| Міністерство освіти та науки України
Чернівецький національний університет
імені Юрія Федьковича
Факультет комп¢ютерних наук
Кафедра комп¢ютерних систем і мереж
ПРОГРАМА "ПОШУК ОБЛИЧЧЯ ЛЮДИНИ У ВІДЕОПОТОКАХ СТАНДАРТУ MPEG-4"
482.362.80915-18 81 03-3
(Пояснювальна записка)
2007
Анотація
Пояснювальна записка містить опис призначення та області застосування програмного продукту, його технічні характеристики, опис алгоритму програми, вхідних та вихідних даних, очікувані техніко-економічні показники.
Програмний документ містить: розділів - 3, сторінок - 31.
Зміст
Вступ
1. Призначення та область застосування
2. Технічні характеристики
2.1 Постановка задачі
2.1.1 Штучна нейронна мережа
2.1.2 Локалізація обличчя
2.1.3 Мережа зі зворотнім розповсюдженням
2.1.4 Розпізнавання обличчя
2.1.5 Метод головних компонент
2.1.6 Гнучкі контурні моделі обличчя
2.1.7 Методи, засновані на геометричних характеристиках обличчя
2.1.8 Порівняння еталонів
2.1 9. Основи кодування відео
2.2 Опис алгоритму
2.3 Опис і обґрунтування вибору методу організації вхідних і вихідних даних
2.4 Опис і обґрунтування вибору складу технічних і програмних засобів
3. Очікувані техніко-економічні показники
Джерела, використані при розробці
На сьогоднішній день ідентифікація особи по зображенню обличчя є одним з пріоритетних напрямів розвитку біометричних систем. Такі біометричні показники, як відбиток пальця і малюнок райдужної оболонки є конфіденційною інформацією, тоді як зображення обличчя є загальнодоступним. Саме технологія ідентифікації на основі зображення обличчя визнана найприйнятнішою для масового застосування, оскільки вона не вимагає фізичного контакту з пристроєм, ненав'язлива, природна і, в потенціалі, може володіти високою надійністю і швидкістю. Крім того, такий підхід вигідний і з тієї причини, що може використовуватися непомітно для оточуючих в місцях масового скупчення людей.
Системи виявлення і розпізнавання облич використовуються не тільки в системах безпеки і контролю доступу. Вони знайшли широке застосування і в таких областях, як організація відеоконференцій, об'єктно-орієнтоване стиснення відеоданих, розпізнавання емоцій людини, створення систем машинного зору в робототехніці.
Реклама

З цією метою розроблюється програма 482.362.80915-18 "Пошук обличчя люди у відеопотоках стандарту MPEG-4", на основі технічного завдання, затвердженого на засіданні кафедри комп’ютерних систем та мереж від 28 серпня 2006 р., протокол №1.
З бурхливим розвитком нових інформаційних технологій і медіа, розробляються ефективніші і дружні методи взаємодії людина-комп'ютер (HCI), які не залежать від традиційних пристроїв, як наприклад клавіатури, миші, і дисплею. До того ж, спадаюче співвідношення "ціна/продуктивність" обчислень знижує собівартість отримування відеозображення, що призводить до того, що системи комп'ютерного зору можуть бути розгорнені в домашніх комп'ютерах і вбудованих системах. Швидко розвиваються дослідження в обробці зображень обличчя, яке засноване на факті, що інформація про особу користувача, стан, і наміри може бути витягнена із зображень, і що комп'ютери можуть відповідно до цього реагувати, наприклад, спостерігаючи вираз обличчя особи. За минулі п'ять років, проблема розпізнавання виразу обличчя сконцентрувала багато уваги, проте вона вже вивчається більш ніж протягом 20 років психофізіологами, невронауковцями, і інженерами. Багато дослідних демонстрацій і комерційних додатків розроблені цими зусиллями. Перший крок будь-якої системи обробки обличчя - знаходження області зображення, де присутні обличчя. Проте, виявлення обличчя з єдиного зображення - це задача, яка потребує вирішення через мінливість в масштабах, розташуванні, орієнтації і позі. Емоційний вираз, завади і умови освітлення також впливають на продуктивність системи.
Необхідно автоматизувати процес розпізнавання осіб шляхом розробки програми для локалізації і розпізнавання обличчя людини у вхідному відопотоці. Вхідний відеопоток подається в ЕОМ через під’єднану веб-камеру. Програма повинна бути розроблена засобами Microsoft Visual C++.
Опис вживаних математичних методів подається у підпунктах пункту 2.1
У останні десятиліття в світі для вирішення високоформалізованих задач використовують апарат штучних нейронних мережах (ШНМ). Актуальність досліджень в цьому напрямі підтверджується масою різних застосувань ШНМ. Це автоматизація процесів розпізнавання образів, адаптивне керування, апроксимація функцій, прогнозування, створення експертних систем, організація асоціативної пам'яті і багато інших додатків. За допомогою ШНМ можна, наприклад, передбачати показники біржового ринку, виконувати розпізнавання оптичних або звукових сигналів, створювати системи самонавчання, що здатні керувати автомашиною при парковці або синтезувати мову по тексту [1].
Реклама

Широкий круг задач, який вирішують ШНМ, не дозволяє в даний час створювати універсальні, могутні мережі, змушуючи розробляти спеціалізовані ШНМ, функціонуючі за різними алгоритмами.
