Эконометрика как наука:
Содержание, цели, задачи,
направления развития
Москва
2007
Содержание
Содержание. 2
Введение. 3
Глава 1. Обзор процедур, используемых для различения TS и DS рядов. 5
П1.1. Критерий Дики-Фуллера. 5
П1.2. Расширенный критерий Дики-Фуллера. Выбор количества запаздывающих разностей. 8
Глава 2. Проблема анализа временных рядов. 9
П2.1. Стационарные временные ряды и их основные характеристики. 9
П2.2. Неслучайная составляющая временного ряда и методы его сглаживания13
П2.3. Модели стационарных временных рядов и их идентификация. Модели авторегрессии порядка p
(AR(p
)-модели)23
Заключение. 30
Литература. 30
Введение
Эконометрика - метод экономического анализа, который объединяет экономическую теорию со статистическими и математическими методами анализа. Это попытка улучшить экономические прогнозы и сделать возможным успешное планирование экономической политики. В эконометрике экономические теории выражаются в виде математических соотношений, а затем проверяются эмпирически статистическими методами. Данная система используется, чтобы создать модели с целью прогнозирования таких важных показателей, как валовой национальный продукт, уровень безработицы, темп инфляции и дефицит федерального бюджета. Эконометрика используется все более широко, несмотря на то, что полученные с помощью нее прогнозы не всегда оказывались достаточно точными.
Проблемы в эконометрики многочисленны и разнообразны. Экономика - это сложный, динамический, многомерный и эволюционирующий объект, поэтому изучать ее трудно. Как общество, так и общественная система изменяются со временем, законы меняются, происходят технологические инновации, поэтому найти в этой системе инварианты непросто. Временные ряды коротки, сильно агрегированы, разнородны, нестационарны, зависят от времени и друг от друга, поэтому мы имеем мало эмпирической информации для изучения. Экономические величины измеряются неточно, подвержены значительным позднейшим исправлениям, а важные переменные часто не измеряются или ненаблюдаемы, поэтому все выводы неточны и ненадежны. Экономические теории со временем меняются, соперничающие объяснения сосуществуют друг с другом, и поэтому надежная теоретическая основа для моделей отсутствует. И среди самих эконометристов, по-видимому, нет согласия по поводу того, как следует заниматься их предметом.
Реклама

В последние годы большое внимание в эконометрической литературе уделяется анализу структурных свойств экономических временных рядов. Это вызвано тем, что далеко не всегда значения временного ряда формируются под воздействием некоторых факторов. Нередко бывает, что развитие того или иного процесса обусловлено его внутренними закономерностями, а отклонения от детерминированного процесса вызваны ошибками измерений или случайными флуктуациями. В последнее время появилось достаточно большое количество работ, в которых рассматриваются различные эконометрические аспекты развития Российской экономики.
Для временных рядов главный интерес представляет описание или моделирование их структуры. Цель таких исследований, как правило, шире моделирования, хотя некоторую информацию можно получить и непосредственно из модели, делая выводы о выполнении тех или иных экономических законов (скажем, закона паритета покупательной способности) и проверяя различные гипотезы (например, гипотезу эффективности финансовых рынков). Построенная модель может использоваться для экстраполяции или прогнозирования временного ряда, и тогда качество прогноза может служить полезным критерием при выборе среди нескольких моделей. Построение хороших моделей ряда необходимо и для других приложений, таких, как корректировка сезонных эффектов и сглаживание. Наконец, построенные модели могут использоваться для статистического моделирования длинных рядов наблюдений при исследовании больших систем, для которых временной ряд рассматривается как входная информация.
Для правильного решения различных содержательных задач экономического анализа необходимо рассматривать различные аспекты каждого исследуемого временного ряда, а для этого, прежде всего, нужно определить его глобальную структуру, т.е. решить вопрос об отнесении каждого из рассматриваемых рядов к классу рядов, стационарных относительно тренда – TS (trend stationary), или к классу рядов, остационариваемых только путем дифференцирования ряда – DS (difference stationary) рядов.
Проблема отнесения макроэкономических рядов динамики, имеющих выраженный тренд, к одному из двух указанных классов активно обсуждалась в последние два десятилетия в мировой эконометрической и экономической литературе, поскольку траектории TS и DS ряды отличаются друг от друга кардинальным образом. TS ряды имеют линию тренда в качестве некоторой “центральной линии”, которой следует траектория ряда, находясь, то выше, то ниже этой линии, с достаточно частой сменой положений выше-ниже. DS ряды помимо детерминированного тренда (если таковой имеется) имеют еще и стохастический тренд, из-за присутствия которого траектория DS ряда весьма долго пребывает по одну сторону от линии детерминированного тренда (выше или ниже соответствующей прямой), удаляясь от нее на значительные расстояния, так что по-существу в этом случае линия детерминированного тренда перестает играть роль “центральной” линии, вокруг которой колеблется траектория процесса. В TS-рядах влияние предыдущих шоковых воздействий затухает с течением времени, а в DS-рядах такое затухание отсутствует и каждый отдельный шок влияет с одинаковой силой на все последующие значения ряда. Поэтому наличие стохастического тренда требует определенных политических усилий для возвращения макроэкономической переменной к ее долговременной перспективе, тогда как при отсутствии стохастического тренда серьезных усилий для достижения такой цели не требуется – в этом случае макроэкономическая переменная “скользит” вдоль линии тренда как направляющей, пересекая ее достаточно часто и не уклоняясь от этой линии сколько-нибудь далеко.
Реклама

Построение адекватной модели макроэкономического ряда, которую можно использовать для описания динамики ряда и прогнозирования его будущих значений, и адекватных моделей связей этого ряда с другими макроэкономическими рядами невозможно без выяснения природы этого ряда и природы рядов, с ним связываемых, т.е. без выяснения принадлежности ряда к одному из двух указанных классов (TS или DS).
В работе нумерация параграфов и уравнений начинается в буквы «П».
Глава 1. Обзор
процедур, используемых для различения TS и DS рядов
П1.1. Критерий Дики-Фуллера
Под критерием Дики-Фуллера в действительности понимается группа критериев, объединенных одной идеей, предложенных и изученных в работах [Dickey (1976)], [Fuller (1976)], [Dickey, Fuller (1979)], [Dickey, Fuller (1981)]. В критериях Дики-Фуллера проверяемой (нулевой) является гипотеза о том, что исследуемый ряд x
t
принадлежит классу DS (DS-гипотеза); альтернативная гипотеза – исследуемый ряд принадлежит классу TS (TS-гипотеза). Критерий Дики-Фуллера фактически предполагает, что наблюдаемый ряд описывается моделью авторегрессии первого порядка (возможно, с поправкой на линейный тренд). Критические значения зависят от того, какая статистическая модель оценивается и какая вероятностная модель в действительности порождает наблюдаемые значения. При этом рассматриваются следующие три пары моделей (SM – статистическая модель, statistical model; DGP – модель порождения данных, data generating process).
