|
Работа с объектами большого объема в MS SQL и ADO
Алексей Ширшов
Введение
Эта статья появилась на свет только благодаря вашим не перестающим появляться вопросам типа: «Кто-нибудь может привести пример кода для работы с полями базы, содержащими картинки…используя ADO и Visual C++…», и тому, что мне лень на них отвечать.
Работа в MS SQL
Давайте сначала разберемся, как работать с большими объектами (LOB – large objects) на уровне базы данных. MS SQL Server поддерживает следующие типы больших объектов:
image – содержит бинарные данные переменной длины. Длина не может превышать 2 гигабайт.
text – содержит текстовые данные переменной длины в кодировке сервера (in code page of the server). Длина не может превышать 2 гигабайт.
ntext – содержит текстовые данные в Unicode-формате. Длина не может превышать 2 гигабайт.
Для хранения данных всех этих типов и низкоуровневой работы с ними SQL Server использует один и тот же механизм.
Физическое размещение больших объектов
MS SQL Server 2000 поддерживает два метода хранения больших объектов: первый метод оставлен ради совместимости со старыми версиями и не обеспечивает должной производительности в определенных случаях, по сравнению с новым методом. По умолчанию сервер работает в старом режиме.
При использовании старого метода сервер всегда размещает данные в отдельных страницах, а указатель на первую из них хранит непосредственно в строке данных.
| ПРИМЕЧАНИЕ
Точнее, в строке данных хранится указатель на корень B-tree, а не на какие-либо таблицы данных. Подробнее об этом, см. следующий раздел.
|
Используя новую стратегию, сервер может хранить часть данных непосредственно в строке таблицы. Это приводит к экономии памяти и увеличению производительности для LOB-ов небольшого размера.
Стратегия размещения по умолчанию
В качестве структуры хранения данных используется B-tree. В строке данных хранится 16-байтный указатель на корень дерева – структуру размером 84 байта. Если размер данных не превышает 32 Кб, в корневой структуре хранятся ссылки на блоки данных, расположенных на этой же или других страницах. Большие объекты хранятся на специальных страницах, на которых нельзя размещать никакие другие данные, кроме image, text и ntext. Однако данные этих типов из разных таблиц могут быть размещены на одной странице. Если общий размер данных не больше 64 байт, все данные сохраняются в корневой структуре.
Реклама

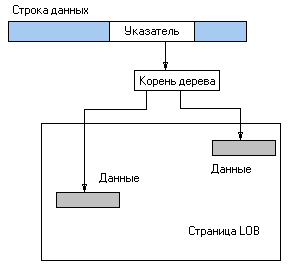
Рисунок 1.
Если размер данных больше 32 Кб, корень дерева ссылается на промежуточные узлы. Промежуточные узлы располагаются на отдельных страницах, которые не могут содержать какие-либо другие данные, или промежуточные узлы других таблиц или даже других колонок данной таблицы.
Улучшенная стратегия
В SQL Server 2000 появилась возможность использовать новый метод хранения больших объектов. В нем отсутствует 16-байтный указатель. В строке данных (data row) могут находиться как сами данные (в случае, если они меньше заданной величины), так и корень B-tree. Для каждой таблицы размер хранимых больших объектов можно задавать индивидуально с помощью процедуры sp_tableoption. Проверить режим размещения можно с помощью инструкции objectproperty с параметром TableTextInRowLimit. В следующем скрипте создается таблица (которую мы будем использовать на протяжении всей статьи) blob_test, затем проверяется режим размещения данных в этой таблице, и, наконец, устанавливается размер данных в строке (350 байт), что автоматически задает улучшенную стратегию размещения больших объектов в таблице.
| create table blob_test(id int identity, img image,txt text,ntxt ntext)
select case
when OBJECTPROPERTY(object_id('blob_test'), 'TableTextInRowLimit') = 0
then 'data outside the table'
else 'data in row'
end
sp_tableoption blob_test, 'text in row', 350
|
Вместо размера больших объектов в процедуру sp_tableoption можно было передать значение On. В этом случае размер устанавливается равным 250 байтам. Отключить размещение данных в строке можно, задав в качестве параметра значение 0 или Off. Максимальный размер данных в строке равен 7000 байт. Следующий рисунок иллюстрирует схему распределения данных при размере, превышающем 350 байт (для нашей таблицы).
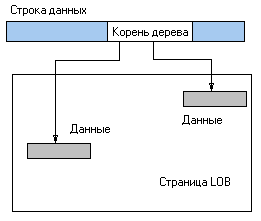
Рисунок 2
Если в строке данных присутствует расширяемое поле типа varchar или varbinary, то при его расширении, если общий размер строки превысит 8060 байт, часть данных из строки может быть выгружена на дополнительные страницы. Другими словами, остальные поля имеют приоритет перед LOB при нехватке пространства в строке данных. Вернем нашу таблицу в начальное состояние, так как следующие примеры рассчитаны на режим по умолчанию:
Реклама

| sp_tableoption blob_test, 'text in row', 'off'
|
После перевода таблицы в режим «данные в строке» сами данные в строку не переносятся, однако обратное действие вызывает немедленную операцию по переносу данных на отдельные страницы. При этом вся таблица полностью блокируется, а при большом количестве переносимых данных операция может занять длительное время.