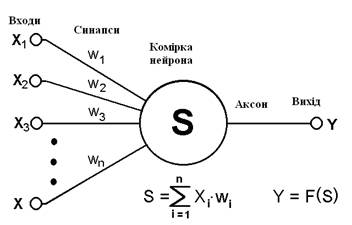
Рис.2.1 Штучний нейрон
Не дивлячись на істотні відмінності, окремі типи ШНМ володіють декількома загальними рисами.
По-перше, основу кожної ШНМ складають відносно прості, в більшості випадків - однотипні, елементи (комірки), що імітують роботу нейронів мозку. Далі під нейроном матиметься на увазі штучний нейрон, що зображений на рис.2.1 тобто осередок ШНМ. Кожен нейрон характеризується своїм поточним станом по аналогії з нервовими клітинами головного мозку, які можуть бути збуджені або загальмовані. Він володіє групою синапсів - однонаправлених вхідних зв'язків, сполучених з виходами інших нейронів, а також має аксон - вихідний зв'язок даного нейрона, з якою сигнал поступає на синапси наступних нейронів. Кожен синапс характеризується величиною синаптичного зв'язку або її вагою wi, який по фізичному значенню еквівалентний електричній провідності.
Поточний стан нейрона визначається, як зважена сума його входів:
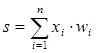 (2.1) (2.1)
Вихід нейрона є функція його стану: у = f (s) (
2.2)
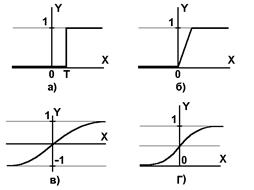
Рис.2.2 Функції активації
Нелінійна функція f називається активаційною і бути різною (рис.2.2). Однієї з найбільш розповсюджених є нелінійна функція з насиченням, так звана логістична функція або сигмоїд (тобто функція S-образного вигляду):
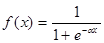 (2.3) (2.3)
При зменшенні a сигмоїд стає пологішим, в межах при a=0 вироджується в горизонтальну лінію на рівні 0.5, при збільшенні a сигмоїд наближається до функції одиничного стрибка з порогом T в точці x=0. З виразу для сигмоїда очевидно, що вихідне значення нейрона лежить в діапазоні [0,1]. Одна з цінних властивостей сигмоїдной функції - простий вираз для її похідної.
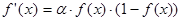 (2.4) (2.4)
Слід зазначити, що сигмоїдная функція диференційована на всій осі абсцис, що використовується в деяких алгоритмах навчання. Крім того вона володіє властивістю підсилювати слабкі сигнали краще, ніж великі, і запобігає насиченню від великих сигналів [1, c.126].
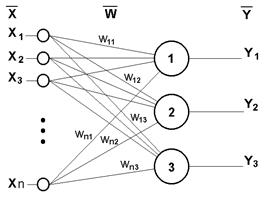
Рис.2.3 Одношаровий перцептрон
Повертаючись до загальних рис, властивих всім ШНМ, відзначимо, по-друге, принцип паралельної обробки сигналів, який досягається шляхом об'єднання великого числа нейронів в так звані шари і з'єднання певним чином нейронів різних шарів, а також нейронів одного шару між собою.
Як приклад простої НС розглянемо трьохнейронний перцептрон (рис.2.3), тобто таку мережу, нейрони якої мають активаційну функцію у вигляді одиничного стрибка. На n входів поступають якісь сигнали, що проходять по синапсах на 3 нейрони, що створюють єдиний шар цієї ШНМ і видаючі три вихідні сигнали:
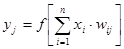 , j=1...3
(2.5) , j=1...3
(2.5)
Оскільки проблема виявлення обличчя може розглядатися як клас розпізнавання, тому були запропоновані різні нейромережеві архітектури. Перевагою використання нейронних мереж для виявлення обличчя є здатність навчання системи захоплювати комплексну густину умов зразків облич.
В запропонованому методі нейронна мережа одержує на вхід набір ознак з регіону 20х20 пікселів зображення і виробляє вихідне значення в межах від 0 до 1. Надаючи тестовий зразок на входи, вихід навченої нейронної мережі вказує присутність обличчя (близько до 1) або іншого зразка (близько до 0). Щоб знайти обличчя через все зображення, нейронну мережу застосовують на всіх ділянках зображення. Щоб знайти обличчя більших за 20х20 пікселів, вхідне зображення циклічно зменшується і мережа застосовується в кожному з масштабів (рис.2.4).

Рис. 2.4 Архітектура нейронної мережі для локалізації обличчя в зображенні.
Попередня обробка - нормалізація інтенсивності. Найпростіша дія нормалізації інтенсивності: зображення І
(x, y
) відображається в площину
I’
(x, y
) = аx
+ by
+ c
, (2.6)
де значення коефіцієнтів а
, b
і c
оцінені, використовуючи метод найменших квадратів, а потім надлишкове освітлення зменшують як результат різниці
І’’ (x, y) = І (x, y) - I’ (x, y). (
2.7)
Після нормалізації, розподіл зображень підвікон стає більш компактним і стандартизованим, що допомагає скорочувати складність подальшої класифікації.
