В.М. Курейчик
Генетические алгоритмы (ГА) есть поисковые алгоритмы, основанные на механизмах натуральной селекции и натуральной генетики. Они реализуют «выживание сильнейших» среди рассмотренных структур, формируя и изменяя поисковый алгоритм на основе моделирования эволюции [1-7].
Основой для возникновения генетических алгоритмов считается модель биологической эволюции и методы случайного поиска [ 6, 7 ]. Один из известных специалистов в мире в области случайного поиска и стохастической оптимизации Растригин пишет [ 6 ]. Случайный поиск (СП) возник как реализация простейшей модели эволюции, когда случайные мутации моделировались случайнымишагами оптимального решения, а отбор “уходом” неудачных вариантов. Например, для прикладных оптимизационных задач
K(X) 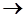  extr, extr,
здесь K- функционая, X- искомое решение, extr – экстремум (принимает
в зависимости от условий задачи минимальное или максимальное значение).
Тогда, например, для максимизации
K(X) min 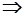 X*, X*,
где X* - наилучшее решение.
Это выражение реализуется с учетом ограничений и граничных условий. Эволюционный поиск согласно [6] – это последовательное преобразование одного конечного множества промежуточных решений в другое. Само преобразование можно назвать алгоритмом поиска или алгоритмом эволюции.
Растригин выделяет три особенности алгоритма эволюции:
– каждая новая популяция состоит только из “жизнеспособных” хромосом;
– каждая новая популяция “лучше” (в смысле целевой функции) предыдущей;
– в процессе эволюции последующая популяция зависит только от предыдущей [ 7 ].
Согласно [7] природа, реализуя эволюцию, как бы решает оптимизационную задачу на основе случайного поиска. Выделяется три основных бионических эвристики случайного поиска:
– клеточный СП,
– моделирование целесообразного поведения особей,
– моделирование передачи наследуемой биологической информации.
Законы эволюции отбирают все ценное и пригодное для эволюции и отметают в сторону, как мусор, как непригодное, все отсталое. Они не знают ни пощады ни состродания и производят оценку каждого лишь по степени пригодности или непригодности ею для дальнейшего развития.
Простой генетический алгоритм был впервые описан Гольдбергом на основе работ Холланда [1,2]. Механизм простого ГА (ПГА) несложен. Он копирует последовательности и переставляет их части. Предварительно ГА случайно генерирует популяцию последовательностей – стрингов (хромосом). Затем ГА применяет множество простых операций к начальной популяции и генерирует новые популяции. ПГА состоит из 3 операторов: репродукция, кроссинговер, мутация. Р е п р о д у к ц и я - процесс, в котором хромосомы копируются согласно их целевой функции (ЦФ). Копирование хромосом с «лучшим» значением ЦФ имеет большую вероятность для их попадания в следующую генерацию. Оператор репродукции (ОР), является искусственной версией натуральной селекции, “выживания сильнейших” по Дарвину. После выполнения ОР оператор кроссинговера (ОК) может выполниться в 3 шага. На первом шаге члены нового репродуцированного множества хромосом выбираются сначала. Далее каждая пара хромосом (стрингов) пересекается по следующему правилу: целая позиция k вдоль стринга выбирается случайно между l и длиной хромосомы меньше единицы т.е. в интервале (1,L-1). Длина L хромосомы это число значащих цифр в его двоичном коде. Число k, выбранное случайно между первым и последним членами, называется точкой ОК или разделяющим знаком.
Реклама

Механизм ОР и ОК. Он включает случайную генерацию чисел, копирование хромосом и частичный обмен информацией между хромосомами.
Генерация ГА начинается с репродукции. Мы выбираем хромосомы для следующей генерации, вращая колесо рулетки, такое количество раз, которое соответствует мощности начальной популяции. Величину отношения 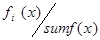 называют вероятностью выбора копий (хромосом) при ОР и обозначают называют вероятностью выбора копий (хромосом) при ОР и обозначают
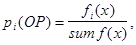 (1) (1)
здесь fi
(x)- значение ЦФ i-той хромосомы в популяции, sum f(x)- суммарное значение ЦФ всех хромосом в популяции. Величину (1) также называют нормализованной величиной.Ожидаемое число копий i-ой хромосомы после ОР определяют
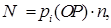 (2) (2)
где n- число анализируемых хромосом.
Число копий хромосомы, переходящее в следующее положение, иногда определяют на основе выражения
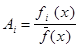 . (3) . (3)
Далее, согласно схеме классического ПГА, выполняется оператор мутации. Считают, что мутация - вторичный механизм в ГА.
Понятие "схема" (схемата), согласно Холланду, есть шаблон, описывающий подмножество стрингов, имеющих подобные значения в некоторых позициях стринга [8]. Для этого вводится новый алфавит {0,1,*}, где * - означает: не имеет значения 1 или 0. Для вычисления числа схем или их границы в популяции требуются точные значения о каждом стринге в популяции.
Реклама

Для количественной оценки схем введены 2 характеристики [1,2]: порядок схемы - О(H); определенная длина схемы - L(H). Порядок схемы - число закрепленных позиций (в двоичном алфавите - число единиц и нулей), представленных в шаблоне.
Предположим, что заданы шаг (временной) t, m примеров частичных схем H, содержащихся в популяции A(t). Все это записывают как m=m(H,t) - возможное различное число различных схем H в различное время t.