Работа с большими данными
В работе с бинарными данными на уровне сервера большого смысла нет. Поэтому большинство примеров использует текстовые данные, хотя описываемые процедуры вполне сгодятся и для бинарных данных.
При работе с LOB можно использовать обычные операторы SQL (select, insert). Но иногда может понадобиться работать не с LOB целиком, а с его частями. Операторы работы с такими небольшими порциями довольно необычны для SQL тем, что в них используются указатели, смещения и другие низкоуровневые понятия.
Указатель представляет собой 16-байтовую переменную типа binary или varbinary. Это абстракция, указывающая на данные в конкретной колонке конкретной строки. Указатель получается путем вызова функции textptr, куда передается имя колонки. Он может быть равен NULL в том случае, если данных не существует. Если указатель равен NULL, вы не можете использовать функции READTEXT, WRITETEXT и UPDATETEXT. Указатель должен содержать какое-либо значение, поэтому для правильной работы этих функций в колонке изначально должны содержаться данные. Для простоты мы запишем туда следующие значения:
| insert into blob_test values(0x0,'My wife is Rosa','My son is Dima')
|
Значения для колонки типа image должны указываться в шестнадцатеричном формате, а для типов text и ntext это должны быть строки.
Для всех операторов DML, изменяющих данные, предыдущее значение всей строки сбрасывается в лог транзакций, однако для операторов WRITETEXT и UPDATETEXT это зависит от модели восстановления базы данных. Для модели Bulk logged данные не записываются в лог транзакций, вместо этого измененные страницы помечаются особым образом и записываются в архив лога транзакций при вызове соответствующей операции архивирования.
READTEXT
Этот оператор предназначен для блочного чтения больших текстовых и бинарных данных:
| READTEXT { table.column text_ptr offset size } [ HOLDLOCK ]
|
Параметры:
table.column – таблица и колонка;
text_ptr – указатель, полученный с помощью функции textptr;
offset – смещение, с которого начинается чтение данных;
size – размер считываемых данных.
Пример:
| declare @p binary(16)
select @p = textptr(txt)
from blob_test
where id = 1
select case
when @p is not null then '@p is valid'
else '@p is invalid'
end
if @p is not null
READTEXT blob_test.txt @p 0 4
|
Для поиска определенного текстового фрагмента нужно воспользоваться функцией PATINDEX. Она не так удобна, как хотелось бы (например, отсутствует возможность искать, начиная с определенной позиции), но вполне подходит для простых операций. В следующем примере выводится весь текст после слова is.
| declare @p binary(16)
declare @idx int,@l int
select @p = textptr(ntxt),
@idx = patindex('%is%',ntxt)-1,
@l = datalength(ntxt)/2-(patindex('%is%',ntxt)-1)
from blob_test
where id = 1
if @p is not null
readtext blob_test.ntxt @p @idx @l
|
Здесь хочется отметить две особенности: patindex возвращает смещение относительно начала строки в символах, считая от единицы, тогда как readtext воспринимает смещение от нуля, а datalength возвращает длину данных в байтах, так что для типа ntext мы должны поделить ее на два.
Давайте задумаемся, что произойдет, если кто-либо попытается изменить данные между операциями получения указателя и его использования. Ничего особенного, просто SQL Server выдаст ошибку 7123, говорящую, что была попытка использовать недействительный указатель. Одной проверки на NULL оказывается недостаточно. Для проверки указателя на действительность нужно воспользоваться функцией textvalid. Однако эта проверка не избавляет нас от проблемы, а лишь помогает выявить ее. Нам нужно, чтобы для данного указателя соблюдалось условие повторяемого чтения. Этого проще всего добиться, использовав в запросе хинт REPEATABLEREAD. Перепишем пример следующим образом:
| declare @p binary(16)
declare @idx int,@l int
begin tran
select @p = textptr(ntxt),
@idx = patindex('%is%',ntxt)-1,
@l = datalength(ntxt)/2-(patindex('%is%',ntxt)-1)
from blob_test (REPEATABLEREAD)
where id = 1
if textvalid(@p) = 1 and @idx >= 0 and @l > 0
readtext blob_test.ntxt @p @idx @l
commit
|
Теперь код написан «по всем правилам»:
на строку с идентификатором 1 накладывается коллективная блокировка, что предотвращает ее изменения из других транзакций;
смещение проверяется на отрицательные значения, так как функция patindex может вернуть 0, если не найдет шаблон;
длина считываемого текста также проверяется на неотрицательные значения.
Функция READTEXT не вернет вам всего объема данных. Размер максимально доступных данных, которые можно получить с помощью этой функции, равен @@textsize. По умолчанию это значение равно 4 Кб. Увеличить его можно с помощью функции set textsize. Для сброса переменной в значение по умолчанию установите размер, равный нулю.
