Министерство образования и науки Украины
ПОЯСНИТЕЛЬНАЯ ЗАПИСКА
к курсовому проекту
на тему: "Методы сжатия цифровой информации. Метод Лавинского"
по курсу "Кодирование и защита
информации"
2004
Содержание
Введение
1. Постановка задачи
2. Обзор существующих методов решения задачи
2.1 Сжатие и кодирование информации в информационно вычислительных комплексах (ИВК)
2.2 Сжатие с восстановлением
2.3 Методы сжатия цифровой информации с повторяющимися фрагментами
3. Выбор и обоснование решения задачи
4. Теоретическое обоснование метода Лавинского
5. Программное обеспечение и информационный выбор метода
Заключение
Библиографический список
Приложение А
Приложение Б
Введение
В наши дни все большее распространение получает обработка и хранение информации при помощи ЭВМ. При этом одной из важнейших задач является сохранение ее целостности, т.е. защита от потери данных, как при их передаче, так и в некоторых случаях при хранении.
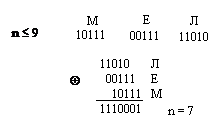
Метод Лавинского относится к простейшим методам сжатия информации (числовых массивов) и он осуществляет сжатие путем уменьшения разрядности числа (исходного). Метод тем лучше функционирует, чем больше массив и разность между числами в нем составляет малую величину.
1. П
остановка задачи
Составить программу сжатия по методу Лавинского, показать её возможности на выбранном Вами примере.
Программный продукт предусматривает сжатие массива, прочитанного из файла, по методу Лавинского, т.е. уменьшения разрядности чисел содержащихся в исходном файле. Это достигается путем преобразования символов файла в биты и запись их в новый файл.
Деархивация строится на основе того, что в новый (сжатый файл) перед каждым символом записывается номер границы к которой это число относится, а размер для каждой границы есть константа умноженная на номер границы.
2. Обзор существующих методов решения задачи
2.1 Сжатие и кодирование информации в информационно вычислительных комплексах (ИВК)
ИВК – это набор, состоящий из одного или нескольких ЭВМ, снабженных устройствами хранения, ввода вывода и передачи информации. ИВК имеет отдельные устройства, разнесенные между собой.
Информационная сеть представляет собой набор ИВК, соединенных между собой каналами передачи информации (каналы могут быть любой протяженности). Для того, чтобы сеть могла функционировать, она снабжается набором протоколов и интерфейсов.
Реклама

Протокол – некоторое множество информационных функций и алгоритмов обработки информации, которые приняты в той или иной сети.
Интерфейс – некоторое соединение или канал между отдельными функциональными частями сети. Интерфейсы бывают физические и программные.
Физический интерфейс – набор шин, для передачи сигналов, и электрических устройств для управления прохождения сигналов по этим шинам. Большинство физических интерфейсов - стыки.
Программный интерфейс – часть программного обеспечения сети, отвечающая за передачу информации от узла к узлу.
Сети могут быть гомогенными и гетерогенными (однородными и разнородными).
В гомогенных сетях используются однотипные ЭВМ и однотипные программное обеспечение.
В гетерогенных сетях протоколы, кроме всего прочего, согласуют разнородное программное обеспечение, а интерфейсы согласуют физические пороги сигналов.
Все универсальные сети являются гомогенными.Сеть чаще всего является открытой системой.
Открытой называется такая система, которая может взаимодействовать с другими системами. Для того, чтобы открытая система нормально функционировала она должна обеспечивать семь уровней этого функционирования:
прикладной
представительский
сеансовый
транспортный
сетевой
канальный
физический
Прикладной уровень функционирования предполагает унификацию и
стандартизацию управляющих сигналов, форматы информационных кадров, методов кодирования и защиты от ошибок и основные служебные посылки. Ф1 и Ф2 – флаги;
А – адрес;
З О – защита от ошибок.
Представительский уровень унифицирует форму представления информации, то есть тип сигналов, вид кодов, способы защиты от ошибок и правила семиотики (науки о знаках) для выбранной знаковой системы.
