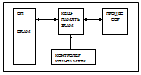
1. Классификация компьютеров и вычислительных систем
ЭВМ – это комплекс технических и программных средств, объединенных общим управлением и предназначенных для преобразования инф. по любому из заданных алгоритмов.
ЭВМ – это электронная система для сбора, преобразования, хранения и выдачи инф.
ЭВМ классифицируются по следующим признакам:
по виду обрабатываемой инф.
по способу представления инф.
по назначению
по способу передачи кодов
по производительности
по способу представления инф.
аналоговые (АВМ)
цифровые (ЦВМ)
В АВМ инф. представляется с помощью непрерывных (аналоговых) сигналов, В ЦВМ – с помощью дискретных сигналов.
АВМ содержит операционных усилителей и компонентов с помощью которых можно было бы моделировать различные мат. функции и операции.
Решение мат. уравнений на АВМ сводилось к набору на наборном поле машины эл. схемы, соотв. данному решаемому уравнению, а решение получалось на экране осциллографа как ф-ция, аргументом к-рой явл. время.
В современной ЭВМ для представления инф. используются двоичные числа. Для представления их исп. 0 и 1, кот в ЭВМ отображаются с помощью двух зон напряжений.
По назначению.
ЭВМ общего назначения
специализированные ЭВМ
Общего назначения имеют широкий набор команд, позволяющий на данной ЭВМ реализовать любой алгоритм.
Спец. ЭВМ имеют огр. набор команд и предназначены для реализации узкого круга алгоритмов, бывают счетные, информационные, управляющие.
По способу передачи и обработки кодов.
параллельные
последовательные
В парал. коды обрабатываются и передаются одновременно во всех разрядах. В посл. побитно и раздельно во времени. Все совр. ЭВМ относятся к ЭВМ параллельного действия. Их достоинством явл. высокое быстродействие, недостатком – большие аппаратные затраты.
По быстродействию.
Малой, средней, высокой, сверхвысокой, супер-ЭВМ.
На базе ЭВМ и процессоров создаются многопроцессорные и многомашинные вычисл. системы (комплексы).
Многомашинный выч. комплекс – это совокупность ЭВМ, объединенных линиями связи и управления с помощью коммутаторов. Основное назначение – повышение надежности выч. систем. Такие комплексы предполагают использование ЭВМ в качестве резервной. Многопроцессорный комплекс – это совокупность процессоров, связанных между собой через общую ОП и функционирующих под единой ОС. Основное назначение – повышение производительности.
Реклама

2.Параметры компьютеров
К основным параметрам ЭВМ относятся:
производительность
разрядность машинного слова
ёмкость оперативной памяти
скорость обмена инф. между ЦП и ОП
скорость обмена инф. между ЦП и ОП и внешними устройствами
надежность
потребляемая мощность
Производительность.
Определяется средним количеством операций, выполняемых за единицу времени при решении широкого класса задач. Измеряется в опер/с - MIPS ( Millen Instructions Per Second). Производительность конкретной ЭВМ определяется используемой в ней элементной базой и архитектурой.
Разрядность машинного слова.
Определяется количеством разрядов, используемых в данной ЭВМ для представления данных и машинных кодов. Определяет максимальное число, которое можно представить в ЭВМ – диапазон представимых чисел в ЭВМ, точность представимых чисел, и обьем адресуемой памяти.
Ёмкость оперативной памяти.
Определяется количеством адресуемых ячеек памяти наименьшей длины – байта.
Скорость обмена инф. между ЦП и ОП и внешними устройствами.
Определяется количеством инф., передаваемой в единицу времени между устройствами. Измеряется в Мбайт/с.
Надёжность.
Характеризуется тремя параметрами:
интенсивность отказов
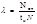
Nот – количество отказов в партии из N изделий за время испытаний tи.
наработка на отказ
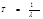
вероятность безотказной работы за время t.
3. Структура ЭВМ. Основные устройства и их назначение
ЭВМ строится по модульному принципу. модули ЭВМ предст собой функц-но законченные устр-ва с типовым напряжением. Устр-ва, сходящие в состав ЭВМ, делятся на центральные (ОП, проц-р) и внешние(перефер – устр-ва в/в и внешн запомин устр-ва).
Схема ЭВМ:
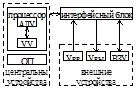
Проц-р предназн для выполнения арифм и логич операций управления вычисл процессом и организации взаимодействия между устр-ми ЭВМ. Проц-р сост из 2-х основных устройств:
– АЛУ Предназн для выполн-я арифм операций над числами, представл-ми в форме с фиксиров, плавающ точкой и в десятичном формате. Предназн для выполн-я арифм операции (+,–,*,/), а также для логич операций над многоразрядными двоичными кодами и формир-я признаков рез-та операции. АЛУ строится на сумматорах, регистрах и др.
– УУ Предназн для управл-я вычисл-ым процессом. УУ дешифрирует коды команд, вырабатывает управляющие сигналы в соответствии с этими кодами для АЛУ и др устройств ЭВМ. В процессе работы на УУ поступают признаки рез-ов и сигналы запросов прерыв-ий, с учетом к-ых, если необходимо, УУ корректирует вычислительный процесс, вызывает программы прерываний и выполняет некоторые др действия.
Реклама

ОП предназн для временного хранения программ, данных, обрабатываемых в программе, исходных, промежут и конечных рез-ов вычислений.
Внешние устр-ва предназн для организации взаимодействия пользователя с центр-ми устр-ми (ЦУ). Делятся на:
– устр-ва ввода (Увв)
– устр-ва вывода (Увы)
– внешние запоминающие устр-ва (ВЗУ)
Увв предназн для ввода информации в ЭВМ. Преобразует инф-ю, представленную на внешних носителях, в электрич сигналы, используемые для представления инф-ции в ЦУ ЭВМ.
Увы выполн функуию, обратную Увв, т.е. преобразует электр сигналы, с помощью к-ых инф-я представлена в ЭВМ, в форму, удобную для восприятия человеком, либо в форму, используемую для представления инф-ции на внешних носителях.
ВЗУ использ для хранения больших массивов инф-ции, к-ые не помещаются в ОП ЭВМ.
Интерфейсный блок предст собой совокупность аппаратных и программных средств, предназн-ых для сопряжения внешних устройств с ЦУ ЭВМ.
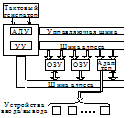
Шина – совокупность линий, по каждой из которых в любой заданный момент времени передается 1 бит инф-ции. Различают
– управляющая шина (ШУ)
– шина адреса (ША)
– шина данных (ШД)
ША однонаправлена. Используется для передачи от проц-ра кодов адресов ячеек ОП, внешних устройств, ячеек ПЗУ.
ШД двунаправлена. Использ для передачи кодов данных между ЦУ и внешними устр-ми ЭВМ.
ШУ двунаправлена. Использ для передачи сигналов синхронизации от проц-ра к ОП и наоборот, от проц-ра к внешн устр-ам и наоборот.
Сигнала синхронизации привязаны к границам тактов, к-ые задаются с помощью тактового генератора.
Разрядность шин опред-ся разрядностью машинного слова, используемой в данной ЭВМ. в соврем ЭВМ исп 32-битовая ША (4 Мб), 64-битовая ШД.
4. Прямой, обратный, дополнительный код
Набор цифр для двоичной системы счисления:
{0,1}, основание р=2
Эквивалент некоторого целого n-значного двоичного числа вычисляется согласно формуле:
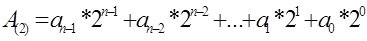
Прямой код, обратный, дополнительныйиспользуються для представления целых и вещественых чисел(двоичная запись).
В прямом коде цифровые биты для отрицательных и положительных чисел выглядят одинаково.
Недостатки прямого кода: неудобство выполнения операций в АЛУ – действия над цифровыми и знаковыми битами нада выполнять раздельно. Исп ользуется в АЛУ при умножении и делении.
Недостаток: +0<>-0.
Достоинства: возможность свести операцию вычитания к операции сложения.
Обратный код (все биты инвертированы).
Недостатки: +0=0..0, -0=1..1.
Достоинство: можно свести операцию вычитания к операции сложения.
Дополнительный код(обратный +1).
Достоинство: +0=-0=0..0.
5. Форматы чисел с фиксированной точкой
Используются для представления целых и дробных чисел. положение двоичной точки в этих форматах никак специально не фиксируется, но строго предполагается, что двоичная точка для целых чисел располагается за младшим цифровым битом, для дробных – перед старшим цифровым битом.
Форматы целых и дробных чисел имеют след представление:
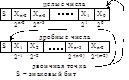
Формат числа определяет разрядную сетку ЭВМ, т.е. диапазон чисел, к-ые могут обрабатываться в данной ЭВМ, а также точность представления чисел.
Числа с фиксиров точкой в памяти ЭВМ представляются в дополн коде. Разрядность формата определяет диапазон чисел с фиксированной точкой, представимой в данной ЭВМ. Если для представления числа используется n разрядов, то диапазон чисел с фиксированной точкой определяется: –2n–1<=x<=2n–1–1
В ЭВМ для представления чисел с фиксированной точкой используется также беззнаковый формат, т.е. знаковый бит используется в качестве цифрового. В таком формате: 0<=|x|<=2n–1-1
В ЭВМ на основе 32-битовых МП-ов используются следующие форматы с фиксированной точкой
Однобайтовый формат
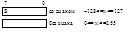
Формат слова

Формат двойного слова
АЛУ современных ЭВМ благодаря использованию 64-битового устройства для операций с плавающей точкой поддерживают также 64-битовый формат чисел с фиксированной точкой. (рис)
6. Форматы чисел с плавающей точкой
Используется для расширения диапазона чисел, представимых в ЭВМ и для увеличения точности их представления. Основан на форме записи дв. чисел: ±Мх 2±Рх.
Где Мх – мантисса, Рх – порядок. В ЭВМ исп. формализованная форма представления чисел с плавающей точкой. 1>Мх>=1/2. Мантисса всегда дробное число, причем первая цифра всегда 1.Порядок представляется в виде целого числа. Знак числа отображается в старшем бите. Для представления порядка и его знака отводится поле из m бит, в кот. размещается код смещенного порядка: Рсм=Рх + 2m-1-1.
Для отображения смещенного порядка исп. коды 000…000 (m) до 111...10 (m). Код с единицами во всех битах зарезервирован для случая возникновения выч. ситуаций переполнения порядка и потери значимости мантиссы (стала равной 0). Мантисса отображается в формате с плавающей точкой в прямом коде. Структура формата такая (32 бита): 31 – S – знак, 23 – 31 – смещенный порядок(m=8), 0 – 23 – мантисса.
Наряду с двоичным словом исп. учетверенное слово (64 бита) и его 80 – битовый формат, тогда под порядок отводится 11 бит и 15 бит соответственно. Длина полей, отводимых для порядка и мантиссы в формате с плавающей точкой, определяет диапазон допустимых чисел. Допустимый диапазон порядка: -(2m-1-1)¸0; 1¸2m-1-1.
7. Форматы для представления десятичных чисел, алфавитно-цифровой информации и логических значений
Наиболее широко используется при обработке статистической и экономической информации. Для представления десятичных чисел в ЭВМ используются поля переменной длины, в отличие от форматов чисел с фиксированной и плавающей запятой. Это связано с тем, что при использовании полей фиксированной длины в случае обработки десятичных чисел увеличивается расход памяти и снижается быстродействие.
Для представления десятичных чисел используется двоично-кодируемый десятичный код в котором каждая десятичная цифра представляется в виде тетрады. Тетрады (1010¸1111) используются для представления знаков чисел и специальных символов применяемых в этих формах.
Варианты представления десятичных чисел:
Распакованный
Для представления одной цифры используется один байт. Тетрада, отображающая цифру, размещается в младшем полубайте этого байта. Старший полубайт может содержать любую информацию. Знак числа в дес. форматах также как и цифры задается 4-х битовым кодом, который размещается в мл. полубайте мл. байта. В старшем полубайте мл. байта размещается цифра мл. разряда дес. числа.
Упакованный формат
Цифры располагаются по две в одном байте.
Для представления десятичных чисел в таком формате всегда отводиться четное количество полубайт. Если при этом старший полубайт этого байта оказывается лишним, он заполняется нулями.
В IBM PC упакованные десятичные форматы используются для представления операндов в десятичных АЛУ. В этом случае используется 80-битовый формат, который позволяет представить любые десятичные числа длиной от 1 до 19 разрядов.
Для представления в ЭВМ символьной информации (буквы, спецсимволы) используется код ASCII. В этом коде каждому символу ставиться в соответствие 8-битовое двоичное число. Таким образом, 1 байт является внутренним представлением символа в ЭВМ. При кодировании используется весовой принцип, в соответствии, с которым значение двоичного кода символа увеличивается в алфавитном порядке.
Алфавитно-цифровая информация представляется в виде полей переменной длины. Для символьной информации поле представляет собой последовательность байт, располагающихся в памяти по соседним адресам, наз. строкой.
В ЭВМ 3-го поколения длина поля 1¸256 байт. В современных ЭВМ для 32 битовых МП поля могут содержать последовательность бит, байт слов, двойных слов и учетверенных слов. Такие последовательности называются цепочками.
Длина цепочек байт, слов, двойных и учетверенных слов 1¸4 Гбайт.
8. Параметры и классификация ЗУ
Под памятью ЭВМ понимают совокупность устройств, предназначенных для хранения, приема и выдачи двоичной информации. Отдельное устройство из этой совокупности называют ЗУ.
