| Министерство Образования Республики Беларусь
Белорусский Государственный Университет
Факультет прикладной математики и информатики
Кафедра математического обеспечения АСУ
Курсовая работа
студента 2 группы 3 курса
Бондаренка Алексея
Машинные словари
в задачах автоматической обработки текста
Руководитель
: Совпель И.В.
Минск 1999
Оглавление
1. Введение.¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼ 3
2. Виды МС.¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼ 4
3. Двуязычные МС.¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼ 6
4. Омонимия и кодирование.¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼7
5. Автоматизация построения словарей (постановка и решение задачи).¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼12
6. Заключение.¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼13
7. Литература.¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼¼ 14
1.Введение
В последнее время всё больше внимания уделяется задачам понимания естественного языка и автоматической переработки текста. Естественный язык (ЕЯ) является универсальным средством описания действительности и коммуникации с вычислительной системой, поэтому для упрощения взаимодействия пользователя и ЭВМ необходимо как можно плотнее приблизить язык общения к естественному. Эта проблема возникла по сути дела вместе с появлением компьютера, но реально ей занялись только в последние годы, когда развитие информационных систем позволило применять полученные ранее теоретические результаты на практике.
Реклама

Одним из основных компонентов любой системы автоматической переработки текста ЕЯ является машинный словарь (МС). Машинный словарь - это упорядоченное конечное множество лингвистической информации, представленное в виде некоторой структуры данных, удобной для размещения в памяти ЭВМ и снабженное процедурами автоматического поиска и ведения. Ясно, что вопросы, связанные с организацией хранения и реализацией поиска, корректировки и т.п. для МС, играют ключевую роль в производительности и эффективности проектируемой системы.
По характеру лексических единиц, включенных в словарь, МС подразделяются на словари основ (список основ и окончаний, позволяющий сократить объем занимаемой МС памяти, но усложняющий морфологический анализ и описание ЕЯ) и словари словоформ, состоящие из всех словарных форм данного ЕЯ. Словари словоформ требуют больше памяти для размещения, однако, морфологический анализ значительно упрощается. Нередко экономия памяти в словарях основ является неоправданной за счет громоздких и не всегда эффективных алгоритмов анализа, к тому же ресурсы современных ЭВМ позволяют хранить словари практически любых необходимых размеров, поэтому использование словарей словоформ предпочтительнее.
Построение словаря словоформ задача достаточно трудоемкая и естественно возникает проблема ее автоматизации. Для этой цели необходим некоторый инструментарий, который, руководствуясь определенными правилами, для каждого слова ЕЯ строит соответствующий ему список словоформ, при, желательно, минимальном участии со стороны пользователя. Состав такого инструментария, его функции существенно зависят от вида создаваемого МС, а также свойств самого ЕЯ.
2.Виды МС
Существует несколько классификаций МС по типам, одна из них это, упомянутая выше, классификация по характеру лексических единиц, входящих в словарь. Также можно привести классификацию по способу организации словника: МС делятся на частотные (словарные единицы упорядочены по убыванию частот), алфавитные, тезаурусы (единицы группируются по семантическим полям, понятийным группам и т.п.), конкордансы (группировка по ключевым словам).
Кроме того, структура словаря может быть разной в зависимости от исходного ЕЯ. Например, для флективно-бедных языков, в частности английского, при построении алфавитного МС словоформ, эффективной по степени сжатия и скорости обработки информации оказывается так называемая ассоциативная структура (АС). АС представляет собой дерево специального вида, каждый узел которого состоит из информационного поля, содержащего букву ЕЯ, и двух ссылок: "вниз" и "вправо". Построение такого дерева происходит по следующей схеме: для первого слова словаря строим вертикальный список (заносим в информационную часть букву, устанавливаем ссылку "вниз" на следующий узел и далее аналогично, конец списка отмечаем специальным символом и в последнюю ссылку заносим адрес семантико-грамматической информации о слове). При добавлении второго слова происходит последовательное сравнение букв слова с буквами в списке, и при первом несовпадении устанавливаем соответствующую ссылку "вправо" на узел, в который заносим несовпадающую букву. Для этого узла строим вертикальный список, используя оставшиеся буквы слова. Каждое следующее слово добавляется аналогично, с учетом того, что новая ссылка "вправо" добавляется лишь в случае несовпадения буквы слова со всеми буквами вертикального списка, в противном случае продолжаем поиск в поддереве, корень которого содержит такую же букву, как и текущая буква добавляемого слова.
