ВСЕРОССИЙСКИЙ ЗАОЧНЫЙ ФИНАНСОВО-ЭКОНОМИЧЕСКИЙ ИНСТИТУТ
КАФЕДРА МАТЕМАТИКИ И ИНФОРМАТИКИ
КУРСОВАЯ РАБОТА
по дисциплине "Информатика"
на тему "Основные структуры данных
"
Барнаул - 2007
ОГЛАВЛЕНИЕ
ВВЕДЕНИЕ
1 ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
1.1 ОБЩАЯ ХАРАКТЕРИСТИКА ДАННЫХ
1.2 ЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ
1.3 ТАБЛИЧНЫЕ СТРУКТУРЫ ДАННЫХ
1.5 УПОРЯДОЧЕНИЕ СТРУКТУР ДАННЫХ
1.6 РЕЖИМЫ ОБРАБОТКИ ДАННЫХ
2 ПРАКТИЧЕСКАЯ ЧАСТЬ
2.1 ОБЩАЯ ХАРАКТЕРИСТИКА ЗАДАЧИ
2.2 ОПИСАНИЕ АЛГОРИТМА РЕШЕНИЯ ЗАДАЧИ
ЗАКЛЮЧЕНИЕ
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
ВВЕДЕНИЕ
Веками человечество накапливало знания, навыки работы, сведения об окружающем нас мире, другими словами — собирало информацию. Вначале информация передавалась из поколения в поколение в виде преданий и устных рассказов. Возникновение и развитие книжного дела позволило передавать и хранить информацию в более надежном письменном виде. Открытия в области электричества привели к появлению телеграфа, телефона, радио, телевидения — средств, позволяющих оперативно передавать и накапливать информацию. Развитие прогресса обусловило резкий рост информации, в связи с чем вопрос о ее сохранении и переработке становился год от года острее. С появлением вычислительной техники значительно упростились способы хранения, а главное, обработки информации. Развитие вычислительной техники на базе микропроцессоров приводит к совершенствованию компьютеров и программного обеспечения. Появляются программы, способные обработать большие потоки информации. С помощью таких программ создаются информационные системы. Целью любой информационной системы является обработка данных об объектах и явлениях реального мира и предоставление нужной человеку информации о них. С моей точки зрения актуально рассмотреть процесс превращения данных в информационные ресурсы и формы представления данных.
Все выше сказанное обусловило цель работы: исследовать основные структуры данных. Для достижения поставленной цели необходимо решить следующие задачи:
─ дать общую характеристику данным;
─ изучить различные структуры данных;
─ проанализировать упорядочение структур данных;
─ рассмотреть режимы обработки данных;
─ решить практическую задачу с использованием средств MSExsel.
Реклама

Объектом исследования являются данные. Предметом исследования служат структуры данных.
Информационной базой исследования являются публикации в сети Интернет и учебная литература по изучаемому вопросу.
Структурно работа состоит из введения, теоретической и практической частей, заключения, списка использованной литературы из 6 источников. Во введении обоснована актуальность работы, определены цель, задачи и предмет исследования. В теоретической части рассмотрены основные структуры данных. В практической части решена задача с применением средств MSExsel.
1.1 ОБЩАЯ ХАРАКТЕРИСТИКА ДАННЫХ
Данные
– это материальные объекты произвольной формы, выступающие в качестве средства представления информации. Преобразование и обработка данных позволяют извлечь информацию, т.е. знание о том или ином предмете, процессе, явлении [2, С.21]. Другими словами данные – диалектическая составная часть информации. Они представляют собой зарегистрированные сигналы. В соответствии с методом регистрации данные могут храниться и транспортироваться на носителях различных видов. Например, на бумаге данные регистрируются путем изменения оптических характеристик ее поверхности. Изменение оптических свойств используется также в устройствах, осуществляющих запись лазерным лучом на пластмассовых носителях с отражающим покрытием (CD-ROM).
