| МИНИСТЕРСТВО НАУКИ И ОБРАЗОВАНИЯ РФ
МОСКОВСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ЭКОНОМИКИ, СТАТИСТИКИ И ИНФОРМАТИКИ
Кафедра математической статистики и эконометрики
Курсовая работа:
«Анализ выживаемости в системе «
Statistica
»
Исполнитель:
Егоров Т.П.
гр. ДЭС-401
Преподаватель:
Иванова Л.В.
Москва, 2008
Содержание
Основные проблемы анализа выживаемости……………………………..……3
I. Таблицы времён жизни …………… …………… …………… …………… ..4
1.1 Исходные данные………………………………………………………….….4
1.2 Построение таблиц времён жизни……………………………………...……6
1.3 Аппроксимация эмпирических данных теоретическим распределением……………………………………………………………………11
II. Оценки Каплана-Майера…………………………………………………..…17
III. Сравнение выживаемости в группах…………………………………….…21
Список литературы………………………………………………………………23
Основные проблемы анализа выживаемости
Методы анализа выживаемости (Survival Analisis) первоначально были развиты в медицинских, биологических исследованиях и страховании, но затем стали шароко применяться в социальных и экономических науках, а также в промышленности в инженерных задачах (анализ надежности и время отказов)
Одной из важных характеристик, описывающих течение болезни, является продолжительность жизни пациентов с момента поступления в клинику или после проведения операции. В принципе, для описания средних времен жизни и сравнения новой методики со старой можно использовать стандартные статистические методы. Однако рассматриваемые данные имеют специфику, которую следует учитывать. Дело в том, что в медицинской практике мы часто имеем дело с неполными данными.
Это связано с тем, что трудно наблюдать все время жизни пациента после операции, так как пациент мог быть выписан или переведен в другую клинику и связь с ним была утеряна. При этом мы располагаем не полной информацией о времени жизни пациента, а лишь частичной. Естественное желание исследователя использовать все данные, т. е. анализировать как полные времена жизни, так и неполные, и не терять с трудом собранную информацию. Для этого и предназначены методы анализа выживаемости, которые позволяют изучать неполные или цензурированные данные. Наблюдения, которые содержат неполную информацию, называются неполными или цензурированными (например, «пациент А был жив по крайней мере 4 месяца после того, как был переведен в другую клинику и контакт с ним был потерян»). Это пример цензурированного наблюдения: информация о том, что пациент был жив 4 месяца, важна и может быть использована для построения оценок. Наблюдения от момента операции до летального исхода называется полными.
Реклама

Итак, в анализе выживаемости различают полные (по-английски complete) и неполные, или цензурированные, наблюдения (по-английски censored). Конечно, можно было использовать только полные времена жизни, но тогда мы имели бы в своем распоряжении очень мало наблюдений и соответственно неточные оценки. Использование, наряду с полными наблюдениями, неполных или цензурированных наблюдений является главной особенностью методов анализа выживаемости.
I
.Таблицы времён жизни
1.1. Исходные данные
Таблица 1
Данные о пациентах, перенесших операцию на сердце
| |
MONTH_1
|
DAY_1
|
YEAR_1
|
MONTH_2
|
DAY_2
|
YEAR_2
|
CENSORED
|
AGE
|
ANTIGEN
|
MISMATCH
|
HOSPITAL
|
| 1
|
JANUARY
|
6
|
68
|
JANUARY
|
21
|
68
|
CENSORED
|
54
|
0
|
1,11
|
HILLVIEW
|
| 2
|
MAY
|
2
|
68
|
MAY
|
5
|
68
|
CENSORED
|
40
|
0
|
1,66
|
HILLVIEW
|
| 3
|
AUGUST
|
31
|
68
|
MAY
|
17
|
70
|
COMPLETE
|
51
|
0
|
1,32
|
HILLVIEW
|
| 4
|
SEPTEMBR
|
9
|
68
|
JANUARY
|
14
|
69
|
CENSORED
|
48
|
0
|
0,36
|
ST_AND
|
| 5
|
OCTOBER
|
5
|
68
|
DECEMBER
|
8
|
68
|
COMPLETE
|
54
|
0
|
1,89
|
ST_AND
|
| 6
|
OCTOBER
|
26
|
68
|
JULY
|
7
|
72
|
COMPLETE
|
54
|
0
|
0,87
|
BINER
|
| 7
|
NOVEMBER
|
22
|
68
|
AUGUST
|
29
|
69
|
COMPLETE
|
49
|
0
|
1,12
|
BINER
|
| 8
|
NOVEMBER
|
20
|
68
|
DECEMBER
|
13
|
68
|
CENSORED
|
56
|
0
|
2,05
|
HILLVIEW
|
| 9
|
FEBRUARY
|
15
|
69
|
FEBRUARY
|
25
|
69
|
COMPLETE
|
55
|
1
|
2,76
|
HILLVIEW
|
| 10
|
FEBRUARY
|
8
|
69
|
NOVEMBER
|
29
|
71
|
COMPLETE
|
43
|
0
