеся залатать SDRAM путем добавления кэша SRAM, вроде ESDRAM, или же путем оптимизации ее работы, вроде VCM SDRAM, не помогли. На выручку пришла популярная в последнее время в компонентах PC технология передачи данных одновременно по двум фронтам сигнала, когда за один такт передаются сразу два пакета данных. В случае с используемой сегодня 64-бит шиной - это два 8-байтных пакета, 16 байт за такт. Или, в случае с той же 133 МГц шиной, уже не 1,064, а 2,128 Мбайт/с. Те самые 2.1 Гбайт/с, что и требуются для сегодняшних PC.
Причем по цене, мало отличающейся от обычной 133 МГц памяти: технология та же (включая методику упаковки чипов - TSOP, не microBGA, как у RDRAM), оборудование - то же, энергопотребление, практически не отличающееся от SDRAM, площадь чипа отличается лишь на несколько процентов. Именно это сочетание доступности с требующейся на сегодняшний день производительностью и заинтересовало в первую очередь прагматичную индустрию DRAM - точно так же в свое время они выбирали PC66, PC100, PC133…
Однако в отличие от этих спецификаций, в название которых входила тактовая частота шины памяти, так же, как и в отличие от спецификации Direct Rambus DRAM, где за основу берется результирующая частота (тактовая частота, помноженная на те же два пакета на такт, что и у DDR SDRAM) - PC600, PC700, PC800, компании, разрабатывавшие DDR SDRAM, а точнее, маркетинговые отделы этих компаний, избрали ту систему (помните мультфильм про относительность единиц измерения - 48 попугаев?), которая позволила получить максимальную цифру в названии - они выбрали пиковую пропускную способность и получили PC1600 для 100 МГц и PC2100 для 133 МГц чипов DDR SDRAM.
Впрочем, эта система названий придумана совсем недавно, хотя чипы DDR SDRAM производятся уже достаточно давно: образцы 64 Мбит чипов появились почти два года назад - в середине 1998 г. Именно к тому времени, в декабре 1998 г., когда Intel уже продолжительное время поддерживал RDRAM, одобрена открытая спецификация DDR SDRAM, не требующая от производителей, использующих ее, никаких лицензионных отчислений. Как и в случае с PC133 SDRAM, основными сторонниками новой спецификации выступили IBM и VIA, к тому времени четко ориентировавшиеся на альтернативные RDRAM архитектуры. Несколькими месяцами спустя, в мае, одобрена спецификация 184-контактных модулей DIMM, а также закончена работа над спецификацией DDR SGRAM.
Примерно через полтора года DDR SDRAM доведен до стадии, когда производители DRAM в состоянии начать его коммерческое производство -появились уже образцы 133 МГц 64 Мбит чипов DDR SDRAM, соответствующие спецификации PC2100 и готовые к началу производства. Однако первыми чипы DDR использовали отнюдь не производители модулей памяти. Производителям видеокарт проще - на карте они в праве применять что угодно, лишь бы на выходе был стандартный сигнал. Да и ширина шины памяти все же всегда была узким местом скорее для графических чипов, чем для центральных процессоров. Так что, производители видеокарт гораздо раньше воспользовались появившейся в графических чипах поддержкой DDR SDRAM/SGRAM.- Уже через несколько месяцев после выхода первого такого чипа, GeForce 256, появились карты с DDR SDRAM и SGRAM чипами на борту.
Стандартной скоростью чипов для первой волны DDR плат стали 150 и 166 МГц (результирующая частота - 300 и 333 МГц соответственно, пропускная способность шины, с учетом 128-бит разрядности - 4.8 и 5.2 Гбайт/с). Можно с большой уверенностью предположить, что осеннее поколение графических чипов будет ориентироваться на 183 МГц чипы (366 МГц, 6 Гбайт/с), а в 2001 г. мы увидим массовый выход видеокарт с 200 МГц (400 МГц, 6.4 Гбайт/с).
Результат замены SDRAM/SGRAM на их вдвое более быстрый аналог не замедлил сказаться. Производительность карт на системах с мощным центральным процессором при использовании приложений, оказывающих заметную нагрузку именно на шину памяти (например 32-бит цвет), возрастает до полутора раз.
Оценивая известную на сегодня информацию о планах разработчиков графических чипов на ближайший год, можно констатировать бесспорную победу DDR над RDRAM. После того как Intel со своим i740 успешно продвинул AGP и отказался от дальнейших попыток прямого влияния в этой области, ситуацией, к счастью, управляет рынок. Дорогой RDRAM оказался никому не нужен, тем более что 128-бит шина памяти выводит DDR SDRAM по производительности даже вперед двухканального RDRAM.
А вот с модулями памяти DIMM DDR SDRAM положение несколько иное: их востребовать некому - весь вопрос встал за чипсетами, обладающими поддержкой этого типа памяти и, соответственно, за материнскими платами на базе этих чипсетов. Первый пользовательский чипсет, обладающий поддержкой этого типа памяти, ожидался от VIA сначала осенью 99 г., затем зимой 2000, весной… Но вроде бы, наконец, ожидание подходит к концу. Уже во втором квартале должен выйти первый чипсет VIA, обладающий поддержкой DDR SDRAM - Apollo Pro266.
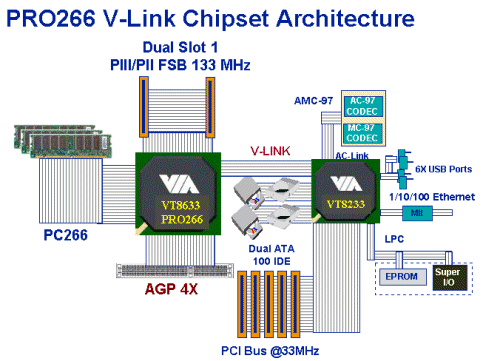
Ко все той же 133 МГц системной шине и AGP 4X добавится поддержка DDR SDRAM, а также V-Link - новой, ускоренной шины обмена информацией между северным и южным мостами чипсета, обеспечивающей пропускную способность 266 Мбайт/с (в два раза быстрее стандартной PCI). Кроме того, ожидается, что поддержка двухпроцессорных конфигураций, встроенная еще в Apollo Pro133A, станет официальной.
Чуть позже, в третьем квартале, ожидается выход варианта Apollo Pro266 с интегрированным видеоядром PM266. Причем, в отличие от PM133 с хиленьким по меркам третьего квартала Savage4, в этот чипсет будет встроен вариант Savage2000 (GX4C). Его производительности для дешевых систем, являющихся нишевым рынком для интегрированных чипсетов, должно быть более чем достаточно.
И в последнем квартале 2000 г. должен выйти первый серверный чипсет VIA, PX266V. Пока о нем известно мало, за исключением того, что там ожидается поддержка до 4 процессоров и двойная шина V-Link: к южному мосту и к подсистеме 64-бит 66 МГц PCI.
На вторую половину этого года запланирован выход и DDR чипсета для Athlon - KX266, по своим возможностям аналогичного своему собрату для Pentium III - Apollo Pro266. Но на всякий случай, AMD предпочла вновь подстраховаться, выпустив в третьем квартале свой чипсет с поддержкой DDR SDRAM - AMD 760. Ожидается поддержка новой частоты системной шины EV6 - 133 МГц (266 МГц), естественно, 133 МГц PC2100 DDR SDRAM, ATA100. Вскоре после AMD 760 должен последовать мультипроцессорный AMD 770 с аналогичными параметрами.
Если уж зашла речь о мультипроцессорных чипсетах, рассчитанных на серверные платформы, то нельзя не упомянуть еще двух игроков на этом рынке: Samsung со своим Caspian, разрабатываемым совместно с AMD, и ServerWorks со своей линейкой ServerSet, которая должна обзавестись DDR SDRAM чипсетом для процессоров Intel уже в первой половине этого года.
