| Министерство образования РФ
Курский государственный технический университет
Кафедра вычислительной техники
Утверждаю
зав. Кафедрой профессор
__________________Титов В. С.
____________________________
____________________________
Выпускная квалификационная работа
бакалавра
Программная модель 32-разрядного микропроцессора фирмы Motorola
Автор выпускной квалификационной работы: Денисов А. Н.
Обозначение выпускной квалификационной работы________________
_______________________________Группа ВМ-81
Направление____________________________________________________
Руководитель работы: __________________ к.т.н. Жмакин А.П.
Нормоконтроль __________________ Чернецкая И. Е.
Со всеми вопросами обращайтесь Denisov_Alex@rambler.ru
Аннотация
Целью данной работы являлось изучение организации 32-разрядного микропроцессора фирмы Motorola. Данная цель может быть достигнута посредством написания программной модели данного микропроцессора.
В ходе работы большое внимание уделено функциональным особенностям объекта разработки, способам организации, системе команд. Данное программное изделие может быть использовано при обучении студентов. Пояснительная записка состоит из 45 страниц, в их состав входит 7 таблиц и 4 рисунка.
Summary.
The purpose of the given work was the study of organization of the 32-bit microprocessor of firm Motorola. The given purpose was achieved by means of a spelling of program model of the given microprocessor.
During work the large attention is given to functional features of object of development, ways of organization, command system. The given program product can be used at training the students. The explanatory slip consists of 45 pages, their structure includes 7 tables and 4 figures.
Содержание
Введение. 5
Техническое задание. 7
2. Постановка задачи.. 9
3. Выбор средств реализации.. 10
4. Описание машины пользователя. 11
5. Интерфейс, органы управления. 33
6. Применение программной модели. 37
7. Описание интерпретатора. 39
Заключение. 44
Список использованных источников. 45
Введение
В современной технике роль микро-ЭВМ весьма значима. Сфера их применения широка. Достаточно назвать лишь несколько областей, в которых применение 16- и 32-разрядных МК стало обыденным явлением, чтобы понять, почему производители МК уделяют им такое внимание:
Реклама

- цифровые устройства проводной и беспроводной связи;
- промышленные контроллеры, системы управления двигателями;
- портативные вычислительно-коммуникационные цифровые средства;
- цифровые бытовые устройства;
- системы передачи информации, и т.д.
Это делает удобным технику в эксплуатации, экономит человеку время, позволяет более рационально расходовать электроэнергию.
Для изучения микро-ЭВМ в Курском Государственном Техническом Университете отсутствуют лабораторные установки, которые позволяли бы студентам ознакомиться с новыми перспективными моделями различных микропроцессоров фирмы Motorola .
Практика работы с существующими лабораторными установками, свидетельствует о том, что студенты вынуждены тратить большую часть времени на рутинные операции (ассемблирование, дизассемблирование и др.). Это объясняется тем, что лабораторные установки обладают не удобным, малофункциональным и не наглядным интерфейсом. Например, в качестве устройства вывода используются шесть семисегментных индикаторов, а программный код вводится побайтно в шестнадцатеричном формате. С целью упрощения работы путём автоматизации рутинных операций и изучения элементной базы новых микропроцессоров и была разработана данная программная модель.
Программная модель дает широкие и удобные возможности для набора и отладки программ (к примеру, может быть возможен одновременный просмотр всех регистров, памяти, ввод команд в мнемонических обозначениях, ассемблирование команд и т. д.).
Применение программной модели дает значительную экономию времени и сил, за счет более удобной отладки и набора программы. Посредством разработанной программы студентам предоставляется возможность изучить различные способы адресации, систему команд и устройство MC
68300.
Техническое задание
1.Назначение и цели разработки.
1.1. Смоделировать 32-разрядый микропроцессор фирмы Motorola МС 68300
на уровне программно-доступных объектов.
1.2. Цель работы – создать программную модель, используемую для начального знакомства с архитектурой МС 68300
и его системой команд, позволяющей отлаживать простые программы на языке мнемокодов (Ассемблера).
Характеристики объекта разработки.
2.Требования к изделию
.
2.1. Функциональные требования.
2.1.1. Не квалифицированные пользователи могут вводить данные по запросу компьютера.
2.1.2. Диалоговый режим.
2.1.3. Выполнение функций:
2.1.3.1. Запрет редактирования результатов обучения пользователям.
2.1.3.2. Возможность просмотра и непосредственного редактирования регистров данных и адреса, а также дампа ОЗУ.
2.1.3.3. Развитая система помощи, включающая информацию по процессору МС 68300
и его языку, а также информацию по программной модели.
Реклама

2.1.4.Разработанная система отладки, позволяющая пользователю легко определить ошибку ввода данных.
2.1.5. Возможность трассировки программ.
2.1.6. Поддерживание различных систем исчисления (двоичная, десятичная, шестнадцатеричная).
2.1.7. Наглядность и доступность интерфейса.
2.2. Требования к надежности.
2.2.1.Обеспечение сохранности данных в файле.
2.2.2. Надёжная работа программы, при условии стабильной работы операционной системы и соблюдении минимальных требований к аппаратным ресурсам.
2.3. Стандартный интерфейс WINDOWS - приложений.
3.Состав и содержание работ по созданию (развитию) системы.
3.1. Граф-дерево структуры системы.
3.2. Составление алгоритма будущей программы.
3.3. Написание текста программы по алгоритму.
3.4. Тестирование программы.
3.5. Компоновка всех документов в единое руководство.
4.Требования к документированию.
4.1. Техническое задание.
4.2. Текст программы – распечатка листинга программы.
4.3. Текст программы в объектно-ориентированной форме.
5. Источники разработки.
5.1. Internet. Сайты, посвящённые микроэлектронике, в частности www.Gaw.ru, раздел посвящённый микропроцессорам.
5.2. Жмакин А.П. Курс лекций по микропроцессорам.
5.3. Фаронов В.В. Delphi 5. Учебный курс, М., “Knowledge”, 2001 год.
5.4 Юров. В. Assembler., Санкт-Петербург, “Питер” 2000 г.
2. Постановка задачи
Целью данной работы является уяснение организации, принципов работы, системы команд микропроцессоров. Цель должна быть достигнута путём разработки программной модели микро-ЭВМ на базе 32 разрядного микропроцессора фирмы Motorola.
Программная модель должна продемонстрировать работу 32 разрядной ЭВМ фирмы Motorola. Программа работает в диалоговом режиме с пользователем, то есть существует возможность ввода исходных данных, просмотр промежуточных и конечных результатов.
Данное программное изделие должно наглядно моделировать процесс работы процессора, т.е. позволять вводить ассемблерный код программ с применением системы команд микропроцессора и допустимых способов адресации, и выводить результат обработки. Должна быть предусмотрена защита от некорректного ввода данных. Программное изделие должно обеспечить наглядную работу объекта моделирования, с возможностью изменения промежуточных результатов.
В функциональном отношении программное изделие должно представлять собой программу, разработанную с применением стандартов интерфейса операционной системы Microsoft Windows.
