МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ УКРАИНЫ
ТАВРИЧЕСКИЙ НАЦИОНАЛЬНЫЙ УНИВЕРСИТЕТ
ИМ. В.И. ВЕРНАДСКОГО
КУРСОВАЯ РАБОТА
на тему:
«Анализ регрессии в изучении экономических проблем»
Студентка 2 курса, группа 202-К, специальность «экономическая киберенетика»
Зворская А.В.
Научный руководитель
ф-м.к.н.,доц., Попов В.Б.
Симферополь 2010
СОДЕРЖАНИЕ
ВВЕДЕНИЕ………………………………………………………………………….3
РАЗДЕЛ 1. РЕГРЕССИОННЫЙ АНАЛИЗ………………………………………..4
РАЗДЕЛ 2 МНОЖЕСТВЕННАЯ ЛИНЕЙНАЯ РЕГРЕССИЯ……………………5
2.1 Определение параметров уравнения регрессии………………………………5
2.2 Расчет коэффициентов множественной линейной регресcии……………….9
2.3 Дисперсии и стандартные ошибки коэффициентов…………………………13
2.4 Интервальные оценки коэффициентов теоретического
уравнения регресcии…………………………………………………………..15
2.5 Анализ качества эмпирического уравнения множественной линейной регрессии………………………………………………………………………16
2.6 Проверка статистической значимости коэффициентов
уравнения регрессии………………………………………………………….16
2.7 Проверка общего качества уравнения регрессии……………………………17
2.8 Анализ статистической значимости коэффициента детерминации………..19
2.9 Проверка равенства двух коэффициентов детерминации…………………..21
2.10 Проверка гипотезы о совпадении уравнений регрессии
для двух выборок……………………………………………………………..23
РАЗДЕЛ 3 ЛИНЕЙНАЯ РЕГРЕССИЯ…………………………………………..25
ВЫВОДЫ…………………………………………………………………………..30
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ…………………………….....31
Введение
Постоянно усложняющиеся экономические процессы потребовали создания и совершенствования особых методов изучения и анализа. Широкое распространение получило использование моделирования и количественного анализа. На этом этапе выделилось и сформировалось одно из направлений экономических исследований – эконометрика.
Эконометрика как научная дисциплина зародилась и получила развитие на основе слияния экономической теории, математической экономики, экономической статистики и математической статистики. Действительно, предметом ее исследования являются экономические явления. Но в отличие от экономической теории эконометрика делает упор на количественные, а не на качественные аспекты этих явлений. Например, экономическая теория утверждает, что спрос на товар с ростом его цены убывает. Но при этом практически неисследованным остается вопрос, как быстро и по какому закону происходит это убывание.
Реклама

Эконометрика отвечает на этот вопрос для каждого конкретного случая. Изучение экономических процессов (взаимосвязей) в эконометрике осуществляется через математические (эконометрические) модели. В этом видится ее родство с математической экономикой. Но если математическая экономика строит и анализирует эти модели без использования реальных числовых значений, то эконометрика концентрируется на изучении моделей на базе эмпирических данных.
Одной из основных задач экономической статистики является сбор, обработка и представление экономических данных в наглядной форме в виде таблиц, графиков, диаграмм. Эконометрика также активно пользуется этим инструментарием, но идет дальше, используя его для анализа экономических взаимосвязей и прогнозирования. Мощным инструментом эконометрических исследований является аппарат математической статистики.
Цель работы: анализ экономических методов и моделей.
Задачи:
1 Обзор литературы;
2 Построение эконометрических моделей;
3 Оценка параметров построенной модели;
4 Проверка качества найденных параметров модели.
РАЗДЕЛ 1.
Регрессионный анализ
Регрессионный анализ — метод моделирования измеряемых данных и исследования их свойств. Данные состоят из пар значений зависимой переменной (переменной отклика) и независимой переменной (объясняющей переменной). Регрессионная модель есть функция независимой переменной и параметров с добавленной случайной переменной. Параметры модели настраиваются таким образом, что модель наилучшим образом приближает данные. Критерием качества приближения(целевой функцией) обычно является среднеквадратичная ошибка: сумма квадратов разности значений модели и зависимой переменной для всех значений независимой переменной в качестве аргумента. Регрессионный анализ — раздел математической статистики и машинного обучения. Предполагается, что зависимая переменная есть сумма значений некоторой модели и случайной величины. Относительно характера распределения этой величины делаются предположения, называемые гипотезой порождения данных. Для подтверждения или опровержения этой гипотезы выполняются статистические тесты, называемые анализом остатков. При этом предполагается, что независимая переменная не содержит ошибок. Регрессионный анализ используется для прогноза, анализа временных рядов, тестирования гипотез и выявления скрытых взаимосвязей в данных.
Реклама

Цели регрессионного анализа:
1 Определение степени детерминированности вариации критериальной (зависимой) переменной предикторами (независимыми переменными)
2 Предсказание значения зависимой переменной с помощью независимой.
3 Определение вклада отдельных независимых переменных в вариацию зависимой.
Регрессионный анализ нельзя использовать для определения наличия связи между переменными, поскольку наличие такой связи и есть предпосылка для применения анализа.
РАЗДЕЛ 2.
