Міністерство освіти і науки України
Національний університет “Львівська політехніка”
К
УРСОВА РОБОТА
З дисципліни: «Системне програмування»
на тему:
“Розробка компілятора з вхідної мови програмування”
Виконав: студ. гр. КІМ-21з
Мевшук Г.Г.
Львів 2011
Анотація
Згідно заданого завдання в даному курсовому проекті розроблено компілятор з вхідної мови програмування Pascal. Оболонка компілятора розроблена в середовищі програмування Borland C під операційну систему Windows і в опис проекту не входить. Сам компілятор написанний на мові Pascal, та поданий у пояснювальній записці, а також разом з оболонкою в електронному варіанті. В пояснювальній записці подано детальний опис мови, огляд існуючих методів розробки компіляторів, а також описано процес розробки програми компілятора на рівні блок-схем і тексту програми. До проекту додано результати тестування програми.
Зміст
Вступ
1. Завдання на курсовий проект
2. Формальний опис вхідної мови програмування
3. Розробка компілятора вхідної мови програмування
3.1 Розробка лексичного аналізатора
3.1.1 Розробка блок-схеми програми
3.2 Розробка синтаксичного аналізатора
3.2.1 Обробка синтаксичних помилок
3.3 Розробка семантичного аналізатора
3.4 Розробка оптимізатора коду
3.5 Розробка генератора коду
4. Відладка та тестування компілятора
4.6.1 Виявлення лексичних помилок
4.6.2 Виявлення синтаксичних помилок
4.6.3 Виявлення семантичних помилок
4.6.4 Загальна перевірка коректності роботи транслятора
Висновки
Література
Додатки
Вступ
Компілятор – це програма, яка читає текст програми, написаної на одній мові – початковій, і транслює (переводить) його в еквівалентний текст на іншій мові – цільовій. Одним з важливих моментів трансляції є повідомлення користувача про наявність помилок в початковій програмі.
Створення компіляторів є одною з невід‘ємних частин системного програмного забезпечення. Одним із завдань компілятора є переведення написаного тексту програми у машинний код, який повинен відповідати комп‘ютерній системі. Оскільки сьогоднішній час – час великого розвитку комп‘ютерної галузі, то створений машинний код з часом стає застарілим, тобто не відповідає принципу оптимального використання комп‘ютерних ресурсів. Тому для запобігання цього явища необхідно створювати нові компілятори, які б відповідали потребам теперішнього часу.
Реклама

Проблема компіляції полягає в пошуку відповідності тексту вхідної програми конструкціям, що визначені граматикою. Граматика визначає форму або синтаксис допустимих виразів мови. Тому текст вхідної мови зручно подавати у вигляді послідовності лексем, що є неподільними одиницями мови. За допомогою компілятора програміст повинен мати можливість редагувати текст вхідної мови. Для цього компілятор має виявляти всі невідповідності тексту програми конструкціям мови і у випадку відсутності помилок генерувати об'єктний код або виконавчий модуль.
На перший погляд, різноманітність компіляторів приголомшує. Використовуються тисячі початкових мов, від традиційних, таких як Fortran і Pascal, до спеціалізованих, виникаючих у всіх областях комп'ютерних технологій. Цільові мови не менше різноманітні – це можуть бути інші мови програмування, різні машинні мови – від мов мікропроцесорів до суперкомп'ютерів. Іноді компілятори класифікують як однопрохідні, багатопрохідні, виконуючі, відлагоджуючі, оптимізуючі — залежно від призначення і принципів та технологій їх створення. Не дивлячись на уявну складність і різноманітність, основні задачі, виконувані різними компіляторами, по суті, одні і ті ж. Розуміючи ці задачі, ми можемо створювати компілятори для різних початкових мов і цільових машин з використанням одних і тих же базових технологій. Знання про організацію і написання компіляторів істотно зросли з часів перших компіляторів, що з'явилися на початку 1950-х рр. Сьогодні складно визначити, коли саме з'явився на світ перший компілятор, оскільки в ті роки проводилося багато експериментів і розробок різними незалежними групами. В основному метою цих розробок було перетворення в машинний код арифметичних формул. В 50-х роках про компілятори ходила слава як про програми, украй складні в написанні (наприклад, на написання першого компілятора Fortran було витрачено людиною 18 - років роботи). З тих пір розроблені різноманітні системні технології рішення багатьох задач, що виникають при компіляції. Крім того, розроблені хороші мови реалізації, програмні середовища і програмний інструментарій. Проблема компіляції полягає в пошуку відповідності тексту вхідної програми конструкціям, що визначені граматикою. Граматика визначає форму або синтаксис допустимих виразів мови.. Тому текст вхідної мови зручно подавати у вигляді послідовності лексем, що є неподільними одиницями мови. За допомогою компілятора програміст повинен мати можливість редагувати текст вхідної мови. Для цього компілятор має виявляти всі невідповідності тексту програми конструкціям мови і у випадку відсутності помилок генерувати об'єктний код або виконавчий модуль. Сьогодні від компілятора вимагається також створення оптимізованого коду програми. Тому створення ефективного виконавчого коду є дуже проблемою в наш час, бо для створення цього необхідно враховувати всі можливі варіанти покращеної апаратної частини, розвиток якої досяг сьогодні теоретичної межі продуктивності.
Реклама

Завдяки цьому "солідний компілятор" може бути реалізований навіть як курсова робота по проектуванню компіляторів.
1. Завдання на курсовий проект
Розробити компілятор з вхідної мови програмування короткий опис якої подано нижче (у відповідності з заданим варіантом) з виводом необхідної проміжної інформації на кожному кроці. Розробити інтерфейс користувача (інтегроване середовище програмування вхідною мовою).
Варіант № 13
В таблиці варіанта завдання використано наступні позначення:
A: Тип даних: byte(1).
B: Додаткова арифметична операція: ^ (піднесення до степеня).
C: Додаткова логічна операція: NOT.
D: Оператор циклу: do-while (2).
| № |
A |
B |
C |
D |
| 13 |
1 (byte) |
^ |
NOT |
do-while |
2. Формальний опис вхідної мови програмування
Розробити компілятор заданої вхідної мови програмування.
- три типи даних: логічний тип даних (boolean), знаковий цілочисельний тип (1byte) та беззнаковий цілочисельний тип розміром 1 байт;
- змінних з довільної довжини;
- арифметичні операції над цілими: +, -, *, /, “-” (унарний мінус), ^ (операція піднесення до степеню);
- символи групування арифметичних операцій “(” , “)”
- логічні операції над цілими: <, >, ==, | = ;
- логічну операцію над логічними даними NOT;
- оператор присвоєння “=”;
- оператори блоку “{“ , “}”;
- оператор виводу (print);
- оператор виконання дії за умовою (if-then-else);
- оператор циклу (do-while);
Визначимо окремі термінальні символи та нерозривні набори термін.
Символів(ключові слова);
{( usigned
} ) char
; < if
= > then
+ = = else
- <> while
^ NOT do
* program true
/ bool false
print
До термінальних символів віднесемо також усі цифри (0-9), латинські букви (a-z, A-Z) та символ пробілу (“ ”). Всього 28+10+52+1=91 термінальних виразів. Це “цеглинки”, з яких має будуватися текст будь-якої вхідної програми.