Учитывая такие факторы как стоимость RDRAM, разницу в производительности RDRAM и DDR SDRAM и падение производительности подсистемы памяти RDRAM при увеличении объема памяти, подавляющее большинство производителей серверов намеревается предпочесть DDR SDRAM перед RDRAM. С этим желанием вынужден считаться даже Intel, который в своем следующем серверных чипсете под x86 (i870) планирует поддерживать именно DDR SDRAM. Да и помимо Intel на рынке серверных чипсетов будет достаточно желающих поддержать DDR - кроме независимых разработчиков, на этом рынке выступят и сами производители серверов, разрабатывающие чипсеты под свои системы - IBM, NEC…
Кварталом позже выхода соответствующих чипсетов, ожидаются материнские платы на них. Так что первые платы, позволяющие использовать модули DDR SDRAM, должны выйти уже в третьем квартале 2000 г. И именно эти временные рамки указаны в планах различных производителей материнских плат. Первым и единственным неудобством для их пользователей должен стать новый форм-фактор модулей DIMM.
К сожалению, ничто на свете не дается даром и увеличение пропускной способности памяти вдвое сопровождается изменением форм-фактора модулей. При сохранении тех же размеров модуля число контактов увеличилось со 168 до 184. Изменившееся положение ключа не позволит вставить модули DIMM DDR SDRAM в сегодняшние разъемы DIMM.
Теперь о перспективах. Стандарт модулей DIMM DDR SDRAM предполагает использование до 200 МГц чипов, с результирующей частотой 400 МГц и пропускной способностью 3.2 Гбайт/с - как у двухканального Direct Rambus DRAM. С того момента, когда DDR SDRAM исчерпает свои возможности, в 2003 г. должен стартовать DDR-II.
Скорость DDR-II чипов, как предполагается, начнется со 100 МГц, но за счет того, что будет передаваться 4 пакета данных за такт, их пропускная способность также должна составить 3.2 Гбайт/с. Учитывая такую технологию работы (передачу 32 байтов за такт) рост производительности DDR-II чипов при росте тактовой частоты будет максимальным - в 4 раза: 150 МГц дадут уже 4.8 Гбайт/с, а 200 МГц - 6.4 Гбайт/с.
Модули на этих чипах, как и модули на чипах DDR, также будут иметь свой собственный форм-фактор (230 контактов), и требовать новых чипсетов. То же самое можно сказать и о чипах Advanced DRAM Technology, которые должны появиться примерно в то же время.
До тех пор, еще три года, нам предстоит выбирать лишь между DDR SDRAM и Direct Rambus DRAM. Если Intel не будет силой влиять на рынок (а он будет!), то результат, учитывая соотношение цена/производительность, выглядит вполне понятным - выигрывает DDR SDRAM. В противном случае ситуация становится непредсказуемой: трудно просчитать, что пересилит - финансовая мощь Intel, или здравый смысл индустрии, и в какой пропорции проявят себя эти два компонента в конечном результате.
В любом случае, если отстраниться от экстремистских точек зрения, то можно констатировать, что как бы ни сложилась ситуация, судьба DDR SDRAM сегодня видится в более радужных оттенках, нежели, скажем, год назад. За этот год успел выйти Athlon, AMD набрала вес, а VIA - сделала ставку на DDR SDRAM. Поэтому, что бы ни произошло на рынке решений от Intel, те, кто будет приобретать в конце этого года процессоры AMD, просто обречены на DDR SDRAM. А это, если ситуация с ценой на RDRAM не изменится кардинально до конца года, уже само по себе выглядит неплохим аргументом в пользу выбора решения от AMD/VIA для тех, кто предпочитает делать покупки, руководствуясь разумом, а не рекламой.
Платформы от ServerWorks, которая сегодня выступает для Intel в роли страховочного варианта, закрывая те области на серверном рынке x86, которые не в состоянии закрыть Intel, смогут выступить столь же достойным ответом на i840 с двумя каналами Rambus на рынке решений для рабочих станций и серверов, как чипсеты VIA - на рынке обычных пользовательских PC.
По предварительным тестам прототипа Samurai, производительность системы на его основе равна производительности системы на базе i840, а порой и обгоняет ее. Это, с учетом цены модулей RIMM, которая вряд ли уменьшится в несколько раз в течение года, и объем памяти в серверах и рабочих станциях дает разницу в стоимости между решениями на базе DDR SDRAM и RDRAM в тысячи долларов при равной производительности.
Итог: производители DRAM не могут позволить себе не выпускать DDR SDRAM. Рынок для этого типа памяти существует, он весьма велик. Затрат для перехода на DDR SDRAM почти не требуется. Себестоимость изготовления чипов не слишком отличается от себестоимости изготовления чипов SDRAM той же тактовой частоты. Стоимость RDRAM столь высока, что пользователи, даже при неудовлетворенном спросе на память, зачастую просто не могут позволить себе увеличить объем памяти в своих PC. Получился парадокс: если отбросить PC133 SDRAM, как технологию, принадлежащую к предыдущему поколению, то на рынке общедоступной памяти просто нет предложения. Ну не считать же таковым безбожно дорогой RDRAM? При данных обстоятельствах воздержаться от выпуска DDR SDRAM было бы непростительной глупостью.
Складывается, наконец, и вторая половина мозаики: чипсеты и материнские платы. Во второй половине 2000 г. на рынке будет вполне достаточно решений, полностью закрывающих поддержкой DDR SDRAM весь спектр рынка: чипсеты VIA и AMD - High-End PC на базе Pentium III и Athlon, чипсеты AMD и Samsung - серверы и рабочие станции на базе Athlon, чипсеты ServerWorks - серверы и рабочие станции на базе Pentium III.
5. Технология памяти Direct Rambus
Процессоры, как выяснилось, развиваются гораздо быстрее, чем за ними поспевает RAM. Предвыборка, распараллеливание выполнения операций, конвейерные структуры - все это раскочегарило процессора так, что у них болше времени уходит на ожидание готовности памяти, чем на сам процесс вычислений.
Спасает кеш, но это тоже не панацея. Во-первых, он дорог, причем цена растет нелинейно при увеличении объема - с ростом кеша увеличивается процент брака, а это делает процессор дороже. Кеш второго уровня - уже не совсем то, что первого, он работает на частоте шины процессора. Далее, кеш никак не спасает от операций, которые не отличаются локальностью обращений к памяти, или от обработки массивов, тривиально не укладывающихся в размер кеша. Никакой кеш не поможет и при обсчетах потоковой информации - будь то оцифровка звука ли, видеоввод, роутинг сетевого трафика. Bus-master, управление шиной силами внешних устройств, вообще идет мимо кеш-подсистемы процессора, прямо в память, причем большие потоки информации "мимо" процессора все равно ограничивают его производительность, так как мешают ему обращаться к памяти.
В общем, сегодняшняя подсистема RAM не удовлетворяет потребностей компьютера ни с какой позиции. И главное - не меняя архитектуры, ее, конечно, можно ускорить. Процентов на 20-30. А нужно бы - раз в 5-10.
Что тут делать? И какие проблемы мешают ускорению памяти?
Во-первых, есть предел повышения частоты, на которой может работать память. При существующей технологии на считывание содержимого ячейки памяти нужно порядка 10 наносекунд, что не позволяет поднять частоту обращения выше 100Мгц.
Во-вторых, увеличение разрядности памяти (включение ячеек параллельно, чтобы получить за одно считывание больше байт) создает свои проблемы - как электрические (придется делать дикого размера микросхемы управления - по 200-300 ножек на корпус), так и бытового характера. Чем больше разрядность, тем большими шагами можно наращивать память, что неудобно с точки зрения потребителя. Представляете, как тяжко пришлось бы покупателям, если бы модули SIMM выпускались только шагами по 32 мегабайта? Или если бы их пришлось ставить в машину не парами, а минимум - четверками?
В общем компания Rambus поглядела, и решила, что пора перепроектировать систему памяти в принципе. Отказаться от сегодняшней методики управления чипами, и сделать все с нуля.