1) Если ряд 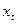 имеет детерминированный линейный тренд (наряду с которым может иметь место и стохастический тренд), то в такой ситуации берется пара имеет детерминированный линейный тренд (наряду с которым может иметь место и стохастический тренд), то в такой ситуации берется пара
SM: 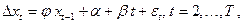
DGP: 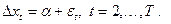
В обоих случаях e
t
– независимые случайные величины, имеющие одинаковое нормальное распределение с нулевым математическим ожиданием..
Методом наименьших квадратов оцениваются параметры данной SM и вычисляется значение t
-статистики t
j
для проверки гипотезы H0
: j
= 0. Полученное значение сравнивается с критическим уровнем tcrit
, рассчитанным в предположении, что наблюдаемый ряд в действительности порождается данной моделью DGP (случайное блуждание со сносом). DS-гипотеза отвергается, если t
j
< tcrit
. Критические уровни, соответствующие выбранным уровням значимости, можно взять из таблиц, если ряд наблюдается на интервалах длины T
= 25, 50, 100, 250, 500.
2) Если ряд xt
не имеет детерминированного тренда (но может иметь стохастический тренд) и имеет ненулевое математическое ожидание, то берется пара
SM: 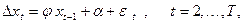
DGP: 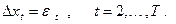
Методом наименьших квадратов оцениваются параметры данной SM и вычисляется значение t
-статистики t
j
для проверки гипотезы H0
: j
= 0. Полученное значение сравнивается с критическим уровнем tcrit
, рассчитанным в предположении, что наблюдаемый ряд в действительности порождается данной моделью DGP (случайное блуждание без сноса). DS-гипотеза отвергается, если t
j
< tcrit
. Критические уровни, соответствующие выбранным уровням значимости, можно взять из таблиц. Если ряд наблюдается на интервалах длины T
= 25, 50, 100, 250, 500.
3) Наконец, если ряд x
t
не имеетдетерминированного тренда (но может иметь стохастический тренд) и имеет нулевое математическое ожидание, то берется пара
SM: 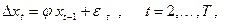
DGP: 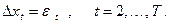
Методом наименьших квадратов оцениваются параметры данной SM и вычисляется значение t
-статистики t
j
для проверки гипотезы H0
: j
= 0. Полученное значение сравнивается с критическим уровнем tcrit
, рассчитанным в предположении, что наблюдаемый ряд в действительности порождается данной моделью DGP (случайное блуждание без сноса). DS-гипотеза отвергается, если t
j
< tcrit
.
Неправильный выбор оцениваемой статистической модели может существенно отразиться на мощности критерия Дики-Фуллера. Например, если наблюдаемый ряд порождается моделью случайного блуждания со сносом, а статистические выводы делаются по результатам оценивания статистической модели без включения в ее правую часть трендовой составляющей, то тогда мощность критерия, основанная на статистике t
j
, стремится к нулю с возрастанием количества наблюдений. С другой стороны, оцениваемая статистическая модель не должна быть и избыточной, поскольку это также ведет к уменьшению мощности критерия.
П1.2. Расширенный критерий Дики-Фуллера. Выбор количества запаздывающих разностей
Описанный выше критерий Дики-Фуллера фактически предполагает, что наблюдаемый ряд описывается моделью авторегрессии первого порядка (возможно, с поправкой на линейный тренд). Если же наблюдаемый ряд описывается моделью более высокого (но конечного) порядка p
и характеристический многочлен имеет не более
одного
единичного корня, то тогда можно воспользоваться расширенным (augmented) критерием Дики-Фуллера. В каждой из трех рассмотренных выше ситуаций достаточно дополнить правые части оцениваемых статистических моделей запаздывающими разностями Dxt
-
j
, t
= 2,…, p
- 1, так что, например, в первой ситуации теперь оценивается расширенная статистическая модель SM: 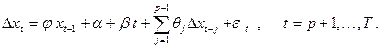
Полученные при оценивании расширенных статистических моделей значения t
-статистик t
j
для проверки гипотезы H0
: j
= 0 сравниваются с теми же критическими значениями tcrit
, что и для рассмотренных выше (нерасширенных) моделей. DS-гипотеза отвергается, если t
j
< tcrit
.
Заметим, что расширенный критерий Дики-Фуллера может применяться и тогда, когда ряд xt
описывается смешанной моделью авторегрессии-скользящего среднего. Если ряд наблюдений x
1
,…, xT
порождается моделью ARIMA(p
, 1, q
) c q
> 0, то его можно аппроксимировать моделью ARI(p
*
, 1) = ARIMA(p
*
, 1, 0) с p
*
< T
1/3
и применять процедуру Дики-Фуллера к этой модели.
Однако даже если ряд наблюдений x
1
,…, xT
действительно порождается моделью авторегрессии AR(p
) конечного порядка p
, то значение p
обычно не известно и его приходится оценивать на основании имеющихся наблюдений, а такое предварительное оценивание влияет на характеристики критерия. Поэтому при анализе данных приходится сначала выбирать значение p=p
max
достаточно большим, так, чтобы оно было не меньше истинного порядка p
0
авторегрессионной модели, описывающей ряд, или порядка р
*
аппроксимирующей авторегрессионной модели, а затем пытаться понизить используемое значение р
, апеллируя к наблюдениям.
Такое понижение может осуществляться, например, путем последовательной редукции расширенной модели за счет исключения из нее незначимых (на 10% уровне) запаздывающих разностей (GS-стратегия перехода от общего к частному) или путем сравнения (оцененных) полной и редуцированных моделей с различными р
³p
max
по информационному критерию Шварца (SIC). Если p
max
³p
0
, то тогда в пределе (при Т
®¥) SIC выбирает правильный порядок модели, а стратегия GS выбирает модель с р
³р
0
; при этом факт определения порядка модели на основании имеющихся данных не влияет на асимптотическое распределение статистики Дики-Фуллера.
При практической реализации указанных двух подходов, когда мы имеем лишь ограниченное количество наблюдений, эти две процедуры могут приводить к совершенно различным выводам относительно необходимого количества запаздываний в правой части статистической модели, оцениваемой в рамках расширенного критерия Дики-Фуллера.
Глава 2. Проблема анализа временных рядов
П2.1. Стационарные временные ряды и их основные характеристики
Поиск модели, адекватно описывающей поведение случайных остатков e
t
анализируемого временного ряда xt
, производят, как правило, в рамках класса стационарных временных рядов.
Определение П2.1.
Ряд xt
называется строго стационарным (или стационарным в узком смысле), если совместное распределение вероятностей m
наблюдений 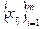 такое же, как и для m
наблюдений такое же, как и для m
наблюдений 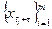 , при любых t
, и t
1
,…, tm
. , при любых t
, и t
1
,…, tm
.
Другими словами, свойства строго стационарного временного ряда не меняются при изменении начала отсчета времени. В частности, при m
= 1 из предположения о строгой стационарности временного ряда xt
следует, что закон распределения вероятностей случайной величины xt
не зависит от t
, а значит, не зависят от t
и все его основные числовые характеристики, в том числе: среднее значение Ext
= m
и дисперсия Dxt
= s
2
.
