Содержание:
| 1. Введение. |
2 |
2. Теоретическая часть.
· Основные понятия
· Регрессионный анализ рынка труда
|
3
3
8
|
| 3. Практическая часть. |
9 |
| 4. Заключение. |
| 5. Список использованной литературы. |
14 |
Введение.
В экономических исследованиях часто решают задачу выявления факторов, определяющих уровень и динамику экономического процесса. Такая задача чаще всего решается методами корреляционного, регрессионного, факторного и компонентного анализа.
Все многообразие факторов, которые воздействуют на изучаемый процесс, можно разделить на две группы: главные (определяющие уровень изучаемого процесса) и второстепенные. Последние часто имеют случайный характер, определяя специфические и индивидуальные особенности каждого объекта исследования.
Взаимодействие главных и второстепенных факторов и определяет колеблемость исследуемого процесса. В этом взаимодействии синтезируется как необходимое, типическое, определяющее закономерность изучаемого явления, так и случайное, характеризующее отклонение от этой закономерности. Случайные отклонения неизбежно сопутствуют любому закономерному явлению.
Для достоверного отображения объективно существующих в экономике процессов необходимо выявить существенные взаимосвязи и не только выявить, но и дать им количественную оценку. Этот подход требует вскрытия причинных зависимостей. Под причинной зависимостью понимается такая связь между процессами, когда изменение одного из них является следствием изменения другого.
Не все факторы, влияющие на экономические процессы, являются случайными величинами. Поэтому при анализе экономических Явлений обычно рассматриваются связи между случайными и неслучайными величинами. Такие связи называются регрессионными, а метод математической статистики, их изучающий, называется регрессионным анализом.
Теоретическая часть.
Основные понятия.
С целью математического описания конкретного вида зависимостей с использованием регрессионного анализа подбирают класс функций, связывающих результативный показатель y
и аргументы x
1
, x
2
,…,
х
k
,
отбирают наиболее информативные аргументы, вычисляют оценки неизвестных значений параметров уравнения связи и анализируют точность полученного уравнения.
Функция f
(x
1
, x
2
,…,
х
k
)
, описывающаязависимость условного среднего значения результативного признака у
от заданных значений аргументов, называется функцией (уравнением) регрессии.
Реклама

Термин "регрессия" (лат. - "regression" - отступление, возврат к чему-либо) введен английским психологом и антропологом Ф.Гальтпном и связан только со спецификой одного из первых конкретных примеров, в котором это понятие было использовано.
Обрабатывая статистические данные в связи с вопросом о наследственности роста, Ф.Гальтон нашел, что если отцыотклоняются от среднего роста всех отцов на x
дюймов, то их сыновья отклоняютсяот среднего роста всех сыновей меньше, чем на x
дюймов. Выявленная тенденция была названа «регрессией к среднему состоянию».
Термин регрессия широко используется в статистической литературе, хотя во многих случаях он недостаточно точно характеризует понятие статистической зависимости.
Для точного описанияуравнения регрессии необходимо знать условный закон распределения результативного показателя у.
В статистической практике такую информацию получить обычно не удается, поэтому ограничиваются поиском подходящих аппроксимаций для функции f
( x
1
, x
2
,…,
х
k
)
, основанных на исходных статистических данных.
В рамках отдельных модельных допущений о типе распределения вектора показателей (у,
x
1
, x
2
,…,
х
k
) может быть получен общий вид уравнения
регрессии
f
(
x
)=
M
(
y
/
x
)
x
=
(
x
1
, x
2
,…,
х
k
)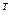 . Например, в предложении, что исследуемая совокупность показателей подчиняется (k
+ 1
) - мерному нормальному закону распределения с вектором математических ожиданий
. Например, в предложении, что исследуемая совокупность показателей подчиняется (k
+ 1
) - мерному нормальному закону распределения с вектором математических ожиданий
M =
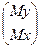 ,
,
гдеMx =
 , m
y =
MY , m
y =
MY
и ковариационной матрицей S = 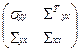 , ,
гдеs
yy
=
s
2
y
= M (y-M
y
) ;
;
Syx
=  ; Sxx
= ; Sxx
= 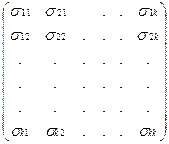 ; ;
s
ij
= M (x
i
– Mx
i
);(x
j
– Mx
j
);
s
jj
=
s
j
= M (x
j
– Mx
j
).
