Министерство образования РФ
Южный Федеральный университет
Факультет математики, механики и компьютерных наук
Кафедра Исследования операций
Курсовая работа на тему:
«Решение задачи распределения капиталовложений»
Выполнил студент 4к 6гр
Семенюк Игорь
Научный руководитель:
Землянухина Л.Д.
Ростов-на-Дону, 2010г
Содержание
1. Введение……………………………………………………………………………3
2. DCP-модель задачи распределения капиталовложений………………………...5
3. Алгоритм решения задачи………………………………………………………...7
4. Реализация алгоритма ……………………………………………………………..10
5. Пример……………………………………………………………………………....12
6. Литература…………………………………………………………………………..13
7. Приложение…………………………………………………………………………14
Введение
В реальных системах принятия решений, действующих в сложной стохастической обстановке, приходится иметь дело с многочисленными событиями. В ряде случаев лицу, принимающему решение, требуется максимизировать вероятностные функции этих событий. Для моделирования стохастических систем принятия решений такого типа предложено новое направление в стохастическом программировании, получившее наименование «стохастическое событийное программирование» (depended-chanceprogramming - DCP). Основная идея данного направления состоит в выборе решения с максимальной вероятностью наступления требуемого события.
Теория событийного программирования отказывается от понятия «допустимое множество» и заменяет его понятием «неопределенная среда». Упрощенно говоря, DCP-модель связана с максимизацией функции шансов событий в неопределенной среде. Детерминированная модель, модель ожидаемых значений и модель программирования с ограничениями на шансы существенно основываются на предположении о том, что допустимая область после завершения моделирования становится детерминированной, т.е. в этих моделях неопределенность связана с тем, что заранее неизвестно, какие значения примут неопределенные функции, входящие в описание области допустимых решений. После того, как в ходе имитационного моделирования получены реализации этих функций, данная неопределенность устраняется и область допустимых решений становится детерминированной. Это значит, что оптимальное решение предполагается существующим независимого от того, может ли оно быть практически реализовано. Может оказаться так, однако, что решения реализовать невозможно, поскольку требуемое значение неопределенного параметра по каким-либо причинам является неблагоприятным. В силу этого в теории событийного программирования нигде не используется предположение о детерминированности допустимого множества решений, взамен введено понятие неопределенной среды. Эта специфическая особенность событийного программирования значительно отличает его от других направлений стохастического программирования. Реальный мир дает достаточное число примеров задач, отвечающих идее событийного программирования.
Реклама

Для решения задач, описываемых DCP-моделями, формируется разновидность гибридного алгоритма, объединяющего средства статического моделирования с нейронной сетью и генетическим алгоритмом.
Поскольку сложная система принятия решений обычно имеет дело с многочисленными событиями, будет иметь место, несомненно, и случай нескольких потенциально возможных целевых функций (некоторые из них будут вероятностными функциями), вовлеченных в процесс решения. Типичную формулировку задачи многокритериального событийного программирования, можно представить как задачу максимизации нескольких вероятностных функций с учетом неопределенной среды:
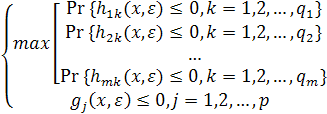
Из принципа неопределенности следует, что можно построить зависимость между векторами решений и вероятностными функциями событий, вычисляя вероятностные функции с помощью метода статистического моделирования или традиционными методами. Если лицом, принимающим решения, задана полная информация о функции предпочтения, то теперь можно решать многокритериальную событийную задачу, используя методы теории полезности. При отсутствии такой информации производится поиск всех эффективных решений. На практике лицо, принимающее решения, может дать только частичную информацию. В этом случае следует применять интерактивные методы.
