Міністерство освіти і науки України
Курсова робота на тему:
"Порівняльний аналіз ефективності та складності прямих алгоритмів сортування масивів"
Зміст
Вступ
Розділ І. Алгоритми, методи сортування
Розділ ІІ. Прямі методи сортування масивів
2.1 Сортування прямим включенням
2.2Сортування бінарним включенням
2.3 Сортування прямим вибором
2.4 Сортування прямим обміном
2.4.1 Метод "бульбашки"
2.4.2 Метод "камінця"
2.4.3 Метод шейкерного сортування
2.5 Порівняння прямих методів сортування масивів
Розділ ІІІ. Огляд функцій сортування із стандартної бібліотеки С++
Висновки
Література
Вступ
Мало яка людина зараз уявляє своє життя без комп’ютера та комп’ютерних технологій. Комп’ютери є скрізь, і в дома і на роботі, і в супермаркеті і на станції технічного обслуговування. Використання комп’ютерної техніки використовується у всіх областях життєдіяльності людини. Тому, різноманіття програмного забезпечення теж вражає.
Розробкою програмного забезпечення займається така галузь науки, як програмування. Саме на програмістах лежить відповідальність за створенні та реалізації різноманітних алгоритмів обробки певних задач. І інколи від вибору того чи іншого алгоритму залежить подальша доля програмного проекту.
Програмування містить цілу низку важливих внутрішніх задач. Однією з найбільш важливих таких задач для програмування є задача сортування. Під сортуванням звичайно розуміють перестановки елементів будь-якої послідовності у визначеному порядку. Наприклад, потрібно відсортувати оцінки за екзамен від мінімальної оцінки до максимальної чи навпаки. Інший приклад – список неправильно вимовляємих слів, відсортований в алфавітному порядку. Особисті дані студентів можна відсортувати або по номеру студентського квитка, або в алфавітному порядку по імені студента. Всі ці задачі мають на меті впорядкування (сортування) за певною ознакою.
Взагалі, відомо, що в будь-якій сфері діяльності, що використовує комп’ютер для запису, обробки та збереження інформації, усі дані зберігаються в базах даних, які також потребують сортування. Певна впорядкованість для них дуже важлива, адже користувачеві набагато легше працювати з даними, що мають певний порядок. Так, можна розташувати всі товари по назві або відомості про співробітників чи студентів за прізвищем або роком народження, тощо.
Реклама

Задача сортування в програмуванні не вирішена повністю. Адже, хоча й існує велика кількість алгоритмів сортування, все ж таки метою програмування є не лише розробка алгоритмів сортування елементів, але й розробка саме ефективних алгоритмів сортування. Ми знаємо, що одну й ту саму задачу можна вирішити за допомогою різних алгоритмів і кожен раз зміна алгоритму приводить до нових, більш або менш ефективних розв’язків задачі. Основними вимогами до ефективності алгоритмів сортування є перш за все ефективність за часом та економне використання пам’яті. Згідно цих вимог, прості алгоритми сортування (такі, як сортування вибором і сортування включенням) не є дуже ефективними та більш простими у реалізації і наглядності.
Мета даної курсовоїроботи:
знайомство з теоретичним положенням, що стосуються прямих алгоритмів сортування, аналіз їх швидкодії і кількості використаних операцій порівняння та обміну, реалізація цих алгоритмів на мові програмування С++.
У курсовій роботі ми детально розглянемо прямі методи сортування елементів масиву, проведемо їх порівняльний аналіз, вкажемо на їх позитиви і недоліки, що дасть змогу краще визначити ефективність і площину застосування.
При реалізації програм ми будемо використовувати мову програмування високого рівня С++. Методи сортування даних можна реалізовувати на багатьох мовах програмування як високого так і низького рівня. Проте, на нашу думку, найкраще на мові програмування фірми Borland – С++ або ж Turbo Pascal. В нашому випадку ми віддали перевагу першій.
С++ побудована на основі мови С. Вона зберігає основні типи даних, операції, синтаксис операторів та структуру програми мови С (про це свідчить сама назва мови: "C" та "++"). Водночас, це зовсім інша мова, яка ввела в практику програмування новий технологічний підхід - об’єктно-орієнтоване програмування. Введення в практику програмування об’єктно-орієнтованої парадигми дозволяє значно підвищити рівень технології створення програмних засобів, скоротити затрати на розробку програм, їх повторне використання, розширити інтелектуальні можливості ЕОМ.
Предмет дослідження:
Прямі алгоритми сортування елементів масиву.
Об’єкт дослідження:
Реалізація прямих методів сортування елементів масиву на С++ та використання їх на практиці.
Реклама

Досягненням мети визначаються наступні завдання
:
1. Вивчити літературу по темі "Прямі алгоритми сортування масивів" їх реалізація на С++;
2. Проаналізувати прямі методи сортування, їх практичне застосування;
3. Реалізувати на мові С++ прямі алгоритми сортування: сортування прямим включенням, бінарним включенням, прямим вибором, прями обміном;
4. Розробити закінчений програмний продукт по темі дослідження.
Розділ І. Алгоритми, методи сортування
Алгоритми - система правил, сформульована на зрозумілій виконавцеві мові, що визначає процес переходу від припустимих вихідних даних до деякого результату й має властивості масовості, кінцівки, визначеності, детермінованості.