3. Выбор средств реализации
При постановке задачи на разработку данного программного изделия была выбрана система Windows в связи с широчайшим распространением, доступностью и наличием гибких средств разработки программного обеспечения под эту платформу, и отсутствием таковых под другие программные платформы в наличии.
При выборе средства разработки любой компилятор для системы Windows мог быть использован для написания модели. Из наиболее распространенных, таких как Microsoft Visual C++, Borland C++, Borland C++ Builder, Watcom C++, Borland Delphi, Symantec C++, Power Builder, был выбран компилятор Borland Delphi. Выбор обоснован широким распространением, удобством использования, высоким качеством генерируемого кода данной среды. Кроме того, несмотря на то, что Delphi является компилятором расширенного языка Pascal, программы, написанные на Delphi полностью совместимы с компилятором Borland C++ Builder, который не был применен из-за более высоких требований к аппаратным ресурсам.
4. Описание машины пользователя
Данный процессор реализует архитектуру, принятую в микропроцессорах семейства 68000, что позволяет использовать большой объем прикладного и системного программного обеспечения, созданного для этого семейства. Процессор CPU32 работает с 16-разрядной шиной данных и 24-разрядной шиной адреса (адресуемая память до 16 Мбайт), аналогично микропроцессорамМС68000.
Основным архитектурным принципом функционирования процессоров семейства 68000 является разделение их ресурсов и возможностей в зависимости от класса решаемых задач. Архитектура процессоров ориентирована на раздельное выполнение двух классов задач: управление работой самой микропроцессорной системы с помощью системного программного обеспечения (операционной системы - супервизора) и решение прикладных задач пользователя. В зависимости от выполняемой задачи процессор CPU32 имеет два режима функционирования:
- режим супервизора,
- режим пользователя.
В зависимости от режима при выполнении программ разрешается доступ ко всем ресурсам микроконтроллера или их части. В режиме супервизора разрешается выполнение любых команд, реализуемых процессором, и доступ ко всем регистрам. В режиме пользователя запрещается выполнение ряда команд и доступ к некоторым регистрам, чтобы ограничить возможности таких изменений состояния системы, которые могут помешать выполнению других программ или нарушить установленный супервизором режим работы процессора. Режим функционирования определяется значением бита S в регистре состояния процессора SR.
МП МС68300 имеет 32-битовую внутреннюю структуру и поэтому может выполнять арифметические и логические операции над 32-разрядными числами.
Технические средства МП 68300, используемые для программирования, показаны на рис. Регистры общего назначения объединены в два набора - регистры данных (D0-D7) и адресные регистры (A0-A7).
Регистры данных:
31 16 15 8 7 0
| D
0
|
| D
1
|
| D
2
|
| D
3
|
| D
4
|
| D
5
|
| D
6
|
| D
7
|
Регистры адреса:
31 16 15 8 7 0
Два указателя стека:
31 0
| Указатель стека пользователя
|
USP
|
| Указатель стека супервизора
|
SSP
|
Программный счётчик:
31 0
Регистр состояния:
15 8 7 0
Регистры данных Dn
В МП МС68300 программно доступны восемь регистров данных, обозначенных D0-D7. Каждый из них может быть использован как источник операнда, приемник операнда или как сам операнд. Регистром данных можно оперировать как байтом (8 бит), словом (16 бит) или длинным словом (32 бита). При битовых операциях используются только младшие 8 бит, а при операциях со словами-младшие 16 бит. Старшие биты в этих операциях не участвуют.
Регистры адреса Аn
Регистры адреса главным образом используются для получения адреса операнда выполняемой команды. Большая часть операций манипулирования данными не может выполняться с помощью адресных регистров. В адресных регистрах операции с байтами не разрешены.
Как показано на рисунке в набор регистров входят девять регистров адреса, два из которых используются как указатели стека: указатель стека супервизора (SSP-Supervisor Stack Pointer) и пользовательский указатель стека (USP-User Stack Pointer). Естественно, что в каждый момент времени процессор имеет доступ только к одному из регистров стека в зависимости от режима, в котором находится процессор. Таким образом адресный регистр А7 физически представляет собой два независимых регистра. В программах на ассемблере он может указываться как A7 и как SP. Процессор автоматически формирует указатель стека при вызове подпрограмм и возврате из них, а также при обработке прерываний.
Программный счетчик РС (Program Counter)
Как и любой другой МП, МС68300 имеет в своем наборе регистров программный счетчик РС.
После выборки команды из памяти программный счетчик всегда указывает на следующую выполняемую команду. В отличие от регистров общего назначения он не может быть явно определен как операнд ни в какой из команд, исключение составляет использование РС в качестве базового регистра в командах с индексной адресацией. При выполнении команд переходов в РС загружается адрес новой команды, которой передается управление. Для всех остальных команд значение РС увеличивается на длину выполняемой команды.
Несмотря на то, что счетчик команд и адресные регистры MC68300 32-разрядные, при обращениях к памяти на внешнюю адресную шину передаются только 24 младших бита адреса. По этой причине обеспечивается доступ только к 224 (16M) байт памяти. Модификации процессора МС68020, МС68030 и 68040 имеют 32-разрядную адресную шину и способны адресовать 4Г байт.
| 15 14
|
13
|
12 11
|
10 8
|
7 5
|
4
|
3
|
2
|
1
|
0
|
| T1-0
|
S
|
0 0
|
I2-0
|
0 0 0
|
X
|
N
|
Z
|
V
|
C
|
| CCR
|
Регистр состояния SR содержит два байта: системный байт и байт пользователя. Полностью регистр SR доступен только в режиме супервизора. В режиме пользователя доступны только младшие разряды (байт пользователя), которые образуют регистр условий CCR. Отдельные биты регистра CCR имеют следующее назначение:
С - признак переноса, принимает значение C=1 при возникновении переноса из старшего разряда обрабатываемых операндов;
V - признак переполнения, принимает значение V=1 в случае переполнения разрядной сетки при обработке операндов со знаком;
Z - признак нуля, принимает значение Z=1 при получении нулевого результата операции;
N - признак знака, принимает значение старшего (знакового) разряда результата операции: N=0 - положительное число, N=1 -отрицательное;
X - признак расширения, в большинстве случаев копирует признак С, но при выполнении некоторых операций эти признаки устанавливаются по-разному.
Биты системного байта регистра состояния SR, определяющие режимы функционирования процессора, имеют следующее назначение:
S-признак супервизора, при S=0 процессор работает в режиме пользователя, при S=1 - в режиме супервизора;
T1-0 - поле режима трассировки (пошаговый режим): при T1=1 процессор останавливается после каждой команды, при T0=1 - только после команд переходов и ветвлений, меняющих ход программы;
I2-0 - поле маски прерываний, определяет минимальный уровень приоритета для обслуживания запросов прерывания. Остальные биты регистра SR не используются или резервированы для последующих моделей процессоров.