Целевое событийное программирование может рассматриваться как расширение целевого программирования в сложных стохастических системах принятия решений. Когда заданы некоторые назначаемые цели, целевая функция может минимизировать положительное или отрицательное отклонение от цели или и то и другое вместе с определенной структурой приоритетов, заданных лицом, принимающим решения. Тогда можно сформулировать стохастическую систему принятия решений как следующую целевую DCP-модель:
Реклама

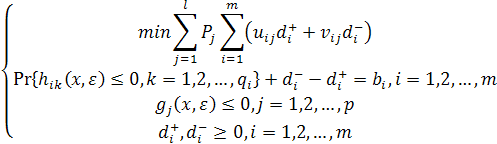
где Pj
– коэффициент преимущественного приоритета, 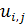 – весовой коэффициент, соответствующий положительному отклонению от i-ой цели с присвоенной ему j-ым приоритетом, – весовой коэффициент, соответствующий положительному отклонению от i-ой цели с присвоенной ему j-ым приоритетом, 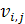 – весовой коэффициент, соответствующий отрицательному отклонению. – весовой коэффициент, соответствующий отрицательному отклонению. 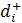 - положительное отклонение от назначенного уровня i-ой цели, - положительное отклонение от назначенного уровня i-ой цели, 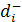 - отрицательное отклонение, - отрицательное отклонение, 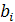 – назначенный уровень i-ой цели, l – число приоритетов и m – число целевых ограничений. – назначенный уровень i-ой цели, l – число приоритетов и m – число целевых ограничений.
В данной работе мной рассмотрена одна из задач целевого событийного программирования, построен алгоритм для решения и программная реализация.
DCP
-модель задачи распределения капиталовложений
Предположим, что имеется n типов машин, производящих n различных видов продукции. Случайные величины, соответствующие производственным мощностям этих n типов машин, предполагаются распределенными по логнормальному закону. Принимается так же, что спрос на указанные n видов продукции, представлен в виде случайных величин, распределенных по экспоненциальному закону.
Уровни затрат, необходимые для приобретения машин i-ого типа, составляют 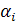 , а суммарный объем средств, выделяемый для покупки машин, равен α. Кроме того, площади, требуемые для размещения машин i-ого типа, принимаются равными , а общая доступная площадь составляет b. , а суммарный объем средств, выделяемый для покупки машин, равен α. Кроме того, площади, требуемые для размещения машин i-ого типа, принимаются равными , а общая доступная площадь составляет b.
Установим следующие целевые уровни и структуру приоритетов для задачи распределения капиталовложений. Вначале зададим ограничение на предельную величину площади , доступной для размещения оборудования:
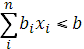
Затем ограничение на предельную стоимость закупки:
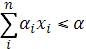
В соответствии с первым уровнем приоритета, уровень вероятности удовлетворения потребности ε1 должен достигать p1, т.е.
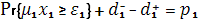
где 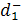 должно быть минимизированно. должно быть минимизированно.
Согласно второму уровню приоритета, вероятность удовлетворения потребности ε2 должна достигать p2, т.е.
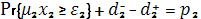
где 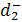 должно быть минимизированно. должно быть минимизированно.
И так далее. В общем виде мы можем записать это так:
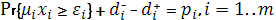
Где m это количество ограничений задачи, а уровень приоритета удовлетворения ограничений уменьшается с ростом i.
В соответствии с приведенной выше структурой приоритетов и целевыми уровнями можно сформулировать следующую целевую DCP – модель:
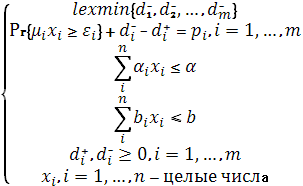
Алгоритм решения
Для решения задач, основанных на DCP-моделях имеем гибридный алгоритм, основанный на объединении средств статического моделирования и генетического алгоритма.
1. Сформировать обучающий набор вход-выходных данных с помощью статистического моделирования для неопределенных функций вида:
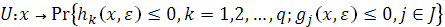
Для этого:
· положить 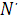 =0; =0;
· получить u в соответствии с функцией распределения;
· если 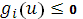 для i=1,..,m тогда увеличить на единицу; для i=1,..,m тогда увеличить на единицу;
· повторить второй и третий шаги N раз
· вычислить и выдать результат: 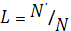
2. Инициализировать pop_size хромосом для генетического алгоритма с помощью статического моделирования (пункт 1):
Для этого потребуется определить размер популяции (от 10 до 100 в зависимости от сложности задачи). Здесь в качестве хромосомы принимается вектор решений исходной задачи. Затем случайным образом генерировать хромосомы так, чтобы они удовлетворяли условиям нашей задачи (ограничениям на площадь и затраты).
3. Модифицировать хромосомы с помощью операций кроссинговера и мутации.