Процедура виявлення обличчя класифікує зображення по значеннях простих ознак. Є багато стимулів для використання ознак замість опікселів. Найзагальніша причина - ознака може кодувати спеціалізовану проблемну область, що важливо при використанні обмеженої кількості учбових даних. Для цієї системи також існує другий критичний стимул: система заснована на ознаках діє набагато швидше, ніж аналогічна заснована на пікселях. Використані прості ознаки нагадують базові функції Хаара, які запропонував Viola [19]. Найістотнішими є три види ознак (рис.2.5). Значенням двохпрямокутної ознаки є різниця між сумою пікселів в межах двох прямокутних рівновеликих і однаково орієнтованих регіонів. Трьохпрямокутна ознака обчислюється як різниця від суми пікселів за межами центрального прямокутника, і суми пікселів самого прямокутника в центрі. Нарешті чотирьохпрямокутна ознака обчислює різницю між діагональними парами прямокутників.

Рис.2.5 Ознаки, що подаються в нейронну мережу:
A,B) двохпрямокутна, C) трьохпрямокутна, D) чотирьох прямокутна
Прямокутні ознаки можуть бути обчислені дуже швидко використовуючи проміжне представлення для зображення, яке Viola [19] назвав інтеграл зображення. Інтегралом зображення в точці x, y містить суму пікселів вище і лівіше x, y:
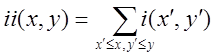 (2.8)
(2.8)
де ii (x, y) - це інтеграл зображення, а i (x, y) є початкове зображення. Використання наступної пари рекурсій:
s (x, y) = s (x, y - 1) + i (x, y) (
2.9)
ii (x, y) = ii (x - 1, y) + s (x, y) (
2.10)
де s (x, y) - це сума ряду, s (x,-1) = 0, і ii (-1, y) = 0.
Інтеграл зображення може бути обчислений одним проходом над початковим зображенням. Використовуючи інтеграл зображення, будь-яка прямокутна сума може бути обчислена чотирма посиланнями в масив. Ясно, що різниця між двома прямокутними сумами може бути обчислена у восьми посиланнях. Очевидно, що з використанням інтегралу зображення відпадає потреба маштабувати початкове зображення.
В даній розробці використано мережу зі зворотнім розповсюдженням, чия процедура навчання є найбільш ефективною. Алгоритм розповсюдження сигналів помилки від виходів ШНМ до її входів, в напрямі, зворотньому прямому розповсюдженню сигналів в звичному режимі роботи навчання ШНМ одержав назву процедури зворотнього розповсюдження (рис.2.6):
1. Подати на входи мережі один з можливих образів і в режимі звичного функціонування ШНМ, коли сигнали розповсюджуються від входів до виходів, розрахувати значення останніх.
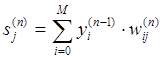 (2.11) (2.11)
де M - число нейронів в шарі n-1 з врахуванням нейрона з постійним вихідним станом +1, що задає зсув; yi (n-1)
=xij (n)
- i-й вхід нейрона j шару n.
2. Розрахувати d
(N)
для вихідного шару по формулі
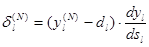 (2.12) (2.12)
Розрахувати по формулі зміни ваг D
w (N)
шару N.
3. Розрахувати по формулах 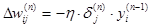 відповідно d
(n)
і D
w (n)
для всієї решти шарів, n=N-1,...1. відповідно d
(n)
і D
w (n)
для всієї решти шарів, n=N-1,...1.
4. Скоректувати всю вагу в ШНМ за формулою:
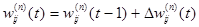 (2.10) (2.10)
5. Якщо помилка мережі істотна, перейти на крок 1. Інакше - кінець.

Рис.2.6 Діаграма сигналів в мережі при навчанні по алгоритму зворотного розповсюдження: А) взаємодія сигналів у внутрішньому шарі, А) взаємодія сигналів у вихідному шарі, С) виправлення ваг
Труднощі, пов'язані з розпізнанням обличчя, можуть бути віднесені до наступних категорій:
Поза. Зображення обличчя змінюються у відповідності до орієнтації пари обличчя-камера, тому деякі лицьові особливості, як наприклад око або ніс, можуть частково або цілком бути за завадами.
Присутність або відсутність структурних компонентів. Лицьові особливості, як наприклад, бороди, вуса, і окуляри можуть бути присутні або ні. Є велика кількість мінливості серед цих компонентів зокрема форма, колір, і розмір.
Вираз обличчя. Форма облич є безпосередньо пов'язаний з виразом обличчя персони.
Завади. Обличчя можуть бути частково приховані іншими об'єктами. У зображенні з групою людей, деякі обличчя можуть частково заховати інші.
Орієнтація зображення. Зображення обличчя безпосередньо видозмінюється у відповідності до обертання оптичної осі фотоапарата.
Умови зображення. Коли зображення сформоване, чинники, як наприклад освітлення (спектри, початкове розповсюдження і інтенсивність) і характеристики фотоапарата (сенсорна відповідь, лінзи) впливають на вираз обличчя.
Хоча розпізнавання обличчя - це високорівнева візуальна проблема, - в нашому методі залучається досить небагато структур. Ми скористаємося частиною цих структур, пропонуючи схему для розпізнавання, яке засноване на підході теорії інформації, прагнучи кодувати найдоречнішу інформацію в групі облич, які краще всього відрізнятимуть їх один від одного. Підхід перетворює зображення обличчя в малий набір характеристичних даних, які є головними компонентами учбового набору зображень облич. Схема функціонує за методом головних компонент, який показав себе як найбільш ефективний серед інших методів.
В даній розробці вибраний метод розпізнавання обличчя, що називається метод головних компонент (Principal Component Analysis, PCA), що стискує простір облич без істотних втрат інформативності. Він полягає в лінійному ортогональному перетворенні вхідного вектора X
розмірності N
у вихідний вектор Y
розмірності M
< N.