При включении микроконтроллера происходит автоматическая установка начального состояния регистров. В регистре SR устанавливается значение бита S=1, и процессор начинает работать в режиме супервизора. Из памяти загружаются начальные значения содержимого программного счетчика PC и указателя стека. Если в процессе дальнейшей работы потребуется перевод процессора в режим пользователя, то с помощью команды MOVE to SR в регистр SR загружается новое содержимое, в котором бит S=0. Обратный перевод в режим супервизора производится при обслуживании запросов прерывания или возникновении исключительных ситуаций, а также в процессе установки процессора в начальное состояние (повторный запуск) при поступлении внешнего сигнала сброса или команды RESET.
Регистры VBR, SFC, DFC доступны только в режиме супервизора. В 32-разрядный регистр VBR заносится базовый адрес таблицы векторов исключений. Загрузка этого регистра производится командой MOVEC. При обслуживании исключений формируемое процессором значение Av=4Ne является относительным адресом (смещением), определяющим положение выбираемого вектора в таблице, которая может быть размещена в любом месте адресного пространства. В 3-разрядные регистры SFC,DFC с помощью команды MOVEC заносится код адресного пространства, который поступает на выводы FC2-0 микроконтроллера при выполнении команды MOVES. Таким образом обеспечивается расширение адресного пространства с помощью организации виртуальной памяти
Форматы данных
Процессор выполняет обработку битов, байтов, 16-разрядных слов, 32-разрядных длинных слов и двоично-десятичных чисел (1 байт = 2 десятичных разряда). Обрабатываемые данные - операнды могут располагаться в регистрах (данных или адреса) или оперативной памяти. Для выборки слова (байты B1-0) или длинного слова (байты B3-0) команда задает адрес старшего байта N, четный или кратный четырем. При этом слова и длинные слова размещаются таким образом, что младшие байты (разряды D7-0 данных) располагаются в ячейках памяти с большими адресами: N+1 или N=3 (рис.3.3). Такое размещение байтов в памяти от старшего к младшему соответствует естественному порядку их написания слева - направо. Этот порядок адресации байтов называется в зарубежной литературе "big-endian". Он отличается от порядка "little-endian", принятого компанией INTEL и рядом других производителей, когда размещение слова начинается с младшего байта, адрес которого служит адресом слова.
МП МС86300 имеет возможность доступа в памяти к байту (8 бит), слову (16 бит) и длинному слову (32 бита). В отличие от МП фирмы Intel (8086, 80286, 80386, 80486) в МП 68300 приняты следующие соглашения:
слова (длинные слова) могут размещаться только по четным адресам;
старшие байты слова (двойного слова) располагаются в ячейках с меньшими адресами;
адресом слова (двойного слова) считается его старший байт.
Таким образом, в соответствии с концепцией, принятой фирмой Моторола, слово размещается в памяти в двух соседних ячейках и начинается со старшего байта. Это означает, что при чтении слова, размещенного по адресу Х МС68300 считывает два соседних байта, причем байт по адресу Х интерпретируется как старший, а байт по адресу Х+1 как младший. Соответственно, длинное слово размещается в четырех смежных ячейках памяти, причем старший байт длинного слова находится по меньшему адресу.
Способы адресации
Процессор CPU32 реализует следующие способы адресации операндов:
- регистровая (операнд в регистре данных или адреса),
- косвенно-регистровая (операнд в ячейке памяти, адресуемой содержимым регистра адреса),
- косвенно-регистровая с постинкрементом (операнд в ячейке памяти, адресуемой содержимым регистра адреса, которое автоматически увеличивается после выборки операнда для адресации следующей ячейки),
- косвенно-регистровая с предекрементом (операнд в ячейке памяти, адресуемой содержимым регистра адреса, которое автоматически уменьшается перед выборкой операнда для адресации предыдущей ячейки),
- косвенно-регистровая со смещением (операнд в ячейке памяти, адрес которой является суммой содержимого регистра адреса и 16-разрядного смещения d16, заданного в команде),
- косвенно-регистровая с индексированием (операнд в ячейке памяти, адрес которой является суммой содержимого регистра адреса, индексного регистра и данного в команде 8-разрядного смещения d8),
- прямая (операнд в ячейке памяти, адрес которой задается числом Abs, указанным в команде),
- относительная (операнд в ячейке памяти, адрес которой является суммой текущего содержимого программного счетчика PC и данного в команде 16-разрядного смещения d16 или базового смещения bd),
- относительная с индексированием (операнд в ячейке памяти, адрес которой является суммой содержимого программного счетчика PC, индексного регистра и данного в команде 16-разрядного смещения d16 или 32-разрядного базового смещения bd),
- непосредственная (значение операнда Im дано в команде).
Форматы команд
Команды процессора МС68300 могут содержать от одного до пяти слов. Любая команда всегда расположена по четному адресу. Формат команды в общем виде показан на рисунке 1:
| Командное слово
(первое слово, определяющее операцию и способ адресации)
|
| Непосредственный операнд
(одно или два слова)
|
| Эффективный адрес источника
(одно или два слова)
|
| Смещение
(одно или два слова)
|
Рисунок 1.
Система команд
CPU
32
Процессор CPU32 выполняет набор из 139 команд, которые реализуют следующие группы операций:
- операции пересылки,
- арифметические операции,
- логические операции,
- операции сдвига,
- операции сравнения и тестирования,
- битовые операции,
- операции управления;
- операции условной установки байтов.