Операции, выполняемые в ЗУ – занесение инф. (запись), выборка инф. (считывание). Операции записи и считывания – операции обращения к памяти.
Основные параметры ЗУ:
-ёмкость,
-удельная ёмкость,
-быстродействие,
Ёмкость – это максимальное количество инф., которую может хранить ЗУ.
Удельная ёмкость – это отношение ёмкости к физическому объему ЗУ.
Быстродействие – определяется временем обращения к памяти. Различают время обращения при записи и время обращения при считывании.
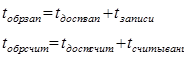
tдоступа определяется как интервал времени между началом обращения к памяти и моментом, когда требуемая инф. становится доступной.
tзаписи, tсчитывания – время, требуемое для записи и считывания инф.
Структура памяти ЭВМ:
Производительность и вычислительные возможности ЭВМ во многом определяются составом и параметрами ЗУ, образующими память ЗУ.
По способу доступа ЗУ делятся:
ЗУ прямого доступа – время доступа не зависит от местоположения инф. в памяти ЭВМ.
ЗУ циклического доступа – доступ к инф. становится возможным через периодически повт. интервалы времени.
ЗУ последовательного доступа – для доступа к любому элементу инф. предварительно осущ. просмотр предшевств. ему элементов инф.
В зависимости от способа хранения и поиска инф. в памяти ЭВМ различают адресные, ассоциативные и стековые ЗУ.
Адресные ЗУ – поиск требуемой инф. осущ. по адресу ячейки, хранящей инф. Для этого каждый байт имеет свой адрес.
Ассоциативные ЗУ – поиск инф. осущ. не по адресу, а по содержимому ячейки памяти (ассоциативный признак).
Стековые ЗУ – также имеют безадресную организацию. Доступ к инф. в них осущ. через опр. ячейку памяти, назыв. вершиной стека.
9. Адресная память
Адресные ЗУ – поиск требуемой инф. осущ. по адресу ячейки, хранящей инф. Для этого каждый байт имеет свой адрес.
Стр – ра адресного ЗУ имеет вид:
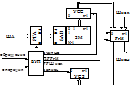
В состав ЗУ входят:
ЗМ – запоминающий массив, состоящий из N n – разрядных ячеек памяти.
БАВ – блок адресной выборки, реализуется на дешифраторах и предназначен для формирования сигнала выборки, активирующего одну из ячеек ЗМ.
РГА – регистр адреса, предназначенный для хранения k – разрядного адреса, пост. по шине адреса ША.
УСС – усилитель считывания.
УСЗ – усилитель записи.
РГИ – предназначен для временного хранения инф., зап. в ЗУ или счит из ЗУ.
Шивх – шина инф. входная.
Шивых – шина инф. выходная.
БУП – блок управления памяти, вырабатывает сигналы, упр. записью и считыв. инф. из ЗУ.
Работа адресного ЗУ.
Процессор, выполняя очередную команду, извлекает из нее адрес операнда и выставляет на шину адреса. В ЗУ возможны две операции – запись и считывание.
Перед каждой из этих операций процессор вырабатывает сигнал обращения по которому БУП выр. сигнал прием регистра адреса – ПрРГА, по кот. адрес, выст. проц. на ША записывается в РГА.
Адрес из РГА поступает в БАВ, который вырабатывает сигнал выборки ячейки памяти из ЗМ. Эта ячейка переходит в состояние, когда к ней возможен доступ.
После того, как ячейка выбрана, проц. вырабатывает сигнал операции, которая может быть либо запись, либо считывание. Если это считывание БУП выр. сигнал считывания, кот. пост. на УСС, открывает усилители и обеспечивает передачу инф. из выбранной ячейки памяти на вход РГИ. После чего с некоторой задержкой БУП выр. сигнал прием РГИ – ПрРГИ. По сигналу РГИ счит. из ЗМ инф. записывается в РГИ и появляется на шине выхода. При операции запись БУП выр. сигнал прием вх. инф. шины, по которому данные, нах, на ШИ вх заносятся в РГИ и поступает на вход усилителя записи, после чего инф заносится в выбранную ячейку памяти.
10.Организация адресного пространства ЭВМ. Выравнивание данных в памяти
Наиболее широкое распространение в ЭВМ получили адресные ЗУ. Адресные ЗУ – поиск требуемой инф. осущ. по адресу ячейки, хранящей инф. Для этого каждый байт имеет свой адрес.
С точки зрения процессора массив таких ЗУ состоит из элементарных ячеек длиной в один байт, каждая из которых имеет свой номер (адрес).
Совокупность таких ячеек образует адресное пространство , максимальный адрес определяется разрядностью шины адреса. При адресации в адресном рпостранстве ячеек памяти, имеющих длину более одного байта мкпроцессор Intel в качестве адреса ячейки исп. миним. адрес байта, входящего в состав ячейки.
При размещении числовых значений в ячейках адресного пространства мл. разряды числа размещаются в байте с минимальным адресом.
Выравнивание данных в памяти.
Адрес можно представить А = А31А30…А1А0, Аi = {0,1}.
Если ячейка памяти имеет длину более одного байта, то возникают вопросы, связанные с размещением ячеек памяти в ЭВМ.
Б3 Б2 Б1 Б0
При адресации такой ячейки памяти в качестве адреса можно выбрать старшие биты адреса А2-А31, а младшие биты адреса А1-А0 исп. для адресации байта внутри ячейки памяти, тогда адресом будет А=А31А30….А3А200.
Тогда адреса остальных байт в пределах ячейки будут:
Б0=А1А0=00; Б1=А1А0=01; Б2=А1А0=10; Б3=А1А0=11.
В принципе, размещение инф. в памяти может быть произвольным и в случае ячеек памяти длиной более одного байта возможны ситуации, когда для считывания дв. слова из памяти потребуется обращение по двум адресам А’ и А’+1, т.е. потребуется два цикла обращения к памяти. Поэтому при программировании рекомендуется выравнивать данные в памяти.
Для выравнивания данных в памяти ЭВМ в случае, если эти данные явл. словами, адреса должны быть четными двойными словами – кратными 4.
В общем случае, если данные в ячейке занимают 2k байт, адреса, по которым размещаются такие данные должны быть кратными 2k.
Практически это означает, что адрес такой ячейки памяти должен содержать k нулей в мл. битах А = А31А30…Аk-100000…, Аi = {0,1}.
11. Ассоциативная память
Являются безадресными. Поиск инф. в запоминающем массиве таких ЗУ осущ. не по адресу, а по содержанию – ассоциативному признаку. Исп. код ассоц. признака.
Для того, чтобы при поиске инф. в ассоц. ЗУ анализировать не все биты хранящихся в таких ячейках слов, а лишь выбранные биты слова исп. код маски.В этом бите 1 указаны в тех битах, где инф. будет исп. при ассоц. поиске и 0 в тех битах, кот. не исп. Структура ассоц. ЗУ:
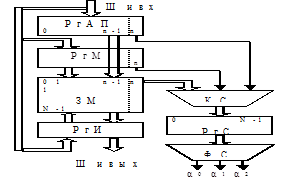
РгАП – регистр ассоц. признака, исп. для его врем. хранения.
РгМ – регистр маски.
ЗМ – запоминающий массив.
РгИ – исп. для времен. хранения инф. в качестве буфера при записи и считыв. из ЗУ.
КС – комбинационная схема, обесп. сравнение ячеек ЗМ, РгАП, РгМ.
РгС – регистр совпадений. Разрядность этого регистра равна кол-ву ячеек памяти ЗМ. Номер любого бита РгС совпадает с номером ячейки памяти ЗМ.
РС – схема формирования р-та ассоц. признака. Он формируется в виде кода ai ={0,1}, a0 a1 a2. Если код равен 100, то в ЗУ отсутствуют ячейки памяти, удовлетв. ассоц. признаку. Если 010-есть только одна ячейка, 001 – более одной ячейки.
Есть доп. разряд , кот. исп. для указания занятости ячейки. 0 -не занята, 1 – занята.
При считывании инф. в РгАМ и РгМ предварительно заносятся коды АП и маски.
Содержимое РгАП и РгМ совместно с содержимым ячеек ЗМ поступает на входы КС, где формируется N – разрядный код, записываемый в РгС. 1 в этом коде стоятв тех битах, номера к-рых совпадают с номерами ячеек ЗМ, для к-рых имело место совпадение по АП.
ФС использует код, поступающий из РгС, формирует рез-т ассоц. поиска a0 a1 a2. Если оказывается, что a0=1, то считывание отменяется. Если a1=1, то содержимое ячейки памяти переносится в РгИ и выставляется на шину инф. выходную.
При записи инф. предварительно осущ. поиск свободных ячеек памяти, для этого в РгАП загружается код 111…1110 – бит занятости. В РгМ загружается 000…0001. Осущ. ассоц. поиска в р-те которого определяется наличие ячеек ЗМ. если a1=1, то инф. , предварит. занесенная в РгИ с Шивх, переносится в свободную ячейку памяти и ее служебный бит уст. в 1. Если есть несколько свободных ячеек, то инф. заносится в свободную ячейку с наименьшим номером. Особенностью ассоц. ЗУ явл. возможность совместить поиск инф. и ее обработку.
12. Стековая память
Стековые ЗУ являются безадресными. ЗМ этих ЗУ состоит из ячеек памяти, связанных между собой разрядными линиями. Это позволяет сдвигать информацию из одной ячейки памяти в другую. Доступ к информации в стековых ЗУ осуществляется через ячейку ЗМ, называемую вершиной стека.
При записи информации, поступающей по Шивх, она заносится в вершину стека. При этом информация, записанная ранее, сдвигается вглубь стека.
При считывании информации информация поступает на Шивых из вершины стека. В том случае, если считывание информации происходит без разрушения, информация, занесенная в вершину стека, теряется, а содержимое соседних ячеек памяти перемещается в ячейки с меньшими номерами.
Стековые ЗУ снабжаются счетчиком стека СчСт, в к-ом хранится код, указывающий заполнение стека. Если стек не заполнен – 0, если заполнен – N-1.
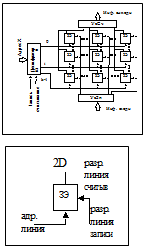
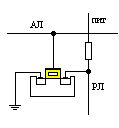
13. Динамические ЗУ со структурой 2D
ЗМ строятся из запоминающих элементов, способных хранить один бит информации. Каждый такой элемент имеет входы, сигналы на которых обеспечивают выборку элемента при обращении к памяти. Эти входы подключаются к адресным линиям. Каждый ЗЭ имеет входы, через которые осуществляется запись информации и выходы, через которые информация считывается. Эти выходы и входы подключаются к так называемым разрядным линиям. Совокупность адресных и разрядных линий называется линиями выборки. В зависимости от количества адресных и разрядных линий ЗМ памяти может иметь двухмерную, трехмерную или промежуточную структуру. Если ЗМ организован в виде двухмерной структуры, то она называется 2D, 3D, 2,5D соответственно.
Наиболее широко в ЗУ используется 2D и 3D. В современных ЭВМ в качестве элементов ЗМ используется схемы на полупроводниковых транзисторах.
В ЗМ со структурой 2D представляет собой плоскую матрицу, строки которой образуются разрядными, а столбцы адресными линиями (см.рис.).
В соответствии с кодом адреса, поступившим на дешифратор, формируется сигнал выборки ячейки в ЗМ.
Считывание информации осуществляется по разрядным линиям через усилители считывания УсСч, запись – по разрядным линиям через УсЗ. Управление записью и считыванием осуществляется с помощью сигналов запись и считывание.
В современных ЭВМ используются ЗЭ, которые допускают объединение входных и выходных разрядных линий. Такие структуры называются структурными 2D-M.
14. Запоминающий элемент динамических ЗУ (схема, работа)
В качестве ЗЭ используются схемы на МОП транзисторах, хранение информации, в которых осуществляется за счет заряда конденсатора. Если конденсатор заряжен в ЗЭ записана единица, и наоборот.
Для работы таких ЗУ требуется периодическая подзарядки конденсаторов, иначе информация будет потеряна. По этой причине ЗУ такого типа называются динамическими, а память DRAM. Процесс восстановления информации в DRAM осуществляется путем разряда конденсатора, при этом содержимое строки ЗМ записывается в буфер, реализованных на статических триггерах, из которого считанная информация передается на выходную информационную шину. После считывания содержимое буфера вновь переписывается в строку ЗМ, из которой оно было выбрано.
Схема запоминающего элемента в DRAM показана на рис. :
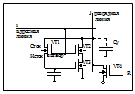
Для хранения информации в данном ЗЭ используется входная емкость L МОП транзистора VT3. Если эта емкость заряжена в этом ЗЭ логическая единица и наоборот. Паразитная емкость разряженной линии ij Су используется в качестве временного источника питания при считывании информации из ЗЭ.
Считывание информации из ЗЭ осуществляется следующим образом : на затвор VT4 подается сигнал R высокого уровня, который обеспечивает отпирание VT4и подзаряд Су.
Затем на адресную линию i поступает сигнал выборки с дешифраторов, величина которого при считывании такая, что обеспечивается отпирание VT2, но не может открыть VT1. Если в ЗЭ конденсатор С заряжен (хранится 1), то транзистор VT3 открыт и Су разряжается через открытые VT2 и VT3, фиксируя на разрядной линии j низкий уровень напряжения (логического 0). Если С разряжен (в ячейке 0), то VT3 закрыт и разряд Су не происходит, что обеспечивает на j высокий уровень напряжения (свидетельствует о том, что в ЗЭ хранится ), т.е. считывание информации из ЗЭ осуществляется в инверсном виде. Состояние разрядной линии j при считывании записывается в соответствующий разряд буферного ЗУ, реализованного на статических триггерах, откуда затем передается устройству, запросившему информацию в ЗУ. После считывания информации требуется восстановление и в динамическом ЗЭ, для этого информация перезаписывается из статического буфера в ячейку DRAM, из которой она была выбрана.