Процесс документирования превращает данные в информационные ресурсы, которые являются основой любой информационной системы. Данные могут быть представлены в виде файлов, базы данных (данные, организованные с определенной целью), базы знаний.
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью методов. Обработка данных включает в себя множество различных операций:
• сбор данных
—
накопление информации с целью обеспечения достаточной полноты для принятия решений;
• формализация данных
—
приведение данных, поступающих из разных источников, к одинаковой форме, чтобы сделать их сопоставимыми между собой, то есть повысить их уровень доступности;
• фильтрация данных
—
отсеивание «лишних» данных, в которых нет необходимости для принятия решений;
• сортировка данных
—
упорядочение данных по заданному признаку с целью удобства использования; повышает доступность информации;
• архивация данных
—
организация хранения данных в удобной и легкодоступной форме;
• защита данных
—
комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных;
Реклама

• транспортировка данных
— прием и передача (доставка и поставка) данных между удаленными участниками информационного процесса;
• преобразование данных
—
перевод данных из одной формы в другую или из одной структуры в другую.
По форме представления данные бывают структурированные
(чертежи, схемы, диаграммы, таблицы, анкеты) и неструктурированные
(текст, картинки, фотографии). Работа с большими наборами данных легче автоматизируется, если элементы данных расположены в наборе в соответствии с некоторыми правилами, образуя заданную структуру. Структура данных определяет способ адресации
элемента данных. Адрес позволяет найти в наборе нужный элемент данных, не зная его значения. Выделяют три основных типа структур данных: линейные, табличные и иерархические.
Линейные структуры – это хорошо знакомые нам списки. Список
– это простейшая структура данных, отличающаяся тем, что каждый элемент данных однозначно определяется своим номером в массиве. Проставляя номера на отдельных страницах рассыпанной книги, мы создаем структуру списка. Обычный журнал посещаемости занятий, например, имеет структуру списка, поскольку все студенты группы зарегистрированы в нем под своими номерами, при этом не могут два студента быть зарегистрированы с одним и тем же номером [3, С.27].
При создании любой структуры данных надо решить два вопроса: как разделять элементы между собой и как разыскивать нужные элементы. В журнале посещаемости, например, это решается так: каждый новый элемент списка заносится с новой строки, то есть разделителем является конец строки. Тогда нужный элемент можно разыскать по номеру строки. Пример:
№ п/п Фамилия, Имя, Отчество
1 Аистов Александр Алексеевич
2 Бобров Борис Борисович
3 Воробьева Валентина Владиславовна
27 Сорокин Сергей Семенович
Разделителем может быть и какой-нибудь специальный символ. Нам хорошо известны разделители между словами – это пробелы. В русском и во многих европейских языках общепринятым разделителем предложений является точка. В рассмотренном нами классном журнале в качестве разделителя можно использовать любой символ, который не встречается в самих данных, например символ «*». Тогда наш список выглядел бы так:
Аистов Александр Алексеевич * Бобров Борис Борисович * Воробьева Валентина Владиславовна * … * Сорокин Сергей Семенович
В этом случае для розыска элемента с номером n
надо просмотреть список, начиная с самого начала и пересчитать встретившиеся разделители. Когда будет отсчитано n
-1 разделителей, начнется нужный элемент. Он закончится, когда будет встречен следующий разделитель.
Еще проще можно действовать, если все элементы списка имеет равную длину. В этом случае разделители в списке вообще не нужны. Для розыска элемента с номером n
надо просмотреть список с самого начала и отсчитать а
(n
-1) символов, где а
– длина одного элемента. Со следующего символа начнется нужный элемент. Его длина тоже равна а
, поэтому его конец определить нетрудно. Такие упрощенные списки, состоящие из элементов равной длины, называют векторами данных
. Работать с ними особенно удобно.