Таблица1 - Набор команд процессора CPU32
| Синтаксис ассемблера
|
Разрядность
|
Операция
|
Адресация
|
| ADD Dn, <EA>
|
B, W, L
|
<dst> + Dn -> <dst>
|
1,(3-9,13)
|
| ADD <EA> , Dn
|
B, W, L
|
Dn+ <src> - Dn
|
(1-14),1
|
| ADDA <EA>, An
|
W, L
|
<dst> + An -> An
|
(1-14),2
|
| ADDI # Im, <EA>
|
B, W, L
|
<dst> + Im -> <dst>
|
12,(1,3-9,13)
|
| ADDQ # Im, <EA>
|
B, W, L
|
<dst> + Im -> <dst>
|
12,(1-9,13)
|
| ADDX Dy, Dx
|
B, W, L
|
Dx + Dy + X -> Dx
|
1,1
|
| ADDX - (Ay),- (Ax)
|
B, W, L
|
<dst> + <src> + X -> <dst>
|
5,5
|
| SUB Dn, <EA>
|
B, W, L
|
<dst> - Dn -> <dst>
|
1,(3-9,13)
|
| SUB <EA>, Dn
|
B, W, L
|
Dn+ <src> -> <dst>
|
(1-14),1
|
| SUBA <EA>,An
|
W, L
|
An- <src> -> An
|
(1-14),2
|
| SUBI # Im, <EA>
|
B, W, L
|
<dst> - Im -> <dst>
|
12,(1,3-9,13)
|
| SUBQ # Im, <EA>
|
B, W, L
|
<dst> - Im -> <dst>
|
12,(1-9,13)
|
| SUBX Dy, Dx
|
B, W, L
|
Dx - Dy - X -> <dst>
|
1,1
|
| SUBX - (Ay), - (Ax)
|
B, W, L
|
<dst> - <src> - X -> <dst>
|
5,5
|
| NEG <EA>
|
B, W, L
|
O - <dst> -> <dst>
|
(1,3-9,13)
|
| NEGX <EA>
|
B, W, L
|
O - <dst> - X -> <dst>
|
(1,3-9,13)
|
| ABCD Dy, Dx
|
W
|
Dx + Dy + X -> Dx
|
1,1
|
| ABCD - (Ay), - (Ax)
|
W
|
<dst> + <src> + X -> <dst>
|
5,5
|
| SBCD Dy, Dx
|
W
|
Dx- Dy - X -> Dx
|
1,1
|
| SBCD - (Ay), - (Ax)
|
W
|
<dst> - <src> - X -> <dst>
|
5,5
|
| NBCD <EA>
|
W
|
O - <dst> - X -> <dst>
|
(1,3-9,13)
|
| MULS <EA>, Dn
|
W, L
|
Dn * <src> -> Dn
|
(1,3-14),1
|
| MULS.L <EA>, Dh-Dl
|
L
|
Dn * <src> -> Dn
|
(1,3-14),1
|
| MULU <EA>, Dn
|
W, L
|
Dn * <src> -> Dn
|
(1,3-14),1
|
| MULU.L <EA>, Dh-Dl
|
L
|
Dl * <src> -> Dh:Dl
|
(1,3-14),1
|
| DIVS <EA>, Dn
|
W, L
|
Dn / <src> -> Dn
|
(1,3-14),1
|
| DIVS.L <EA>, Dr:Dq
|
L
|
Dr:Dq / <src> -> Dr:Dq
|
(1,3-14),1
|
| DIVSL.L <EA>, Dr:Dq
|
L
|
Dq / <src> -> Dr:Dq
|
(1,3-14),1
|
| DIVU <EA>, Dn
|
W
|
Dn / <src> -> Dn
|
(1,3-14),1
|
| DIVU.L <EA>, Dr:Dq
|
L
|
Dr:Dq / <src> -> Dr:Dq
|
(1,3-14),1
|
| DIVUL.L <EA>, Dr:Dq
|
L
|
Dq / <src> -> Dr:Dq
|
(1,3-14),1
|
| CLR <EA>
|
B,W,L
|
0 -> <dst>
|
(1,3-9,13)
|
Таблица2 - Команды логических операций
| Синтаксис ассемблера
|
Разрядность
|
Операции
|
Адресация
|
| AND <EA>, Dn
|
B, W, L
|
Dn ^ <src> -> Dn
|
(1, 3 - 14), 1
|
| AND Dn, <EA>
|
B, W, L
|
<dst> ^ Dn -> <dst>
|
1, (1,3 - 9,13)
|
| ANDI # Im, <EA>
|
B, W, L
|
<dst> ^ Im -> <dst>
|
12, (1, 3 - 9,13)
|
| ANDI # Im, CCR
|
W
|
CCR ^ Im -> CCR
|
12, -
|
| ANDI # Im, SR
|
W
|
SR ^ Im -> SR
|
12, -
|
| OR <EA>, Dn
|
B, W, L
|
Dn <src> -> Dn
|
(1, 3 - 14), 1
|
| OR Dn, <EA>
|
B, W, L
|
<dst> Dn -> <dst>
|
1, (1,3 - 9,13)
|
| ORI # Im, <EA>
|
B, W, L
|
<dst> Im -> <dst>
|
12, (1, 3 - 9,13)
|
| ORI # Im, CCR
|
W
|
CCR Im -> CCR
|
12, -
|
| ORI # Im, SR
|
W
|
SR Im -> SR
|
12, -
|
| EOR Dn, <EA>
|
B, W, L
|
<dst> + Dn -> <dst>
|
1, (1, 3 - 9,13)
|
| EORI # Im, <EA>
|
B, W, L
|
dst> + Im -> <dst>
|
12, (1, 3 - 9,13)
|
| EORI # Im, CCR
|
W
|
CCR + Im -> CCR
|
12, -
|
| EORI # Im, SR
|
W
|
SR + Im -> SR
|
12, -
|
| NOT
|
B, W, L
|
<dst> -> <dst>
|
(1, 3 - 9.13)
|
Таблица3 -
Команды сдвигов
| Синтаксис ассемблера
|
Разрядность
|
Адресация
|
| ASL Dx, Dv
|
B, W, L
|
1, 1
|
| ASL # Ns, Dv
|
B, W, L
|
12, 1
|
| ASL <EA>
|
W
|
(3 - 9,13)
|
| ASR Dx, Dv
|
B, W, L
|
1,1
|
| ASR # Ns, Dv
|
B, W, L
|
12,1
|
| ASR <EA>
|
W
|
(3 - 9,13)
|
| LSL Dx, Dv
|
B, W, L
|
1,1
|
| LSL # Ns, Dv
|
B, W, L
|
12,1
|
| LSL <lEA>
|
W
|
(3 - 9,13)
|
| LSR Dx, Dv
|
B, W, L
|
1,1
|
| LSR # Ns, Dv
|
B, W, L
|
12,1
|
| LSR <lEA>
|
W
|
(3 - 9,13)
|
| ROL Dx, Dv
|
B, W, L
|
1,1
|
| ROL # Ns, Dv
|
B, W, L
|
12,1
|
| ROL <EA>
|
W
|
(3 - 9,13)
|
| ROR Dx, Dv
|
B, W, L
|
1,1
|
| ROR # Ns, Dv
|
B, W, L
|
12,1
|
| ROR <EA>
|
W
|
(3 - 9,13)
|
| ROXL Dx, Dv
|
B, W, L
|
1,1
|
| ROXL # Ns, Dv
|
B, W, L
|
12,1
|
| ROXL <EA>
|
W
|
(3 - 9,13)
|
| ROXR Dx, Dv
|
B, W, L
|
1,1
|
| ROXR # Ns, Dv
|
B, W, L
|
12,1
|
| ROXR <EA>
|
W
|
(3 - 9,13)
|
Таблица4 - Команды сравнения и тестирования.
| Синтаксис ассемблера
|
Разрядность
|
Операции
|
Адресация
|
| СMP <EA>, Dn
|
B, W, L
|
Dn - <src>
|
(1 - 14), 1
|
| СMP <EA>, An
|
W, L
|
An - <src>
|
(1 - 14), 2
|
| CMPI # Im, <EA>
|
B, W, L
|
<dst> - Im
|
12, (1, 3 - 11,13,14)
|
| CMPM (Av) +,(Ax) +
|
B, W, L
|
<dst> - <src>
|
4,4
|
| CMP2 <EA>, Rn
|
B, W, L
|
(Rn)<LB, (Rn)>UB
|
(3,6-11,13,14), (1,2)
|
| TST <EA>
|
B, W, L
|
<dst> - 0
|
(1, 3 – 9,13)
|
| TAS <EA>
|
B
|
<dst> - 0, 1 -> b7
|
(1, 3 - 14)
|
Таблица 5 - Команды битовых операций.