- символ “ | ” розділяє альтернативи
- символи “ [ ”,“ ] ” означає необов’язковість
- символи “ { ”,“ } ” означає повтор
Формальний опис заданої мови BNF:
<program>::= prog <block>
<block>::= {<statement> | [{<statement >}]}
<statement>::= <declaration> | <operator>
<declaration>::=<type><ident>;
<operator>::=<bind> | <if-then-else> | <do-while > | <print>
<bind>::=<ident> = <expression>;
<if-then-else>::= if <bool expression> then <bloc> [else<bloc>]
<while-do>::= while <bool_ehpression> do <bloc>
<print>::= print <ident> | <int-const> | <log-const>;
<type>::= boolean | byte | ubyte
<ident>::=<letter> [{<letter>}]
<byte_corst>::= [] <number> [{<number>}]
<bool_const>::= true | false
<letter>::= a | …| z | A | … | Z
<number>::= 0 | 1 | … | 9
<logic.conct>::= true | fals
<expression>::=<num.expression>|<bool_expression>|<log.expression>
<num.expression>::=<num_operand>[{<num.operation><num.operand>}]
<bool_expression>::=<num.operand>[{<bool.operation><num_operand>}]
<logic_expression>::=<logic_operand>[{|<logic.operand>}]
<logic_operand>::= (<logic_expression>) | <ident>|<logic_const>
<num.operand>::=(<num.expression>) | <ident> | <byte_const>
<num.operation>::= * | / | + | - | ^
<bool_operation>::= < | > | = = | < >
<log_expression>::=<log_operand> [{NOT<log_operand>}]
<log_operand>:: (<log_expression>) | <cident> | <logic_const>
3. Розробка компілятора вхідної мови програмування
Процедурно-орієнтовані мови програмування, такі як FORTRAN, Pascal, C, C++ та ін. засновані на принципі послідовного виконання операторів, команд або директив. Їх базові оператори, операції, команди та директиви можна класифікувати по трьох основних групах:
а) Безумовні оператори (statements) обрахунків та перетворень;
б) Оператори обробки розгалужень та передачі управління;
в) Оператори організації циклічної обробки.
В загальному випадку віртуальна машина складається з інформаційного, операційного, управляючого та комунікаційного компонентів. Будь-яка віртуальна машина повинна мати:
а) Пам’ять різних видів та типів для збереження кодів програм і даних (інформаційний компонент) і механізми доступу до неї;
б) Вказівник поточної операції (основа управляючої компоненти), що змінюється при підрахунку номера оператора;
в) Блок виконання операцій (operators), який реалізує функції операційних та управляючих компонентів. Разом з інтерфейсним обладнанням він реалізує комунікаційний компонент, який забезпечує зв’язок ВМ із зовнішнім світом.
Загальна схема компілятора
Можна виділити сім різних логічних задач:
а. Інтерпретація – визначення точного змістового навантаження, створення матриці та таблиць з допомогою програм інтерпретації;
б. Машинно-незалежна оптимізація – створення оптимальнішої матриці;
в. Лексичний аналіз – розпізнавання базових елементів та створення стандартних символів;
г. Синтаксичний аналіз – розпізнавання базових синтаксичних конструкцій з використанням редукцій;
д. Розподіл пам’яті – модифікація таблиць ідентифікаторів та літералів. В матриці розміщується інформація, з допомогою якої генерується код, який розподіляє динамічну пам’ять;
е. Генерація коду – використання макропроцесора для отримання більш оптимального вихідного коду;
Фази з першої по четверту машинно-незалежні і визначаються тільки мовою. Фази з п’ятої по сьому – машинно-залежні і не залежать від мови. З метою забезпечення вищої ефективності ці фази можуть не розділятись так чітко.
Компілятор необхідно оцінювати не тільки по об’єктному коду, що генерується, але також і по об’єму оперативної пам’яті, що він займає і по часу, що потрібен для трансляції. На жаль, ці критерії оптимальності часто досить суперечливі. Крім того, оптимальність коду обернено пропорційна складності, розміру та часу роботи самого компілятора. Насправді необхідні компроміси.
Компілятором використовуються бази даних, що забезпечують зв’язки між фазами: вхідний код, таблиця стандартних символів, таблиця термінальних символів, таблиця ідентифікаторів, таблиця літералів, редукції, матриця, кодові продукції, код компоновки, кінцевий об’єктний код.
3.1 Розробка лексичного аналізатора
Для обробки текстів вхідних програм існує кілька способів побудови мовних процесорів. Одним з варіантів є інтерпретатор.
Інтерпретатор – це програма, яка обробляє вхідну програму, написану на вхідній мові і проводить обчислення, задані цією мовою.
Транслятор – програма, що обробляє вхідну програму, написану на вхідній мові і генерує програму на об’єктній мові. Об’єктна мова як правило є мовою деякої ЕОМ і таку програму одразу можна виконувати. Транслятори можна поділити на асемблери і компілятори, які транслюють відповідно мови низького і високого рівня.
Перед написанням компілятора вхідну мову потрібно подати в термінах деякої граматики. Ця граматика визначає форму або синтаксис допустимих виразів мови. Проблема компіляції – проблема пошуку в тексті вхідної програми конструкцій, що визначені граматикою та генерації відповідного коду для кожного виразу вхідної мови. Конструкції вхідної мови зручно подавати у вигляді лексем. Лексеми – це неділимі фундаментальні одиниці мови. Перегляд вхідного тексту та розпізнавання лексем називається лексичним аналізом, а процедура, яка його виконує – сканером. Після розпізнавання лексем кожен вираз можна розпізнати як окрему конструкцію мови, що описані граматикою. Цей процес називається синтаксичним аналізом.
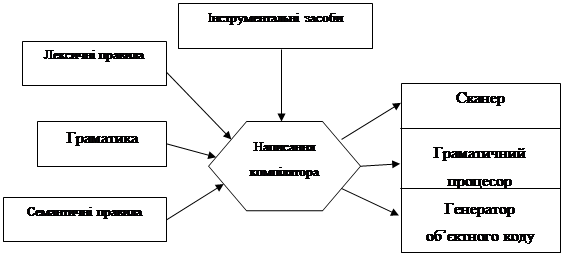
Процес розробки компілятора можна зобразити такою схемою:
Рисунок 1 - Процес розробки компілятора.
Сканер або лексичний блок – одна з найпростіших частин компілятора. Він переглядає символи вхідної програми зліва направо і групує певні термінальні символи в єдині синтаксичні об’єкти. Цілі числа, ідентифікатори, символьні константи є нетермінальними символами і також групуються в таблиці.
Процес роботи лексичного аналізатора є складнішим. Побудований при лексичному аналізі список лексем проглядається зліва направо і аналізується. Є два основні способи для аналізу списку лексем. Це спосіб операторного передування і рекурсивний спуск.
Для роботи компілятора різна допоміжна інформація знаходиться в таблицях, якими дані передаються від одного до іншого етапу. В деяких реалізаціях записи, що заносяться в таблицю можуть мати різну довжину. Таким чином компілятору потрібні методи організації інформації, здатні швидко запам’ятати і видати інформацію про велику частину програми. Основну проблему синтаксичного аналізу можна сформулювати так: є велика кількість об’єктів, що можуть зустрічатися в програмі. Об'єкти можуть зустрічатися в непередбачуваному порядку. Як тільки об’єкт зустрівся, потрібно перевірити, чи не був він раніше занесений в таблицю. Якщо в таблиці об’єкту немає, його необхідно туди записати. Одним із способів запам'ятовування об'єктів є таблиці з прямим доступом.
При рекурсивному спуску відповідність блоків лексем синтаксичним правилам перевіряється відповідно до дерева розбору деякої конструкції.
Покажемо на прикладі дерево конструкції while мови С.
While (f+a*d) a=a+5;
Рисунок 2 Конструкції while мови С
При знаходженні ключового слова while перевіряється наявність дужки і викликається процедура перевірки запису виразу.
При перегляді виразу методом операторного передування лексеми проглядаються в обох напрямках, якщо це потрібно і визначається, чи порядок їх співпадає з описаними конструкціями.
