Дипломная работа
на тему
Метод анализа главных компонентов регрессионной модели измерений средствами нейронных сетей
Содержание
Список сокращений
Введение
1. Организация нейронных сетей для вычисления дисперсионных характеристик случайных сигналов
1.1 Архитектуры нейронных сетей
1.2 Однослойные сети прямого распространения
1.3 Многослойные сети прямого распространения
1.4 Инварианты в структуре нейронной сети
1.5 Анализ главных компонентов алгоритмами самообучения нейронных сетей
1.5.1 Структура анализа главных компонентов
1.5.2 Основные представления данных
1.5.3 Матричная формулировка алгоритма самообучения
1.5.4 Анализ главных компонентов на основе фильтра Хебба
1.5.5 Исследование сходимости при решении главной компоненты сигнала
1.5.6 Оптимальность обобщенного алгоритма Хебба
1.5.7 Алгоритм GHA в сжатом виде
2. Оценка параметров регрессионных уравнений при аппроксимации дисперсионных распределений методом АГК
2.1 Организация наблюдений и регрессионные методы оценки параметров
2.2.1 Оценивание по конечному числу наблюдений
2.1.2 Оценки по методу наименьших квадратов
2.2 Нейронные сети и статистические характеристики
2.3 Различие нейронных сетей и статистики
2.4 Нейронные сети и статистические экспертные системы
2.5 Сети интервальных нейронов
2.6 Сети и свойства численных структур регрессионного анализа
2.6.1 Идея сингулярного разложения матрицы данных
2.6.2 Линейный МНК
2.7 Нелинейные решения проблем стандартного МНК
2.7.1 Аппроксимация линейным или нелинейным МНК
2.7.2 Нелинейный МНК с использованием гессиана или без него
2.7.3 Нелинейный МНК как обратная коммуникация
2.8 Решение параметров регрессионного уравнения с использованием аппроксимации ковариационной матрицы по данным ГК при обучении НС
Заключение
Библиографический список использованной литературы
Список сокращений
АГК – анализ главных компонент;
БД – база данных;
ИТ – информационные технологии;
МНК – метод наименьших квадратов;
НС – нейронные сети;
ОС – операционная система;
ПК – персональный компьютер;
ПО – программное обеспечение;
ЦОС – цифровая обработка сигналов;
ЭВМ – электронная вычислительная машина;
Введение
Одно из современных направлений технических исследований – поиск адаптивных методов адаптации и формул нейронных сетей к традиционным задачам цифровой обработки сигналов (анализ Фурье, свертка) и регрессионному анализу (МНК и его модификации). Причем данные задачи НС решает путем перевода пространства данных в пространство признаков, фактически изменяя входные размерности и формируя гиперпространства для поиска решения. НС имеет универсальную структуру, что бы напрямую моделировать решение задач ЦОС и ряд косвенных методов получения характеристик стохастических сред, которые потом можно использовать традиционными способами оценки параметров регрессионных моделей на основе свойств отношения корреляций и спектров исходных регрессий.
Реклама

Формирование пространства признаков с помощью унарных операторов, или их вещественных аналогов – ортогональных операторов (при ограниченной Евклидовой норме) – это основная особенность нейронных сетей, отличающая результат ее решений от методов ЦОС, регрессионного и спектрального анализа. Подобия их решений сеть находит на элементах анализа в пространстве признаков и самый простой способ обучения сети работает эффективней, чем, например, классический метод ЦОС при попытке того же разделения данных на признаки. Только специфичная формула сети прямого распространения способна с минимальной трудностью для алгоритмов ЭВМ построить систему независимых подмножеств – ортогональных подпространств собственных векторов, образующих совокупность унарных операторов преобразования пространства данных в пространство признаков той же или отличной размерности. Это принципиальное отличие НС от методов регрессионного анализа, у которых унарный оператор зависит от характеристик исходной среды и строится, например, минимизацией Евклидовой нормы вектора ошибки. Вектор имеет размерность только входного пространства данных, а условия для критерия его минимизации часто оказываются тривиальными, а отклонения, например в сторону корреляции нормируемых помех, уже приводит к несостоятельному результату оценки параметров или матрица корреляции данных, являющаяся основой минимизируемого функционала ошибки, становится вырожденной. В свою очередь, НС, преобразует пространство данных в пространство признаков, выполняя задачу статистического распознавания. Каждый признак на выходе нейрона получает собственный набор ортогональных векторов в виде весов этого нейрона, значения всех признаков в ортонормированных базисах также взаимно ортогональны. Это следует понимать как разложение исходного пространства данных в прямую сумму собственных подпространств, где собственными векторами являются веса нейронов, а собственными числами – значении их выходов после стадии самообучения. Эта общность на уровне линейных пространств способна порождать множество задач в области прикладного анализа в различных дисциплинах, с той разницей, что стадия анализа в НС наряду с компонентом анализа вычисляет совокупность собственных подсистем векторов в качестве унарного оператора, или ортогонального матричного оператора, например в виде ограниченной Евклидовой нормы.