Слово "алгоритм" походить від імені великого середньоазіатського вченого 8-9 ст. Аль-Хорезми (Хорезм - історична область на території сучасного Узбекистану). З математичних робіт Аль-Хорезми до нас дійшли тільки дві - алгебраїчна (від назви цієї книги народилося слово алгебра) і арифметична. Друга книга довгий час вважалася загубленої, але в 1857 у бібліотеці Кембриджського університету був знайдений її переклад на латинську мову. У ній описані чотири правила арифметичних дій, практично ті ж, що використаються й зараз. Перші рядки цієї книги були переведені так: "Сказав Алгоритми. Віддамо належну хвалу Богу, нашому вождеві й захисникові". Так ім’я Аль-Хорезми перейшло в Алгоритми, звідки й з’явилося слово алгоритм. Термін алгоритм вживався для позначення чотирьох арифметичних операцій, саме в такім значенні він і ввійшов у деякі європейські мови. Наприклад, в авторитетному словнику англійської мови Webster’s New World Dictionary, виданому в 1957, слово алгоритм позначене позначкою "застаріле" і пояснюється як виконання арифметичних дій за допомогою арабських цифр.
Слово "алгоритм" знову стало вживаним з появою електронних обчислювальних машин для позначення сукупності дій, що становлять деякий процес. Тут мається на увазі не тільки процес рішення деякого математичного завдання, але й багато інших послідовних правил, що не мають відносини до математики, - всі ці правила є алгоритмами.
Аналогічно як існує алгоритм приготування борщу, існують алгоритми сортування масивів.
Способів сортування є дуже багато, ще більше є способів їх фізичної реалізації. Так, один і той самий метод можна реалізувати, спираючись на різні структури, методи і використання різних прийомів програмування. Тобто ми можемо використати як звичайний лінійний підхід до розв’язання задачі, так і процедурний, а можемо той самий алгоритм реалізувати з допомогою рекурсії.
Вибір алгоритму залежить від структури даних, що обробляються. У випадку сортування ця залежність настільки велика, що відповідні методи навіть були розбиті на дві групи - сортування масивів і сортування файлів (послідовностей). Іноді їх називають внутрішнім і зовнішнімі сортуванням, оскільки масиви зберігаються в швидкій внутрішній пам’яті (оперативній) із довільним доступом, а файли розміщуються в менш швидкій, проте більш об’ємній зовнішній пам’яті.
Метод сортування називається стійким,
якщо в процесі впорядкування відносне розміщення елементів з рівними значеннями не міняється. Стійкість сортування часто буває бажаним, якщо йде мова про елементи, що вже впорядковані по деяких вторинних ключах (тобто ознаках), які не впливають на основний ключ.
Нехай маємо масив елементів довільного типу (тут і надалі ми будемо працювати із масивом цілих чисел int mas[1000]
, за необхідності його досить легко переробити в масив дійсних чисел, символів, чи рядків. Тобто універсальність алгоритмів сортування полягає в тому, що вони практично не залежать від типу елементів масиву). Даний масив містить 1001
елемент, елемент з індексом 0
ми будемо використовувати лише в окремих випадках, і працюватимемо лише із певною частиною масиву з індексами 1 . . . n
, де n
– кількість елементів масиву, що потрібно відсортувати. Аналогічно, ми будемо сортувати ці масиви по зростанню, що аж ніяк не обмежує загальності.
Алгоритми сортування окрім критерію економії пам’яті будуть класифікуватися по швидкості, тобто по часу їх роботи. Оскільки на різних типах ЕОМ одні і ті ж методи показуватимуть відмінні результати, то в якості міри ефективності алгоритму можуть бути прийняті числа: C
- кількість необхідних порівнянь ключів; M
- кількість перестановок елементів. Очевидно, що ці числа є функціями від кількості елементів в масиві N
.
Методів сортування є досить багато, це прямі, та швидкі, які більш складні у реалізації але дають відмінні результати швидкості. Швидкі методи в основному реалізовані за рахунок введення додаткових конструкцій, як то дерева, стеки, черги.
До прямих методів належать:
- сортування прямим включенням;
- сортування бінарним включенням;
- сортування прямим вибором;
- сортування прямим обміном.
В основі прямих методів лежить повторення N
етапів обробки масиву із зменшенням на кожному з них кількості порівнюваних елементів. Ефективність даних алгоритмів є величиною порядку O(N
2
). Саме тому, їх ще називають квадратичними методами сортування. Такі методи зручно використовувати на так званих "коротких" масивах.
Зрозуміло, що крім самих методів сортування існує ще більше способів їх реалізації, які в певних випадках прискорюють їх роботу, а в певних випадках їх пригальмовують. Так, для прикладу алгоритм сортування Шела можна реалізувати використовуючи рекурсивні запити, а можна і лінійним програмуванням. Для прикладу, обмін елементів масиву використовуючи операції віднімання та додавання відбувається в загальному швидше ніж введення тимчасової змінної із подальшим її переприсвоєнням.