WRITETEXT
Эта функция оставлена только для совместимости. Ее заменила более мощная UPDATETEXT, которую я рассмотрю позднее.
Вот синтаксис функции WRITETEXT:
| WRITETEXT { table.column text_ptr }
[ WITH LOG ] { data }
|
table.column – таблица и колонка;
text_ptr – указатель;
with log – игнорируется для SQL Server 2000;
Data – данные. Их размер не может превышать 120 Кб.
WRITETEXT полностью перезаписывает содержимое колонки. Для операции обновления также актуальна проблема действительности указателя. Но здесь уже недостаточно просто установить коллективную блокировку на обновляемую строку, так как это может привести к взаимоблокировке, например, если две транзакции одновременно получают коллективную блокировку и пытаются сконвертировать ее в монопольную. Для предотвращения подобной ситуации необходимо наложить блокировку обновления. В следующем примере производится обновление бинарных данных в первой строке:
| declare @p binary(16)
begin tran
select @p = textptr(img)
from blob_test (updlock)
where id = 1
if textvalid('blob_test.img',@p) = 1
writetext blob_test.img @p 0x4034
commit
|
Более подробно механизм блокировок в MS SQL Server и понятие уровней изоляции транзакций рассмотрены в предыдущем номере журнала.
UPDATETEXT
Эта более мощная функция обновления данных, чем WRITETEXT. Она также позволяет копировать данные из другой колонки (правда, нельзя указать размер копируемых в этом случае данных). Вот ее синтаксис:
| UPDATETEXT { table_name.dest_column_name dest_text_ptr }
{ NULL | insert_offset }
{ NULL | delete_length }
[ WITH LOG ]
[ inserted_data
| { table_name.src_column_name src_text_ptr } ]
|
table_name.dest_column_name – таблица и колонка.
dest_text_ptr – указатель на обновляемую область.
insert_offset – смещение в байтах, по которому будут изменяться данные. Если указывается NULL, данные будут добавлены к текущим данным.
delete_length – количество удаляемых байт. Если указывается NULL, данные будут удалены от смещения до конца. Для вставки данных необходимо указать значение 0.
with log – не имеет значения на SQL Server 2000.
inserted_data – вставляемые данные.
table_name.src_column_name – таблица и колонка, откуда данные вставляются.
src_text_ptr – указатель на исходные данные.
Следующие два вызова аналогичны:
| WRITETEXT table.column text_ptr inserted_data
UPDATETEXT table.column text_ptr 0 NULL inserted_data
|
Давайте рассмотрим пример. Предположим, я ошибся, набирая имя своей жены, и мне его сейчас необходимо заменить:
| declare @p binary(16)
declare @l int,@idx int
begin tran
select @p = textptr(txt),
@idx = patindex('%Rosa%',txt)-1,
@l = datalength(txt)-(patindex('%Rosa%',txt)-1)
from blob_test (updlock)
where id = 1
if textvalid(' blob_test.txt',@p) = 1
updatetext blob_test.txt @p @idx 4 '[Correct name]'
commit
|
Пожалуй, это все. Осталось еще одна тонкость.
Данные в строке
Читая Books Online, я наткнулся на такое предложение:
After you have turned on the text in row option, you cannot use the READTEXT, UPDATETEXT or WRITETEXT statements, to read or modify parts of any text, ntext, or image value stored in the table.
Вот это да! Т.е. я не могу пользоваться функциями, приведенными выше, если таблица находится в режиме «данные в строке»? Это неправда. Хотя вот такой пример может убедить кого угодно:
| declare @p binary(16)
declare @idx int,@l int
select @p = textptr(ntxt),
@idx = patindex('%is%',ntxt)-1,
@l = datalength(ntxt)/2-(patindex('%is%',ntxt)-1)
from blob_test (repeatableread)
where id = 1
if textvalid('blob_test.ntxt',@p) = 1
readtext blob_test.ntxt @p 0 14
|
Он выдает ошибку:
You cannot use a text pointer for a table with option 'text in row' set to ON.
Дело в том, что в режиме «данные в строке» указатель становить неверным сразу же по окончании транзакции. Так как SQL Server по умолчанию находится в режиме автоматического подтверждения транзакции (auto commit), указатель перестает быть действительным сразу после выполнения запроса. Чтобы наш пример заработал, необходимо включить обе операции (получение указателя и его использование) в одну транзакцию. Кроме этого, SQL Server автоматически устанавливает коллективную блокировку в момент получения указателя для данных в строке, так что не нужно прибегать к каким-либо хинтам. Эта блокировка снимется после того, как указатель станет недействительным. Как я сказал, это происходит в конце транзакции или при использовании следующих команд:
create clustered index
drop clustered index
alter table
drop table
truncate table
sp_tableoption(‘text in row’)
sp_indexoption
Можно и вручную сделать указатель недействительным с помощью вызова функции sp_invalidate_textptr.