Реклама

Главной задачей в статистическом распознавании является выделение признаков или извлечение признаков. Под выделением признаков понимается процесс, в котором пространство данных преобразуется в пространство признаков, теоретически имеющее ту же размерность, что и исходное пространство. Однако обычно преобразования выполняются таким образом, чтобы пространство данных могло быть представлено сокращенным количеством "эффективных" признаков. Это актуально и для регрессионных сред, где часть «незначащих» дисперсий ковариационной матрицы данных могут быть значительно меньше дисперсии помех, что приводит к несостоятельной оценке параметров регрессионных моделей. По существу цель преобразования стохастической среды в пространство признаком можно разделить на два существенных направления: выделение характеристик среды для методов корреляционного и дисперсионного анализа; изменение размерности исходных данных среды с потерей несущественных признаков в плане минимума их среднеквадратичной ошибки. Эти два направления должны выполнить задачу обеспечения регрессионных методов невырожденными унитарными операторами, когда априорной информации об ошибках измерений недостаточно или она трудно извлекаема из исходных данных среды.
Анализ главных компонентов осуществляет выделение главных признаков на этапе анализа; сокращает размерности, игнорируя незначащие величины признаков; при синтезе исходных данных проводит линейное преобразование, при котором сокращение будет оптимальным в смысле среднеквадратической ошибки. При осуществлении метода НС на исходных данных стохастической среды, собственными числами (выход нейрона) являются распределения дисперсий, собственные вектора (веса нейрона) – ортонормированная система собственного числа, образующая с ним собственное подпространство, где путем настройки ориентации весов решается задача экстремума для дисперсии. Совокупности дисперсий образуют диагональную матрицу – численный аналог корреляционной матрицы исходных данных, а совокупность весовых собственных подпространств формирует унарный, в вещественном смысле ортогональный, оператор. Матричное произведение ортонормированной системы и входной реализации случайной величины анализируют главные компоненты признаков, а дуальная операция признаков относительно ортогональной матрицы воссоздает исходный вектор данных стохастической среды. При этом выделяются главные признаки в дисперсионном распределении (диагональный оператор собственных чисел) при свойстве маленькой дисперсии отдельных компонентов. Таким образом, АКГ максимизирует скорость уменьшения дисперсии и вероятность правильного выбора. Алгоритмы обучения НС, основанные на принципах Хебба, после стадии самообучения НС осуществляют анализ главных компонентов интересующего вектора данных. Основным объектом АГК для регрессионного и дисперсионного анализа являются дисперсионные распределения, полученные дисперсионным зондом при настройке собственных подпространств в виде весов НС. Но, в отличие от критерия минимизации регрессионных методов, здесь применяется критерий определения таких единичных векторов из совокупности весов нейрона, для которых дисперсионный зонд принимает экстремальные значения. После настройки весов однослойной сети имеется решение – диагональная матрица, состоящая из собственных значений корреляционной матрицы данных (ортогональное преобразование подобия) и ортогональная матрица из объединения собственных векторов. Матричное произведение этих объектов приводит к результату, или получению числового оригинала дисперсий – корреляционной матрицы данных. То есть сама матрица корреляции может быть выражена в терминах своих собственных векторов и собственных значений по выражению спектральной теоремы. Преобразование подобия, спектральные операции синтеза данных являются теми общностями, на которые следует обратить внимание при регрессионном моделировании, если традиционные методы при малости априорной информации не позволяют получить достаточный объем данных из характеристик стохастической среды.