Сразу скажем - ей удалось. Хотя риск был велик - в основном, риск того, что за Rambus-ом не пойдут, и новый стандарт не приживется. Ан, пошли. Правда, еще не прижился, но производить новую память (модуль такой памяти, сделанный по технологии Direct Rambus, называется RIMM) принялись несколько крупнейших фирм, включая известнейшего памятестроителя Kingston и толстяка айбиэма.
Новая технология отличается от старой решительно всем - только вот на вид почти точно такая же, как всем известные DIMM-ы. Direct Rambus вобрал в себя почти все новшества памятестроения, совместив их в аккуратно и вдумчиво спроектированной схеме.
Новая схема
· Общается с контроллером по мультиплексированной 800-мегагерцовой шине, что резко снижает необходимое число контактов и энергопотребление интерфейсных схем
· Использует полностью параллельное соединение разъемов под модули SIMM, что гарантирует временное согласование сигналов, сколько бы модулей не было вставлено. Отсюда - возможность работы на 800 Мгц.
· Адресует модули независимо, что резко увеличивает число независимых банков памяти, а значит, позволяет выполнять частично перекрывающиеся во времени обращения чаще.
· Позволяет делать конвейерные выборки из памяти, причем передача адреса может выполняться одновременно с передачей данных. Отсюда - возможность сильного перекрытия запросов к памяти во времени. Контроллер может передать в память до 4-х запросов (причем возможно перемежать считывание и запись), которые будут выполнены последовательно.
Итого, на практике контроллер может выжать из шины памяти 95% ее максимальной теоретической производительности, которая равна 1.6 гигабайта в секунду (800мгц, два байта за такт). Правда, на сегодня пиковая производительность реальных схем - 600 мегабайт в секунду, но это уже очень хорошо. А запас в гигабайт в секунду карман не тянет. Не успеешь глазом моргнуть, как новые процессоры, интеллектуальные дисковые и графические контроллеры используют его до корки, и попросят добавки.
Определенной проблемой новой технологии является притормаживание перехода на нее компании Intel. Гигант не торопится переключаться на RIMM-ы, объясняя это необходимостью плавного перехода. Как именно задержка обеспечивает плавность - мне не совсем ясно, но, безусловно, эволюционные подходы - неизбежны. Если завтра все начнут делать материнские платы под RIMM-s, куда производители денут выпускающиеся мощным потоком DIMM-s и SIMM-s? Тем не менее, переход на RIMM-ы можно считать предопределенным.
В других областях - от видеоконтроллеров до спец-компьютеров и встроенных систем RIMM-ы тоже делают первые шаги. К примеру, TI и S3 уже лицензировали технологию Direct Rambus, а значит, без работы ей не умереть.
Предполагается, что в персональных компьютерах Direct Rambus RIMMs будут применяться в следующем году, к 2000-му году займут порядка 30, а в 2001-м и все 50% рынка.
6. Transmeta Crusoe.
Ну вот и наступил тот день, когда оказались сняты покровы секретности, окружающие одну из самых таинственных компаний последних пяти лет, Transmeta, а также и их детище - процессор под кодовым названием Crusoe. Одно из ранних и общепринятых предположений полностью подтвердилось: Crusoe действительно не является конкурентом процессоров для настольных компьютеров от AMD и Intel - он самую малость опоздал с этим, но зато его возможности по энергосбережению возможно делают его идеальным выбором для производителей портативных продуктов - от ноутбуков до HPC. Но к этому моменту мы вернемся чуть позже, когда речь пойдет о конкретных деталях чипов. А сейчас посмотрим на более фундаментальные вещи, и первое, на что стоит обратить внимание в данном случае - это технология Code Morphing, позволяющая "на лету" преобразовывать x86 код во внутреннюю систему команд процессора.
Crusoe относится к разряду VLIW процессоров. То есть, в отличие от привычных каждому пользователю PC чипов, работающих с CISC инструкциями, он в своей работе опирается на VLIW (very long instruction word), будучи в этом более близок к таким продуктам, как Merced или Elbrus 2000. (Последнее, пожалуй, особенно справедливо, если учесть, что глава Transmeta, Dave Dietzel, в свое время немало времени провел в Москве, контактируя с будущими создателями E2K).
Так вот, вернемся к VLIW. Поскольку эта архитектура несовместима напрямую с x86, а отказываться от такого преимущества, каким является накопленный парк x86 программного обеспечения создателям Crusoe совсем не хотелось, и был разработан промежуточный, частично аппаратный, частично программный, невидимый для программ слой - Code Morphing, который во время выполнения программы, незаметно для нее преобразует ее x86 инструкции в инструкции VLIW.
Плюсы и минусы такого подхода, по сравнению с традиционным, очевидны. Это:
1. Возможность достаточно радикально менять структуру процессора, подгоняя его к тем или иным требованиям - все равно все изменения его архитектуры для программ можно замаскировать на уровне Code Morphing.
2. Возможность вносить те или иные изменения в уже выпущенные процессоры, опять же на уровне преобразования кода.
3. Очень удобная вещь для работы с различными новыми наборами инструкций - SSE, 3DNow!, и т.д. Была бы лицензия.
4. Как ни крути, а эмуляция остается эмуляцией, со всеми вытекающими последствиями в плане производительности. В качестве примера можно посмотреть на душераздирающие результаты эмуляции x86 программ на PowerPC. Но Transmeta неплохо поработала в этом направлении.
Как это все работает?
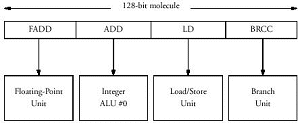
Для начала надо сказать пару слов о логической структуре процессора. Ядро Crusoe состоит из пяти модулей четырех различных типов: два блока для операций с целыми числами, один для операций числами с плавающей запятой, один - для операций с памятью, и один - модуль переходов. Соответственно, и каждая VLIW инструкция ("молекула", по терминологии Transmeta, длиной 64 или 128 бит) может состоять из четырех RISC-подобных операций этих типов ("атомов"). Все атомы выполняются параллельно, каждый соответствующим модулем, молекулы идут друг за другом, в строгом соответствии с очередью, в отличие от большинства сегодняшних суперскалярных x86 процессоров, где используется механизм внеочередного выполнения команд (out-of-order), это заметно упрощает внутреннюю структуру процессора, позволяя отказаться от некоторых громоздких функциональных модулей (например, декодера инструкций, коих в x86 наборе не так уж и мало). Для иллюстрации можно сравнить площадь мобильного 0.18 мкм Coppermine с суммарным объемом кэша 288 Кбайт с площадью TM5400 с суммарным кэшем 384 Кбайт - 106 квадратных милиметров против 73. Что, естественно, напрямую сказывается и на разнице в тепловыделении и энергопотреблении процессоров.
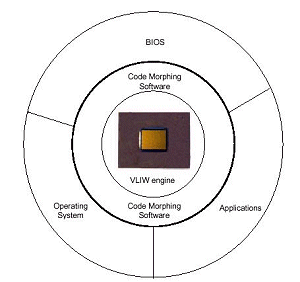
Но вернемся вновь к принципу работы процессора. На вышеописанный уровень "молекулы", по возможности максимально плотно упакованные "атомами", попадают с уровня Code Morphing, где в них превращаются исходные инструкции (на данный момент речь идет только о x86, но в перспективе ничто не мешает сделать версию транслятора и для другого набора команд). Вся окружающая среда с которой сталкивается процессор, начиная от BIOS и заканчивая операционной системой и программами, контактирует только с Code Morphing, не имея прямого доступа к самому ядру процессора. Очень удобно, учитывая, что даже уже у двух первых объявленных процессоров Transmeta это самое ядро - разное.