Очевидно, значение m
определяет постоянный уровень, относительно которого колеблется анализируемый временной ряд xt
, а постоянная величина s
характеризует размах этих колебаний. Поскольку закон распределения вероятностей случайной величины xt
одинаков при всех t
, то он сам и его основные числовые характеристики могут быть оценены по наблюдениям x
1
,…, xT
. В частности: 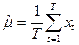 - оценка среднего значения, - оценка среднего значения, 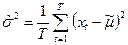 - оценка дисперсии. (П2.1) - оценка дисперсии. (П2.1)
Автоковариационная функция
g
(
t
).
Значения автоковариационной функции статистически оцениваются по имеющимся наблюдениям временного ряда по формуле 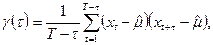 где t
= 1,… T
- 1, а где t
= 1,… T
- 1, а 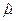 вычислено по формуле (П2.1). вычислено по формуле (П2.1).
Очевидно, значение автоковариационной функции при t
= 0 есть не что иное, как дисперсия временного ряда, и, соответственно,
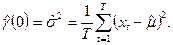 (П2.2) (П2.2)
Автокорреляционная функция r
(
t
).
Одно из главных отличий последовательности наблюдений, образующих временной ряд, от случайной выборки заключается в том, что члены временного ряда являются, вообще говоря, статистически взаимозависимыми. Степень тесноты статистической связи между двумя случайными величинами может быть измерена парным коэффициентом корреляции. Поскольку в нашем случае коэффициент измеряет корреляцию, существующую между членами одного и того же временного ряда, его принято называть коэффициентом автокорреляции. При анализе изменения величины r
(t
) в зависимости от значения t
принято говорить об автокорреляционной функции r
(t
). График автокорреляционной функции иногда называют коррелограммой. Автокорреляционная функция (в отличие от автоковариационной) безразмерна, т.е. не зависит от масштаба измерения анализируемого временного ряда. Ее значения, по определению, могут колебаться от -1 до +1. Кроме того, из стационарности следует, что r
(t
) = r
(-t
), так что при анализе поведения автокорреляционных функций ограничиваются рассмотрением только положительных значений t
.
Выборочный аналог автокорреляционной функции определяется формулой
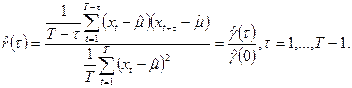 (П2.3) (П2.3)
Существуют общие характерные особенности, отличающие поведение автокорреляционной функции стационарного временного ряда. Другими словами, можно описать в общих чертах схематичный вид коррелограммы стационарного временного ряда. Это обусловлено следующим общим соображением: очевидно, чем больше разнесены во времени члены временного ряда xt
и xt+
t
, тем слабее взаимосвязь этих членов и, соответственно, тем меньше должно быть по абсолютной величине значение r
(t
). При этом в ряде случаев существует такое пороговое значение r
0
, начиная с которого все значения будут тождественно равны нулю.
Частная автокорреляционная функция
r
част
(
t
).
С помощью этой функции реализуется идея измерения автокорреляции, существующей между разделенными t
тактами времени членами временного ряда xt
и xt
+
t
, при устраненном опосредованном влиянии на эту взаимозависимость всех промежуточных членов этого временного ряда. Частная автокорреляция 1-го порядка может быть подсчитана с использованием соотношения:
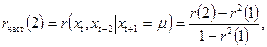 (П2.4) (П2.4)
где m
- среднее значение анализируемого стационарного процесса.
Частные автокорреляции более высоких порядков могут быть подсчитаны аналогичным образом по элементам общей корреляционной матрицы R
= ||rij
||, в которой rij
= = r
(xi
, xj
) = r
(|i
-
j
|), где i
,j
= 1,…, T
и r
(0) = 1. Так, например, частная автокорреляция 2-го порядка определяется по формуле:
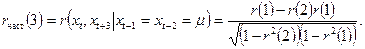 (П2.5) (П2.5)
Эмпирические (выборочные) версии автокорреляционных функций
получаются с помощью тех же соотношений (П2.4), (П2.5) при замене участвующих в них теоретических значений автокорреляций r
(t
) их статистическими оценками 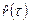 . .
Полученные таким образом частные автокорреляции r
част
(1),r
част
(2),… можно нанести на график, в котором роль абсциссы выполняет величина сдвига t
.
Знание автокорреляционных функций r
(t
) и r
част
(t
) оказывает существенную помощь в решении задачи подбора и идентификации модели анализируемого временного ряда.
Спектральная плотность
p
(
w
).
Спектральную плотность стационарного временного ряда определяется через его автокорреляционную функцию соотношением
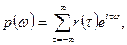
где 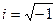 . Так как r
(t
) = r
(-t
), спектральная плотность может быть записана в виде . Так как r
(t
) = r
(-t
), спектральная плотность может быть записана в виде
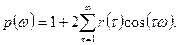
Следовательно, функция p
(w
) является гармонической с периодом 2p
. График спектральной плотности, называемый спектром, симметричен относительно w
= p
. Поэтому при анализе поведения p
(w
) ограничиваются значениями 0 £w
£p
. Спектральная плотность принимает только неотрицательные значения.
Использование свойств этой функции в прикладном анализе временных рядов определяется как «спектральный анализ временных рядов». Применительно к статистическому анализу экономических рядов динамики этот подход не получил широкого распространения, т.к. эмпирический анализ спектральной плотности требует в качестве своей информационной базы либо достаточно длинных стационарных временных рядов, либо нескольких траекторий анализируемого временного ряда (и та и другая ситуация весьма редки в практике статистического анализа экономических рядов динамики).
Для содержательного анализа важно, что величина спектральной плотности характеризует силу взаимосвязи, существующей между временным рядом xt
и гармоникой с периодом 2p
/w
. Это позволяет использовать спектр как средство улавливания периодичностей в анализируемом временном ряду: совокупность пиков спектра определяет набор гармонических компонентов в разложении (1.1.1). Если в ряде содержится скрытая гармоника частоты w
, то в нем присутствуют также периодические члены с частотами w
/2, w
/3 и т.д.
Можно несколько расширить класс моделей стационарных временных рядов, используемых при анализе конкретных рядов экономической динамики.
Определение 2.2.
Ряд называется слабо стационарным (или стационарным в широком смысле), если его среднее значение, дисперсия и ковариации не зависят от t
.
П2.2. Неслучайная составляющая временного ряда и методы его сглаживания
Принципиальные отличия временного ряда от последовательности наблюдений, образующих случайную выборку, заключаются в следующем:
· во-первых, в отличие от элементов случайной выборки члены временного ряда не являются независимыми;
· во-вторых, члены временного ряда не обязательно являются одинаково распределенными, так что P
{xt
< x
} ¹P
{xt
¢
< x
} при t
¹t
¢
.
Это означает, что свойства и правила статистического анализа случайной выборки нельзя распространять на временные ряды. С другой стороны, взаимозависимость членов временного ряда создает свою специфическую базу для построения прогнозных значений анализируемого показателя по наблюденным значениям.
Генезис наблюдений, образующих временной ряд (механизм порождения данных).