Еще раз уточним различие принципов АГК и оценивания параметров статистических регрессионных моделей в достижении одной цели – получения характеристик стохастических сред, в особенности наиважнейшей из них – корреляционной функции входного пространства данных. Именно разница принципов позволяет достигать результата при нехватке априорной информации – если мала априорная информация о помехах, то решение обращается к дисперсионным моделям случайных реализаций с их собственным ортонормированным пространством.
• Проекции дисперсий реализации случайной величины в ортонормированном векторном пространстве помех должны быть минимальны. Тем самым минимизируется корреляция аддитивных помех с выходом модели. Преимущество подхода – исследуется только модель шума, физическая природа полезного сигнала игнорируется. При этом параметры подбираются стохастически и функция оценки имеет определенный тип распределения.
• При АГК наоборот учитывается корреляционная модель сигнала, определяется ортогональный оператор таким образом, что бы проекции коэффициентов, предоставляемые корреляционной матрицей, были максимальны. Тогда на выходе нейронов в пространстве признаков формируются скаляры – дисперсии исходных реализаций случайной величины, или собственные числа корреляционной матрицы. Это преобразование подобия – результат самообучения сети, по результату которого возможно спектральное воссоздание корреляционной матрицы с максимальными дисперсиями в пространстве данных. Это и есть противоположность минимальной дисперсии данных в ортонормированном пространстве вектора помех. Максимум дисперсий данных в АГК и минимум функционала ошибки регрессионных линейных статических методов способствуют состоятельным оценкам решения.
Теперь можно сделать выводы, касающиеся продукции анализа главных компонентов по отношению к регрессионному анализу.
• Собственные векторы матрицы корреляции случайного вектора данных с нулевым средним определяют настраиваемые веса НС; они представляют основные направления, вдоль которых дисперсионный зонд (выхода нейронов) принимает экстремальные значения.
• Экстремальные значения дисперсионного зонда – это собственные числа корреляционной матрицы входных данных; последовательность чисел образует преобразование подобия этой матрицы в виде диагонального оператора.
Формально результат анализа – это проекции вектора данных на основные направления, представленные единичными векторами в виде весов каждого нейрона НС. Эти проекции называются главными компонентами и их количество соответствует размерности вектора данных.
Итак, выбрав тему работы на принципах АГК, нужно представлять выполняемые задачи как проблемы математического анализа на граничном пересечении технологий и методов корреляционной оценки параметров стохастических моделей и адаптивных алгоритмов пространственных преобразований. Для основного объема работы следует выбрать три формулы АГК на базе ортогонального оператора, полученного средствами НС.
• Формула ортогонального преобразования получения подобия корреляционной матрицы данных – диагонального оператора из дисперсий пространства данных.
• Формула анализа – вычисление проекции вектора реализации случайной величины в каждой ортогональной подсистеме собственных векторов.
• Спектральная формула синтеза ковариационной матрицы по исходной реализации случайного вектора данных.
Формула синтеза исходных данных с сокращением размерности может не приниматься во внимание, так как она в основном относится к задачам распознавания образов в пространстве признаков; проблема текущей темы – расчет скалярных и векторных величин в пространстве признаков НС для решения плохо обусловленных задач регрессионного анализа.
Актуальность работы: возможность использования эффективных численных методов на алгоритмах ЭВМ при решении регрессионных методов, но в условиях дефицита априорной информации о помехах.
Целю работы является разработка технологии применения метода АГК в решении плохо обусловленных задач статического регрессионного анализа.
Основные задачи, определенные в соответствии с поставленной целью квалификационной работы:
– анализ существующих методов идентификации статических моделей статистических объектов;
– анализ основных проблем решения регрессионных задач линейными методами при дефиците априорной информации о помехах;
– изучение пространственных характеристик АГК и структур НС при обработке ими стохастических сред;
– создание на основе выявленных критериев состоятельности методов АГК описания принципов адаптации АГК к проблемам регрессионного анализа;
– модернизация классических технологий получения дисперсионных характеристик стохастических сред алгоритмами самообучения НС в пространстве признаков;
– составление алгоритмов на основе АГК, содействующие регрессионному анализу, тесты эталонных моделей с истинными параметрами;
– составление ряда рекомендаций по использованию разработанных адаптивных алгоритмов с корреляционными методами получения оценок для регрессионных моделей.