На етапі синтаксичного аналізу визначаються помилки. Після того, як синтаксис оператора визначено, іде інтерпретація його значення, тобто семантичний аналіз. Кожній синтаксичній одиниці відповідає певне значення, яке може бути виражене в формі реальних входів або в проміжній формі. Проміжною формою синтаксичної конструкції є дерево розбору.
Після синтаксичного і семантичного аналізу тексту програми відбувається трансляція тексту в проміжну мову, якою у більшості випадків є асемблер. Трансляція тексту може відбуватись як за один, так і за декілька проходів. Перевагою однопрохідних компіляторів є те, що не потрібно підтримувати зв’язок між проходами, але недоліком є те, що всі змінні, функції, мітки і константи мусять обов’язково бути описані перед їх використанням.
Процес компіляції вхідного файлу можна розділити умовно на кілька етапів. Основні етапи – це лексичний, синтаксичний та семантичний аналіз та трансляція. На кожному з цих етапів дані представляються у зручному для обробки вигляді.
Для лексичного аналізу вхідними даними є текстовий файл. Лексичний аналізатор формує динамічний список в основній пам'яті, в якому кожен вузол містить як інформацію про лексему, так і вказівник на наступну лексему. Останній вказівник має значення NULL. Структура вузла списку:
NODE
{ int line;– номер рядка лексеми
int idlexem;– код лексеми (номер у таблиці)
int type;– тип, якщо це ідентифікатор
int is_int;– чи це ідентифікатор, чи рядкова константа, чи число
int is_ar;– кількість індексів масиву (для простої змінної – 0)
NODE* next; }– вказівник на наступний елемент списку
Кожен ідентифікатор, не знайдений в таблиці лексем, записується в таблицю лексем, що є двовимірним символьним масивом. Паралельно існує масив вказівників на список параметрів, в якому всі елементи, що відповідають функції, мають вказівник на список параметрів функції. Структура вузла цього списку:
FPAR {
int type;– тип параметра (1..4)
FPAR* next; }– вказівник на наступний елемент списку
Список лексем є вхідним для синтаксичного аналізатора, який є суміщений з семантичним. На виході синтаксичного аналізатора є інформація про аналіз, що записується у файл. Це є повідомлення про першу знайдену помилку або ж повідомлення про те, що помилок немає.
Якщо помилки немає, запускається транслятор, який транслює список лексем у файл на проміжній мові С++ відповідно до таблиці С-лексем і правил побудови вхідної мови.
Порміжний файл з розширенням с транслюється у ехе-файл стандартним компілятором bсс.ехе.
3.1.1 Розробка блок-схеми програми
Для побудови компілятора необхідно спроектувати його будову на рівні функцій і їх взаємозв'язків, тобто правил виклику. Це потрібно для побудови узгодженої багатомодульної структури при програмуванні зверху вниз. Кожну задачу розділяємо на дрібніші підзадачі, які потім в свою чергу уконкретнюємо.
Загальну структуру програми можна подати в такому спрощеному вигляді:
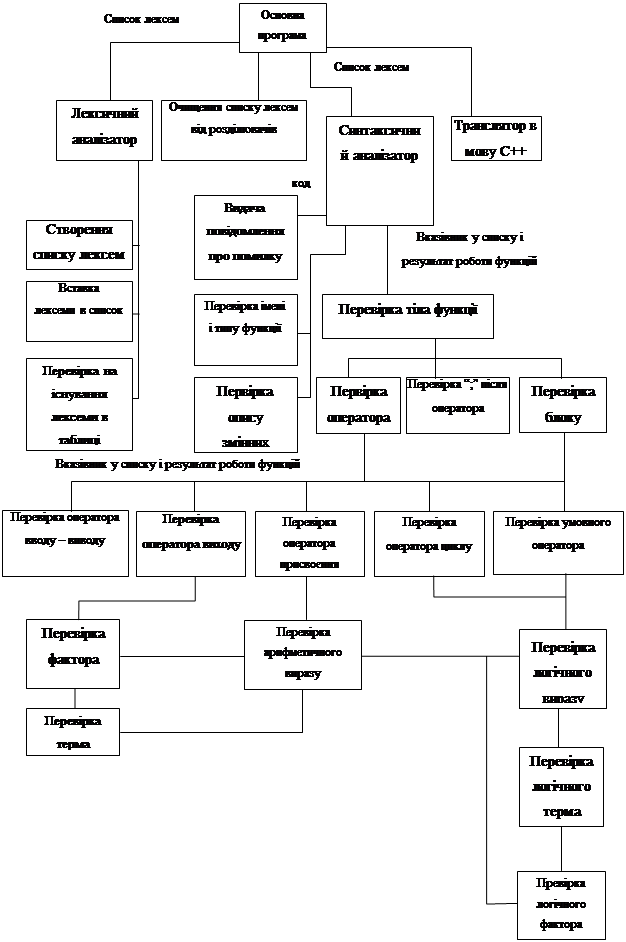
Рисунок 3 Загальна структура програми у спрощеному вигляді
3.2 Розробка синтаксичного аналіз
атора
Синтаксичний аналіз – це процес, в якому досліджується послідовність лексем, яку повернув лексичний аналізатор, і визначається, чи відповідає вона структурним умовам, що сформульовані у визначені синтаксису мови.
Синтаксичний аналізатор – це частина компілятора, яка відповідає за виявлення основних синтаксичних конструкцій вхідної мови. В задачу синтаксичного аналізатора входить: знайти та виділити основні синтаксичні конструкції мови в послідовності лексем програми, встановити тип та правильність побудови кожної синтаксичної конструкції і представити синтаксичні конструкції у вигляді, зручному для подальшої генерації тексту результуючої програми. Крім того, важливою функцією є локалізація синтаксичних помилок. Як правило, синтаксичні конструкції мови програмування можуть бути описані за допомогою контекстно-вільних граматик. Розпізнавач дає відповідь на питання, належить чи ні, ланцюжок вхідних лексем заданій мові. Але задача синтаксичного аналізу не обмежується тільки такою перевіркою. Синтаксичний аналізатор повинен мати деяку результуючу мову, за допомогою якої він передає наступним фазам компіляції інформацію про знайдені і розібрані синтаксичні конструкції, якщо відокремлюється фаза генерації об’єктного коду.
Кожна мова програмування має правила, які визначають синтаксичну структуру коректних програм. В Pascal, наприклад, програма створюється з блоків, блок – з інструкцій, інструкції – з виразів, вирази – з токенів і т.д. Синтаксис конструкцій мови програмування може бути описаний за допомогою контекстно-вільних граматик або нотації БНФ (Backus-Naur Form, форма Бекуса-Наура). Граматики забезпечують значні переваги розробникам мов програмування і авторам компіляторів.
Граматика дає точну і при цьому просту для розуміння синтаксичну специфікацію мови програмування.
Для деяких класів граматик можливо автоматично побудувати ефективний синтаксичний аналізатор, який визначає, чи коректна структура початкової програми. Додатковою перевагою автоматичного створення аналізатора є можливість виявлення синтаксичних неоднозначностей та інших складних для розпізнавання конструкцій мови, які інакше могли б залишитися непоміченими на початкових фазах створення мови і його компілятора.
Правильно побудована граматика додає мові програмування структуру, яка сприяє полегшенню трансляції початкової програми в об'єктний код і виявленню помилок. Для перетворення описів трансляції, заснованих на граматиці мови, в робочій програмі є відповідний програмний інструментарій.
З часом мови еволюціонують, збагатившись новими конструкціями і виконуючи нові задачі. Додавання конструкцій в мову виявиться більш простою задачею, якщо існуюча реалізація мови заснована на його граматичному описі.