Сеансовый уровень унифицирует длительность сеансов связи между узлами сети, служебную информацию для вызова или организации таких сеансов, способ стыковки между функциональными частями при сеансе связи.
Транспортный уровень унифицирует собственно передачу информации, то есть ее скорость или время, способ передачи (параллельно, последовательно или смешанно) информации и виды модемов и аппаратуры передачи данных.
Сетевой уровень унифицирует (стандартизует) прохождение сигналов по очередям, вид этих очередей, способ обслуживания, разновидности персональной защиты и доступа (ключи, пароли, шифры).
Канальный уровень унифицирует прохождение сигналов по каналу с помощью унификации инициализации, синхронизации и аппаратуры защиты от ошибок.
Реклама

Физический уровень проводит унификацию физических сигналов по уровню (амплитуде), частоте, фазе и по виду модуляции сигналов.
В открытых сетях, в виду огромных объемов проходящей информации, производится сжатие информации. Существует сжатие без восстановления и с восстановлением. Сжатие без восстановления предполагает, что передается алфавитно-цифровая информация, которая тем или иным способом уменьшается в объеме и на приемной стороне принимается сжатый объем. А при сжатии с восстановлением приемник получает исходный текст, при условии, что передавался сжатый текст. В общем случае, сжатие (компрессия) данных представляет собой процесс выделения из исходного информационного массива его информативной части путем отбрасывания некоторых символов, несущих минимальное число этой информации. Сжатие производится до тех пор, пока информативность сохраняется. Простейший способ сжатия без восстановления для текстовой информации на естественном языке, предполагает наличие словаря запретов, который поддерживается сетью и доводится до всех абонентов. В него входят одно, двух и трехбуквенные слова с минимальной информативностью, которые из текста исключаются. Из текста, начиная от конца слова к началу, убирают все гласные и часть согласных до наличия еще в слове необходимого смысла. Первые три согласные несут 84% информации.
Если информация представлена в цифровом виде, то в этом случае задают длину блока, до которого необходимо ее сжать.
Весь текст бьется на блоки заданной длины или меньшей и затем производится либо сложение их по модулю два, либо двоичное сложение и передается их сумма.

Если информация не цифровая, а текстовая, то можно использовать тот же метод, если каждую букву закодировать некоторым кодом равномерной длины.
В том случае, если длина блока, кодирующего букву меньше, чем требуемая длина блока для передачи, сложение производится при ступенчатом сдвиге одной буквы относительно другой на одну позицию влево, начиная от первой буквы слова к последней. 2.2 Сжатие с восстановлением
Методы сжатия с восстановлением должны обеспечить переход к исходному сообщению при заданном КСЖ.
n1 – число символов в исходном сообщении
n2 – число символов в сжатом сообщении
Простейшим способом такого сжатия является способ хранения атрибутов в виде битовой матрицы.
Передаются только единицы, которые оговариваются либо частотой, либо временем и т. д.
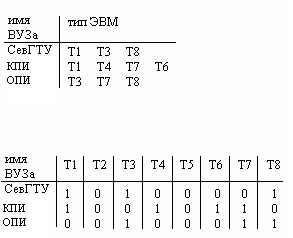
2.3 Методы сжатия цифровой информации с повторяющимися фрагментами

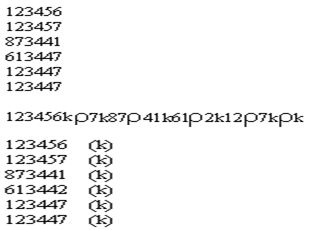
Предполагается, что информация записывается в файлы. Первая часть применима для тех информационных массивов, в которых повторяющиеся фрагменты стоят в начале строки. В этом случае используется символ пропуска r , весь массив передается одной строкой.
123456 r 7 r 41 r 2
Восстановление начинается от конца к началу, при известном количестве символов в строке. Запись каждой строки производится до символа пропуска.