Из этого следует, что уравнение регрессии (условное математическое ожидание) имеет вид:
M(y/x) =
m
y
+ 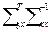 (x - Mx). (x - Mx).
Таким образом, если многомерная случайная величина (у,
x
1
, x
2
,…,
х
k
) подчиняется (k +1)-мерному нормальному закону распределения, то уравнение регрессии результативного показателя у
по объясняющим переменным x
1
, x
2
,…,
х
k
имеет линейный по х
вид.
Однако в статистической практике обычно приходится ограничиваться поиском подходящих аппроксимаций для неизвестной истинной функции регрессии f
(
x
)
, так как исследователь не располагает точным знанием условного закона распределения вероятностей анализируемого результатирующего показателя у
при заданных эначениях аргументов х=х
.
Рассмотрим взаимоотношение между истиной f
(х)=
M
(
y
/
x
),
модельной у
и оценкой у
регрессии.
Реклама

Пусть результативный показатель у
связан с аргументом х
соотношением::
y = 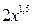 +
e
, +
e
,
где e - случайная величина, имеющая нормальный закон распределения, причем М
e
= 0 и
D
e
=
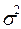 .
.
Истинная функция регрессии в этом случае имеет вид:
F(x) = M(y/x) =
2x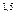 .
.
Предположим, что точный вид истинного уравнения регрессии нам не известен, но мы располагаем девятъю наблюдениями над двумернойслучайной величиной, связанной соотношением у
i
= 2x
+ ei
, ипредcтавленной на рисунке:
 у у
 70 70 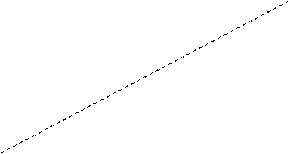   60 60
 50 50
40 30 30
20
 10 10
 0 0 0 2 4 6 8 10
Взаимное расположение истинной f
(
x
)
и теоритической у
модели регрессии.
Расположение точек на рисунке позволяет ограничиться классом линейных зависимостей вида: у =
b
0
+
b
1
x
.
С помощью метода наименьших квадратов найдем оценку уравнения регрессии
у =
b
0
+
b
1
x
.
Дли сравнения на рисунке приводятся графики истинной функции регрессии f
{х) =
2x
,теоретической аппроксимирующей функции регрессии 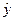 = b
0
+
b
1
x
. К последней сходится по вероятности оценка уравнения регрессии при неограниченном увеличении объема выборки (n = b
0
+
b
1
x
. К последней сходится по вероятности оценка уравнения регрессии при неограниченном увеличении объема выборки (n
 )
. )
.
Поскольку мы ошиблись в выборе класса функции регрессии, что, к сожалению, достаточно часто встречается в практике статистических исследований, то наши статистические выводы и оценки не будут обладать свойством состоятельности, т.е., как бы
мы не увеличивали объем наблюдений, наша выборочная оценка не будет сходиться к истинной функции регрессии f
(х)
.
Если бы мы правильно выбрали класс функций регрессии, то неточность в описании f
(
x
)
с помощью объяснялась бы только ограниченностью выборки и, следовательно, она могла бы быть сделана сколько угодно малой при n
.
С целью наилучшего восстановления по исходным статистическим данным условного значения результатирующего показателя у(х)
и неизвестной функции регрессии f
(
x
) =
M
(
y
/
x
)
наиболее часто используют следующие критерии адекватности
(функции потерь).