Розділ ІІ. Прямі методи сортування масивів
2.1
Сортування прямим включенням
В основі розглядуваного методу лежить пошук для чергового елемента масиву відповідного місця у відсортованій частині із наступним включенням його в знайдену позицію. Таким чином елементи масиву умовно діляться на дві групи - вже "готову" послідовність mas[1], mas[2], … ,mas[i]
та вихідну послідовність. На кожному етапі, починаючи з i=2
та збільшуючи i
кожен раз на 1
, із вихідної послідовності вибирається один елемент і вставляється в потрібне місце у вже впорядковану послідовність. Очевидно, що початкова ліва послідовність буде "готовою", оскільки одноелементний масив завжди впорядкований. Продовжуючи по аналогії, в кінці-кінців отримаємо впорядкований список, що містить всі елементи масиву, а новий список відповідно збільшиться. Для реалізації цього алгоритму можна використовувати інший масив, куди будуть добавлятися скопійовані в потрібне місце елементи другого масиву, а можна використовувати той же масив, адже зрозуміло, що один масив росте із тією ж швидкістю що і інший зменшується.
Даний алгоритм можна показати наочно наступним чином:

Розглянемо реалізацію даного алгоритму на нашому масиві. Нехай маємо 7 елементів масиву mas
із індексами від 0
до 7
. Елемент mas[0]
відіграє роль бар’єра, що використовуватиметься нами для обміну елементами і спростить реалізацію алгоритму. Використання додаткового елемента в масиві - "бар’єра" mas[0]=x
забезпечує гарантоване припинення процесу просіювання. Це дозволяє зменшити кількість логічних умов в заголовку циклу while
до однієї, а кількість логічних операцій від 2i-1
до i
на кожному етапі. Звичайно, при цьому необхідно попередньо розширити на один елемент масив a
та діапазон допустимих значень індексу. На жаль, таке покращення ефективності по кількості порівнянь не зменшує об’єму перестановок елементів.
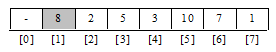
Елемент масиву mas[1]
, виділений, щоб підкреслити те, що навіть в вихідному стані цю область можна розглядати як невеликий, окремо-впорядкований масив. Фактично, робота алгоритму починається із другого елемента масиву mas[2]
, до "впорядкованого масиву", в якому тепер будуть знаходитися два елементи.
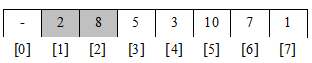
Таким чином, перші два елементи (2, 8) утворюють невеликий впорядкований список, и нам необхідно додати до нього решту елементів (5, 3, 10, 7, 1). Після добавлення числа 5 отримаємо наступну картинку.
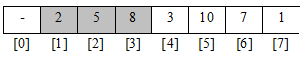
Продовжуючи процес, беремо наступний необроблений елементі вставляємо його в відповідне місце впорядкованого масиву. При цьому з кожнам разом розмір упорядкованої частину збільшується, а інша частина масиву зменшується на ту ж саму величину. В результаті розмір впорядкованого масиву стане рівним розміру початкового масиву, і сортування можна вважати закінченим. На практиці даний процес можна записати так:
For (i=2;i<n;i++)
Вставити елемент mas[i] в упорядковану частину масиву
Операція вставки елемента mas[i]
виконується в три кроки, що ми зараз і продемонструємо для і=4
.
1. Зберігаємо копію вставляємого числа.
В даному прикладі елемент mas[4]
копіюємо в mas[0]
, який ми спеціально для цього і не використовували для запису масиву.
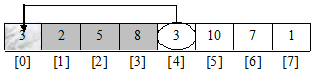
2. Проводимо здвиг вправо елементи, розміщені до mas[i], поки не буде знайдено потрібне місце під вставку елемента.
В нашому випадку спочатку потрібно здвинути вправо число 8, а потім – число 5, як показано на рисунку.

3. Помістити нове значення на потрібне місце.
Для даного прикладу число 3 вставляємо в масив із mas[0]
.

Процес просіювання (пошуку потрібного місця для включення елемента x
) може припинитися при виконанні однієї із двох умов :
1) знайдено елемент a j
з ключем, меншим ніж ключ у x
;
2) досягнутий лівий кінець "готової" послідовності.
Таким чином програмна реалізація методу прямого включення матиме вигляд (Файл SORT_1.CPP):
#include <conio.h>
#include <iostream.h>
#include <stdlib.h>
int mas[1000];
void vuv(int s)
{ for(int i=1;i<=s;i++)
cout<<mas[i]<<‘ ‘;
cout<<endl<<"--------------------------------"<<endl;
}
main()
{clrscr();
cout<<"Vvedit kilkist elementiv masuvy - n"<<endl;
int n,tmp,k;
cin>>n;
for (int i=1;i<=n;i++)
{
cout<<"vvedit "<<i<<" -element masuvy"<<endl;
cin>>mas[i];
}
clrscr();
cout<<"Maemo masuv "<<endl;
vuv(n);
//Sort_prjamojy vstavkojy
for (int j=2;j<=n;j++)
{
tmp=mas[j]; mas[0]=tmp; i=j;
while (tmp<mas[j-1])
{
mas[j]=mas[j-1];
j--;
}
mas[j]=tmp;
}
cout<<"Masuv vidsortovanuy "<<endl;
vuv(n);
getch();
return 0;
}
Аналіз прямого включення.