Далее сверху вниз записываем символы предыдущей строки.
Второй способ используется для тех массивов, в которых повторы не только в начале строки: используется символ r и символ конца строки k.
Если массив строк одинаковой длины содержит несколько повторяющихся фрагментов в различных местах строки, то в этом случае вводятся символы, обозначающее количество пропусков и можно не использовать символ r конца строки.
Восстановление начинают с первой исходной строки, где количество пропусков определяется предыдущей строкой.
Если информация анкетного типа, записанная в алфавитно-цифровой форме, то можно использовать вместо части повторяющегося текста два значка (символа). Один из символ повтора, а второй – сколько букв пропущено при повторе.
2.4 Зонное сжатие
Метод зонного сжатия используют для текстовых массивов с учетом символов естественного алфавита и знаков препинания.
28 = 256
предложено использовать четыре бита (полубайт) для записи каждой буквы, тем самым создавая некоторый алфавит из шестнадцати букв, где каждая ячейка дает нам m = 24 = 16
162 = 256
Мы наши шестнадцать букв делим на некоторое количество зон:
| 0 |
0000 |
4 |
0100 |
8 |
1000 |
| 1 |
0001 |
5 |
0101 |
9 |
1001 |
| 2 |
0010 |
6 |
0110 |
A |
1100 |
| 3 |
0011 |
7 |
0111 |
B |
1011 |
| C |
1100 |
D |
1101 |
E |
1110 |
| F |
1110 |
Для русского алфавита достаточно 13 букв, распределенных по трем зонам.
0…С – имена букв
D…F – имена зон
С учетом вероятности появления букв друг с другом в тексте, таблица для русского алфавита выглядит следующим образом:
| D |
E |
F |
| 0 |
Space |
З |
Ц |
| 1 |
О |
У |
Ж |
| 2 |
Е |
Д |
Х |
| 3 |
А |
Я |
Ч |
| 4 |
Р |
Ь |
Э |
| 5 |
П |
Ф |
Ю |
| 6 |
Т |
Ы |
, |
| 7 |
Н |
Щ |
. |
| 8 |
В |
Ш |
; |
| 9 |
И |
Б |
: |
| A |
С |
Г |
! |
| B |
М |
К |
? |
| C |
Л |
Й |
- |
Сжатие определяется нахождением букв в одной или в соседних зонах. И вероятность нахождения буквы где-либо по отношению к другой букве:
а – вероятность нахождения буквы в зоне D
б – вероятность нахождения буквы в зоне E в – вероятность нахождения буквы в зоне F
Каждая буква записывается двумя символами:
номер зоны
номер буквы
если рядом стоящие буквы попадают в одну зону, то номер зоны пишется только один раз, а буквы чередуем.

В некоторых случаях можно использовать сочетание из двух и более букв в таблице, разделенные по зонам, принцип разделения можно оставить тем же.
Любой из перечисленных методов сжатия используется тогда, когда он дает максимальный эффект, который определяется величиной коэффициента сжатия или объемом сэкономленной памяти.
3. Выбор и обоснование решения задачи
4. Теоретическое обоснование метода Лавинского
Данный метод предполагает сжатие последовательности чисел путём разбиения последовательности на равномерные интервалы и отыскание числа не в его натуральном виде путем перебора всех подряд, а с помощью порядкового номера отсчета от ближайшей границы.
Сам метод состоит в следующем. Пусть имеем некоторое количество чисел М и максимальное по длине число L. Очевидно, что для хранения в натуральном виде этих чисел необходимо следующее количество ячеек
Q = M * log 2 L (1)
Лавинский предложил множество М разбить на N интервалов. Интервалы между собой равные и тогда очевидно, что для хранения самих чисел необходим следующий объем памяти
Q’ = M * log 2 (L / N) (2)
И нам необходимо хранить информацию об этих самых границах
Q” = (M – 1) * log 2 (N - 1) (3)
В целом объем памяти необходимый для самих чисел и памяти будет следующим
Q = Q’ + Q” (4)
Взяв производную из (4), для нахождения оптимального разбиения последовательности и приравняв ее нулю, получим
N ОПТ = М / ln M (5)
Формула (5) определяет оптимальное количество интервалов. Для определения величины самого интервала мы все количество возможных вариантов относим к количеству самого интервала, то есть для определения количества символов в интервале используем следующую формулу
C = 2 [log2 N] / N (6)
Для нахождения самого интервала (номер границы) используем следующее отношение
К = Х / С (7),
где Х – искомое число в натуральном виде.
