Техническая реализация коммутаторов
После того, как технология коммутации привлекла общее внимание и получила высокие оценки специалистов, многие компании занялись реализацией этой технологии в своих устройствах, применяя для этого различные технические решения. Многие коммутаторы первого поколения были похожи на маршрутизаторы, то есть основывались на центральном процессоре общего назначения, связанном с интерфейсными портами по внутренней скоростной шине (рисунок 4.1). Однако, это были скорее пробные устройства, предназначенные для освоения самой компании технологии коммутации, а не для завоевания рынка.
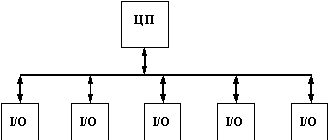
Рис. 4.1. Коммутатор на процессоре общего назначения
Основным недостатком таких коммутаторов была их низкая скорость. Универсальный процессор никак не мог справиться с большим объемом специализированных операций по пересылке кадров между интерфейсными модулями.
Для ускорения операций коммутации нужны были специализированные процессоры со специализированными средствами обмена данными, как в первом коммутаторе Kalpana, и они вскоре появились. Теперь коммутаторы используют заказные специализированные БИС, которые оптимизированы для выполнения основных операций коммутации. Часто в одном коммутаторе используется несколько специализированных БИС, каждая из которых выполняет функционально законченную часть операций.
В настоящее время коммутаторы используют в качестве базовой одну из трех схем взаимодействия своих блоков или модулей:
- коммутационная матрица;
- разделяемая многовходовая память;
- общая шина.
Часто эти три способа взаимодействия комбинируются в одном коммутаторе.
Коммутаторы на основе коммутационной матрицы
Коммутационная матрица
- основной и самый быстрый способ взаимодействия процессоров портов, именно он был реализован в первом промышленном коммутаторе локальных сетей. Однако, реализация матрицы возможна только для определенного числа портов, причем сложность схемы возрастает пропорционально квадрату количества портов коммутатора (рисунок 4.2).
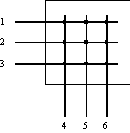
Рис. 4.2. Коммутационная матрица
Более детальное представление одного из возможных вариантов реализации коммутационной матрицы для 8 портов дано на рисунке 4.3. Входные блоки процессоров портов на основании просмотра адресной таблицы коммутатора определяют по адресу назначения номер выходного порта. Эту информацию они добавляют к байтам исходного кадра в виде специального ярлыка - тэга (tag). Для данного примера тэг представляет просто 3-х разрядное двоичное число, соответствующее номеру выходного порта.
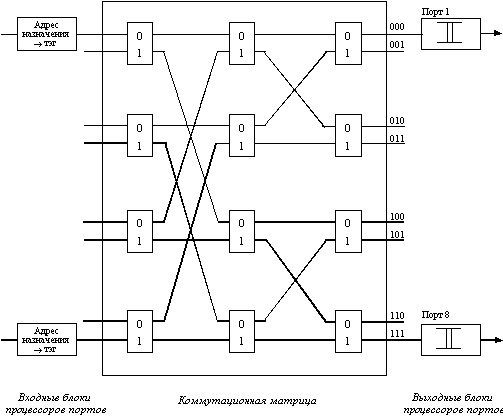
Рис. 4.3. Реализация коммутационной матрицы 4х4 с помощью двоичных переключателей
Матрица состоит из трех уровней двоичных переключателей, которые соединяют свой вход с одним из двух выходов в зависимости от значения бита тэга. Переключатели первого уровня управляются первым битом тэга, второго - вторым, а третьего - третьим.
Матрица может быть реализована и по-другому, на основании комбинационных схем другого типа, но ее особенностью все равно остается технология коммутации физических каналов. Известным недостатком этой технологии является отсутствие буферизации данных внутри коммутационной матрицы - если составной канал невозможно построить из-за занятости выходного порта или промежуточного коммутационного элемента, то данные должны накапливаться в их источнике, в данном случае - во входном блоке порта, принявшего кадр.
Реклама

Коммутаторы с общей шиной
Коммутаторы с общей шиной используют для связи процессоров портов высокоскоростную шину, используемую в режиме разделения времени. Эта архитектура похожа на изображенную на рисунке 4.1 архитектуру коммутаторов на основе универсального процессора, но отличается тем, что шина здесь пассивна, а активную роль выполняют специализированные процессоры портов.