При записи на информации на адресную линию i подается сигнал, уровень которого достаточен для отпирания VT1. VT1 открывается и подключается. Конденсатор С к разрядной линии j, что обеспечивает заряд конденсатора С до уровня напряжения, действующего на этой линии (если на j единица – С получает заряд и наоборот).
Т.к. в рассмотренных ЗУ требуется подзарядка конденсаторов, следующее считывание информации , после данного возможно только через определенный промежуток времени, необходимый для перезарядки конденсатора. Этот промежуток времени занимает 80%-90% от времени обращения к таким ЗУ. Поэтому DRAM обладает меньшим быстродействием чем SRAM. В современны компьютерах время обращения к DRAM – 60-100нc.
В адресных ЗУ со структурой 2D используется мультиплексирование адреса. Для этого код адреса разбивается на 2 части.
код строк
код столбцов
В начале в ЗУ передаются старшие биты адреса (адрес строки), которые сопровождаются сигналом RAS. После чего передаются младшие биты адреса, которые сопровождаются сигналом CAS. Использование мультиплексирования позволяет уменьшить количество выводов БИС памяти. Кроме того удобно для страничной организации памяти. Для увеличения быстродействия DRAM в современных компьютерах используются методы чередования адресов, страничной выборки и пакетной выборки.
Метод чередования адресов заключается в том, что адресное пространство разбивается на отдельные части ( банки ). Обращение к банкам осуществляется поочередно. При считывании информации из данного банка одновременно осуществляется регенерация информации в других банках. Это снижает влияние процесса перезарядки на быстродействие DRAM.
Метод страничного доступа заключается в том, что если информация считывается с одной и той же страницы, т.е. старшие биты адреса для всех единиц считываемой информации одинаковы при обращении к памяти сигнал RAS не используется, а передаются лишь младшие биты, сопровождаемые сигналом CAS.
Метод пакетного доступа заключен в том, что при каждом обращении к памяти считывается не одна единица информации, а несколько, расположенных рядом.
15. Статические ЗУ со структурой 3D (организация запоминающего массива,
функционирование)
В этом ЗУ для ЗЭ используется не 1 адресная линия, а 2, сигналы по которой связаны между собой конъюнктивно. Значит, такой ЗЭ будет выбран в ЗМ, если на обоих входах выборки будет лог.1.
Данная память имеет 3х мерную структуру. В этом ЗУ для каждого разряда двойного слова представляют собой плоскую матрицу в строках и столбцах которой стоят элементы.
ЗУ такого типа получили назв. ЗУ с двухадресной выборкой. В них адрес разбивается на две части. Ст. биты адреса образуют компоненту АХ, обеспечив. выборку строки в ЗМ, мл. биты обр. ком. АУ, обесп. выборку столбца в ЗМ.
Структура запоминающего массива для j-го бита слова (одна матрица) ЗУ выглядит следующим образом:
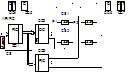
При чтении и записи информации в матрице выборка элемента осуществляется с помощью 2х компонент адреса: Ах и Ау (младший и старший биты адреса). Выбранным оказывается ЗЭ для которого i’=i’’=1. При поступлении сигнала считывания СЧ информация из выбранного ЗЭ через усилитель считывания УССЧ передается на j линию схемы данных. При записи информация по сигналу ЗП с jй линии входной шины через усилитель записи УСЗП заносится в выбранный ЗЭ.
Адрес, исп. для выборки, хранится в регистре адреса ДД1. С выхода этого регистра адрес разбивается на две компоненты, кот. пост. на дешиф. строки ДД2 и дешиф. столбца матрицы ДД3. Каждый ЗЭ связан двумя входами выборки CS1 и CS2 с дешиф. строки и столбца. Запись и считыване инф. в ЗЭ осущ. через их инф. выводы Р1 и Р2. Эти выводы связаны через усилительзаписиДД5 и усилитель считывания ДД6. В соответствии с адресом, хранящимся в ДД1, осущ. выборка одного ЗЭ в матрице. При записи или считывании открываются соотв. усилители и произв. запись или считывание. Такие схемы имеют сигнал стробирования.
16. Запоминающий элемент статических ЗУ (схема, работа)
Используется для реализации статической памяти. в качестве ЗЭ используется статические триггеры на биполярных или полевых транзисторах. Схемы на биполярных транзисторах имеют высокое энергопотребление и большую стоимость, однако обл. выс. быстродействием.. схемы на МОП тр-рах имеют более низкое быстродействие, обесп. более выс. степень интеграции и более низкое энерго потребление.
Схема на рисунке
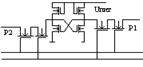
Работа схемы:
Соответствие лог 0 или 1 ЗЭ определяется тем, какой мз триггеров VT1 или VT2 открыт. Если открыт 1, то 0, если второй – 1. В триггерах эмиттеры 11, 21 – информационные, через них осущ запись и счит инф. Элементы 12, 13,22,23 – адресные, исп для выборки ЗЭ в ЗМ в соответствии с сигналами на адресных линиях i’ i’’ в состоянии хранения информации ток открытого транзистора замыкается через адресные эмиттеры на линиях выборки i’ i’’ в состоянии хранения с вых УСЗП0 и УСЗП1 на информационные эмиттеры 11 21 поступ напряжение 1-1.5 В, кот удержив эмиттерные переходы в закрытом состоянии. это необх для исключения ответвления тока транзистора через инф эмиттер.
При считыв инф на вх УСЗП0 и УСЗП1 подается сигнал лог 0, закрывающий выходные транзисторы усилителей записи, затем подается сигнал выборки i’ i’’ , что приводит к запиранию адресных эмиттеров и открыванию информационных. Ток открытого эмиттера начинает течь на вход соответствующего усилителя считывания, насыщая выход транз этого уселителя и обеспечивая на его вых лог 0
Запись информации :
На вход соотв усилителя подается лог 1 (если необх записать в ячейку 1, то подается на вход УСЗП1, если 0 – УСЗП0). Сигнал лог 1 открывает вых транзистор усилителя записи и замыкает соотв инф эмиттер на землю. Сигнал выборки i’=i’’=1 при записи также запираются эмиттерные переходы 12 13 22 23, а на инф эмиттере транзистора VT1 при записи лог 1 либо транзистора VT2 при записи лог 0, удержив-ся уровень напряжения 1-1.5 В. если в ячейке записи лог 1, т.е. на выходе УСЗП1 лог 0 при открытом транзисторе VT2 в ЗЭ – 1, ток через эмиттер и открытый выходной транзистор УСЗП1 замыкается на землю, и состояние ЗЭ не изменяется. В том случае ,если в ЗЭ лог 0 , открыт транзистор VT1 , появление на вых УСЗП1 сигнала выборки i’=i’’=1 приводит к отпиранию транзистора VT2 и запиранию VT1. Транзистор открывается , ток через инф эмиттер течет на землю и в ячейке лог 1.
17. Масочные и однократно программируемые ПЗУ
Программируются непосредственно в процессе производства. Для этого используется фотоэлектронная либо рентгеновская литография и специальные шаблоны, называемые масками.
Создаются масочные ПЗУ следующим образом:
На 1-ом этапе используются все шаблоны-маски, к-ые позволяют создать все связи между адресными и разрядными линиями ПЗУ. Это означает, что исходно формируются все элементы транзисторов (К, Б, Э), диодов (n-область, p-область), к-ые выполняют функцию ЗЭ, связывающих адресные и разрядные линии.
На следующем этапе создания масочного ПЗУ один из шаблонов заменяют шаблоном, к-ый позволяет убрать отдельные элементы у диодов либо транзисторов, состоящих в связях между адресными и разрядными линиями. ЗЭ масочных ПЗУ, реализованные на биполярных и униполярных транзисторах, показаны на рис.
 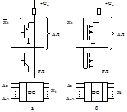
В случае, если ЗЭ ПЗУ реализованы на биполярных транзисторах (рис а), выборка слова из ЗМ осуществляется с помощью инверсного унитарного кода, снимаемого с выхода диода. Это означает, что будет выбрана та АЛ, к-ая подключена к выходу дешифратора, на к-ом 0. При этом если транзистор имеет эмиттер, он открывается и подключает разрядную линию (РЛ) к земле. На РЛ формируется U0. Если эмиттер у транзистора отсутствует, на РЛ сохраняется U1, поступающее от Uп, т.е. на РЛ U1.
Программирование ППЗУ осуществляется путем устранения специальных перемычек, выполненных из нихрома, поликремния или титаната вольфрама, к-ые в состав ЗЭ этих ПЗУ. ЗЭ обычно реализуется на биполярных или униполярных транзисторах. Схема ЗЭ ППЗУ показ на рис.
 Исходно в ППЗУ с такими ЗЭ записаны двоичные слова, содержащие единицы во всех разрядах. Для записи в какой- либо ЗЭ логического 0 необходимо устранить перемычку.
Программирование ППЗУ осуществляется с помощью специальных устройств – программаторов, в состав к-ых входит клавиатура, схема управления, буферные ЗУ и схемы формирования сигналов.
Программирование ППЗУ данного типа заключается в кратковременном (1мс) повышении напряжения питания транзисторов до 12 В и пропускании тока 20–30 мА через ЗЭ, для к-ых перемычки надо устранить.
18. Флэш память
Flash’ка: для запоминания и стирания используються два физэффекта.
для запоминания: надбарьерная электронная эммисия.
для стирания: туннельнный эффект (эффект Фаулера-Нордхейма)
Эммисия:
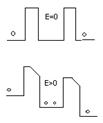
при Е>0 искривляется барьер и для эммисии электрону требуется меньшая энергия => больше электронов перепрыгивают барьер.
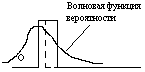
тунельный эффект достигается при толщине барьера 100-1000А
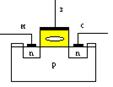
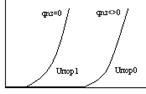
При Uпор=0 – образуется n-канал в проводнике р-типа. В транзисторе с плавающим затвором величина порогового напряжения при котором транзюк открывается зависит от наличия заряда на плавающем затворе. Запоминающий Элемент flash-памятиможет состоять из одного или двух транзисторов. ЗЭ – плоская матрица (типа DRAM).
Схема на одном транзюке:
Uвыборки = (Un1+Un0)/2
При записи U1 на АЛ – Uзап,а на РЛ - 1/2Uзап.
В транзисторе образуется n-канал электроны из которого за счет разности Uзс и за счет надбарьерной эмиссии «горячих» электронов переходят на затвор.
При записи U0 на АЛ – +Uзап,а на РЛ - 0.
Не образуется n-канал, эмиссии электронов нет.
Стирание: на АЛ - -Uc на Uпит - +Uc. Если в ПЗ имеються электроны, то они туннелируют в Uпит.
19. КЭШ – память, (общая характеристика )
Кеш-память (SRAM) используется для ускорения обмена информации между ОП ВМ, которая реализована на DRAM, и быстродействующим процессором.
Она позволяет снизить простои процессора, при обращении к ОП и , тем самым, повысить производительность ЭВМ.
Кеш-память реализована на основе статических триггеров SRAM, которая обладает высоким быстродействием и допускает многократное считывание без разрушения информации.
Система Кеш-памяти:
Контролер Кеш-памяти предназначен для управления ресурсами кэш-памяти и наиболее эффективного ее использования.
При обращении к памяти процессор выставляет на шину адреса адрес ОП, интересующей его информации. Контролер Кеш-памяти проверяет имеется ли такая информация в кэш-памяти, если имеется она немедленно передается процессору, если нет возвращает кэш-памяти отказ.
При отказе контролер по адресу находим информацию в ОП и передает ее в кэш. После чего команда повторяется.
В том случае, если при обращении к памяти требуемая инф-ция находится в кэш говорят о кэш попадании, если нет – о кэш промахе. Коэффициент попадания определяется как отношение числа попаданий к общему числу обращений.
Коэффициент зависит от объема и организации кэш-памяти, от алгоритма поиска инф-ции и особенности выполняемой программы.
При обращении к ОП контролер кэш обеспечивает передачу данных из ОП в кэш-память в виде блоков, которые могут иметь длину 2, 4, 8 и 16 бит. Эти блоки содержат не только ту информацию, которую процессор требует из памяти в данный момент времени, но и ин-цию, которая может потребоваться в дальнейшем. При считывание ин-ции из ОП в кэш. Это может осуществляться тремя путями.
С упреждением – в считываемом блоке содержится не только данный байт, но и байты с большими адресами, которые могут потребоваться в дальнейшем.
С отставанием ‑ в ОП считывается предшествующий ему байт.
С упреждением и с отставанием.
Длина блока передающегося из ОП в кэш влияет на эффективность кэш-памяти. При небольших размерах блока снижается коэффициент попадания. В современных ЭВМ используется длина слова 2 или 4. Растет разрядность шины.
КЭШ – память имеет строчную организацию. Одну и ту же строку Кэш могут занимать различные блоки данных. Для того, чтобы знать, какой блокданных занимает в данный момент времени строку Кэш, исп. спец. код – ТЭГ, который размещается в начале строки. В зависимости от того, каким обр. сравнительно большая ОП отображается в в ср. малой Кэш памяти различают три типа архитектуры Кэш: кэш с прямым отображением, полностью ассоциативные Кэш, наборно – ассоциативная Кэш.