В линейных структурах элементы данных располагаются последовательно, друг за другом. Между соседними элементами данных существует отношение непосредственного предшествования. С каждым элементом данных непосредственно или косвенно сопоставляется его порядковый номер в наборе данных, определяющий его адрес, по которому в свою очередь элемент данных однозначно определяется (рис.1) [1, С.36].
Таким образом, линейные структуры данных (списки) – это упорядоченные структуры, в которых адрес элемента однозначно определяется его номером.
1.3 ТАБЛИЧНЫЕ СТРУКТУРЫ ДАННЫХ
С таблицами данных мы тоже хорошо знакомы, достаточно вспомнить таблицу умножения. Табличные структуры отличаются от списочных тем, что элементы данных определяются адресом ячейки,
который состоит не из одного параметра, как в списках, а из нескольких. Для таблицы умножения, например, адрес ячейки определяется номерами строки и столбца. Нужная ячейка находится на их пересечении, а элемент выбирается из ячейки.
При хранении табличных данных количество разделителей должно быть больше, чем для данных, имеющих структуру списка. Например, когда таблицы печатают в книгах, строки и столбцы разделяют графическими элементами – линиями вертикальной и горизонтальной разметки (рис.2).
| Планета
|
Расстояние до Солнца, а.е.
|
Относительная масса
|
Количество спутников
|
| Меркурий |
0,39 |
0,056 |
0 |
| Венера |
0,67 |
0,88 |
0 |
| Земля |
1,0 |
1,0 |
1 |
| Марс |
1,51 |
0,1 |
2 |
| Юпитер |
5,2 |
318 |
16 |
Рис.2.
В двумерных таблицах, которые печатают в книгах, применяется два типа разделений – вертикальные и горизонтальные
Если нужно сохранить таблицу в виде длинной символьной строки, используют один символ-разделитель между элементами, принадлежащими одной строке, и другой разделитель для отделения строк, например так:
Меркурий0,39*0,056*0#Венера*0,67*0,88*0#Земля*1,0*1,0*1#Марс*1,51*0,1*2#...
Для розыска элемента, имеющего адрес ячейки (m
,
n
), надо просмотреть набор данных с самого начала и пересчитать внешние разделители. Когда будет отсчитан m
-
1 разделитель, надо пересчитывать внутренние разделители. После того как будет найден n
-1 разделитель, начнется нужный элемент. Он закончится, когда будет встречен любой очередной разделитель.
Еще проще можно действовать, если все элементы таблицы имеют равную длину. Такие таблицы называют матрицами.
В данном случае разделители не нужны, поскольку все элементы имеют равную длину и количество их известно. Для розыска элемента с адресом (m
,
n
) в матрице, имеющей M
строк и N
столбцов, надо просмотреть ее с самого начала и отсчитать а
[N
(m
-
1)+(n
-1)] символ, где а –
длина одного элемента. Со следующего символа начнется нужный элемент. Его длина равна а,
поэтому его конец определить нетрудно.
Таким образом, табличные структуры данных (матрицы
) – это упорядоченные структуры, в которых адрес элемента определяется номером строки и номером столбца, на пересечении которых находится ячейка, содержащая искомый элемент
Мы рассмотрели пример таблицы, имеющей два измерения (строка и столбец), но нередко приходится иметь дело с таблицами, у которых количество измерений больше, т.е. с многомерными таблицами. Вот пример таблицы, с помощью которой может быть организован учет учащихся:
Номер факультета: 3
Номер курса (на факультете): 2
Номер специальности (на курсе): 2
Номер группы в потоке одной специальности: 1
Номер учащегося в группе: 19
Размерность такой таблицы равна пяти, и для однозначного отыскания данных об учащемся в подобной структуре надо знать все пять параметров (координат).
1.4 ИЕРАРХИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ
Нерегулярные данные, которые трудно представить в виде списка или таблицы, часто представляют в виде иерархических структур
. С подобными структурами мы знакомы по обыденной жизни. Иерархическую структуру имеет система почтовых адресов. Подобные структуры также широко применяются в научных систематизациях и всевозможных классификациях (рис.3).