|
1,13
|
BINER
|
| 11
|
MARCH
|
29
|
69
|
MAY
|
7
|
69
|
COMPLETE
|
42
|
0
|
1,38
|
HILLVIEW
|
| 12
|
APRIL
|
13
|
69
|
APRIL
|
13
|
71
|
COMPLETE
|
58
|
0
|
0,96
|
ST_AND
|
| 13
|
JULY
|
16
|
69
|
NOVEMBER
|
29
|
69
|
COMPLETE
|
52
|
1
|
1,62
|
ST_AND
|
| 14
|
MAY
|
22
|
69
|
APRIL
|
1
|
74
|
CENSORED
|
33
|
0
|
1,06
|
ST_AND
|
| 15
|
AUGUST
|
16
|
69
|
AUGUST
|
17
|
69
|
CENSORED
|
54
|
0
|
0,47
|
BINER
|
| 16
|
SEPTEMBR
|
3
|
69
|
DECEMBER
|
18
|
71
|
COMPLETE
|
44
|
0
|
1,58
|
BINER
|
| 17
|
SEPTEMBR
|
14
|
69
|
NOVEMBER
|
13
|
69
|
COMPLETE
|
64
|
0
|
0,69
|
HILLVIEW
|
| 18
|
JANUARY
|
16
|
70
|
APRIL
|
1
|
74
|
CENSORED
|
49
|
0
|
0,91
|
BINER
|
| 19
|
JANUARY
|
3
|
70
|
APRIL
|
1
|
74
|
CENSORED
|
40
|
0
|
0,38
|
HILLVIEW
|
| 20
|
MAY
|
19
|
70
|
JULY
|
12
|
70
|
COMPLETE
|
49
|
0
|
2,09
|
HILLVIEW
|
| 21
|
MAY
|
13
|
70
|
JUNE
|
29
|
70
|
COMPLETE
|
61
|
1
|
0,87
|
ST_AND
|
| 22
|
MAY
|
9
|
70
|
MAY
|
9
|
70
|
CENSORED
|
41
|
0
|
0,87
|
ST_AND
|
| 23
|
JULY
|
4
|
70
|
APRIL
|
1
|
74
|
CENSORED
|
48
|
0
|
0,75
|
BINER
|
| 24
|
OCTOBER
|
15
|
70
|
APRIL
|
1
|
74
|
CENSORED
|
45
|
0
|
0,98
|
BINER
|
| 25
|
JANUARY
|
5
|
71
|
FEBRUARY
|
18
|
71
|
CENSORED
|
36
|
0
|
0,00
|
ST_AND
|
| 26
|
JANUARY
|
11
|
71
|
OCTOBER
|
1
|
73
|
COMPLETE
|
48
|
0
|
0,81
|
BINER
|
| 27
|
FEBRUARY
|
22
|
71
|
APRIL
|
14
|
71
|
COMPLETE
|
47
|
0
|
1,38
|
HILLVIEW
|
| 28
|
MARCH
|
22
|
71
|
APRIL
|
1
|
74
|
CENSORED
|
36
|
0
|
1,35
|
HILLVIEW
|
| 29
|
APRIL
|
24
|
71
|
JANUARY
|
2
|
72
|
COMPLETE
|
48
|
1
|
1,08
|
HILLVIEW
|
| 30
|
AUGUST
|
18
|
71
|
OCTOBER
|
8
|
71
|
COMPLETE
|
52
|
0
|
1,51
|
ST_AND
|
| 31
|
NOVEMBER
|
8
|
71
|
APRIL
|
1
|
74
|
CENSORED
|
38
|
0
|
0,98
|
ST_AND
|
| 32
|
OCTOBER
|
13
|
71
|
AUGUST
|
30
|
72
|
COMPLETE
|
48
|
1
|
1,82
|
ST_AND
|
| 33
|
DECEMBER
|
15
|
71
|
APRIL
|
1
|
74
|
CENSORED
|
41
|
0
|
0,19
|
BINER
|
| 34
|
NOVEMBER
|
20
|
71
|
JANUARY
|
9
|
72
|
COMPLETE
|
49
|
0
|
0,66
|
BINER
|
| 35
|
JANUARY
|
7
|
72
|
APRIL
Реклама

|
1
|
74
|
CENSORED
|
32
|
1
|
1,93
|
BINER
|
| 36
|
MARCH
|
4
|
72
|
SEPTEMBR
|
6
|
73
|
CENSORED
|
48
|
0
|
0,12
|
HILLVIEW
|
| 37
|
MARCH
|
17
|
72
|
MAY
|
22
|
72
|
COMPLETE
|
51
|
0
|
1,12
|
HILLVIEW
|
| 38
|
MAY
|
18
|
72
|
JANUARY
|
1
|
73
|
CENSORED
|
19
|
0
|
1,02
|
HILLVIEW
|
| 39
|
APRIL
|
9
|
72
|
JUNE
|
13
|
72
|
COMPLETE
|
45
|
1
|
1,68
|
ST_AND
|
| 40
|
JUNE
|
10
|
72
|
APRIL
|
1
|
74
|
CENSORED
|
48
|
0
|
1,20
|
ST_AND
|
| 41
|
JUNE
|
21
|
72
|
JULY
|
16
|
72
|
COMPLETE
|
53
|
1
|
1,68
|
ST_AND
|
| 42
|
AUGUST
|
20
|
72
|
APRIL
|
1
|
74
|
CENSORED
|
47
|
0
|
0,97
|
BINER
|
| 43
|
AUGUST
|
17
|
72
|
APRIL
|
1
|
74
|
CENSORED
|
26
|
1
|
1,46
|
BINER
|
| 44
|
OCTOBER
|
7
|
72
|
DECEMBER
|
9
|
72
|
COMPLETE
|
56
|
1
|
2,16
|
BINER
|
| 45
|
SEPTEMBR
|
22
|
72
|
OCTOBER
|
4
|
72
|
CENSORED
|
29
|
0
|
0,61
|
HILLVIEW
|
| 46
|
NOVEMBER
|
18
|
72
|
APRIL
|
1
|
74
|
CENSORED
|
52
|
1
|
1,70
|
HILLVIEW
|
| 47
|
MAY
|
31
|
73
|
APRIL
|
1
|
74
|
CENSORED
|
49
|
0
|
0,81
|
HILLVIEW
|
| 48
|
FEBRUARY
|
4
|
73
|
MARCH
|
5
|
73
|
COMPLETE
|
54
|
0
|
1,08
|
ST_AND
|
| 49
|
DECEMBER
|
31
|
72
|
APRIL
|
1
|
74
|
CENSORED
|
46
|
0
|
1,41
|
ST_AND
|
| 50
|
JANUARY
|
17
|
73
|
APRIL
|
1
|
74
|
CENSORED
|
52
|
1
|
1,94
|
ST_AND
|
| 51
|
FEBRUARY
|
24
|
73
|
APRIL
|
13
|
73
|
CENSORED
|
53
|
0
|
3,05
|
BINER
|
| 52
|
MARCH
|
7
|
73
|
DECEMBER
|
29
|
73
|
COMPLETE
|
42
|
0
|
0,60
|
BINER
|
| 53
|
MARCH
|
8
|
73
|
APRIL
|
1
|
74
|
CENSORED
|
48
|
1
|
1,44
|
BINER
|
| 54
|
MAY
|
19
|
73
|
JULY
|
8
|
73
|
COMPLETE
|
46
|
0
|
2,25
|
HILLVIEW
|
| 55
|
APRIL
|
27
|
73
|
APRIL
|
1
|
74
|
CENSORED
|
54
|
0
|
0,68
|
HILLVIEW
|
| 56
|
AUGUST
|
21
|
73
|
OCTOBER
|
28
|
73
|
COMPLETE
|
51
|
1
|
1,33
|
HILLVIEW
|
| 57
|
SEPTEMBR
|
12
|
73
|
OCTOBER
|
8
|
73
|
CENSORED
|
52
|
1
|
0,82
|
ST_AND
|
| 58
|
MARCH
|
2
|
74
|
APRIL
|
1
|
74
|
CENSORED
|
45
|
0
|
0,16
|
ST_AND
|
| 59
|
AUGUST
|
7
|
73
|
APRIL
|
1
|
74
|
CENSORED
|
47
|
0
|
0,33
|
ST_AND
|
| 60
|
SEPTEMBR
|
17
|
73
|
FEBRUARY
|
25
|
74
|
COMPLETE
|
43
|
0
|
1,20
|
BINER