Это выглядит следующим образом:
Модификация кроссинговером:
· Определяем параметр 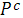 как вероятность этой модификации; как вероятность этой модификации;
· Выявить родительские хромосомы. Для этого формируем случайное число r из (0,1), и если 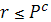 , то данная хромосома выбирается как родительская. Процедуру повторяем pop_size раз для каждой хромосомы; , то данная хромосома выбирается как родительская. Процедуру повторяем pop_size раз для каждой хромосомы;
· В итоге имеем m родительских хромосом, если m нечетное, то m=m-1. И разбиваем их на пары: 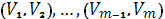 ; ;
· Затем для каждой пары формируется случайное число с из (0,1), и оператор кроссинговера действует следующим образом на родительскую пару: 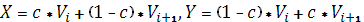 , где X и Y – потомки, которые заменят своих родителей, если будут удовлетворять условиям задачи (если допустимое множество выпуклое, то это будет выполнено однозначно) , где X и Y – потомки, которые заменят своих родителей, если будут удовлетворять условиям задачи (если допустимое множество выпуклое, то это будет выполнено однозначно)
Модификация мутацией:
· Определяем параметр  как вероятность этой модификации; как вероятность этой модификации;
· Как и в процессе отбора родительских хромосом для кроссинговера, выбираем родителей для мутации;
· Мутация производится следующим образом: пусть M – некоторое положительное число, выбираем направление мутации 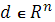 случайным образом. Далее модифицируем хромосому случайным образом. Далее модифицируем хромосому 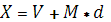 , где X – потомок. Если он удовлетворяет условию задачи, тогда проводится замена предка потомком, если же нет, то M выбирается случайным образом из (0,M), и операция повторяется, пока не будет достигнута допустимость , где X – потомок. Если он удовлетворяет условию задачи, тогда проводится замена предка потомком, если же нет, то M выбирается случайным образом из (0,M), и операция повторяется, пока не будет достигнута допустимость
4. Вычислить целевые функции для всех хромосом с помощью статистического моделирования. Т.е зная нашу популяцию хромосом (вектор решений) мы можем вычислить значение каждого из отрицательных отклонений в нашем условии и проверить на допустимость ограничений.
5. Вычислить значения функции приспособленности для каждой хромосомы в соответствии со значениями целевых функций:
· Для этого мы должны расположить хромосомы начиная с наилучшей, зная значение lexmin(отрицательных отклонений), полученное на предыдущем шаге.
· Приспособленность каждой хромосомы вычисляется с помощью функции оценки, основанной на ранжировании;
· Каждой хромосоме ставим в соответствии значение функции:
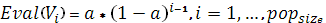
6. Произвести селекцию хромосом, использую случайный выбор:
· Вычислить кумулятивную вероятность 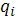 для каждой хромосомы для каждой хромосомы 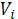 : :
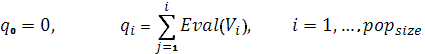
· Сформировать случайное число r в интервале 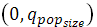
· Выбрать i-ую хромосому 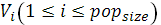 так, чтобы так, чтобы 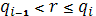
· Повторить 2 и 3 шаги pop_size раз и получить pop_size экземпляров хромосом
7. Повторить шаги с 3 по 6 для заданного числа циклов.
8. Выбрать наилучшую хромосому как оптимальное решение.
Реализация алгоритма
Статистическое моделирование
1. Repeat //Внешний цикл
2. for i:=1 to n do
3. x[i]:=round(random); //Заполнение вектора решений
4. ifodz(x) then //Если удовлетворяет условию, то
5. fori:=1 tomdo //m-количество вероятностных ограничений
6. N1:=0;
7. for k:=1 to max_st_m do //max_st_m – количество цикловстат.модел.