Множественная линейная регрессия
2.1 Определение параметров уравнения регрессии
На любой экономический показатель практически всегда оказывает влияние не один, а несколько факторов. Например, спрос на некоторое благо определяется не только ценой данного блага, но и ценами на замещающие и дополняющие блага, доходом потребителей и многими другими факторами. В этом случае вместо парной регрессии
M(Y|x) = f(x) рассматривается множественная регрессия
М(Y|x1, x2, …, xm) = f(x1, x2, …, xm). (2.1)
Задача оценки статистической взаимосвязи переменных Y и X1, X2, ..., Xm формулируется аналогично случаю парной регрессии. Уравнение множественной регрессии может быть представлено в виде
Y = f(β, X) + ε, (2.2)
где X = (X1, X2, ..., Xm) − вектор независимых (объясняющих) переменных; β − вектор параметров (подлежащих определению); ε − случайная ошибка (отклонение); Y – зависимая (объясняемая) переменная. Предполагается, что для данной генеральной совокупности именно функция f связывает исследуемую переменную Y с вектором независимых переменных X. Рассмотрим самую употребляемую и наиболее простую из моделей множественной регрессии – модель множественной линейной регрессии. Теоретическое линейное уравнение регрессии имеет вид:
Y = β0 + β1X1 + β2X2 + ... + βmXm + ε (2.3)
или для индивидуальных наблюдений i, i = 1, 2, …, n:
yi = β0 + β1xi1 + β2xi2 + ... + βmxim + εi. (2.4)
Здесь β = (β0, β1, ..., βm) – вектор размерности (m + 1) неизвестных параметров. βj, j = 1, 2, …, m, называется j-м теоретическим коэффициентом регрессии (частичным коэффициентом регрессии). Он характеризует чувствительность величины Y к изменению Xj. Другими словами, он отражает влияние на условное математическое ожидание
М(Y|x1, x2, …, xm) зависимой переменной Y объясняющей переменной Хj при условии, что все другие объясняющие переменные модели остаются постоянными. β0 – свободный член, определяющий значение Y, в случае, когда все объясняющие переменные Xj равны нулю. После выбора линейной функции в качестве модели зависимости необходимо оценить параметры регрессии. Пусть имеется n наблюдений вектора объясняющих переменных
X = (X1, X2, …, Xm) и зависимой переменной Y:
(xi1, xi2, …, xim, yi), i = 1, 2, …, n. Для того чтобы однозначно можно было бы решить задачу отыскания параметров β0, β1, ..., βm (т. е. найти некоторый наилучший вектор β), должно выполняться неравенство n ≥ m + 1. Если это неравенство не будет выполняться, то существует бесконечно много различных векторов параметров, при которых линейная формула связи между Х и Y будет абсолютно точно соответствовать имеющимся наблюдениям. При этом, если n = m + 1, то оценки коэффициентов вектора β рассчитываются единственным образом – путем решения системы m + 1 линейного уравнения:
yi = β0 + β1x i1 + β2x i2 + ... + βmx im , i = 1, 2, ..., m + 1. (2.5)
Например, для однозначного определения оценок параметров уравнения регрессии Y = β0 + β1X1 + β2X2 достаточно иметь выборку из трех наблюдений (x i1,x i2, xi3, yi), i = 1, 2, 3. Но в этом случае найденные значения параметров β0, β1, β2 определяют такую плоскость
Y = β0 + β1X1 + β2X в трехмерном пространстве, которая пройдет именно через имеющиеся три точки. С другой стороны, добавление в выборку к имеющимся трем наблюдениям еще одного приведет к тому, что четвертая точка (x 41,x 42, x 43, y4) практически наверняка будет лежать вне построенной плоскости (и, возможно, достаточно далеко). Это потребует определенной переоценки параметров. Таким образом, вполне логичен следующий вывод: если число наблюдений больше минимально необходимого, т. е. n > m+1, то уже нельзя подобрать линейную форму, в точности удовлетворяющую всем наблюдениям, и возникает необходимость оптимизации, т. е. оценивания параметров α0, α1, ..., αm, при которых формула дает наилучшее приближение для имеющихся наблюдений.
В данном случае число ν = n – m – 1 называется числом степеней свободы. Нетрудно заметить, что если число степеней свободы невелико, то статистическая надежность оцениваемой формулы невы-сока. Например, вероятность верного вывода (получения более точных оценок) по трем наблюдениям существенно ниже, чем по тридцати. Считается, что при оценивании множественной линейной регрессии для обеспечения статистической надежности требуется, чтобы число наблюдений, по крайней мере, в 3 раза превосходило число оцениваемых параметров.
Самым распространенным методом оценки параметров уравнения множественной линейной регрессии является метод наименьших квадратов (МНК). Напомним, что его суть состоит в минимизации суммы квадратов отклонений наблюдаемых значений зависимой переменной Y от ее значений YПрежде чем перейти к описанию алгоритма нахождения оценок коэффициентов регрессии, напомним о желательности выполнимости ряда предпосылок МНК, которые позволят проводить анализ в рамках классической линейной регрессионной модели.
Предпосылки МНК:
1
Математическое ожидание случайного отклонения εi равно нулю:
M(εi) = 0 для всех наблюдений. Данное условие означает, что случайное отклонение в среднем не оказывает влияния на зависимую переменную. В каждом конкретном наблюдении случайный член может быть либо положительным, либо отрицательным, но он не должен иметь систематического смещения. Отметим, что выполнимость M(εi) = 0 влечет выполнимость:
M(Y|X = = xi) = β0 + β1xi.
2
Дисперсия случайных отклонений εi постоянна:
D(εi) = D(εj) = σ2 для любых наблюдений i и j. Данное условие подразумевает, что несмотря на то, что при каждом конкретном наблюдении случайное отклонение может быть либо большим, либо меньшим, не должно быть некой априорной причины, вызывающей большую ошибку (отклонение).Выполнимость данной предпосылки называется гомоскедастичностью (постоянством дисперсии отклонений).
Невыполнимость данной предпосылки называется гетероскедастичностью (непосто-янством дисперсий отклонений). Поскольку D(εi) = M(εi − M(εi))2 = M(еi2) , то данную предпосылку можно переписать в форме: M(еi2)= σ2. Причины невыполнимости данной предпосылки и проблемы, свяанные с этим, подробно рассматриваются в главе 8.
3
Случайные отклонения εi и εj являются независимыми друг от друга для i ≠ j. Выполнимость данной предпосылки предполагает, что отсутствует систематическая связь между любыми случайными отклонениями. Другими словами, величина и определенный знак любого случайного отклонения не должны быть причинами величины и знака любого другого отклонения. Поэтому, если данное условие выполняется, то говорят об отсутствии автокорреляции. С учетом выполнимости предпосылки 10 соотношение (5.6) может быть переписано в виде: M(εiεj) = 0 (i ≠ j). Причины невыполнимости данной предпосылки и проблемы, свя-занные с этим, подробно рассматриваются в главе 9.
4
Случайное отклонение должно быть независимо от объясняющих переменных. Обычно это условие выполняется автоматически при условии,что объясняющие переменные не являются случайными в данной модели. Данное условие предполагает выполнимость следующего соотношения:
у = cov(εi, xi) = M((εi − M(εi))(xi − M(xi))) = M(εi(xi − M(xi))) =
еixi = M(εixi) − M(εi) M(xi) = M(εixi) = 0.
Следует отметить, что выполнимость данной предпосылки не столь критична для эконометрических моделей.
5
Модель является линейной относительно параметров
6
Отсутствие мультиколлинеарности. Между объясняющими переменными отсутствует строгая (сильная) линейная зависимость.
7
Ошибки εi имеют нормальное распределение /Выполнимость данной предпосылки важна для проверки статистических гипотез и построения интервальных оценок.