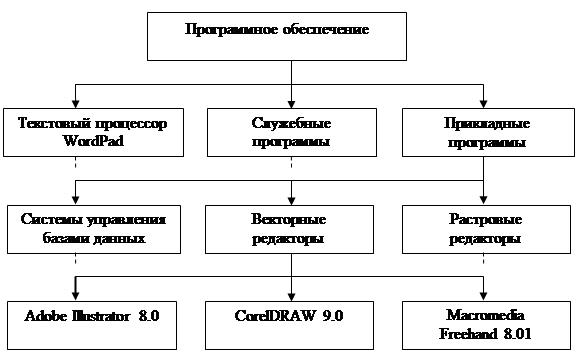
Рис.3.
Пример иерархической структуры данных
В иерархической структуре адрес каждого элемента определяется путем доступа (маршрутом), ведущим от вершины структуры к данному элементу
[3, С.30].Вот, например, как выглядит путь доступа к команде, запускающей программу Калькулятор (стандартная программа компьютеров, работающих в операционной системе Windows 98):
Пуск → Программы → Стандартные → Калькулятор.
Дихотомия данных.
Основным недостатком иерархических структур данных является увеличенный размер пути доступа. Очень часто бывает так, что длина маршрута оказывается больше, чем длина самих данных, к которым он ведет. Поэтому в информатике применяют методы для регуляризации иерархических структур с тем, чтобы сделать путь доступа компактным. Один из методов получил название дихотомии.
Его суть понятна из примера, представленного на рис.4.
| Текстовый процессор Word 2000 |
|
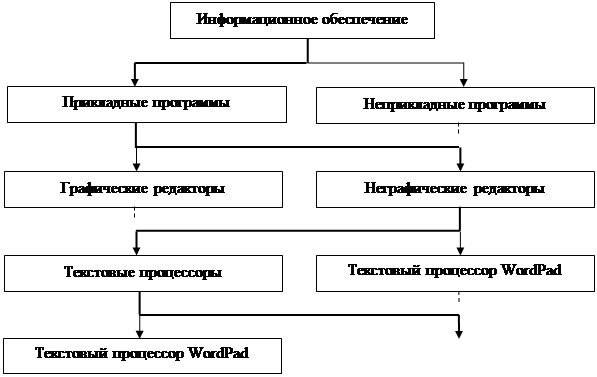 Рис.4
. Пример, поясняющий принцип действия метода дихотомии
В иерархической структуре, построенной методом дихотомии, путь доступа к любому элементу можно представить как путь через рациональный лабиринт с поворотами налево (0) или направо (1) и, таким образом, выразить путь доступа в виде компактной двоичной записи. В нашем примере путь доступа к текстовому процессору Word 2000 выразится следующим двоичным числом: 1010.
Списочные и табличные структуры являются простыми. Ими легко пользоваться, поскольку адрес каждого элемента задается числом (для списка), двумя числами (для двумерной таблицы) или несколькими числами для многомерной таблицы. Они также легко упорядочиваются. Основным методом упорядочения является сортировка.
Данные можно сортировать по любому избранному критерию, например: по алфавиту, по возрастанию порядкового номера или по возрастанию какого-либо параметра [3, С. 30-31].
Несмотря на многочисленные удобства, у простых структур данных есть и недостаток – их трудно обновлять. Если, например, перевести студента из одной группы в другую, изменения надо вносить сразу в два журнала посещаемости; при этом в обоих журналах будет нарушена списочная структура. Если переведенного студента вписать в конец списка группы, нарушится упорядочение по алфавиту, а если его вписать в соответствии с алфавитом, то изменятся порядковые номера всех студентов, которые следуют за ним.
Таким образом, при добавлении произвольного элемента в упорядоченную структуру списка может происходить изменение адресных данных у других элементов.