После этого само число записывается, как порядковый отсчет этой границы и определяет экономию памяти как
D Q = QИСХ – QОПТ (8)
Пусть интервал 128, Х = 200, тогда К = 1.56. К лежит 2> K> 1, значит код числа составит 200 – 127 = 73.
5 П
рограммная реализация
Для разработки программы был выбран язык программирования высокого уровня Delphi 5.0 (Object Pascal).
Он весьма полно выражает идеи структурного программирования. Это проявляется в том, что Delphi может успешно использоваться для записи программ на разных уровнях ее детализации, не прибегая к помощи блок-схем или специального языка проектирования программ. Средства языка Delphi позволяют осуществлять достаточный контроль правильности использования данных различных типов и программных объектов как на этапе трансляции, так и на этапе ее выполнения.
Delphi позволяет без особых трудностей реализовать удобный пользовательский интерфейс, не пребегая к написанию низкоуровневого кода.
В программе есть так же возможность считать данные для кодирования из файла.
Заключение
В ходе выполнения курсовой работы были закреплены знания, полученные в ходе изучения дисциплины «Кодирование и защита информации». Работа выполнена в соответствии с постановкой задачи на курсовое проектирование.
Для проверки работоспособности программы и правильности обработки входных данных разработан тестовый пример. Тестирование программы подтвердило, что программа правильно выполнила обработку данных и выдает верные результаты.
Библиографический список
Конспект лекций по дисциплине “Кодирование и защита информации”.
Березюк Н. Т., Андрющенко А. Г., Мощинский С. С. и др. Кодирование информации – Харьков: Выща школа, 1978. – 252 с.
Кузьмин И. В., Кедрус В. А. Основы теории информации и кодирования. – Киев: Выща школа, 1977. – 280 с.
Цымбал В. П. Теория информации и кодирование. Киев, ”Вища школа”, 1997, 288 с.
Приложение А
uses
Forms,
Kizi in 'Kizi.pas' {Main};
{$R *.res}
begin
Application.Initialize;
Application.CreateForm(TMain, Main);
Application.Run;
end.
unit Kizi;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, StdCtrls,math;
type
TMain = class(TForm)
Button1: TButton;
Button2: TButton;
Button3: TButton;
fOpen: TOpenDialog;
fSave: TSaveDialog;
procedure Button3Click(Sender: TObject);
procedure Button1Click(Sender: TObject);
procedure Button2Click(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
var
Main : TMain;
f,f1:textfile;
i1:integer; // счетчик элементов (чисел) в файле
massivelementov: array [0..24]of longint;// сжимаемый массив
massivelementov1: array[0..3,0..4] of longint; //рабочий массив разбитый на интервалы
kolelementovfila:real;//количество элементов М
maxchislo:integer;// Максимальное число из М
chisloposled:integer; //Количество элементов в интервале
Interval:integer;//количество интервалов
kolmetok:integer;// количесьво меток
k:real;//флаг опред метки
polovina:real;//половина интервала
nomer:integer; // порядковый номер массива
granica:array of integer;//порядковый номер границы от нуля
mm:integer;
implementation
{$R *.dfm}
function DecToBin(dec:integer):string;
var
bin:string;
i:integer;
begin
bin:='';
for i:=1 to 8 do
begin
bin:=inttostr(dec mod 2)+bin;
dec:=dec div 2;
end;
DecToBin:=bin;