| Синтаксис ассемблера
|
Разрядность
|
Операции
|
Адресация
|
| BTST Dn, <EA>
|
B, L
|
bn -> Z
|
1, (1, 3 - 14)
|
| BTST # Nb, <EA>
|
B, L
|
bn -> Z
|
12, (1, 3 - 14)
|
| BSET Dn, <EA>
|
B, L
|
bn -> Z, 1 -> bn
|
1, (1, 3 - 9,13,14)
|
| BSET # Nb, <EA>
|
B, L
|
bn -> Z, 1 -> bn
|
12, (1, 3 - 9,13,14)
|
| BCLR Dn, <EA>
|
B, L
|
bn -> Z, 0 -> bn
|
1, (1, 3 - 9,13,14)
|
| BCLR # Nb, <EA>
|
B, L
|
bn -> Z, 0 -> bn
|
12, (1, 3 - 9,13,14)
|
| BCHG Dn, <EA>
|
B, L
|
bn -> Z, bn -> bn
|
1, (1, 3 - 9,13,14)
|
| BCHG # Nb, <EA>
|
B, L
|
bn -> Z, bn -> bn
|
12, (1, 3 - 9,13,14)
|
Таблица 6 - Команды управления и установки байтов.
| Синтаксис ассемблера
|
Операции
|
Адресация
|
| JMP <EA>
|
<dst> -> PC
|
(3, 6 - 11,13,14)
|
| JSR <EA>
|
SP - 4 -> SP, PC -> (SP), <dst> -> PC
|
(3, 6 - 11,13,14)
|
| RTS
|
(SP) -> PC, SP + 4 -> SP
|
|
| RTR
|
(SP) -> CCR, SP + Z -> SP, (SP) -> PC, SP + 4 -> SP
|
|
| Scc <EA>
|
Если (сс) выполняется, то 1 ... 1 -> <dst>,
если (сс) не выполняется, то 0 ... 0 -> <dst>
|
(1, 3 - 9,13,14)
|
Таблица 7 - Изменение признаков после выполнения команд
| Команды
|
X
|
N
|
Z
|
V
|
C
|
Примечание
|
| ABCD, SBCD, NBCD
|
+
|
?
|
*
|
?
|
+
|
X=С - десятичный перенос
|
| ADD, ADDI, ADDQ, SUB, SUBI, SUBQ, NEG
|
+
|
+
|
+
|
+
|
+
|
X=С - десятичный перенос
|
| ADDX, SUBX, NEGX
|
+
|
+
|
*
|
+
|
+
|
X=С - десятичный перенос
|
| MULS, MULU, DIVS, DIVU
|
-
|
+
|
+
|
+
|
0
|
| MOVE, MOVEQ, AND, ANDI,
OR, ORI, EOR, EORI, NOT, CLR,
EXT, TAS, TST
|
-
|
+
|
+
|
0
|
0
|
| CMP, CMPI, CMPM
|
-
|
+
|
+
|
+
|
+
|
| CMP2
|
-
|
?
|
+
|
?
|
+
|
| BTST, BSET, BCLR, BCHG
|
-
|
-
|
+
|
-
|
-
|
Z = bn (инверсия)
|
| ASL, ASR
|
+
|
+
|
-
|
+
|
+
|
V = 1 при изменении знака
|
| LSL, LSR
|
+
|
+
|
+
|
0
|
+
|
| ROL, ROR
|
-
|
+
|
+
|
0
|
+
|
| ROXL, ROXR
|
+
|
+
|
+
|
0
|
+
|
| CHK
|
+
|
+
|
+
|
+
|
+
|
| MOVE, ANDI, ORI, EORI to CCR или SR
|
+
|
+
|
+
|
+
|
+
|
В общем виде запись типовой двухадресной команды на языке ассемблера имеет следующий вид:
COP.x <src>, <dst>
где в качестве COP указывается мнемокод соответствующей команды, а вместо x ставится символ, определяющий разрядность операндов: B - байт, W - слово, L - длинное слово. Если после мнемокода отсутствует символ разрядности, то по умолчанию операндом служит слово.
Операнды условно обозначаются как <src> - источник, <dst> - приемник, причем в качестве приемника указывается операнд, на месте которого помещается результат операции. При записи конкретных команд в качестве <src>, <dst> указываются символические адреса операндов на языке ассемблера в соответствии с используемым способом их адресации. Для одноадресных команд в поле операндов дается один символический адрес, в безадресных командах адрес операнда в явном виде не задается. При непосредственной адресации вместо указывается значение операнда Im, перед которым ставится префиксный символ #.
Числа Im, d8, d16, bd, Abs.W, Abs.L в поле операндов могут даваться в различных системах счисления, которые определяются префиксным символом:
& - десятичное число,
% - двоичное число,
@ - восьмеричное число,
$ - шестнадцатиричное число.
При отсутствии префиксного символа число воспринимается как десятичное.
С целью повышения производительности в CPU32 организован трехступенчатый конвейер выполняемых команд. Контроль состояния конвейера обеспечивается с помощью выходных сигналов процессора:
IPIPE# - принимает значение 0 в первом такте выполнения каждой команды в конвейере;
IFETCH# - принимает значение 0 при загрузке очередной команды в конвейер, а также при освобождении конвейера (отсутствии команд).
Данные сигналы могут использоваться внешним анализатором для контроля текущего состояния процессора.
Ниже в этом разделе рассматриваются команды, выполняемые процессором CPU32. В таблицах для каждой команды дан ее синтаксис на языке ассемблера и указана разрядность операндов: фиксированная (указывается числом) или изменяемая (определяется символом B,W,L, который ставится после мнемокода команды). Операнды, адрес которых вычисляется в соответствии с заданным способом адресации, обозначены символами <EA>. При выполнении многих команд для вычисления EA можно использовать только определенные способы адресации.
Команды MOVE, MOVEA и MOVEQ
Команда MOVE, в зависимости от формата её операнда, может перемещать байт, слово или длинное слово из регистра в регистр, между регистром и памятью и между памятью и памятью. Эта команда может также перемещать слово в (из) регистра состояния и длинное слово между пользовательским указателем стека (USP) и регистром адреса. Когда USP определён как операнд, или регистр состояния (SR) - как приёмник операнда, команда становится привилегированной и, следовательно, не может быть выполнена в пользовательском режиме.
Команда MOVEA (move address) предназначена для инициализации адресного регистра. Только слово и длинное слово, как операнды, возможно перемещать непосредственно в адресный регистр. Для операции со словом, операнд-источник перед помещением в регистр адреса переводится в 32-х разрядную сетку с учётом знака.
Команда MOVEQ (move quick) - это укороченная форма команды перемещения непосредственного операнда в регистр данных. Непосредственный операнд ограничен диапазоном от -128 до 127. Под размерностью операции подразумевается длинное слово. Следовательно, 8-битный непосредственный операнд должен быть преобразован в 32-битовый знаковый перед перемещением его в приёмник, которым является регистр данных. Некоторые ассемблеры могут различать три формы: MOVE data, MOVEA и MOVEQ по операндам, т.к. каждая форма определяется своим единственным типом операнда. Для таких ассемблеров некоторые мнемоники команды MOVE могут быть использованы также успешно для MOVEA и MOVEQ, т. к. соответствующие коды операции ассемблируются согласно операнду.