Если транзакция выполняется на уровне изоляции READ UNCOMMITTED, полученный указатель можно использовать только в операциях чтения. Операция обновления закончится ошибкой 7106: You cannot update a blob with a read-only text pointer.
Работа с ADO
В этом разделе я приведу примеры работы с большими объектами, используя ADO.NET и ADO. Начнем с простого.
Чтение изображения и вывод на экран с помощью VB6
Хотя VB6 уже не так популярен, как несколько лет назад, на нем все же очень удобно писать определенного вида программы. Я иногда просто удивляюсь, как много VS.NET переняла из среды VB6, вплоть до иконок. Программируя на C#, вы по прежнему в меню Project можете найти пункт References, а в списке событий формы – события OnLoad. Очень удобная технологий DataBinding, которую я и буду использовать в примерах, также благополучно перекочевала в дотнет. На самом деле, очень много знаний из «прежней жизни» вы можете использовать в новой среде. Вот только я не понимаю, почему совместимости в ADO.NET уделено меньше всего внимания. Например, тот же самый DataBinding не работает со старым ADO. Вместо этого нужно «заливать» ADO-шный Recordset в DataSet, и использовать уже его. Ну, хватит лирики, давайте перейдем к предмету разговора.
Алгоритм вывода изображения на экран из БД может быть таким:
Подготовка соединения;
Открытие соединения;
Выборка данных в Recordset;
Связывание изображения с помощью встроенной технологии DataBinding.
Вот фрагменты кода из демонстрационного приложения, реализующие этот алгоритм.
| 'Задаем провайдера
conn.Provider = "sqloledb"
sb.SimpleText = "Connecting to DB..."
sb.Refresh
'Открываем соединение с БД
conn.Open "localhost", "user", "psw"
sb.SimpleText = "Ready"
sb.SimpleText = "Loading image..."
sb.Refresh
Dim ra As Long
'Создаем Recordset
Set rs = conn.Execute("select * from blob_test", ra)
'Производим связывание данных
Set imgImg.DataSource = rs
'Здесь выполняется фактическая пересылка данных
'и вывод изображения на экран
imgImg.DataField = "img"
sb.SimpleText = "Ready"
...
|
Если нужно просто сохранить графический объект в файл на диске, алгоритм несколько меняется. Вместо связывания данных нужно открыть файл на запись и записать в него данные. Однако все не так просто:
| 'Открываем файл как бинарный для записи
Open "c:\temp_img.bmp" For Binary Access Write As #1
Dim b() As Byte
'Выделяем память под массив
ReDim b(Len(rs.Fields("img").Value))
'Копирование данных в массив
b = rs.Fields("img").Value
'запись в файл
Put #1, , b
Close #1
|
В этом примере мне пришлось скопировать данные во временный буфер, так как инструкция Put добавляет к некоторым типам, экземпляры которых вы хотите сохранить, разные заголовки. Зачем это сделано, мне не совсем понятно; видимо разработчики хотели упростить реализацию сохранения/восстановления состояния переменных программы, однако это у них не очень хорошо получилось – для объектов эта инструкция не поддерживается. В случае сохранения таким образом:
| Put #1, , rs.Fields("img").Value
|
в файл запишется одному лишь богу известный заголовок, который будет мешать воспринимать этот файл как нормальный bmp. Поэтому я вынужден копировать данные в дополнительный массив байтов и сохранять уже его.
Для чтения графической информации из файла можно воспользоваться инструкцией Get.
Все идет хорошо до тех пор, пока не понадобится читать/писать бинарные данные небольшими блоками. Здесь на помощь приходят следующие методы:
AppendChunk – применим к полям с атрибутом adFldLong. Если метод вызван первый раз с тех пор, как вы редактируете текущее поле, данные перезаписываются. Иначе - метод добавляет данные к существующему значению. Другими словами, если вы только начали редактировать поле, вызвав метод AppendChunk, содержащиеся в нем до этого значения будут потеряны. Однако последующие вызовы метода будут добавлять данные к существующему значению. Как только вы начнете редактировать другое поле, возможность добавлять данные исчезнет. Этот метод также можно вызвать для параметров с установленным атрибутом adParamLong. Для параметров данные всегда добавляются к существующим.
GetChunk – применим к полям с атрибутом adFldLong. Возвращает заданное количество байтов с позиции, на которой закончилось предыдущее считывание данных. До тех пор, пока вы не перейдете к работе с другим полем, данные будут считываться последовательно. Если вы начали работать с другим полем, а потом вернулись к этому, данные снова будут читаться с нулевого смещения.
Эти два метода позволяют работать с порциями (chunks) данных. Например, вот такой код позволяет считать всего лишь первые 100 байт данных:
| Dim b() As Byte
b = rs.Fields("img").GetChunk(100)
|
Это все замечательно, но как же рекомендации MSDN использовать более гибкий объект Stream? Сейчас мы и до него доберемся.