Как и в случае парной регрессии, истинные значения параметров βj по выборке получить невозможно. В этом случае вместо теоретического уравнения регрессии (6.3) оценивается так называемое эмпирическое уравнение регрессии. Эмпирическое уравнение регрессии представим в виде:
Y = b0 + b1X1 + b2X2 + ... + bmXm+ е. (2.6)
Здесь b0, b1, ..., bm − оценки теоретических значений β1, β2, ..., βm коэффициентов регрессии (эмпирические коэффициенты регрессии); е − оценка отклонения ε. Для индивидуальных наблюдений имеем:
yi = b0 + b1xi1 + … + bmxim + ei. (2.7)
Оцененное уравнение в первую очередь должно описывать общий тренд (направление) изменения зависимой переменной Y. При этом необходимо иметь возможность рассчитать отклонения от этого тренда. По данным выборки объема n: (xi1, xi2,… , xim, yi), i = 1, 2, … , n требуется оценить значения параметров βj вектора β, т. е. провести параметризацию выбранной модели (здесь xij, j = 1, 2, … , m − значение переменной Xj в i-м наблюдении). При выполнении предпосылок МНК относительно ошибок εi оценки b0, b1, ..., bm параметров β1, β2, ..., βm множественной линейной регрессии по МНК являются несмещенными, эффективными и состоятельными (т. е. BLUE-оценками). На основании (6.7) отклонение еi значения yi зависимой переменной Y от модельного значения y)i , соответствующего уравнению регрессии в i-м наблюдении (i = 1, 2, …, n), рассчитывается по формуле:
ei = yi – b0 – b1xi1 − … − bmxim. (2.8)
Тогда по МНК для нахождения оценок b0, b1, ..., bm минимизируется следующая функция:
Q= ∑ei2 = ∑(yi −(b0 +∑bjxij))2 . (2.9)
i=1 i=1 j=1
Данная функция является квадратичной относительно неизвестных величин bj, j = 0, 1, ..., m. Она ограничена снизу, следовательно, имеет минимум. Необходимым условием минимума функции Q является равенство нулю всех ее частных производных по bj. Частные производные квадратичной функции (6.9) являются линейными функциями.
Приравнивая их к нулю, мы получаем систему (m + 1) линейного уравнения с (m + 1) неизвестным:
∂Q/ ∂b0 = −2∑n (yi −(b0 +∑mbjxij)),
∂Q/ ∂bj = −2∑(yi −(b0 +∑bjxij))xij, j=1, 2, ... , m. (2.10)
Такая система имеет обычно единственное решение. В исключительных случаях, когда столбцы системы линейных уравнений линейно зависимы, она имеет бесконечно много решений или не имеет решения вовсе. Однако данные реальных статистических наблюдений к таким исключительным случаям практически никогда не приводят. Система (6.11) называется системой нормальных уравнений. Ее решение в явном виде наиболее наглядно представимо в векторноматричной форме.
2.2 Расчет коэффициентов множественной линейной регресcии
Представим данные наблюдений и соответствующие коэффициенты в матричной форме. Здесь Y − вектор-столбец размерности n наблюдений зависимой переменной Y; Х − матрица размерности n Ч (m + 1), в которой i-я строка (i = 1, 2, … , n) представляет наблюдение вектора значений независимых переменных X1, X2, … , Xm; единица соответствует переменной при свободном члене b0; B − вектор-столбец размерности
(m + 1) параметров уравнения регрессии (6.6); e − вектор-столбец размерности n отклонений выборочных (реальных) значений yi зависимой переменной Y от значений y^i , получаемых по уравнению регрессии
Y^i = b0 + b1X1 + b2X2 + ... + bmXm. (2.12)
Нетрудно заметить, что функция Q= ∑ei2 в матричной форме представима как произведение вектор-строки eT = ( e1, e2, ... , en ) на вектор-столбец e. Вектор-столбец e, в свою очередь, может быть записан в следующем виде:
e = Y − XB. (2.13)
Отсюда:
Q = eT⋅e = (Y − XB)T⋅( Y −XB) = YT Y −BT XT Y −YT XB +BT XT XB =
= YT Y − 2BT XT Y + BTXT XB. (2.14)
Здесь eT, BT, XT, YT − векторы и матрицы, транспонированные к e, B, X, Y соответственно. При выводе формулы (6.14) мы воспользовались известными соотношениями линейной алгебры:
(Y − XB)T = YT - (XB)T; (XB)T = BTXT; BT XT Y = YT XB. (2.15)
Эти соотношения легко проверить, записав поэлементно все мат-рицы и выполнив с ними нужные действия. Необходимым условием экстремума функции Q является равенство нулю ее частных производных 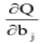 по всем параметрам bj, в матричном виде имеет следующий вид: по всем параметрам bj, в матричном виде имеет следующий вид:
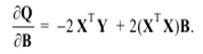 (2.16) (2.16)
Для упрощения изложения обозначим матрицу XT X размерности (m + 1) Ч (m + 1) через Z. Обозначим вектор-столбец ХTY размерности (m + 1) через R. Тогда BT XT Y = BTR = ∑ajrj+1, где rj+1 – соответствующий элемент вектора R.
Следовательно, формула (2.16) справедлива. Приравняв ∂Q/ ∂b0 нулю, получим общую формулу (2.18) вычисления коэффициентов множественной линейной регрессии.
Здесь (XT X)−1 − матрица, обратная к XT X. Полученные общие соотношения справедливы для уравнений регрессии с произвольным количеством m объясняющих переменных. Проанализируем полученные результаты для случаев m = 1, m = 2. Для парной регрессии Y = b0 + b1X + e имеем: (Приложения А)
Сравнивая диагональные элементы z′jj матрицы Z−1= (XT X)−1 с формулами , замечаем, что Sb2j= S2 ⋅ z′jj , j = 0, 1. Рассуждая аналогично, можно вывести формулы (осуществление выкладок рекомендуем в качестве упражнения) определения коэффициентов регрессии для уравнения с двумя объясняющими переменными (m = 2). Соотношение (6.17) в этом случае в расширенной форме имеет вид системы трех линейных уравнений с тремя неизвестными b0, b1, b2:
∑yi = nb0 + b1∑xi1 + b2∑xi2 ,
∑xi1yi =b0∑xi1 +b1∑xi21 +b2∑xi1xi2, (2.19)
∑xi2yi =b0∑xi2 +b1∑xi1xi2 +b2∑xi22.