Для иллюстрации работы команды MOVE, присвоим D1=56789ABC, A1=01020304 и CCR=0010001 установим перед выполнением команды. После того, как показанные ниже команды будут выполнены, мы получим следующие результаты:
MOVE #0,CCR На регистр или память нет воздействия,
N=0, Z=0, V=0, C=0, X=0
MOVE.W A1,D1 D1=56780304,
N=0, Z=0, V=0, C=0, X=1
MOVE D1,A1 A1=FFFF9ABC,
N=0, Z=0, V=0, C=1, X=1
MOVE #-10,D1 D1=FFFFFFF6,
N=1, Z=0, V=0, C=0, X=1
Команды MOVEM и MOVEP
Команда MOVEM (move multiple register) переносит слово или длинное слово между списком регистров и последовательно идущими участками памяти. В случае, когда слово перемещают в регистр, каждое слово памяти должно быть преобразовано в 32-х разрядную сетку с учётом знака перед загрузкой в соответствующий регистр. Каждый регистр, участвующий в перемещении, может быть указан в списке и отделён символом "/", возможно также указание в списке начального и конечного регистра, разделенных символом "-". В памяти выделенные регистры всегда располагаются так, что D0 переписывается по младшему адресу, D1 в следующий, ... , затем с A0 по A7, причем A7 записывается в самый верхний адрес памяти. При перемещении регистров в память адрес операнда памяти может определяться в зависимости от управляющего способа адресации или режимом с предекрементом. Для обратного перемещения эффективный адрес может быть определён в зависимости от управляющего способа адресации или режимом с постинкрементом.
Типовое применение команды MOVEM - это запись и восстановление регистров в стек при обращении к подпрограммам. Перед вызовом подпрограммы все регистры могут быть записаны в стек системы посредством выполнения команды
MOVEM.L D0-D7/A0-A6,-(A7)
При возврате в управляющую программу, эти регистры восстанавливаются к своему первоначальному виду командой
MOVEM.L (A7)+,D0-D7/A0-A6
Заметьте, что хотя команда MOVEM.L (A7),D0-D7/A0-A6 будет также восстанавливать содержимое записанных регистров, но указатель стека A7 при этом не будет обновлён с присвоением значения, которое было изначально в вершине стека.
Команда MOVEP (move peripherial data) предназначена для облегчения программного ввода/вывода. Множество интерфейсов ввода/вывода - 8-битные устройства. Для простоты связи между 16-битной адресной шиной и 8-битным устройством ввода/вывода, устройство соединяется с каждым младшим или старшим байтом шины данных. В случае соединения с младшим байтом, все внутренние регистры устройства доступны через последовательность нечётных адресов. В другой конфигурации все внутренние регистры доступны через последовательность чётных адресов. Команда MOVEP может осуществлять ввод/вывод данных из (в) двух (для операции со словом) или четырёх (для операции с длинным словом) последовательно расположенных регистров устройства ввода/вывода. Только косвенный регистровый способ адресации со смещением допускается для определения порта ввода/вывода. На Рис. 14 показаны два примера работы команды MOVEP.
Команды EXG и SWAP
Команда EXG (exchange) осуществляет обмен содержимого двух регистров, в то время как команда SWAP обменивает младшее слово в регистре данных со старшим словом. Подразумевается, что размерность операнда для EXG - длинное слово, для SWAP - слово.
Команды LEA и PEA
Команда LEA (load effective address) перемещает адрес операнда-источника (а не его содержимое) в адресный регистр - приёмник. Следовательно, команда
MOVEA.L #OPER,A1
эквивалентна команде
LEA OPER,A1
Команда PEA (push effective address) записывает адрес операнда-источника в стек системы. Эта команда обычно используется для передачи адресов параметра в подпрограмму через стек. Операндами-источниками для обеих команд LEA и PEA должны быть операнды памяти.
В качестве некоторой иллюстрации к описанным командам, предположим, что мы хотим записать несложную последовательность команд, которая будет перемещать 4 длинных слова из массива ABC в начало массива XYZ. Простая последовательность, выполняющая это, следующая:
MOVE.L ABC,XYZ
MOVE.L ABC+4,XYZ+4
MOVE.L ABC+8,XYZ+8
MOVE.L ABC+12,XYZ+12
Те же действия могут быть выполнены двумя командами:
MOVEM ABC,D0-D3
MOVEM D0-D3,XYZ
Ещё один способ иллюстрируется следующей последовательностью команд:
MOVEA.L #ABC,A1
MOVEA.L #XYZ,A2
MOVE.L (A1)+,(A2)+
MOVE.L (A1)+,(A2)+
MOVE.L (A1)+,(A2)+
MOVE.L (A1)+,(A2)+
В этом способе, использующем постинкрементный способ адресации, одна и та же команда MOVE.L повторяется для перемещения последующих элементов. Следовательно, эта последовательность команд может быть легче преобразована в итерационный цикл для перемещения большого числа элементов между двумя массивами.
Результатом проектирования является программная модель, наиболее точно реализующая все вышеперечисленные особенности микропроцессора MC
68300
. Особое внимание уделено способам адресации, в частности программная модель реализует 14 способов адресации предусмотренных в микропроцессоре, возможности ввода данных в различных системах счисления, в частности в системах по основанию 2, 10, 16. Общую структуру программы для наглядности можно представить на рисунке 2:
Ввод
данных
Рисунок 2 – Общая структура программы.
Модуль интерпретатора
реализует следующие функции:
- проверку на наличие ошибок в синтаксисе команд, введённых пользователем,
- приведение всех операндов к системе счисления с основанием 16,
- возможность просмотра эффективного адреса операндов (ЕА);
- приведение всех команд к форме, понятной обработчику.
Модуль обработки команд
, по желанию пользователя может осуществлять как выполнение всей программы, так и её пошаговую трассировку и осуществляет выполнение команд в соответствии с их мнемокодом.
После обработки команд, у пользователя есть возможность просмотра результата их выполнения, т.е. активным становится модуль интерфейса.
5. Интерфейс, органы управления
После запуска программы пользователь получает доступ к графическому интерфейсу, позволяющему осуществлять ввод, корректировку и вывод данных в диалоговом режиме (рис.1).
Программная модель поддерживает два режима работы: супервизора и пользователя, каждый из которых характеризуется своим множеством операций. После запуска программы появляется окно, позволяющее пользователю выбрать режим работы. В пользовательском режиме процессор работает с определёнными ограничениями. Хотя большинство команд микропроцессора выполняется одинаково в обоих режимах, некоторые команды, вызывающие особые действия в системе, в пользовательском режиме запрещены.