Работа с изображением с помощью Stream на С++
Я выбрал С++, так как с VB6 мы уже поработали (хорошего помаленьку), и потому, что большинство вопросов касается именно С++. (На RSDN ходят настоящие индейцы.)
Алгоритм действий примерно тот же, что и в предыдущем примере:
Подготовка соединения.
Открытие соединения.
Выборка данных в Recordset.
Создание и открытие объекта Stream.
Чтение данных в Stream.
Работа со Stream.
Код реализации алгоритма приведен далее, а сейчас я бы хотел остановиться на шестом пункте, так как он выглядит слишком расплывчато, а мы, программисты, чужды неопределенности.
Объект Stream (поток) предназначен специально для работы с нереляционными и двоичными данными. Его возможности очень велики.
Он поддерживает интерфейс IStream, а значит, его можно спокойно пересылать по сети, сохранять в составной файл и загружать из него изображение.
Его можно сохранять/загружать в/из файла.
Его можно сохранять/загружать в/из текстовой строки.
Он может загружать данные из объекта Record или какого-либо ресурса по URL.
Его можно клонировать.
Для иллюстрации работы с объектом Stream приведу-таки пример на VB6, который сохраняет изображение в файл без использования инструкции Put:
| Dim stream As New ADODB.stream
'Тип потока - бинарный
stream.Type = adTypeBinary
'Открываем пустой
stream.Open
'Записываем значение поля img
stream.Write rs.Fields("img")
'Созраняем в файл
stream.SaveToFile "c:\temp_img.bmp"
|
Но хватит БЕЙСИКа (по крайней мере, VB6 в этой статье больше не встретится), перейдем к реализации описанного выше алгоритма.
| void ShowError()
{
CComPtr<IErrorInfo> ef;
GetErrorInfo(NULL,&ef);
CComBSTR desc;
ef->GetDescription(&desc);
USES_CONVERSION;
MessageBox(NULL,OLE2T(desc),_T("Error"),MB_ICONERROR);
}
void LoadPicture(IPicture** pic)
{
//Создаем соединение
HRESULT hr;
hr = conn.CoCreateInstance(L"ADODB.Connection");
if (FAILED(hr)){
ShowError();
return;
}
//Устанавливаем провайдера
hr = conn->put_Provider(CComBSTR(L"sqloledb"));
if (FAILED(hr)){
ShowError();
return;
}
//Открываем соединение
hr = conn->Open(CComBSTR(L"Data source=localhost"),CComBSTR(L"user"),CComBSTR(L"psw"));
if (FAILED(hr)){
ShowError();
return;
}
//Создаем Recordset
CComPtr<ADORecordset> rs;
hr = rs.CoCreateInstance(L"ADODB.Recordset");
if (FAILED(hr)){
ShowError();
return;
}
//Открываем Recordset
hr = rs->Open(CComVariant(L"blob_test"),CComVariant(conn));
if (FAILED(hr)){
ShowError();
return;
}
//Получаем Fields
CComPtr<ADOFields> flds;
hr = rs->get_Fields(&flds);
if (FAILED(hr)){
ShowError();
return;
}
//Получаем бинарное поле
CComPtr<ADOField> fld;
hr = flds->get_Item(CComVariant(L"img"),&fld);
if (FAILED(hr)){
ShowError();
return;
}
//Считываем значение
CComVariant v;
hr = fld->get_Value(&v);
if (FAILED(hr)){
ShowError();
return;
}
CComVariant vtMissing(DISP_E_PARAMNOTFOUND,VT_ERROR);
//Создаем Stream
CComPtr<ADOStream> stream;
hr = stream.CoCreateInstance(L"ADODB.Stream");
ATLASSERT(SUCCEEDED(hr));
//Задаем тип содержимого
hr = stream->put_Type(adTypeBinary);
if (FAILED(hr)){
ShowError();
return;
}
//Открываем Stream
hr = stream->Open(vtMissing);
if (FAILED(hr)){
ShowError();
return;
}
//Записываем данные в Stream
hr = stream->Write(v);
if (FAILED(hr)){
ShowError();
return;
}
//Устанавливаем внутренний курсор на начало
hr = stream->put_Position(0);
if (FAILED(hr)){
ShowError();
return;
}
//Загружаем картинку из Stream-а
CComQIPtr<IStream> strm(stream);
if (strm){
hr = OleLoadPicture(strm,0,TRUE,IID_IPicture,(void**)pic);
if (FAILED(hr)){
ShowError();
return;
}
}
}
|
Для того чтобы подобный код работал, необходимо подключить заголовочный файл adoint.h. Можно было воспользоваться директивой import для генерирования удобных оберток над соответствующими объектами и методами ADO. Пример получился бы проще, но тогда вы могли упустить кое-какие детали.