2.3 Дисперсии и стандартные ошибки коэффициентов
Знание дисперсий и стандартных ошибок позволяет анализировать точность оценок, строить доверительные интервалы для теоретических коэффициентов, проверять соответствующие гипотезы. Наиболее удобно формулы расчета данных характеристик приводить в матричной форме. Попутно заметим, что три первые предпосылки МНК в матричной форме будут иметь вид:
1 M(ε) = 0;
2 D(ε) = σ2I;
3 K(ε) = M(εεT) = σ2E.

Как показано выше, эмпирические коэффициенты множественной линейной регрессии определяются по формуле (2.18)
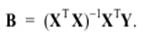
Подставляя теоретические значения Y = Xβ + ε в данное соотношение, имеем:
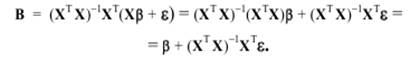
Построим дисперсионно-ковариационную матрицу
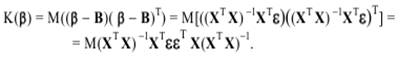
В силу того, что Хj не являются случайными величинами, имеем:
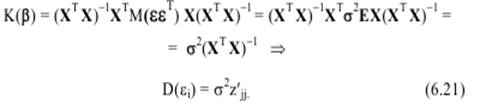
Напомним, что z′jj− j-й диагональный элемент матрицы Поскольку истинное значение дисперсии σ2 по выборке определить невозможно, оно заменяется соответствующей несмещенной оценкой

где m − количество объясняющих переменных модели. Отметим, что иногда в формуле (6.22) знаменатель представляют в виде n − m − 1 = = n − k, подразумевая под k число параметров модели (подлежащих определению коэффициентов регрессии). Следовательно, по выборке мы можем определить лишь выбороч-ные дисперсии эмпирических коэффициентов регрессии:
Sb2j= S2 z′jj = n−∑mei2−1 z′jj, j = 0, 1, …, m. (2.23)
Как и в случае парной регрессии, S = S2 называется стандартной ошибкой регрессии. Sbj = S2bj называется стандартной ошибкой коэффициента регрессии. В частности, для уравнения Y) =b0 +b1X1 +b2X2 с двумя объясняющими переменными дисперсии и стандартные ошибки коэффициентов вычисляются по следующим формулам (Приложение В) .Здесь r12 = rx1x2− выборочный коэффициент корреляции между
объясняющими переменными Х1 и Х2.
2.4 Интервальные оценки коэффициентов теоретического уравнения регресcии
По аналогии с парной регрессией после определения точечных оценок bj коэффициентов βj (j = 0, 1, …, m) теоретического уравнения регрессии могут быть рассчитаны интервальные оценки указанных коэффициентов. Для построения интервальной оценки коэффициента βj строится t-статистика имеющая распределение Стьюдента с числом степеней свободы ν = = n − m − 1 (n − объем выборки, m − количество объясняющих переменных в модели). Пусть необходимо построить 100(1 − α)%-ный доверительный интервал для коэффициента βj. Тогда по таблице критических точек распределения Стьюдента по требуемому уровню значимости α и числу степеней свободы ν находят критическую точку tб , n−m−1=2
Таким образом, доверительный интервал, накрывающий с надежностью (1 − α) неизвестное значение параметра βj, Не вдаваясь в детали, отметим, что по аналогии с парной регрессией (см. раздел 5.5) может быть построена интервальная оценка для среднего значения предсказания:
В матричной форме это неравенство имеет вид:
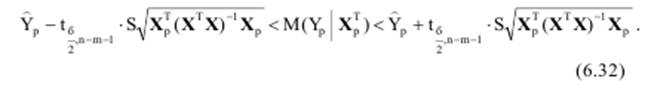
2.5 Анализ качества эмпирического уравнения множественной линейной регрессии
Построение эмпирического уравнения регрессии является начальным этапом эконометрического анализа. Первое же построенное по выборке уравнение регрессии очень редко является удовлетворительным по тем или иным характеристикам. Поэтому следующей важнейшей задачей эконометрического анализа является проверка качества уравнения регрессии. В эконометрике принята устоявшаяся схема такой проверки (по крайней мере, на начальной стадии). Это нашло отражение практически во всех современных эконометрических пакетах. Проверка статистического качества оцененного уравнения регрессии проводится по следующим направлениям:
• проверка статистической значимости коэффициентов уравнения
регрессии;
• проверка общего качества уравнения регрессии;
• проверка свойств данных, выполнимость которых предполагалась при оценивании уравнения (проверка выполнимости предпосылок
МНК).
2.6 Проверка статистической значимости коэффициентов уравнения регрессии
Как и в случае парной регрессии ,статистическая значимость коэффициентов множественной линейной регрессии с m объясняющими переменными проверяется на основе t-статистики: t=bj/Sbj (2.33)
Имеющей в данной ситуации распределение Стьюдента с числом степеней свободы ν = n − m − 1 (n − объем выборки). При требуемом уро-вне значимости α наблюдаемое значение t-статистики сравнивается с критической точкой распределения Стьюдента.
Коэффициент bj считается статистически незначимым (статистически близким к нулю). Это означает, что фактор Xj фактически линейно не связан с зависимой переменной Y. Его наличие среди объясняющих переменных не оправдано со статистической точки зрения. Не оказывая серьезного влияния на зависимую переменную, он лишь искажает реальную картину взаимосвязи. Поэтому после установления того факта, что коэффициент bj статистически незначим, рекомендуется исключить из уравнения регрессии переменную Xj. Это не приведет к существенной потере качества модели, но сделает ее более конкретной. Зачастую строгая проверка значимости коэффициентов заменяется простым сравнительным анализом.
• Если |t| < 1 ( bj < Sbj ), то коэффициент статистически незначим.
• Если 1 < |t| < 2 ( bj < 2Sbj ), то коэффициент относительно значим. В данном случае рекомендуется воспользоваться таблицами.
• Если 2 < |t| < 3, то коэффициент значим. Это утверждение является гарантированным при числе степеней ν > 20 и α ≥ 0.05 (см. таблицу критических точек распределения Стьюдента).
• Если |t| > 3, то коэффициент считается сильно значимым. Вероятность ошибки в данном случае при достаточном числе наблюдений не превосходит 0.001.
2.7 Проверка общего качества уравнения регрессии
После проверки значимости каждого коэффициента регрессии обычно проверяется общее качество уравнения регрессии. Для этой цели, как и в случае парной регрессии, используется коэффициент детерминации R2, который в общем случае рассчитывается по формуле:
R2=1-∑ei2/∑(yi-y)2 (2.34)
Суть данного коэффициента как доли общего разброса значений зависимой переменной Y, объясненного уравнением регрессии. Как отмечалось, в общем случае 0 ≤ R2 ≤ 1. Чем ближе этот коэффициент к единице, тем больше уравнение регрессии объясняет поведение Y. Поэтому естественно желание построить регрессию с наибольшим R2. Для множественной регрессии коэффициент детерминации является неубывающей функцией числа объясняющих переменных. Добавление новой объясняющей переменной никогда не уменьшает значение R2.Действительно, каждая следующая объясняющая переменная может лишь дополнить, но никак не сократить информацию, объясняющую поведение зависимой переменной. Это уменьшает (в худшем случае не увеличивает) область неопределенности в поведении Y. Иногда при расчете коэффициента детерминации для получения несмещенных оценок в числителе и знаменателе вычитаемой из единицы дроби делается поправка на число степеней свободы. Вводится так называемый скорректированный (исправленный) коэффициент детерминации
Можно заметить, что ∑(yi −y)2/(n−1) является несмещенной оценкой общей дисперсии − дисперсии отклонений значений переменной Y от y. При этом число ее степеней свободы равно (n −1). Одна степень свободы теряется при вычислении y. ∑ei2 /(n−m−1) является несмещенной оценкой остаточной дисперсии − дисперсии случайных отклонений (отклонений точек наблюдений от линии регрессии). Ее число степеней свободы равно (n−m−1). Потеря (m + 1) степени свободы связана с необходимостью решения системы (m + 1) линейного уравнения при определении коэффициентов эмпирического уравнения регрессии. Попутно заметим, что несмещенная оценка объясненной дисперсии (дисперсии отклонений точек на линии регрессии от y) имеет число степеней свободы, равное разности степеней свободы общей дисперсии и остаточной дисперсии:
(n − 1) − (n − m − 1) = m.