При цьому компоненти вектора Y
є некорельованими і загальна дисперсія після перетворення залишається незмінною. Матриця X
складається зі всіх зразків зображень навчального набору. Розв’язавши рівняння 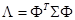 , одержуємо матрицю ортонормованих власних векторів , одержуємо матрицю ортонормованих власних векторів 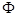 , де , де 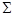 - коваріаційна матриця для X
, а - коваріаційна матриця для X
, а 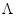 - діагональна матриця власних значень. Вибравши з підматрицю - діагональна матриця власних значень. Вибравши з підматрицю 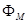 , що відповідає найбільшим власним числам, одержимо, що перетворення , що відповідає найбільшим власним числам, одержимо, що перетворення 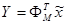 , де , де 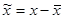 - нормалізований вектор з нульовим математичним очікуванням, характеризує велику частину загальної дисперсії і відображає найістотніші зміни X.
Вибір перших M
головних компонент розбиває векторний простір на головний (власний простір) - нормалізований вектор з нульовим математичним очікуванням, характеризує велику частину загальної дисперсії і відображає найістотніші зміни X.
Вибір перших M
головних компонент розбиває векторний простір на головний (власний простір) 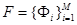 ,
що містить головні компоненти, і його ортогональне доповнення ,
що містить головні компоненти, і його ортогональне доповнення 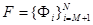 . Застосування цього методу для задачі розпізнавання людини по зображенню обличчя має наступний вигляд (рис.2.7). Вхідні вектори є центрованими і приведеними до єдиного масштабу зображеннями облич. Власні вектори, обчислені для всього набору зображень облич, називаються власними обличчями (eigenfaces) [3]. . Застосування цього методу для задачі розпізнавання людини по зображенню обличчя має наступний вигляд (рис.2.7). Вхідні вектори є центрованими і приведеними до єдиного масштабу зображеннями облич. Власні вектори, обчислені для всього набору зображень облич, називаються власними обличчями (eigenfaces) [3].

Рис 2.7 Приклад зображень власних векторів (власних облич)
Для кожного зображення обличчя обчислюються його головні компоненти. Звичайно береться від 5 до 200 головних компонент. Решта компонентів кодує дрібні відмінності між обличчями і шум. Процес розпізнавання полягає в порівнянні головних компонент невідомого зображення з компонентами решти зображень.
Метод головних компонент так само застосовується для виявлення обличчя на зображенні. Для облич значення компонент у власному просторі мають великі значення, а в доповненні власного простору - близькі до нуля. По цьому факту можна знайти, чи є вхідне зображення обличчям. Для цього перевіряється величина помилки реконструкції: чим більше помилка, тим більше ймовірність, що це не обличчя.
При зміні ракурсу зображення, наступає момент, коли цей метод при розпізнаванні починає реагувати більше на ракурс зображення, ніж на міжкласові відмінності. Класи при цьому більше не є кластерами у власному просторі. Це розв'язується додаванням в навчальну вибірку зображень в різних ракурсах. При цьому власні вектори втрачають обличчеподібну форму. При зміні кута повороту голови, головні компоненти викреслюють криві у власному просторі, які однозначно ідентифікують обличчя людини і по яких можна провести розпізнавання. Ці криві були названі власними сигнатурами (eigensignatures). По максимумах власних сигнатур було так само відмічено, що найбільшу інформативність має зображення обличчя в напівпрофіль [4].
Основна перевага застосування аналізу головних компонент - це зберігання і пошук зображень у великих базах даних, реконструкція зображень. Основний недолік - високі вимоги до умов зйомки зображень. Зображення повинні бути одержані в близьких умовах освітленості, однаковому ракурсі і повинна бути проведена якісна попередня обробка, що приводить зображення до стандартних умов (масштаб, поворот, центрування, вирівнювання яскравості, відсікання фону). Небажана наявність таких чинників, як окуляри, зміни в зачісці, виразі обличчя і інших внутрішньокласових варіацій.
У даних методах розпізнавання проводиться на основі порівняння контурів обличчя. Контури, звичайно, витягуються для ліній голови, вух, губ, носа, брів і очей (рис.2.7). Контури представлені ключовими позиціями, між якими положення точок, що належать контуру, обчислюється інтерполюванням. Для локалізації контурів в різних методах використовується як апріорна інформація, так і інформація, одержана в результаті аналізу навчального набору.
Ключові точки розміщуються вручну на наборі тренувальних зображень. Потім витягується інформація про інтенсивність пікселів, що лежать на лінії, перпендикулярній контуру для кожної точки контура. При пошуку контурів нового обличчя використовувався метод симуляції відпалу з цільовою функцією з двох складових. Перша із них максимізовувалася при відповідності інтенсивностей пікселів, витягнутих на перпендикулярній контуру лінії аналогічним пікселям з навчальної вибірки. Друга - при збігу контура з формою контурів тренувальних прикладів. Таким чином, витягувався не просто контур, а контур рис обличчя. Як повинен виглядати типовий контур рис обличчя, процедура пошуку знає з тренувальних прикладів. Для порівняння зображень використовуються значення головних компонент, обчислених на наборі векторів, що є координатами ключових точок [2].

Рис 2.8 Контури зображення створені за допомогою перетворення Хау
Головною задачею при розпізнаванні по контурах є правильне виділення цих контурів. У загальному випадку ця задача по складності порівнянна безпосередньо з розпізнаванням зображень. Крім того, використання цього методу самого по собі для задачі розпізнавання недостатньо.