20. Кэш-память с прямым отображением
Каждая строка такой кэш однозначно определяется адресом выставляемым процессором. На одну строку может претендовать два или более блоков. Контролер кэш такого типа выделяет в адресе три группы бит.
Старшая группа бит образует Тег , по которому выбирается линия в кэш затребованной информации. Младшая группа бит называется смещением. Определяет положение байта внутри строки. Промежуточная группа бит определяет номер строки кэш.
В соответствии с адресом, получаемым от процессора контролер кэш по смещению определяет нужную информацию. Процессор по номеру определяет строку кэш-памяти и сравнивает ее Тег со старшими битами адреса. Если имеет место совпадение данные, начиная с байта, номер которого определяется в строке смещением пересылается процессору. Если Тег не совпадает со старшими битами адреса происходит обращение контролера кэш к ОП, из которой ин-ция передается в процессор.
Достоинство – простота аппаратной реализации, фактически требуется только аппаратная часть дя сравнения Тега строки со старшими битами адреса.
Недостаток – большая вероятность конфликтов, которые приводят к тому, что если два или более блоков одинаково часто используемых процессором претендуют на одну и туже строку кэш. Это снижает оперативность обмена между процессором и памятью.
21. Полностью ассоциативная и наборно ассоциативная кэш-память
Ассоциат-я кэш-память. В этом случае информация поступившая из процессора или переносимая из ОП может расположится в любой строке кэш. Адрес рассматривается контролером кэш, состоящим из двух групп бит: младшие биты и смещение.
В соответствии с адресом выставленном процессором, контролер кэш осуществляет параллельный ассоциативный поиск во всех строках кэш. В качестве ассоциативного признака используются старшие биты адреса, которые сравниваются с тегами строк.
Если в кэш имеется строка, удовлетворяющая ассоциативному признаку, из той строки процессору предаются байты, начина яс номера, определяемого смещением.
Достоинством ассоциативной кэш является то, что инф-я может располагаться в любой строке. Недостатком является большие аппаратные затраты для параллельного поиска во всех строках кэш.
Наборно-ассоциативная кэш-память. В этом случае все строки кэш разделяются на группы (наборы). В представленных наборах осуществляется ассоциативный поиск. А инф-ция о ноборе задается в коде адреса
В этом случае контролер кэш по мере набора определяет группу строк, в которой осуществляется параллельный ассоциативный поиск, если требу-я ин-цмя имеется в наборе. В соответствии со смещением осуществляется пересылка ин-ции из строки в процессор.
В современных ЭВМ наиболее часто используется кэш-память с двумя и четырьмя наборами.
22. Обновление КЭШ – памяти
В системах с КЭШ – памятью нужно учитывать, что в ЭВМ хранится одновременно две копии инф. с одинаковыми адресами – одна в КЭШ, другая в ОП. При модификации данных они прежде всего заносятся в КЭШ. Может возникнуть ситуация, когда в КЭШ и ОП по одному и тому же адресу будут храниться различные данные. Для недопущения ситуации, когда в процессе исполнения программы могут быть использованы старые данные, что приведет к ошибке, сущ. спец. способы обновления КЭШ – памяти.
Системы со сквозной записью - в этом случае модифицированные данные заносятся в КЭШ и сразу же перезаписываются в ОП. Это исключает появление различных копий в ОП и КЭШ. Недостатком этого способа обновления явл. частое обр. к ОП, что снижает производительность системы.
Система со сквозной записью и буферизацией – в этом случае модиф. данные задерживаются в КЭШ (спец. буфере перед записью их в ОП). Это дает возможность проц. приступить к выполнению след. команды не дожидаясь, пока данные будут переписаны из КЭШ в ОП. В этом случае увеличение произв. обеспечивается, если при выполнении след. команды имеет место КЭШ – попадание. В рассматриваемом случае (как и в предыдущем) модифиц. данные, хранящ. в КЭШ могут быть исп. каким – либо устр-вом ЭВМ только после перезаписи их в ОП. Обычно КЭШ имеет только1 буфер.
Повторная запись – в этом случае в тэге КЭШ – памяти исп. дополнительный бит изменения. Этот бит устанавливается в 1, если в данную строку КЭШ занесены модиф. данные, кот. ещё не перезаписаны в ОП. При обращении к строке КЭШ контроллер кэш проверяет бит изменения, если в нем 1 перед занесением в эту строку новых данных контроллер перезаписывает их в ОП, после этого записывает новые, если бит изменения 0, в строку кэш сразу же записываются новые данные без перенесения строки в ОП.
23. Назначение процессора и классификация операций
Процессор – это центральное устройство ЭВМ, осуществляющее обработку данных и управление этим процессом. Проц. декодирует и выполняет команды программы, организует обращение к ОП, инициирует работу периферийных устройств, принимает и обрабатывает запросы прерываний, поступающих от устройств ЭВМ и из внешней среды. Действие проц., задаваемые одной командой программы наз. машинной операцией. Операции делятся: арифметико-логические, сдвига, пересылки, управления, ввода–вывода, арифметические, операции присвоения знака, прибавление переноса, вычет заема, сложение, вычитание, умножение, деление, логические. операции отрицания, дизъюнкции, конъюнкции, сложение по модулю 2 – М2., cдвига.
Операции арифметического сдвига, циклического сдвига, логического сдвига.
При выполнении этих опер. двоичный код сдвигается в разрядной сетке влево или вправо. Логический сдвиг – это такой сдвиг, когда освобождающиеся при сдвиге разряды заполняются нулями, а разряды кода, выходящие за пределы разрядной сетки теряются. При лог. сдвиге сдвигаются все разряды кода. Арифметический сдвиг - сдвигаются все цифровые биты числа по тем же правилам, без изменения положения знакового бита. В случае прямых кодов чисел и полож. чисел в любом коде освобождающиеся биты заполняются 0. Циклический сдвиг – в этом случае выходящие за пределы разрядной сетки разряды слова передаются в освобождающиеся разряды.
Пересылки.
Обеспечивает перемещение инф. между регистрами процессора, регистрами и ячейками ОП, между ячейками ОП. Делятся на пересылочные операции типа регистр – регистр, регистр – память, память – память.
Управления.
Управляют процессом выполнения программы и состоянием процессора ЭВМ.
К операциям, управляющим процессом отн.: операции безусловного и условного перехода, вызова подпрограмм, возврата из подпрограмм. Операции безусловного перехода позволяют изменить порядок выполнения программы, условного перехода – при выполнении некоторого условия. Операции вызова подпрограммы обеспечивают запоминание адреса возврата и передают управление по адресу, соотв. адресу первой команды подпрограммы. Операции возврата из подпрограммы обеспечивает передачу управления по адресу, который был заполнен при вызове подпрограммы.
Команды управления состоянием процессора позволяют фиксировать признаки результатов операций, устанавливают приоритеты процессов, переводить процессор в режим ожидания и режим обработки прерываний. Состояние процессора фиксируется в регистре флагов с помощью установки определенных бит этого регистра в 0 или 1. Команды упр. процессором позв. воздействовать на отдельные биты регистра флагов. Так, например, команды признака результатов позв. установку бита регистра флагов Z в 1, если результат операции 0.
24. Форматы команд процессора
ЭВМ осуществляет автоматическую обработку инф., используя программное управление. Программа – алг. решения задачи, предоставленный в виде последовательности машинных команд. Маш. ком-а – двоичный код, содержащий информацию о типе выполняемой операции и адресы операндов, участвующих в операции. Команда состоит из операционной и адресной части:
Операционная часть содержит код операции Коп, указывающий процессору, какая операция подлежит выполнению.
Адресная часть содержит инф. о адресах операндов.
В общем случае обе части могут состоять из ряда полей, которые имеют определённое функциональное назначение. Форматом команды называется её структура, представленная с нумерацией бит, границ полей с указанием их функционального назначения. В общем случае , адресная часть формата команды должна содержать поля, дающую информацию об адресе операндов, адресе по которому размещается результат и адрес следующей команды, подлежащей выполнению. Такой формат называется четырёх адресным и имеет вид:
А1, А2 – адреса операндов (для однооперандных команд имеется одно поле А1)
А3 – адрес, по которому размещается результат выполняемой операции.
А4 – адрес следующей команды, подлежащей выполнению.
Данный формат является избыточным и не используется в ЭВМ т.к. команды ( исп. команды переходов) выполняются в естественном порядке следования их в программе. Это позволяет процессору автоматически вычислять адрес следующей команды, прибавляя к текущему адресу А, выполняемой команды, ее длину L байт.
Поэтому в форматах команд поле А4 не указывается Это приводит к трёхадресной команде, имеющей формат:
Трёхадресные команды также не нашли применение в соврем. ЭВМ. Используются команды, подразумевающие по умолчанию размещение результата операции по адресу одного из операндов, либо результат размещается в специально отведённом для этого регистре процессора, называемом аккумулятором:
Операнды размещаются по адресам А1, А2 , а результат выполнения операции заносится по адресу первого операнда А1 при этом значение операнда теряется. Использование аккумулятора позволяет по умолчанию размещать один из операндов в нём и не указывать адрес этого операнда в команде. В этом случае команда одноадресная и имеет формат
Существуют команды, которые не содержат адресной части (безадресные команды), например команды управления
Адресная часть команд, представленная в приведённых выше форматах , имеет схематический характер в том смысле, что в этой части команды могут представляться не непосредственно адреса операндов, а некоторый код, позволяющий определить адрес. Конкретный бит адресной части формата команды определяется спосовом адресации. В современных ЭВМ используется несколько способов адресации.
25. Подразумеваемая, непосредственная, прямая, регистровая и косвенная адресация
Способ адресации – способ, представляющий порядок задания адреса операнда в адресной части команды. При рассмотрении способов адресации будем различать
Адресный код (Ак) – код указываемый в адресной части команды, который содержит информацию об адресе операнда.
Исполнительны адрес (Аи) – адрес ячейки ОП или регистра.
В общем случае Ак ¹ Аи.
1) Подразумеваемая адресация – в этом случае адрес операнда никак не указывается, но он подразумевается. Пример, могут указываться адреса двух операндов и предполагается, что результат находится в одном из этих операндов. Может быть указан один из операндов, а второй операнд подразумевается, первый располагается в специальном регистре – аккумуляторе, туда же заносится результат операции.
2) Непосредственная адресация. В этом случае значение операнда указывается в адресной части команды. Наиболее часто используется при адресации константы, пишем в операцию сразу её значение
3) Прямая адресация – в этом случае в адресной части команды указывается адрес ячейки памяти Иа , при этом Аи = Ак. Этот способ наиболее часто использовался в ЭВМ первого и второго поколения. Недостаток – с ростом объёма памяти пишутся длинные команды mov al,[10abf002h]
4) Регистровая адресация. При регистровой адресации в адресной части указывается адрес регистра хранящего операнду – наиболее экономичный способ адресации. При регистровой адресации длинна адресной части получается коротко т.к. номер регистра является его адресом, занимает длину пол байта в случае sub cx,bx. При регистровой адресации благодаря короткой длине команд экономится память при размещении программы в ОП, кроме того такие команды уменьшают число обращений к ОП, что повышает быстродействие.
5) Косвенная адресация. В этом случае в команде указывается не адрес операнда, а адрес регистра или ячейки памяти содержащий адрес операнда. Не адресация операнды, а адресация памяти.
Косвенная адресация предполагает как минимум 2 обращения к ОП , если адрес операнда хранится в ОП. Допускается использование многоступенчатой косвенной адресации. В этом случае в команде указывается адрес первой ячейки и кратность адресации, а операнд располагается в последней адресной ячейке. В современных ЭВМ допускается 6¸8 кратная адресация, но как правило косвенная адресация однократна. В малых и микро ЭВМ с короткой длинной длиной машинного слова, косвенная адресация позволяет обойти проблемы возникающие при адресации ячеек памяти, адреса которых имеют большую длину. В этом случае адрес ячейки памяти записывается в регистр. В команде указываться адрес регистра хранящего адрес операнда. add cz,[bx] или mov eax,[ecx] На наличие косвенной адресации в команде может указываться либо код операции команды, либо специальный бит отводимый в коде команды для указания на способ адресации. Если этот бит 1 – адресация косвенная, иначе нет.
26. Относительная и индексная адресация
В этом случае адрес операнда задается относительно некоторого базового адреса (Аб).
Для хранения Аб выделяется специал. регистр, который называется базовым регистром. Это может быть один из РОН.
Будем в дальнейшем обозначать такой регистр В, а его содержимое (В); D-смещение.
При относительной адресации в адресной части команды указывается номер базового регистра и смещение:
Принцип относительной адресации поясняется схемой:
 
Схема, поясняющая формирование Аи, показана на рис.:
При реализации оптимальной адресации процессор по номеру базового регистра В, содержащегося в команде находит в РОН базовый регистр передает его содержимое на сумматор СМ, куда поступает также D. На выходе сумматора формируется исполнительный адрес Аи.

Выполнение операции сложения требует определенных затрат времени, поэтому в некоторых случаях для повышения быстродействия формирование Аи осуществляется путем совмещения базового адреса В и смещения D. В этом случае младшие биты В должны содержать нули. Количество нулевых бит должно быть равно длине смещения. Схема формирования Аи имеет вид:
Одно из основных достоинств относительной адресации возможность перемещения программы в ОП. Для этого достаточно изменить содержимое базового регистра. При использовании этой адресации в ассемблерных программах адрес операнда представляется в виде записи регистр + смещение, который помещается в [].