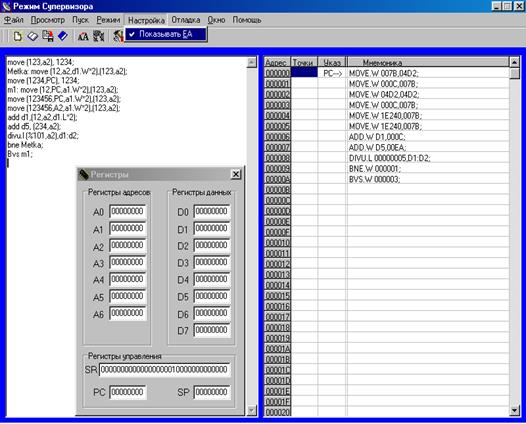
Рис. 3
Основной экран программы состоит из двух окон: окно для ввода текста программы (диалоговое окно) и окно отладчика, в котором отражается адрес команды в памяти, положение указателя стека, мнемоника команды и её машинный код. Программная модель обладает возможностью просмотра и корректировки промежуточных результатов выполнения микропроцессорных программ. Для этой цели в неё включены возможности просмотра содержимого регистров микропроцессора. Осуществляется это путём выбора соответствующего подменю в выпадающем меню PopUp (Просмотр/Регистры). Микропроцессор имеет 17 32-разрядных регистров (восемь регистров данных, семь адресных регистров и два указателя стека). Кроме того, в нём есть 32-разрядный счётик команд, в котором используются только младшие 24 разряда. Регистр состояния микропроцессора имеет 16 разрядов. Все эти регистры отображены в соответствующем окне (рис. 2). Закрыть окна просмотра регистров можно щёлкнув на системную иконку закрытия окна или же выбрав в меню пункт “Окно”, ”Закрыть все”
Переключение между режимами осуществляется путём выбора соответствующего режима в меню “Режим”. При переключении между режимами все данные, введённые пользователем должны быть сохранены, о чём появится соответствующая подсказка.
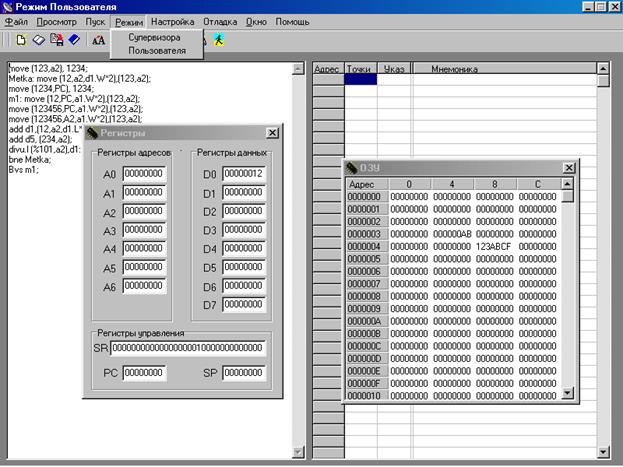
Рис. 4
Программная модель предоставляет пользователю возможность работы с файлами. Для этой цели в меню “Файл” необходимо выбрать нужное действие (Создание нового программного листа, открытие уже существующего, сохранение редактируемого, его закрытие). Здесь также существует возможность выхода из программы, все в дальнейшем необходимые данные должны быть предварительно сохранены.
В меню “Пуск” отражены команды, управляющие выполнением и отладкой микропроцессорных программ. Команда “Выполнить” выполняет программу из диалогового окна. Команда “Останов” прерывает выполнение программы. Команда “Ассемблирование” переводит мнемонику команд в ассемблерный код, который также отображается в соответствующем окне. Команда “Дизассемблирование” наоборот переводит машинный код в мнемонику, понятную пользователю. Команда “Трассировка” позволяет выполнять программу в пошаговом режиме, что может быть полезно для уяснения тонкостей алгоритма выполнения программы, а также может использоваться для устранения ошибок в программном коде.
В меню также существует пункт “Помощь”, где пользователь сможет найти всю интересующую его информацию по работе программной модели, устройству микропроцессора и его системе команд.
Для облегчения работы, наиболее часто выполняемые операции вынесены на панель инструментов.
6. Применение программной модели.
Программная модель дает широкие и удобные возможности для набора и отладки учебных программ (к примеру, может быть возможен одновременный просмотр всех регистров, памяти, ввод команд в мнемонических обозначениях, ассемблирование команд и т. д.).
Применение программной модели дает значительную экономию времени и сил, за счет более удобной отладки и набора программы. Посредством разработанной программы студентам предоставляется возможность изучить различные способы адресации, систему команд и устройство MC
68300.
Примером программы, предложенной для обучения, может служить программа вычисления максимального элемента массива значений, размером в слово (WORD).
move #10,D0 ; задаёт размерность массива 10->DO
M1: move (a1),d1 ; загружает содержимое ячейки памяти по адр. А1->D1
movea d3,A2 ; загружает содержимое регистра D3->A2
move d1,d3 ; D3->D1
sub A2,D1 ;D1-A2->D1
SPL Met ; если положительный результат, то переход на Met:
move a2,d3 ; A2-D3
Met: adda #2,a1 ; A1+2->A1
sub #1,D0 ;D0-1->D0
sne M1 ; если ненулевой результат, то переход на M1
move d3,d0 ; D3->D0.
Посредством наглядного интерфейса пользователь может просмотреть покомандно выполнение программы (так называемый режим трассировки), содержимое регистров и флагов и их изменение при выполнении команд. Существует также возможность быстрого выполнения команды, что обеспечивает возможность почти мгновенного получения результатов обработки.
7. Описание интерпретатора
При разработке программной модели этап лексической обработки текста исходной программы выделяется в отдельный этап работы компилятора, как с методическими целями, так и с целью сокращения общего времени компиляции программы. Последнее достигается за счет того, что исходная программа, представленная на входе компилятора в виде непрерывной последовательности символов, на этапе лексической обработки преобразуется к некоторому стандартному виду, что облегчает дальнейший анализ. При этом используются специализированные алгоритмы преобразования, теория и практика построения которых в литературе проработана достаточно глубоко.
В дальнейшем под лексическим анализом
будем понимать процесс предварительной обработки исходной программы, на котором основные лексические единицы
программы - лексемы:
ключевые (служебные) слова, идентификаторы, метки, константы приводятся к единому формату и заменяются условными кодами или ссылками на соответствующие таблицы, а комментарии исключаются из текста программы.
Выходами лексического анализа являются поток образов лексем-дескрипторов и таблицы, в последних хранятся значения выделенных в программе лексем.
Дескриптор
— это пара вида: (<тип лексемы>, <указатель>),
где <тип лексемы> — это, как правило, числовой код класса лексемы, который означает, что лексема принадлежит одному из конечного множества классов слов, выделенных в языке программирования;
<указатель> — это может быть либо начальный адрес области основной памяти, в которой хранится адрес этой лексемы, либо число, адресующее элемент таблицы, в которой хранится значение этой лексемы.
Количество классов лексем (т.е. различных видов слов) в языках программирования может быть различным. Наиболее распространенными классами являются:
- идентификаторы;
- служебные (ключевые) слова;
- разделители;
- константы.
