|
1. Исходные данные на проектирование:
На склад привозят товар из разных организаций и увозят в разные организации. Движение товаров сопровождается накладной и доверенностью. Накладную выписывает сторона, отдающая товар, доверенность - принимающая товар. Одна накладная и доверенность может сопровождать несколько товаров. В накладной указывается:
- номер, дата, организация поставщик, организация получатель, а также следующая информация о каждом товаре:
- наименование товара,
- кол-во,
- цена,
- стоимость.
В доверенности указывается: номер, дата, организация поставщик, организация получатель, номер платежного поручения, Ф.И.О. принимающего лица, номер накладной.
Выполняемые функции:
-учет движения товара
-возможность выборки по критериям
-информация об остатках на складе
Создание отчетов разнообразных отчетов, таких как:
- сколько товара и на какую сумму прибыло из определенной организации за определенный промежуток времени.
- сколько товара и на какую сумму куплено за определенный промежуток времени и кто ее получил.
- сколько товара и на какую сумму находилось на складе в определенный день.
Общие требования:
1. Разработать структуру базы данных.
2. Привести структуру базы к третьей нормальной форме.
3. Разработать программу ввода и коррекции информации (Access, MS SQL Server) включая проверку целостность и непротиворечивости базы данных.
Технические средства - ПЭВМ типа IBM PC.
Операционная система - MS Windows.
СУБД и инструментальные программные средства - по выбору разработчика.
Определение модели данных предусматривает указание множества допустимых информационных конструкций, множества допустимых операций над данными и множества ограничений для хранимых значений данных.
Модель данных, с одной стороны, представляет собой формальный аппарат для описания информационных потребностей пользователей, а с другой - большинство СУБД ориентируются на конкретную модель данных, и, таким образом, если информационные потребности удается точно выразить средствами одной из моделей данных, то соответствующая СУБД позволяет относительно быстро создать работоспособный фрагмент ИС.
Информационные конструкции, операции и ограничения моделей данных выбираются из достаточно небольшого множества вариантов, характеризующего "крупные" информационные объекты и операции. В частности, не допускается рассмотрение отдельных символов данных, операций сложения атрибутов, ограничения на соответствие типов данных и т. п., что характерно для языков программирования.
Реклама

Информационные объекты послужили основой для объектно-ориентированного проектирования систем, когда фиксируется множество информационных объектов и действий над объектами. Типичный список действий включает в себя создание/уничтожение объекта, редактирование объекта, фиксацию одного объекта в качестве части другого объекта, связывание объектов, синхронизацию действий над объектами.
Довольно-таки часто все названные объекты встраиваются в структуру отношений, которые можно считать простейшими универсальными объектами.
Количество существенно различающихся моделей данных определяется наличием различных множеств информационных конструкций.
Хранимые в базе данные имеют определенную логическую структуру, то есть, представлены некоторой моделью, поддерживаемой СУБД. К числу важнейших относятся следующие модели данных
:
1. инфологическая;
2. иерархическая;
3. сетевая;
4. реляционная;
5. объектно-ориентированная.
Инфологическая модель занимает особое положение по отношению к другим моделям. Она соответствует четвертому этапу построения сложной системы и дает формализованное описание проблемной области независимо от структур данных. Инфологическая область моделирования данных охватывает естественные для человека концепции отображения реального мира.
Создание этой модели является первым шагом процесса формализации. В отличие от представления на естественном языке она в основном исключает неоднозначность за счет использования средств формальной логики.
Одно из главных понятий инфологической модели - объект. Это понятие связано с событиями: возникновение, исчезновение и изменение.
Объекты
могут быть атомарными или составными.
Атомарный объект
- это объект определенного типа, дальнейшее разложение которого на более мелкие объекты внутри данного типа невозможно.
Составные объекты
включают в себя множества объектов, кортежи объектов. Применяя это определение, рекурсивно можно получить произвольную структуру составных объектов.