8. if LogN(a,b)*x>=Expa(c) then N1:=N1+1; //a,b,c-коэф. распределения
9. Pr[i]:=N1/max_st_m; //Вычисления значения вероятности
10. until odz(x); //пока вектор решений не удовлетворит одз
Инициализация
хромосом
1. i:=1;
2. whilei<=pop_sizedo //пока не достигнут размер популяции
3. stat_model(x,Pr); //статистическое моделирование
4. hr[i]:=x; //присвоение хромосоме удачный результат
5. inc(i);
Процесс кроссинговера
1. j:=0;
2. fori:=1 topop_sizedo //цикл для выбора родительских хромосом
3. r:=random;
4. if r<=Pc then //Pc – коэфициент модификации
5. inc(j);
6. parent[j]:=hr[i]; //родитель найден
7. pos[j]:=i; //позиция родителя в популяции
8. if j-нечетное then j:=j-1;
9. i:=1;
10. While i<j do //циклкроссинговера
11. c:=random;
12. for k:=1 to n do
13. hr[pos[i],k]:=round(c*parent[i,k]+(1-c)*parent[i+1,k]); //модификация
14. hr[pos[i+1],k]:=round((1-c)*parent[i,k]+c*parent[i+1,k]); //модификация
15. i:=i+2;
Процесс мутации
1. j:=0;
2. for i:=1 to pop_size do //цикл выбора родительских хромосом
3. r:=random;
4. ifr<=Pmthen //Pm – коэффициент модификации
5. inc(j);
6. parent[j]:=hr[i]; //родитель найден
7. pos[j]:=i; //номер родителя в популйции
8. i:=1;
9. l:=0; //счетчик для выхода при плохом направлении
10. While i<=j do //циклмутации
11. inc(l);
12. for k:=1 to n do
13. c[k]:=random*power(-1,random); //формирование случайного направления
14. M:=random; //количество шагов в направлении
15. for k:=1 to n do parent[i,k]:=round(parent[i,k]+M*c[k]); //модификация
16. if odz(parent[i]) then //если новая хромосома удовлетворяет одз
17. hr[pos[i]]:=parent[i]; //она заменяет родителя
18. inc(i);
19. l:=0;
20. Else //если же нет, то
21. M:=random(M); // новое количество шагов <M
22. ifl>=10 theninc(i); //проверка счетчика на выход
Селекция хромосом
До этого нами уже была проведена сортировка хромосом и вычислена для каждой функция приспособленности (Eval):
1. for i:=1 to pop_size do //циклповсейпопуляции
2. q[i]:=0;
3. forj:=1 toidoq[i]:=q[i]+Eval[j]; //вычисление кумулятивной вероятности
4. forj:=1 topop_sizedo //новый цикл для определения новой популяции
5. r:=random*q[pop_size]; //определение номера хромосомы
6. i:=1;
7. while q[i]<=r do inc(i);
8. hr1[j]:=hr[i]; //переход одной хромосомы в новую популяцию
Пример реализации
В качестве примера было взято n=5 (количество станков), общая стоимость α=12500, размер склада b=500, вектор стоимости станков (300,800,700,900,1000), вектор площади станков (20,30,50,30,10). Вектор желаемого исхода (0.97, 0.95, 0.90). Количество циклов статистического моделирования равен 3000, генетического алгоритма - 400
Результат работы программы выглядит следующим образом:
X=(7,4,2,3,2) , общая стоимость = 11400, общая площадь = 470, вектор исходов (0.99, 0.95, 0,89)
Литература
1. Б. Лю. Теория и практика неопределенного программирования. - М.: Бином: Лаборатория знаний, 2005.
2. Iwamura, K and Liu, B., Dependet-chance integer programming applied to capital budgeting, Journal of the Operations Research Society of Japan, Vol.42, No. 2, 117-127, 1999.
3. Ермольев Ю.М. Методы стохастического программирования. – М.: Наука, 1976.
4. Юдин Д.Б. Задачи и методы стохастического программирования. – М.: Сов. радио, 1979.
5. Вентцель Е.С. Исследование операций. – М.: Сов. радио 1972.
6. Горбань А.Н. Обучение нейронных сетей. – М.: СП ПараГраф, 1990.