Пример такой архитектуры приведен на рисунке 4.4. Для того, чтобы шина не была узким местом коммутатора, ее производительность должна быть по крайней мере в N/2 раз выше скорости поступления данных во входные блоки процессоров портов. Кроме этого, кадр должен передаваться по шине небольшими частями, по несколько байт, чтобы передача кадров между несколькими портами происходила в псевдопараллельном режиме, не внося задержек в передачу кадра в целом. Размер такой ячейки данных определяется производителем коммутатора. Некоторые производители, например, LANNET (сейчас подразделение компании Madge Networks), выбрали в качестве порции данных, переносимых за одну операцию по шине, ячейку АТМ с ее полем данных в 48 байт. Такой подход облегчает трансляцию протоколов локальных сетей в протокол АТМ, если коммутатор поддерживает эти технологии.
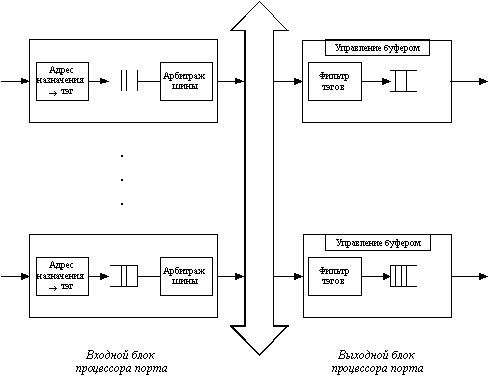
Рис. 4.4. Архитектура общей шины
Входной блок процессора помещает в ячейку, переносимую по шине, тэг, в котором указывает номер порта назначения. Каждый выходной блок процессора порта содержит фильтр тэгов, который выбирает тэги, предназначенные данному порту.
Шина, так же как и коммутационная матрица, не может осуществлять промежуточную буферизацию, но так как данные кадра разбиваются на небольшие ячейки, то задержек с начальным ожиданием доступности выходного порта в такой схеме нет.
Коммутаторы с разделяемой памятью
Третья базовая архитектура взаимодействия портов - двухвходовая разделяемая память. Пример такой архитектуры приведен на рисунке 4.5.
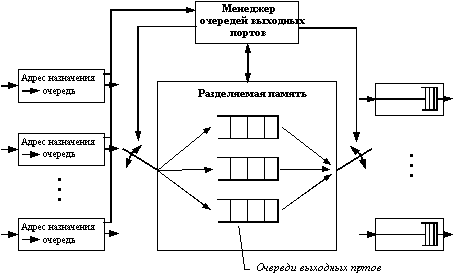
Рис. 4.5. Архитектура разделяемой памяти
Входные блоки процессоров портов соединяются с переключаемым входом разделяемой памяти, а выходные блоки этих же процессоров соединяются с переключаемым выходом этой памяти. Переключением входа и выхода разделяемой памяти управляет менеджер очередей выходных портов. В разделяемой памяти менеджер организует несколько очередей данных, по одной для каждого выходного порта. Входные блоки процессоров передают менеджеру портов запросы на запись данных в очередь того порта, который соответствует адресу назначения пакета. Менеджер по очереди подключает вход памяти к одному из входных блоков процессоров и тот переписывает часть данных кадра в очередь определенного выходного порта. По мере заполнения очередей менеджер производит также поочередное подключение выхода разделяемой памяти к выходным блокам процессоров портов, и данные из очереди переписываются в выходной буфер процессора.
Реклама

Память должна быть достаточно быстродействующей для поддержания скорости переписи данных между N портами коммутатора. Применение общей буферной памяти, гибко распределяемой менеджером между отдельными портами, снижает требования к размеру буферной памяти процессора порта.
Комбинированные коммутаторы
У каждой из описанных архитектур есть свои преимущества и недостатки, поэтому часто в сложных коммутаторах эти архитектуры применяются в комбинации друг с другом. Пример такого комбинирования приведен на рисунке 4.6.