1. Организация нейронных сетей для вычисления дисперсионных характеристик случайных сигналов
1.1 Архитектура сетей
Структура нейронных сетей тесно связана с используемыми алгоритмами обучения. Классификация алгоритмов обучения будет приведена в следующей главе, а вопросы их построения будут изучены в последующих главах. В данном разделе мы сосредоточим внимание на архитектурах сетей (структурах).
В общем случае можно выделить три фундаментальных класса нейросетевых архитектур.
1.2 Однослойные сети прямого распространения
В многослойной нейронной сети нейроны располагаются по слоям. В простейшем случае в такой сети существует входной слой (inputlayer) узлов источника, информация от которого передается на выходной слой (outputlayer) нейронов (вычислительные узлы), но не наоборот. Такая сеть называется сетью прямого распространения (feedforward) или ацикличной сетью (acyclic). На рис. 1.1 показана структура такой сети для случая четырех узлов в каждом из слоев (входном и выходном). Такая нейронная сеть называется однослойной (single-layernetwork), при этом под единственным слоем подразумевается слой вычислительных элементов (нейронов). При подсчете числа слоев мы не принимаем во внимание узлы источника, так как они не выполняют никаких вычислений.
1.3 Многослойные сети прямого распространения
Другой класс нейронных сетей прямого распространения характеризуется наличием одного или нескольких скрытых слоев (biddenlayer), узлы которых называются скрытыми нейронами (hiddenneuron), или скрытыми элементами (hiddenunit). Функция последних заключается в посредничестве между внешним входным сигналом и выходом нейронной сети. Добавляя один или несколько скрытых слоев, мы можем выделить статистики высокого порядка.
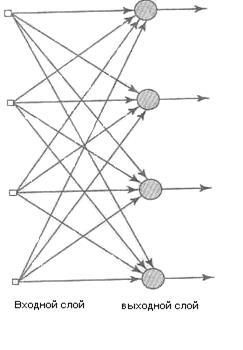
Рисунок 1.1 - Сеть прямого распространения с одним слоем нейронов
Такая сеть позволяет выделять глобальные свойства данных помощью локальных соединений за счет наличия дополнительных синаптических связей и повышения уровня взаимодействия нейронов. Способность скрытых нейронов выделять статистические зависимости высокого порядка особенно существенна, когда размер входного слоя достаточно велик.
Узлы источника входного слоя сети формируют соответствующие элементы шаблона активации (входной вектор), которые составляют входной сигнал, поступающий на нейроны (вычислительные элементы) второго слоя (т.е. первого скрытого слоя). Выходные сигналы второго слоя используются в качестве входных для третьего слоя и т.д. Обычно нейроны каждого из слоев сети используют в качестве входных сигналов выходные сигналы нейронов только предыдущего слоя. Набор выходных сигналов нейронов выходного (последнего) слоя сети определяет общий отклик сети на данный входной образ, сформированный узлами источника входного (первого) слоя. Сеть, показанная на рис. 1.1, называется сетью 10-4-2, так как она имеет 10 входных, 4 скрытых и 2 выходных нейрона. В общем случае сеть прямого распространения с m входами, h1нейронами первого скрытого слоя, h2 нейронами второго скрытого слоя и qнейронами выходного слоя называется сетью m — h1— h2—q-
Нейронная сеть, показанная на рис. 1.1, считается полносвязной (fullyconnected) в том смысле, что все узлы каждого конкретного слоя соединены со всеми узлами смежных слоев. Если некоторые из синаптических связей отсутствуют, такая сеть называется неполносвязной (partiallyconnected).
1.4 Инварианты в структуре нейронной сети
Рассмотрим следующие физические явления.
• Если исследуемый объект вращается, то соответствующим образом меняется и его образ, воспринимаемый наблюдателем.
• В когерентном радаре, обеспечивающем информацию об амплитуде и фазе источников окружающей среды, эхо от движущегося объекта смещено по частоте. Это связано с эффектом Доплера, который возникает при радиальном движении объекта наблюдения относительно радара.
• Диктор может произносить слова как тихим, так и громким голосом, как медленно, так и скороговоркой.