В журналах успеваемости это пережить нетрудно, но в системах, выполняющих автоматическую обработку данных, нужны специальные методы для решения этой проблемы.
Иерархические структуры данных по форме сложнее, чем линейные и табличные, но они не создают проблем с обновлением данных. Их легко развивать путем создания новых уровней. Даже если в учебном заведении будет создан новый факультет, это никак не отразится на пути доступа к сведениям об учащихся прочих факультетов.
Недостатком иерархических структур является относительная трудоемкость записи адреса элемента данных и сложность упорядочения. Часто методы упорядочения в таких структурах основывают на предварительной индексации,
которая заключается в том, что каждому элементу данных присваивается свой уникальный индекс, который можно использовать при поиске, сортировке и т.п. Ранее рассмотренный принцип дихотомии на самом деле является одним из методов индексации данных в иерархических структурах. После такой индексации, данные легко разыскиваются по двоичному коду связанного с ними индекса.
Адресные данные.
Если данные хранятся в организованной структуре (причем любой), то каждый элемент данных приобретает новое свойство (параметр), который можно назвать адресом. Конечно, работать с упорядоченными данными удобнее, но за это приходится платить их размножением, поскольку адреса элементов данных – это тоже данные, и их тоже надо хранить и обрабатывать.
1.6 РЕЖИМЫ ОБРАБОТКИ ДАННЫХ
Режим обработки данных
– способ выполнения заданий (задач), характеризующийся порядком распределения ресурсов системы между заданиями (задачами). Требуемый режим обработки данных обеспечивается управляющими программами операционной системы, которые выделяют заданиям оперативную и внешнюю память, устройства ввода–вывода, процессорное время и прочие ресурсы в соответствующем порядке с учетом атрибутов заданий – имен пользователей, приоритетов заданий, сложности задач и вычислений и др.
Порядок распределения ресурсов между заданиями влияет на время пребывания задания в системе, производительность системы, стоимость решения задач и другие характеристики системы и процессов обработки задач. Режим обработки данных связан с организацией процесса функционирования системы и отражается в первую очередь на характеристиках системы. Рассмотрим основные режимы обработки данных и их влияние на характеристики СОД.
Мультипрограммная обработка
. В общем случае процесс решения задачи сводится к последовательности этапов процессорной обработки, ввода и вывода данных и обращений к внешним запоминающим устройствам. При этом задача в каждый момент времени обрабатывается, как правило, одним устройством, а остальные не могут использоваться до завершения работы этого устройства, следовательно, могут распределяться для выполнения других задач. Режим обработки, при котором в системе одновременно обрабатывается несколько задач, называется мультипрограммной обработкой или мультипрограммированием. Цель мультипрограммирования – увеличение производительности системы.
Оперативная и пакетная обработка данных.
Применительно к СОД, предназначенным для информационного обслуживания пользователей (но не технических объектов и систем). Оперативная обработка данных характеризуется: 1) малым объемом вводимых – вводимых данных и вычислений, приходящимся на одно взаимодействие пользователя с системой (на одну задачу); 2) высокой интенсивностью взаимодействия и вытекающим отсюда требованием уменьшения времени ответа. Оперативная обработка необходима в системах банковских, резервирования билетов, справочных и т.д. Пакетная обработка данных характеризуется: 1) большим объемом вводимых – вводимых данных и вычислений, приходящимся на одно взаимодействие пользователя с системой (на одну задачу); 2) низкой интенсивностью взаимодействия и допустимостью большого времени ответа. Пакетная обработка типична для вычислительных центров научно-технического профиля, систем обработки учетно-статистических данных, результатов геофизических измерений и т.д.