|
| 61
|
OCTOBER
|
16
|
73
|
APRIL
|
1
|
74
|
CENSORED
|
26
|
0
|
0,46
|
BINER
|
| 62
|
DECEMBER
|
12
|
73
|
APRIL
|
1
|
74
|
CENSORED
|
23
|
1
|
1,78
|
BINER
|
| 63
|
MARCH
|
19
|
74
|
APRIL
|
1
|
74
|
CENSORED
|
28
|
1
|
0,77
|
HILLVIEW
|
| 64
|
MARCH
|
31
|
74
|
APRIL
|
1
|
74
|
CENSORED
|
35
|
0
|
0,67
|
ST_AND
|
В строках располагаются данные о каждом из прооперированных пациентов. В столбцах указаны даты начала наблюдения за пациентом (дата поступления в клинику/дата операции) – первые три переменные, даты окончания наблюдения (пациент выписался, и связь с ним была потеряна или умер) – последние три переменные. Программа интерпретирует первую и четвёртую переменные как месяцы, вторую и пятую – как дни, а третью и шестую – как год. Имеется также возможность сразу ввести времена жизни (что соответствует одной переменной в файле данных, вместо шести указанных) или даты в другом формате (соответственно, две переменные: дата начала и дата окончания наблюдения).
Так, например, из пятой строки видно, что пациенту под номером 4 была сделана операция 9 сентября 1968, а выписался он 14 января 1969 года. Так как далее связь с этим пациентом была утеряна, то имеем неполное (цензурированное) наблюдение. Ему соответствует значение стоящей в седьмом столбце
переменной – censored
(
цензурирован).
Следующая за ней переменная в столбце 8
(AGE) характеризует возраст пациентов.
Переменные в 9-м и 10-м столбцах
содержат специальную медицинскую информацию об особенностях операции (ANTIGEN, MISMATCH).
Значение переменной в столбце 11
указывает на название клиники, где была сделана операция.
Файл исходных данных содержит 64 наблюдения, т.е. данные о 64 пациентах трех клиник.
1.2. Построение таблиц времени жизни
На основе данных таблиц времен жизни (таблиц смертности - в терминологии страхования) определяется ряд элементарных статистик, необходимых для описания времени жизни пациентов (клиентов - в страховании).
В некоторых случаях времена отказов (failure time) представляются в виде сгруппированных данных. Это объясняется тем, что во многих реальных исследованиях сложно оценить время отказов с достаточной точностью, однако можно определить, сколько отказов произошло или сколько наблюдений было цензурировано в течение определенного интервала времени. Такого рода данные называются таблицами времен жизни.
Таблицу времен жизни подобного вида можно рассматривать как «расширенную» таблицу частот. Область возможных времен наступления критических событий (смертей или отказов, в зависимости от предмета исследования) разбивается на определенное число интервалов. Для каждого интервала определяются количество и доля индивидов, которые были живы в начале рассматриваемого временного периода и тех, которые выбыли из наблюдения на данном интервале, а также тех, связь с которыми была утеряна по той или иной причине, т.е. цензурированные. Таким образом, отличие от обычной таблицы частот заключается в том, что она строится по полным наблюдениям, а в таблице жизни учитываются как полные, так и неполные (цензурированные) наблюдения.
Количество интервалов на временной оси пользователь может задать самостоятельно. В приведенной ниже таблице это число равно 12 (с учетом того, что стандартный период наблюдения за пациентом составляет обычно 1 год).
Применительно к страхованию, область возможных времен наступления страховых случаев разбивается на некоторое число интервалов, а затем для каждого из них вычисляются доли объектов, у которых на данном интервале наступил страховой случай.
В модуле «Анализ выживаемости» предусмотрена возможность, обрабатывать как непосредственно файл первичных данных, так и сгруппированные данные. Ниже приведена таблица времен жизни, полученная в результате обработки исходной информации:
Таблица 2
Таблица времен жизни
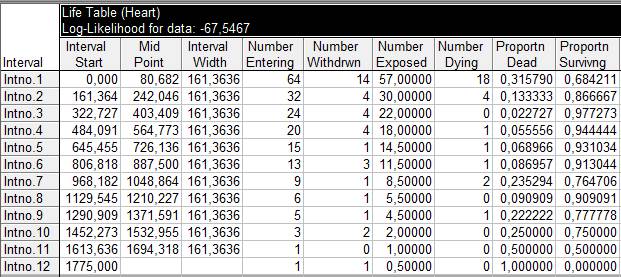
Обратимся к интерпретации переменных, составляющих содержание полученной электронной таблицы времен жизни (по столбцам):
· Номер интервала (
Interval
/
Intno
=
Interval
Number
)
для сгруппированных данных.