Функція подібності з одним джетом у фіксованій позиції і іншим із змінною позицією є достатньо гладкою, для того, щоб одержати швидку і надійну збіжність при пошуку із застосуванням простих методів, таких як дифузія або градієнтний спуск. Досконаліші функції подібності залучають інформацію про фазу.
Для різних ракурсів відповідні ключові точки відмічені вручну на навчальному наборі. Крім того, щоб для одного і того ж обличчя представити різні варіації його зображення в одному і тому ж графі, для кожної точки використовуються декілька джетів, кожний з яких може відповідати різним локальним характеристикам даної точки, наприклад розплющеному і закритому оку.
Майже аналогічинм є метод еластичного графу. В цьому випадку відмінність між двома графами d
(Q,R
) обчислюється за допомогою деякої функції, що враховує як значення ознак - вага вершин, так і ступінь деформації ребер графа.

Рис.2.9 Еластичний граф, що покриває зображення обличчя
Деформація графа відбувається шляхом зсуву кожної з його вершин на деяку відстань в певних напрямах щодо її початкового положення і вибору такої позиції, при якій різниця у вазі вершин 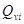 графа, що деформується, і відповідній їй вершині графа, що деформується, і відповідній їй вершині 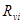 еталона буде мінімальною (рис.2.9). Дана операція виконується по черзі для всіх вершин графа до тих пір, поки не буде досягнуте найменше (для даної пари графів) значення d
(Q,R
) [5]. еталона буде мінімальною (рис.2.9). Дана операція виконується по черзі для всіх вершин графа до тих пір, поки не буде досягнуте найменше (для даної пари графів) значення d
(Q,R
) [5].
Один з найперших методів - це аналіз геометричних характеристик обличчя. Спочатку застосовувався в криміналістиці і був там детально розроблений. Потім з'явилися комп'ютерні реалізації цього методу. Суть його полягає у виділенні набору ключових точок (або областей) обличчя і подальшому виділенні набору ознак. Кожна ознака є або відстанню між ключовими точками, або відношенням таких відстаней. На відміну від методу порівняння еластичних графів тут відстані вибираються не як дуги графів. Набори найбільш інформативних ознак виділяються експериментально (рис.2.10).
Ключовими точками можуть бути кути очей, губ, кінчик носа, центр ока і т.п. Як ключові області можуть бути прямокутні області, що включають очі, ніс, рот [13].

Рис 2.10 Ідентифікаційні точки і відстані
В процесі розпізнавання порівнюються ознаки невідомого обличчя з ознаками, що зберігаються в базі. Задача знаходження ключових точок наближається до трудомісткості безпосередньо розпізнавання, і правильне знаходження ключових точок на зображенні багато в чому визначає успіх розпізнавання. Тому зображення обличчя людини повинне бути без шумів, що заважають процесу пошуку ключових точок. До таких завад відносять окуляри, бороди, прикраси, елементи зачіски і макіяжа. Освітлення бажане рівномірне і однакове для всіх зображень. Крім того, зображення обличчя повинно мати фронтальний ракурс, можливо з невеликими відхиленнями. Вираз обличчя повинен бути нейтральним. Це пов'язано з тим, що в більшості методів немає моделі врахування таких змін [14].
Таким чином, даний метод пред'являє строгі вимоги до умов зйомки, потребує надійного механізму знаходження ключових точок для загального випадку. Крім того, потрібне застосування досконаліших методів класифікації або побудови моделі змін. У загальному випадку цей метод не найоптимальніший, проте, для деяких специфічних задач перспективний. До таких задач можна віднести документарний контроль, коли вимагається порівняти зображення обличчя, одержаної у нинішній момент з фотографією в документі. При цьому інших зображень цієї людини немає, і, отже, механізми класифікації, засновані на аналізі тренувального набору, недоступні.
Порівняння еталонів (Template Matching) полягає у виділенні областей обличчя на зображенні, і подальшому порівнянні цих областей для двох різних зображень [11]. Кожна область, що співпала, збільшує міру схожості зображень. Це також один з історично перших методів розпізнавання людини по зображенню обличчя. Для порівняння областей використовуються прості алгоритми, наприклад, попіксельне порівняння [15].
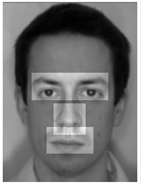
Рис.2.11 Області-еталони обличчя
Недолік цього методу полягає у тому, що він вимагає багато ресурсів, як для зберігання ділянок, так і для їх порівняння. З причини того, що використовується простий алгоритм порівняння, зображення повинні бути отримані в строго встановлених умовах: не допускається помітних змін ракурсу, освітлення, емоційного виразу.
MPEG-4 - це стандарт для запам'ятовування і доставки мультимедійного вмісту. Він був розроблено як наступник для стандартів MPEG-1 і MPEG-2. Первинна мета була зробити стандарт для додатків низького бітрейту, але у фазі специфікації MPEG-4 був розширений для роботи із сильною компресією, що покриває як низькі, так і високі бітрейти.
MPEG-4 - це не тільки кодек відео, використовуваний для стиснення DVD. Фактично кодування/декодування відео - це тільки одна частина стандарту. На додаток до кодування відео, ще є звукове кодування, синтезоване відео і звук, інтерактивність, доставка контенту.