Кількість порівнянь ключів Ci
при i
-ому просіюванні найбільше дорівнює i
, найменше - 1
, а середньоймовірна кількість - i/2
. Кількість же перестановок (переприсвоєнь ключів), включаючи бар’єр, Mi
=Ci
+2
. Тому для оцінки ефективності алгоритму у випадках початково впорядкованого, зворотньо впорядкованого та довільного масиву можна скористатися наступними співвідношеннями:
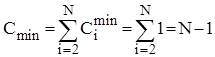 ; ;
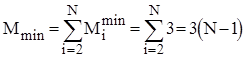 ; ;
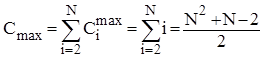 ; ;
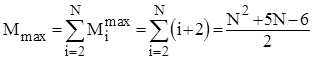 ; ;
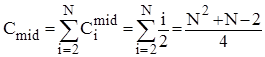 ; ;
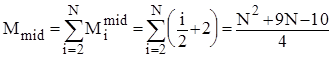 . .
Очевидно, що розглянутий алгоритм описує процес стійкого сортування. Загальна кількість операцій буде рівня (n-1
), що відповідатиме при обрахунку кількості операцій O(n2
). Тому найгірший час сортування вставками дійсно є квадратичним.
2.2 Сортування бінарним включенням
Алгоритм прямого включення можна значно покращити, якщо врахувати, що "готова" послідовність є вже впорядкованою. Тому можна скористатися бінарним пошуком точки включення в "готову" послідовність. Тобто даний метод містить в собі метод бінарного пошуку елемента (пошук бінарним деревом) в масиві, в даному випадку – місця між елементами, де повинен бути розміщений даний елемент. Тому що пошук місця під наступний елемент можна зобразити як рух по дереву, від "стовбура" до "кореня". На першому кроці ділимо весь відсортований масив навпіл, далі порівнюємо даний елемент із елементами масиву з що посередині, якщо він менший, знову ділимо лівий підмасив, більший – правий. І так до тих пір поки не визначимо місце, де буде знаходитися даний елемент.
{l=1;r=j;tmp=mas[j];
while (l<r)
{
m=(r+l)/2;
if (mas[m]<=tmp) l=m+1; else r=m;
}
Нехай маємо впорядкований масив (8, 9, 10, 16, 18, 20, 35), покажемо жирним рух по бінарному дереву, для знаходження місця елементу = 19.

Програмна реалізація такого модифікованого методу включення матиме вигляд наступної програми (Файл SORT_2.СРР):
#include <conio.h>
#include <iostream.h>
#include <stdlib.h>
int mas[1000];
void vuv(int s)
{ for(int i=1;i<=s;i++)
cout<<mas[i]<<‘ ‘;
cout<<endl<<"--------------------------------"<<endl;
}
main()
{clrscr();
cout<<"Vvedit kilkist elementiv masuvy - n"<<endl;
int n,tmp,k;
cin>>n;
for (int i=1;i<=n;i++)
{
cout<<"vvedit "<<i<<" -element masuvy"<<endl;
cin>>mas[i];
}
clrscr();
cout<<"Maemo masuv "<<endl;
vuv(n);
//Sort_binarn vstavkojy
int l,r,m;
for (int j=2;j<=n;j++)
{l=1;r=j;tmp=mas[j];
while (l<r)
{
m=(r+l)/2;
if (mas[m]<=tmp) l=m+1; else r=m;
}
for (i=j;i>=(r+1);i--) mas[i]=mas[i-1];
mas[r]=tmp;
}
cout<<"Masuv vidsortovanuy "<<endl;
vuv(n);
getch();
return 0;
}
Аналіз бінарного включення.
Зрозуміло, що кількість порівнянь у такому алгоритмі фактично не залежить від початкового порядку елементів. Місце включення знайдено, якщо L=R
. Отже вкінці пошуку інтервал повинен бути одиничної довжини. Таким чином ділення його пополам на i
-ому етапі здійснюється log(i)
раз. Тому кількість операцій порівняння буде:
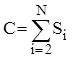 , де , де 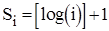 , , 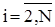 . .
Апроксимуючи цю суму інтегралом, отримаємо наступну оцінку :
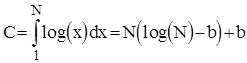 , де , де 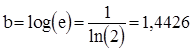 . .
Однак істинна кількість порівнянь на кожному етапі може бути більшою ніж log(i)
на 1
. Тому
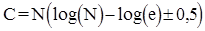 . .
Нажаль покращення, що породженні введенням бінарного пошуку, стосується лише кількості операцій порівняння, а не кількості потрібних переміщень елементів. Фактично кількість перестановок M
залишається величиною порядку N2
.
Для досить швидких сучасних ЕОМ рух елемента, тобто самого ключа і зв’язаної з ним інформації, займає значно більше часу, ніж порівняння самих ключів. Крім того сортування розглядуваним методом вже впорядкованого масиву за рахунок log(i)
операцій порівняння вимагатиме більше часу, ніж у випадку послідовного сортування з прямим включенням. Очевидно, що кращий результат дадуть алгоритми, де перестановка, нехай і на велику відстань, буде пов’язана лише з одним елементом, а не з переміщенням на одну позицію цілої групи.
2.3 Сортування прямим вибором
На відміну від включення, коли для чергового елемента відшукувалося відповідне місце в "готовій" послідовності, в основу цього методу покладено вибір відповідного елемента для певної позиції в масиві. Цей прийом базується на таких принципах :
1) на i
-ому етапі серед елементів mas[i], mas[i+1],…,mas[n]
вибирається елемент з найменшим ключем mas[j]=min
;
2) проводиться обмін місцями mas[j]
та mas[i]
.
Процес послідовного вибору і перестановки проводиться поки не залишиться один єдиний елемент - з самим найбільшим ключем.