7. http://orsc.edu.cn/~liu
Приложение
program Gibrid;
uses
SysUtils,Math;
const max=10;
const Nmax=3000;
const pop_size=10;
const mu1=1;
const bt=4/3;
const ap=0.05;
const nu1=0.01;
Type koef=array [1..max] of real;
Type ves=array[1..max] of koef;
Type mis=array[1..Nmax] of real;
Type learn=array[1..Nmax,1..max] of real;
Type hromo=array[1..pop_size] of koef;
Type position=array[1..max]of integer;
var mu:real;
cost,sq:position;
d,ogr,dd,x:koef;
w0,w1,zn:ves;
max_st_m,gen_alg:integer;
function LogN(mu, sigma: real):real;
var u1,u2,y: real;
begin
randomize;
u1:=random;
u2:=random;
y:=sqrt(-2*ln(u1))*sin(2*Pi*u2);
y:=mu+sigma*y;
result:=exp(y);
end;
function Expa(sigma:real):real;
var u:real;
begin
randomize;
u:=random;
result:=-sigma*ln(u);
end;
procedure uslovie;
var i:integer;
begin
writeln('Input cost: ');
for i:=1 to 5 do
begin
write(i,' = ');
readln(cost[i]);
end;
write('Input max cost: ');
readln(ogr[1]);
writeln('Input square: ');
for i:=1 to 5 do
begin
write(i,' = ');
readln(sq[i]);
end;
write('Input max sq: ');
readln(ogr[2]);
writeln('Input fun result (0,1): ');
for i:=1 to 3 do
begin
write(i,' = ');
readln(d[i]);
end;
writeln;
for i:=1 to 5 do
if i<5 then write(cost[i],'*x[',i,']+')
else write(cost[i],'*x[',i,']= ');
writeln(ogr[1]);
writeln;
for i:=1 to 5 do
if i<5 then write(sq[i],'*x[',i,']+')
else write(sq[i],'*x[',i,']= ');
writeln(ogr[2]);
write('Input max iter of stat.model (0..3000) = ');
readln(max_st_m);
write('Input num of gen algoritm = ');
readln(gen_alg);
end;
function odz(x:koef):boolean;
var
j:integer;
summ1,summ2:real;
begin
summ1:=0;
for j:=1 to 5 do
summ1:=summ1+cost[j]*x[j];
summ2:=0;
for j:=1 to 5 do
summ2:=summ2+sq[j]*x[j];
if (summ1<=ogr[1]) and (summ2<=ogr[2]) and (x[1]>=0) and (x[2]>=0) and (x[3]>=0) and (x[4]>=0) and (x[5]>=0) then
result:=true
else result:=false;
end;
procedure stat_model(var x:koef; var dd:koef);
var
i,N1,k:integer;
begin
repeat
for i:=1 to 5 do
begin
randomize;
x[i]:=round(random*10);
end;
if odz(x) then
begin
N1:=0;
for k:=1 to max_st_m do
if LogN(3,1)*x[1]>=Expa(10) then N1:=N1+1;
dd[1]:=N1/max_st_m;
N1:=0;
for k:=1 to max_st_m do
if LogN(4,1.6)*x[2]>=Expa(15) then N1:=N1+1;
dd[2]:=N1/max_st_m;
N1:=0;
for k:=1 to max_st_m do
if (LogN(5,1.6)*x[3]>=Expa(20)) and (LogN(4,1.2)*x[4]>=Expa(18)) and (LogN(3,0.8)*x[5]>=Expa(16)) then N1:=N1+1;
dd[3]:=N1/max_st_m;
end;
until odz(x);
end;
procedure pech(hr:hromo);
var i,j:integer;
begin
for i:=1 to pop_size do
begin
for j:=1 to 5 do
write(hr[i,j]:4:2,' ');
writeln
end;
end;
procedure stat_res(x:koef; var dd:koef);
var
N1,k:integer;
begin
N1:=0;
for k:=1 to max_st_m do
if LogN(3,1)*x[1]>=Expa(10) then N1:=N1+1;
dd[1]:=N1/max_st_m;
N1:=0;
for k:=1 to max_st_m do
if LogN(4,1.6)*x[2]>=Expa(15) then N1:=N1+1;
dd[2]:=N1/max_st_m;
N1:=0;
for k:=1 to max_st_m do
if (LogN(5,1.6)*x[3]>=Expa(20)) and (LogN(4,1.2)*x[4]>=Expa(18)) and (LogN(3,0.8)*x[5]>=Expa(16)) then N1:=N1+1;
dd[3]:=N1/max_st_m;
end;
procedure init(var hr:hromo);