· Нижняя граница интервала (
Interval
Start
)
· Середина интервала (
Mid
Point
)
· Ширина интервала (
Interval
Width
)
· Число в начале (
Number
Entering
)
Число пациентов, которые были живы в начале рассматриваемого временного интервала.
· Число изъятых (
Number
Withdrwn
) объектов
Число пациентов, связь с которыми была утеряна (т.е. изъятых из дальнейшего рассмотрения после того, как они выписались/перевелись из данной клиники). Эти объекты имеют метку цензурированные (censored
) в файле исходных данных.
· Число изучаемых (
Number
Exposed
) объектов
Число пациентов, которые были живы в начале рассматриваемого временного интервала, за вычетом половины от числа изъятых (цензурированных).
· Число умерших (
Number
Dying
)
Число пациентов, умерших на данном отрезке времени (интервалe). Умершие объекты имеют метку complete
.
· Доля
умерших
(Proportn Dead)
Отношение числа объектов, умерших в соответствующем интервале, к общему числу объектов, попавших в этот интервал.
Таблица 3
Таблица времен жизни (окончание)
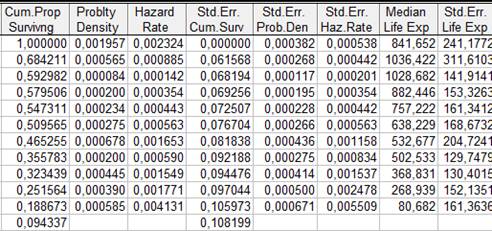
· Кумулятивная доля выживших объектов или функция выживания (
Cum
.
Prop
Survivng
)
Это кумулятивная доля выживших к началу соответствующего временного интервала. Полученная доля, как функция от времени, представляет собой оценку функции выживания, то есть вероятность того, что пациент переживет данный период времени. Поскольку вероятности выживания считаются независимыми на разных интервалах, эта доля равна произведению долей выживших объектов по всем предыдущим интервалам.
· Плотность вероятности (
Problty
Density
)
Это оценка вероятности смерти (отказа) на соответствующем интервале. Получается в результате вычитания из значения функции выживания на данном
интервале значения функции выживания на следующем
интервале с последующим делением на ширину соответствующего интервала:
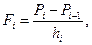
где 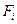 - оценка вероятности смерти (отказа) в i
-м интервале, - оценка вероятности смерти (отказа) в i
-м интервале, 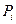 - кумулятивная доля выживших объектов (функция выживания) к началу i
-го интервала, - кумулятивная доля выживших объектов (функция выживания) к началу i
-го интервала, 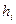 - ширина i
-го интервала. - ширина i
-го интервала.
Например, значение второй строки столбца Problty
Density
рассчитывается следующим образом:
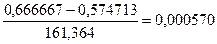 . .
На графике оценки плотности вероятности видно, что вероятность смерти в первые 160 дней после операции максимальна. Далее она резко падает.
Большие вероятности смерти расположены также в интервалах от 161 до 332, от 968 до 1129 и т.д.
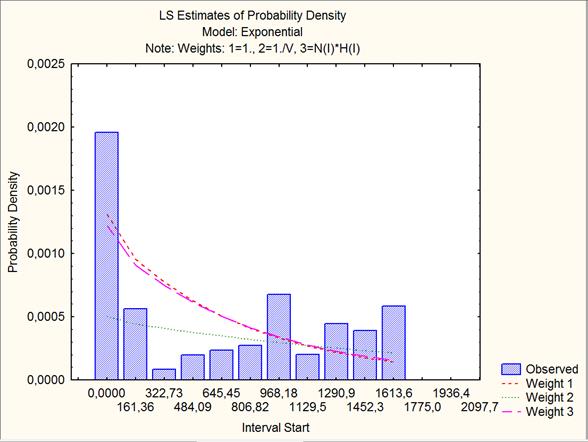
Рис. 1. Функция плотности вероятности смерти.
· Функция мгновенного риска или функция интенсивности (
Hazard
Rate
)
Это одна из важных характеристик, описывающих течение болезни, обладающая хорошими прогностическими
свойствами. В общем случае формально она соответствует вероятности наступления отказа в течение малого интервала времени [t
,
t
+
dt
), при условии, что до момента t
отказ не произошел. В терминах анализа выживаемости значение функции интенсивности соответствует вероятности того, что пациент умрет на данном временном интервале, при
условии
, что в начале интервала он был жив
.
Оценка функции интенсивности вычисляется как число смертей (отказов), приходящихся на единицу времени соответствующего интервала, деленное на среднее число пациентов (объектов), доживших до момента времени, приходящегося на середину этого интервала.
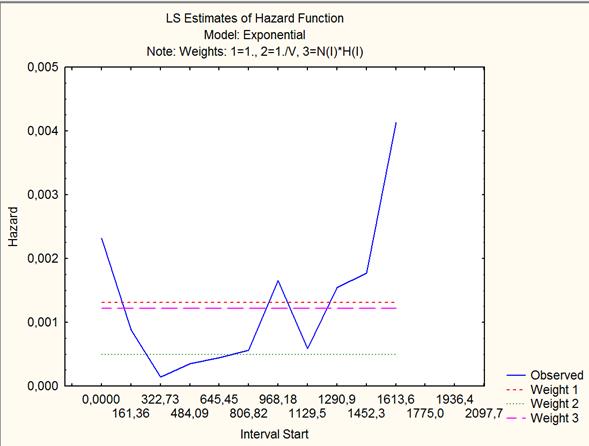
Рис. 2. Функция мгновенного риска.