В примере производится загрузка изображения из базы данных в объект, поддерживающий интерфейс IPicture. Этот интерфейс позволит вам в дальнейшем выводит (рендерить) изображение или сохранять его на диск в различных форматах. Вывод изображения на экран делается примерно так (обработчик WM_PAINT):
| LRESULT CMainDlg::OnPaint(UINT /*uMsg*/, WPARAM /*wParam*/, LPARAM /*lParam*/, BOOL& /*bHandled*/)
{
CPaintDC dc(m_hWnd);
if (pic){
OLE_XSIZE_HIMETRIC SizeX;
OLE_YSIZE_HIMETRIC SizeY;
pic->get_Height(&SizeY);
pic->get_Width(&SizeX);
RECT rc;
GetClientRect(&rc);
//Собственно вывод
pic->Render(dc,0,0,rc.right,rc.bottom,0,SizeY,SizeX,-SizeY,NULL);
}
return 0;
}
|
Загружать файл в базу на С++ примерно так же просто, как и получать:
| #define TESTHR(hr) do{HRESULT _hr = hr; if (FAILED(_hr)){ \
IErrorInfo* ef = 0; GetErrorInfo(0,&ef); \
_com_raise_error(_hr,ef);}}while(false)
void UploadPicture2DB(PCWSTR szPath)
{
try{
CComVariant vtMissing(DISP_E_PARAMNOTFOUND,VT_ERROR);
//Загружаем картинку из файла
TESTHR(OleLoadPicturePath(szPath,NULL,NULL,0,IID_IPicture,(void**)&pic));
CComPtr<ADOStream> stream;
TESTHR(stream.CoCreateInstance(L"ADODB.Stream"));
TESTHR(stream->put_Type(adTypeBinary));
TESTHR(stream->Open(vtMissing));
CComQIPtr<IStream> strm(stream);
CComQIPtr<IPersistStream> ps(pic);
//Сохраняем картинку в объект ADODB.Stream
TESTHR(ps->Save(strm,TRUE));
CComPtr<ADORecordset> rs;
TESTHR(rs.CoCreateInstance(L"ADODB.Recordset"));
TESTHR(rs->Open(CComVariant(L"blob_test"),CComVariant(conn),adOpenStatic,
adLockOptimistic,adCmdTable));
//Добавляем новую пустую запись
TESTHR(rs->AddNew(vtMissing,vtMissing));
CComPtr<ADOFields> flds;
TESTHR(rs->get_Fields(&flds));
CComPtr<ADOField> fld;
TESTHR(flds->get_Item(CComVariant(L"img"),&fld));
TESTHR(stream->put_Position(0));
//Заливаем содержимое Stream-а в поле img
CComVariant v;
TESTHR(stream->Read(adReadAll,&v));
TESTHR(fld->put_Value(v));
//Сохраняем изменения в БД
TESTHR(rs->Update(vtMissing,vtMissing));
}
catch(_com_error& e){
MessageBox(e.Description(),_T("Error"),MB_ICONERROR);
}
return;
}
|
Чтобы максимально упростить пример, я использовал исключения вместо анализа кодов ошибок и стандартный класс _com_error, который определен в файле comutil.h.
Кроме этого, в примере нет кода открытия соединения, так как предполагается, что в момент вызова этой функции соединение с БД уже открыто (глобальная переменная conn).
При чтении данных типа text или ntext, тип варианта будет VT_BSTR. Я не думаю, что с ним могут возникнуть какие-либо проблемы.
| ПРИМЕЧАНИЕ
В случае бинарных данных тип варианта VT_ARRAY|VT_UI1.
|
Теперь давайте рассмотрим метод добавления бинарных данных в базу с помощью хранимых процедур.
Хранимые процедуры и ADO.NET
Наша процедура будет выглядеть следующим образом:
| create proc AddBlob(@img image)
as
insert into blob_test(img) values(@img)
|
К счастью, в ADO.NET работа с потоками не слишком изменилась (их по-прежнему нужно откручивать назад).
Алгоритм загрузки графического файла с диска в базу может быть таким:
Получаем имя файла.
Открываем соединение.
Создаем объект FileStream.
Читаем данные из файла.
Создаем объект SqlCommand для вызова хранимой процедуры.
Одному из параметров передаем считанные данные.
Вызываем метода ExecuteNonQuery объекта SqlCommand.
Параметры соединения с базой данных можно настроить в окне дизайнера, поэтому в коде этого делать не придется, нужно лишь вызвать функцию Open без параметров – и соединение будет установлено.
| ofd1.Filter = "(*.bmp)|*.bmp"
If ofd1.ShowDialog() = DialogResult.OK Then
sb.Text = "connecting to database..."
sb.Refresh()
'Если соединение не открыто, открываем
If conn.State <> ConnectionState.Open Then
conn.Open()
End If
sb.Text = "loading image..."
sb.Refresh()
Dim stream As New FileStream(ofd1.FileName, FileMode.Open)
Dim b() As Byte
ReDim b(CInt(stream.Length))
'Чтение данных из файла
stream.Read(b, 0, CInt(stream.Length))
'Создание и подготовка к вызову хранимой процедуры
Dim cmd As New SqlClient.SqlCommand("AddBlob", conn)
With cmd
.CommandType = CommandType.StoredProcedure
.Parameters.Add("@img", SqlDbType.Image)
With .Parameters("@img")
.Direction = ParameterDirection.Input
.Value = b
End With
'Вызов хранимой процедуры
.ExecuteNonQuery()
End With
sb.Text = "Ready"
End If
|
Все выглядит достаточно просто, и если учитывать, что весь мусор уберет GC, жизнь становится совсем легкой.