Взагалі, існує декілька способів реалізації даного алгоритму. Можна використовувати два масиви і копіювати елементи в потрібному порядку із одного масиву в другий. Проте, це є більш затратний спосіб. Наведемо графічний аналіз реалізації самого методу. Нехай маємо задачу, на прикладі масиву, зображеного нижче. Спробуємо впорядкувати цей масив по зростанню.
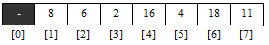
На першому кроці переглядаємо весь масив від індексу 1
до індексу n
(в даному випадку n=7
) з метою пошуку найменшого елемента масиву. Далі беремо цей індекс на кожному кроці записуємо в комірку з індексом 0
. По закінченню проходження циклу міняємо елементи з індексом і-
початкове та елемент індекс якого записаний у комірці під номером 0
.

Дальше переглядаємо масив вже без першого елемента, оскільки ж відомо що в ньому записаний найменший елемент масиву.
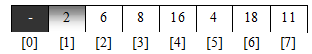
Маємо, що мінімальний елемент решти масиву знаходиться в позиції 5
, при його пошуку індекс заноситься в комірку з індексом 0
. Знову проводимо обмін.

Запишемо саму програму реалізації даного методу (Файл SORT_3.CPP):
#include <conio.h>
#include <iostream.h>
#include <stdlib.h>
int mas[1000];
void vuv(int s)
{ for(int i=1;i<=s;i++)
cout<<mas[i]<<‘ ‘;
cout<<endl<<"--------------------------------"<<endl;
}
main()
{clrscr();
cout<<"Vvedit kilkist elementiv masuvy - n"<<endl;
int n,tmp,k;
cin>>n;
for (int i=1;i<=n;i++)
{
cout<<"vvedit "<<i<<" -eltment masuvy"<<endl;
cin>>mas[i];
}
clrscr();
cout<<"Maemo masuv "<<endl;
vuv(n);
//Sort_prjamum vuborom
for(int j=1;j<n;j++)
{
k
]=j;
for(i=j+1;i<=n;i++)
if (mas[i]<mas[k]) {
k
]=i;}
mas[0]=mas[k]; mas[k]=mas[j]; mas[j]=mas[0];
}
cout<<"Masuv vidsortovanuy "<<endl;
vuv(n);
getch();
return 0;
}
Аналіз прямого вибору.
Очевидно, що кількість порівнянь ключів Ci
на i
-ому виборі не залежить від початкового розміщення елементів і дорівнює N-i
. Таким чином
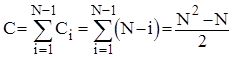
Кількість же перестановок залежить від стартової впорядкованості масиву. Це стосується переприсвоєнь у внутрішньому циклі по j
при пошуку найменшого ключа. В найкращому випадку початково впорядкованогомасиву Mi
=4
; в найгіршому випадку зворотно впорядкованогомасиву Mi
=Ci
+4 ;
для довільного масиву рівномовірно можливе значення Mi
=Ci
/2+4.
Тому для оцінки ефективності алгоритму по перестановках можна скористатися наступними співвідношеннями:
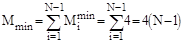 ; ;
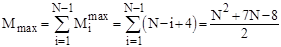 ; ;
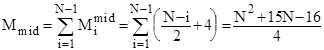 . .
Як і в попередньому випадку алгоритм прямого вибору описує процес стійкого сортування.
2.4 Сортування прямим обміном
Даний метод базується на повторенні етапів порівняння сусідніх ключів при русі вздовж масиву. Якщо наступний елемент виявиться меншим від попереднього, то відбувається обмін (звідси і назва методу). Таким чином, при русі з права наліво за один етап найменший ключ переноситься на початок масиву. Зрозуміло, що кожен наступний прохід можна закінчувати після позиції знайденого на попередньому етапі мінімального елемента, оскільки всі елементи перед ним вже впорядковані. Розглядуваний процес дещо нагадує виштовхування силою Архімеда бульбашки повітря у воді. Тому цей алгоритм ще називають "бульбашковим" сортуванням. Аналогічно, метод "камінця" базуються на зворотній дії. Тобто, якщо етапи порівняння та обміну проводити зліва направо, то відбуватиметься виштовхування найбільшого елемента вкінець масиву. Очевидно такий процес відповідає опусканню під дією сили тяжіння камінця у воді.
Обидва алгоритми згідно із визначаючим принципом вимагають досить великої кількості обмінів. Тому виникає питання, чи не вдасться підвищити їх ефективність хоча б за рахунок зменшення операцій порівняння? Цього можна добитися при допомозі наступних покращень:
1) фіксувати, чи були перестановки в процесі деякого етапу. Якщо ні, то - кінець алгоритму ;
2) фіксувати крім факту обміну ще і положення (індекс) останнього обміну. Очевидно, що всі елементи перед ним або після нього відповідно для сортування "бульбашкою" або "камінцем" будуть впорядковані;
3) почергово використовувати алгоритми "бульбашки" і "камінця". Тому що для чистої "бульбашки" за один прохід "легкий" елемент виштовхується на своє місце, а "важкий" опускається лише на один рівень. Аналогічна ситуація з точністю до навпаки і для "камінця". Такий алгоритм називається "шейкерним" сортуванням.
2.4.1
Метод
"бульбашки
"
Проведемо більш детальний розгляд методу бульбашки. Нехай маємо масив mas
, який необхідно впорядкувати за зростанням.