1. Метод наименьших квадратов
, согласно которому минимизируется квадрат отклонения наблюдаемых значений результативного показателя y
i
(
i
=
1,2,…,n
)
от модельных значений 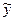 i
=
f
(
xi
,
b
)
, где b
= (
b
0,
b
1,…,
b
k
)
- коэффициенты уравнения регрессии, x
i
– значение вектора аргументов в i
-
м наблюдении: i
=
f
(
xi
,
b
)
, где b
= (
b
0,
b
1,…,
b
k
)
- коэффициенты уравнения регрессии, x
i
– значение вектора аргументов в i
-
м наблюдении:
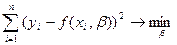 . .
Решается задача отыскания оценки 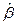 вектора b
. Получаемая регрессия называется среднеквадратической
. вектора b
. Получаемая регрессия называется среднеквадратической
.
2. Метод наименьших модулей
, согласно которому минимизируется сумма абсолютных отклонений наблюдаемых значений результативного показателя от модульных значений 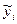 = f
(
x
i
,
b
)
, т.е. = f
(
x
i
,
b
)
, т.е.
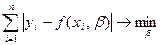 . .
Получаемая регрессия называется среднеабсолютной (медианой)
.
3. Метод минимакса
сводится к минимизации максимума модуля отклонения наблюдаемого значения результативного показателя y
i
от модельного значения f
(
x
i
,
b
)
, т.е.
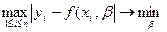 . .
Получаемая при этом регрессия называется минимаксной
.
В практических положениях часто встречаются задачи, в которых изучается случайная величина у
, зависящая от некоторого множества переменных x
1
, x
2
,…,
х
k
и неизвестных параметров b
j
(j
=
0,1,2,…,k
). Будем рассматривать (у,
x
1
, x
2
,…,
х
k
) как
(k
+
1) – мерную генеральную совокупность, из которой взята случайная выборка объемов n
, где (у
i
,
x
i
1
,
x
i
2
,…,
x
ik
)результат i
-го наблюдения i
=
1,2,…,n
. Требуется по результатам наблюдений оценить неизвестные параметры b
j
(j
=
0,1,2,…,k
).
Описанная выше задача относится к задачам регрессионного анализа.
Регрессионным анализом
называется метод статистического анализа зависимости случайной величины у
от переменных x
j
(j
=
1,2,…,k
), рассматриваемых в регрессионном анализе как неслучайные величины, независимо от истинного закона распределения x
j
.
Обычно предполагается, что случайная величина у
имеет нормальный закон распределения с условным математическим ожиданием , являющимся функцией от аргументов x
j
(j
=
1,2,…,k
)и постоянной, не зависящей от аргументов дисперсий 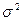 , т.е. следует помнить, что требование нормальности закона распределения необходимо лишь для проверки значимости уравнения регрессии и его параметров b
j
,
а также для интервального оценивания регрессии и его параметров b
j
.
Для получения точечных оценок b
j
(j
=
0,1,2,…,k
)этого условия не требуется. , т.е. следует помнить, что требование нормальности закона распределения необходимо лишь для проверки значимости уравнения регрессии и его параметров b
j
,
а также для интервального оценивания регрессии и его параметров b
j
.
Для получения точечных оценок b
j
(j
=
0,1,2,…,k
)этого условия не требуется.
В общем виде линейная модель
регрессионного анализа имеет вид:
у = 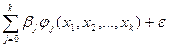 ,
,
где jj – некоторая функция его переменных x
1
, x
2
,…,
х
k
;
e - случайная величина с нулевым математическим ожиданием и дисперсией s
Примечание.
В регрессионном анализе под линейной моделью подразумевает модель, линейно зависящую о неизвестных параметров b
j
.
Собственно линейной будем называть модель, линейно зависящую как от параметров b
j
, так иот переменных х
j
.
В регрессионном методе вид уравнения регрессии выбирают исходя из анализа физической сущности изучаемого явления и результатов наблюдения.
Наиболее часто встречаются следующие виды уравнений регрессии
:
· собственно линейное многомерное
= 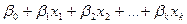 ; ;
· полиномиальное
= 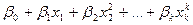 ; ;
· гиперболическое
= 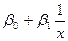 ; ;
· степенное
= 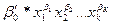 . .
Путем логарифмирования степенные уравнения регрессии могут быть преобразованы в линейные уравнения относительно параметров b
j
.