Є три основні типи синтаксичних аналізаторів граматик. Універсальні методи розбору, такі як алгоритми Кока-Янгера-Касамі або Ерлі, можуть працювати з будь-якою граматикою. Проте ці методи дуже неефективні для використання в промислових компіляторах. Методи, які звичайно використовуються в компіляторах, класифікуються як низхідні (зверху вниз, top-down) або висхідні (з низу до верху, bottom-up). Як видно з назв, низхідні синтаксичні аналізатори будують дерево розбору зверху вниз (до листя), тоді як висхідні починають з листя і йдуть до кореня. В обох випадках вхідний потік синтаксичного аналізатора сканується посимвольно зліва направо. Найефективніші низхідні і висхідні методи працюють тільки з підкласами граматик, проте деякі з цих підкласів, такі як LL- і LR-граматики, достатньо виразні для опису більшості синтаксичних конструкцій мов програмування. Реалізовані вручну синтаксичні аналізатори частіше працюють з LL-граматиками. Синтаксичні аналізатори для дещо більшого класу LR-граматик звичайно створюються за допомогою автоматизованих інструментів. Будемо вважати, що вихід синтаксичного аналізатора є деяким представленням дерева розбору вхідного потоку токенів, виданого лексичним аналізатором. На практиці є безліч задач, які можуть супроводжувати процес розбору, - наприклад, збір інформації про різні токени в таблиці символів, виконання перевірки типів і інших видів семантичного аналізу, а також створення проміжного коду. Всі ці задачі представлені одним блоком "Інші задачі початкової фази компіляції" ( рисунок 4).
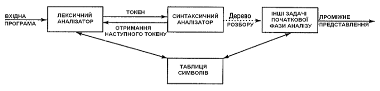
Рисунок 4 Місце синтаксичного аналізатора в моделі компілятора
3.2.1 Обробка синтаксичних помилок
Якщо компілятор матиме справу виключно з коректними програмами, його розробка і реалізація істотно спрощуються. Проте дуже часто програмісти пишуть програми з помилками, і добрий компілятор повинен допомогти програмісту знайти їх і локалізувати. Примітно, що хоча помилки — явище надзвичайно поширене, лише в декількох мовах питання обробки помилок розглядалося ще на фазі створення мови. Наша цивілізація істотно відрізнялася б від свого нинішнього стану, якби в природних мовах були такі ж вимоги до синтаксичної точності, як і в мовах програмування.
Більшість специфікацій мов програмування, проте, не визначає реакції компілятора на помилки — це питання віддається на відкуп розробникам компілятора. Проте планування системи обробки помилок з самого початку роботи над компілятором може як спростити його структуру, так і поліпшити його реакцію на помилки.
Будь-яка програма потенційно містить безліч помилок самого різного рівня. Наприклад, помилки можуть бути
• лексичними, такими як невірно записані ідентифікатори, ключові слова або оператори;
• синтаксичними, наприклад, арифметичні вирази з незбалансованими дужками;
• семантичними, такими як оператори, використані до несумісних операндів;
• логічними, наприклад нескінченна рекурсія.
Часто основні дії по виявленню помилок і відновленню після них концентруються у фазі синтаксичного аналізу. Одна з причин цього полягає в тому, що багато помилок за своєю природою є синтаксичними або виявляються, коли потік токенів, що йде від лексичного аналізатора, порушує визначаючі мова програмування граматичні правила. Друга причина полягає в точності сучасних методів розбору; вони дуже ефективно виявляють синтаксичні помилки в програмі. Визначення присутності в програмі семантичних або логічних помилок — задача набагато складніша.
Обробник помилок синтаксичного аналізатора має просту формульовану мету:
• він повинен ясно і точно повідомляти про наявність помилок;
• він повинен забезпечувати швидке відновлення після помилки, щоб продовжити пошук подальших помилок;
• він не повинен істотно уповільнювати обробку коректної програми.
Ефективна реалізація цієї мети є вельми складною задачею. На щастя, звичайні помилки достатньо прості, і для їх обробки часто достатньо простих механізмів обробки помилок.
В деяких випадках, проте, помилка може відбутися задовго до моменту її виявлення (і за багато рядків коду до місця її виявлення), і визначити її природу вельми непросто. В складних ситуаціях обробник помилок, по суті, повинен просто здогадатися, що саме мав на увазі програміст, коли писав програму. Деякі методи розбору, такі як LL і LR, виявляють помилки, як тільки це стає можливим. Точніше кажучи, вони володіють властивістю перевірки коректності префіксів, тобто виявляють помилку, як тільки з'ясовується що префікс вхідної інформації не є префіксом жодного коректного рядка мови.
3.3 Розробка семантичного аналіз
атора
В процесі роботи компілятор зберігає інформацію про об'єкти програми. Як правило, інформація про кожний об'єкт складається із двох основних елементів: імені об'єкта і його властивостей. Інформація про об'єкти програми повинна бути організована так, щоб пошук її був по можливості швидше, а необхідної пам'яті по можливості менше. Крім того, з боку мови програмування можуть бути додаткові вимоги.
Імена можуть мати певну область видимості. Наприклад поле запису повинне бути унікально в межах структури (або рівня структури), але може співпадати з ім'ям об'єктів зовні запису (або іншого рівня запису). В той же час ім'я поля може відкриватися оператором приєднання, і тоді може виникнути конфлікт імен (або неоднозначність в трактуванні імені). Якщо мова має блокову структуру, то необхідно забезпечити такий спосіб зберігання інформації, щоб, по-перше підтримувати блоковий механізм видимості, а по-друге – ефективно звільняти пам'ять по виході з блоку. В деяких мовах (наприклад, Аді) одночасно (в одному блоці) можуть бути видимі декілька об'єктів з одним ім'ям, в інших така ситуація неприпустима. Є декілька основних способів організації інформації в компіляторах:
· таблиці ідентифікаторів;
· таблиці символів;
· способи реалізації блокової структури;
Перевірка типів
Компілятор повинен переконатися, що початкова програма слідує як синтаксичним, так і семантичним угодам початкової мови. Така перевірка, іменована статичній (static checking), — на відміну від динамічної, виконуваної в процесі роботи цільової програми, — гарантує, що будуть виявлені певні типи програмних помилок.
Нижче представлені приклади статичних перевірок.
1. Перевірки типів. Компілятор повинен повідомляти про помилку, якщо оператор застосовується до несумісному з ним операнда, наприклад при складанні змінних, що є масивом і функцією.
2. Перевірки управління. Передача управління за межі мовних конструкцій повинна проводитися в певне місце. Наприклад, в мові програмування С оператор break передає управління за межі самої вкладеної інструкції while, for або switch; якщо ж такі відсутні, то виводиться повідомлення про помилку.
3. Перевірки єдиності. Існують ситуації, коли об'єкт може бути визначений тільки один раз. Наприклад, в мові програмування Pascal ідентифікатор повинен оголошуватися тільки один раз, всі мітки в конструкції case повинні бути різний, а елементи в скалярному типі не повинні повторюватися.
4. Перевірки, пов'язані з іменами. Іноді одне і те ж ім'я повинне використовуватися двічі (або більше число раз). Наприклад, в мові програмування Ada цикл або блок може мати ім'я, яке повинне знаходитися як на початку, так і в кінці конструкції.