Из (2.36) очевидно, что R2 <R2для m > 1. С ростом значения m скорректированный коэффициент детерминации R2 растет медленнее, чем (обычный) коэффициент детерминации R2. Другими словами, он корректируется в сторону уменьшения с ростом числа объясняющих переменных. Нетрудно заметить, что R2 =R2только при R2 = 1.
R2 может принимать отрицательные значения (например, при R2 = 0). Доказано, что R2 увеличивается при добавлении новой объясняющей переменной тогда и только тогда, когда t-статистика для этой переменной по модулю больше единицы. Поэтому добавление в модель новых объясняющих переменных осуществляется до тех пор, пока растет скорректированный коэффициент детерминации. Обычно в эконометрических пакетах приводятся данные как по R2, так и по R2, являющиеся суммарными мерами общего качества уравнения регрессии. Однако не следует абсолютизировать значимость коэффициентов детерминации. Существует достаточно примеров неправильно специфицированных моделей, имеющих высокие коэффициенты детерминации (обсудим данную ситуацию позже). Поэтому коэффициент детерминации в настоящее время рассматривается лишь как один из ряда показателей, который нужно проанализировать, чтобы уточнить строящуюся модель.
2.8 Анализ статистической значимости коэффициента детерминации
После оценки индивидуальной статистической значимости каждого из коэффициентов регрессии обычно анализируется совокупная значимость коэффициентов. Такой анализ осуществляется на основе проверки гипотезы об общей значимости − гипотезы об одновременном равенстве нулю всех коэффициентов регрессии при объясняющих переменных:
Н0: β1 = β2 = … = βm = 0.
Если данная гипотеза не отклоняется, то делается вывод о том, что совокупное влияние всех m объясняющих переменных Х1, Х2, …, Хm модели на зависимую переменную Y можно считать статистически несущественным, а общее качество уравнения регрессии − невысоким. Проверка данной гипотезы осуществляется на основе дисперсионного анализа − сравнения объясненной и остаточной дисперсий. Н0: (объясненная дисперсия) = (остаточная дисперсия),
Н1: (объясненная дисперсия) > (остаточная дисперсия).
Для этого строится F-статистика:
F= ∑ki2/m/∑ei2/(n-m-1)=∑(yi-y)2/m/∑(yi-yi)2/(n-m-1) (2.37)
где ∑ki2/m − объясненная дисперсия; ∑ei2/(n−m−1) − остаточная дисперсия. При выполнении предпосылок МНК построенная F-статистика имеет распределение Фишера с числами степеней свободы ν1 = = m, ν2 = n − m − 1. Поэтому, если при требуемом уровне значимости α Fнабл. > Fкр. = Fα;m;n−m−1 (где Fα;m;n−m−1 − критическая точка распределения Фишера), то Н0 отклоняется в пользу Н1. Это означает, что объясненная дисперсия существенно больше остаточной дисперсии, а следовательно, уравнение регрессии достаточно качественно отражает динамику изменения зависимой переменной Y. Если Fнабл. < Fкр. = Fα;m;n−m−1, то нет оснований для отклонения Н0. Значит, объясненная дисперсия соизмерима с дисперсией, вызванной случайными факторами. Это дает основания считать, что совокупное влияние объясняющих переменных модели несущественно, а следовательно, общее качество модели невысоко. Однако на практике чаще вместо указанной гипотезы проверяют тесно связанную с ней гипотезу о статистической значимости коэффициента детерминации R2:
Н0: R2 = 0,
Н0: R2 > 0.
Для проверки данной гипотезы используется следующая F-
статистика:
F=R2/1-R2*n-m-1/m (2.38)
Величина F при выполнении предпосылок МНК и при справедливости H0 имеет распределение Фишера аналогичное F-статистике (2.37). Действительно, разделив числитель и знаменатель дроби в (2.37) на общую сумму квадратов отклонений ∑(yi −y)2
Очевидно, что показатели F и R2 равны или не равны нулю одновременно. Если F = 0, то R2 = 0, и линия регрессии Y = y является наилучшей по МНК, и, следовательно, величина Y линейно не зависит от X1, Х2, ..., Xm. Для проверки нулевой гипотезы H0: F= 0 при заданном уровне значимости α по таблицам критических точек распределения Фишера находится критическое значение Fкр. = Fα;m;n−m−1. Нулевая гипотеза отклоняется, если F > Fкр.. Это равносильно тому, что R2 > 0, т. е. R2 статистически значим. Анализ статистики F позволяет сделать вывод о том, что для принятия гипотезы об одновременном равенстве нулю всех коэффициентов линейной регрессии, коэффициент детерминации R2 не должен существенно отличаться от нуля. Его критическое значение уменьшается при росте числа наблюдений и может стать сколь угодно малым.
Пример:
Пусть, например, при оценке регрессии с двумя объясняющими переменными по 30 наблюдениям R2 = 0.65. Тогда F = 0.65 ⋅ 30−2−1 ≈ 25.07. По таблицам критических точек распределения Фишера найдем F0.05;2;27 = 3.36; F0,01;2;27 = 5.49. Поскольку F набл. = 25.07 > F крит. как при 5%, так и при 1% уровне значимости, то нулевая гипотеза в обоих случаях отклоняется. Если в той же ситуации R2 = 0.4, то F = 9. Предположение о не значимости связи отвергается и здесь. Отметим, что в случае парной регрессии проверка нулевой гипотезы для F-статистики равносильна проверке нулевой гипотезы для t-статистики коэффициента корреляции В этом случае F-статистика равна квадрату t-статистики. Самостоятельную важность коэффициент R2 приобретает в случае множественной линейной регрессии.