Логарифмируя, получим:
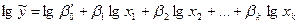 . .
Пусть lgx
j
= u
j
для j
=1,2,…,k
; 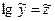 и и 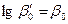 , тогда после подстановки будем иметь собственно линейные уравнения регрессии: , тогда после подстановки будем иметь собственно линейные уравнения регрессии:
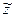 = = 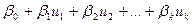 . .
Путем подстановок 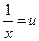 и и 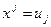 гиперболическое и полиномиальное уравнения могут быть преобразованы в собственно линейные, теория которых разработана наиболее полно. гиперболическое и полиномиальное уравнения могут быть преобразованы в собственно линейные, теория которых разработана наиболее полно.
Оценки неизвестных параметров уравнения регрессии находят обычно методом наименьших квадратов и свойствах оценок, найденных этим методом.
Регрессионный анализ рынка труда.
В общем виде задача статистики в области изучения взаимосвязей состоит не только в количественной оценке их наличия, направления и силы связи, но и в определении формы (аналитического выражения) влияния факторных признаков на результативный. Для ее решения применяют метод регрессионного анализа.
Задачами регрессионного анализа являются выбор типа модели (формы связи), установление степени влияния независимых переменных на зависимую и определение расчетных значений зависимой переменной (функции регрессии).
Решение всех названных задач приводит к необходимости комплексного использования этого метода.
Для характеристики влияния изменений Х на вариацию У служат методы регрессионного анализа. В случае парной линейной зависимости строится регрессионная модель:
Yi = ao + a1·Xi + ?i,i = 1,...,n,
где n - число наблюдений; ao , a1 - неизвестные параметры уравнения; ?i - ошибка случайной переменной У.
Уравнение регрессии записывается как
Уi теор = ao + a1·Xi,
где Уi теор - рассчитанное выравненное значение результативного признака после подстановки в уравнение Х.
Параметры ao и a1 оцениваются с помощью процедур, наибольшее распространение из которых получил метод наименьших квадратов. Его суть заключается в том, что наилучшие оценки ao и a1 получают, когда
?( Yi - Уi теор)? = min,
т.е. сумма квадратов отклонений эмпирических значений зависимой переменной от вычисленных по уравнению регрессии должна быть минимальной. Сумма квадратов отклонений является функцией параметров ao и a1. Ее минимизация осуществляется решением системы уравнений:
n ao + a1?X = ?У;
ao ?X + a1?X? = ?ХУ.
Важен смысл параметров: a1 - это коэффициент регрессии, характеризующий влияние, которое оказывает Х на У. Он показывает, на сколько единиц в среднем изменится У при изменении Х на одну единицу. Если a1 больше 0, то наблюдается положительная связь. Если a1 имеет отрицательное значение, то увеличение Х на единицу влечет за собой уменьшение У в среднем на a1. Параметр a1 обладает размерностью отношения У к Х.
Параметр ao - это постоянная величина в уравнении регрессии. Экономического смысла она не имеет, но в ряде случаев его интерпретируют как начальное значение У.
Рассмотрим регрессионную зависимость доли убыточных промышленных предприятий от показателей, характеризующих степень разгосударствления промышленности. Результаты расчетов приведены в табл. 1-8.
Таблица 1.
Результаты анализа от 3 характеристик разгосударствления промышленности:
| Множественный коэффициент корреляции (R) |
0,556 |
| R-квадрат |
0,309 |
| Нормированный R-квадрат |
0,281 |
| Стандартная ошибка |
8,517 |
| Наблюдения |
78 |
| F-статистика |
11,046 |
| DW-статистика |
1,036 |
Таблица 2. Коэффициенты линейной регрессии:
| Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
| Свободный член |
131,428 |
16,091 |
8,168 |
0,000 |
| Доля предприятий |
-0,587 |
0,200 |
-2,933 |
0,004 |
| Доля продукции |
-0,040 |
0,159 |
-0,249 |
0,804 |
| Доля работающих |
-0,267 |
0,182 |
-1,468 |
0,146 |
Приведенные результаты показывают, что построенная регрессия в целом значима на высоком уровне (F = 11,046). Однако лишь связь доли убыточных предприятий промышленности с долей предприятий негосударственного сектора значимо отрицательна (Pv
= 0,004). В то же время связь доли убыточных предприятий а с долей работающих на негосударственных промышленных предприятиях и долей продукции, производимой промышленными предприятиями негосударственного сектора, отрицательна, но незначима (Pv
= 0,146 и 0,804, соответственно). Кроме того, значение статистики DW = 1,036 свидетельствует о наличии автокорреляции в остатках. Построим регрессию без показателя доли производимой продукции. Результаты приведены в табл. 3 и 4.