На першому етапі перевіряємо чи елемент із номером [і-1]
не є більший за елемент з номером [i]
, якщо так, то міняємо місцями. Далі зменшуємо і на 1 з нову проводимо порівняння до тих пір поки і
не рівне j
(на першому проході = 2). Зробивши перший прохід масиву, ми матимемо на місці 1 елемента найменший. Проходить якби виштовхування найменшого в ліву частину масиву.


Отже, після першого проходу маємо масив, де перший елемент з індексом [1] є вже впорядкований.

Далі аналогічним чином проводимо впорядкування іншої частини масиву, на другому кроці і
буде змінюватися від n
(n=7
у даному прикладі) до 3
.
Запишемо саму програму реалізації даного методу (Файл SORT_4.CPP):
#include <conio.h>
#include <iostream.h>
#include <stdlib.h>
int mas[1000];
void vuv(int s)
{ for(int i=1;i<=s;i++)
cout<<mas[i]<<‘ ‘;
cout<<endl<<"--------------------------------"<<endl;
}
main()
{clrscr();
cout<<"Vvedit kilkist elementiv masuvy - n"<<endl;
int n,tmp,k;
cin>>n;
for (int i=1;i<=n;i++)
{
cout<<"vvedit "<<i<<" -eltment masuvy"<<endl;
cin>>mas[i];
}
clrscr();
cout<<"Maemo masuv "<<endl;
vuv(n);
//Sort_Bulbashka
for(int j=2;j<=n;j++)
for(i=n;i>=j;i--)
{
if (mas[i-1]>mas[i]){
tmp=mas[i];mas[i]=mas[i-1];mas[i-1]=tmp;
}
cout<<"Masuv vidsortovanuy "<<endl;
vuv(n);
getch();
return 0;}
2.4.2 Метод
"камінця
"
Даний метод мало чим відрізняється від методу "бульбашки", тому наведемо лише його реалізацію (Файл SORT_5.CPP):
#include <conio.h>
#include <iostream.h>
#include <stdlib.h>
int mas[1000];
void vuv(int s)
{ for(int i=1;i<=s;i++)
cout<<mas[i]<<‘ ‘;
cout<<endl<<"--------------------------------"<<endl;
}
main()
{clrscr();
cout<<"Vvedit kilkist elementiv masuvy - n"<<endl;
int n,tmp,k;
cin>>n;
for (int i=1;i<=n;i++)
{
cout<<"vvedit "<<i<<" -eltment masuvy"<<endl;
cin>>mas[i];
}
clrscr();
cout<<"Maemo masuv "<<endl;
vuv(n);
//Sort_kamin
for (int j=1;j<n;j++)
for (i=1;i<=(n-j);i++)
{
if (mas[i]>mas[i+1]){
tmp=mas[i];mas[i]=mas[i+1];mas[i+1]=tmp;
}
}
cout<<"Masuv vidsortovanuy "<<endl;
vuv(n);
getch();
return 0;}
2.4.3 Метод шейкерного сортування
Якщо розглянути необхідну кількість дій, що виконується при сортуванні „бульбашковим" методом чи методом „камінця" то вона має порядок O(n2
)
. Зовнішній цикл виконується (n-1)
раз, а на кожному його кроці внутрішній цикл виконується, в середньому, n
на 2
раз. Взагалі, „бульбашкове" сортування відноситься до найменш ефективних методів. Дещо покращати його можна, чергуючи порядок проходу масиву та зупиняючись, коли всі елементи відсортовано. Такий модифікований алгоритм дістав назву „шейкерного" сортування.
Нижче наведемо реалізацію цього методу (Файл SORT_6.CPP):
#include <conio.h>
#include <iostream.h>
#include <stdlib.h>
int mas[1000];
void vuv(int s)
{ for(int i=1;i<=s;i++)
cout<<mas[i]<<‘ ‘;
cout<<endl<<"--------------------------------"<<endl;
}
main()
{clrscr();
cout<<"Vvedit kilkist elementiv masuvy - n"<<endl;
int n,tmp,k;
cin>>n;
for (int i=1;i<=n;i++)
{
cout<<"vvedit "<<i<<" -eltment masuvy"<<endl;
cin>>mas[i];
}
clrscr();
cout<<"Maemo masuv "<<endl;
vuv(n);
//Sort_Sheikerne
int l,r;
l=2; r=n; k=r;
while (l<r)
{
for(int j=l;j<=r;j++)
if (mas[j]<mas[j-1]) {tmp=mas[j];mas[j]=mas[j-1];mas[j-1]=tmp;k=j;}
r=k-1;
for(j=r;j>=l;j--)
if (mas[j]<mas[j-1]) {tmp=mas[j];mas[j]=mas[j-1];mas[j-1]=tmp;k=j;}
l=k+1;
}
cout<<"Masuv vidsortovanuy "<<endl;
vuv(n);
getch();
return 0;
}
Аналіз алгоритмів на основі прямого обміну.
Розглянемо спочатку чисту "бульбашку". Для "камінця" оцінки будуть такими ж самими. Зрозуміло, що кількість порівнянь ключів Ci
на i
-ому проході не залежить від початкового розміщення елементів і дорівнює N-i
. Таким чином
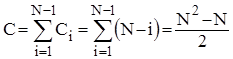
Кількість же перестановок залежить від стартової впорядкованості масиву. В найкращому випадку початково-впорядкованогомасиву Mi
=0
; в найгіршому випадку зворотно-впорядкованогомасиву Mi
=Ci
*3;
для довільного масиву рівноймовірно можливе значення Mi
=Ci
*3/2.