Одним из методов увеличения производительности такого нетрадиционного способа работы, является очень логичная система кэширования. Каждая x86 инструкция, будучи оттранслированной один раз, сохраняется в специальном кэше, располагающемся в системной памяти, и в следующий раз, при необходимости ее выполнения, этап трансляции можно пропустить, сразу достав из кэша необходимую цепочку молекул. Вдобавок, как обещает Transmeta, Code Morphing со временем еще и обучается: по мере выполнения программ, оптимизируя их для более быстрого выполнения, обращает внимание на наиболее часто выполняемые участки кода, анализирует переходы в теле программы, и т.д.
Первые процессоры Transmeta максимально ориентированы на рынок мобильных чипов (что, впрочем, не мешает компании уже поговаривать о серверном процессоре этой же архитектуры!), соответственно одним из наиболее важных параметров процессора здесь является его энергопотребление. И если с младшим из сегодняшних чипов Transmeta, TM3120, с его 92 Кбайт кэша, особых проблем нет, то в TM5400 компания встроила механизм LongRun, функционально подобный технологии SpeedStep от Intel - возможность изменения тактовой частоты и напряжения на ядре процессора на лету. Причем, куда более гибко, чем это возможно в случае с двумя фиксированными значениями у SpeedStep.
Если уж зашла речь о конкретных чипах, то давайте займемся этим вопросом более внимательно. Итак, на сегодняшний день объявлены два первых CPU, созданных по представленной Transmeta технологии. Первый, TM3120, нацелен на рынок HPC, второй, TM5400 куда больше подходит для рынка субноутбуков. Итак, по порядку:
TM3120. Младший процессор в семействе, с тактовой частотой 333, 366, и 400 МГц. Обладает всего лишь 96 Кбайт разделенного кэша L1 (64 Кбайт под инструкции, 32 Кбайт - под данные). Процессор рассчитан на напряжение 1.5 В.
Содержит стандартные для серии PC-on-a-chip элементы: 66-133 МГц SDRAM контроллер с 3.3 В интерфейсом, рассчитанный на применение со стандартными для мобильных приложений модулями SO-DIMM. Частота памяти получается путем применения определенного делителя (от 1/2 до 1/15) к тактовой частоте процессора. Контроллер шины PCI также обладает стандартным 33 МГц PCI 2.1 совместимым интерфейсом, обеспечивая полноценную работу со всеми сегодняшними продуктами, могущими его использовать. Из поддержки периферии надо упомянуть контроллер флэш-памяти - если уж продукт ориентирован на рынок самых маленьких компьютеров, то без этого там никуда.
Как любой нормальный процессор, предназначенный для работы с Windows (а в список проверенных ОС входят Microsoft Windows 95, Windows 98, Windows NT и Linux), TM3120 должен соответствовать системе управления энергопотреблением ACPI, что он успешно и делает, потребляя в системном состоянии Deep Sleep всего лишь 0.015 Вт. Разумеется, при выполнении мощных вычислений энергопотребление вырастает на несколько порядков. Например, при проигрывании DVD оно доходит до 2.9 Вт, что тоже, впрочем, чертовски хорошо, если сравнивать, скажем, с мобильными процессорами Intel и AMD.
Что касается старшего варианта, TM5400, то все вышесказанное в основном относится и к нему, но с рядом поправок. Во-первых, до 500-700 МГц выросла скорость. Во вторых, что не менее важно, значительно увеличился и объем кэша - наряду с 128 Кбайтами (64+64) L1, появился и L2 - причем сразу 256 Кбайт. Здесь, в зависимости от частоты, напряжение ядра плавает - от 1.2 до 1.6 В. Энергопотребление, впрочем, даже в случае проигрывания DVD доходит всего лишь до 1.8 Вт - в первую очередь сказывается LongRun.
Что касается PC-on-a-chip возможностей, то здесь всего одно пополнение, но такое, которое просто нельзя не заметить - к SDRAM контроллеру прибавился его DDR SDRAM собрат. Все что было сказано выше о скорости SDRAM, относится и к DDR.
Все это замечательно, но как Crusoe ведет себя в реальной жизни? Вполне неплохо для начала. Уже была продемонстрирована работа на компьютере на базе Crusoe заявленных операционных систем, без особых проблем работали реальные приложения - Power Point, Quake...
Что касается производительности, то Transmeta поступила весьма разумно, решив предложить для этого собственный тест - Mobile Platform Benchmark. Впрочем, надо признать, весьма логичный, во главу угла ставящий соотношение производительность/энергопотребление. (Ну а то, что здесь выигрывает Crusoe - это, разумеется, проблемы конкурентов). По тестам, произведенным на нем самой Transmeta, TM5400, с варьировавшейся в течение теста (LongRun был включен) от 266 до 533 МГц скоростью, на ряде задач шел вровень с мобильным Pentium III 500, на ряде отставал. Причем во всех задачах его энергопотребление было в несколько раз ниже. Здесь можно привести еще один показатель, правда, опять со слов самой компании - 667 Мгц TM5400 по производительности примерно равен 500 МГц Pentium III.
7. VIA Joshua
Всю свою историю, самой отличительной чертой процессоров Cyrix была их максимальная доступность. AMD всегда пыталась быть этаким средним классом, а Intel традиционно снимал сливки сверху. Этим стратегиям к концу 90-х годов полностью соответствовало и финансовое состояние компаний. Вдобавок, сильное влияние оказал и еще один момент: вспыхнувшая в последние годы тенденция к резкому снижению стоимости PC не сделала Cyrix королем, как это можно было бы подумать. Напротив, в результате на этот рынок обратили серьезнейшее внимание Intel и AMD, развернувшие в последние два года там кровопролитную ценовую войну, что очень напоминало борьбу двух слонов в посудной лавке.
Результат мы знаем. Летом, после достаточно продолжительной агонии своей линейки MII, National Semiconductor был вынужден оставить рынок x86 процессоров, шаг, который был вполне очевиден уже в конце 98 года. В течение второй половины прошедшего года ушли и другие компании, работавшие в той же нише: IDT и Rise. Но их уход отнюдь не означал, что спрос на процессоры, стоящие несколько два-три десятка долларов, внезапно испарился. Напротив, он остался, и даже, пожалуй, несколько вырос: все же последние несколько лет требования офисных пакетов застыли практически на одном и том же уровне, и этому уровню вполне соответствует производительность, обеспечиваемая подобными процессорами. Таким образом, спрос остался, а вот предложение фактически исчезло. Ситуация, которую надо было исправить.
И здесь на выручку пришла VIA Technology, амбиции которой к началу прошедшего года выросли до немыслимых высот. Компания, вполне успешно конкурирующая в последнее время с Intel в области чипсетов, причем во многом за счет умения продавать именно дешевые продукты, решила попробовать применить эту стратегию в области процессоров. Самым простым путем к реализации этого плана была покупка компании, уже работающей в этой области. Тем более, что ситуация сложилась так, что VIA крайне был необходим доступ к патентам, имеющим отношение к шине GTL+. Этим летом она получила его, за счет приобретения двух групп разработчиков процессоров - Cyrix у National Semiconductor и Centaur у IDT. Несмотря на то, что явным фаворитом VIA является Centaur, первым ее процессором все же станет процессор от Cyrix. О нем здесь речь и пойдет.
Первые сведения о нем появились еще осенью 1997 года, на MicroProcessor Forum, традиционном месте для объявлений такого рода. Вице-президент Cyrix, Роберт Махер, описал ядро Cayenne - модифицированное ядро 6x86 линейки, обладающее поддержкой MMXFP - набора SIMD инструкций, разработанного самим Cyrix, модуль операций с целыми числами оставался практически нетронутым, а вот модуль операций с числами с плавающей точкой должен был подвергнуться довольно значительным изменениям: появлялась конвейерная обработка и возможность обработки до двух операций с такими числами за такт. Новый сопроцессор должен был вывести процессор Cyrix почти на тот же уровень, что и Pentium II/Pentium III. То же самое можно сказать и работе Cayenne с MMX инструкциями.