График функции мгновенного риска наглядно свидетельствует о том, что в первые дни после операции на сердце риск смерти очень велик, затем он значительно падает до 322 дня, а спустя некоторое время вновь начинает возрастать до 806 дня, затем резко возрастает до 968 дня, после этого идет столь же резкое падение вероятности смерти до 1129 дня, после чего функция вновь начинает резкий рост. Заметим, что именно функция риска используется исследователем в дальнейшем для прогностических целей.
Итак, исследователя интересует функция риска, однако реально возможно получить лишь
оценку
функции риска. Поэтому важна точность
получаемых оценок. Понятно, что нельзя доверять оценкам, имеющим большую погрешность (например, если погрешность имеет тот же порядок, что и сами оценки). Поэтому следует внимательно просмотреть построенную таблицу и, если позволяет объем выборки, удалить из неё все «плохие» оценки, т.е. оценки с большой погрешностью. Это чрезвычайно важный принцип анализа данных!
С этой целью в таблице наряду с оценками
приведены их стандартные
ошибки
для каждой из трех описанных выше функций (Std
.
Err
.
Cum
.
Proportion
Surviving
,
Probability
Density
,
Hazard
Rate
)
.
Замечание.
Для получения надежных оценок параметров трех вышеназванных основных функций (функции выживания, плотности вероятности и интенсивности) и их стандартных ошибок на каждом временном интервале в таблицах времен жизни требуется, чтобы исходный файл содержал не менее
30 наблюдений.
· Медиана ожидаемого времени жизни (
Median
Life
Exp
)
По определению, медиана
соответствует точке на временной оси, в которой кумулятивная функция выживания принимает значение 0,5. Например, из первой строчки таблицы столбца Median
Life
Exp
видно, что пациент с вероятностью 0,5 будет жить 842 дня после операции. Если пациент пережил первый временной интервал (161 день после операции на сердце), то с вероятностью 0,5 он проживет еще 1037 дней, что соответствует второй строке таблицы и т.д. Другие процентили (например, 25-й и 75-й процентили или квартили) кумулятивной функции выживания вычисляются по такому же принципу. Следует иметь ввиду, что 50-й процентиль (медиана) кумулятивной функции выживания обычно не совпадает с точкой выживания 50% наблюдений данной выборки! Такое совпадение возможно только тогда, когда в течение прошедшего отрезка времени не было цензурированных наблюдений
Еще раз подчеркнем, что в общем случае таблица времен жизни дает хорошее представление о распределении смертей (отказов – в технике) во времени, если наблюдений достаточно много (как минимум 30).
1.3. Аппроксимация эмпирических данных теоретическим распределением.
Для целей прогноза часто необходимо знать аналитическую
форму
построенной функции выживания. Для описания продолжительности жизни в анализе выживаемости наиболее важны и часто используемы следующие семейства распределений: экспоненциальное
распределение (в том числе модель с линейной интенсивностью
), распределение Вейбулла
(экстремальных значений) и распределение Гомперца
.
Существует два основных метода подгонки теоретического распределения к сгруппированным данным.
Первый подход
состоит в интерполяции, т.е. в переводе таблицы времен жизни в непрерывный массив данных, при этом предполагается, что:
(1) каждый отказ происходит в середине интервала группировки,
(2) цензурирование происходит после отказов (т.е. цензурированные наблюдения располагаются за отказами в каждом интервале группировки). Данный метод применим в ситуациях, когда интервалы группировки относительно малы.
Во втором подходе
имеющиеся данные рассматриваются как таблица времен жизни. Для проведения оценивания параметров применима модель линейной регрессии, т.к. все перечисленные семейства распределений могут быть сведены к линейным относительно оцениваемых параметров с помощью соответствующих преобразований. Поэтому процедура оценивания основана на методе наименьших квадратов.
Однако, такие преобразования приводят иногда к тому, что дисперсия остатков зависит от интервалов (то есть дисперсия различна на разных интервалах). Чтобы учесть это, в алгоритмах подгонки дополнительно используются оценки метода взвешенных наименьших квадратов двух типов. Программа по умолчанию сама выбирает те из них, которые производят лучшую аппроксимацию (на основе критерия c²). На практике оба подхода приводят к очень близким значениям оценок параметров. Возможно также для оценки параметров сгруппированных данных применение метода максимального правдоподобия.
В модуле Анализ выживаемости
(
Survival
Analysis
)
предусмотрена возможность аппроксимировать данные основными семействами распределений, используя либо обычный метод наименьших квадратов, либо две его модификации с весами.
Чтобы выбрать наиболее подходящее семейство распределений из имеющегося в арсенале исследователя списка, сначала рассмотрим модель экспоненциального распределения (выбрав позицию Экспоненциальный (
Exponential
)
в выпадающем списке поля Результаты для м
одели (
Results
for
Model
))
. Кроме того, в этом поле имеется возможность выбрать следующие модели распределений: модель с линейной интенсивностью (
Linear
Hazard
)
, модель Гомпертца (
Gompertz
)
и модель Вейбулла (
Weibull
)
.
Оценка согласия теоретического и эмпирического распределений проводится с помощью критерия c².
Чтобы определить оценки для выбранного семейства распределений, а также значение c², нажимаем кнопку Оценки параметров (
Parameter
estimates
)
.
Таблица 4
Процедура оценки параметров экспоненциального распределения
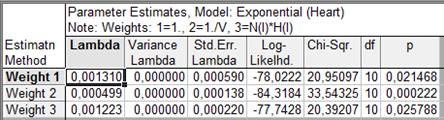
Если критерий значим, делается вывод о том, что подогнанное (теоретическое) распределение значимо отличается от эмпирического (как в данном примере), поэтому это семейство распределений отвергается для описания формы функции выживания.