var i,j:integer;
dd:koef;
begin
i:=1;
while i<=pop_size do
begin
stat_model(x,dd);
for j:=1 to 5 do hr[i,j]:=x[j];
inc(i);
end;
end;
procedure cross(var hr:hromo);
var i,j,k:integer;
r,c:real;
parent:hromo;
pos:position;
begin
j:=0;
for i:=1 to pop_size do
begin
randomize;
r:=random;
if r<=0.3 then
begin
inc(j);
parent[j]:=hr[i];
pos[j]:=i;
end;
end;
if ((j mod 2)=1)then j:=j-1;
i:=1;
While i<j do
begin
randomize;
c:=random;
for k:=1 to 5 do
begin
hr[pos[i],k]:=round(c*parent[i,k]+(1-c)*parent[i+1,k]);
hr[pos[i+1],k]:=round((1-c)*parent[i,k]+c*parent[i+1,k]);
end;
i:=i+2;
end;
end;
procedure mut(var hr:hromo);
var i,j,k,l,M:integer;
r:real;
parent:hromo;
pos:position;
c:koef;
begin
j:=0;
for i:=1 to pop_size do
begin
randomize;
r:=random;
if r<=0.2 then
begin
inc(j);
parent[j]:=hr[i];
pos[j]:=i;
end;
end;
i:=1;
l:=0;
While i<=j do
begin
inc(l);
for k:=1 to 5 do
begin
randomize;
c[k]:=random*power(-1,random(2));
end;
randomize;
M:=random(10);
for k:=1 to 5 do parent[i,k]:=round(parent[i,k]+M*c[k]);
if odz(parent[i]) then
begin
hr[pos[i]]:=parent[i];
inc(i);
l:=0;
end
else
begin
M:=random(M);
if l>=10 then inc(i);
end;
end;
end;
procedure cel_f(hr:hromo; var zn:ves);
var i,j:integer;
begin
for i:=1 to 10 do
begin
stat_res(hr[i],dd);
for j:=1 to 3 do
if d[j]>dd[j] then zn[i,j]:=d[j]-dd[j]
else zn[i,j]:=0;
end;
end;
procedure sort(var hr:hromo);
var i,j:integer;
e1:koef;
begin
cel_f(hr,zn);
for i:=1 to pop_size-1 do
for j:=i+1 to pop_size do
if zn[i,1]>zn[j,1] then
begin
e1:=hr[i];
hr[i]:=hr[j];
hr[j]:=e1;
e1:=zn[i];
zn[i]:=zn[j];
zn[j]:=e1;
end;
for i:=1 to pop_size-1 do
for j:=i+1 to pop_size do
if zn[i,1]=zn[j,1] then
if zn[i,2]>zn[j,2] then
begin
e1:=hr[i];
hr[i]:=hr[j];
hr[j]:=e1;
e1:=zn[i];
zn[i]:=zn[j];
zn[j]:=e1;
end;
for i:=1 to pop_size-1 do
for j:=i+1 to pop_size do
if zn[i,2]=zn[j,2] then
if zn[i,3]>zn[j,3] then
begin
e1:=hr[i];
hr[i]:=hr[j];
hr[j]:=e1;
e1:=zn[i];
zn[i]:=zn[j];
zn[j]:=e1;
end;
end;
procedure eval(var ev:koef);
var i:integer;
a:real;
begin
a:=0.05;
for i:=1 to pop_size do ev[i]:=power(a*(1-a), i-1);
end;
procedure selection(var hr:hromo);
var q,ev:koef;
i,j:integer;
r:real;
hr1:hromo;
begin
sort(hr);
eval(ev);
for i:=1 to pop_size do
begin
q[i]:=0;
for j:=1 to i do q[i]:=q[i]+ev[j];
end;
for j:=1 to pop_size do
begin
randomize;
r:=random*q[pop_size];
i:=1;
while q[i]<=r do inc(i);
hr1[j]:=hr[i];
end;
for i:=1 to pop_size do hr[i]:=hr1[i];
end;
procedure res(hr:hromo);
var i:integer;
summ1,summ2:real;
begin
for i:=1 to 5 do
write(hr[1,i]:4:2,' ');
writeln;
stat_res(hr[1],dd);
for i:=1 to 3 do
write(dd[i]:5:3,' ');
summ1:=0;
for i:=1 to 5 do
summ1:=summ1+cost[i]*hr[1,i];
summ2:=0;
for i:=1 to 5 do
summ2:=summ2+sq[i]*hr[1,i];
writeln('cost = ',summ1);
writeln('square = ',summ2);
end;
procedure gib;
var hr:hromo;
i:integer;
begin
init(hr);
for i:=1 to gen_alg do
begin
writeln(i,' step');
cross(hr);
mut(hr);
selection(hr);
end;
res(hr);
end;
begin
uslovie;
gib;
Readln;
end.
|