В течение репродукции стринги копируются согласно их ЦФ или более точно: стринг A(i) получает выбор с вероятностью, определяемой выражением (1).
После сбора непересекающихся популяций размера n с перемещением из популяции A(t) мы ожидаем иметь m(H,t+1) представителей схемы H в популяции за время t+1. Это вычисляется уравнением
m(H,t+1)=m(H,t) * n * f(H)/sum[ f(j) ], (4)
где f(H) – есть средняя ЦФ стрингов, представленных схемой H за время t.
Если обозначить среднюю ЦФ всей популяции как f*=sum[f(j)]/n, тогда
m(H,t+1)=m(H,t)*f(H)/f* . (5)
Правило репродукции Холланда: схема с ЦФ выше средней “живет”, копируется и с ниже средней ЦФ “умирает” [1].
Предположим, что схема H остается с выше средней ЦФ с величиной c?f*, где c-константа. Тогда выражение (5) можно модифицировать так
m(H,t+1)=m(H,t)*(f*+c*f*)/f*=(1+c)*m(H,t) (6)
Некоторые исследователи считают, что репродукция может привести к экспоненциальному уменьшению или увеличению схем, особенно если выполнять генерации параллельно [3-5].
Отметим, что если мы только копируем старые структуры без обмена, поисковое пространство не увеличивается и процесс затухает. Потому и используется ОК. Он создает новые структуры и увеличивает или уменьшает число схем в популяции.
Очевидно, что нижняя граница вероятности выживания схемы после применения ОК может вычислена для любой схемы. Так как схема выживает, когда точка ОК попадает вне "определенной длины", то вероятность выживания для простого ОК запишется
P(s)=1-O(H)/(L-1). (7)
Если ОК выполняется посредством случайного выбора, например, с вероятностью P(ОК), то вероятность выживания схемы определится
P(s)?1-P(ОК)*L(H)/(L-1). (8)
Допуская независимость репродукции (ОР) и ОК, получим [1]:
m(H,t+1) ? m(H,t) * f(H)/f* *[1-P(ОК) *
L(H)/(l-L)]. (9)
Из выражения (9) следует, что схемы с выше средней ЦФ и короткой L(H) имеют возможность экспоненциального роста в новой популяции.
Рассмотрим влияние мутации на возможности выживания. ОМ есть случайная альтернативная перестановка элементов в стринге с вероятностью Р(ОМ). Для того, чтобы схема H выжила, все специфические позиции должны выжить. Следовательно, единственная хромосома выживает с вероятностью (1-P(ОМ)) и частная схема выживает, когда каждая из l(H) закрепленных позиций схемы выживает.
1-L(H)*Р(ОМ). (10)
Тогда мы ожидаем, что частная схема H получает ожидаемое число копий в следующей генерации после ОР,ОК ОМ
m(H,t+1)>m(H,t)*f(H)/f**[1-Р(ОК)*l(H)/(l-1)-
l(H)*P(ОМ)]. (11)
Это выражение называется "схема теорем" или фундаментальная теорема ГА [1].
Ответа на вопрос, почему необходимо давать выживание схемам с лучшей ЦФ, нет или он расплывчатый, или каждый раз зависит от конкретной задачи.
Основная теорема ГА, приведенная Холландом, показывает ассимптотическое число схем "выживающих” при реализации ПГА на каждой итерации. Очевидно,что это число, конечно приблизительное и меняется в зависимости от вероятности применения ГА. Особенно сильное влияние на число "выживающих" и "умирающих" схем при реализации ПГА оказывает значение целевой функции отдельной хромосомы и всей популяции.
Во многих проблемах имеются специальные знания, позволяющие построить аппроксимационную модель. При использовании ГА это может уменьшить объем и время вычислений и упростить моделирование функций, сократить число ошибок моделирования.
ГА - это мощная стратегия выхода из локальных оптимумов. Она заключается в параллельной обработке множества альтернативных решений с концентрацией поиска на наиболее перспективных из них. Причем периодически в каждой итерации можно проводить стохастические изменения в менее перспективных решениях. Предложенные схемы эффективно используются для решения задач искусственного интеллекта и комбинаторно-логических задач на графах. ГА позволяют одновременно анализировать некоторое подмножество решений, формируя квазиоптимальные решения. Временная сложность алгоритмов зависит от параметров генетического поиска и числа генераций.
Список
литературы
Holland John H., Adaptation in Natural and Artificial Systems: An Introductory Analysis with Application to Biology, Control, and Artificial Intelligence. University of Michigan , 1975.
Goldberd David E. Genetic Algorithms in Search, Optimization and Machine Learning. Addison-Wesley Publishing Company, Inc. 1989, 412p.
Handbook of Genetic Algorithms, Edited by Lawrence Davis, Van Nostrand Reinhold, New York, 1991, 385p.
Курейчик В.М., Лях А.В. Задачи моделирования эволюции в САПР. Труды международной конференции (CAD-93), РФ - США, Москва, 1993.
Chambers L.D., Practical Handbook of Genetic Algorithms. CRS Press, Boca Ration FL, 1995, v. 1, 560 p., v. 2, 448 p.
Растригин Л.А. статистические методы поиска. М: Наука, 1968.
Эволюционные вычисления и генетические алгоритмы. Составители Гудман Э.Д., Коваленко А.П. Обозрение прикладной и промышленной математики, том 3, вып. 5, Москва, ТВП, 1996, 760с.
|