Коммутатор состоит из модулей с фиксированным количеством портов (2 - 8), выполненных на основе специализированной БИС (ASIC), реализующей архитектуру коммутационной матрицы. Если порты, между которыми нужно передать кадр данных, принадлежат одному модулю, то передача кадра осуществляется процессорами модуля на основе имеющейся в модуле коммутационной матрицы. Если же порты принадлежат разным модулям, то процессоры общаются по общей шине. При такой архитектуре передача кадров внутри модуля будет происходить чаще всего быстрее, чем при межмодульной передаче, так как коммутационная матрица - наиболее быстрый, хотя и наименее масштабируемый способ взаимодействия портов. Скорость внутренней шины коммутаторов может достигать нескольких Гб/c, а у наиболее мощных моделей - до 10 - 14 Гб/с.
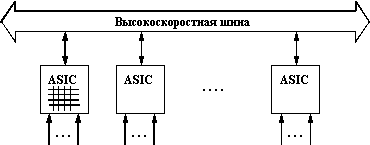
Рис. 4.6. Комбинирование архитектур коммутационной матрицы и общей шины
Можно представить и другие способы комбинировании архитектур, например, использование для взаимодействия модулей разделяемой памяти.
Модульные и стековые коммутаторы
В конструктивном отношении коммутаторы делятся на:
- автономные коммутаторы с фиксированным количеством портов;
- модульные коммутаторы на основе шасси;
- коммутаторы с фиксированным количеством портов, собираемые в стек.
Первый тип коммутаторов обычно предназначен для организации небольших рабочих групп.
Модульные коммутаторы на основе шасси чаще всего предназначены для применения на магистрали сети. Поэтому они выполняются на основе какой-либо комбинированной схемы, в которой взаимодействие модулей организуется по быстродействующей шине или же на основе быстрой разделяемой памяти большого объема. Модули такого коммутатора выполняются на основе технологии "hot swap", то есть допускают замену на ходу, без выключения коммутатора, так как центральное коммуникационное устройство сети не должно иметь перерывов в работе. Шасси обычно снабжается резервированными источниками питания и резервированными вентиляторами, в тех же целях. В целом такие коммутаторы напоминают маршрутизаторы высшего класса или корпоративные многофункциональные концентраторы, поэтому иногда они включают помимо модулей коммутации и модули повторителей или маршрутизатров.
С технической точки зрения определенный интерес представляют стековые коммутаторы. Эти устройства представляют собой коммутаторы, которые могут работать автономно, так как выполнены в отдельном корпусе, но имеют специальные интерфейсы, которые позволяют их объединять в общую систему, которая работает как единый коммутатор. Говорят, что в этом случае отдельные коммутаторы образуют стек.
Обычно такой специальный интерфейс представляет собой высокоскоростную шину, которая позволяет объединить отдельные корпуса подобно модулям в коммутаторе на основе шасси. Так как расстояния между корпусами больше, чем между модулями на шасси, скорость обмена по шине обычно ниже, чем у модульных коммутаторов: 200 - 400 Мб/c. Не очень высокие скорости обмена между коммутаторами стека обусловлены также тем, что стековые коммутаторы обычно занимают промежуточное положение между коммутаторами с фиксированным количеством портов и коммутаторами на основе шасси. Стековые коммутаторы применяются для создания сетей рабочих групп и отделов, поэтому сверхвысокие скорости шин обмена им не очень нужны и не соответствуют их ценовому диапазону.
Структура стека коммутаторов, соединяемых по скоростным специальным портам, показана на рисунке 4.7.
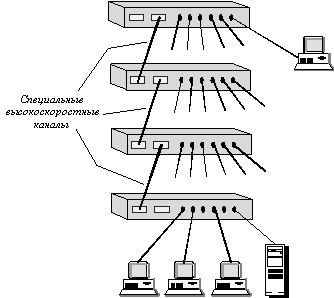
Рис. 4.7. Стек коммутаторов, объединяемых по высокоскоростным каналам
Компания Cisco предложила другой подход к организации стека. Ее коммутатор Catalyst 3000 (ранее называвшийся EtherSwitch Pro Stack) также имеет специальный скоростной интерфейс 280 Мб/с для организации стека, но с его помощью коммутаторы соединяются не друг с другом, а с отдельным устройством, содержащим коммутационную матрицу 8(8, организующую более высокопроизводительный обмен между любыми парами коммутаторов.
|