Для того чтобы создать систему распознавания объекта, речи или эхо-локации, учитывающую явления такого рода, необходимо принимать во внимание диапазон трансформаций (transformation) наблюдаемого сигнала. Соответственно основным требованием при распознавании образов является создание такого классификатора, который инвариантен к этим трансформациям. Другими словами, на результат классификации не должны оказывать влияния трансформации входного сигнала, поступающего от объекта наблюдения.
Существуют как минимум три приема обеспечения инвариантности нейронной сети классификации к подобным трансформациям.
1. Структурная инвариантность (invariancebystructure). Инвариантность может быть привнесена в нейронную сеть с помощью соответствующей структуризации. В частности, синаптические связи между отдельными нейронами сети строятся таким образом, чтобы трансформированные версии одного и того же сигнала вызывали один и тот же выходной сигнал. Рассмотрим для примера нейросетевую классификацию входного сигнала, которая должна быть инвариантна по отношению к плоскому вращению изображения относительно своего центра. Структурную инвариантность сети относительно вращения можно выразить следующим образом. Пусть Wji— синаптический вес нейрона j, связанного с пикселем iвходного изображения. Если условие Wji = Wjkвыполняется для всех пикселей jи k, лежащих на равном удалении от центра изображения, нейронная сеть будет инвариантной к вращению. Однако, для того чтобы обеспечить инвариантность относительно вращения, нужно дублировать синаптические веса Wjiвсех пикселей, равноудаленных от центра изображения. Недостатком структурной инвариантности является то, что количество синаптических связей изображения даже среднего размера будет чрезвычайно велико.
 
Рисунок 1.2 - Диаграмма системы, использующей пространство инвариантных признаков
2. Инвариантность по обучению (invariancebytraining). Нейронные сети обладают естественной способностью классификации образов. Эту способность можно использовать для обеспечения инвариантности сети к трансформациям. Сеть обучается на множестве примеров одного и того же объекта, при этом в каждом примере объект подается в несколько измененном виде (например, снимки с разных ракурсов). Если количество таких примеров достаточно велико и если нейронная сеть обучена отличать разные точки зрения на объект, можно ожидать, что эти данные будут обобщены и сеть сможет распознавать ракурсы объекта, которые не использовались при обучении. Однако с технической точки зрения инвариантность по обучению имеет два существенных недостатка. Во-первых, если нейронная сеть была научена распознавать трансформации объектов некоторого класса, совсем не обязательно, что она будет обладать инвариантностью по отношению к трансформациям объектов других классов. Во-вторых, такое обучение является очень ресурсоемким, особенно при большой размерности пространства признаков.
3. Использование инвариантных признаков (invariantfeaturespace). Третий метод создания инвариантного нейросетевого классификатора проиллюстрирован на рис. 1.2. Он основывается на предположении, что из входного сигнала можно выделить информативные признаки, которые описывают самую существенную информацию, содержащуюся в наборе данных, и при этом инвариантны к трансформациям входного сигнала. При использовании таких признаков в нейронной сети не нужно хранить лишний объем информации, описывающей трансформации объекта. В самом деле, при использовании инвариантных признаков отличия между разными экземплярами одного и того же объекта могут быть вызваны только случайными факторами, такими как шум. Использование пространства инвариантных признаков имеет три важных преимущества. Во-первых, уменьшается количество, признаков, которые подаются в нейронную сеть. Во-вторых, ослабляются требования к структуре сети. И, в-третьих, гарантируется инвариантность всех объектов по отношению к известным трансформациям. Однако этот подход требует хорошего знания специфики проблемы.
Итак, из вышесказанного можно сделать вывод, что использование инвариантных признаков является наиболее подходящим методом для обеспечения инвариантности нейросетевых классификаторов.
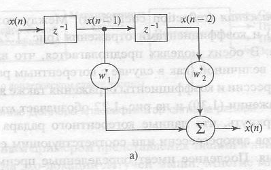
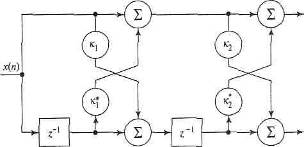
Рисунок 1.3 - Модель авторегрессии второго порядка: модель фильтра на линии задержки с отводами (а) и модель решетчатого фильтра (б).