В рамках оперативной обработки выделяют два режима: запрос-ответ и диалоговый. Режим запрос-ответ характеризуется меньшей интенсивностью и большей продолжительностью взаимодействия по сравнению с диалоговым режимом. Типичный пример использования режима запрос-ответ – справочная служба на основе ЭВМ. При этом пользователь формирует текст запроса, который вводится в ЭВМ, и ответ должен быть получен за несколько десятков секунд. Работа в диалоговом режиме предполагает практически мгновенный контакт пользователя с системой, при котором система реагирует на действия пользователя с задержкой в несколько секунд или доли секунды. Быстрота реакции системы на действия пользователя является непременным условием диалогового режима. Стоимость выполнения программы в диалоговом режиме больше, чем в пакетном, из-за немалых издержек, связанных с управлением процессами со стороны операционной системы.
Обработка в реальном масштабе времени
. В системах управления реальными объектами, построенных на основе ЭВМ, процесс управления сводится к решению фиксированного набора задач. Каждая задача инициируется либо периодически, либо при возникновении определенных ситуаций в системе. При этом темп инициирования задач и время получения результатов вычислений жестко регламентируются динамическими свойствами управляемого объекта: технологической установки, подвижного объекта и др. Это означает, что на время решения задач управления налагаются ограничения, определяющие предельно допустимое время ответа для задач соответственно. Режим, при котором организация обработки данных подчиняется темпу процессов вне СОД, называется обработкой в реальном масштабе времени (РМВ).
Режим телеобработки данных
. Телеобработка (удаленная обработка) – режим обработки данных при взаимодействии пользователей с СОД через линии связи. Телеобработка рассматривается в качестве самостоятельного режима обработки данных по следующим причинам. Во-первых, удаленность пользователей от СОД и наличие между ними специфического средства передачи данных – линии связи – порождает необходимость в специальных действиях пользователей при организации доступа к системе и завершении сеанса работы. Во-вторых, наличие линий связи налагает ограничения на форму и время обмена данными между пользователями и СОД. Эти ограничения приводят к необходимости специальных способов организации данных и доступа к ним, что в свою очередь отражается на структуре прикладных программ, используемых в режиме телеобработки. Режим телеобработки характеризуется, прежде всего, спецификой доступа пользователя к системе и системы к данным, передаваемым через удаленные терминалы, т.е. связан в первую очередь с организацией обработки данных внутри СОД. При этом пользователи могут работать в режимах пакетном, диалоговом или "запрос-ответ". Каждый из этих режимов характеризуется специфичным способом взаимодействия пользователей с системой и соответствующим временем ответа.
2.1 ОБЩАЯ ХАРАКТЕРИСТИКА ЗАДАЧИ
В бухгалтерии ООО "Снежок" производится расчет отчислений по каждому сотруднику предприятия:
· в федеральный бюджет:
· фонды обязательного медицинского страхования (ФФОМС – федеральный, ТФОМС – территориальный);
· фонд социального страхования (ФСС).
Процентные ставки отчислений приведены. Данные для расчета отчислений в фонды по каждому сотруднику приведены.
1. Построить таблицы по приведенным данным.
2. Выполнить расчет размеров отчислений с заработной платы по каждому сотруднику предприятия, данные расчета занести в таблицу.
3. Организовать межтабличные связи для автоматического формирования ведомости расчета ЕСН (единого социального налога
) по предприятию.
4. Сформировать и заполнить ведомость расчета ЕСН.
5. Результаты расчета ЕСН по каждому сотруднику за текущий месяц представить в графическом виде.
1. На рабочем листе Ставки ЕСН
MSExcel создать таблицу ставок ЕСН по исходным данным (рис. 1).
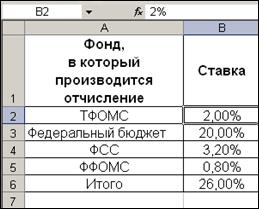
Рис. 1
. Процентные ставки отчислений
2. Разработать структуру шаблона таблицы "Данные по сотруднику"
(рис. 2.).

Рис. 2.
Структура шаблона таблицы "Данные по сотруднику"
3. На рабочем листе Данные по сотруднику
MSExcel создать таблицу данных по каждому сотруднику по исходным данным.