Компілятор повинен перевірити, що в обох місцях використовується одне і те ж ім'я. В цьому розділі нас, в першу чергу, цікавить перевірка типів. Як видно з наведених приклади, більшість інших статичних перевірок є рутинною і може бути реалізований з використанням технологій, описаних в попередньому розділі. Деякі з них можуть використовуватися і для виконання інших дій. Наприклад, при внесенні інформації про ім'я в таблицю символів ми можемо переконатися в єдиності оголошення даного імені. Багато компіляторів Pascal об'єднують статичні перевірки і генерацію проміжного коду з синтаксичним аналізом. За наявності складніших конструкцій, на зразок тих, що використовуються в мові програмування Ada, може виявитися більш зручним виконати окремий прохід для проведення перевірок типів між синтаксичним аналізом і генерацією проміжного коду, як показано на рисунку 5.

Рисунок 5 Місце семантичного аналізатора в моделі компілятора.
Програма перевірки типів перевіряє, щоб тип конструкції відповідав очікуваному в даному контексті. Наприклад, вбудований арифметичний оператор mod в Pascal вимагає цілих операндів, тому програма перевірки типів повинна перевірити, щоб операнди mod в початковій програмі — цілого типу. Так само програма перевірки типів повинна переконатися, що операція розіменування застосовується до покажчика, індексація виконується з масивом, що визначена користувачем функція.
3.4 Розробка оптимізатора коду
компілятор програмування оболонка операційна
Оптимізація програмного коду - це модифікація програм, виконувана оптимізуючим компілятором або інтерпретатором з метою поліпшення їхніх характеристик, таких як продуктивності або компактності, - без зміни функціональності.
Оптимізація - не обов'язковий, але важливий етап компіляції. У принципі, вона може відбуватися під час трансляції програми, але, як правило, оптимізацію програми виділяють як окремий етап функціонування компіляторів. Компонувальники також можуть виконувати частина оптимізацій, таких як видалення невикористовуваних підпрограм або перевпорядкування підпрограм.
Розрізняють низько- і високорівневу оптимізацію. Низкорівнева оптимізація перетворює програму на рівні елементарних команд, наприклад, інструкцій процесорів архітектури x86. Високорівнева оптимізація здійснюється на рівні структурних елементів програми, таких як розгалуження й цикли.
3.5 Розробка генератора коду
Останньою стадією розробки компілятора є генератор коду, який дістає на вхід проміжне представлення вихідної програми і виводить еквівалентну цільову програму.
Традиційно, до генератора коду висуваються жорсткі вимоги. Вихідний код повинен бути коректним і високоякісним, що означає ефективне використання ресурсів цільової машини. Крім того, ефективно повинен бути розроблений і сам генератор коду.
Математично, проблема генерації оптимального коду є нерозв’язною. На практиці ми вимушені користуватись евристичними технологіями, які дають хороший, але не обов’язково оптимальний код. Вибір евристики дуже важливий, оскільки детально розроблений алгоритм розробки генератора коду може давати код, що працю в декілька раз швидше, ніж код отриманий недостатньо продуманим алгоритмом.
Хоча дрібні деталі генератора колу залежать від цільової машини і операційної системи, такі питання, як керування пам’яттю, вибір інструкцій, розподіл регістрів і порядок обчислень, властиві усім задачам, зв’язаним з генерацією коду.
Вхідний потік генератора коду являє собою проміжне представлення вихідної програми, отримане на початковій стадії компіляції, разом із таблицею символів, яка використовується для обчислення адрес часу виконання об’єктів даних, зазначених в проміжному представленні іменами.
Результатом генератора коду являється цільова програма. Подібно до проміжного коду, результат генератора коду може приймати різні види: абсолютний машинний код, переміщуваний машинний код, або асемблерна мова. Перевагою генерації абсолютної програми в машинному коді є те, що такий код поміщається у фіксоване місце пам’яті і негайно виконується. Невеликі програми при цьому швидко компілюються і виконуються.
Генерація переміщуваної програми у машинному коді (об’єктного модуля) забезпечує можливість роздільної компіляції підпрограм. Багато переміщуваних модулів можуть бути після цього зв’язані в одне ціле і завантажені на виконання спеціальною програмою – завантажувачем. Додаткові затрати на зв’язування і завантаження компенсуються можливістю роздільної компіляції підпрограм і викликом інших, раніше скомпільованих підпрограм із об’єктних модулів. Якщо цільова машина не обробляє переміщення автоматично, компілятор має надати завантажувачеві явну інформацю про переміщення для зв’язування сегментів роздільно скомпільованиз підпрограм.
Отримання на виході генератора коду програми на мові асемблера трохи полегшує процес генерації коду; в результаті ми можемо створювати символьні інструкції і використовувати можливості макросів асемблера. Плата за цю простоту – додатковий крок в обробці мови програмування асемблер після генерації коду.
4 Відладка та тестування компілятора
4.6.1 Виявлення лексичних помилок
Повідомлення про лексичну помилку виводиться, коли лексичний аналізатор знаходить лексему, що не відповідає лексиці мови програмування та ні одному з імен описаних користувачем змінних. Для перевірки розробленого компілятора на виявлення лексичних помилок внесемо в текст програми помилку – лексему BegAn.
'Error 13: Невідомий символ: BegAn '
З повідомлення стає зрозуміло, що в ході компіляції було виявлено невідомий символ ’ BegAn’ в 2-ому рядку.
Під час роботи сканера може виникнути помилка вище наведеного типу (тобто виявлено невідому лексему), а також неправильне оголошення ім’я змінної (коли першою є цифра).
Результат тестування в додатку Б.
4.6.2 Виявлення синтаксичних помилок
Повідомлення про синтаксичну помилку виводиться, коли синтаксичний аналізатор знаходить ланцюжок лексем, що не відповідає граматиці заданої мови. Для перевірки компілятора на виявлення синтаксичних помилок пропустимо в тексті програми роздільник «;
».
В результаті на екрані отримуємо наступні повідомлення:
Error15: Пропущено ; пiсля операцii writeln'
З повідомлення випливає, що в ході компіляції було виявлено синтаксичну помилку – пропущено роздільник ’;’. Після цього компіляцію було перервано.
Результат тестування в додатку Б.
Повідомлення про семантичну помилку виводиться семантичним аналізатором, коли у виразі не співпадають типи використовуваних змінних. Для перевірки компілятора на виявлення семантичних помилок внесемо в текст програми вираз з використанням змінних різних типів. Результат тестування в додатку Б.
'Error 18: Пропущено змінну: b'
З повідомлення випливає, що в ході компіляції було виявлено семантичну помилку – було виявлено неоголошену змінну b. Після чого компіляцію було перервано.
Можливі наступні типи семантичні помилок, що реалізовані в компіляторі:
1. Багатократне оголошення;
2. Змінна не оголошена;
3. Змінна не ініціалізована;
4. Не співпадіння типів змінних.
4.6.4 Загальна перевірка коректності роботи транслятора
Загальна перевірка полягає у здатності розробленого компілятора виконувати свої функції. Компілятор повинен транслювати програму у проміжне представлення на мові асемблер та створювати об’єктний і виконуваний файли за допомогою файлів tasm.exe та tlink.exe. Результат тестування в додатку Б.
Висновок
Під час виконання курсової роботи:
1. Складено формальний опис мови програмування М13 у формі розширеної нотації Бекуса-Наура, дано опис усіх символів та ключових слів.
2. Створено компілятор мови програмування М13, а саме:
2.1.1.Розроблено лексичний аналізатор, здатний розпізнавати лексеми, що є описані в формальному описі мови програмування, та додані під час безпосереднього використання компілятора.
2.1.2.Розроблено синтаксичний аналізатор на основі автомата з магазинною пам’яттю. Складено таблицю переходів для даного автомата згідно правил записаних в нотації у формі Бекуса-Наура.
2.1.3.Розроблено генератор коду, який починає свою роботу після того, як лексичним, синтаксичним та семантичним аналізатором не було виявлено помилок у програмі, написаній мовою М13. Проміжним кодом генератора є програма на мові Assembler(i8086). Вихідним кодом є машинний код, що міститься у виконуваному файлі
3. Проведене тестування компілятора за допомогою тестових програм за наступними пунктами:
3.1.1.Виявлення лексичних помилок.