Реклама

Для упрощения выделения и обработки словарных оборотов в организации алфавитного МС часто используется треугольная структура. В словарь наряду с отдельными словоформами включаются также и словарные обороты, затем записи сортируются в алфавитном порядке по первому слову, а подмножество записей имеющих одинаковые первые слова сортируется в порядке убывания количества содержащихся в них словоформ. При обработке текста треугольная структура обеспечивает выделение из текста наибольших по длине словарных оборотов.
Для русского и беларуского языков, являющихся флективно-богатыми языками, при построении МС словоформ более приемлемой является так называемая гнездовая структура. В данном случае под гнездом подразумевается совокупность словоформ одной основы или, что то же самое, множество всех грамматических форм некоторого основного слова. При использовании такой структуры, в памяти ЭВМ явно хранится лишь основное слово, а для остальных - информация о том насколько они отличаются от него (см. табл. 1). Это обеспечивает значительную экономию памяти наряду с небольшими потерями машинного времени при развертывании гнезда. Следует отметить, что особенно полезной данная структура может оказаться в многоязычной ситуации, когда исходный текст принадлежит одному ЕЯ, а выходной - другому.
Таблица 1
Представление гнезда словоформ
Список словоформ гнезда Представление гнезда после сжатия
перевод перевод
перевода 7а
переводом 7ом
переводе 7е
переводы 7ы
переводу 7у
переводам 7ам
переводами 9и
переводах 8х
переводить 7ить
переводил бы 8л бы
3. Двуязычные МС
 Особое место в задачах автоматической переработки текстов занимают двуязычные (бинарные) машинные словари, т.е. словари вида (
Lp,
Lq
)
,
где Lp,
Lq
- соответственно входной и выходной ЕЯ. В каждом таком словаре отдельному r-тому слову или словосочетанию языка Lp
ставится в соответствие некоторое конечное множество альтернативных эквивалентов языка Lq
: Особое место в задачах автоматической переработки текстов занимают двуязычные (бинарные) машинные словари, т.е. словари вида (
Lp,
Lq
)
,
где Lp,
Lq
- соответственно входной и выходной ЕЯ. В каждом таком словаре отдельному r-тому слову или словосочетанию языка Lp
ставится в соответствие некоторое конечное множество альтернативных эквивалентов языка Lq
:
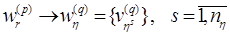
(1)
Бинарные МС составляют основу разработки систем машинного перевода и требуют эффективных методов своего представления в памяти компьютера, обеспечивающих максимальное устранение повторяемости данных и оптимальный доступ к ним. Понятно, что представление рассматриваемого класса МС в виде, например, совокупности отдельных списков, каждый из которых реализует соответствие типа (1), не является таковым. Так как, во-первых, имеет место большая избыточность данных, и, во-вторых, не учитываются особенности функционирования систем машинного перевода, основная из которых заключается в том, что обращение к выходному языку Lq
происходит только в конечной стадии процесса перевода.
Информационно-лингвистическую основу задачи построения интегрированной системы автоматического ввода, корректировки, редактирования и перевода текстов в двуязычной информационной среде составляют машинные словари входного и выходного языков. Их разработка включает следующие этапы:
1) сбор статистического материала из разных источников текстов выходного языка и составление картотеки всех словоупотреблений, которые встречаются в этих источниках;
2) создание на основе полученной картотеки словаря выходного языка;
3) развертывание для каждой лексической единицы всех ее грамматических форм;
4) перевод каждой лексической единицы с выходного языка на входной;
5) перенос словаря на машинные носители информации и последующая его корректировка.
4. Омонимия и кодирование
Слова с одинаковым буквенным составом, обозначающие разные понятия, называются омонимами
(греч. homos
- одинаковый и onуma, onoma
- имя). Омонимы надо отличать от многозначных слов. Когда все оттенки значения слова совпадают в его основном, общем значении, то в таком случае говорят о многозначности
слова. Когда же отдельные значения слова резко расходятся, отделяются от основного значения слова и утрачивают с ним связь, то возникает омонимичность, это значит, образуются новые самостоятельные слова - омонимы.
В зависимости от значения и образования омонимы делятся на два основные типа:
I. лексические, или простые омонимы;
II. морфологические, или производные омонимы.
К первому типу принадлежат слова, относящиеся к одной части речи и имеющие одинаковые формы словоизменений,
К другому типу омонимов относятся слова, которые по звуковому составу совпадают только в определённых грамматических формах. Они обычно принадлежат к разным частям речи. Такие омонимы называются омоформами
.