Тому для оцінки ефективності алгоритму по перестановках можна скористатися наступними співвідношеннями:
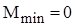 ; ;
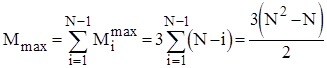 ; ;
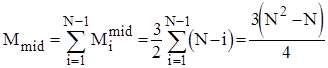 . .
Очевидно, що і цей алгоритм, аналогічно з іншими прямими методами, описує процес стійкого сортування.
Розглянемо тепер покращений варіант "шейкерного" сортування. Для цього алгоритму характерна залежність кількості операцій порівняння від початкового розміщення елементів в масиві. В найкращому випадку вже впорядкованої послідовності ця величина буде 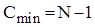 . У випадку зворотно-впорядкованогомасиву вона співпадатиме з ефективністю для чистої "бульбашки". . У випадку зворотно-впорядкованогомасиву вона співпадатиме з ефективністю для чистої "бульбашки".
Як видно, всі покращення не змінюють кількості переміщень елементів (переприсвоєнь), а лише зменшують кількість повторюваних порівнянь. На жаль операція обміну місцями елементів в пам’яті є "дорожчою" ніж порівняння ключів. Тому очікуваного виграшу буде небагато. Таким чином "шейкерне" сортування вигідне у випадках, коли відомо, що елементи майже впорядковані. А це буває досить рідко.
2.5 Порівняння прямих методів сортування масивів
З метою порівняння методів сортування масивів було виконано тестування. Для кожного методу за алгоритмом було написано підпрограму на С++, після чого виконано тестування для масивів цілих чисел розміром 1024, 4096 та 16384. Результати тестування (кількість секунд з точністю до сотих) на комп’ютері Pentium-II/450 наведено у таблиці. Для кожного розміру масиву використовувалось 3 способи його побудови:
1) вже впорядкований за зростанням масив;
2) масив, впорядкований за спаданням;
3) масив з випадкових чисел.
24 4096 16384
Прямим включ.
.00 0.05 0.00 .00 0.88 0.44 .00 14.01 6.98
Бінарним включ.
.00 0.06 0.06 .00 0.61 0.28 .05 9.67 4.83
Прямим вибором
.06 0.05 0.00 .50 0.49 0.49 .30 8.46 8.29
Бульбашка/Кам
інець
.00 0.11 0.11 .54 1.70 1.21 .73 27.79 19.45
Шейкерне
.00 0.11 0.05 .00 1.71 0.99 .00 27.30 15.82
Результати показують, що оскільки швидкість сортування елементів є квадратичною, то час виконання практично однаковий, в той же час, для вже відсортованого масиву хороші результати продемонстрували сортування включенням та шейкерне сортування, у яких кількість операцій суттєво залежить від вигляду масиву. Отже, ці прості алгоритми сортування можна використовувати для „майже" відсортованих масивів, тобто, коли до відсортованого масиву додають m елементів (m<<n
).
Розділ ІІІ. Огляд функцій сортування із стандартної бібліотеки С++
Мова програмування С++ має в своєму складі функції, які дають змогу виконувати сортування елементів довільного типу без реалізації алгоритмів. Так, функція sort
має декілька версій, в базовому її варіанті прототип виглядає наступним чином:
Void sort(Iterarot begin, Iterator end);
В якості параметрів функції використовуються два ітератори довільного доступу, призначені для роботи з окремим контейнером класу. З допомогою функціїsort
дані контейнера впорядковуються, починаючи з елемента begin
і закінчуючи елементом end
(не включаючи його).
Оскільки вказівник на елемент масиву в С++ вважається ітератором довільного доступу, можна впорядкувати частину, або весь масив. Наприклад:
int
mas
[7]= {0, 10, 2, 0, 4, 15, 6}
//Елементи масиву будуть впорядковані. Зверніть увагу на те,
// що ім’я
mas використовується в якості вказівника на перший
// елемент,
mas
+7, вказує на елемент, що знаходиться
// на одну позицію дальше границі масиву
sort(
mas,
mas+7);
Проте, дана функція підтримується лише новими компіляторами (Файл SORT_7.CPP).
#include <conio.h>
#include <iostream.h>
#include <stdlib.h>
#include <
algorithm
.h>
int mas[1000];
void vuv(int s)
{ for(int i=1;i<=s;i++)
cout<<mas[i]<<‘ ‘;
cout<<endl<<"--------------------------------"<<endl;
}
main()
{clrscr();
cout<<"Vvedit kilkist elementiv masuvy - n"<<endl;
int n,tmp,k;
cin>>n;
for (int i=1;i<=n;i++)
{
cout<<"vvedit "<<i<<" -eltment masuvy"<<endl;
cin>>mas[i];
}
clrscr();
cout<<"Maemo masuv "<<endl;
vuv(n);
//S
ort_Bibliotrchna_fukccia
sort(mas, mas+n);
cout<<"Masuv vidsortovanuy "<<endl;
vuv(n);
getch();
return 0;
}
Крім даної функції, в С++ існує ще ряд інших призначених для сортування масивів довільних типів. Наприклад, однією із перших функцій даного напрямку, що ввійшла в стандартну бібліотеку мови С була функція qsort.