Речь идет о структуре и классификации основных факторов, под воздействием которых формируются значения временного ряда. Как правило, выделяются 4 типа таких факторов.
· Долговременные
, формирующие общую (в длительной перспективе) тенденцию в изменении анализируемого признака xt
. Обычно эта тенденция описывается с помощью той или иной неслучайной функции f
тр
(t
) (аргументом которой является время), как правило, монотонной. Эту функцию называют функцией тренда или просто – трендом.
· Сезонные
, формирующие периодически повторяющиеся в определенное время года колебания анализируемого признака. Поскольку эта функция j
(е
) должна быть периодической (с периодами, кратными «сезонам»), в ее аналитическом выражении участвуют гармоники (тригонометрические функции), периодичность которых, как правило, обусловлена содержательной сущностью задачи.
· Циклические (конъюнктурные)
, формирующие изменения анализируемого признака, обусловленные действием долговременных циклов экономической или демографической природы (волны Кондратьева, демографические «ямы» и т.п.) Результат действия циклических факторов будем обозначать с помощью неслучайной функции y
(t
).
· Случайные (нерегулярные)
, не поддающиеся учету и регистрации. Их воздействие на формирование значений временного ряда как раз и обусловливает стохастическую природу элементов xt
, а, следовательно, и необходимость интерпретации x
1
,…, xT
как наблюдений, произведенных над случайными величинами x
1
,…,x
Т
. Будем обозначать результат воздействия случайных факторов с помощью случайных величин («остатков», «ошибок ») e
t
.
Конечно, вовсе не обязательно, чтобы в процессе формирования значений всякого временного ряда участвовали одновременно факторы всех четырех типов. Выводы о том, участвуют или нет факторы данного типа в формировании значений конкретного ряда, могут базироваться как на анализе содержательной сущности задачи, так и на специальном статистическом анализе исследуемого временного ряда. Однако во всех случаях предполагается непременное участие случайных факторов. Таким образом, в общем виде модель формирования данных (при аддитивной структурной схеме влияния факторов) выглядит как:
xt
= c
1
f
(t
) + c
2
j
(t
) +c
3
y
(t
) + e
t
. (1.1.1)
где c
i
= 1, если факторы i-
го типа участвуют в формировании значений ряда и c
i
= 0 – в противном случае.
Основные задачи анализа временных рядов.
Базисная цель статистического анализа временного ряда заключается в том, чтобы по имеющейся траектории этого ряда:
1. определить, какие из неслучайных функций присутствуют в разложении (1.1.1), т.е. определить значения индикаторов c
i
;
2. построить «хорошие» оценки для тех неслучайных функций, которые присутствуют в разложении (1.1.1);
3. подобрать модель, адекватно описывающую поведение случайных остатков e
t
, и статистически оценить параметры этой модели.
Успешное решение перечисленных задач, обусловленных базовой целью статистического анализа временного ряда, является основой для достижения конечных прикладных целей исследования и, в первую очередь, для решения задачи кратко- и среднесрочного прогноза значений временного ряда.
Существенную роль в решении задач выявления и оценивания трендовой, сезонной и циклической составляющих в разложении (1.1.1) играет начальный этап анализа, на котором:
· выявляется сам факт наличия/отсутствия неслучайной (и зависящей от времени t
) составляющей в разложении (1.1.1); по существу, речь идет о статистической проверке гипотезы
H
0
:Ext
= m
= const (П2.6)
(включая утверждение о взаимной статистической независимости членов исследуемого временного ряда) при различных вариантах конкретизации альтернативных гипотез типа
H
А
: Ext
¹ const;
· строится оценка (аппроксимация) для неизвестной интегральной неслучайной составляющей f
(t
) = c
1
f
тр
(t
) + c
2
j
(t
) +c
3
y
(t
), т.е. решается задача сглаживания (элиминирования случайных остатков e
t
) анализируемого временного ряда xt
.
П2.2.1. Проверка гипотезы о неизменности среднего значения временного ряда
Критерий серий, основанный на медиане.
Расположим члены анализируемого временного ряда в порядке возрастания, т.е. образуем по наблюдениям вариационный ряд:
x
(1)
, x
(2)
,…, x
(
T
)
.
Определим выборочную медиану по формуле
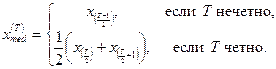
После этого мы образуем «серии» из плюсов и минусов, на статистическом анализе которых основана процедура проверки гипотезы (П2.6). По исходному временному ряду, построим последовательность из плюсов и минусов следующим образом: вместо xt
ставится «+», если 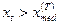 , и «-», если , и «-», если 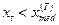 (члены временного ряда, равные (члены временного ряда, равные 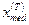 , в полученной таким образом последовательности плюсов и минусов не учитываются). , в полученной таким образом последовательности плюсов и минусов не учитываются).
Образованная последовательность плюсов и минусов характеризуется общим числом серий n
(Т
) и протяженностью самой длинной серии t
(Т
). При этом под «серией» понимается последовательность подряд идущих плюсов и подряд идущих минусов. Если исследуемый ряд состоит из статистически независимых наблюдений, случайно варьирующих около некоторого постоянного уровня (т.е. справедлива гипотеза (П2.6)), то чередование «+» и «-» в построенной последовательности должно быть случайным, т.е. эта последовательность не должна содержать слишком длинных серий подряд идущих «+» или «-», и, соответственно, общее число серий не должно быть слишком малым. Так что в данном критерии целесообразно рассматривать одновременно пару критических статистик (n
(Т
); t
(Т
)).
Справедлив следующий приближенный статистический критерия проверки гипотезы Н
0,
выраженной соотношением (П2.6): если хотя бы одно из неравенств 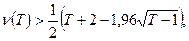 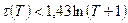 окажется нарушенным, то гипотеза (П2.6) отвергается с вероятностью ошибки a
, такой, что 0,05 < a
< 0,0975 и, тем самым, подтверждается наличие зависящей от времени неслучайной составляющей в разложении (1.1.1). окажется нарушенным, то гипотеза (П2.6) отвергается с вероятностью ошибки a
, такой, что 0,05 < a
< 0,0975 и, тем самым, подтверждается наличие зависящей от времени неслучайной составляющей в разложении (1.1.1).
Критерий «восходящих» и «нисходящих» серий.
Этот критерий «улавливает» постепенное смещение среднего значения в исследуемом распределении не только монотонного, но и более общего, например, периодического характера.
Так же, как и в предыдущем критерии, исследуется последовательность знаков - плюсов и минусов, однако правило образования этой последовательности в данном критерии иное. Здесь на i-
ом месте вспомогательной последовательности ставится «+», если xi+
1
-xi
> 0, и «-»с, если xi+
1
-xi
< 0 (если два или несколько следующих друг за другом наблюдений равны между собой, то принимается во внимание только одно из них). Последовательность подряд идущих «+» (восходящая серия) будет соответствовать возрастанию результатов наблюдения, а последовательность «-» (нисходящая серия) - их убыванию. Критерий основан на том же соображении, что и предыдущий: если выборка случайна, то в образованной последовательности знаков общее число серий не может быть слишком малым, а их протяженность - слишком большой.