Sub AX,[EBX+8]
Индексная адресация.
Используется при обработке массивов и организации циклов. Массив – упорядоченная совокупность элементов одинакового типа. Различные элементы массива имеют одинаковую длину и располагаются последовательно в ОП. Положение элементов внутри массива задается с помощью индексов. Для хранения индекса при индексной адресации среди РОН выделяется индексный регистр. Значение Аи=(В)+(Х)+Р, где Х - индексный регистр, (Х) – его содержимое.
Схема формирования Аи приведена на рис.:
При выполнении команды по номерам базового и индексного регистров, содержащимся в команде, процессор обращается к соответствующим регистрам, извлекает их содержимое и передает на сумматор, куда поступает также смещение D. На выходе сумматора формируется Аи элемента массива. При индексной адресации одна и та же команда без изменения отдельных ее частей может многократно выполнятся в цикле. При этом автоматически происходит изменение содержимого индексного регистра Х путем увеличения автоинкримента на 1, либо наоборот при каждом прохождении цикла. В ассемблерных командах имя Х указывается в [] :MOV AX,[EBХ][EDX].
В современных 32 битных микропроцессорах допускается масштабирование Х, если операнды являются 32-битовыми. Но заключаются в умножении содержимого Х на значения 2, 4, 8. Такой прием удобен при организации обработки элементов массива, имеющих длину 2, 4, 8 байт. В этом случае ассемблерная команда:
MOV AX,[EBХ][EDX*8], где [EDX*8] индексный регистр.
28. Стековая адресация
Используется при работе со стековой памятью и представляет собой один из безадресных (подразумеваемых) способов адресации. Это связано с тем, что в стековой памяти запись и чтение информации осуществляется через одну и ту же ячейку памяти. Называемую вершиной стека. Этот процесс иллюстрируется следующей схемой:

При работе со стековой памятью обычно используют указатель вершины стека, в котором хранится адрес последней, заполненной стековой памятью ячейки. При записи/чтении из стека содержимое указателя стека (УС) изменяется автоматически. При записи увеличивается, при чтении уменьшается, поэтому отпадает необходимость в командах указывать адреса ячеек стековой памяти. В командах, использующих стековую память указываются только номера регистров, либо номера ячеек ОП, в которых хранятся операнды, используемые в операциях со стековой памятью.
Операции со стековой памятью широко используются в современных ЭВМ для организации работы с подпрограммами.
29. Алгоритм работы процессора. Рабочий цикл процессора
1.вычисление адреса ком-ды
2.выборка ком-ды
3.декодирование ком-ды
4.вычисление адресов операндов
5.выборка операндов
6.исполнение операции
7.запись результата
Для хранения адреса ком-ды используется содержимое указателя ком-ды IP(счетчик ком-д). При выполнении текущей ком-ды, адрес которой хранится в программном счетчике ПС, процессор определяет длину этой ком-ды в байтах и прибавляет к содержимому ПС, таким образом, уже на этапе выполнения данной ком-ды процессор формирует адрес следующей ком-ды. Такой порядок вычисления адреса ком-ды имеет место при выполнении программы в естественном порядке следования ком-д. При наличии в программе ком-д переходов в ПС загружается адрес перехода, содержащийся в этих ком-дах.
Выборка осуществляется контроллером шинного интерфейса по адресу, хранящемуся в ПС. Выбираемую ком-ду контроллер помещает в очередь ком-д. В современных процессорах осуществляется не поком-дная выборка, а выборка ком-д в виде блока длиной в 16 байт, который может содержать более одной ком-ды. Такая выборка называется опережающей. Блоки из ОП выбираются выровненными, то есть их младший байт имеет адрес, содержащий нули в четырех младших битах. Опережающая выборка ком-д сочетается с опережающим декодированием.
Декодирование ком-д делится на первичное и вторичное. При первичном декодировании определяется тип ком-ды и ее адрес. Знание типа ком-ды позволяет упростить алгоритм обработки ком-д, так как ком-ды одного типа выполняются одинаковым образом. Это позволяет уменьшить длину адресного кода. Вторичное декодирование осуществляется после вычисления адресов операндов и их выборки.
Производится только для адресных ком-д и зависит от типа адресации операндов в ком-де. Первым вычисляется адрес операнда-источника, то есть такого операнда, который не изменяет своего значения в процессе выполнения ком-ды. Вторым вычисляется адрес операнда-приемника, то есть операнда, изменяющего свое значение и по адресу которого располагается результат выполнения операции. Процесс вычисления адресов операндов сочетается с выборкой, то есть после вычисления адреса операнда-источника, затем он выбирается из ОП, а потом вычисляется адрес приемника. На этапе вычисления адресов операндов используется содержимое базовых, индексных и регистров смещения:
Aи=(B)+(I)+D, где D-смещение, с использованием сумматора контроллера шинного интерфейса. Вычисленный адрес помещается в регистр адреса РА.
В случае безадресных ком-д выборка не производится. Эти ком-ды выполняются сразу же после первичного декодирования. В случае ком-д пересылки выборка операнда-приемника заменяется операцией записи операнда-источника по адресу операнда-приемника. По отношению к интерфейсу процессора выборка операндов сводится к последовательности операций: ввод – пауза – вывод. Пауза необходима для выполнения операций, предписываемой ком-дой.
Исполнение операции осуществляется в зависимости от типа операции, определяемой ком-дой. В арифметико-логических операциях УУ процессора вырабатывает последовательность сигналов для АЛУ. Операнды подключаются к АЛУ, результат записывается по адресу операнда-приемника. В ком-де безусловного перехода адрес перехода, содержащийся в ком-де, загружается в ПС. В ком-дах условного перехода предварительно перед загрузкой адреса, в ПС анализируется условие. Если оно не выполняется, содержимое ПС сохраняется, если выполняется – в ПС загружается адрес перехода. Ком-ды управления являются безадресными и выполняются после первичного декодирования. Действия этих ком-д сводятся к изменению внутренних регистров процессора, содержащих управляющую информацию. Ком-ды ввода/вывода обеспечивают обмен информацией между процессором и внешними ПУ. Этот процесс аналогичен операции пересылки информации, поэтому для его реализации используются ком-ды пересылки, в которых в качестве операндов источника и приемника используются регистры портов ввода/вывода и ПУ. Этим регистрам присваиваются определенные адреса из адресного пространства ЭВМ.
30. Программная модель процессора (регистры общего назначения и сегментные регистры)
Набор программно доступных регистров, имеющихся в составе процессора, определяет его программную или регистровую модель. Эти регистры определяют те ресурсы, которые предоставляются пользователю при программировании процессора. В разработке программных моделей процессора существуют 2 подхода:
В первом подходе все регистры считаются универсальными, то есть могут участвовать в одних и тех же операциях.
Во втором подходе, характерном для МП Intel, регистры являются специализированными, то есть могут участвовать в определенных операциях, в которых за ними закрепляются специальные функции.
В программную модель 32-битовых МП входит 31 регистр, которые делятся на 16 регистров прикладного программиста (пользовательские регистры) и 15 системных регистров.
Основные пользовательские регистры:
Они делятся на 8 регистров РОН, 6 сегментных регистров, на ПС-регистр и регистр флагов. РОН имеет длину 32 бита: (см. рис)
Первые 4 РОН допускают адресацию двойных слов так называемые расширенные регистры EAX, EBX, EDX, ECX (32 бита). AX, BX, CX, DX (16 бит). Допускается адресация только младшей половины регистров (биты 0 - 15), а 16 – 31 биты не допускают адресации. В младшей половине регистров допускается адресация старшего и младшего байтов:
AH BH DH CH (биты 8 - 15)
AL BL DL CL (биты 0 - 7)
Такая адресация первых 4 РОН позволяет легко оперировать при программировании на ассемблере байтами, словами и двойными словами. Все РОН могут использоваться в различных операциях, но существуют операции, в которых эти регистры выполняют специальные функции. Отсюда происходит и название регистров:
EAX/ AX/ AL – регистр-аккумулятор. Используется в арифметических и логических операциях, операциях ввода/вывода и др. в операциях деления и умножения в этих регистрах хранятся делимое и множимое, в него же помещается результат. Причем используется подразумеваемая адресация.
EBX/ BX/ BL – базовый регистр, используется для хранения базового адреса при относительной адресации операндов.
EDX/ DX/ DL – регистр данных, используется для хранения данных в арифметических и логических операциях, операциях пересылки и пр. В операциях ввода/вывода с использованием портов в этом регистре хранится адрес порта ввода/вывода.
ECX/ CX/ CL – регистр-счетчик циклических операций над цепочками бит, байт, слов и двойных слов.
ESP/ SP – используется в стековых операциях. Имя этого регистра неявно полагается в операциях PUSH и POP, применяется для хранения адреса вершины стека в данном сегменте памяти.
EBP/ BP – указатель базы, используется для указания базового адреса при строковых операциях.
ESI/ SI – индекс источника.
EDI/ DI – индекс приемника. оба эти регистра используются для хранения индексов при выполнении цепочных операций.
Сегментные регистры
Введены в связи с сегментной организацией памяти. Сегмент – совокупность ячеек памяти с последовательными адресами. В 32-битовых МП используется 6 сегментных регистров:
CS, SS, DS, ES, FS, GS (см. рис)
Сегментные регистры содержат информацию о текущих сегментах памяти, используемых при выполнении программы. В МП i8086 в них хранится физический базовый адрес сегмента. В МП начиная с i80386 сегментные регистры адресуют сегменты с помощью дескрипторной таблицы, которая определяет базовый адрес сегмента, его размеры и права доступа, то есть те программы и операции, которые доступны для данного сегмента. В МП i8086 составлял 64 Кб, а в современных 32-битовых МП память может содержать тысячи сегментов длиной по 4 Гб. Каждый сегментный регистр имеет следующее назначение:
1. регистр CS – сегмент кода, хранит информацию о сегменте памяти, в которых располагается команда текущей выполняемой программы.
2. SS содержит информацию о сегменте памяти, используемой в типовых операциях, то есть все операции осуществляются через SS. Вершина стека для сегмента, определяемого SS адресует регистр ESP/ SP.
3. DS – сегмент данных, определяет сегмент памяти, в котором хранятся данные, обрабатываемые в текущей программе.
4. ES, FS, BS – определяет дополнительные сегменты памяти, доступные текущей выполняемой программы.
31. Программная модель процессора (указатель команд и регистр флагов)
Регистр – указатель команд EIP/ IP (см рис)
Содержит адрес текущей команды, выполняемой процессором. К моменту завершению рабочего цикла процессора здесь формируется адрес, подлежащий выполнению.
Регистр флагов. EFLAGS/ FLAGS
Флажки управления: AC, VM, RF, DF, IF, TF.
Флажки состояния: NT, IOPL, OF, SF, ZF, AF,PF, CF.
Регистр флагов содержит 8 флагов состояния и 6 флагов управления. Флаги состояния определяют вычислительные ситуации, которые могут возникать во время выполнения программы, фиксирует признаки результатов при выполнении операций и программ. Флаги управления позволяют управлять работой процессора.
CF – перенос, 1, если перенос из старшего бита.
PF – паритет, 1, если четное число единиц.
AF – дополнительный перенос, используется в операциях десятичной арифметики.
ZF – нуль, 1, если нуль.
SF – знак, 1, если отрицательный результат.
TF – флаг трассировки, 1, если режим трассировки.
IF – прерывание, 1, если прерывания разрешены.
DF – флаг направления.
OF – переполнение, 1, если переполнение.
IOPL – привилегии доступа.
NT – флаг вложенности задачи, 1, если существует переключение к другой задаче.
RF – используется при редактировании программы.
VM – устанавливает виртуальный режим процессора.
AC – выравнивание данных в ОП.
32. Понятие о состоянии процессора. Слово состояния процессора
В процессе выполнения каждой команды происходит изменение состояния управляющих регистров, содержимого регистров, счетчиков проце-ов. В этом смысле можно говорить об изменении состояния процессора. Состояние процессора в любой момент времени, должно как-то фиксироваться. Для того, чтобы восстановить выполнение программы с той точки, с которой она была прервана по какой-либо причине. В общем случае под состоянием процессора понимается содержимое всех его управляющих триггеров, регистров, счетчиков, а также ячеек ОП ЭВМ.
Следует отметить, что не все перечисленные инф. элементы изменяются при выполнении программы. С точки зрения фиксации состояния процессора в любой заданный момент времени. Важны те инф. элементы, которые имеют наиболее важные значения для управления вычислительным процессом и изменяются наиболее часто при выполнении программы.
Совокупность таких элементов называется словом, или вектором состояния процессора (программы) – ССП. Для ЭВМ, реализованных на основе микропроцессора Intel ССП входит содержимое программного счетчика, или указателя команд EIP; аккумулятора EAX и регистра флажков EFLAG.
Необходимо отметить, что отдельные устройства имеют свое слово состояния программы.
33. Принципы организации системы прерываний процессора
Прерывания выполнения программы возникают как реакция процессора на ситуации, возникающие внутри самой ЭВМ, и во внешней среде при выполнении программы. Реакция заключается в том, что процессор приостанавливает (прерывает) выполнение текущей прогр-ы и переходит к вып-ю спец-ой прогр-ы, предназн-ой для этого случая. После завершения этой прогр-ы происходит переход к исходной прогр-е, вып-е к-ой было приостан-о.