Проте в ній програмісту самому було потрібно написати функцію порівняння елементів для її повноцінної роботи, наприклад:
і
nt
compare_integers(const void* p1, const void* p2)
{
returne* ((int *)) p1)-*((int*)p2));
}
А вже маючи готову функцію порівняння, можна використовувати функцію qsort
. Наприклад, для сортування масиву цілих чисел виклик функції буде мати вигляд:
int mas[7]= {0, 10, 2, 0, 4, 15, 6};
qsort((void*)mas,7,sizeof(int),compare_integer);
Використовуючи дані функції, можна зробити порівняльний аналіз затрат для програмування власних, швидкості виконання, затрачених ресурсів.
Висновки
Виконуючи курсову роботу, ми опрацювали тематичну літературу, провели історичний огляд понять алгоритмів, їх застосування. Провели аналіз методів сортування та застосування їх у повсякденному житті.
Застосування того чи іншого алгоритму сортування для вирішення конкретної задачі є досить складною проблемою, вирішення якої потребує не лише досконалого володіння саме цим алгоритмом, але й всебічного розглядання того чи іншого алгоритму, тобто визначення усіх його переваг і недоліків.
У своїй роботі ми розглянули прямі алгоритми сортування, навели графічне відображення покрокового виконання. Також нами було розроблено ряд програм, для наочної демонстрації роботи кожного окремого методу.
Нами було проведений детальний аналіз швидкодії кожного алгоритму, проведено порівняльний аналіз між швидкодією прямих методів сортування.
Виконуючи дану роботу, ми прийшли до ряду висновків:
- алгоритми прямого сортування, не є складними у розумінні, легко виконувані і прості у реалізації;
- дані алгоритми, що ми розглянули, можна використовувати для сортування даних довільного типу, тобто ці алгоритми в певній мірі є універсальні;
- сортування методами вибору і сортування вставками як при найгіршому, так і при середньому варіанті мають квадратичний час виконання.
- швидкодія прямих методів сортування невелика, але якщо впорядковуваний масив є невеликим або ж сортування проводиться не часто, то ними користуватися є більш вигідно, ніж іншими алгоритмами;
- сортування вставками дає більш відчутну перевагу, якщо вихідний масив близький до впорядкованого стану;
- Застосування того чи іншого алгоритму сортування для вирішення конкретної задачі є досить складною проблемою, вирішення якої потребує не лише досконалого володіння саме цим алгоритмом, але й всебічного розглядання того чи іншого алгоритму, тобто визначення усіх його переваг і недоліків.
Виконуючи дану курсову роботу ми не тільки детально проаналізували теоретичний матеріал по напряму "Прямі алгоритми сортування", а й реалізували їх на практиці, з використанням мови високого рівня програмування С++. Це дало змогу в режимі відладки програми спостерігати за переміщенням елементів масиву, зробити практичний матеріал більш наглядним.
Оскільки прямі алгоритми сортування вважаються більш простими, дана курсова робота може стати у пригоді при вивченні більш складних алгоритмів сортування, наприклад в графах, списках. Її можна буде використати як початковий матеріал для сортування об’єктів класу за певним ключем. Також у курсовій роботі наведені стандартні процедури сортування з допомогою шаблонів, що теж буде допомогою при подальшому вивченні матеріалу, пов’язаного з сортуванням.
Література
1. Айра П. Обьектно-Ориентированное прогрпммирование на С++. М.: Санкт-Петербург, 1999. – 460 с.
2. Архангельський А.Я. С++Builder 6: Справ. Пособие. Кн.1. Язык С++. – М.: Бином, 2004. – 544 с.
3. Глушаков С.В. Программирование на Visual C++. – М.: АСТ; Х.: Фоліо, 2003. – 726 с.
4. Дейтел Х. Как программировать на С++. – М.: Бином, 2001. – 1152 с.
5. Джонс Ж., Харроу К. Решение задач в системе Турбо Паскаль. М, 1991. – 709 с.
6. Клюшин Д. А. Полный курс С++. Москва: Санкт-Петербург, 2004. – 668 с.
7. Кнут Д.Э. Искуство програмирования, том 3. Поиск и сортировка, 3-е изд.: Пер. с англ.: Уч. Пос. – М.:Издательский дом "Вильямс", 2000. – 750 с.
8. Ковалюк Т.В. Основи програмування. Київ: Видавнича група ВНV, 2005. – 385 с.
9. Культин Н. Б. С/С++ в задачах и примерах. – М., 2002. – 288 с.
10. Кучеренко В. Язык программирования С++ для начинающих и не только. – М.: Майор, 2001. – 160 с.
11. Львов М. С., Співаковський О. В. Основи алгоритмізації та програмування. Херсон, 1997.
12. Марченко А.И., Марченко Л.А. Программирование в среде Turbo Pascal 7.0. К.: ВЕК, 2000. – 441 с.
13. Мешков А.В. Visual C++ u MFC. - М, 2003. – 1040 с.
14. Павловская Т.А. С/С++: Программирование на языке высокого уровня: Учебник для студ. ВУЗ. М, 2002. – 464 с.
15. Секунов Н.Ю. Самоучитель Visual C++. М., 2002. – 735 с.
16. Франка П. С++: Учебный курс. М., 2002. – 521 с.
17. Щедріна О.І. Алгоритмізація та програмування процедур обробки інформації. К., 2001. – 240 с.
|