При уровне значимости 0,05 < a
< 0,0975 критерий вид:
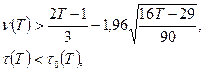 (П2.7) (П2.7)
где величина t
0
(Т
) определяется следующим образом:
| Т
|
Т
£ 26 |
26 < Т
£ 153 |
153 < Т
£ 1170 |
| t
0
(Т
) |
t
0
= 5 |
t
0
= 6 |
t
0
= 7 |
Если хотя бы одно из неравенств (П2.7) окажется нарушенным, то гипотезу (П2.6) следует отвергнуть.
Критерий квадратов последовательных разностей (критерий Аббе).
Если есть основания полагать, что случайный разброс наблюдений x
(t
)
относительно своих средних значений подчиняется нормальному закону распределения вероятностей, то для выяснения вопроса о возможном систематическом смещении среднего в ходе выборочного обследования целесообразно воспользоваться критерием Аббе, являющимся в этом случае более мощным.
Для проверки гипотезы (П2.6) с помощью данного критерия подсчитывают величину 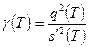 , где , где 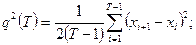 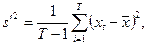 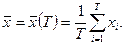 Если Если 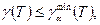 то гипотеза (П2.6) отвергается. При этом величина то гипотеза (П2.6) отвергается. При этом величина 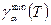 для T
> 60 подсчитывается как для T
> 60 подсчитывается как 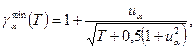 где u
a
-a
-
квантиль нормированного нормального распределения. Величины при T
££ 60 для трех наиболее употребительных значений уровня значимости приведены в табл. 4.9 книги [Большев, Смирнов (1965)]. где u
a
-a
-
квантиль нормированного нормального распределения. Величины при T
££ 60 для трех наиболее употребительных значений уровня значимости приведены в табл. 4.9 книги [Большев, Смирнов (1965)].
П2.2.2. Методы сглаживания временного ряда (выделение неслучайной составляющей)
Методы выделения неслучайной составляющей в траектории, отражающей поведение временного ряда, подразделяются на два типа.
Методы первого типа (аналитические)
основаны на допущении, что известен общий вид неслучайной составляющей в разложении (1.1.1)
f
(t
) = c
1
f
тр
(t
) + c
2
j
(t
) +c
3
y
(t
). (П2.8)
Например, если известно, что неслучайная составляющая временного ряда описывается линейной функцией времени f
(t
) = q
0
+q
1
t
, где q
0
и q
1
- некоторые неизвестные параметры модели, то задача ее выделения (задача элиминирования случайных остатков или задача сглаживания временного ряда) сводится к задаче построения хороших оценок 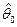 и и 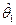 для параметров модели. для параметров модели.
Методы второго типа (алгоритмические)
не связаны ограничительным допущением о том, что общий аналитический вид искомой функции (П2.8) известен исследователю. В этом смысле они являются более гибкими, более привлекательными. Однако «на выходе» задачи они предлагают исследователю лишь алгоритм расчета оценки 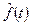 для искомой функции f
(t
) в любой наперед заданной точке t
и не претендуют на аналитическое представление функции (П2.8). для искомой функции f
(t
) в любой наперед заданной точке t
и не претендуют на аналитическое представление функции (П2.8).
Аналитические методы выделения (оценки) неслучайной составляющей временного ряда.
Эти методы реализуются в рамках моделей регрессии, в которых в роли зависимой переменной выступает переменная xt
, а в роли единственной объясняющей переменной - время t
. Таким образом, рассматривается модель регрессии вида
xt
= f
(t
, q
) + e
t
, t
= 1,…, T
,
в которой общий вид функции f
(t
, q
) известен, но неизвестны значения параметров q
= (q
0
, q
1
,…, q
m
). Оценки параметров 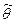 строятся по наблюдениям строятся по наблюдениям 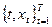 . Выбор метода оценивания зависит от гипотетического вида функции f
(t
, q
) и стохастической природы случайных регрессионных остатков e
t
. . Выбор метода оценивания зависит от гипотетического вида функции f
(t
, q
) и стохастической природы случайных регрессионных остатков e
t
.
Алгоритмические методы выделения неслучайной составляющей временного ряда (методы скользящего среднего).
В основе этих методов элиминирования случайных флуктуаций в поведении анализируемого временного ряда лежит простая идея: если «индивидуальный» разброс значений члена временного ряда xt
около своего среднего (сглаженного) значения a
характеризуется дисперсией s
2
, то разброс среднего из N
членов временного ряда (x
1
+ x
2
+…+ xT
) / N
около того же значения a
будет характеризоваться гораздо меньшей величиной дисперсии, а именно дисперсией, равной s
2
/ N
. А уменьшение меры случайного разброса (дисперсии) и означает как раз сглаживание соответствующей траектории. Поэтому выбирают некоторую нечетную «длину усреднения» N
= 2m
+ 1, измеренную в числе подряд идущих членов анализируемого временного ряда. А затем сглаженное значение временного ряда xt
вычисляют по значениям xt
-
m
, xt
-
m
+1
,…, xt
, xt
+1
,…, xt
+
m
по формуле
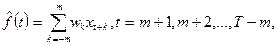 (П2.9) (П2.9)
где wk
(k
= -m
, -
m
+ 1,…, m
) - некоторые положительные «весовые» коэффициенты, в сумме равные единице, т.е. wk
> 0 и 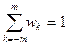 . Поскольку, изменяя t
от m
+ 1 до T
-m
, мы как бы «скользим» по оси времени, то и методы, основанные на формуле (П2.9), принято называть методами скользящей средней (МСС). . Поскольку, изменяя t
от m
+ 1 до T
-m
, мы как бы «скользим» по оси времени, то и методы, основанные на формуле (П2.9), принято называть методами скользящей средней (МСС).
Очевидно, один МСС отличается от другого выбором параметров m
и wk
.
Определение параметров wk
основано на следующей процедуре. В соответствии с теоремой Вейерштрасса любая гладкая функция f
(x
) при самых общих допущениях может быть локально представлена алгебраическим полиномом подходящей степени p
. Поэтому берем первые 2m
+ 1 членов временного ряда x
1
,…, x
2m
+1
, строим с помощью МНК полином 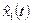 степени p
, аппроксимирующий поведение этой начальной части траектории временного ряда, и используем этот полином для определения оценки сглаженного значения f
(t
) временного ряда в средней (т.е. (m
+ 1)-й) точке этого отрезка ряда, т.е. полагаем степени p
, аппроксимирующий поведение этой начальной части траектории временного ряда, и используем этот полином для определения оценки сглаженного значения f
(t
) временного ряда в средней (т.е. (m
+ 1)-й) точке этого отрезка ряда, т.е. полагаем 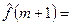 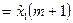 . Затем «скользим» по оси времени на один такт и таким же способом подбираем полином . Затем «скользим» по оси времени на один такт и таким же способом подбираем полином 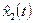 той же степени p
к отрезку временного ряда x
2
,…, xm
+2
и определяем оценку сглаженного значения временного ряда в средней точке сдвинутого на единицу отрезка временного ряда, т.е. той же степени p
к отрезку временного ряда x
2
,…, xm
+2
и определяем оценку сглаженного значения временного ряда в средней точке сдвинутого на единицу отрезка временного ряда, т.е. 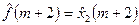 , и т.д. , и т.д.