2.9 Проверка равенства двух коэффициентов детерминации
Другим важным направлением использования статистики Фишера является проверка гипотезы о равенстве нулю не всех коэффициентов регрессии одновременно, а только некоторой части этих коэффициентов. Данное использование статистики F позволяет оценить обоснованность исключения или добавления в уравнение регрессии некоторых наборов объясняющих переменных, что особенно важно при совершенствовании линейной регрессионной модели. Пусть первоначально построенное по n наблюдениям уравнение регрессии имеет вид
Y = b0 + b1X1 + b2X2 + ... + bm-kXm-k + ... + bmXm , (6.39)
и коэффициент детерминации для этой модели равен R12. Исключим из рассмотрения k объясняющих переменных (не нарушая общности, положим, что это будут k последних переменных). По первоначальным n наблюдениям для оставшихся факторов построим другое уравнение регрессии:
Y = с0 + с1X1 + с2X2 + ... + сm-kXm-k, (6.40)
для которого коэффициент детерминации равен R22. Очевидно, R2 ≤R2, так как каждая дополнительная переменная объясняет часть (пусть незначительную) рассеивания зависимой переменной. Возникает вопрос: существенно ли ухудшилось качество описания поведения зависимой переменной Y. На него можно ответить, проверяя гипотезу H0: R12 − R22 = 0 и используя статистику
F=R2/1-R2*n-m-1/k (2.41)
В случае справедливости H0 приведенная статистика F имеет распределение Фишера с числами степеней свободы ν1 = k , ν2 = n − m − 1.
Здесь (R12 −R22) − потеря качества уравнения в результате отбрасывания k объясняющих переменных; k − число дополнительно появившихся степеней свободы; (1−R12)/(n−m−1) − необъясненная дисперсия первоначального уравнения. Следовательно, мы попадаем в ситуацию аналогичную (6.37). По таблицам критических точек распределения Фишера находят Fкр. = Fα;m;n−m−1 (α − требуемый уровень значимости).
Если рассчитанное значение Fнабл. статистики (6.41) превосходит Fкр., то нулевая гипотеза о равенстве коэффициентов детерминации (фактически об одновременном равенстве нулю отброшенных k коэффициентов регрессии) должна быть отклонена. В этом случае одновременное исключение из рассмотрения k объясняющих переменных некорректно, так как R12существенно превышаетR22. Это означает, что общее качество первоначального уравнения регрессии существенно лучше качества уравнения регрессии с отброшенными переменными, так как оно объясняет гораздо большую долю разброса зависимой переменной. Если же, наоборот, наблюдаемая F-статистика невелика (т. е. меньше, чем Fкр.), то это означает, что разность R12− R22 незначительна. Следовательно, можно сделать вывод, что в этом случае одновременное отбрасывание k объясняющих переменных не привело к существенному ухудшению общего качества уравнения регрессии, и оно вполне допустимо. Аналогичные рассуждения могут быть использованы и по поводу обоснованности включения новых k объясняющих переменных. В этом случае рассчитывается F-статистика. Если она превышает критическое значение Fкр., то включение новых переменных объясняет существенную часть необъясненной ранее дисперсии зависимой переменной.
Поэтому такое добавление оправдано. Однако отметим, что добавлять переменные целесообразно, как правило, по одной. Кроме того, при добавлении объясняющих переменных в уравнение регрессии логично использовать скорректированный коэффициент детерминации (6.35), т. к. обычный R2 всегда растет при добавлении новой переменной; а в скорректированном R2одновременно растет величина m, уменьшающая его. Если увеличение доли объясненной дисперсии при добавлении новой переменной незначительно, то R2 может уменьшиться. В этом случае добавление указанной переменной нецелесообразно. Заметим, что для сравнения качества двух уравнений регрессии по коэффициенту детерминации R2 обязательным является требование, чтобы зависимая переменная была представлена в одной и той же форме, и число наблюдений n для обеих моделей было одинаковым. Например, пусть один и тот же показатель Y моделируется двумя уравнениями:
линейным Y = β0 + β1X1 + β2X2 + ε и
лог-линейным lnY = β0 + β1X1 + β2X2 + ε.
Тогда их коэффициенты детерминации R12 и R22 рассчитываются по формулам:
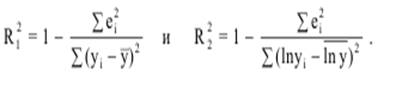
Так как знаменатели дробей в приведенных соотношениях различны, то прямое сравнение коэффициентов детерминации в этом случае будет некорректным.
2.10 Проверка гипотезы о совпадении уравнений регрессии для двух выборок.
Еще одним направлением использования F-статистики является проверка гипотезы о совпадении уравнений регрессии для отдельных групп наблюдений. Одним из распространенных тестов проверки данной гипотезы является тест Чоу, суть которого состоит в следующем. Пусть имеются две выборки объемами n1 и n2 соответственно.
Для каждой из этих выборок оценено уравнение регрессии вида:
Y = b0k + b1kX1 + b2kX2 + ... + bmkXm + ek, k = 1, 2. (6.44)
Проверяется нулевая гипотеза о равенстве друг другу соответствующих коэффициентов регрессии
H0: bj1 = bj2, j = 0, 1, ..., m.
Другими словами, будет ли уравнение регрессии одним и тем же для обеих выборок?
Пусть суммы ∑ei2k (k = 1, 2) квадратов отклонений значений yi от линий регрессии равны S1 и S2 соответственно для первого и второго уравнений регрессии. Пусть по объединенной выборке объема (n1 + n2) оценено еще одно уравнение регрессии, для которого сумма квадратов отклонений yi от уравнения регрессии равна S0. Для проверки Н0 в этом случае строится следующая F-статистика:
В случае справедливости H0 построенная F-статистика имеет распределение Фишера с числами степеней свободы ν1 = m + 1; ν2 = n1 + + n2 − 2m − 2 . Очевидно, F-статистика близка к нулю, если S0 ≈ S1 + S2 , и это фактически означает, что уравнения регрессии для обеих выборок практически одинаковы. В этом случае F < Fкрит.=Fб;н1;н2. Если же F > Fкрит., то нулевая гипотеза отклоняется. Приведенные выше рассуждения особенно важны для ответа на вопрос, можно ли за весь рассматриваемый период времени построить единое уравнение регрессии (рис. 6.1, а), или же нужно разбить временной интервал на части и на каждой из них строить свое уравнение регрессии (рис. 6.1).
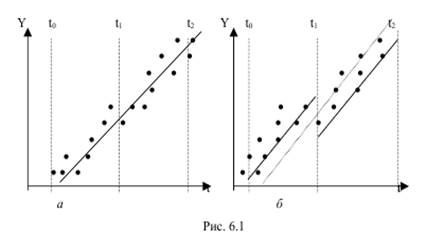
Некоторые причины необходимости использования различных уравнений регрессии для описания изменения одной и той же зависимой переменной на различных временных интервалах будут анализироваться ниже при рассмотрении фиктивных переменных и временных рядов.
РАЗДЕЛ 3.