Обычно объект имеет некоторое свойство или взаимосвязь (связь) с другими объектами. Свойство может быть не определено формально, а лишь охарактеризовано как некоторое утверждение по поводу множества объектов.
Реклама

Инфологическая модель позволяет выделить три категории фактов: истинные, значимые и ложные.
С одной стороны, это обеспечивает модели дополнительную гибкость, с другой - создает определенные сложности.
Различия между традиционными и инфологическими моделями данных аналогичны различию между мнением и истиной. Во многих моделях большинство сообщений относится к одной из двух категорий: истина или ложь. Инфологическая модель предполагает возможность представления любого сообщения с какой-то долей вероятности, т.е. в виде аналога мнения. Анализ такого сообщения возможен при учете конкретного контекста. В правильном контексте сообщение истинно. Но и ошибочное утверждение может рассматриваться как мнение.
Цель инфологического моделирования
- формализация объектов реального мира предметной области и методов обработки информации в соответствии с поставленными задачами обработки и требованиями представления данных естественными для человека способами сбора и представления информации.
Инфологические модели позволяют получать произвольные представления простых событий. На их основе могут быть сконструированы также типы моделей, подобные поддерживаемым сильно типизированными моделями.
В таких моделях ссылки на объекты и сами объекты разделены, а сообщения интерпретируются с учетом контекста. Это позволяет реализовать множественность ссылок и обеспечить разнообразие интерпретации.
Инфологическая модель может включать в себя ряд компонентов. Принципиальной особенностью этой модели является возможность отображения как формализуемых средствами формальной логики процессов и объектов, так и не формализуемых в дальнейшем процессов.
Основными компонентами инфологической модели являются:
• описание предметной области;
• описание методов обработки;
• описание информационных потребностей пользователя. Инфологическая модель носит описательный характер. В силу некоторой произвольности форм описания в настоящее время не существует общепринятых способов ее построения. Используют аналитические методы, методы графического описания, системный подход.
Приложение “Склад ” предназначено для автоматизации деятельности торговых предприятий. С помощью программы ведется учет товаров на складе, удобной работы с предложениями фирм-поставщиков, ведения работы с входящими/исходящими документами. Кроме того, работа с этой программой должна вестись без всякого напряжения со стороны пользователя.
Программа "Склад" предназначена для облегчения учета движения товаров. Наиболее рутинными и в то же время наиболее ответственными процессами являются:
· ввод приходных документов с указанием поступивших товаров.
· Выписывание расходных документов.
· подготовка различных отчетов по движению товаров.
По перечню функций видно, что с помощью программы работа существенно упрощается.
Кроме того, появляется возможность быстро ориентироваться в огромной массе коммерческих предложений, анализировать спрос на те или иные виды товаров. Достоинства применения очевидны.

Вся информация для хранения в базе данных разбита на сущности и атрибуты по специфическим признакам. Каждая сущность представляет собой таблицу базы данных. Анализ описанной предметной области и решаемых задач позволяет выделить следующие сущности:
| № п/п
|
тип сущности
|
атрибуты
|
| 1.
|
Движение товара
|
Код операции; Наименование товара; Приход; Расход; Цена; Примечание
|
| 2.
|
Получатели
|
Код получателя; Название фирмы; Адрес; Примечание
|
| 3.
|
Поставщики
|
Код поставщика; Название фирмы; Адрес; Примечание
|
| 4.
|
Приход
|
Код операции; Номер накладной; Дата привоза; Поставщик; Получатель; Примечание
|
| 5.
|
Расход
|
Код операции; Получатель; Номер доверенности; Номер накладной; Дата получения; Номер платежного документа; ФИО получателя; Примечание
|
| 6.
|
Справочник товаров
|
Код товара; Название товара; Ед.изм.; Примечание
|
5. Физическое проектирование
До физического создания БД необходимо провести датологическое проектирование, т.е. построить логическую структуру БД, установить связи, нормализовать отношения.