4. Выполнить расчет размеров отчислений с заработной платы по каждому сотруднику предприятия (рис. 3).
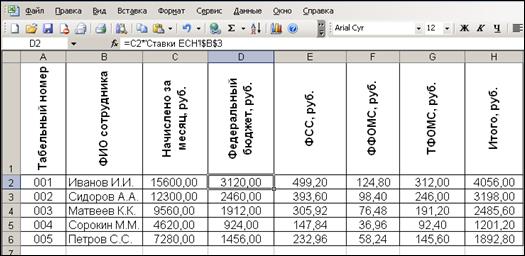
Рис. 3.
Расчет размеров отчислений ЕСН за текущий месяц по каждому сотруднику
5. На рабочем листе Ведомость расчета ЕСН
MSExcel создать таблицу ведомости.
6. Путем создания межтабличных связей заполнить ведомость полученными данными из таблицы "Данные по сотруднику
" (рис. 4).
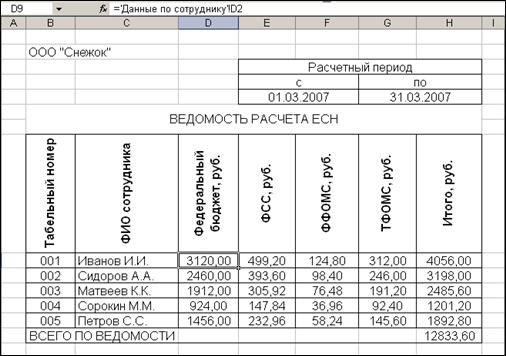
Рис. 4.
Ведомость расчета ЕСН
7. На рабочем листе График
MSExcel создать сводную диаграмму (со сводной таблицей) расчетов ЕСН по каждому сотруднику за текущий месяц (рис. 5).
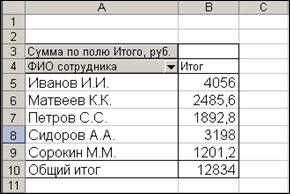
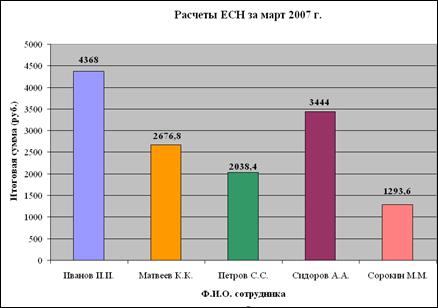
Рис. 5.
Сводная таблица и графическое представление результатов вычислений
Большинство задач, решаемых в финансово-экономической сфере, связано с обработкой больших объемов информации, интеграцией данных разных форм и документов, использованием графической интерпретации данных в виде диаграмм и графиков, необходимостью группировки и сортировки данных по разным показателям, проведением анализа данных для дальнейшего принятия решения, а также выводом на печать большого количества отчетных форм. В работе бухгалтера чаще всего используются данные в форме таблицы.
В MSOffice средством для создания электронных таблиц является табличный процессор Excel, также популярными являются электронные таблицы QuattroPro фирмы Novell и Lotus 1-2-3 фирмы LotusDevelopment. Все они работают в среде Windows и выполняют принципиально одни и те же функции с некоторыми различиями в их реализации.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
Книга одного и более авторов:
1. Информатика: Учебник / Под общ. ред. А.Н. Данчула. – М.: Изд-во РАГС, 2004.
2. Экономическая информатика: Учебник / Под ред. В.П. Косарева. – 2-е изд., перераб. и доп. – М.: Финансы и статистика, 2005. – 592 с.
3. Информатика: Базовый курс / С.В. Симонович и др. – СПб.: Питер, 2003.
Публикации в сети Интернет:
4. http://www.mkgt.ru
5. http://www.lcard.ru
6. http://256bit.ru/education/infor1/lecture1-4.htm.
|