Из приведенной таблицы видно, что ни один из представленных методов оценивания (подгонки) не даёт для экспоненциального распределения удовлетворительного согласия. Такую же картину можно наблюдать на приведенном ниже графике эмпирической функции выживания и кривых экспоненциального распределения: ни одна из трех экспонент (соответствующих трем различным алгоритмам оценивания) не аппроксимирует наблюдаемую функцию выживания удовлетворительно. Эмпирическая функция выживания сильно отклоняется от второй аппроксимирующей функции (Weight 2); согласованность с двумя другими теоретическими кривыми (Weight 1, Weight 3) несколько лучше, но при этом сохраняется значимое их отличие от «волнообразного» характера поведения рассматриваемой эмпирической функции. Поэтому необходимо продолжить поиск лучшей аппроксимации.
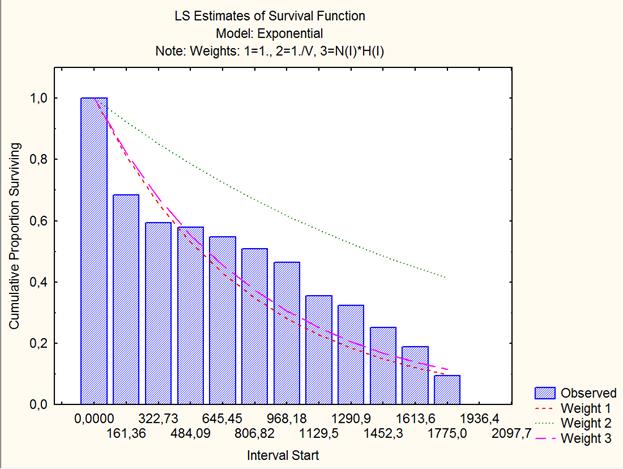
Рис.3. Графическое представление эмпирической функции выживания и теоретических кривых экспоненциального распределения.
Теперь рассмотрим модель с линейной интенсивностью (
Linear
Hazard
)
.
Таблица 5
Процедура оценки параметров линейного распределения

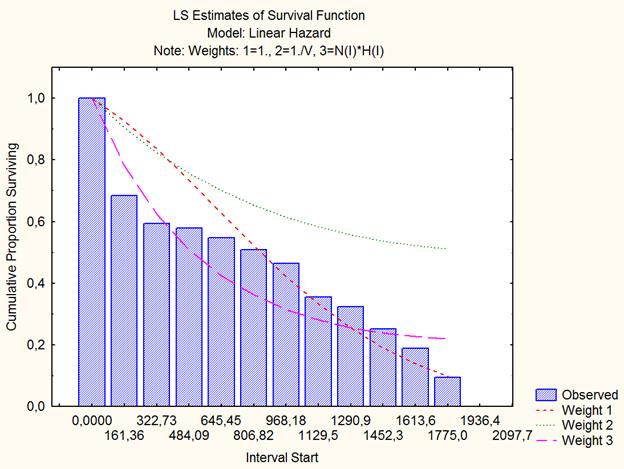
Рис.4. Графическое представление эмпирической функции выживания и теоретических кривых линейного распределения.
Эмпирическая функция выживания сильно отклоняется от второй аппроксимирующей функции (Weight 2); согласованность с двумя другими теоретическими кривыми (Weight 1, Weight 3) несколько лучше, но при этом сохраняется значимое их отличие от «волнообразного» характера поведения рассматриваемой эмпирической функции. Поэтому необходимо продолжить поиск лучшей аппроксимации.
Теперь рассмотрим модель Гомпертца (
Gompertz
).
Таблица 6
Процедура оценки параметров распределения Гомпертца

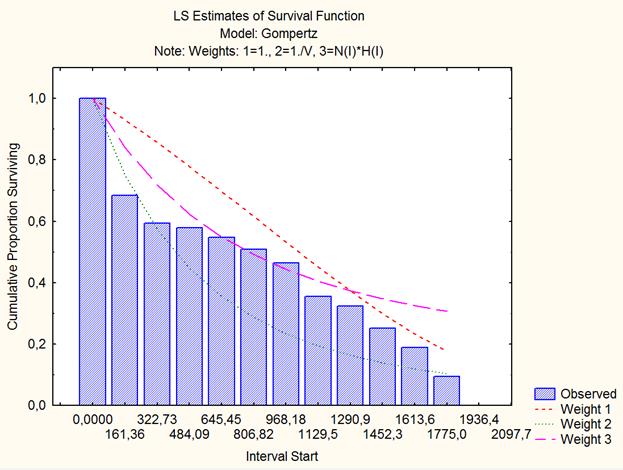
Рис.5. Графическое представление эмпирической функции выживания и теоретических кривых распределения Гомпертца.
Эмпирическая функция выживания сильно отклоняется от первой аппроксимирующей функции (Weight 1); согласованность с двумя другими теоретическими кривыми (Weight 2, Weight 3) лучше, но всё же необходимо продолжить поиск лучшей аппроксимации.
Наконец, рассмотрим модель Вейбулла (
Weibull
).
Таблица 7
Процедура оценки параметров распределения Вейбулла

Сравнив оценки параметров для остальных семейств распределений, предлагаемых системой «Statistica», можно сделать вывод, что только для распределения Вейбулла (при оценивании по минимуму суммы взвешенных квадратов, т.е. по третьему алгоритму Weight 3) отсутствует значимое отличие от наблюдаемых значений: c²-критерий не даёт значимого отклонения (p=0,58). Следовательно, распределение Вейбулла с таким набором параметров описывает наблюдаемые времена жизни наилучшим образом. Однако стоит заметить, что исследователь ограничен в выборе лишь из трех представленных наборов параметров.
Ниже представлены графики функции выживания для семейства распределений Вейбулла, подогнанные на основе трех алгоритмов (Weight1, Weight2, Weight3).