Прогр-а, вып-е к-ой приостанавливается, наз прерываемой. Прогр-а, к-ая начинает вып-ся после прерывания текущей, наз прерывающей. Прерывание инициализируется спец-ми сигналами, поступающими в процессор, наз запросами прерывания. Схема процесса прер-ия мож быть представлена след образом:
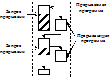
Запросы прер-ий могут инициал-ся ситуациями, возникающими внутри ЭВМ: аппаратные сбои (аппар прерыв-я), вычислительные ситуации (деление на 0, переполнение и др), требования в/в перефер-ых устройств.
Запросы прер-я из внешней среды могут возникать от других ЭВМ, с к-ми данная связана в сеть, от аварийных датчиков, если ЭВМ работает АСУТП и др.
ЭВМ имеет набор аппар-ых и прогр-ых средств для обработки прер-ий, к-ый получил назв-е системы прер-ий процессора. Осн назначение сист-ы прер-ий сост из 2-х ф-ций:
– Запомнить состояние прерванной прогр-ы и перейти к вып-ю прерыв-щей прогр-ы
– Восстановить состояние прерв-ой прогр-ы и вернуться к ее вып-ю.
Для обработки прер-ий процессор имеет спец входы INTR и NMI, а шинный интерфейс процессора – спец шины, по к-ым поступают запросы прер-ия. После вып-я каждой команды процессор опрашивает состояние шин запросов прер-ий и если на них имеется сигнал запроса прер-я, процессор переходит в режим обработки прер-я. Для обработки прер-ий важное значение имеет ССП.
По запросу прер-я процессор сохраняет ССП прерванной прогр-ы в стеке или в спец-ой ячейки ОП, после чего из ОП извлекается ССП прерыв-щей прогр-ы (прогр-ы обработки прер-ий) и оно загружается в соотв-щие рег-ры. После этого начинается вып-е прерыв-щей прогр-ы. Для возврата от прер-щей прогр-ы к прер-ой в системе команд проц-ра есть спец команда IRET, по к-ой осуществ-ся возврат к прерв-ой прогр-е. Эта команда инициирует следующ действия: из стека или ячейки ОП извлекается ССП прерв-ой прогр-ы и загружаится в соотв-щие рег-ры. Бит прер-ий IF рег-ра флажков сбрасывается в 0 и осущ-ся прогр-ое восстановление содержимого других рег-ов, после чего происх продолжение вып-я прерв-ой прогр-ы с того места, где она была приостановлена.
При вып-ии прогр-ы одновременно может возникать несколько запросов прер-ий, к-ые одновременно поступают в процессор. Сущ определенная система приоритетов, определяющая порядок обработки запросов прер-ий. В том случае если прер-я поступают по разным шинам прер-ий, вопрос о порядке обработки запросов решает сам процессор. Если несколько запросов поступают по одной и той же шине, их обработку осуществляет спец устр-во – контроллер прер-ий, к-ый выполняется в виде отдельной МС либо может входить в состав процессора.
Контроллер прер-ий может обрабатывать одновременно несколько прер-ий. Входной информацией для контроллера прер-ий явл код прер-ия, к-ый снимается с шины прер-ий. Каждый бит этого кода соответствует какому-либо одному прер-ю. Для того, чтобы запретить обработку каких-либо прер-ий, использ маска. Маска – двоичный код, к-ый имеет ту же разрядность, что и код прер-ия. Если обработку какого-либо прер-я нужно запретить, в соотв-щем бите маски устанавливается 0, если разрешить – 1.
Запрет того или иного прер-я или его разрешение осущ-ся путем побитового логического умножения кода прер-я и кода маски. В соответствии с рез-ом умножения кода прер-я и маски контроллер прер-я формирует вектор прер-ий, к-ый используется для поиска в дескриптерной таблице адреса ССП прерыв-щей прогр-ы в ОП. ССП извлекается, загружается и начинается выполнение прерыв-щей прогр-ы.
34. Контроллер прерываний
КП – устройство, предназначенное для разрешения конфликтов между запросами прерываний и формирования вектора прерываний. При формировании запросов прер-ий используется код прер-ий, к-ый в общем случае имеет вид: P=P1P2…P3, где Pi – сигнал, к-ый поступает по i-ой шине прерываний Pi={0,1}. Если имеет место прер-е с номером I, соотв-щее номеру разряда кода прер-я, то Pi=1. Для управления запросами прер-ий (ЗП) исп код маски, к-ая имеет ту же разрядность, что и код прер-ия. Она позвол маскировать прер-я, устанавливая в каком-либо бите 0. сигнал запросов прер-ия явл входным для КП. M=M1M2…Mn. Сигнал запроса прер-ий, явл-щийся выходным для КП, формируется как конъюнкция кода прер-ия и маски. Если в соотв-щем бите кода маски установить 0, то это запрещает обработку прер-ия с номером, соотв-щем номеру бита в коде маски, в к-ом 0.
Структ схема КП показ на рис.
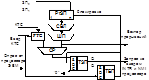
РгЗП – рег запросов прер-ий, исп для хранения кода ЗП. Строится на Д-триггерах, имеющих возможность блокировки.
СВЛ – схема выделения левой единицы. Преобразует код запроса прер-ий в унитарный код путем оставления крайней левой единицы в коде ЗП.
ШП – шифратор приоритетов. Преобразует унитарный код с выхода СВЛ в двоичный код вектора прер-ий, к-ый исп-ся процессором для нахождения адреса ячейки памяти дескрипторной таблицы, по к-ому в ОП хранится ССП прерыв-щей прогр-ы.
СР – схема сравнения. Сравнение кода вектора прер-ий и кода, поступ-щего из РТС.
РТС – регистр технического состояния, к-ый хранит код текущего состояния (КТС).
ТЗП – триггер запросов прер-ий. Реализован как Д-триггер с прямым динамическим управлением и с конъюнктивной записью по информ-му входу Д.
ТБП – триггер блокировки прер-я. Реализован как DRS-тг, запись инф-ии в к-ый может осуществляться сигналом низкого уровня на входе S, либо синхронно при наличии на входе С перепада из 1 в 0
35.Конвейерная обработка (КО)
КО позаоляет совместить во времени отдельные операции рабочего цикла процессора и яв. Одним из способов организации параллельных процессов выч-ных систем. Для КО рабочий цикл процессора разбивается на отдельные этапы каждый из которых выполняется отдельным автономным устр-вом в составе процессора ЭВМ. Совмещая во времени работу этих устройств можно обеспечить повышение производительности процессора. Основными этапами выполнения команды в раб. Цикле процессора:
--выборка команды (ВК)
--дешифрация --||-- (ДК)
--выборка операндов (ВО)
--исполнение команды (ИК)
Указанные этапы выполняются послед. Во времени
®[ВК]®[ДК]®[ВО]®[ИК]®
В случае обычного процессора в нём в любой заданный момент времени обрабатывается только одна команда, для кот. выполняется последовательность этапов, представленная выше. После выполнения донной команды это повторяется дальше и т. д. Временная диаграмма выполнния команды для обычного процессора имеет вид:(см. рис.).
tпос=tвк+tдк+tво+tис
4tT=tпос - длительность такта (один этап выполняется за один такт)
P=1/tпос=1/4tТ (операций / с) производительность
КО позволяет совместить различные этапы когда одна команда выбирается, др. декодируется, для 3-ей выбираются операнды, а 4-ая исполняется. Для реализации такого порядка обработки в составе процессора имеются спец. устр-ва, функционирование во времени к-ых совмещается. Операционное устройство исполняет первую команду, реализуя этап ИК, устр-во ВО обеспечивает этап ВО для 2-ой команды, устр-во декодирования обеспечивает этап ДК для 3-ей команды и устр-во ВК обеспечивает этап для 4-ой команды. В этом случае временная диаграмма исполнения после-сти команд имеет вид:(см. рис.)
Как видно из временной диаграммы, начиная с момента t0 конвейер полностью заполнен и в каждом последующем такте выполняется одна команда программы. Это означает, что время выполнения команды : tконв=tT , а pконв=1/tT (1)
Видно, что pконв> pпост
На самом деле производительность процессора при конвейерной обработке не строго определяется соотношением (1). Это связано с простоями конвейера, к-ые возникают при выполнении команд условного перехода и прерываниях. Наиболее негативное влияние на конвейерную обработку оказывают команды условных переходов, т.к. процессор до получения рез-та анализа условия не может знать какую последовательность команд он должен выполнять следующей. Для повышения производительности конвейера при выполнении команд условных переходов совр МП содержат спец блоки ветвлений. К к-ые одноврем загружаются обе ветви, по к-ым может пойти процесс при выполнении команды условного перехода. В этом случае после получения рез-та анализа условия, процессор сразу же может приступить к обработки ветви, т.к. эти команды имеются уже в процессоре.
В 32 битовых МП Intel, начиная с 386 бок ВК осущ опережающую выборку, помещая в очередь команд 16 байт (3-7 коинд).
Суперскалярные процессоры (СП)
Современные МП яв суперскалярными.
Суперскалярность означает способность процессора одновременно выполнять 2 и более команд. Это обеспечивается использованием процессора параллельных конвейеров.
36. Микропроцессор Pentium (общая ха-ка, структура)
Объединяет на одном кристале 3,1 млн транзисторов. Имеет тактовую частоту 60МГц.
В Pentium впервые были использованы 2 параллельных конвейера и ряд новых архитектурных решений, к-ые позволили увеличить производительность Pentium, так что она ув в 2,6 раза.
Производительность Pentium 112 MIPS. Основными архитектурными решениями, позволившими ув производительность Pentium по сравнению с предшествующими яв:
- Суперскалярная структура
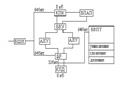
- Использование раздельного кэширования (т.е. отдельное хранение команд и данных)
- Предсказание правильного адреса перехода
- Использование блока вычислений с плавающей точкой встроенного процессора
- Использование внешней 64-битовой шины данных.
Структура МП:
КПК – Кэш-память команд
КПД – Кэш память данных
БПАП – блок предсказания адреса переходов
БВУ – блок выборки с упреждением
АЛУ – целочисленные АЛУ для выполнения операций над адресами и целочисленными данными в форме с фиксироаной точкой
БР – блок регистров, содержит 64 битовые регистры, к-ые могут использоваться как буфер и для др целей
БВПТ – блок вычислений с плавающей точкой
БШИ – блок шинного интерфейса
37. Микропроцессор Pentium (организация конвейера, кэш команд и данных, блок предсказания адреса переходов)
3. D2 - второе декодирование (вычисление адресов операндов и их выборка)
4. ИК - исполнение команды
5. ЗБ - запись в буфер результата
Этапы ВК и D1 в Pentium являются общими для обоих конвейеров. На этих этапах выбираются и декодируются по 2 команды, предназначенные для работы в конвейерах.
Структура конвейерной обработки:
В Pentium используется 2 конвейера U и V.
V конвейер имеет некот. ограничения по сравнению с U конвейером. На этапе исполнения команды проверяются 2 след. команды, подлежащие исполнению.
Если допускается их одновременное исполнение, то они запускаются в U и V конвейер.

Если допускается выполнение только одной команды, она запускается в U конвейер, V конвейер при этом простаивает. На этапе повторного декодирования D2 используется целочисленное АЛУ, каждый конвейер имеет свое АЛУ. АЛУ выполняет операции аппаратного, без привлечения микропрограммного управления, широкоиспользовавшегося в 16битовых процессорах и ниже, это повышает производительность конвейера.
Блоки КПК и КПД.
Эти блоки обеспечивают раздельное кеширование команд (КПК) и данных (КПД). Раздельное хранение программ и данных в МП Pentium и в последующих поколениях исключает конфликты при одновременном обращении по шине для чтения или записи данных и команд. МП Pentium имеет встроенную 8Кбайтную КПК и КПД.
КПК и КПД имеют наборно-ассоциативную структуру с длиной строки КЭШа 32 байта. КПД имеет отдельные интерфейсы, кот. позволяют одновременно обеспечивать данными 2 команды, выполняемые в конвейере.
Блоки БВУ и БПАП.
БВУ используется для предвыборки команд из КПК. Он состоит из 4-ех независимых буферов длиной 32 байта. Для загрузки конвейера осуществляется выборка двух команд из КПК, для временного хранения кот. используются 2 буфера БВУ. БВУ работает совместно с БПАП. БПАП отслеживает команды, кот. загружаются в БВУ, если среди них не всречается команд переходов, программа выполняется в естественном порядке следования команд. В том случае, если появляется команда перехода, БПАП предсказывает адрес перехода. Практически это осуществляется след. образом: если переход предсказывается, БПАП запоминает команду перехода и ее адрес и загружает в свободный буфер БВУ ветвь перехода, т.е. последовательность команд, начиная с команды, хранящейся по адресу перехода. В том случае, если переход предсказан неправильно, конвейер очищается, программа возвращается к точке, из кот. был вызван неправильный переход и продолжает выполняться в естественном порядке следования команд. Для этого потребуется определенное время, кот. реализуется ввиде так наз. штрафных циклов конвейера. При неправильном предсказании перехода U - 3 штрафных цикла, V - 4 цикла.
38. Принципы динамического исполнения программ
Современные процессоры реализуют динамическое выполнение программ, которое базируется на трех компонентах: 1) предсказании адреса перехода, 2) анализе потока данных, 3) опережающем или внеочередном исполнении программы.