При наличии хорошо документированной логической структуры физическая реализация базы данных представляет собой четко определенный, стандартизованный процесс; кроме того, обеспечивается надежное, эффективное хранение и поиск данных.
Вся информация базы данных хранится в виде таблиц, такая БД носит название
реляционной БД.
Реляционная база данных – это совокупность отношений, содержащих всю информацию, которая должна храниться в БД. Однако пользователи могут воспринимать такую базу данных как совокупность таблиц.
1. Каждая таблица состоит из однотипных строк и имеет уникальное имя.
2. Строки имеют фиксированное число полей (столбцов) и значений (множественные поля и повторяющиеся группы недопустимы). Иначе говоря, в каждой позиции таблицы на пересечении строки и столбца всегда имеется в точности одно значение или ничего.
3. Строки таблицы обязательно отличаются друг от друга хотя бы единственным значением, что позволяет однозначно идентифицировать любую строку такой таблицы.
4. Столбцам таблицы однозначно присваиваются имена, и в каждом из них размещаются однородные значения данных (даты, фамилии, целые числа или денежные суммы).
5. Полное информационное содержание базы данных представляется в виде явных значений данных, и такой метод представления является единственным. В частности, не существует каких-либо специальных "связей" или указателей, соединяющих одну таблицу с другой.
6. При выполнении операций с таблицей ее строки и столбцы можно обрабатывать в любом порядке безотносительно к их информационному содержанию. Этому способствует наличие имен таблиц и их столбцов, а также возможность выделения любой их строки или любого набора строк с указанными признаками.
Логическая структура базы данных определяет:
• таблицы и их имена, также называемые сущностями
(entities);
• имена полей, также называемые атрибутами
(attributes) каждой таблицы;
• характеристики полей, например уникальность их значения и допустимость значений NULL, а также тип данных, хранимых в поле;
• первичный ключ каждой таблицы — поле (несколько полей) со значениями, уникально идентифицирующими каждую запись в таблице. В таблице также могут существовать другие уникальные поля, но только одно из них рассматривается как уникальный ключ доступа для поиска записей — первичный ключ. В таблице не обязательно должен существовать первичный ключ, однако рекомендуется определять его для каждой таблицы;
• связи между таблицами. Записи в таблице могут зависеть от одной или нескольких записей другой таблицы. Такие отношения между таблицами называются связями.
Связь определяется следующим образом: поле или несколько полей одной таблицы, называемое внешним ключом,
ссылается на первичный ключ другой таблицы.
Существует три типа связей между таблицами:
один к одному —
каждая запись родительской таблицы связана только с одной записью дочерней. Такая связь реализуется путем определения уникального внешнего ключа;
один ко многим —
каждая запись родительской таблицы связана с одной или несколькими записями дочерней. Например, один клиент может сделать несколько заказов, однако несколько клиентов не могут сделать один заказ.
многие ко многим —
несколько записей одной таблицы связаны с несколькими записями другой. Например, один автор может написать несколько книг и несколько авторов — одну книгу. Подобная связь между двумя таблицами реализуется путем создания третьей таблицы и реализации связи типа «один ко многим» каждой из имеющихся таблиц с промежуточной таблицей.
Нормализация
– это разбиение таблицы на две или более, обладающих лучшими свойствами при включении, изменении и удалении данных. Окончательная цель нормализации сводится к получению такого проекта базы данных, в котором каждый факт появляется лишь в одном месте
, т.е. исключена избыточность информации. Это делается не столько с целью экономии памяти, сколько для исключения возможной противоречивости хранимых данных.
Как указывалось ранее, каждая таблица в реляционной БД удовлетворяет условию, в соответствии с которым в позиции на пересечении каждой строки и столбца таблицы всегда находится единственное атомарное значение, и никогда не может быть множества таких значений. Любая таблица, удовлетворяющая этому условию, называется нормализованной
. Фактически, ненормализованные таблицы, т.е. таблицы, содержащие повторяющиеся группы, даже не допускаются в реляционной БД.