Линейная регрессия
В тех случаях, когда из природы процессов в модели или из данных наблюдений над ней следует вывод о нормальном законе распределения двух СВ- Y и X, из которых одна является независимой, т. е. Y является функцией X, то возникает соблазн определить такую зависимость аналитически. В случае успеха нам будет намного проще вести моделирование. Конечно, наиболее заманчивой является перспектива линейной зависимости типа Y = a + b(X .Подобная задача носит название задачи регрессионного анализа и предполагает следующий способ решения. Выдвигается следующая гипотеза:H0: случайная величина Y при фиксированном значении величины распределена нормально с математическим ожиданием.
My = a + b(X и дисперсией Dy, не зависящей от X. При наличии результатов наблюдений над парами Xi и Yi предварительно вычисляются средние значения My и Mx, а затем производится оценка коэффициента b в вид
b =[pic][pic] = Rxy [pic][pic]
что следует из определения коэффициента корреляции. После этого вычисляется оценка для a в виде {2 - 16}и производится проверка значимости полученных результатов. Таким образом, регрессионный анализ является мощным, хотя и далеко не всегда допустимым расширением корреляционного анализа, решая всё ту же задачу оценки связей в сложной системе. Теперь более подробно рассмотрим множественную или многофакторную регрессию. Нас интересует только линейная модель вида Y=A0+A1X1+A2X2+…..AkXk.
Изучение связи между тремя и более связанными между собой признаками носит название множественной (многофакторной) регрессии. При исследовании зависимостей методами множественной регрессии задача формулируется так же,как и при использовании парной регрессии, т. е. требуется определить аналитическое выражение связи между результативным признаком (У) и факторными признаками (х1 х2, х3 ..., хn) найти функцию: Y=f(х1. Х2..., хn
Построение моделей множественной регрессии включает несколько этапов:
• выбор формы связи (уравнения регрессии):
• отбор факторных признаков:
• обеспечение достаточного объема совокупности для получения
несмещенных оценок.
Рассмотрим подробнее каждый из них. Выбор формы связи затрудняется тем, что, используя математический аппарат, теоретически зависимость между признаками может быть выражена большим числом различных функций. Выбор типа уравнения осложнен тем, что для любой формы зависимости выбирается целый ряд уравнений, которые в определенной степени будут описывать эти связи. Некоторые предпосылки для выбора определенного уравнения регрессии получают на основе анализа предшествующих аналогичных исследований или на базе анализа подобных работ в смежных отраслях знаний. Поскольку уравнение регрессии строится главным образом для объяснения и количественного выражения взаимосвязей, оно должно хорошо отражать сложившиеся между исследуемыми факторами фактические связи более приемлемым способом определения вида исходного уравнения регрессии является метод перебора различных уравнений. Сущность данного метода заключается в том, что большое число уравнений (моделей) регрессии, отобранных для описания связей какого-либо социально- экономического явления или процесса, реализуется на ЭВМ с помощью специально разработанного алгоритма перебора с последующей статистической проверкой, главным образом на основе t-критерия Стьюдeнта и F-критерия Фишера. Способ перебора является достаточно трудоемким и связан с большим объемом вычислительных работ. Практика построения многофакторных моделей взаимосвязи показывает, что все реально существующие зависимости между социально-экономическими явлениями можно описать, используя пять типов моделей:
1. линейная: Y=A0+A1X1+….AkXk
2. степенная
3. показательная
4. параболическая
5. гиперболическая
Основное значение имеют линейные модели в силу простоты и логичности их экономической интерпретации. Нелинейные формы зависимости приводятся к линейным путем линеаризации
Важным этапом построения уже выбранного уравнения множественной регрессии являются отбор и последующее включение факторных признаков. Сложность формирования уравнения множественной регрессии заключается в том, что почти все факторные признаки находятся в зависимости один от другого. Проблема размерности модели связи, т. е. определение оптимального числа факторных признаков, является одной из основных проблем построения множественного уравнения регрессии. С одной стороны, чем больше факторных признаков включено в уравнение, тем оно лучше описывает явление. Однако модель размерностью 100 и более факторных признаков сложно реализуема и требует больших затрат машинного времени. Сокращение размерности модели за счет исключения второстепенных, экономически и статистически несущественных факторов способствует простоте и качеству ее реализации. В то же время построение модели регрессии малой размерности может привести к тому, что такая модель будет недостаточно адекватна исследуемым явлениям и процессам. Проблема отбора факторных признаков для построения моделей взаимосвязи может быть решена на основе эвристических или многомерных статистических методов анализа.
Метод экспертных оценок как эвристический метод анализа основных макроэкономических показателей, формирующих единую ,родную систему расчетов, основан на интуитивно-логических предпосылках, содержательно-качественном анализе. Анализ экспертной информации проводится на базе расчета и анализа непараметрических показателей связи: ранговых коэффициентов корреляции Спирмена, Кендалла и конкордации. Наиболее приемлемым способом отбора факторных признаков является шаговая регрессия (шаговый регрессионный анализ).
Сущность метода шаговой регрессии заключается в последовательном включении факторов в уравнение регрессии и последующей проверке их значимости. Факторы поочередно вводятся в уравнение так называемым "прямым методом". При проверке значимости введенного фактора определяется, насколько уменьшается сумма квадратов остатков и увеличивается величина множественного коэффициента корреляции . одновременно используется и обратный метод, т.е. исключение факторов, ставших незначимыми на основе t-критерия Стьюдента. Фактор является незначимым, если его включение в уравнение регрессии только изменяет значение коэффициентов регрессии, не уменьшая суммы квадратов остатков и не увеличивая их значения.
Если при включении в модель соответствующего факторного признака величина множественного коэффициента корреляции увеличивается, а коэффициент регрессии не изменяется (или меняется несущественно), то данный признак существен и его включение в уравнение регрессии необходимо. Если же при включении в модель факторного признака коэффициенты регрессии меняют не только величину, но и знаки, а множественный коэффициент корреляции не возрастает, то данный факторный признак признается нецелесообразным для включения в модель связи.
Сложность и взаимное переплетение отдельных факторов, обусловливающих исследуемое экономическое явление (процесс), могут проявляться в так называемой мультиколлинеарности. Под мультиколлинеарностью понимается тесная зависимость между факторными признаками, включенными в модель. Наличие мультиколлинеарности между признаками приводит к:
1 искажению величины параметров модели, которые имеют тенденцию к
завышению;
2 изменению смысла экономической интерпретации коэффициентов регрессии;
3 слабой обусловленности системы нормальных уравнений;
4 осложнению процесса определения наиболее существенных факторных
признаков.