3.1.2.Виявлення синтаксичних помилок.
3.1.3.Загальна перевірка роботи компілятора.
Тестування не виявило помилок в роботі компілятора, а всі помилки в тестових програмах мовою М13 були виявлені і дано попередження про їх наявність.
В результаті виконання даної курсової роботи було успішно засвоєно методи розробки та реалізації компонент системного програмного забезпечення.
1. Бек Л.С. Введение в системное програмирование. – М.:Мир, 1988.
2. Касаткин М.В. Касаткина Т.Я. Професиональное програмирование на языке С.В 3т. – М. Мир, 1989.//т.3. Системное програмирование.
3. Кузьмин А.Я. Лексический анализ. – М.:ВШ.,1985.
4. Фролов А.В. Проэктирование компиляторов. –М.: Мир,1989.
5. Страуструп Б. Введение в язык C++, 2001.
6. Ахо А., Сети Р., Ульман Дж.Компиляторы: принципы, технологии, инструменты. – М.: Издательский дом «Вильямс», 2003.
7. Джордейн Р. Справочник программиста ПК IBM PC, XT/AT. – М.: ФиС, 1992.
8. Абель П. Ассемблер для IBM PC, 1991.
9. Прата С. Язык программирования Си, 2003
Додатки
Додаток A
| № |
A |
B |
C |
D |
| 13 |
1 (byte) |
^ |
NOT |
while-do |
program TFirst;
uses App,dialogs,drivers,menus,objects,stddlg,views,validate;
type TMyApp=object(TApplication)
procedure InitStatusLine; virtual;
procedure InitMenuBar; virtual;
procedure NewWindow; virtual;
procedure HandleEvent(var Event:TEvent);virtual;
procedure NewDialog;virtual;
{procedure Init;virtual;}
end;
DialogData=record
{CheckBoxData:Word;
RadioButtonData:word;}
InputLineData:string[128];
end;
MyStruct=record
b:integer;
b1:integer;
c:string[32];
end;
PM13Window=^TM13Window;
TM13Window=object(TWindow)
constructor Init(Bounds:TRect;
WinTitle:string;WindowNo:Word);
procedure MakeInterior(Bounds:TRect);
end;
var M13DialogData:DialogData;
s1:string;
const
MaxLines=2000;
var LineCount:integer;
Lines:array [0..MaxLines-1]of PString;
type
PInterior=^TInterior;
TInterior=object(Tscroller)
constructor Init(var Bounds:TRect;AHScrollBar,
AVScrollBar:PScrollBar);
procedure Draw;virtual;
end;
const cmNewWin=199;cmFileOpen=200;WinCount:Integer=0;cmCompile=201;
procedure TMyApp.InitStatusLine;
var r:TRect;
begin
{GetExtent(r);}
r.a.y:=r.b.y+1;
StatusLine:=New(PStatusLine,Init(r,
NewStatusDef(0,$ffff,
NewStatusKey('~Alt-X~ Exit', kbAltX, cmQuit,
NewStatusKey('~Alt-F4~ New', kbF4, cmNewWin,
NewStatusKey('~Alt-F3~ Close', kbAltF3, cmClose,
NewStatusKey( '',kbF10, cmMenu,
nil)))),
nil)));
end;
procedure TMyApp.InitMenuBar;
var r:TRect;
begin
GetExtent(r);
r.b.y:=r.a.y+1;
MenuBar:=New(PMenuBar, Init(r, NewMenu(
NewSubMenu('~F~ile', hcNoContext, NewMenu(
NewItem('~O~pen', 'F3',kbF3,cmFileOpen, hcNoContext,
NewItem('~N~ew', 'F4',kbF4,cmNewWin, hcNoContext,
NewLine(
NewItem('E~x~it', 'Alt-x', kbAltX, cmQuit, hcNoContext,
nil))))),
NewSubMenu('~W~indow', hcNoContext, NewMenu(
NewItem('~N~ext', 'F6',kbF6,cmNext, hcNoContext,
NewItem('~Z~oom', 'F5',kbF5,cmZoom, hcNoContext,
nil))),
NewSubMenu('~C~ompile', hcNoContext, NewMenu(
NewItem('~C~ompile','Alt-F9',kbAltF9,cmCompile,hcNoContext,
nil)),
nil
))))));end;
procedure TMyApp.NewWindow;
var Window:PM13Window;
r:TRect;
i:integer;
begin
i:=0;
inc(WinCount);
r.assign(0,0,80,23-wincount+1);
r.move(0,i+wincount-1);
window:=new(pM13window, init(r, 'Compile window', wincount));
desktop^.insert(window);
end;
procedure TMyApp.NewDialog;
var
Dialog:PDialog;
R:TRect;
control:Word;
B:PView;
Window:PM13Window;
i:integer;
f:text;
s:string;
begin
R.Assign(20,6,60,19);
Dialog:=New(PDialog,Init(R,'M13 Dialog'));
with Dialog^ do
begin
R.Assign(15,10,25,12);
Insert(New(PButton,Init(R,'~O~K',cmOK,bfDefault)));
R.Assign(28,10,38,12);
Insert(New(PButton,Init(R,'Cancel',cmCancel,bfNormal)));
R.Assign(3,8,37,9);
B:=New(PInputLine,Init(r,128));
insert(b);
R.Assign(2,7,24,8);
insert(New(PLabel,Init(R,'Delivery instructions',B)));
end;
Dialog^.SetData(M13DialogData);
Control:=DeskTop^.ExecView(Dialog);
if Control<>cmCancel then Dialog^.GetData(M13DialogData);
i:=0;
while M13DialogData.InputLineData[i]<>'.' do
begin
s[i]:=M13DialogData.InputLineData[i];
i:=i+1;
end;
s[i]:=M13DialogData.InputLineData[i];
s[i+1]:=M13DialogData.InputLineData[i+1];
s[i+2]:=M13DialogData.InputLineData[i+2];
s[i+3]:=M13DialogData.InputLineData[i+3];
s1:=s;
LineCount:=0;
Assign(F,s);
reset(F);
while not Eof(F) and (LineCount<MaxLines)do
begin
readln(f,s);
lines[linecount]:=newstr(s);
inc(linecount);
{writeln(lines[linecount]^);}
end;
close(F);
i:=0;
inc(WinCount);
r.assign(0,0,80,23-wincount+1);
r.move(0,i+wincount-1);
window:=new(pM13window, init(r, s1, wincount));
desktop^.insert(window);
end;
function vuraz(var s:char):integer;
var
w:integer;
begin
if ((integer(s)>=97)and(integer(s)<=122))or((integer(s)>=65)and(integer(s)<=90))
then vuraz:=30
else vuraz:=29;
end;
procedure Compiles;
label aa;
var a1:array [1..100] of MyStruct;
i,j,j1,k,kk,i1,i2,var_kil,begin_kil,end_kil,var_index,begin_index,end_index:integer;
q,q1:string;
ss:array [1..50] of string[50];
f1,f2,f3,f4:text;
ch,ch1:char;
mn:string;
m,nerivne,m1,pa:integer;