В результате мы найдем оценки для сглаженных значений анализируемого временного ряда при всех t
, кроме t
= 1,…, m
и t
= T
,… T
-
m
+ 1.
Подбор наилучшего (в смысле критерия МНК) аппроксимирующего полинома к траектории анализируемого временного ряда приводит к формуле вида (П2.9), причем результат не зависит от того, для какого именно из «скользящих» временных интервалов был осуществлен этот подбор.
Метод экспоненциально взвешенного скользящего среднего (метод Брауна [
Brown
(1963)]).
В соответствии с этим методом оценка сглаженного значения в точке t
определяется как решение оптимизационной задачи вида
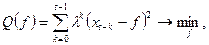 (П2.10) (П2.10)
где 0 < l
< 1. Следовательно, веса l
k
в критерии Q
(f
) обобщенного («взвешенного») МНК уменьшаются экспоненциально по мере удаления наблюдений xt
-
k
в прошлое.
Решение оптимизационной задачи (П2.10) дает:
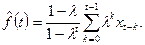 (П2.11) (П2.11)
В отличие от обычного МСС здесь скользит только правый конец интервала усреднения и, кроме того, веса экспоненциально уменьшаются по мере удаления в прошлое. Формула (П2.11) дает оценку сглаженного значения временного ряда не в средней, а в правой конечной точке интервала усреднения.
П2.2.3. Подбор порядка аппроксимирующего полинома с помощью метода последовательных разностей
Реализация алгоритмических методов выделения неслучайной составляющей временного ряда связана с необходимостью подбора порядка p
локально-аппроксимирующего полинома. Эта же задача возникает и при реализации аналитических методов выделения неслучайной составляющей. При решении этой задачи широко используется так называемый метод последовательных разностей членов анализируемого временного ряда, который основан на следующем математическом факте: если анализируемый временной ряд xt
содержит в качестве своей неслучайной составляющей алгебраический полином f
(t
) = q
0
+
q
1
t
+ q
p
tp
порядка p
, то переход к последовательным разностям порядка p
+ 1, исключает неслучайную составляющую, оставляя элементы, выражающиеся только через остаточную случайную компоненту e
t
.
Обсудим способ подбора порядка p
полинома, представляющего собой неслучайную составляющую f
(t
) в разложении анализируемого временного ряда xt
. Заметим, прежде всего, что если мы знаем, что среднее значение наблюдаемой случайной величины x
равно нулю (E
x
= 0), то выборочным аналогом ее дисперсии является величина 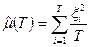 , где x
I
, i
= 1, 2,…, T
- наблюденные значения этой случайной величины. Если же E
x
¹ 0, то выборочным аналогом дисперсии будет статистика , где x
I
, i
= 1, 2,…, T
- наблюденные значения этой случайной величины. Если же E
x
¹ 0, то выборочным аналогом дисперсии будет статистика 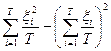 , так что величина , так что величина 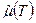 будет давать в этом случае существенно завышенные оценки для D
x
. Возвращаясь к последовательному переходу к разностям Dk
xt
, k
= 1, 2,…, p
+ 1, отметим, что при всех k
< p
+ 1 средние значения этих разностей будут отличны от нуля, так как будут выражаться не только через остатки e
t
, но и через коэффициенты q
0
,q
1
,…,q
p
и степени t
. И только для k
³p
+ 1 можно утверждать, что: будет давать в этом случае существенно завышенные оценки для D
x
. Возвращаясь к последовательному переходу к разностям Dk
xt
, k
= 1, 2,…, p
+ 1, отметим, что при всех k
< p
+ 1 средние значения этих разностей будут отличны от нуля, так как будут выражаться не только через остатки e
t
, но и через коэффициенты q
0
,q
1
,…,q
p
и степени t
. И только для k
³p
+ 1 можно утверждать, что:
E
(Dk
xt
) = 0 и 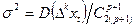 . .
С учетом этих замечаний можно сформулировать следующее правило подбора порядка сглаживающего полинома p
, называемое методом последовательных разностей.
Последовательно для k
= 1, 2,… вычисляем разности Dk
xt
(t
= 1,…, T
-
k
), а также величины
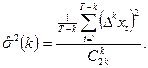 (П2.12) (П2.12)
Анализируем поведение величины 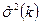 в зависимости от k
. Величина как функция k
будет демонстрировать явную тенденцию к убыванию до тех пор, пока k
не достигнет величины p
+ 1. Начиная с этого момента величина (П2.12) стабилизируется, оставаясь (при дальнейшем увеличении p
) приблизительно на одном уровне. Поэтому значение k
= k
0
, начиная с которого величина стабилизируется, и будет давать завышенный на единицу искомый порядок сглаживающего полинома, т.е. p
= k
0
- 1. в зависимости от k
. Величина как функция k
будет демонстрировать явную тенденцию к убыванию до тех пор, пока k
не достигнет величины p
+ 1. Начиная с этого момента величина (П2.12) стабилизируется, оставаясь (при дальнейшем увеличении p
) приблизительно на одном уровне. Поэтому значение k
= k
0
, начиная с которого величина стабилизируется, и будет давать завышенный на единицу искомый порядок сглаживающего полинома, т.е. p
= k
0
- 1.
Этот метод привлекателен своей простотой, но его практическое применение требует определенной осторожности. Последовательные значения не являются независимыми, и часто обнаруживается тенденция их медленного убывания (а иногда возрастания) без видимой сходимости к постоянному значению. Кроме того, процесс перехода к разностям имеет тенденцию уменьшать относительное значение любого систематического движения, кроме сезонных эффектов с периодом, близким к временному интервалу, так что сходимость отношения не доказывает, что ряд первоначально состоял из полинома плюс случайный остаток, а только то, что он может быть приближенно представлен таким образом. Однако для нас этот метод ценен лишь тем, что он дает верхний предел порядка полинома p
, который целесообразно использовать для элиминирования неслучайной составляющей.
П2.3. Модели стационарных временных рядов и их идентификация
. Модели авторегрессии порядка p
(AR(p
)-модели)
В П2.2 рассматривался класс стационарных временных рядов, в рамках которого подбирается модель, пригодная для описания поведения случайных остатков исследуемого временного ряда (1.1.1). Здесь рассматривается набор линейных параметрических моделей из этого класса и методы их идентификации. Таким образом, речь здесь идет не о моделировании временных рядов, а о моделировании их случайных остатков e
t
, получающихся после элиминирования из исходного временного ряда xt
его неслучайной составляющей (П2.8). Следовательно, в отличие от прогноза, основанного на регрессионной модели, игнорирующего значения случайных остатков, в прогнозе временных рядов существенно используется взаимозависимость и прогноз самих случайных остатков.