Одним из индикаторов определения наличия мультиколлинеарности между признаками является превышение парным коэффициентом корреляции величины 0,8.Устранение мультиколлинеарности может реализовываться через исключение из корреляционной модели одного или нескольких линейно-связанных факторных признаков или преобразование исходных факторных признаков в новые, укрупненные факторы. Вопрос о том, какой из факторов следует отбросить, решается на основании качественного и логического анализов изучаемого явления. Качество уравнения регрессии зависит от степени достоверности и надежности исходных данных и объема совокупности. Исследователь должен стремиться к увеличению числа наблюдений, так как большой объем наблюдений является одной из предпосылок построения адекватных статистических моделей. Аналитическая форма выражения связи результативного признака и ряда факторных называется многофакторным (множественным) уравнением регрессии, или моделью связи.
Уравнение линейной множественной регрессии имеет вид:
Y=A0+A1X1+….AkXk
Коэффициенты Аn вычисляются при помощи систем нормальных уравнений.
Проверка адекватности моделей, построенных на основе уравнений регрессии, начинается с проверки значимости каждого коэффициента регрессии. Значимость коэффициентов регрессии осуществляется с помощью t-критерия Стьюдента:
- дисперсия коэффициента регрессии. Параметр модели признается статистически значимым, если tp>tкр Наиболее сложным в этом выражении является определение дисперсии, которая может быть рассчитана двояким способом. Наиболее простой способ, выработанный методикой экспериментирования, заключается в том, что величина дисперсии коэффициента регрессии может быть приближенно определена по выражению:
- дисперсия результативного признака: k - число факторных признаков в уравнении.
Наиболее сложным этапом, завершающим регрессионный анализ, является интерпретация уравнения, т. е. перевод его с языка статистики и математики на язык экономиста. Интерпретация моделей регрессии осуществляется методами той отрасли знаний, к которой относятся исследуемые явления. Но всякая интерпретация начинается со статистической оценки уравнения регрессии в целом и оценки значимости входящих в модель факторных признаков, т. е. с выяснения, как они влияют на величину результативного признака. Чем больше величина коэффициента регрессии, тем значительнее влияние данного признака на моделируемый. Особое значение при этом имеет знак перед коэффициентом регрессии. Знаки коэффициентов регрессии говорят о характере влияния на результативный признак. Если факторный признак имеет знак плюс, то с увеличением данного фактора результативный признак возрастает; если факторный признак со знаком минус, то с его увеличением результативный признак уменьшается. Интерпретация этих знаков полностью определяется социально-экономическим содержанием моделируемого (результативного) признака. Если его величина изменяется в сторону увеличения, то плюсовые знаки факторных признаков имеют положительное влияние.
При изменении результативного призна-л-1 в сторону снижения положительное значение имеют минусовые знаки факторных признаков. Если экономическая теория подсказывает, что факторный признак должен иметь положительное значение, а он со знаком минус, то необходимо проверить расчеты параметров уравнения регрессии. Такое явление чаще всего бывает в силу допущенных ошибок при решении. Однако следует иметь в виду, что при анализе совокупного влияния факторов, при наличии взаимосвязей между ними характер их влияния может меняться. Для того чтобы быть уверенным, что факторный признак изменил знак влияния, необходима тщательная проверка решения данной модели, так как часто знаки могут меняться в силу допустимых ошибок при сборе или обработке информации.
При адекватности уравнения регрессии исследуемому процессу возможны следующие варианты.
1. Построенная модель на основе ее проверки по F-критерию Фишера в целом адекватна, и все коэффициенты регрессии значимы. Такая модель может быть использована для принятия решений к осуществлению прогнозов.
2. Модель по F-критерию Фишера адекватна, но часть коэффициентов регрессии незначима. В этом случае модель пригодна для принятия некоторых решений, но не для производства прогнозов.
3. Модель по F-критерию Фишера адекватна, но все коэффициенты регрессии незначимы. Поэтому модель полностью считается неадекватной. на ее основе не принимаются решения и не осуществляются прогнозы.
ВЫВОДЫ
Регрессионный анализ — метод моделирования измеряемых данных и исследования их свойств .Он используется для прогноза, анализа временных рядов, тестирования гипотез и выявления скрытых взаимосвязей в данных. На любой экономический показатель практически всегда оказывает влияние не один, а несколько факторов. Например, спрос на некоторое благо определяется не только ценой данного блага, но и ценами на замещающие и дополняющие блага, доходом потребителей и многими другими факторами.
Изучение связи между тремя и более связанными между собой признаками носит название множественной (многофакторной) регрессии. Построение моделей множественной регрессии включает несколько этапов:
• выбор формы связи (уравнения регрессии):
• отбор факторных признаков:
• обеспечение достаточного объема совокупности для получения
несмещенных оценок.
Выбор типа уравнения осложнен тем, что для любой формы зависимости выбирается целый ряд уравнений, которые в определенной степени будут описывать эти связи.
Основное значение имеют линейные модели в силу простоты и логичности их экономической интерпретации. Наиболее сложным этапом, завершающим регрессионный анализ, является интерпретация уравнения, т. е. перевод его с языка статистики и математики на язык экономиста. Интерпретация моделей регрессии осуществляется методами той отрасли знаний, к которой относятся исследуемые явления.
При адекватности уравнения регрессии исследуемому процессу возможны следующие варианты:
1. Построенная модель на основе ее проверки по F-критерию Фишера;
2. Модель по F-критерию Фишера ;
3. Модель по F-критерию Фишера адекватна, но все коэффициенты регрессии незначимы. Поэтому модель полностью считается неадекватной. на ее основе не принимаются решения и не осуществляются прогнозы.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
1 Вводный курс эконометрики: Бородич С. А. ,Учебное пособие − Мн.: БГУ,
2000. − 354 с.
2 Анализ данных с помощью Microsoft Excel. : Берк, Кеннет, Кэйри, Патрик. Пер. с англ. — М. : Издательский дом "Вильяме", 2005. — 560 с. : ил. — Парал. тит. англ.
3 Норман Дрейпер, Гарри Смит Прикладной регрессионный анализ. Множественная регрессия = Applied Regression Analysis. — 3-е изд. — М.: «Диалектика», 2007. — С. 912.
4 Радченко Станислав Григорьевич, Устойчивые методы оценивания статистических моделей: Монография. — К.: ПП «Санспарель», 2005. — С. 504.
5 Дрейпер Н., Смит Г. Прикладной регрессионный анализ. Издательский дом «Вильямс». 2007. 912 с.
6 Стрижов В. В. Методы индуктивного порождения регрессионных моделей. М.: ВЦ РАН. 2008. 55 с.
7 Лукашин Ю.П. Адаптивные методы краткосрочного прогнозирования временных рядов; Учеб. пособие. — М.: Финансы и статистика, 2003. -416 с:
8 http://www.basegroup.ru/glossary/definitions/linear_regression/
ПРИЛОЖЕНИЕ А

ПРИЛОЖЕНИЕ Б

|