end;
function Bin24ToDec24(bin:string):integer;
var
i:integer;
dec:integer;
begin
if strlen(pchar(bin))<24 then
for i:=strlen(pchar(bin))+1 to 24 do
bin:='0'+bin;
dec:=0;
for i:=0 to 23 do
dec:=dec+trunc(strtoint(copy(bin,24-i,1))*intpower(2,i));
Bin24ToDec24:=dec;
end;
function Dec24ToBin24(dec:integer):string;
var
bin:string;
i:integer;
begin
bin:='';
for i:=1 to 24 do
begin
bin:=inttostr(dec mod 2)+bin;
dec:=dec div 2;
end;
Dec24ToBin24:=bin;
end;
procedure TMain.Button3Click(Sender: TObject);
begin
Main.close;
end;
procedure TMain.Button1Click(Sender: TObject);
var
c:char;
g,i,j:integer;
fileperem:array [0..9999] of char;
fileperem1:array [0..9999] of string;
flag1:integer;// счетчик символов в файле
flag2:integer;// счетчик элементов массива fileperem1
flag3:integer;//флаг содержания буквы в фмйле
flag4:integer;// флаг выхода из блока чтения из файла
flag5:integer;// условие увеличения флага flag2
metca:integer;//для определения значения интервла
outBuf: array[1..3] of Char;
outf: file of char;
outpos:integer;
outcomb:string;
tmp:char;
k:integer;
begin
// Чтение из файла
//---------------------------------------
fopen.Filter:='Текстовые файлы | *.txt';
fsave.Filter:='Архивированные файлы | *.arhi';
While flag4<>1 do
begin
i:=0;
flag4:=1;
if fopen.Execute then
begin
flag3:=0;
assignfile(f,fopen.filename);
reset(f);
for i:=0 to 9999 do fileperem[i]:=' ';
i:=0;
while (not eof(f)) and (i<100000) do
begin
read(f,c);
if (c<>' ')and((c<'0')or(c>'9'))and(c<>'-')and (c<>'+')and (c<>#13)and
(c<>#10 ) then
begin
if MessageDlg('Фаил содержит буквенный символ. Указать другой фаил?',
mtconfirmation,[mbYes,mbno],0) =mryes
then flag3:=1 else flag3:=11;
i:=1000000;
end else
begin
fileperem[i]:=c;
i:=i+1;
if i>99999 then
begin
showmessage('Фаил слишком большой');
flag3:=1;
i:=1000000;
end;
end;
end;
end;
if flag3=1 then
begin
flag3:=12;
flag4:=0;
end;
end;
//---------------------
// Забивка рабочего массива
//------------------------------
flag1:=0;
flag2:=0;
if (flag3=0) or (flag3=1) and (flag3<>11) then
begin
if flag3<>1 then
begin
while flag1<=i do
begin
while (fileperem[flag1]<>#13)and(fileperem[flag1]<>' ')and
(fileperem[flag1]<>#10) do
begin
fileperem1[flag2]:=fileperem1[flag2]+fileperem[flag1];
flag1:=flag1+1;
flag5:=1;
end;
flag1:=flag1+1;
if flag5=1 then
begin
flag2:=flag2+1;
flag5:=0;
end;
end;
kolelementovfila:=flag2;
{SetLength(massivelementov, trunc(kolelementovfila));
SetLength(massivelementov1, trunc(kolelementovfila));}
maxchislo:=strtoint(fileperem1[0]);
for i:=0 to trunc(kolelementovfila)-1 do
begin
massivelementov[i]:= strtoint(fileperem1[i]);
if maxchislo< massivelementov[i] then maxchislo:=massivelementov[i];
end;
end;
end;
//---------------------------------
// алгоритм кодирования
//---------------------------------
// определение колличества интервалов и числа символов в них
//---------------------------------
if (flag3=0) or (flag3=1) and (flag3<>11) then
begin
chisloposled:={trunc(kolelementovfila/trunc(ln(kolelementovfila)))+1}5;
Interval:={trunc(kolelementovfila/chisloposled)+1}5;
kolmetok:=trunc(Interval)-1;
SetLength(granica,kolmetok);
metca:=0;
for i:=0 to kolmetok-1 do
begin
granica[i]:=i;
end;
i:=0;
j:=0;