begin
assign(f1,s1);
reset(f1);
i:=0;j:=0;
while s1[i]<>'.' do
begin
q[j]:=s1[i];q1[i]:=s1[i];
i:=i+1;j:=j+1;
end;
q[j]:=s1[i];j:=j+1;q[j]:='t';j:=j+1;q[j]:='x';j:=j+1;q[j]:='t';
q1[i]:=s1[i];q1[i+1]:='a';q1[i+2]:='s';q1[i+3]:='m';
for i:=1 to 100 do
a1[i].b:=0;
i1:=1;
assign(f2,q);
Rewrite(f2);
assign(f3,q1);
rewrite(f3);
j1:=1;k:=0;i:=1;
j:=1;
while not EOF(f1) do
begin
readln(f1,ss[j]);
a1[i].c[1]:=ss[j][1];j1:=2;ch1:=ss[j][1];
i2:=2;
while ss[j][i2]<>#0 do
begin
if (ss[j][i2]=' ')or(ss[j][i2]=';')or(ss[j][i2]='+')or(ss[j][i2]='-')or(ss[j][i2]='*')
or (ss[j][i2]='.')or(ss[j][i2]='/')or(ss[j][i2]=')')or(ss[j][i2]='(')or(ss[j][i2]=',')or(ss[j][i2]=':')
or(ss[j][i2]='=')or(ss[j][i2]='>')or(ss[j][i2]='<')or((ss[j][i2]='<')and(ss[j][i2]='>'))
or ((ss[j][i2]='=')and(ss[j][i2]='='))or(ss[j][i2]='^')
then begin
if (ch1=' ')or(ch1=';')or(ch1='+')or(ch1='-')or(ch1='*')
or (ch1='.')or(ch1='/')or(ch1=')')or(ch1='(')or(ch1=',')or(ch1=':')or(ch1='=')
or(ch1='>')or(ch1='<')or((ch1='<')and(ch1='>'))
or ((ch1='=')and(ch1='='))or(ch1='^')
then begin i:=i+1;end
else begin a1[i].c[j1]:=#0;i:=i+1;end;
ch1:=ss[j][i2];
a1[i].c[1]:=ss[j][i2];a1[i].c[2]:=#0;i:=i+1;j1:=1;
end
else begin a1[i].c[j1]:=ss[j][i2];j1:=j1+1;ch1:=ss[j][i2];end;
i2:=i2+1;
end;
j:=j+1;
end;
k:=i-1;
for i:=1 to k do
begin
if ((a1[i].c[1]='p')and( a1[i].c[2]='r')and( a1[i].c[3]='o')and( a1[i].c[4]='g')
and( a1[i].c[5]='r')and( a1[i].c[6]='a')and( a1[i].c[7]='m'))then a1[i].b:=1;
if (( a1[i].c[1]='v')and( a1[i].c[2]='a')and( a1[i].c[3]='r'))then a1[i].b:=2;
if (( a1[i].c[1]='b')and( a1[i].c[2]='y')and( a1[i].c[3]='t')and( a1[i].c[4]='e'))then a1[i].b:=3;
if (( a1[i].c[1]='c')and( a1[i].c[2]='h')and( a1[i].c[3]='a')and( a1[i].c[4]='r'))then a1[i].b:=4;
if (( a1[i].c[1]='b')and( a1[i].c[2]='o')and( a1[i].c[3]='o')and( a1[i].c[4]='l')
and( a1[i].c[5]='e')and( a1[i].c[6]='a')and( a1[i].c[7]='n'))then a1[i].b:=5;
if (( a1[i].c[1]='b')and( a1[i].c[2]='e')and( a1[i].c[3]='g')and( a1[i].c[4]='i')
and( a1[i].c[5]='n'))then a1[i].b:=7;
if (( a1[i].c[1]='w')and( a1[i].c[2]='r')and( a1[i].c[3]='i')and( a1[i].c[4]='t')
and( a1[i].c[5]='e')and( a1[i].c[6]='l')and( a1[i].c[7]='n'))then a1[i].b:=8;
if (( a1[i].c[1]='r')and( a1[i].c[2]='e')and( a1[i].c[3]='a')and( a1[i].c[4]='d')
and( a1[i].c[5]='l')and( a1[i].c[6]='n'))then a1[i].b:=9;
if (( a1[i].c[1]='e')and( a1[i].c[2]='n')and( a1[i].c[3]='d'))then a1[i].b:=15;
if (a1[i].c[1]=';')then a1[i].b:=16;
if (a1[i].c[1]=',')then a1[i].b:=17;
if (a1[i].c[1]='(')then a1[i].b:=18;
if (a1[i].c[1]=')')then a1[i].b:=19;
if (a1[i].c[1]='*')then a1[i].b:=20;
if (a1[i].c[1]='+')then a1[i].b:=21;
if (a1[i].c[1]='-')then a1[i].b:=22;
if (a1[i].c[1]='/')then a1[i].b:=23;
if (a1[i].c[1]=' ')then a1[i].b:=24;
if (a1[i].c[1]='\n')then a1[i].b:=25;
if (a1[i].c[1]=':')then a1[i].b:=26;
if (a1[i].c[1]='=')then a1[i].b:=27;
if (a1[i].c[1]='.')then a1[i].b:=28;
if (a1[i].c[1]='>')then a1[i].b:=29;
if (a1[i].c[1]='<')then a1[i].b:=30;
if ((a1[i].c[1]='!')and(a1[i].c[1]='=')) then a1[i].b:=31;
if ((a1[i].c[1]='=')and(a1[i].c[1]='=')) then a1[i].b:=32;
if (a1[i].c[1]='^')then a1[i].b:=33;
if (( a1[i].c[1]='N')and( a1[i].c[2]='O')
and( a1[i].c[3]='T'))then a1[i].b:=34;
end;
for i:=0 to k do
if a1[i].b=0 then a1[i].b:=vuraz(a1[i].c[1]);
var_kil:=0;begin_kil:=0;end_kil:=0;
for i:=1 to k do
begin
if a1[i].b=2 then var_kil:=var_kil+1;
if a1[i].b=7 then begin_kil:=begin_kil+1;
if a1[i].b=15 then end_kil:=end_kil+1;
end;
for i:=1 to k do
begin
writeln(f2,a1[i].b);
end;
if var_kil>1 then writeln(f2,'Error 1: Декiлька разiв вiдбуваеться опис даних');
if begin_kil>1 then writeln(f2,'Error 2: Декiлька разiв введено слово begin');
if end_kil>1 then writeln(f2,'Error 3: Декiлька разiв введено слово end');
if var_kil=0 then writeln(f2,'Error 4: Немає опису даних');
if begin_kil=0 then writeln(f2,'Error 5: Немає початку тiла програми');
if end_kil=0 then writeln(f2,'Error 6: Немає кiнця тiла програми');
if nevid=0 then writeln(f2,'Error 18: Невідома змінна:',k);
var_index:=0;begin_index:=0;end_index:=0;
for i:=1 to k do
begin
if a1[i].b=2 then var_index:=i;
if a1[i].b=7 then begin_index:=i;
if a1[i].b=15 then end_index:=i;
end;
for i:=var_index to begin_index do
begin
if a1[i].b=3 then begin if a1[i-1].b<>26 then
writeln(f2,'Error 7: Пропущено- : при описi змiнних типу Byte');
j:=i-2;
while a1[j].b<>16 do
begin
if a1[j].b=30 then a1[j].b:=35;
j:=j-1;
end;
end;
if a1[i].b=4 then begin if a1[i-1].b<>26then
writeln(f2,'Error 7: Пропущено- : при описi змiнних типу Char');
j:=i-2;
while a1[j].b<>26 do
begin
if a1[j].b=30 then a1[j].b:=36;
j:=j-1;
end;
end;
if a1[i].b=5 then begin if a1[i-1].b<>16then
writeln(f2,'Error 7: Пропущено- : при описi змiнних типу Boolean');
j:=i-2;
while a1[j].b<>16 do
begin
if a1[j].b=30 then a1[j].b:=37;
j:=j-1;
end;
end;
end;
assign(f4,'1.M13');
reset(f4);
readln(f4,mn);
writeln(f3,'ideal');
writeln(f3,'model small');
writeln(f3,'stack 256');
writeln(f3,'dataseg');
writeln(f3,'perkur db ',mn,'$',mn);