Предсказание адреса перехода. Механизм пр.а.п. основывается на запоминании адреса перехода и анализе предыстории перехода, для чего процессор использует БАП, в котором запоминаются адреса переходов и специальные биты предыстории, которые несут информацию о том, имел ли место переход с данным адресом ранее. Это дает процессору возможность, не дожидаясь завершения анализа выполнения условия перехода, направлять в конвейер команды, начиная с адреса перехода. Это уменьшает простой и повышает производительность. Естественно если переход предсказан не правильно, то потребуется перегрузка конвейера. Наиболее эффективное предсказание перехода выполняется для циклов. Для современных процессоров вероятность правильного предсказания – 0.9. БПАП содержит БАП, который реализован как ассоциативная память. Каждая ячейка такой памяти способна хранить адрес перехода и биты предыстории. Когда команда условного перехода по какому либо адресу встречается первый раз, адрес перехода заносится в БАП и осуществляется установка определенных битов предыстории. Для каждой команды условного перехода осуществляется сравнение адреса перехода, указанного в команде с содержимым ячеек БАП. Если оказывается, что переход по такому адресу имел место, то по определённому алгоритму анализируются биты предыстории и предсказывается или не предсказывается переход. В микропроцессоре Pentium Pro БАП содержит 512 ячеек памяти и использует 4-х битовый код предыстории, который позволяет фиксировать до 4-х переходов.
Анализ потока данных и опережающее выполнение команд. В процессе выполнения программы процессор анализирует связи между командами и доступность операндов для команды. В соответствии с результатом такого анализа обеспечивается направление команд на исполнение, если все операнды оказываются доступными. Это позволяет осуществлять неупорядоченное выполнение команд. Опережающее выполнение команд позволяет эффективно заполнять конвейер процессора, уменьшить простой.
39. Микропроцессор Pentium Pro (общая ха-ка, структура)
Микропроцессор интегрирует 5,5 млн. транзисторов, самый слабый на частоте 150МГц имеет вторичную КЭШ 256кбайт и напряжение питания 3,1В. Понижение напряжения питания в микропроцессоре ПентиумПРО и последующих поколений связана с необходимостью снижения энерговыделения для обеспечения нормального теплового режима процессора при растущей степени интеграции и рабочей частоте. Чем больше частота, тем больше потерь.
Новым архитектурным решением, используемым в микропроцессоре ПентиумПРО является то, что он выполняет программу, отличную от ее выполнения в микропроцессорах предшествующих поколений. ПентиумПРО разбивает программу на отдельные фрагменты и выполняет их в наиболее оптимальной последовательности с точки зрения обеспечения минимума затрат времени и ресурсов системы. Эта последовательность может существенно отличаться от последовательности следовательности команд в программе. На заключительном этапе спец.блоки микропроцессора упорядочивают результаты в том порядке, что они соответствуют порядку выполнения программы.
Другим новым архитектурным решением является использование КЭШ 2-го уровня и раздельных шин связи. Одна шина связи-системная и используется для взаимодействия микропроцессора с ОП и внешними устройствами, другая- используется для обмена процессора с КЭШ 2-го уровня.
Обмен осуществляется параллельными 64-битовыми кодами. В микропроцессоре ПентиумПРО используется 3 параллельных конвейера, которые позволяют выполнять до 3-х команд за 1 такт. В отличие от микропроцессоров Пентиум(5 ступ.) конвейер микропроцессора ПентиумПРО включают 14 ступеней. Одновременно в конвейере происходит обработка 3-х команд, которые в блоке декодирования разбивают на простейшие микрооперации. То есть одновременно в блоке декодирования могут выдавать до 6 микроопераций.
Не упорядоченное ядро процессора осуществляет подключение микроопераций к исполнительным устройствам (АЛУ для операций с фиксированной точкой, блок выполнения с плавающей запятой, блок цепи ветвления и др.) и обеспечивает выполнение микроопераций наиболее оптимальным образом, причем порядок выполнения микроопераций может отличаться от порядка, предписываемого командами программ. На этапе исполнения микроопераций может осуществляться дополнительная конвейеризация. Так конвейеризация может иметь место при выполнении арифметических операций,
операций с плавающей с плавающей запятой.
40. Блок упорядоченной обработки процессора Pentium Pro
Структура блока:

БВДК – взаимодействует с кеш – памятью команд через блок шинного интерфейса. На этом этапе выборки команд этот блок учитывает предсказание адреса переходов которые используют буфер адреса перехода.
ДК – декодер, состоит из 4-х автономно работающих устройств трансл. Команд в программе в послед. микрокоманд. ДК использует два блока простой обработки которые используются для обработки команд транслируемых в одну микрокоманду. Блок сложной обработки используется для декодирования сложных команд которые транслируются в несколько микрокоманд (до 4-х) если команда транслируется в большее число микрокоманд дополнительно используется блок упорядочения микрокоманд. В любой момент времени работают три блока обработки, которые наполняют командами три параллельно работающих конвейера.
ТПР – таблица псевдонимов регистров предназначена для реализации виртуальных регистров предназначыннных для реализации виртуальной многозадачности.
На этом этапе выборки команд БВДК извлекает из КПК с учётом предсказания адреса перехода, для чего используется БАП, блок команд длинной 64байта. Затем используя указатель текущей команды выбирает из 64-б. блока 16-и байтовый блок команд который выравнивается и пересылается в ДК. Выборка 64-б., а не 16 нужных для ДК определяется тем, что длинна строки кеш 32б. и чтоб не делать дополнительного обращения к памяти если 16-б. блок находится в двух соседних строках кеш. 16-б. блок поступивший в ДК обрабатывает тремя ранее упомянутыми блоками в результате чего за один такт может генерироватся до шести микрокоманд.
ТПР осуществляет преобразование логических адресов регистров в физич. адр. регистров в БРР. Необходимость использования БРР и ТПР связано с тем что ко-во регистров опред. прогр. Моделью в процессоре intel, недостаточно для организации динмического выполнения программ. После завершения этапа упорядоченной обработки программы, микрокоманды пересылаются в БДК и БВПК, где также фиксируется код статуса команд.
41. Блок обработки с изменением последовательности процессора Pentium Pro
Этот блок представляет неупорядоченное ядро в процессоре Pentium Pro.
БДК – блок диспетчер команд, в котором микрокоманды ожидают своей очеди на исполнение. Имеется три типа исполняемых устройств (блоки неупорядоченной обработки).
БОП – блок операции с памятью, который содержит буфер данных, блок генерации адр. записи, блок генерации адр. считывания.
БЦО – блок целочисленных операций.
БОПЗ – блок операций с плавающей запятой.
Используемые блок состоят из ряда автономных модулей, которые обеспеч. Паралельную работу трёх конвейеров процессора. Микрокоманды находящиеся в БДК направлены на исполнение когда для них оказываются доступны все операнды и свободны соответствующие операц. блоки предназначены для исполнения этих команд. Если команда поступившая а БДК имеет все необходимые операнды она направляется на исполнение. Результат выполнения микрокоманд пересылается другим микрокомандам для которых они являются операндами, а также фиксируются в БРР и в БВПК для дальнейшего восстановления последовательности команд. Для команд пересыски исп. БОП, а также для исключ, нарушений правил доступа к памяти – блок упорядоченого обращения к памяти (БУОП).
42. Блок вывода и внешняя шина процессора Pentium Pro
Блок вывода вкл. два осн. блока:
Блок восстановления последовательности команд;
Блок реальных регистров.
Основное назначение блока – организовать правильный вывод рез-тов и удаление команд из конвейера в соответствии с программой выполняемой процессором. Блок восстановления последовательности команд состоит из 40 элементов которые могут хранить 254б. каждый.
Каждый такой элемент может фиксировать одну команду, два её операнда, рез-тат выполнения, спец. код статуса команды. Биты этого кода несут информацию о том, выполняется ли эта команда, доступны ли вве операнды для команды.
Восстановление порядка вывода результата и выполненных команд из конвейера обеспечивается тем, что элементы БВПК загружаются командами определённым образм, а именно так, как они следуют в выполняемой программе. На этом этапе вывода рез-та анализир. Статус команд хранящихся в БВПК и в соответствии с ним формируется очередь команд на удаление из конвейера и очередь вывода рез–тов в соответствии с порядком следования команд.
Шина процессора
При организации шины исп. новое решение. исп. кеш L2 емкостью 256-512 кб. интегр. непоср. в процессоре. Это снижает число обращений по шине ОП и тем самым повышает производительность. Также как и в Pentium исп. 64б. (8бит коррекция ошибок: всего 72). Шина адреса – 36бит. Внешняя шина использует концепцию транзакций, суть которой закл. В том что процессор может посылать ряд последоват. запросов по шине к устройствам подключ. к ней, не дожидаясь ответов на эти запросы. Когда ответ будет подготовлен контроллер памяти сообщит об этом процессору и перешлёт ответ.
43. Процессор Pentium 4 (общая характеристика, новые архитектурные решения)
Предназначен для работы с такими процессами: обработка графики, потоков видео и звука, мультимедиа. Изготовляется по 0.18 мкн технологии, 1.3-1.6 ГГц, напряжения питания – 1.6 В. Используются архитектурные решения, найденные ранее. Раздельный КЭШ команд и данных, суперскалярный, предсказание адреса перехода, динамическое исполнение команд. Новшеством является: 1) Большая глубина конвейера – 20-тистадийный, 2) Уникальный алгоритм предсказания адреса перехода, 3) Использование специализированного КЭШа. – trace cash – он хранит декодирование команды, 3) Целочисленное АЛУ процессора PIV работает на вдвое большей частоте, чем сам процессор, 5) Применение расширенного набора команд для обработки потоковых данных, 6) Новая системная шина с повышенной частотой 400-800 MHz.
44. Структура и функционирование процессора Pentium 4
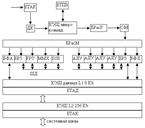
БШИ – блок шинного интерфейса, предназначен для обмена процессора через системную шину с ОП и устройствами ВВ. Шина данных двунаправленная 64 бита, шина адреса 41 бит.
КЭШ L2 используется для совместного хранения команд и данных. Интегрируется в кристалл процессора. Имеет наборную организацию с длиной строки КЭШ 128 байт и 8-ю областями ассоциативности.
БТАД – блок трансляции адреса данных – проявление гарвардской структуры, т. е. разделение потока команд и данных PIV начинается после КЭШа L2, данные и команды по отдельным каналам передаются в КЭШ L1 битрейс КЭШ. Команды поступают на декодер (ДК) и осуществляется их декодирование, при этом используется блок трансляции адреса команд БТАК и блок трассировки и предсказания ветвления БТПВ. Команды в ДК преобразовываются в последовательность микрокоманд. Это новое архитектурное решение, отличающее PIV от процессоров предшествующих поколений. Хранение декодированных команд позволяет сэкономить время на процессе декодирования, когда поступает команда программы, которая ранее выполнялась, например, цикл. В этом случае БТПВ просто извлекает из КЭШ последовательность микрокоманд данной команды и направляет их на дальнейшую обработку. КЭШ микрокоманд может хранить 12 тысяч микрокоманд, поэтому если она заполняла КЭШ, то практически для каждой вновь поступающей команды можно найти её закодированный вариант. В том случае, если встречалась команда условного перехода, БТПВ включает механизм предсказания перехода. БПАП в PIV содержит БАВ способный запоминать свыше 4000 переходов. Команды, выходящие из КЭШ поступают на БРасР (блок распределения регистров), где для них выделяются регистры, необходимые в блоках зарезервированных регистров, операционные части конвейера процессора. Регистры по внутренней шине данных ШД связаны с операционным устройством процессора. В PIV используется в БРЗ 32 битные регистры для операций с плавающей точкой, а также введены расширенные 128 битные регистры, которые могут одновременно хранить по 2 операнда с плавающей точкой. Команды, прошедшие БРасР и получившие необходимые для их выполнения регистры, помещаются в очередь на выполнение. Динамическое выполнение программы реализуется блоком распределения команд (БРасК), который анализирует поток микрокоманд, определяет связи между микрокомандами, наличие у микрокоманд операндов, и с учетом этих данных и наличия свободных исполнительных устройств направляет эти команды на выполнение. В PIV очередь микрокоманд расширена до 126. Обработка команд осуществляется автономно с параллельно работающими арифметическими блоками, которые включают 4-е АЛУ для операций с фиксированной точкой. АЛУ блок MMX, который предназначен для обработки нескольких целочисленных операндов с помощью одной микрокоманды. Для групповой обработки с плавающей запятой используется блок SSE, тоже одной командой. Операнды для операционных блоков поставляются из БРЗ, либо из КЭША данных L1 и записываемых в неё формируются буфером формирования адреса БФА. БФА при обращении к памяти одновременно выдает адреса двух операндов, один для загрузки операнда в БРЗ, другой - из БРЗ в память. Опережающее динамическое исполнение команд, не требующих операндов, позволяет эффективно наполнить 20-ти стадийный конвейер.
45. общая характеристика и классификация АЛУ процессора
АЛУ выполняет основные операции обработки многоразрядных кодов. К этим операциям относятся операции двоичной арифметики над числами с фиксированной точкой, а также над числами с плавающей точкой, операции десятичной арифметики над двоично-десятичными числами, операции индексной арифметики, операции над цифровыми полями, операции специальной арифметики, логические операции. Основными узлами АЛУ являются сумматоры, поскольку все основные операции выполняются на сумматорах: сложение, вычитание (как сложение в доп. коде), умножение (последовательность операций сложения и сдвига), деление (последовательность операций вычитания и сдвига). Различают АЛУ целочисленные и для операций над числами с плавающей точкой.
Целочисленные АЛУ выполняют арифметические операции над числами в формате с фикс. точкой как в знаковом формате, так и в беззнаковом, логические операции, индексные, и некоторые операции специальной арифметики.