Стандарт MPEG-4 відкритий, що означає, що будь-хто може отримати специфікації і реалізувати їх. Це приводить до змагання реалізацій, які теоретично повинно знизити ціни і збільшити якість продукції. Відкритий стандарт також дозволяє усунути пастки єдиного коду, як наприклад, відсутність модифікацій і усунення дефектів.
Файл відео складається з серій послідовних зображень - фреймів, або візуальних об'єктних площин (VOP) в термінах MPEG-4. Сьогодні більшість кодеків відео, зокрема, MPEG-4 - блочні. У блочних кодах, VOP діляться на блоки одної розмірності - квадрати, наприклад 8x8 або 16x16 пікселів. Вони називаються макроблоками, і різні методи кодування застосовуються до цих макроблоків замість цілого VOP.
Відео може бути стиснене, маніпулюючи індивідуальними фреймами. Цей метод називається інтра-кодуванням, і стислий індивідуальний фрейм називається intra VOP (I-VOP). Через природу відео, два послідовні фрейми часто виглядають подібно один одному за вийнятком деякого руху об'єктів між двома фреймами. Замість стиснення індивідуальних послідовних фреймів, сучасний кодек використовує різні методи кодування, які враховують цю схожість в серіях фреймів. Це інтеркодування використовується для досягнення вищої компресії. Наприклад, в прогнозованому кодуванні, тільки різниця між двома зображеннями запам'ятовується. Це приводить до сильної компресії, коли фрейми більш подібні один одному. Прогнозоване кодування не працює ефективно в ситуаціях, де великі частини зображення перемістилися між двома фреймами як при панорамній зйомці. В даному випадку використовується техніка, яка називається прогноз компенсування руху. Прогноз компенсування руху призначає вектор руху кожному макроблоку і пробує знайти краще можливе представлення фрейма з макроблоками від довідкового фрейма, який перемістився в напрямі вектору руху. Фрейм, який використовує попередній фрейм як довідковий, називається передбаченим VOP (P-VOP) У цьому прикладі більшість даних фрейма може бути представлене тільки одним вектором руху і попереднім фреймом як довідковим (рис.2.12).

Рис.2.12. Прогноз компенсації руху
Прогноз компенсування руху може також бути застосований двома шляхами. Фрейм, який використовує попередній фрейм, як довідковий називається реверсивно передбачений VOP (B-VOP). Декодування B-VOP вимагає більшої пам'яті і обробки, ніж декодування P-VOP, тому що дешифратору доведеться утримувати два довідкові фрейми в пам'яті замість одного.
Блочні кодеки в загальному використовують дискретне косинусне перетворення (DCT) в об'єднанні з квантуванням для стиснення природних даних. DCT - це математичний метод для перетворення статичного зображення в частотний домен. Це означає, що замість представлення зображення як серії кольорових значень, зображення представляється серією коефіцієнтів дійсного значення функції косинуса. Скорочуючи кількість біт для представлення кожного коефіцієнту, кодек може досягти сильної компресії. Цей метод називається квантуванням, і впливає на якість. Різні методи квантування можуть зробити наголос на різних областях (наприклад, дрібні деталі) [17].
2.2
Опис алгоритму
Методом детекції обличчя у відеопотоці в даній програмі було обрано апарат штучних нейронних мереж, розпізнавання облич реалізовано методом "власні вектори". Дані методи забезпечують високу продуктивність при мінімальних витратах ресурсів комп’ютера. Алгоритм програми поданий на рис.2.13.

Згідно технічного завдання вхідними параметрами для програми повинен бути відеопоток і база відомих облич, з якими необхідно співставити знайдені. В зв’язку з описаними вимогами до вхідних даних, в програмі реалізовано модуль роботи з веб-камерою.
Згідно технічного завдання на розробку вихідними даними є знайдені у відеопотоці зображення облич та їх класифікація згідно вхідної бази даних. Тому було вирішено не не зберігати вихідні дані, а детекцію і розпізнавання проводити інтерактивно.
Основною вимогою до складу технічних засобів є наявність веб-камери в складі ЕОМ. Вибір веб-камери зумовлений в першу чергу постановкою задачі. Перевагами даного пристрою відеовведення порівнянні з іншими є:
стандартизованість обміну даними;
наявність великої кількості інформації по організації роботи з данимпристроєм;
порівняно невисока ціна;
відносна швидкість отримання відеопотоку.
Вимоги до параметрів ЕОМ визначаються загалом вимогами операційної системи до характеристик ЕОМ. Сама програма вимагає 1 Мб вільного місця на жорсткому диску та 5 Мб оперативної пам’яті.
Вимоги до об’єму оперативної пам’яті - мінімум 128 Мб зумовлені вимогами операційної системи.
Вимоги до об’єму жорсткого диску - мінімум 1Гб зумовлені вимогами операційної системи.
Обов’язковою вимогою до програмних засобів є наявність встановленої операційної системи Windows XP. Операційна система Windows XP була обрана в зв’язку з тим, що вона містить багато системних об’єктів для доступу до апаратних ресурсів.
В якості середовища розробки програми було обрано інтегроване середовище розробки додатків Microsoft Visual C++, оскільки воно забезпечує швидку та зручну розробку графічних додатків, дозволяє проводити збереження даних у файли, має засоби для інтеграції коду на мові асемблер в код програми на мові C++, містить зручну систему налагодження програм.