writeln(f3,'TrueStr db ',mn,'TRUE$',mn);
writeln(f3,'FalseStr db ',mn,'False$',mn);
writeln(f3,'InString db 255 DUP(?)');
writeln(f3,'OutString db 255 DUP(?)');
writeln(f3,'CharStr db 2,5 DUP(?)');
writeln(f3,'len dw ?');
for i:=var_index+1 to begin_index do
begin
if a1[i].b=31 then begin j:=1;
while a1[i].c[j]<>#0 do
begin
write(f3,a1[i].c[j]);
j:=j+1;
end;
writeln(f3,' dw ?');
end;
if a1[i].b=32 then begin j:=1;
while a1[i].c[j]<>#0 do
begin
write(f3,a1[i].c[j]);
j:=j+1;
end;
writeln(f3,' db ?');
end;
if a1[i].b=33 then begin j:=1;
while a1[i].c[j]<>#0 do
begin
write(f3,a1[i].c[j]);
j:=j+1;
end;
writeln(f3,' db ?');
end;
end;
writeln(f3,'codeseg');
writeln(f3,'start:');
writeln(f3,'mov ax,@data');
writeln(f3,'mov ds,ax');
i:=begin_index+1;
while i<>end_index do
begin
kk:=i;
if a1[i].b=8
then
begin
if (a1[i+1].b<>18)then writeln(f2,'Error: Пропущено ( при написаннi функцii writeln');
kk:=i+2;
while a1[kk].b<>19 do
begin
if (a1[kk].b<>17) or (a1[kk].b<>19) then
begin
for j:=var_index+1 to begin_index do
begin
if (copy(a1[kk].c,1,a1[kk].b1))=(copy(a1[j].c,1,a1[j].b1))
then a1[kk].b:=a1[j].b;
end;
writeln(a1[kk].b);
if a1[kk].b=31 then
begin
writeln(f3,'mov ax,[',copy(a1[kk].c,1,a1[kk].b1),']');
writeln(f3,'call WriteByte');
end;
if a1[kk].b=32 then
begin
writeln(f3,'mov al,[',copy(a1[kk].c,1,a1[kk].b1),']');
writeln(f3,'call WriteChar');
end;
if a1[kk].b=33 then
begin
writeln(f3,'mov al,[',copy(a1[kk].c,1,a1[kk].b1),']');
writeln(f3,'call WriteBool');
end;
end;
kk:=kk+1;
end;
if a1[kk+1].b<>16 then if a1[kk+2].b<>16 then
writeln(f2,'Error: Пропущено ; пiсля операцii writeln');
end;
if a1[i].b=9
then
begin
if (a1[i+1].b<>18)then writeln(f2,'Error: Пропущено ( при написаннi функцii writeln');
kk:=i+2;while a1[kk].b<>19 do
begin
if a1[kk].b<>17 then
begin
m:=0;while a1[kk].c[m]<>#0 do
m:=m+1;
m:=m+1;
for j:=var_index+1 to begin_index do
begin
nerivne:=0;m1:=0;
while m1<>m do
begin
if a1[kk].c[m1]=a1[j].c[m1] then nerivne:=nerivne+1;
m1:=m1+1
end;
if nerivne=m then a1[kk].b:=a1[j].b;
end;
if a1[kk].b=31 then
begin
writeln(f3,'call ReadInt');
writeln(f3,'mov [',a1[kk].c,'],ax');
end;
if a1[kk].b=32 then
begin
writeln(f3,'call ReadChar');
writeln(f3,'mov [',a1[kk].c,'],al');
end;
if a1[kk].b=33 then
begin
writeln(f3,'call ReadBool');
writeln(f3,'mov [',a1[kk].c,'],al');
end;
end;
kk:=kk+1;
end;
if a1[kk+1].b<>16 then if a1[kk+2].b<>16 then
writeln(f2,'Error 15: Пропущено ; пiсля операцii writeln');
end;
{if a1[i].b=30 then pa:=assign(a1,i);}
i:=kk+1;
end;
close(f3);
close(f2);
close(f1);
writeln('Кiнець');
end;
procedure TMyApp.HandleEvent(var Event:TEvent);
begin
TApplication.HandleEvent(Event);
if Event.What=evCommand then
begin
case Event.Command of
cmNewWin:NewWindow;
cmFileOpen:NewDialog;
cmCompile:Compiles;
else
Exit;
end;
ClearEvent(Event);
end;
end;
constructor TInterior.Init(var Bounds:TRect;AHScrollBar,
AVScrollBar:PScrollBar);
begin
TScroller.Init(Bounds,AHScrollBar,AVScrollBar);
GrowMode:=gfGrowHiX+gfGrowHiY;
SetLimit(128,LineCount);
end;
procedure TInterior.Draw;
var i,y:integer;
Color:Byte;
B:TDrawBuffer;
begin
Color:=GetColor(1);
for y:=0 to size.y-1 do
begin
MoveChar(B,' ',Color,Size.x);
i:=Delta.Y+y;
if (i<LineCount) and (Lines[i]<>nil) then
MoveStr(B,Copy(Lines[i]^,Delta.x+1,Size.x),Color);
writeLine(0,y,Size.x,1,b);
end;
end;
procedure ReadFile;
var
F:Text;
S:String;
begin
LineCount:=0;
Assign(F,'Test.M13');
reset(F);
while not Eof(F) and (LineCount<MaxLines)do
begin
readln(f,s);
lines[linecount]:=newstr(s);
inc(linecount);
{writeln(lines[linecount]^);}
end;
close(F);
end;
procedure TM13Window.MakeInterior(Bounds:Trect);
var
HScrollBar,VScrollBar:PScrollBar;
interior:PInterior;
R:TRect;
begin
VScrollBar:=StandardScrollBar(sbVertical+sbHandleKeyboard);
HScrollBar:=StandardScrollBar(sbHorizontal+sbHandleKeyboard);
Interior:=New(PInterior,Init(Bounds,HScrollBar,VScrollBar));
Insert(Interior);
end;
constructor TM13Window.Init(Bounds:TRect;
WinTitle:string;WindowNo:Word);
var s:string[3];
begin
str(WindowNo, s);
TWindow.Init(Bounds, WinTitle+' '+s, wnNoNumber);
GetExtent(Bounds);
Bounds.Grow(-1,-1);
MakeInterior(Bounds);
end;
procedure DoneFile;
var
i:integer;
begin
for i:=0 to linecount-1 do
if lines[i]<>nil then disposestr(lines[i]);
end;
var MyApp:TMyApp;
begin
MyApp.Init;
MyApp.Run;
MyApp.Done;
end.
Додаток Б
Тестова програма на мові M13 з лексичною помилкою:
'Error 13: Невідомий символ: BegAn '
program ja;
var a:byte;
begАn
a:=13;
writeln ('Varian :', a);
end.
Тестова програма на мові M13 з синтаксичною помилкою:
Error15: Пропущено ; пiсля операцii writeln'
program ja;
var a:byte;
begin
a:=13;
writeln ('Varian :', a)
end.
Тестова програма на мові M13 з семантичною помилкою:
'Error 18: Пропущено змінну: b'
program ja;
var a,c:byte;
begАn
a:=53;
b:=13;
c:=a+b;
writeln ('Varian :', b)
end.
Тестова програма на мові M13 без помилок:
program ja;
var a:byte;
begin
b:=13;
writeln ('Varian :', b);
end.

Рисунок 6 Вигляд працездатного компілятора.
|