Всякая нормализованная таблица автоматически считается таблицей в первой нормальной форме
, сокращенно 1НФ
. Таким образом, строго говоря, "нормализованная" и "находящаяся в 1НФ" означают одно и то же. Однако на практике термин "нормализованная" часто используется в более узком смысле – "полностью нормализованная", который означает, что в проекте не нарушаются никакие принципы нормализации. Дадим точные определения наиболее распространенных форм нормализации.
Таблица находится в первой нормальной форме
(1НФ
) тогда и только тогда, когда ни одна из ее строк не содержит в любом своем поле более одного значения и ни одно из ее ключевых полей не пусто
Таблица находится во второй нормальной форме
(2НФ
), если она удовлетворяет определению 1НФ и все ее поля, не входящие в первичный ключ, связаны полной функциональной зависимостью с первичным ключом.
Таблица находится в третьей нормальной форме
(3НФ
), если она удовлетворяет определению 2НФ и не одно из ее неключевых полей не зависит функционально от любого другого неключевого поля.
Таким образом, каждая нормальная форма является в некотором смысле более ограниченной, но и более желательной
, чем предшествующая. Это связано с тем, что "(N+1)-я нормальная форма" не обладает некоторыми непривлекательными особенностями, свойственным "N-й нормальной форме". Общий смысл дополнительного условия, налагаемого на (N+1)-ю нормальную форму по отношению к N-й нормальной форме, состоит в исключении этих непривлекательных особенностей.
Теория нормализации основывается на наличии той или иной зависимости между полями таблицы. Определены два вида таких зависимостей: функциональные и многозначные.
Функциональная зависимость
. Поле В таблицы функционально зависит от поля А той же таблицы в том и только в том случае, когда в любой заданный момент времени для каждого из различных значений поля А обязательно существует только одно из различных значений поля В. Отметим, что здесь допускается, что поля А и В могут быть составными.
Полная функциональная зависимость
. Поле В находится в полной функциональной зависимости от составного поля А, если оно функционально зависит от А и не зависит функционально от любого подмножества поля А.
Многозначная зависимость
. Поле А многозначно определяет поле В той же таблицы, если для каждого значения поля А существует хорошо определенное множество соответствующих значений В.






Вот основные преимущества нормализации:
облегчается сортировка и создание индекса, поскольку таблицы стали более компактными;
создается большее число кластерных индексов, поскольку таблиц стало больше;
индексы становятся более компактными;
меньшее число индексов в одной таблице позволяет быстрее выполнять обновления записей;
в таблицах содержится меньше значений NULL и избыточных данных, что повышает компактность базы данных;
уменьшается вероятность конфликтов блокировок таблиц,
поскольку блокировать приходится ограниченные наборы данных.
Сложные реляционные соединения, обычно присутствующие в нормализованной базе данных, могут понизить производительность. В качестве примера рассмотрим получение отчета из базы данных регистрации студентов, в котором перечислены аудитории, где читается тот или иной курс. При создании отчета Вам потребуется извлекать имя студента из таблицы Students
,
коды посещаемых студентом курсов (
CourseID
) —
из таблицы Registrations
,
код читающего курс лектора (
LecturerID
) —
из таблицы Courses
и номер аудитории (
Room
),
где читается курс, — из таблицы Lecturers
.
По правилам нормализации, номер аудитории не должен являться значением поля таблицы Courses
.
В противном случае возможна ситуация, когда данные не будут согласованными. Тем не менее здесь допустимо добавить поле Room
в таблицу Courses
,
чтобы не обращаться к таблице Lecturers
для поиска номера аудитории.