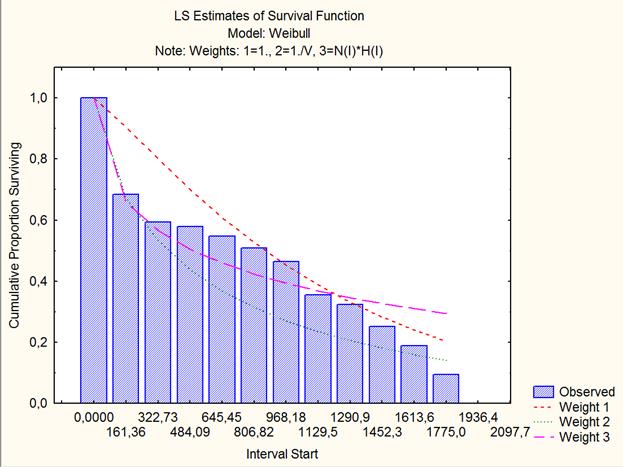
Рис.5. Графическое представление эмпирической функции выживания и теоретических кривых распределения Гомпертца.
В заключение отметим, что имеется возможность анализировать в качестве исходных табулированные данные. Для этого нужно выбрать закладку Таблица времен жизни
(
Table
of
Survival
Times
)
в диалоговом окне Таблицы и распределения времен жизни
. В этом случае файл с табулированными данными должен содержать три переменные со следующей информацией:
а) нижняя граница временных интервалов;
б) количество цензурированных наблюдений;
в) число отказов (умерших) в каждом временном интервале.
Если не удается получить хорошую подгонку к наблюдаемым данным, то для определения формы функции надежности можно использовать независимые от распределения методы оценки параметров, т.н. непараметрические оценки (доступные в окне результатов). В этом случае предусмотрен метод Каплана-Майера, позволяющий получить оценку предела
функции надежности (выживания). Эта оценка не зависит от предположения о природе распределения исходных данных.
II
. Оценки Каплана–Майера
Как указывалось выше, одна из задач анализа выживаемости состоит в оценке функции выживания S(t).
Если все наблюдения являются полными (
completed
)
, то оценка S(t) строится просто: подсчитывается количество пациентов, проживших t дней после проведения операции, и делится на общее число пациентов. При наличии неполных
(
censored
)
наблюдений ситуация усложняется: требуется строить таблицу времен жизни (механизм ее построения был подробно изложен в предыдущем параграфе).
В случае цензурированных (но не группированных) наблюдений имеется также возможность оценить функцию выживания непосредственно
, не используя таблицу времен жизни. Такой метод впервые был предложен Капланом и Майером (Kaplan & Meier (1958)). .
Его основная идея состоит в следующем. Пусть массив исходных данных содержит зафиксированные последовательно в хронологическом порядке отдельные наблюдения (события). Если исходить из того, что каждое наблюдение содержит точно один временной интервал, то перемножая вероятности выживания в каждом интервале получим следующую формулу для функции выживания:
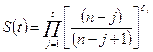 , где , где
S
(
t
) –
оценка функции выживания,
n
– общее число наблюдений (объем выборки),
j
– порядковый (хронологический) номер отдельного события (наблюдения),
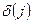 - индикатор цензурирования. Причем - индикатор цензурирования. Причем 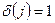 ,
если j
-e событие означает отказ (смерть), и ,
если j
-e событие означает отказ (смерть), и 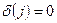 ,
если речь идет о потере наблюдения для дальнейшего исследования независимо от причин. ,
если речь идет о потере наблюдения для дальнейшего исследования независимо от причин.
П
- произведение по всем наблюдениям j
, завершившимся к моменту времени t
.
Так как приведенная оценка функции выживания состоит из произведения нескольких сомножителей, она также носит название мультипликативной (множительной).
Обратимся к тому же файлу исходных данных, который использовался для построения таблиц времен жизни. Оценки Каплана-Майера функции выживания, построенные по этим данным, показаны в следующей таблице:
Таблица 8
Результаты оценки функции выживания методом Каплана-Майера.
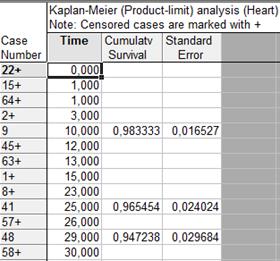
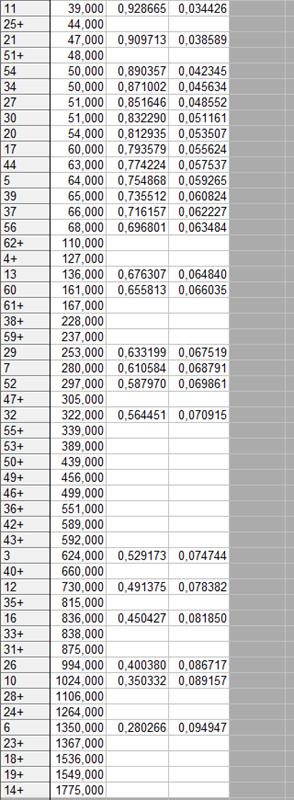
В первом столбце таблицы показаны номера наблюдений, для которых в соответствующий момент времени произошло некоторое событие. Знаком «+» обозначены цензурированные наблюдения (пациент был выписан).
Из таблицы видно, что вероятность того, что пациент проживёт больше 47 дней, равна 0,9097; вероятность того, что пациент проживёт больше 66 дней, равна 0,7161 и т.д.
Следует обратить внимание на стандартные ошибки полученных оценок. Стандартная ошибка функции выживания достаточно мала.
Сравним ошибками функции выживания (
Cum
.
Prop
Survivng
)
, рассчитанной для таблиц времен жизни в табл.3).
Таблица 9
Стандартные ошибки функция выживания для таблиц времен жизни
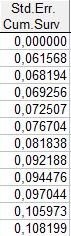
Как мы видим, стандартные ошибки полученных оценок полностью не совпадают, прежде всего, это связано с тем, что в таблицах времён жизни данные были сгруппированы. В один интервал входит приблизительно 5 наблюдений, а в таблицах Каплана-Майера каждое наблюдение рассматривается в отдельности.