АЛУ — для операций над числами в формате с плавающей точкой (ч.с.п.т.) выполняют опер над ч.с.п.т. и некоторые операции специальной арифметики.
46. Сложение и вычитание чисел в формате с фиксированной точкой
При выполнении операций сложения используется дополнительный код чисел, операция выполняется совместно над знаковыми и цифровыми битами числа. (переводится в дополнительный код и складывается в столбик)
Операция вычитания чисел с фиксированной точкой также реализуется в дополнительном коде и сводится к операции сложения, для чего вычитаемое преобразуется в АЛУ в дополнительный код и складывается с уменьшаемым. (переводим вычитаемее в обратный код, прибавляем 1, и складываем в столбик с уменьшаемым)
47. Структура АЛУ для сложения и вычитания чисел с фиксированной точкой
Функцию по преобразованию информации в процессоре выполняет АЛУ.
АЛУ выполняет арифметические и логические операции много разрядных двоичных кодов, называемые операндами.
Современные ЭВМ в составе процессора содержат целочисленные АЛУ для операций над целыми числами со знаком и без знака (числа с фиксированной точкой), логические операции, устройства десятичной арифметики, устройства выполнения операций с плавающей точкой.
Основным исполнительным узлом АЛУ ЭВМ является много разрядный параллельный сумматор. Это связано с тем, что всю совокупность операций в двоичной арифметике можно свести к операциям сложения и сдвига.
Целочисленые АЛУ.
В почве операндов таких АЛУ используются целые двоичные числа, представленные в форме с фиксированной точкой в обратном или дополнительном коде. Всю совокупность арифм. операций АЛУ выполняет исп. сумматор, поэтому все операции двоичной арифметики сводятся к выполнению операций сложения и сдвига. Для выполнения операций сложения и вычитания в целочисл. АЛУ исп. обратный и дополн. коды. Операции выпол. над всеми цифровыми разрядами числа, а также и над знаковым разрядом. АЛУ должно предусматривать цикл. перенос из знакового бита р-та, значение прибавляется к мл. биту р-та, если исп. обратный код. Целоч. АЛУ, вып. опер. сложения в доп. коде циклический перенос не исп. При вып. операции сложения может возникать переполнение, кот. должно учитыв. при работе АЛУ. Признаком переполнения явл. разные значения переноса из ст. цифрового бита числа и знакового бита числа, если разный перенос, то переполнение.
При выполнении опер. вычитания в целоч. АЛУ она сводится к опер. сложения. Для чего вычитаемое преобр. АЛУ в обратный или доп. код и складыв. с уменьшаемым в доп. коде. Переполнение фиксируется также.
Цел. АЛУ могут выполнять и опер. над числами без знака. В этом случае операнды всегда положительны. Алу фиксирует переполнение по наличию переноса из старшего бита р-та. В случае вычитания переполнение не возникает, однако р-т может быть как полож., так и отр. Признаком полож. р-та явл. наличие переноса из ст. бита р-та, если перенос отсутствует, то р-т отрицательный. По этим признакам формируется признак полож. или отр. р-та.
Структура АЛУ для слож. и выч. (см. рис. 1)
РгА, РгВ – входные буферные n – разрядные регистры – сумматоры.
РгСМ – выходной рег. сумматора.
Рг 1 – входной рег. АЛУ предусм. передачу его содержимого в РгА в прямом или инверсном коде
ПР – комбинационная схема для формирования признака р-та.
Работа АЛУ.
Данные в АЛУ поступают по ШИвх в доп. коде из ОП или РОН процессора. Первый операнд командой ПрРгВ (при вычитании – уменьшаемое) заносится в рег. РгВ. Второй операнд командой ПрРг1 (при вычитании – вычитаемое) заносится в рег. Рг1, откуда при выполнении сложения командой ПрРгАП передается в прямом коде в РгА. При вычитании ком. ПрРгАИ передается в инверсном виде в РгА. Операнды с выходов РгА и РгВ поступают на сумматор, где складываются, при выч. к р-ту присум. 1. Р-т с вых. сумматора командой ПрРгСМ записывается в РгСМ и выставляется на ШИвых , откуда может быть передан в РОН или ОП. При выполнении операций сложения и вычитания АЛУ формирует признак р-та, для чего исп. комбинационная схема ПР. Признак р-та формируется в виде двух битового кодав соотв с 0 – 00, <0 – 01, >0 – 10, переполнение – 11.
48. Алгоритм умножения и структура АЛУ для умножения чисел с фиксированной точкой
Операция умножения сводится к выполнению последовательных операций сложения и сдвига. АЛУ для умножения n-разрядных чисел должно предусматривать 2n-разрядов для результата.
Поскольку в сомножителях старшие биты – знаковые, после выполнения операции умножения множимого на все цифровые биты множителя, цифра старшего бита произведения будет располагаться в бите (2n-1). Для правильного расположения произведения в разрядной сетке после выполнения умножения требуется дополнительный сдвиг вправо на один быт, чтобы располагаться в бите (2n-2). Может быть реализовано в прямом и обратном коде. Наиболее просто реализовать, преобразовав сомножители к без знаковой форме.
В зависимости от того как осуществляется умножение (начиная с младшей/старшей цифры множителя; со сдвигом вправо/влево суммы частичных произведений) существует 4 способа умножения двоичных чисел.
Рассмотрим алгоритм умножения двоичных чисел с младших цифр множителя при неподвижном множимом и сумма частичных произведений сдвигается вправо.
Алгоритм состоит в следующем :
Складываются по модулю 2 знаковые биты сомножителей (это дает знак результата);
Сомножители из дополнительного кода преобразуются в беззнаковую форму (в модуль числа);
Сумма частичных произведений устанавливается равной нулю;
Анализируется (начиная с младшего разряда) текущая цифра множителя. Если она равна 1, к сумме частичных произведений прибавляется множимое, если =0 – ничего не прибавляется, либо прибавляются нули.
Осуществляется сдвиг суммы частичных произведений вправо на один бит
Пункты 4 и 5 повторяются до тех пор, пока не будет выполнено умножение на все цифровые биты множителя.
Результат сдвигается на 1 бит вправо для правильного расположения произведения в разрядной сетке
Беззнаковый результат преобразуется в дополнительный код с учетом знака произведения, полученного в пункте 1.
Структура АЛУ для умножения чисел
АЛУ реализующая рассмотренный выше алгоритм имеет следующую структуру
В структуре АЛУ не показаны блоки обеспечивающие вычисление знака произведения и преобразования сомножителей из дополнительного кода в беззнаковую форму. Будем предполагать, что такие блоки есть, так что сомножители по шине ШИВх приходят уже в беззнаковой форме. В схеме отсутствуют также цепи считывания результата в ОП.
Множимое хранится в регистрах Рг1 и РгА, множители – в Рг2 и Рг2’; частичные произведения – РгВ и РгСм.
СЧЦ – счетчик циклов, хранит количество циклов умножения, выполняемых в пунктах 4 и 5. ПРИНЦИП РАБОТЫ
Работа начинается с загрузки сомножителей. По команде ПрРг1 множимое загружается с ШИВх в Рг1, по команде ПрРг2 – множитель загружается в Рг2. В СЧЦ командой СЧЦ:=n-1 загружается количество циклов умножения, а в РгВ по команде РгВ:=0 начальное значение суммы частичных произведений. Анализируется младший бит Рг2. Если он равен 0, то в РгА заносится 0 (РгА:=0), если равен 1 – из Рг1 в РгА передается множимое. Осуществляется сдвиг множителя вправо на 1 бит (Рг2’:=П(1)Рг2, Рг2:=Рг2’). В освободившийся старший бит Рг2’ передается цифра младшего разряда суммы частичных произведений с выхода сумматора (Рг2’[n-1]:=СМ[0]). Затем осуществляется сдвиг суммы частичных произведений вправо на один бит (РгСМ:=П(1)СМ). После чего содержимое РгСМ передается во входной регистр сумматора РгВ (РгВ:=РгСМ). После выполнения этих операций на входе сумматора (выход РгВ) оказывается сдвинутое на один бит вправо частичное произведение, а в младшем бите Рг2 следующая цифра множителя. После этого ПР уменьшает содержимое счетчика циклов на 1 (СЧЦ:=СЧЦ-1). ПР анализирует содержимое СЧЦ, и если он не равен 0 продолжает повторение цикла умножения в соответствии с операциями описанными выше. Если СЧЦ=0, умножение завершено.
АЛУ выполняет дополнительный сдвиг произведения вправо на 1 бит для правильного расположения его в разрядной сетке (). После выполнения этих команд старшие биты –разрядного произведения окажутся в регистре РгВ, а младшие в Рг2, откуда могут быть считаны, преобразованы в дополнительный код и переданы в ОП.
Рассмотренное функционирование АЛУ требует микропрограммного управления, т.е. устройство управления для таких АЛУ должно содержать блоки микропрограммного управления, в котором в ПЗУ хранится микропрограмма состоящая из последовательности микрокоманд обеспечивающих функционирование АЛУ в соответствии с рассмотренным алгоритмом. Это снижает быстродействие, т.к. требует довольно большие затраты времени на дешифрацию команд и выработку сигнала для устройств АЛУ. Кроме того реализация алгоритма умножения требует не менее () такта.
49. Аппаратная реализация умножения чисел с фиксированной точкой
В современных ЭВМ для ускорения операции умножения используется ее аппаратная реализация. В качестве примере такой реализации рассмотрим матричный умножитель. Он позволяет выполнять операцию умножения за 1 такт и требует для реализации сумматор и логические элементы.
Однобитовая операция умножения совпадает с логической операцией конъюнкции. И может быть реализована с помощью логического элемента «И». Для построения многоразрядных умножителей (например 4- и 2-разрядных) требуется 8 двухвходовых логических элементов «И» и 4-разрядный сумматор.
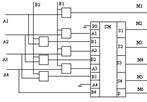
Умножение осуществляется за 1 такт.
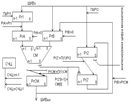
50. Алгоритм деления и структура АЛУ для деления чисел с фиксированной точкой
Операция деления в двоичной ариф. сводится к выполнения операций вычитанию из делимого делителя и сдвига. Текущая цифра частного определяется по знаку рез-та вычитания : 1 – если рез-т положителен и 0 –рез-т отриц. При выполнении вычитания неподвижными м. оставаться частичные остатки, а делитель сдвигаться вправо, либо наоборот, но остатки сдвиг-ся влево. Деление м. производиться как восстан-ем остатка, так и без восстан-я.
При реализации АЛУ для деления чисел фиксир. точкой, для делимого выделяется 2n разрядов, для делителя и частного n разрядов. Старший бит в операндах имеет 2n-1 цифровых разрядов, а делитель и частное n-1. Для размещения в разрядной сетке частного операций z=x/y, z<2n-1 для размещения в разрядной сетке, поэтому цифра частного, получаемого пои первом вычитании д.б. =0( частич. остаток отриц.). Первое вычит-е делителя из делимого рассматр-ся как пробное. Операция деления не вып-ся, если рез-т этого деления положителен.
Перед вып-ем операции дел-я, делитель располаг-ся относит. делимого т.обр., что его младший бит(0-ой)распол-ся по n-1 битам делимого. Рассм. алг. деления чисел с фиксир. точкой с восст-ем остатка неподвижным делителем ичастичн. Остатками, сдвигаемыми влево. Алг. использует модульную форму представления операндов:
1. по mod 2 складыв-ся знак. биты операндов. Рез-т дает знак частного и остатка берутся модули делимого и делителя
2. делитель и делимое передаются в АЛУ т. обр., что на входе сумматора младш разряд делителя и n-1 разряд делителя(это м. осущ-ся сдвигом делимого влево на 1 бит)
3. из делимого а в последствии из част остатков, выч-ся делитель( практ-и это осущ. дополнит кода делителя). Активизируется знак рез-та: <0 – текущая цифра частного 0; >0 – 1.При вычит-и модулей чисел о положит разнице свидет наличие переноса из старш бита рез-та, об отриц – отсутствие такого переноса.
4. При <0( част остатке) производ-ся его восст-е путем прибавл-я прямого кода делителя.
5. Част остаток сдвигается влево на 1 бит.
6. Пункты 4,5,6 вып-ся пока не получены все цифры частного.
Структура АЛУ, реализующего данный алг, показана на рис:
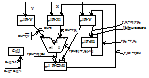
Делитель размещается в PгY .
В PгХ1 – старшие разряды делимого, а в PгХ2 - младшие.
В структуре не показаны цепи перелачи операндов в АЛУ и рез-та в ОП, а такжеустр-во, преобразующее операнды в модульную форму,рез-т в код, используемый в ОП.
PгХ3 дополнительный регистр, к-ый используется для операции деления.
Работа АЛУ начинаеися с его начальной установки: В РгY передается модуль делителя; РгX1 старшие биты модуля делимого; РгX2 - младшие биты модуля делимого.
51. особенности арифметических операций над числами с плавающей точкой
Числа с плавающей точкой имеют в компьютерном виде особое представление: в них мантисса и порядок хранятся раздельно, и операции над ними выполняются пораздельности. Т.е. при сложении чисел одинакового порядка складываются только мантиссы, а порядок остается. При сложении чисел с разными порядками необходимо привести числа к представлению с одинаковым порядком. При умножении чисел с плавающей точкой складываются порядки, а мантиссы умножаются. При делении вычитается порядок делителя из порядка делимого. После выполнения любой операции над числами в формате с плавающей точкой необходимо нормализовать результат — привести к виду, в котором в первом бите мантиссы находится 1.
|