nomer:=0;
// кодирование
while J<=kolmetok-1 do
begin
massivelementov1[j,i]:=massivelementov[nomer]-trunc(granica[j])*150;
nomer:=nomer+1;
i:=i+1;
if i=chisloposled then
begin
{nomer:=0;}
J:=J+1;
i:=0;
end;
end;
closefile(f);
if fsave.Execute then
begin
AssignFile(outf,fsave.filename+'.arhi');
Rewrite(outf);
outpos:=0;
for i:=0 to kolmetok-1 do
for j:=0 to Interval-1 do
begin
tmp:=chr(granica[i]);
write(outf,tmp);
inc(outpos);
seek(outf,outpos);
outcomb:=dec24tobin24(massivelementov1[i,j]);
for k:=1 to 3 do
outbuf[k]:=chr(bin24todec24(copy(outcomb,k*8-7,8)));
for k:=1 to 3 do
begin
write(outf,outbuf[k]);
inc(outpos);
seek(outf,outpos);
end;
end;
CloseFile(outf);
end;
end;
end;
procedure TMain.Button2Click(Sender: TObject);
var inf: file of char;
outf:textfile;
inbuf:array[1..3] of char;
temp:string;
k:integer;
inpos:integer;
tmp:char;
massive,chislo,granica:integer;
begin
fopen.Filter:='Архивированные файлы | *.arhi';
fsave.Filter:='Текстовые файлы | *.txt';
if fopen.execute and fsave.execute then
begin
AssignFile(inf,fopen.Filename);
Reset(inf);
inpos:=0;
AssignFile(outf,fsave.Filename);
Rewrite(outf);
inpos:=0;
while not(eof(inf)) do
begin
read(inf,tmp);
inc(inpos);
Seek(inf,inpos);
granica:=ord(tmp);
for k:=1 to 3 do
begin
read(inf,inbuf[k]);
inc(inpos);
Seek(inf,inpos);
end;
temp:='';
for k:=1 to 3 do
temp:=temp+dectobin(ord(inbuf[k]));
massive:=bin24todec24(temp);
chislo:=massive+granica*150;
write(outf,inttostr(chislo),' ');
end;
closefile(outf);
closefile(inf);
end;
end;
end.
Приложение Б
Руководство пользователя
Для начала пользователь должен предварительно подготовить текстовый файл исходных данных (*.txt), в котором должен находиться массив чисел.
После за пуска программы(KiZI.ехе) на экране появится панель на которой находится три кнопки:
· Архивация
· Деархивация
· Выход
При нажатии кнопки «Архивация» появится окно «Открыть файл для архивации», где пользователю предложено выбрать текстовый файл с входными данными, если пользователем в файл с входными данными будет записан другой символ кроме числа, то программа выдаст ошибку: «Файл содержит буквенный символ. Указать другой файл?»
· при нажатии кнопки «Yes» пользователю будет предложено выбрать другой файл;
· при нажатии кнопки «No» пользователь будет возвращен в начальное меню;
Если файл, выбранный пользователем содержит корректные входные данные (числа), то программа предложит пользователю окно «Сохранить заархивированный файл», где пользователю нужно только выбрать папку куда файл нужно сохранить и ввести имя файла, расширение программа добавит сама (*.arhi). В этот файл программа запишет заархивированную информацию.
При нажатии кнопки «Деархивация» появится окно «Открыть файл для архивации», где пользователю предложено выбрать архивный файл, затем пользователю программа предложит окно «Сохранить заархивированный файл», где пользователю нужно выбрать только папку, куда нужно сохранить файл и ввести имя файла, расширение программа добавит сама (*.txt). В этот файл программа запишет разархивированную информацию.
При нажатии кнопки «Выход» программа заканчивает свою работу и происходит выход в операционную систему.
Программа производит сжатие информации примерно на 14%.
|