Розрахуємо витрати праці, виходячи з того, що розмір вихідного тексту програми в основному визначає затрати праці і
та час розробки 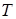 програмного продукту: програмного продукту:
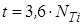 , (3.1) , (3.1)
де 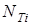 - кількість вихідних команд в тисячах. - кількість вихідних команд в тисячах.
В якості вихідної команди приймаємо рядок програми. Загальний об'єм вихідного тексту програми-додатка складає приблизно 2000 рядків. Тоді:
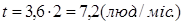
Продуктивність праці розробників програмного забезпечення визначається наступним чином:
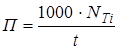 (3.2) (3.2)
Тоді ми отримуємо, що продуктивність праці розробників:
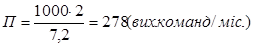
Час необхідний для розробки програмного продукту, можна визначити за формулою:  , (3.3) , (3.3)
де  - період розробки програмного продукту; - період розробки програмного продукту; 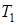 - коефіцієнт вірності постановки завдання; - коефіцієнт вірності постановки завдання; 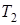 - час розробки алгоритму; - час розробки алгоритму; 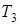 - час настройки та тестування; - час настройки та тестування; 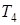 - час на підготовку тексту; - час на підготовку тексту; 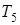 - час на розробку документації. - час на розробку документації.
Зазначені величини обчислюються по наступним формулам:
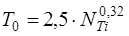 , (3.4), , (3.4), 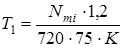 , (3.5) , (3.5)
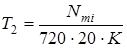 , (3.6), , (3.6), 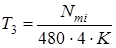 , (3.7) , (3.7)
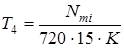 , (3.8), , (3.8), 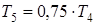 , (3.9) , (3.9)
де К - залежить від ступеня підготовки програміста;
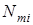 - кількість рядків програми. - кількість рядків програми.
Підставляємо значення в останні формули враховуючи, що К=0,8 (стаж роботи до 2-х років).
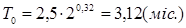 , , 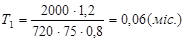
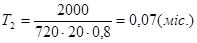 , , 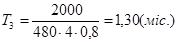
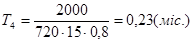 , , 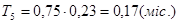
Тоді час, який необхідний для розробки програмного продукту дорівнює:
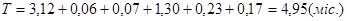 . .
Визначимо собівартість години роботи ПК. Для цього розраховуються поточні витрати на експлуатацію ПК. До їх складу включаються витрати на електроенергію і амортизаційні відрахування від вартості ПК та інше.
Витрати на електроенергію визначають множенням витрати електроенергії за одну годину на вартість 1 кВт/год електроенергії і на час роботи ПК за рік. Час роботи комп'ютера за рік визначається множенням кількості робочих днів у рік на час роботи комп'ютера за день:
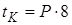 , (3.10) , (3.10)
де 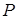 - середня кількість робочих днів у рік. - середня кількість робочих днів у рік.
Таким чином:
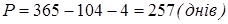 . .
Тоді, час роботи ПК за рік дорівнює
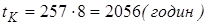 . .
Витрати енергії визначаються за формулою:
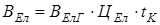 , (3.11) , (3.11)
де  - витрати електроенергії за одну годину; - витрати електроенергії за одну годину;
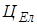 - вартість 1 кВт/год електроенергії; - вартість 1 кВт/год електроенергії;
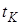 - час роботи комп’ютера за рік. - час роботи комп’ютера за рік.
Тоді витрати енергії складають:
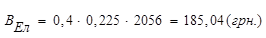 . .
Амортизаційні відрахування визначаються множенням вартості комп'ютера на норму амортизаційних відрахувань 10%:
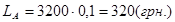 . .
Річна заробітна плата обслуговуючого персоналу (інженера з місячним посадовим окладом 600 грн.) складає:
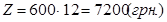 . .
Відрахування на соціальне страхування складають 3% від загальної заробітної плати за рік:
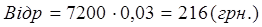 . .
Вартість витрачених матеріалів складає 2% від вартості обчислювальної техніки:
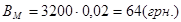 . .
Утримання на ремонт приміщень, в яких знаходяться засоби обчислювальної техніки, складає 3% від вартості обчислювальної техніки:
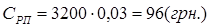 . .
Кількість комп'ютерів, на яких працюватиме програма: 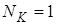 . .
Собівартість години роботи на комп'ютері визначається співвідношенням:
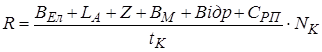 . (3.12) . (3.12)
Підставляємо значення в останню формулу й отримаємо:
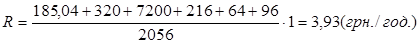 . .
Розраховуємо прямі витрати на виконання магістерської роботи, які визначаються добутком:
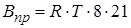 , (3.13) , (3.13)
де 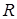 - собівартість години роботи на комп’ютері; - собівартість години роботи на комп’ютері; 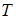 - час необхідний для розробки програмного продукту. Підставляємо значення й одержуємо: - час необхідний для розробки програмного продукту. Підставляємо значення й одержуємо:
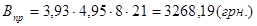 . .
Накладні витрати, що включають витрати на освітлення, опалення і т.п., приймаються в розмірі 40-50% від суми прямих витрат:
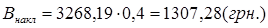 . .
Загальні витрати на виконання магістерської роботи:
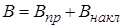 . (3.14) . (3.14)
Підставляємо дані й одержуємо:
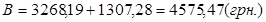
Ціна програмного продукту визначається співвідношенням:
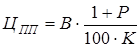 , (3.15) , (3.15)
де В - витрати на виконання дипломного проекту;
P - рівень рентабельності, в нашому випадку P = 10;
K - коефіцієнт, що залежить від науково-технічного рівня, в нашому випадку К = 1,3.