Введем обозначения. Так как здесь описывается поведение случайных остатков, то моделируемый временной ряд обозначим e
t
, и будем полагать, что при всех t
его математическое ожидание равно нулю, т.е. E
e
t
, º 0. Временные последовательности, образующие «белый шум», обозначим d
t
.
Описание и анализ, рассматриваемых ниже моделей, формулируется в терминах общего линейного процесса, представимого в виде взвешенной суммы настоящего и прошлых значений белого шума, а именно:
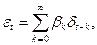 (П2.13) (П2.13)
где b
0
= 1 и 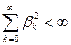 . .
Таким образом, белый шум представляет собой серию импульсов, в широком классе реальных ситуаций генерирующих случайные остатки исследуемого временного ряда.
Временной ряд e
t
можно представить в эквивалентном (П2.13) виде, при котором он получается в виде классической линейной модели множественной регрессии, в которой в качестве объясняющих переменных выступают его собственные значения во все прошлые моменты времени:
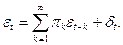 (П2.14) (П2.14)
При этом весовые коэффициенты p
1
,p
2
,… связаны определенными условиями, обеспечивающими стационарность ряда e
t
. Переход от (П2.14) к (П2.13) осуществляется с помощью последовательной подстановки в правую часть (П2.14) вместо e
t
-
1
,e
t
-
2
,… их выражений, вычисленных в соответствии с (П2.14) для моментов времени t
- 1, t
- 2 и т.д.
Рассмотрим также процесс смешанного типа, в котором присутствуют как авторегрессионные члены самого процесса, так и скользящее суммирование элементов белого шума:
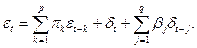
Будем подразумевать, что p
и q
могут принимать и бесконечные значения, а также то, что в частных случаях некоторые (или даже все) коэффициенты p
или b
равны нулю.
Рассмотрим сначала простейшие частные случаи.
Модель авторегрессии 1-го порядка
-
AR(1) (марковский процесс).
Эта модель представляет собой простейший вариант авторегрессионного процесса типа (П2.14), когда все коэффициенты кроме первого равны нулю. Соответственно, она может быть определена выражением
e
t
= a
e
t
-
1
+d
t
, (П2.15)
где a
- некоторый числовой коэффициент, не превосходящий по абсолютной величине единицу (|a
| < 1), а d
t
- последовательность случайных величин, образующая белый шум. При этом e
t
зависит от d
t
и всех предшествующих d
, но не зависит от будущих значений d
. Соответственно, в уравнении (П2.15) d
t
не зависит от e
t
-
1
и более ранних значений e
.
В связи с этим, d
t
называют инновацией (обновлением).
Последовательности e
, удовлетворяющие соотношению (П2.15), часто называют также марковскими процессами. Это означает, что
E
e
t
º 0, (П2.16)
r
(e
t
,e
t
±
k
) = a
k
, (П2.17)
D
e
t
= 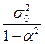 , (П2.18) , (П2.18)
cov(e
t
,e
t
±
k
) = a
k
D
e
t
. (П2.19)
Одно важное следствие (П2.19) состоит в том, что если величина |a
| близка к единице, то дисперсия e
t
будет намного больше дисперсии d
. А это значит, что если соседние значения ряда e
t
сильно коррелированы, то ряд довольно слабых возмущений d
t
будет порождать размашистые колебания остатков e
t
.
Основные характеристики процесса авторегрессии 1-го порядка следующие.
Условие стационарности ряда (П2.15)
определяется требованием к коэффициенту a
: |a
| < 1,
или, что то же, корень z
0
уравнения 1 -a
z
= 0 должен быть по абсолютной величине больше единицы.
Автокорреляционная функция марковского процесса
определяется соотношением (П2.17):
r
(t
) =r
(e
t
,e
t
±
t
) = a
t
. (П2.20)
Отсюда же, в частности, следует простая вероятностная интерпретация параметра a
: a
= r
(e
t
,e
t
±
1
),
т.е. значение a
определяет величину корреляции между двумя соседними членами ряда e
t
.
Из (П2.20) видно, что степень тесноты корреляционной связи между членами последовательности (П2.15) экспоненциально убывает по мере их взаимного удаления друг от друга во времени.
Частная автокорреляционная функция
r
част
(t
) = r
(e
t
,e
t
+
t
| e
t
+1
=e
t
+2
=…= e
t
+
t
-
1
= 0) может быть подсчитана с помощью формул (П2.4)–(П2.5). Непосредственное вычисление по этим формулам дает следующий простой результат: значения частной корреляционной функции r
част
(t
) равны нулю для всех t
= 2, 3,…. Это свойство может быть использовано при подборе модели: если вычисленные выборочные частные корреляции 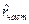 статистически незначимо отличаются от нуля при t
= 2, 3,…, то использование модели авторегрессии 1-го порядка для описания поведения случайных остатков временного ряда не противоречит исходным статистическим данным. статистически незначимо отличаются от нуля при t
= 2, 3,…, то использование модели авторегрессии 1-го порядка для описания поведения случайных остатков временного ряда не противоречит исходным статистическим данным.
Спектральная плотность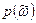 марковского процесса (П2.15) может быть подсчитана с учетом известного вида автокорреляционной функции (П2.20):
марковского процесса (П2.15) может быть подсчитана с учетом известного вида автокорреляционной функции (П2.20):
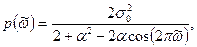 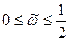 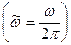 . .
В случае значения параметра a
близкого к 1, соседние значения ряда e
t
близки друг к другу по величине, автокорреляционная функция экспоненциально убывает оставаясь положительной, а в спектре преобладают низкие частоты, что означает достаточно большое среднее расстояние между пиками ряда e
t
. При значении параметра a
близком к –1, ряд быстро осциллирует (в спектре преобладают высокие частоты), а график автокорреляционной функции экспоненциально спадает до нуля с попеременным изменением знака.
Идентификация модели
, т.е. статистическое оценивание ее параметров a
и 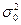 по имеющейся реализации временного ряда xt
(а не его остатков, которые являются ненаблюдаемыми), основана на соотношениях (П2.16)-(П2.19) и может быть осуществлена с помощью метода моментов. Для этого следует предварительно решить задачу выделения неслучайной составляющей , что позволит оперировать в дальнейшем остатками по имеющейся реализации временного ряда xt
(а не его остатков, которые являются ненаблюдаемыми), основана на соотношениях (П2.16)-(П2.19) и может быть осуществлена с помощью метода моментов. Для этого следует предварительно решить задачу выделения неслучайной составляющей , что позволит оперировать в дальнейшем остатками
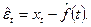 (П2.21) (П2.21)
Затем подсчитывается выборочная дисперсия 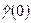 остатков по формуле остатков по формуле
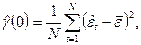
где 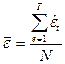 , а «невязки» (остатки) вычислены по формуле (П2.21). , а «невязки» (остатки) вычислены по формуле (П2.21).