Что касается технических параметров нового процессора, то подразумевалось, что Cayenne начнет производиться во второй половине 1998 года с использованием 0.25 мкм техпроцесса (площадь чипа из 6.8 миллионов транзисторов должна была составить около 70 кв. мм), в течение 98 года его скорость вырастет с 250 до 350 МГц (PR рейтинг - с 300 до 400 МГЦ). А уже в 99 году ему на смену должен был придти Jalapeno.
Тем не менее, прошел 98 год, прошла первая половина 99, Cyrix уже успел отказаться от собственного расширенного набора инструкций в пользу 3DNow!, а Cayenne все продолжал доводиться разработчиками, успев переименоваться сначала в Jedi, а потом, после появления претензий со стороны LucasFilm, и в Gobi. Что касается изменений, произошедших в дизайне процессора за это время, то известно только, что, как и предполагалось еще на MPR'97, у него появился кэш L2 на чипе, причем, достаточно внушительный - 256 Кбайт, как у сегодняшнего Coppermine. (А еще стоит вспомнить 64 Кбайт единого кэша L1 - вдвое больше, чем у того же Coppermine). В таком состоянии находились дела, когда Cyrix был приобретен VIA.
К этому моменту процессор находился уже на грани появления на свет: достаточно сказать только, что незадолго до приобретения Cyrix он уже демонстрировался на Computex'99. Таким образом, покупая Cyrix, VIA кроме получения столь необходимых ей патентов получала доведенный до кондиции в течение двух лет дешевый, но достаточно производительный процессор - именно то, что ей и было надо. Так что, разогнав половину Cyrix, VIA все же оставила полторы сотни человек с тем, чтобы они в течение нескольких месяцев довели процессор до стадии, когда было бы возможным его коммерческое производство.
К тому времени он уже начал принимать завершенные черты: четко определился интерфейс - Socket 370, частота системной шины (66/100/133 МГц), техпроцесс - 0.18 мкм и, самое главное, имя - Joshua. На самом деле, конечно, главное - это скорость, но вот с этим точной определенности не было. На момент написания этой статьи предполагается, что PR-рейтинг процессора будет составлять 433/466/500/533/566 МГц, причем, по видимому, на момент выхода будут доступны только два первых варианта из этой линейки.
Возможность разгона оставляет достаточно смутные впечатления. С одной стороны - незафиксированный коэффициент умножения: прямо-таки рай после процессоров Intel и AMD. С другой стороны, процессор, который изначально рассчитан на напряжение 2.2В (и это для не столь уж больших 300 МГц для PR-рейтинга 433!), заставляет крепко задуматься о перспективах его разгона: похоже, это сделали уже до нас. С другой стороны, 0.18 мкм техпроцесс TSMC все же оставляет некоторую надежду.
Что касается производительности, то, исходя из архитектуры процессора, стоит ожидать ее примерно на уровне Celeron, работающего тактовой частотой, соответствующей его PR-рейтингу - некоторые недостатки лишь слегка улучшенной архитектуры несколько летней давности должен во многом вытянуть 256 Кбайт кэш L2, работающий на тактовой частоте процессора. В основном, конечно, это касается офисных приложений, где лишние 128 Кбайт L2 совсем не помешают. Что касается игр, то здесь скажется значительно улучшенный со времен 6x86MX сопроцессор, и, разумеется, не стоит скидывать со счетов поддержку 3DNow! - сегодня под этот набор SIMD инструкций оптимизирована любая из выходящих мало-мальски серьезных игр и новые драйвера под любую видеокарту.
И все это за очень (наши источники в VIA категорически подчеркивают это слово) доступную цену. Учитывая, что по последним данным о планах Intel, прогресс линейки Celeron в этом году значительно замедлится, и его частота лишь слегка перешагнет за 600 МГц, то позиции VIA выглядят вполне надежными.
8. Merced
Введение
Merced - название 64-разрядного микропроцессора общего назначения, разрабатываемого в настоящее время фирмой Intel. Его выпуск начнется в середине 2000 года по 0.18-микронной технологии. Опытное производство - в 1999 году.
Процессор получил название от города Merced, расположенного недалеко от Сан-Хосе (США).
Merced станет первым процессором нового семейства IA-64. IA-64 - аббревиатура от Intel 64-bit Architecture - 64-разрядная Архитектура Intel. IA-64 воплощает концепцию EPIC (аббревиатура от Explicitly Parallel Instruction Computing - Вычисления с Явным Параллелизмом Команд). Концепция EPIC разработана совместно фирмами Intel и Hewlett-Packard, по их заявлениям, EPIC - концепция той же значимости, что CISC и RISC. В IA-64 используется новый 64-разрядный набор команд, разработанный также совместно фирмами Intel и HP (для него в официальных сообщениях Intel и HP вводится аббревиатура 64-bit ISA - 64-bit Instruction Set Architecture). Вдобавок, Merced будет полностью совместим с семейством x86 (В официальных сообщениях Intel семейство x86 обозначают аббревиатурой IA-32 - Intel 32-bit Architecture - 32-разрядная Архитектура Intel).
В настоящее время доподлино известно о работах над двумя процеcсорами семейства IA-64:
· уже упомянутый Merced, разрабатываемый в основном силами Intel
· McKinley, который разрабатывается в HP и появится в конце 2001 года
Недавно были добавлены еще два названия:
В 2002 должен появиться Madison, а за ним - Deerfield.
Хронология событий
Hewlett-Packard и Intel объявили о совместном исследовательском проекте в июне 1994 года. Цель проекта - создание более совершенных технологий в сфере "рабочих станций конца десятилетия, серверов и информационно-вычислительных продуктов масштаба предприятия". Проект включал разработку "архитектуры 64-разрядного набора команд" и оптимизирующих компиляторов.
В 1996 году фирма HP выпустила свой первый 64-разрядный процессор общего назначения - PA-8000, представитель нового семейства PA-RISC 2.0. Естественно предположить, что PA-RISC 2.0 - результат совместного проекта "архитектуры 64-разрядного набора команд", тем более, что в PA-8000 применены решения, которые в терминологии IA-64 называются "предикация" и "загрузка по предположению". Но нет официальных данных, подтверждающих это предположение.
9 октября 1997 года фирма Intel объявила, что
· производство Merced, первого представителя нового семейства 64-разрядных микропроцессоров, начнется в 1999 году по 0.18-микронному технологическому процессу фирмы Intel, который также создается;
· процессор предназначен для рабочих станций и серверов;
· Merced сможет выполнять программы для 32-разрядных процессоров Intel;
· Intel обладает средой разработки программного обеспечения, полностью совместимого с IA-64, и "ключевые" независимые продавцы программного обеспечения уже используют эту среду для разработки операционных систем и приложений уровня предприятия;
14 октября 1997 года, на Микропроцессорном Форуме в Сан-Хосе, Калифорния, фирмы Intel и HP впервые публично описали основы IA-64. Совместно выступили John Crawford, Intel Fellow and Director of Microprocessor Architecture и Jerry Huck, Hewllet-Packard`s Manager and Lead Architect. Запись их речей можно найти на Web-сервере Intel, а демонстрировавшиеся слайды - на Web-сервере HP. Фирма Intel дополнила это выступление заявлениями для прессы .
В тот же день на Микропроцессорном Форуме выступал Joel Birnbaum, Director of Hewlett-Packard Laboratories, Senior Vice President of Research and Development. Он вкратце рассказал о работах HP над процессорными архитектурами с 1980-х до альянса с Intel в 1994. По его словам, отправной точкой для альянса с Intel послужил проект, называемый сначала Wide-Word, а затем Super-Parallel Processor Architecture (SP-PA). Этот проект был выполнен в HP Labs под руководством Bill Worley, который одновременно возглавлял работы над PA-RISC. Согласно Joel Birnbaum, в проекте Wide-Word были проведены эксперименты со статическим параллелизмом и загрузкой по предположению, разработана "обобщенная предикация", механизмы, позволяющие масштабировать количество функциональных устройств и их "скорость". Также он объяснил, зачем фирме HP понадобилось заключать альянс с Intel, но это объяснение слишком обширно, чтобы приводить его здесь.