Существует несколько видов омонимии, например межкатегориальная (межродовая) и межсистемная (межъязыковая) (более подробно см. [2]), которые в свою очередь детализируются на подтипы и подвиды омонимии с разновидностями по роду и представляют серьезнейшую помеху при автоматическом переводе даже при близости таких языков как русский и беларуский.
Если рассматривать омонимию с точки зрения порождения и восприятия текста, то можно отметить следующее:
· для говорящего и пишущего омонимии нет, если автор специально не хочет использовать омонимы в каких-то специальных целях;
· для слушающего и читающего омонимии почти нет, так как ударение, контекст снимают практически все омонимичные ситуации;
· при машинной обработке текстов и при машинном переводе омонимия возрастает, так как при двух системных омонимиях возникает еще и межсистемная омонимия.
Единственным способом снятия омонимии в двух языках в плане грамматическом и лексическом является системное кодирование. Системный характер кода представляет следующие характеристики:
1) код должен быть экономным и в то же время избыточным; таким кодом является система-язык.
2) код должен снимать омонимию, т.е. быть однозначным
;
3) код должен быть простым и в то же время сопряженным, что дает экономичность коду.
В качестве такой системы на базе симметрии/асимметрии, так как язык-система является именно симметрично-асимметричной (иначе не было бы и омонимии как феномена, когда при симметричности формы имеется асимметрия разных значений), например, для русско-беларуской информационной среды может быть использована следующая симметрично-асимметричная матрица кодов.
Таблица 2
Матрица кодов
Падеж Время Наклонение
И. Р. Д. В. Т. П. Прош Наст Буд Пов.
Я 01 11 21 31 41 51 61 71 81 91
мы 02 12 22 32 42 52 62 72 82 92
ты 03 13 23 33 43 53 63 73 83 93
вы 04 14 24 34 44 54 64 74 84 94
он 05 15 25 35 45 55 65 75 85 95
они 06 16 26 36 46 56 66 76 86 96
она 07 17 27 37 47 57 67 77 87 97
-- 08 18 28 38 48 58 68 78 88 98
оно 09 19 29 39 49 59 69 79 89 99
-- 00 10 20 30 40 50 60 70 80 90
Примечания:
1. Код состоит из трех символов.
2. Первый символ обозначает часть речи, он отсутствует в матрице:
существительное = 1,
глагол = 2,
местоимение = 3,
наречие = 4,
союз = 5,
краткое страдательное причастие = 6,
прилагательное = 7,
частица = 8;
предлог = 9,
числительное = 0.
3. Два другие символа кодируют грамматические позиции рода, числа, падежа для существительных, прилагательных, причастий. Для глаголов - род, время, лицо. Для местоимений - падеж, род, лицо, число;
4. Первый символ 6 после кода глагола как части речи означает прошедшее время, символ 7 - настоящее время и символ 8 - будущее время, символ 9 - повелительное наклонение. Второй символ означает лицо и число. Вторые нечетные символы везде означают единственное число, четные символы - множественное.
5. Предлоги, управляющие только одним падежом, берут код соответствующего падежа:
9-1 - родительным,
9-2 - дательным,
9-3 - винительным,
9-4 - творительным,
9-5 - предложным.
Многопадежные предлоги требуют специального кодирования.
6. Первые символы при чтении по вертикали кодируют шесть падежей (от 0 до 5), три времени и одно наклонение (с 6 до 9). Вторые символы при чтении по горизонтали кодируют лицо, род, число - для местоимений и глаголов; число и род - для существительных, прилагательных и причастий.
7. Две последних строки пусты - этими кодами можно кодировать еще некоторые сложные позиции.
Матрица кодов позволяет однозначно закодировать местоимения, прилагательные, существительные, причастия и глаголы так, что грамматическая, межклассовая и внутриклассовая, внутрипарадигматическая и межпарадигматическая внутри одного класса омонимии снимаются кодом. Особенно это хорошо в случаях согласования в роде, в роде и числе, в роде, числе и падеже.
Однако, при таком кодировании возникает проблема - во многих случаях анализа окружения недостаточно для выбора одной из омонимичных форм, либо данные окружения являются противоречивыми. В исходном словаре на словоформу ее
имеются три кодировки в виде: 317, 337 и 737 с аналогичными кодами во втором языке, а так как алгоритмы корректировки будут отталкиваться от этого слова, то существует вероятность неправильного выбора слов из гнезда при переводе окружения.