Оценку 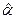 параметра a
получаем с помощью формулы (П2.18), подставляя в нее вместо коэффициента корреляции его выборочное значение, т.е. параметра a
получаем с помощью формулы (П2.18), подставляя в нее вместо коэффициента корреляции его выборочное значение, т.е. 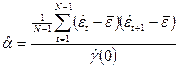 . .
Наконец, оценка 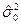 параметра основана на соотношении (П2.19), в котором величины D
e
t
и a
заменяются оценками, соответственно, и : параметра основана на соотношении (П2.19), в котором величины D
e
t
и a
заменяются оценками, соответственно, и : 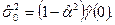
Модели авторегрессии 2-го порядка –
AR
(2) (процессы Юла).
Эта модель, как и AR(1), представляет собой частный случай авторегрессионного процесса, когда все коэффициенты p
j
в правой части (П2.14) кроме первых двух, равны нулю. Соответственно, она может быть определена выражением
e
t
= a
1
e
t
-
1
+ a
2
e
t
-
2
+ d
t
, (П2.22)
где последовательность d
1
,d
2
,… образует белый шум.
Условия стационарности ряда
(П2.22) (необходимые и достаточные) определяются как: 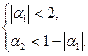
В рамках общей теории моделей те же самые условия стационарности получаются из требования, чтобы все корни соответствующего характеристического уравнения лежали бы вне единичного круга. Характеристическое уравнение для модели авторегрессии 2-го порядка имеет вид: 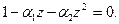
Автокорреляционная функция процесса Юла
подсчитывается следующим образом. Два первых значения r
(1) и r
(2) определены соотношениями
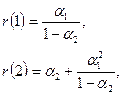
а значения для r
(t
), t
= 3, 4,… вычисляются с помощью рекуррентного соотношения r
(t
) = a
1
r
(t
- 1) + a
2
r
(t
- 2).
Частная автокорреляционная функция
временного ряда, сгенерированного моделью авторегрессии 2-го порядка, обладает следующим отличительным свойством: r
част
(t
) = 0 при всех t
= 3, 4,…
Спектральная плотность процесса Юла
может быть вычислена с помощью формулы: 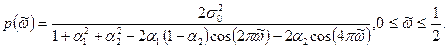
Идентификация модели авторегрессии 2-го порядка
основана на соотношениях, связывающих между собой неизвестные параметры модели a
1
, a
2
и со значениями различных моментов «наблюдаемого» временного ряда e
t
.
По значениям 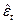 вычисляются оценки вычисляются оценки 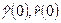 и и 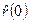 , соответственно, дисперсии D
e
t
и автокорреляций r
(1) и r
(2). Это делается с помощью соотношений (П2.2) и (П2.3): , соответственно, дисперсии D
e
t
и автокорреляций r
(1) и r
(2). Это делается с помощью соотношений (П2.2) и (П2.3):
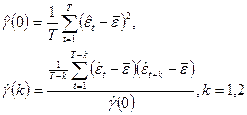
После этого можно получить оценки 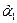 и и 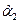 из соотношений из соотношений
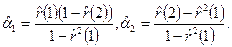
Наконец, оценку параметра получаем с помощью
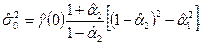
Модели авторегрессии
p
-
го порядка –
AR
(
p
) (
p
³
3).
Эти модели, образуя подмножество в классе общих линейных моделей, сами составляют достаточно широкий класс моделей. Если в общей линейной модели (П2.14) полагать все параметры p
j
, кроме первых p
коэффициентов, равными нулю, то мы приходим к определению AR(p
)-модели:
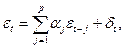 (П2.23) (П2.23)
где последовательность случайных величин d
1
,d
2
,… образует белый шум.
Условия стационарности
процесса, генерируемого моделью (П2.23), также формулируются в терминах корней его характеристического уравнения
1 -a
1
z
-a
2
z
2
-…-a
p
zp
= 0.
Для стационарности процесса необходимо и достаточно, чтобы все корни характеристического уравнения лежали бы вне единичного круга, т.е. превосходили бы по модулю единицу.
Автокорреляционная функция
процесса (П2.23) может быть вычислена с помощью рекуррентного соотношения по первым p
ее значениям r
(1),…, r
(p
). Это соотношение имеет вид:
r
(t
) =a
1
r
(t
- 1) +a
2
r
(t
- 2) +…+a
p
r
(t
-p
), t
= p
+ 1, p
+ 2,... (П2.24)
Частная автокорреляционная функция
процесса (П2.23) будет иметь ненулевые значения лишь при t
£p
; все значения rчаст
(p
) при t
> p
будут нулевыми. Это свойство частной автокорреляционной функции AR(p
)-процесса используется, в частности, при подборе порядка в модели авторегрессии для конкретных анализируемых временных рядов. Если, например, все частные коэффициенты автокорреляции, начиная с порядка k
, статистически незначимо отличаются от нуля, то порядок модели авторегрессии естественно определить равным p
= k
- 1.
Спектральная плотность
процесса авторегрессии p
-
го порядка определяется с помощью формулы:
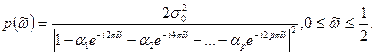
Идентификация модели авторегрессии
p
-го порядка
основана на соотношениях, связывающих между собой неизвестные параметры модели и автокорреляции исследуемого временного ряда. Для вывода этих соотношений последовательно подставляются в (П2.24) значения t
= 1, 2,…, p
. Получается система линейных уравнений относительно a
1
,a
2
,…,a
p
:
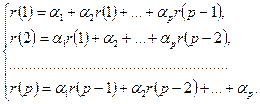 (П2.25) (П2.25)
называемая уравнениями Юла–Уокера [Yule (1927)], [Walker (1931)]. Оценки 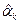 для параметров a
k
получим, заменив теоретические значения автокорреляций r
(k
) их оценками для параметров a
k
получим, заменив теоретические значения автокорреляций r
(k
) их оценками 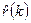 и решив полученную таким образом систему уравнений. Оценка параметра получается из соотношения и решив полученную таким образом систему уравнений. Оценка параметра получается из соотношения 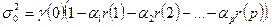 заменой всех участвующих в правой части величин их оценками. заменой всех участвующих в правой части величин их оценками.
Заключение
Разнообразные содержательные задачи экономического анализа требуют использования статистических данных, характеризующих исследуемые экономические процессы и развернутых во времени в форме временных рядов. При этом одни и те же временные ряды используются для решения разных содержательных проблем.
Литература
1. Айвазян С.А., Мхитарян В.С. (1998)
Прикладная статистика и основы эконометрии. – М.: ЮНИТИ, 1998.
2. Бокс Дж., Дженкинс Г. (1974)
Анализ временных рядов. Прогноз и управление. - М.: Мир, 1974. - Вып. 1, 2.
3. Большев Л.Н., Смирнов Н.В. (1965)
Таблицы математической статистики. - М.: Наука, 1965.
4. Дженкинс Г., Ватс Д. (1971, 1972)
Спектральный анализ и его применения. - М.: Мир, 1971, 1972. - Вып. 1,2.
5. Джонстон Дж. (1980)
Эконометрические методы. - М.: Статистика, 1980.
|