Таблица 3 .
Результаты регрессионного анализа от 2 характеристик разгосударствления промышленности:
| Множественный коэффициент корреляции (R) |
0,556 |
| R-квадрат |
0,309 |
| Нормированный R-квадрат |
0,290 |
| Стандартная ошибка |
8,464 |
| Наблюдения |
78 |
| F-статистика |
16,747 |
| DW-статистика |
1,035 |
Таблица 4.
Коэффициенты линейной регрессии:
| Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
| Свободный член |
130,652 |
15,687 |
8,329 |
0,000 |
| Доля предприятий |
-0,582 |
0,198 |
-2,941 |
0,004 |
| Доля работающих |
-0,303 |
0,109 |
-2,789 |
0,007 |
Как видно из приведенных результатов, в данном случае построенная регрессия значима даже на 1% уровне (F = 16,747). Регрессионные коэффициенты также значимы на 1% уровне. Однако значение статистики DW = 1,035 и в этом случае свидетельствует о наличии автокорреляции в остатках. Поэтому построим регрессию от всех трех показателей с учетом преобразования Кохрана-Орката, позволяющего избавиться от автокоррелированности остатков. Результаты приведены в табл. 5 и 6.
Таблица 5 .
Результаты регрессионного анализа от 3 характеристик разгосударствления промышленности (П1, П2 и Р) с учетом преобразования Кохрана-Орката:
| Множественный коэффициент корреляции (R) |
0,605 |
| R-квадрат |
0,366 |
| Нормированный R-квадрат |
0,331 |
| Стандартная ошибка |
7,520 |
| Наблюдения |
78 |
| F-статистика |
13,880 |
| DW-статистика |
2,220 |
Таблица 6 .
Коэффициенты линейной регрессии с учетом преобразования Кохрана-Орката:
| Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
| Свободный член |
121,667 |
13,491 |
9,016 |
0,000 |
| Доля предприятий |
-0,524 |
0,166 |
-3,150 |
-0,002 |
| Доля продукции |
-0,012 |
0,126 |
-0,097 |
-0,923 |
| Доля работающих |
-0,247 |
0,145 |
-1,701 |
-0,093 |
Приведенные результаты показывают, что построенная регрессия значительно лучше по всем параметрам регрессии, характеристики которой приведены в табл. П.5.6. и П.5.7: она в целом значима на высоком уровне (F = 13,880), множественной коэффициент корреляции равен 0,605 против 0,556. Связь доли убыточных предприятий промышленности с долей предприятий негосударственного сектора значимо отрицательна (Pv
= 0,002). Связь доли убыточных предприятий с долей работающих на негосударственных промышленных предприятиях становится значимой на 10% уровне (Pv
= 0,093). Однако связь с долей продукции, производимой промышленными предприятиями негосударственного сектора остается не значимой (Pv
= 0,923). Поэтому построим регрессию без показателя доли производимой продукции. Результаты приведены в табл. 7 и 8.
Таблица 7. Результаты регрессионного анализа от 2 характеристик разгосударствления промышленности (П1 и Р) с учетом преобразования Кохрана-Орката:
| Множественный коэффициент корреляции (R) |
0,605 |
| R-квадрат |
0,366 |
| Нормированный R-квадрат |
0,340 |
| Стандартная ошибка |
7,468 |
| Наблюдения |
78 |
| F-статистика |
21,104 |
| DW-статистика |
2,218 |
Таблица 8 .