Завершая описание системы кодов, можно сказать, что свои задачи она решает достаточно полно, так как содержащейся в коде информации достаточно и для более глубокой переработки текста. Избыточность информации позволяет рассчитывать на улучшение алгоритмов корректировки и, как следствие, повышение качества перевода.
Структура гнезда русско-беларуского словаря
ГНЕЗДО/НАЧАЛО
ОсноваРУС=ОсноваБЕЛ
оконч(1)РУС+КОД=оконч(1)БЕЛ+КОД
оконч(2)РУС+КОД=оконч(2)БЕЛ+КОД
...
оконч(Х-1)РУС+КОД=оконч(Х-1)БЕЛ+КОД
оконч(Х)РУС+КОД=оконч(Х)БЕЛ+КОД
ГНЕЗДО/КОНЕЦ
5. Автоматизация построения словарей
(постановка и решение задачи)
Рассмотрим подробнее основные алгоритмы и методы подготовки словника.
При построении системы машинного перевода деловой прозы с русского языка на беларуский (см. [2]), словник в своем окончательном варианте включал более 100.000 исходных слов, каждое из которых имеет гнездо словоизменений (около 12 словоформ в среднем). Каждая словоформа имеет свой код, содержащий лингвистическую информацию. Ввод такого словника одним человеком без дополнительной автоматизации занял бы, по меньшей мере, 25000 часов непрерывной работы. В связи с этим были созданы три программные системы для ввода словника:
- программа поиска и формирования групп слов с одинаковыми окончаниями (1);
- программа заполнения гнезд по группам (2);
- программа заполнения гнезд по признакам (3).
Словарь исходных форм был введен вручную. Далее исследования при помощи программы 1 выявили основные группы окончаний слов, имеющих в гнезде идентичное изменение и кодирование. Например, слова учитель, строитель, канавокопатель
изменяются и кодируются аналогично в обоих
языках и имеют группу (гласная)+тель
.
Далее программа 2 строила, исходя из группы, возможное гнездо, и оператор после беглого просмотра (в ходе работы было выяснено, что ошибки в кодах могут встречаться лишь в двух падежах) подтверждал или отменял выбор системы. Этим способом было создано около 70% словаря. Однако эти слова (наиболее легко формализуемые) имеют самую низкую частоту встречаемости в текстах. Таким образом, эти 70% словаря переводили лишь 5-15% текста! Следовательно, оставалась небольшая, но очень сложноформализуемая и сложнокодируемая часть словаря.
Программа 3 создавала гнезда, исходя не из окончаний (хотя тоже исследовала некоторые признаки), а из задаваемых оператором параметров для исходного слова. Например, слова стол
и слон
аналогичны в смысле кодирования. Но сгруппировать их по признаку гласная +согласная в конце
нельзя, потому что еще множество слов оканчиваются так же, но изменяются по-другому. Поэтому оператор относил их к группе существительное мужского рода, согласная в конце
вручную, а гнездо создавалось автоматически. С помощью этой программы удалось ввести еще 20% словаря. Обработка недостающих 10% производилась практически вручную.
Таким образом алгоритм задачи построения машинного словаря словоформ можно представить в виде следующей схемы:
1. Ввод исходных словоформ (вручную).
2. Выделение по окончаниям групп слов, которые кодируются идентично (автоматически).
3. Построение гнезд по группам (автоматически).
4. Выделение групп аналогично кодируемых слов исходя из их морфологии и состава (вручную).
5. Построение гнезд по группам (автоматически).
6. Добавление оставшейся части словаря (вручную).
6. Заключение
В данной работе была исследована роль машинных словарей в задачах автоматической обработки текста, их основные типы и особенности. Рассмотрено такое явление естественного языка как омонимия, показаны вызываемые ею сложности при обработке текста и предложена система кодирования для ее снятия. Поставлена задача автоматизированного построения машинного словаря на этапе развертывания основных грамматических форм. Разработаны алгоритмы ее решения, реализованные в виде трех программных модулей, каждый из которых на соответствующем этапе обеспечивает значительное ускорение построения словаря.
7. Литература
1. Совпель И.В.
Инженерно-лингвистические принципы, методы и алгоритмы автоматической переработки текста. - Мн.: Выш.шк.,1991.
2. Совпель И.В., Невмержицкая Г.П. и др.
Отчет о научно-исследовательской работе "Разработать программные средства машинного перевода текста".
|