Все они присутствуют в данной программной модели.
Могут вводиться и другие классы. Это обусловлено в первую очередь той ролью, которую играют различные виды слов при написании исходной программы и, соответственно, при переводе ее в машинную программу. При этом наиболее предпочтительным является разбиение всего множества слов, допускаемого в языке программирования, на такие классы, которые бы не пересекались между собой. В этом случае лексический анализ можно выполнить более эффективно. В общем случае все выделяемые классы являются либо конечными (ключевые слова, разделители и др.) — классы фиксированных для данного языка программирования слов, либо бесконечными или очень большими (идентификаторы, константы, метки) — классы переменных для данного языка программирования слов.
С этих позиций коды образов лексем (дескрипторов) из конечных классов всегда одни и те же в различных программах для данного компилятора. Коды же образов лексем из бесконечных классов различны для разных программ и формируются каждый раз на этапе лексического анализа.
В ходе лексического анализа значения лексем из бесконечных классов помещаются в таблицы соответствующих классов. Конечность таблиц объясняет ограничения, существующие в языках программирования на длины (и соответственно число) используемых в программе идентификаторов и констант. Необходимо отметить, что числовые константы перед помещением их в таблицу могут переводиться из внешнего символьного во внутреннее машинное представление. Содержимое таблиц, в особенности таблицы идентификаторов, в дальнейшем пополняется на этапе семантического анализа исходной программы и используется на этапе генерации объектной программы.
Первоначально в тексте исходной программы лексический анализатор выделяет последовательность символов, которая по его предположению должна быть словом в программе, т.е. лексемой. Может выделяться не вся последовательность, а только один символ, который считается началом лексемы. Это наиболее ответственная часть работы лексического анализатора. Пользователю необходимо учитывать, что метка (если она присутствует) начинается сначала строки (пробелы – если они есть – во внимание не принимаются), и от операций отделяется символом “:
”
Пример:
М: moveq #123,D1;
add D1,D2;
причём количество пробелов “:
”до, после “:
”, между операндами, между командой и операндами (и их наличие) может быть произвольным. Обязательной является “,” между приёмником и источником. В конце мнемоники команды в обязательном порядке должна стоять “;”, которая отделяет мнемокод от комментариев пользователя, которые интерпретатором игнорируются. В противном случае произойдёт выработка исключительной ситуации, о чём появится на экран соответствующее сообщение.
После этого проводится идентификация лексемы. Она заключается в сборке лексемы из символов, начиная с выделенного на предыдущем этапе, и проверки правильности записи лексемы данного класса.
Идентификация лексемы из конечного класса выполняется путем сравнения ее с эталонным значением. Основная проблема здесь — минимизация времени поиска эталона. В общем случае может понадобиться полный перебор слов данного класса, в особенности для случая, когда выделенное для опознания слово содержит ошибку. Уменьшить время поиска можно, используя различные методы ускоренного поиска:
- метод линейного списка;
- метод упорядоченного списка;
- метод расстановки и другие.
Для идентификации лексем из бесконечных (очень больших) классов используются специальные методы сборки лексем с одновременной проверкой правильности написания лексемы. При построении этих алгоритмов широко применяется формальный математический аппарат — теория регулярных языков, грамматик и конечных распознавателей. В данном случае – время поиска не актуально, так как оно и так не высоко из-за не очень большого количества команд микропроцессора.
При успешной идентификации значение лексемы из бесконечного класса помещается в таблицу идентификации лексем данного класса. При этом необходимо предварительно проверить: не хранится ли там уже значение данной лексемы, т.е. необходимо проводить просмотр элементов таблицы. Если ее там нет, то значение помещается в таблицу. При этом таблица должна допускать расширение. Опять же для уменьшения времени доступа к элементам таблицы она должна быть специальным образом организована, при этом должны использоваться специальные методы ускоренного поиска элементов.
После проведения успешной идентификации лексемы формируется ее образ — дескриптор, он помещается в выходной поток лексического анализатора. В случае неуспешной идентификации формируются сообщения об ошибках в написании слов программы.
В ходе лексического анализа осуществляются и другие виды лексического контроля, в частности, проверяется парность скобок, допустимость и правильность записи способов адресации.
Выходной поток с лексического анализатора в дальнейшем поступает на вход синтаксического анализатора. Имеется две возможности их связи:
- раздельная связь, при которой выход лексического анализатора формируется полностью и затем передается синтаксическому анализатору;
- нераздельная связь, когда синтаксическому анализатору требуется очередной образ лексемы, он вызывает лексический анализатор, который генерирует требуемый дескриптор и возвращает управление синтаксическому анализатору.
Второй вариант характерен для однопроходных трансляторов, который и реализуется в данной модели. Таким образом, процесс лексического анализа может быть достаточно простым, но в смысле времени компиляции оказывается довольно долгим. Больше половины времени, затрачиваемого компилятором на компиляцию, приходится на этап лексического анализа. Несмотря на это, данный способ позволяет успешно решать задачи, поставленные пользователем перед программой.
Заключение
Целью данной работы являлось изучение организации 32-разрядного микропроцессора фирмы Motorola. Данная цель была достигнута посредством написания программной модели данного микропроцессора.
В ходе работы большое внимание уделено функциональным особенностям объекта разработки, способам организации, системе команд, представлению исходных данных в различных системах исчисления. Данное программное изделие может быть использовано при обучении студентов. Наглядный интерфейс, простота в работе, широкие возможности позволяют лучше понять структуру микропроцессора. Объектно – ориентированные методы написания программной модели позволяют в дальнейшем усовершенствовать её структуру, превратив тем самым программную модель микропроцессора в программную модель микро ЭВМ.
Список использованных источников
1. Internet. Сайты, посвящённые микроэлектронике, в частности www.Gaw.ru, раздел посвящённый микропроцессорам.
2. Жмакин А.П. Курс лекций по микропроцессорам.
3. Фаронов В.В. Delphi 5. Учебный курс, М., “Knowledge”, 2001 год.
4 Юров. В. Assembler., Санкт-Петербург: Питер” 2000 г.
5. Фаронов В. В. Delphi 5. Учебный курс.-М.: «Нолидж», 2001. –608 с., ил.
6. Архангельский А. Я. Программирование в Delphi 4 – М.: ЗАО “Издательство БИНОМ”, 1999 г. – 768 с., ил.
7. Дантеман Джефф, Мишел Джим, Тейлор Дон. Программирование в среде Delphi: Пер с англ. / Дантеманн Джефф, Тейлор Джон. – К.:НИПФ “ДиаСофтЛтд.”, 1995. – 608 с.
8. Фёдоров А. Г. Создание Windows – приложений в среде Delphi: - М.: ТОО фирма “КомпьютерПресс”, 1995. – 287 с., с ил.
9. Проектирование аппаратных и программных средств переработки информации./ Методические указания для выполнения работы бакалавра. – КГТУ. Курск.
10. Лишнер Р. Секреты Delphi 2: Пер. с англ. – Киев НИФП “ДиаСофтЛтд”, 1996. – 800 с.
|