Підставляємо ці значення й отримаємо ціну програмного продукту, яка дорівнює:
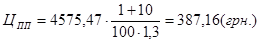 . .
Річний економічний ефект визначається таким чином:
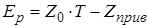 , (3.16) , (3.16)
де  - витрати на розв’язання задачі традиційними методами; - витрати на розв’язання задачі традиційними методами;
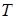 - періодичність розв’язку задачі, для нашого випадку T=100; - періодичність розв’язку задачі, для нашого випадку T=100;
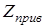 - приведені витрати. - приведені витрати.
Для визначення параметру 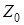 використовується формула: використовується формула:
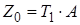 , (3.17) , (3.17)
де 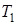 - трудомісткість на складання документу, вимірюється в годинах; - трудомісткість на складання документу, вимірюється в годинах;
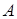 - заробітна плата виконавця за одну годину. - заробітна плата виконавця за одну годину.
Підставляємо значення в останню формулу й одержуємо:
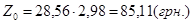 . .
Для визначення параметру 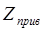 використовується формула: використовується формула:
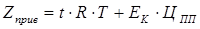 , (3.18) , (3.18)
де 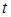 - загальний об’єм вихідного тексту програмного додатка; - загальний об’єм вихідного тексту програмного додатка;
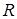 - собівартість години роботи на комп’ютері; - собівартість години роботи на комп’ютері;
- продуктивність праці розробників програмного забезпечення;
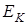 - нормативно-галузевий коефіцієнт ( - нормативно-галузевий коефіцієнт (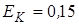 ); );
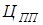 - ціна програмного продукту. - ціна програмного продукту.
Отже, приведені витрати дорівнюють:
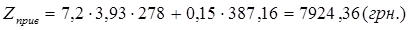 . .
Таким чином, річний економічний ефект рівний:
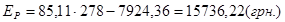 . .
1. Головко В.В. Нейроинтеллект: Теория и применения. Книга 1. Организация и обучение нейронных сетей с прямыми и обратными связями. - Брест: БПИ, 1999. - 260 с.
2. Sung K.,Poggio T. Learning Human Face Detection in Cluttered Scene // Computer Analysis of Images and Patterns. - 1995. - №4. - P.432-439.
3. Graham D.,Allinson N. Face Recognition Using Virtual Parametric Eigenspace
Signatures // Image Processing and its Applications. - 1997. - №21. - P.123-129.
4. Belhumeur P., Hespanha J. Eigenfaces vs Fisherfaces: Recognition Using Class Specific Linear Projection // IEEE Transactions on Pattern Analysis and Machine Intelligence. - 1997. - №19. - P.711-720.
5. Hallinan P.,Gordon G. Two - and Three-Dimensional Patterns of the Face. - Natick: A. K. Peters Ltd., 1999. - 260 p.
6. Lanitis A.,Taylor C. Automatic Interpretation and Coding of Face Images Using Flexible Models // IEEE Transactions on Pattern Analysis and Machine Intelligence. - 1997. - №19. - P.743-756.
7. Wiskott L.,Fellous J. - M. Face Recognition by Elastic Bunch Graph Matching // IEEE Transactions on Pattern Analysis and Machine Intelligence. - 1997. - №19. - P.775-779.
8. Duc B.,Fischer S. Face Authentication with Gabor Information on Deformable Graphs // IEEE Trans. on Pattern Analysis and Machine Intelligence. - 1999. - №8. - P.504-516.
9. Wurtz R. Object Recognition Robust Under Translations, Deformations, and Changes in Background // IEEE Transactions on Pattern Analysis and Machine Intelligence. - 1997. - №19. - P.769-775.
10. Grudin M.,Lisboa P.compact Multi-level Representation of Human Faces for Identification // Image Processing and its Applications. - 1997. - №4. - P.111-115.
11. Самаль Д. B., Старовойтов В. K. Выбор признаков для распознавания на основе статистических данных // Цифровая обработка изображений. - 1999. - №3. - P.100-114.
12. Gutta S.,Wechsler H. Face Recognition Using Hybrid Classifiers // Pattern
Recognition. - 1997. - №30. - P.539-553.
13. Самаль Д. B., Старовойтов В. K. Методика автоматизированного распознавания людей по фотопортретам // Цифровая обработка изображений. - 1999. - №4. - P.81-85.
14. Самаль Д. B. Построение систем идентификации личности на основе антропометрических точек лица // Цифровая обработка изображений. - 1998. - №2. - P.72-79.
15. Brunelli R.,Poggio T. Face Recognition: Features Versus Templates // IEEE Transactions on Pattern Analysis and Machine Intelligence. - 1993. - №15. - P.235-241.
16. Хорн Б. Зрение роботов. -М.: Мир, 1989. - 488 c.
17. Кейт Д. Видео без секретов, 4-е изд. -М.: Вильямс, 2005. - 953 с.
18. Люгер Л., Джордж Ф. Искусственный интелект: стратегии и методы решения сложных проблем, 4-е изд. -М.: Вильямс, 2005. - 864 с.
19. Viola P.,Jones M. Object Robust Real-Time Face Detection // IEEE Transactions on Pattern Analysis and Machine Intelligence. - 2004. - №26. - P.435-440.
|