Коэффициенты линейной регрессии с учетом преобразования Кохрана-Орката:
| Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
| Свободный член |
121,326 |
12,945 |
9,373 |
0,000 |
| Доля предприятий |
-0,522 |
0,163 |
-3,199 |
0,002 |
| Доля работающих |
-0,258 |
0,082 |
-3,155 |
0,002 |
Как видно из приведенных результатов, в данном случае построенная регрессия значима даже на 1% уровне (F = 21,104). Регрессионные коэффициенты значимы на 3% уровне.
Практическая часть.
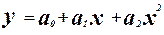 - уравнение регрессии. - уравнение регрессии.
| x
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
| y
|
1.35
|
1.09
|
6.46
|
3.15
|
5.80
|
7.2
|
8.07
|
8.12
|
8.97
|
10.66
|
Приведем квадратное уравнение к линейной форме:
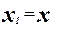 ; ;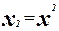
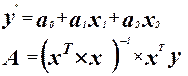
Запишем матрицу X.
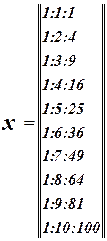
Составим матрицу Фишера.
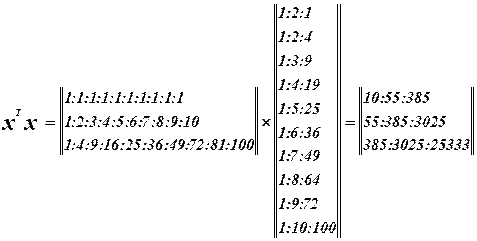
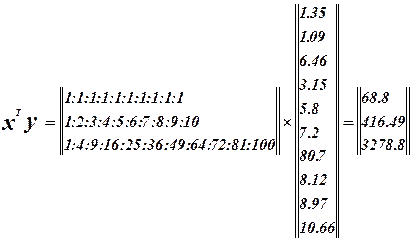
 Система нормальных уравнений. Система нормальных уравнений.
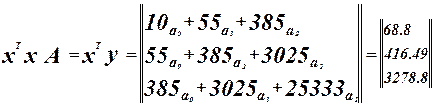
Решим ее методом Гаусса.
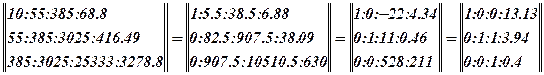
Уравнение регрессии имеет вид:
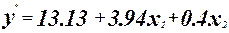
Оценка значимости коэффициентов регрессии.
Для проверки нулевой гипотезы используем критерий Стьюдента.
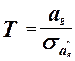 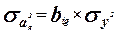
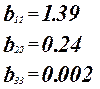
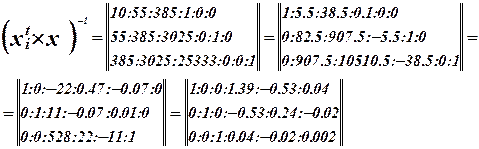

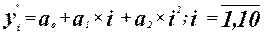
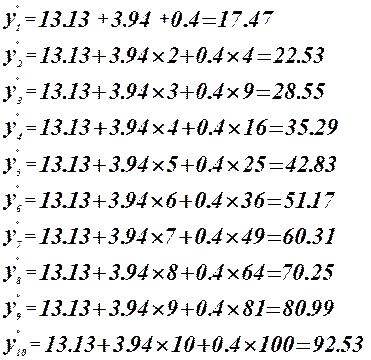
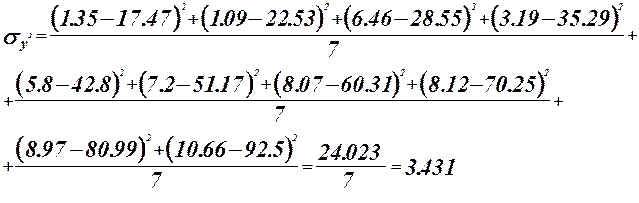 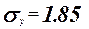
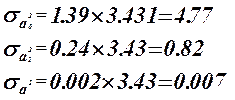 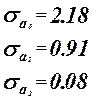
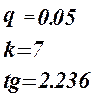
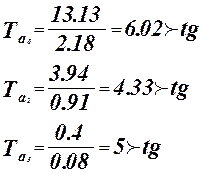
Коэффициенты  значимые коэффициенты. значимые коэффициенты.