А что, если у вас уже есть изображение (скажем, в объекте PictureBox) и вам нужно сохранить его в базу? В этом случае нужно использовать другой поток – MemoryStream. Вот как это может быть сделано:
| sb.Text = "connecting to database..."
sb.Refresh()
'Если соединение не открыто, открываем
If conn.State <> ConnectionState.Open Then
conn.Open()
End If
sb.Text = "loading image..."
sb.Refresh()
'Создание и подготовка к вызову хранимой процедуры
Dim cmd As New SqlClient.SqlCommand("AddBlob", conn)
cmd.CommandType = CommandType.StoredProcedure
'Сохранение изображения в поток в памяти в формате BMP
Dim stream As New MemoryStream()
img1.Image.Save(stream, Imaging.ImageFormat.Bmp)
stream.Seek(0, SeekOrigin.Begin)
'Подготовка параметров
cmd.Parameters.Add("@img", SqlDbType.Image)
With cmd.Parameters("@img")
.Direction = ParameterDirection.Input
'Воспользуемся удобным методом ToArray. Жалко что его нет у FileStream-a
.Value = stream.ToArray()
End With
'Вызов хранимой процедуры
cmd.ExecuteNonQuery()
sb.Text = "Ready"
|
Теперь рассмотрим случай, когда нужно извлекать изображение из базы с помощью ADO.NET. Последовательность действий может быть такой:
Открыть соединение.
Подготовить команду (SqlCommand).
Заполнить SqlDataReader – аналог ADO Recordset в очень урезанном варианте.
Считать данные в MemoryStream.
Загрузить Image из потока.
Перед чтением данных из DataReader-а необходимо вызвать метод Read. Вот реализация:
| sb.Text = "connecting to database..."
sb.Refresh()
'Установка соединения
If conn.State <> ConnectionState.Open Then
conn.Open()
End If
sb.Text = "Loading image..."
sb.Refresh()
'Подготовка запроса на выборку данных
Dim cmd As New
SqlClient.SqlCommand("select img from blob_test where id = 3", conn)
'Создание и заполнение объекта DataReader
Dim reader As SqlDataReader = cmd.ExecuteReader()
Dim ms As New MemoryStream()
'Переход на первую строку
reader.Read()
Dim bb() As Byte
bb = reader.Item("img")
'Запись данных в поток в памяти
ms.Write(bb, 0, CInt(bb.Length))
ms.Seek(0, SeekOrigin.Begin)
'Загружаем графическое изображение в Image
pb.Image = Image.FromStream(ms)
sb.Text = "Ready"
|
Если нужно читать данные порциями, а не целиком, как это сделано в примере, воспользуйтесь методом GetBytes, который аналогичен ADO-методу GetChunk. Однако если объем данных очень велик, это не сильно поможет, так как они передаются клиенту все сразу в момент вызова метода Read. Для того чтобы данные передавались на клиента только по запросу, необходимо передать в качестве параметра метода ExecuteReader флаг CommandBehavior.SequentialAccess. В этом случае данные будут считываться непосредственно в момент вызова GetBytes.
| ПРИМЕЧАНИЕ
Для этого флага есть одно замечание. Если вы выбираете несколько полей, считывать их значения вы должны в той последовательности, в которой они возвращаются из базы. Видимо поэтому флаг называется «Последовательный доступ».
|
Я знаю, что многие не любят хранимые процедуры. Действительно, для использования хранимых процедур вы должны быть более-менее знакомы с T-SQL и знать общие принципы работы с реляционными БД. Кроме этого, считается, что архитектура, в которой слишком большой упор сделан на вынесение логики на уровень SQL Server-а, имеет ряд недостатков: плохое масштабирование, сложное сопровождение и отладка. Отчасти все это правда, однако лично я все же стараюсь использовать хранимые процедуры везде, где возможно, и лишь в тех случаях, когда бизнес-логика действительно сложна и требует взаимодействия нескольких бизнес-компонентов, отказываюсь от их использования. Тем, кто не хочет использовать хранимые процедуры для обновления больших объектов, я советую прочитать статью  http://support.microsoft.com/default.aspx?scid=kb;en-us;Q309158&ID=kb;en-us;Q309158, в которой излагается метод чтения и записи больших объектов с помощью DataSet. http://support.microsoft.com/default.aspx?scid=kb;en-us;Q309158&ID=kb;en-us;Q309158, в которой излагается метод чтения и записи больших объектов с помощью DataSet.