29 мая 1998 года фирма Intel сообщила о переносе на год выпуска процессора Merced. Было объявлено, что серийное производство начнется в середине 2000 года. А опытное - в 1999 году. В официальном сообщении нет никаких сведений ни об архитектуре Merced, ни о технологии его производства.
С 12 по 15 октября 1998 года проходил очередной Микропроцессорный Форум. От Intel выступал Stephen Smith с темой "IA-64 Processors: Features and Futures". Он сообщил несколько новых технических деталей, рассказал о перспективах семейства IA-64.
EPIC, IA-64, Merced
Концепция EPIC, согласно Intel и HP, обладает достоинствами VLIW, но не обладает ee недостатками.
John Crawford перечислил следующие особенности EPIC:
· Большое количество регистров.
· Масштабируемость архитектуры до большого количества функциональных устройств. Это свойство представители фирм Intel и HP называют "наследственно масштабируемый набор команд" (inherently scaleable instruction set)
· Явный параллелизм в машинном коде. Поиск зависимостей между командами производит не процессор, а компилятор.
· Предикация (Predication). Команды из разных ветвей услового ветвления снабжаются предикатными полями (полями условий) и запускаются параллельно.
· Загрузка по предположению (Speculative loading). Данные из медленной основной памяти загружаются заранее.
Ниже эти особенности EPIC объяснены подробнее.
Представители Intel и HP назывют EPIC концепцией следующего поколения и противопоставляют ее CISC и RISC. По мнению Intel, традиционные архитектуры имеют фундаментальные свойства, ограничивающие производительность. Производители RISC процессоров не разделяют подобного пессимизма. Кстати, в 1980-х, когда возникла концепция RISC, прозвучало много заявлений, что концепция CISC устарела, имеет фундаментальные свойства, ограничивающие производительность. Но процессоры, причисляемые к CISC (например, семейство x86 фирмы Intel), широко используются до сих пор, их производительность растет.
Дело в том, что все эти аббревиатуры - CISC, RISC, VLIW обозначают только идеализированные концепции. Реальные микропроцессоры трудно классифицировать. Современные микропроцессоры, причисляемые к RISC, сильно отличаются от первых процессоров RISC архитектуры. То же относится и к CISC. Просто в наиболее совершенных процессорах заложено множество удачных идей вне зависимости от их принадлежности к какой-либо концепции.
Регистры IA-64:
· 128 64-разрядных регистров общего назначения (целочисленных)
· 128 80-разрядных регистров вещественной арифметики.
· 64 1-pазpядных пpедикатных pегистpов.
Напомним, что наличие большого числа регистров названо John Crawford в числе основных черт EPIC. Действительно, 128 - много по сравнению с 8 регистрами общего назначения семейства x86. Но, например, MIPS R10000 содержит 64 целых и 64 вещественных 64-разрядных регистров.
Формат команды IA-64:
· идентификатор команды,
· три 7-разрядных поля операндов - 1 приемник и 2 источника (операндами могут быть только регистры, а их - 128=2^7)
· особые поля для вещественной и целой арифметики
· 6-разрядное предикатное поле (64=2^6)
Команды IA-64 упаковываются (группируются) компилятором в "связку" длиною в 128 pазpядов. Связка содеpжит 3 команды и шаблон, в котоpом будут указаны зависимости между командами (можно ли с командой к1 запустить параллельно к2, или же к2 должна выполниться только после к1) , а также между другими связками (можно ли с командой к3 из связки с1 запустить параллельно команду к4 из связки с2).
Перечислим все варианты составления связки из 3-х команд:
i1 || i2 || i3 - все команды исполняются паpаллельно
i1 & i2 || i3 - сначала i1, затем исполняются паpаллельно i2 и i3
i1 || i2 & i3 - паpаллельно исполняются i1 и i2, после них - i3
i1 & i2 & i3 - последовательно исполняются i1, i2, i3
Одна такая связка, состоящая из трех команд, соответствует набору из трех функциональных устройств процессора. Процессоры IA-64 могут содержать разное количество таких блоков, оставаясь при этом совместимыми по коду. Ведь благодаря тому, что в шаблоне указана зависимость и между связками, процессору с N одинаковыми блоками из трех функциональных устройства будет соответствовать командное слово из N*3 команд ( N связок ). Таким образом должна обеспечиваться масштабируемость IA-64. Несомненно, это красивая концепция. К сожалению, IA-64 присущи и некоторые недостатки.
· Tom R. Halfhill в статье журнала BYTE предполагает что без перекомпиляции код с одного процессора семейства IA-64 не будет эффективно исполняться на другом.
· Уже упомянутый Jerry Huck отметил, что в IA-64 можно произвольно (блоками по 3) увеличивать количество функциональных устройств, но при этом число регистров должно оставаться неизменным.
· Также Jerry Huck предупредил, что размер кода для IA-64 будет больше, чем для RISC процессоров, потому что на 3 команды IA-64 приходится 128 bit, а длина RISC команды обычно равна 32 bit, то есть, в 128 битах содержатся 4 команды RISC.
Вдобавок произошла путаница. На прошедшем во второй половине февраля 1998 года Форуме Разработчиков Intel ведущий инженер Carole Dulong сказала, что в такой архитектуре, как Merced, пропорция целочисленых, вещественных, специализированных устройств и устройств чтения/записи будет определяться сочетанием соответствующих команд в предполагаемом машинном коде. Тогда как на Микропроцессорном Форуме представители фирм Intel и HP объясняли, что процессоры семейства IA-64 будут содержать N одинаковых блоков по три функциональных устройства. Причем, можно предположить, что такой блок должен состоять из целочисленного устройства, устройства вещественной арифметики и устройства чтения/записи. Данные высказывания противоречат друг другу.
Кстати, EPIC удивительно напоминает архитектру VelociTI семейства сигнальных процессоров TMS320C6x фирмы Texas Instruments. Примером может служить TMS320C6201. В этом процессоре довольно много регистров - 32 регистра общего назначения. 8 функциональных устройств - это много даже по меркам современных процессоров общего назначения. Команды TMS320C6201 упаковываются во VLIW-слова, состоящие из 8 команд и шаблона. В шаблоне указаны зависимости между командами - явный параллелизм. За такт может исполниться до 8 команд. Все команды снабжены полем условия - предикация.
Помимо семейства IA-64 идут разработки еще нескольких универсальных процессоров с VLIW-подобной архитектурой.
Например, в России группой Эльбрус с 1992 года разрабатывается микропроцессор E2k (Эльбрус-2000). Научный руководитель группы Эльбрус член-корреспондент РАН Б.А. Бабаян утверждает, что отечественный E2k будет в два раза производительнее, чем McKinley (последователь Merced). По оценкам полученным на логической модели, производительность E2k составит 135 SPECint95 и 350 SPECfp95.
Еще примеры:
· В 1995 году была образована фирма Transmeta Ее руководителем является Dave Ditzel, который ранее, будучи сотрудником Sun, взаимодействовал с коллективом Эльбрус и имел доступ к информации по разрабатываемому E2k.
· Исследования VLIW в исследовательском центре IBM имени T.J. Watson начались в 1986.
Кроме этого, сейчас появляется все больше сигнальных и "медийных" процессоров с архитектурой VLIW.
Предикация
Предикация - способ обработки условных ветвлений. Суть этого способа - компилятор указывает, что обе ветви выполняются на процессоре параллельно. Ведь EPIC процессоры должны иметь много функциональных устройств.
Опишем предикацию более подробно.
Если в исходной программе встречается условное ветвление (по статистике - через каждые 6 команд), то команды из разных ветвей помечаются разными предикатными регистрами (команды имеют для этого предикатные поля), далее они выполняются совместно, но их результаты не записываются, пока значения предикатных регистров неопределены. Когда, наконец, вычисляется условие ветвления, предикатный регистр, соответствующий "правильной" ветви, устанавливается в 1, а другой - в 0. Перед записью результатов процессор будет проверять предикатное поле и записывать результаты только тех команд, предикатное поле которых содержит предикатный регистр, установленный в 1.