Проверка адекватности модели по критерию Фишера.
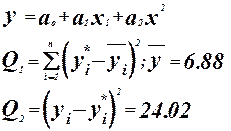
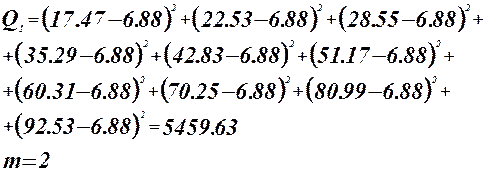
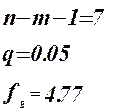
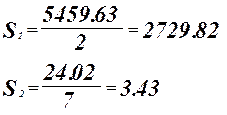
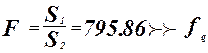 гипотеза о равенстве математического ожидания отвергается. гипотеза о равенстве математического ожидания отвергается.
Проверка адекватности модели по коэффициенту детерминации или множественной корреляции.
Коэффициент детерминации :
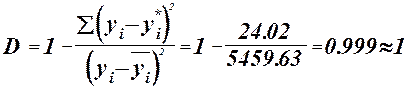
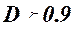 - регрессионная модель адекватна. - регрессионная модель адекватна.
Коэффициент множественной корреляции 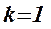
Рассчитать и построить график уравнения прямолинейной регрессии для относительных значений PWC170
и времени челночного бега 3х10 м у 13 исследуемых и сделать вывод о точности расчета уравнений, если данные выборок таковы:
xi
,
кГ м/мин/кг ~ 15,6; 13,4; 17,9; 12,8; 10,7; 15,7; 11,7; 12,3; 12,3; 11,1; 14,3; 12,7; 14,4
yi
, с ~ 6,9; 7,2; 7,1; 6,7; 7,6; 7,0; 6,4; 6,9; 7,7; 7,6; 7,9; 8,2; 6,8
Решение
1. Занести данные тестирования в рабочую таблицу и сделать соответствующие расчеты.
| xi
|
xi
-
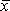 |
(xi
-
)2
|
yi
|
yi
–
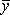 |
(yi
–
)2
|
(xi
-
)(yi
–
)
|
| 15.6 |
2.1 |
4.41 |
6.9 |
-0.3 |
0.09 |
-0.63 |
| 13.4 |
-0.1 |
0.01 |
7.2 |
0 |
0 |
0 |
| 17.9 |
4.4 |
19.36 |
7.1 |
-0.1 |
0.01 |
-0.44 |
| 12.8 |
-0.7 |
0.49 |
6.7 |
-0.5 |
0.25 |
0.35 |
| 10.7 |
-2.8 |
7.84 |
7.6 |
0.4 |
0.16 |
-1.12 |
| 15.7 |
2.2 |
4.84 |
7.0 |
-0.2 |
0.04 |
-0.44 |
| 11.7 |
-1.8 |
3.24 |
6.4 |
-0.8 |
0.64 |
1.44 |
| 12.3 |
-1.2 |
1.44 |
6.9 |
-0.3 |
0.09 |
0.36 |
| 12.3 |
-1.2 |
1.44 |
7.7 |
0.5 |
0.25 |
-0.60 |
| 11.1 |
-2.4 |
5.76 |
7.6 |
0.4 |
0.16 |
-0.96 |
| 14.3 |
0.8 |
0.64 |
7.9 |
0.7 |
0.49 |
0.56 |
| 12.7 |
-0.8 |
0.64 |
8.2 |
1 |
1 |
-0.80 |
| 14.4 |
0.9 |
0.81 |
6.8 |
-0.4 |
0.16 |
-0.36 |
| = 13.5
|
 |
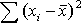 =50,92 =50,92
|
= 7,2
|
|
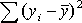 =3,34 =3,34
|
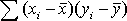 = -2,64 = -2,64 |
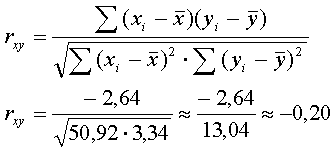
2. Рассчитать конечный вид уравнений прямолинейной регрессии по формулам (2) и (3):
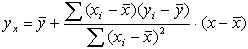 (2) (2)
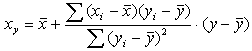 (3) (3)
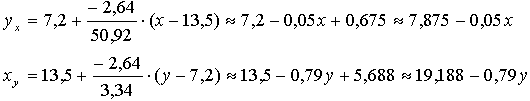
Т.е.