Последнее, на чем я бы хотел остановиться, и что вызывает наибольшее количество проблем у начинающих программистов это работа с большими объектами в Oracle. Традиционно этот вопрос довольно сложен: в про-дотнетовскую эру доступ к СУБД Oracle с помощью OLEDB-провайдеров в основном обеспечивали две библиотеки: MSDAORA и OraOLEDB.
Провайдер MSDAORA – предоставлял слабый сервис (нельзя было, например, узнать количество строк в выборке) и не позволял работать с большими объектами в принципе. Единственным достоинством данного провайдера является то, что он входит в стандартный пакет MDAC – Microsoft Data Access Components.
Провайдер OraOLEDB – родной провайдер, который предоставлял большую функциональность, чем MSDAORA, и позволял работать с большими объектами.
| ПРИМЕЧАНИЕ
В Oracle, как и в MS SQL, большие текстовые данные отличаются от больших бинарных данных. Первые называются CLOB и NCLOB – Character Large OBjects, вторые – BLOB – Binary Large OBjects. Аналогию с типами MS SQL провести несложно.
|
Получать и изменять данные с помощью объекта Recordset можно точно так же, как и в случае MS SQL Server-а. Пример я приводил выше. Единственная проблема связана с передачей больших объектов в качестве параметров хранимых процедур. Для того чтобы это работало, необходимо в объекте Command установить динамический параметр SPPrmsLOB в TRUE.
Я не буду подробно и с примерами останавливаться на работе с этими провайдерами, вместо этого сосредоточившись на управляемом ADO.NET провайдере. Если у вас будут вопросы, обратитесь к документации или, если совсем плохо будет, задайте вопрос в нашем форуме по базам данных.
Провайдер для ADO.NET не поставляется с .NET Framework 1.0, его нужно устанавливать вручную. Скачать последнюю версию можно по адресу http://www.microsoft.com/downloads/details.aspx?familyid=4f55d429-17dc-45ea-bfb3-076d1c052524&languageid=f49e8428-7071-4979-8a67-3cffcb0c2524&displaylang=en.
Вводную информацию об использовании этого провайдера в ASP.NET-приложениях можно получить из статьи http://msdn.microsoft.com/vstudio/using/building/default.aspx?pull=/library/en-us/dndotnet/html/manprooracperf.asp.
Следующий пример демонстрирует методы работы с большими объектами с помощью управляемого провайдера. Для его правильной работы вам необходимо подключить сборку System.Data.OracleClient.dll.
| Sub FillDBFromStream(stream as Stream, UserName as String)
'Открываем соединение
Dim con As New OracleClient.OracleConnection("server=srv;Uid=u;pwd=p")
'Создаем запрос с одним параметром username
Dim da As New OracleClient.OracleDataAdapter("select *
from USERS_STATE where USERNAME = :username", con)
'Добавляем параметр и устанавливаем его значение
da.SelectCommand.Parameters.Add("username", Data.OracleClient.OracleType.VarChar).Value = UserName
Dim ds As New DataSet()
'Объект CommandBuilder необходим для обновления данных
Dim cb As New OracleClient.OracleCommandBuilder(da)
'Производим выборку
da.Fill(ds, "UState")
'Считываем данные из потока во внутренний массив
Dim b() as Byte
ReDim b(CInt(ms.Length))
stream.Read(b, 0, CInt(stream.Length))
'Если выборка пуста, создаем новую запись
If ds.Tables("UState").Rows.Count = 0 Then
'Создание записи
Dim dr As DataRow = ds.Tables("UState").NewRow()
dr("username") = UserName
dr("b_state") = b
'Добавление записи
ds.Tables("UState").Rows.Add(dr)
Else
'Обновление записи
Dim dr As DataRow = ds.Tables("UState").Rows(0)
dr("b_state") = b
End If
'Изменения записываем в базу
da.Update(ds, "UState")
End Sub
|
Надо сказать, что этот способ будет работать, только если в таблице имеется первичный ключ. В моем случае, логичнее всего он смотрится на поле username. При отсутствии ключа в момент выполнения команды Update вы получите следующую ошибку:
| Dynamic SQL generation for the UpdateCommand is not supported against a SelectCommand that does not return any key column information.
|
В документации по Oracle утверждается, что обновление данных лучше производить в явных транзакциях.
| ПРИМЕЧАНИЕ
По умолчанию соединение открывается в режиме неявной транзакции, в котором транзакция начинается в момент выполнения первой команды после окончания предыдущей транзакции. Этот режим аналогичен установке SET IMPLICIT_TRANSACTIONS ON в MS SQL Server.
|
Это связано с тем, что транзакция, в контексте которой производится обновление, автоматически подтверждается в момент выполнения команды Update. Так что если вы затем захотите отменить изменения – это вам так просто не удастся сделать. Проблема решается с помощью объекта Transaction, пример использования которого, как и пример сохранения больших данных с помощью хранимых процедур, можно найти по адресу http://support.microsoft.com/default.aspx?scid=kb;EN-US;Q322796.
Ну вот, пожалуй, и все. Буду рад, если эта статья помогла вам в работе с большими объектами.
|