Ниже приведен график функции выживания.
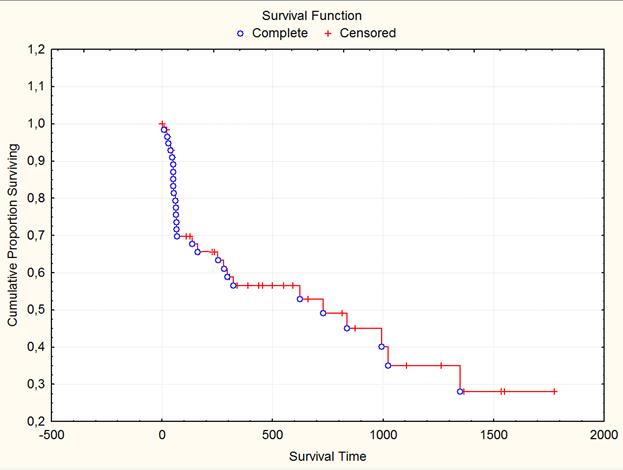
Рис. 7. Функция выживания.
Для удобства интерпретации на графике полные наблюдения отмечены точками, неполные наблюдения - крестиками.
Преимущество метода Каплана-Майера, по сравнению с методом таблиц времен жизни, состоит в том, что получаемые оценки не зависят от разбиения времени жизни пациента (объекта) на интервалы, т.е. от группировки. Здесь нет необходимости разбивать временную ось на интервалы. Метод множительных оценок Каплана-Майера и метод таблиц времен жизни приводят практически к одинаковым результатам, если временные интервалы содержат максимум по одному наблюдению.
III. Сравнение выживаемости в группах
Представляет интерес сравнить времена жизни пациентов в различных группах, например, в группах мужчин и женщин. В системе «Statistica» предусмотрены специальные процедуры для сравнения выживаемости в группах.
Если имеется две группы, то используется опция Сравнение двух выборок (
Comparing
two
samples
)
.
Если количество групп больше двух, то используется опция Сравнение нескольких выборок (
Comparing
multiple
samples
)
.
Так как времена жизни не являются нормально распределенными, в этом случае приходится использовать непараметрические тесты, основанные на рангах. Имеется множество непараметрических критериев, которые могут быть применены для сравнения времен жизни, однако в подавляющем большинстве они неприменимы для цензурированных данных.
Для сравнения выживаемости в группах имеется несколько критериев (критерии для сравнения нескольких выборок представляют собой развитие соответствующих двухвыборочных):
- непараметричесий критерий Вилкоксона, предложенный для неполных наблюдений Геханом и Пето;
- F-критерий Кокса;
- логарифмический ранговый критерий (Lee, 1975 и 1980).
Эти критерии основаны на соответствующих z
-значениях стандартного нормального распределения, которые могут быть использованы для статистической проверки различий между группами. В то же время надёжные результаты получаются лишь при достаточно больших объёмах выборок, в противном случае эти критерии не столь надёжны. Для иллюстрации адекватности построенной модели удобно применять параллельно визуальные методы.
Замечание.
F-критерий Кокса обычно мощнее, чем критерий Вилкоксона-Гехана, если объёмы выборок (групп) меньше 50 ( ). Это верно также в том случае, если выборки извлекаются из экспоненциального распределения или распределения Вейбулла. ). Это верно также в том случае, если выборки извлекаются из экспоненциального распределения или распределения Вейбулла.
Сравним времена жизни пациентов, перенесших операции на сердце, в различных клиниках. Так как исходные данные содержат информацию о трех клиниках (Hillview, Biner и St. Andreas), выбираем опцию Сравнение нескольких выборок (
Comparing
multiple
samples
).
Графики позволяют наглядно убедиться в существовании различий между обозначенными группами (клиниками).
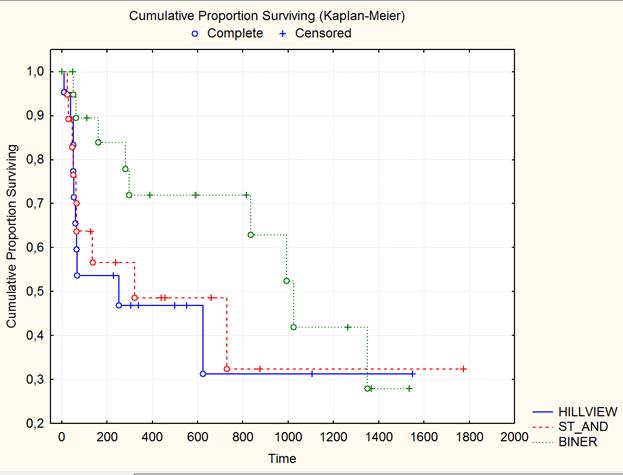
Рис. 8. Функции выживания для пациентов трех клиник.
Выводы:
Сразу можно отметить, что вероятность дожития пациентов, прооперированных в клинике BINER
, значительно выше, чем в двух других клиниках на протяжении практически всего наблюдаемого периода времени.
Список литературы
- Айвазян С.А., Мхитарян В.С. Прикладная статистика и основы эконометрики. – М., ЮНИТИ, 1998
- Боровиков В.П., Боровиков И.П. Статистический анализ и обработка данных в среде Windows. – М., Информационно-издательский дом «Филинъ», 1997
- Боровиков В.П. Популярное введение в программу «Statistica». – М., Компьютер-пресс, 1998
- Боровиков В.П. Statistica. Анализ и обработка данных в системе WINDOWS. – М., Финансы и статистика, 1998
- Боровиков В.П. Statistica: искусство анализа данных на компьютере (для профессионалов). – СПб., ПИТЕР, 2003
- Халафян А.А. Statistica 6. Статистический анализ данных. – М., Бином, 2008
- Экономико-математические методы и прикладные модели. Под редакцией Федосеева В.В. – М., ЮНИТИ, 1999
|