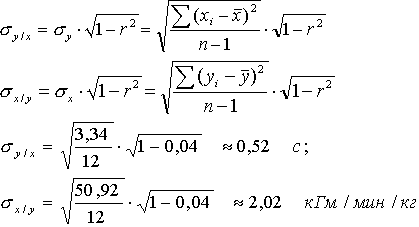
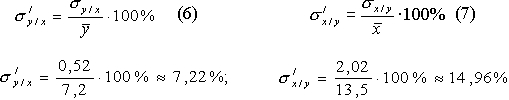
1. при х = 12,8 кГм/мин/кг у =7,235 с » 7,2 с;
2. при у = 6,7 с х = 13,895 с » 13,9 кГм/мин/кг.
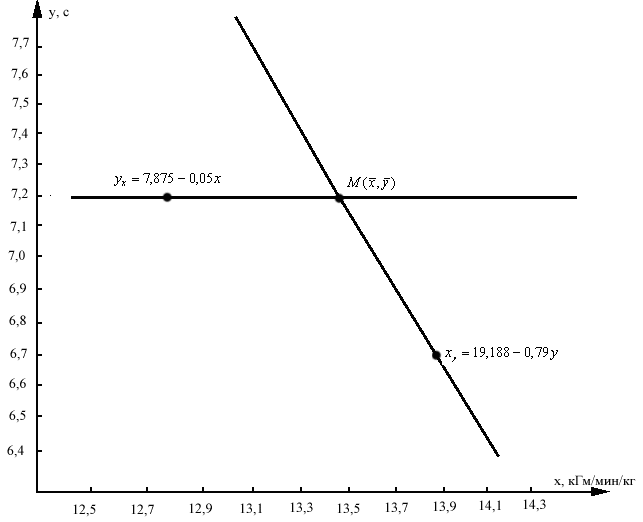
8. На основании произведенных расчетов и графического изображения уравнения регрессии сделать вывод.
Вывод:
1) в исследуемой группе наблюдается недостоверная обратная взаимосвязь между данными относительных значений PWC170
и времени челночного бега 3х10 м, т.к. rху
= -0,20 < rst
= 0,55
для К= 11 при = 95%;
2) относительная погрешность функции ух
= 7,875 – 0,05х
меньше (7,22%), а, следовательно, прогноз результата в челночном беге по данным относительных значений пробы PWC170
более точен;
3) на графике линии уравнения регрессии расположены почти под прямым углом, так как значения коэффициента корреляции близки к нулю.
Список использованной литературы:
1. Айвазян С.А., Бежаева З.И., Староверов О.В. Классификация многомерных наблюдений. – М.: Статистика, 1974. – 240с.
2. Андерсон Т. Введение в многомерный статистический анализ / Пер. с англ. – М.: ГИФМЛ, 1963. – 500с.
3. Болч Б., Хуань К. Многомерные статистические методы экономики / Пер. с англ. – М.: Статистика, 1979. – 317с.
4. Дубров А.М. Последовательный анализ в статистической обработке информации. – М.: Статистика, 1976 – 160с.
5. Кендалл М.., Стюарт А. Статистические выводы и связи. – М.: Наука, 1973.
6. Маленво Э. Статистические методы эконометрии / Пер. с фр.: Вып. 1. – М.: Статистика, 1975. – 423с.
7. Рао С.Р. Линейные статистические методы и их применение / Пер. с англ. – М.: Наука, 1968. – 548с.
|