Техника, подобная предикации, используется в RISC процессорах архитектуры ARM от Advanced RISC Machines Ltd. (Cambridge, UK) начиная с первых ARM в 1980-х. Кстати, фирма Intel обладает лицензией фирмы Advanced RISC Machines на производство, продажу и модификацию микропроцессоров семейства StrongARM (разработан фирмой DEC, также обладавшей лицензией на ARM). В уже упомянутых сигнальных процессорах серии TMS320 все команды снабжены полем условия. Также и некоторые команды HP PA-RISC снабжены полем условия. В IBM POWER3 могут выполняться по предположению команды из обеих ветвей.
Описывая предикацию, представители Intel и HP ссылаются на исследовательскую работу A Comparison of Full and Partial Predicated Execution Support for ILP Processors, выполненную Scott A. Mahlke, Richard E. Hank, James E. McCormick, David I. August, и Wen-mei W. Hwu из исследовательской группы IMPACT университет штата Иллинойс. Работа опубликована в трудах 22-го Международного Симпозиума по Вычислительной Архитектуре, прошедшего в 1995 году. В настоящее время некоторые из авторов трудятся в лабораториях HP. В этой работе изучалось применение предикации на гипотетическом процессоре, содержащем 8 функциональных устройств. Было показано, что предикацию можно применить (в среднем) к половине условных ветвлений в программе.
К сожалению, Intel и HP не объяснили, как в процессорах семейства IA-64 будет обрабатываться оставшаяся половина условных ветвлений.
Современные же процессоры кроме предикации используют предсказание и исполнение по предположению. Кстати, RISC процессоры довольно часто правильно предсказывают ветвь - в 95% случаев.
Загрузка по предположению
Этот механизм предназначен снизить простои процессора, связанные с ожиданием выполнения команд загрузки из относительно медленной основной памяти.
Компилятор перемещает команды загрузки данных из памяти так, чтобы они выполнились как можно раньше. Следовательно, когда данные из памяти понадобятся какой-либо команде, процессор не будет простаивать. Перемещенные таким образом команды называются командами загрузки по предположению и помечаются особым образом. А непосредственно перед командой, использующей загружаемые по предположению данные, компилятор вставит команду проверки предположения. Если при выполнении загрузки по предположению возникнет исключительная ситуация, процессор сгенерирует исключение только когда встретит команду проверки предположения. Если, например, команда загрузки выносится из ветвления, а ветвь, из которой она вынесена, не запускается, возникшая исключительная ситуация проигнорируется.
Обычно для борьбы с зависимостью от медленной памяти в процессорах применяются кэши 2-х, 3-х уровней. Например HP PA-8500 содержит кэш 1-го уровня емкостью в 1.5 Mb.
Но, вдобавок к этому, например в процессорах Sun UltraSPARC (SPARC version 9), IBM POWER3 и HP PA-8xxx есть команды, указывающие процессору, что именно (данные и команды) загрузить в кэш 1-го уровня - это сильно напоминает загрузку по предположению.
Оценки производительности
Согласно заявлениям фирмы Intel, Merced достигнет наибольшей производительности в отрасли. Более точных оценок официально объявлено не было. Но затем фирма Intel анонсировала 32-разрядный Foster. Оказывается, он будет равен Merced в производительности на вещественных операциях. И даже последователь Merced, McKinley, будет медленнее, чем Foster в 32-разрядной целочисленной арифметике. Таким образом, фирма Intel сама себя опровергла. Merced не будет чемпионом по производительности.
Аналитики из MicroDesign Resources полагают, что производильность Merced с частотой 800 MHz на наборе команд IA-64 не превысит 45 SPECint95 и 70 SPECfp95, а на наборе команд x86 будет соответствовать Pentium с частотой 500 MHz. Производительность Pentium II на 450 MHz равна 17.2 SPECint95 и 12.9 SPECfp95. Получается, что при исполнении на Merced x86-кода производительность ухудшится в 3-5 раз.
Уже сейчас Compaq/DEC Alpha 21264 на частоте 500 MHz выдает 27.7 SPECint95 и 58.7 SPECfp95. На Alpha можно исполнять x86-код с помощью бинарного транслятора FX!32. Производительность при этом уменьшается в среднем в 3 раза.
Кстати, в 1997 году фиpма Intel закупила у DEC ряд лицензий, используемых в DEC Alpha. Intel была вынуждена сделать это, чтобы избежать судебного наказания за использование технологических решений DEC Alpha в своих продуктах. Веpоятно, ноу-хау DEC Alpha оказали существенное влияние и на будущий Merced.
Аналитик Tony Iams из D.H.Brown Association сообщает, что виденные им оценки производительности показывают, что UltraSPARC будет превосходить Merced в вещественной производительности, а целочисленная будет одинакова.
По оценкам, UltraSPARC-III на частоте 600MHz покажет около 35 SPECint95 и 60 SPECfp95.
В общем, считается, что конкурентами Merced станут DEC Alpha 21264, Sun UltraSPARC-III, IBM POWER3. Hо Alpha 21264 и POWER3 уже выпускаются, а выпуск UltraSPARC-III ожидается в 1999 году, тогда как Merced появится в 2000 году.
Разрядность
Merced станет в 2000 году пеpвым 64-pазpядным микропроцессором pазpаботки фиpмы Intel. Первый 64-разрядный микропроцессор общего назначения MIPS R4000 появился в 1992 году. Ныне MIPS широко используется в суперкомпьютерах, серверах, рабочих станциях и даже в игровых приставках (Nintendo и Sony). Также уже в течение нескольких лет шиpоко используются 64-pазpядные микропроцессоры общего назначения DEC Alpha (1992 год), PowerPC-620 (1994 год), Sun UltraSPARC (1995 год), HP PA-RISC 2.0 (1996 год). Более того, в процессоре UltraSPARC присутсвуют 128-разрядные регистры.
Тактовая частота
Linley Gwennap предполагает, что тактовая частота первого Merced будет около 800 MHz. С 1997 года серийно выпускается Alpha 21164 с частотой 612 MHz. В октябре 1996 года был показан Exponential Technologies` PowerPC-750 MHz, а в феврале 1998 года фирма IBM продемонстрировала Xperimental PowerPC с частотой 1GHz.
Технология производства
Произвдство Merced начнется в 2000 году по 0.18 микронному технологическому процессу. Данный процесс ныне разрабатывается фирмой Intel. Уменьшение этой технологической хаpактеpистики позволяет снизить потребляемую мощность, поднять тактовую частоту, увеличить степень интеграции, а, следовательно, разместить на микропроцессоре большее количество исполняющих устройств, регистров, кэш-памяти. В настоящий момент все пеpечисленные выше 64-pазpядные микропроцессоры пpоизводятся по технологиям 0.35 и 0.25 мкм; Фиpма Intel выпускает по технологии 0.25 мкм свои 32-pазpядные процессоры семейства x86;
По словам Ronald Curry, Merced director of marketing, первый Merced будет выпускаться в картриджах, включающих ЦПУ, L2 кэш и интерфейс шины. Для Merced разрабатывается новая системная шина, использующая концепции шины Pentium-II.
Совместимость
До официального объявления Intel в 1997 году ожидалось, что архитектура, разрабатываемая совместно фирмами Intel и HP будет совместим по коду с семействами x86 и PA-RISC. Тепеpь выяснилось, что Merced, построенный по этой архитектуре, будет исполнять код только семейства x86.
Концепции EPIC и CISC противоположны. В случае EPIC организация вычисления возложена в основном на компилятор, в случае CISC - на процессор. А теперь эти две концепции объединяются в одном процессоре.