Этот случай — типичный пример денормализации —
процесса намеренного создания ненормализованной таблицы для повышения производительности и упрощения запросов. Денормализация приемлема, когда при ее применении Вы получаете определенные преимущества. При этом, однако, для обеспечения целостности данных следует предпринять дополнительные меры. В дальнейшем мы рассмотрим использование триггеров для обеспечения целостности данных денормализованных таблиц.
| №п/п
|
Статьи затрат
|
Затраты, руб.
|
| 1
|
Основная заработная плата разработчиков
|
З осн.
|
| 2
|
Дополнительная заработная плата
|
Здоп. = 0,25 * Зосн.
|
| 3
|
Отчисления на социальное страхование. Зсоц
|
(Зосн+Здоп)*40.5%.
|
| 4
|
Амортизационные отчисления Зам
|
Зам.=Сперв.*(На/100)*Т*фаб/Фд.о.) Сперв.- первоначальная стоимость ЭВМ.
На - норма амортизационных отчислений обычно 12,5%
Т - количество используемых ЭВМ;
фаб. - время работы ЭВМ в часах;
Фд.о. - действительный годовой фонд времени работы ЭВМ. Примем: Фд.о. = Кол.раб.дн. * Кол.смен * Продолж.смены = 252 дня* 1 смена* 8 ч. =
2016 ч.
|
| 5
|
Расходы на электроэнергию
|
Зэл.эн.=Цэ.*Р*Т*фаб ,где: Р - мощность ЭВМ, используемой при разработке программы;
Цэ. - цена 1 кВт* ч электроэнергии
|
| 6
|
Накладные расходы
|
Рнакл.=Кн * (Зосн.+Здоп) где:
Кн - коэффициент накладных расходов. Примем Кн равным 1.1.
|
| 7
|
Итого:
|
Зосн+Здоп+Зсоц+Зам+Зэл.эн+Рнакл
|
Определим экономическую эффективность с помощью трудовых и стоимостных показателей.
На ручную обработку до внедрения ИС затрачивалось Т0
чел./ч . При использовании ИС Т1
чел./ч . Абсолютный показатель экономической эффективности Тэк
составляет:
Тэк
= Т0
- Т1
(2.1)
Относительный индекс производительности труда вычисляется по формуле:
J п.т.
= Т1
/Т0
(2.2)
И отражает экономия трудовых затрат.
Рассчитаем стоимостной показатель по формуле 2.3.
Сэк
= С0
- С1
(2.3) , где
С0 –
затраты до внедрения ИС. С1
Затраты после внедрения ИС.
Индес стоимости затрат определяется по формуле 2.4
J ст.затр..
= С1
/С0
(2.4)
Срок окупаемости затрат вычисляется по формуле 2.5
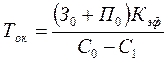 , где (2.5) , где (2.5)
З0
– затраты на техническое оборудование;
П0
– затраты на программное обеспечение; Кэф
– коэффициент эффективности. Подставим имеющиеся данные в формулу 2.5, получим время окупаемости затрат.
З осн=12 000руб. З доп=0.25*12 000 = 3000
З соц=(12000+3000)*40.5%=6075
З ам=(20000*(12,5%/100)*1*1000)/2016=12,4
З эл.=1,5*0,450*1*1000=675
Р накл=1,1*(12000+3000)=16500
Итого=12000+3000+6075+12,4+675+16500=38262,4
Тэк=12-7=5 Jпт=7/12=0,58
Сэк=6000-3000=3000
Jзт.затр=3000/5000=0,6
Ток=((20000+5000)*0,6)/3000=5мес.
1. Антипов Д. В.,Соколов А. В. «Базы данных». Москва, 2000.
2. Верман А. Я. «Access 97 для профессионалов». СПб, 2002
3. Вейскас Д. «Эффективная работа с Access 2000». СПб., 2001
4. Дуванов А. А. «Конструирование баз данных». СПб, 2003
|