В статье из Microprocessor Report анализируются патенты Intel на некий 64-разрядный процессор с двумя наборами команд: 64-разрядным и набором команд x86. Можно предположить, что этот процессор - Merced. В патенте сказано, что процессор будет выполнять программы, в которых перемешаны команды из набоpов x86 и IA-64, будут команды пеpехода из режима IA-64 в x86 и обpатно. Причем, по словам автора статьи, Linley Gwennap, "в некоторых местах документ создает впечатление, что Intel относится IA-64 просто как к 64-разрядному расширению x86, аналогично новым 32-разрядным режимам появившимся в i386".
В общем, относительно совместимости Merced с x86 ясно лишь, что эта совместимость будет, об этом неоднократно было заявлено представителями Intel.
Заключение
Основная особенность EPIC та же, что и VLIW - распараллеливанием потока команд занимается компилятор, а не процессор.
Достоинства данного подхода:
· упрощается архитектура процессора; вместо распараллеливающей логики на EPIC процессоре можно разместить больше регистров, функциональных устройств.
· процессор не тратит время на анализ потока команд
· возможности процессора по анализу программы во время выполнения ограничены сравнительно небольшим участком программы, тогда как компилятор способен произвести анализ по всей программе
· если некоторая программа должна запускаться многократно, выгоднее распараллелить ее один раз (при компиляции), а не каждый раз, когда она исполняется на процессоре.
Недостатки:
· Компилятор производит статический анализ программы, раз и навсегда планируя вычисления. Однако даже при небольшом изменении начальных данных путь выполнения программы сколь угодно сильно изменяется.
· Очень увеличится сложность компиляторов. Значит, увеличится число ошибок в них, время компиляции.
· Еще более увеличится сложность отладки, так как отлаживать придется оптимизированный параллельный код.
· Производительность Merced будет всецело зависеть от качества компилятора. Компиляторы для IA-64 в настоящее время разрабатываются, об их качестве ничего не известно.
Пpедставляется, что pазpаботка качественного pаспаpаллеливающего компилятоpа для Merced - более сложная задача, чем pазpаботка самого Merced. Сегодня известен, пожалуй, только один успешный коммерческий компилятор подобного типа - это компилятор для семейтва сигнальных процессоров TMS320C6x фирмы Texas Instruments. Этот компилятор разрабатывался довольно долгое время.
Согласно заявлениям фирм Intel и HP, одно из достоинств EPIC - упрощение архитектуры, но IA-64 будет аппаратно поддерживать CISC систему команд семейства x86.
Пpоизводительность Merced 800 MHz на набоpе команд x86, вероятно, будет на уpовне Pentium 500 MHz. То есть, стаpое пpогpаммное обеспечение для пpоцессоpов x86 не будет эффективно исполняться на Merced. Запускать на нем DOS или Windows - чересчур дорого. Сама фирма Intel заявляет, что Merced предназначен для рабочих станций и серверов верхнего уровня. В этом секторе компьютерного рынка процессоры x86 не использовались, поэтому непонятно, зачем в Merced нужна совместимость с x86.
Также вероятно, что наращивание числа исполняющих устройств - не столь тяжелая задача для RISC процессоров и не столь легкая для EPIC, как утверждается разработчиками EPIC и IA-64. Тем более, что так называемые RISC процессоры уже используют многие идеи, которые будут воплощены в Merced. Повторим, что классификация процессоров на CISC, RISC и VLIW условна. Современные процессоры воплощают удачные идеи из всех перечисленных концепций. В Microprocessor Report за 26 января 1998 года высказывается предположение, что EPIC может быть добавлено в виде расширения в существующие RISC наборы команд; измененный таким образом RISC процессор будет способен запускать старый код, а на программах скомпилированных для EPIC будет работать так же быстро, либо быстрее, чем IA-64 процессоры.
Intel и HP неоднократно заявляли, что Merced будет построен по революционной концепции EPIC. Но уже существуют процессоры, по всем признакам попадающие в категорию EPIC - отечественный Эльбрус-3 (1991г), TMS320C6x (1997г).
Все же, Merced - это интересный эксперимент в области разработки процессоров. И его ожидает трудная, но интересная судьба. Поэтому Intel и HP, призывая всю компьютерную индустрию переходить на Merced, сами стараются перестраховаться. Это утверждение подтвеpждатся следующими фактами. Intel продолжает линию 32-разрядных x86-процессоров и, вдобавок, закупила лицензию у DEC на RISC-пpоцессоp Alpha; Hewllet-Packard, одновpеменно с pазpаботкой EPIC, пpодолжает pазpаботку новых супеpскаляpных RISC-пpоцессоpов сеpии PA-RISC.
Словарь терминов
CISC - аббревиатура от Complex Instruction Set Computer
Пpи pазpаботке набора команд CISC заботились об удобстве пpогpаммиста / компилятора а не об эффективности исполнения команд пpоцессоpом. В систему команд вводили много сложных команд (производящих по несколько простых действий). Часто эти команды представляли собой программы, написанные на микрокоде и записанные в ПЗУ процессора. Команды CISC имеют разную длину и время выполнения. Зато машинный код CISC процессоров - язык довольно высокого уровня. В наборе команд CISC часто присутсвуют, например, команды организации циклов, команды вызова подпрограммы и возврата из подпрограммы, сложная адресация, позволяющая реализовать одной командой доступ к сложным структурам данных. Основной недостаток CISC - большая сложность реализации процессора при малой производительности.
Примеры CISC процессоров - семейство Motorola 680x0 и процесссоры фирмы Intel от 8086 до Pentium II. Эти процессоры популярны и по сей день.
Концепция CISC противопоставляется RISC.
RISC - аббревиатура от Reduced Instruction Set Computer
Основными чертами RISC-концепции являются:
· одинаковая длина команд
· одинаковый формат команд - код команды ; регистр-приемник ; два регистра-источника
· операндами команд могут быть только регистры
· команды выполняют только простые действия
· большое количество регистров общего назначения (могут быть использованы любой командой)
· конвейер(ы)
· выполнение команды не дольше, чем за один такт
· простая адресация
К RISC процессорам причисляют MIPS, SPARC, PowerPC, DEC Alpha, HP PA-RISC, Intel 960, AMD 29000.
RISC концепция предоставляет компилятору большие возможности по оптимизации кода. В настоящее время именно RISC процессоры наиболее распространены. Область их применения очень широка - от микроконтроллеров до суперкомпьютеров. RISC процессоры лидируют по производительности среди процессоров общего назначения. Существуют стандарты на RISC процессоры, например SPARC - Scalable Processor ARChitecture (текущая версия - 9, UltraSPARC), MIPS (текущая версия - IV, R10000), PowerPC; часто их называют открытыми архитектурами.
VLIW - аббревиатура от Very Long Instruction Word
VLIW - это набор команд, реализующий горизонтальный микрокод. Несколько (4 - 8) простых команд упаковываются компилятором в длинное слово. Такое слово соответствует набору функциональных устройств.
VLIW архитектуру можно рассматривать как статическую суперскалярную архитектуру. Имеется в виду, что распараллеливание кода производится на этапе компиляции, а не динамически во время исполнения. То есть, в машинном коде VLIW присутствует явный параллелизм.
VLIW процессоры мало распространены. Наиболее известна была VLIW система фирмы Multiflow Computer, Inc. Эта фирма уже не существует. Многие бывшие инженеры из Multiflow Computer работают теперь в HP. В нашей стране довольно известен суперкомпьютер "Эльбрус-3", использующий VLIW концепцию. К VLIW можно причислить семейство сигнальных процессоров TMS320C6x фирмы Texas Instruments. C 1986 года ведутся исследования VLIW архитектуры в IBM's T. J. Watson Research Center.
Несомненно, между EPIC и VLIW можно найти много общего.
Список использованной литературы:
1. Подшивка журнала Компьютерра за 1997-2000 годы
2. Информация с Интернет-сайта IXBT
3. Журнал «Аппаратные средства PC» №5, 1999 г.
|