Чтобы проиллюстрировать идею пространства инвариантных признаков, рассмотрим в качестве примера систему когерентного радара, используемую авиадиспетчерами, во входном сигнале которой может содержаться информация, поступающая от самолетов, стаи птиц и некоторых погодных явлений. Сигнал радара, отраженный от различных целей, имеет разные спектральные характеристики. Более того, экспериментальные исследования показали, что сигнал такого радара можно промоделировать с помощью авторегрессионного процесса (AR-процесса) среднего порядка (autoregressiveprocessofmoderateorder). AR-процесс представляет собой особый вид регрессионной модели, описываемой следующим образом:
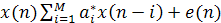 (1.1) (1.1)
где 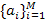 — коэффициенты (coefficient) авторегрессии; М — порядок модели (modelorder); x(n) — входной сигнал (inputsignal); e(n) — помеха (error), представляющая собой белый шум. Модель, описанная формулой (1.1), представляет собой фильтр на линии задержки с отводами (tapped-delay-linefilter), показанный на рис. 1.3, а для М = 2. Аналогично, ее можно представить как решетчатый фильтр (latticefilter), показанный на рис. 1.3, б, коэффициенты которого называются коэффициентами отражения (reflectioncoefficient). Между коэффициентами авторегрессии (рис. 1.3, а) и коэффициентами отражения (рис. 1.3, б) существует однозначное соответствие. В обеих моделях предполагается, что входной сигнал x(n) является комплексной величиной (как в случае с когерентным радаром), в которой коэффициенты авторегрессии и коэффициенты отражения также являются комплексными. Звездочка в выражении (1.1) и на рис. 1.3 обозначает комплексное сопряжение. Здесь важно подчеркнуть, что данные когерентного радара можно описать множеством коэффициентов авторегрессии или соответствующим ему множеством коэффициентов отражения. Последнее имеет определенные преимущества в плане сложности вычислений. Для него существуют эффективные алгоритмы получения результата непосредственно из входных данных. Задача выделения признаков усложняется тем фактом, что движущиеся объекты характеризуются переменными доплеровскими частотами, которые зависят от скорости объекта относительно радара и создают искажения в спектре коэффициентов отражения, по которым определяются признаки. Для того чтобы обойти эту сложность, в процессе вычисления коэффициентов отражения следует использовать инвариантность Доплера (Dopplerinvariance). Угол фазы первого коэффициента отражения принимается равным доплеровской частоте сигнала радара. Соответственно для всех коэффициентов выполняется нормировка относительно доплеровской частоты, устраняющая влияние сдвига доплеровской частоты. Для этого определяется новое множество коэффициентов отражения кm, связанных с множеством исходных коэффициентов отражения Кm следующим соотношением: — коэффициенты (coefficient) авторегрессии; М — порядок модели (modelorder); x(n) — входной сигнал (inputsignal); e(n) — помеха (error), представляющая собой белый шум. Модель, описанная формулой (1.1), представляет собой фильтр на линии задержки с отводами (tapped-delay-linefilter), показанный на рис. 1.3, а для М = 2. Аналогично, ее можно представить как решетчатый фильтр (latticefilter), показанный на рис. 1.3, б, коэффициенты которого называются коэффициентами отражения (reflectioncoefficient). Между коэффициентами авторегрессии (рис. 1.3, а) и коэффициентами отражения (рис. 1.3, б) существует однозначное соответствие. В обеих моделях предполагается, что входной сигнал x(n) является комплексной величиной (как в случае с когерентным радаром), в которой коэффициенты авторегрессии и коэффициенты отражения также являются комплексными. Звездочка в выражении (1.1) и на рис. 1.3 обозначает комплексное сопряжение. Здесь важно подчеркнуть, что данные когерентного радара можно описать множеством коэффициентов авторегрессии или соответствующим ему множеством коэффициентов отражения. Последнее имеет определенные преимущества в плане сложности вычислений. Для него существуют эффективные алгоритмы получения результата непосредственно из входных данных. Задача выделения признаков усложняется тем фактом, что движущиеся объекты характеризуются переменными доплеровскими частотами, которые зависят от скорости объекта относительно радара и создают искажения в спектре коэффициентов отражения, по которым определяются признаки. Для того чтобы обойти эту сложность, в процессе вычисления коэффициентов отражения следует использовать инвариантность Доплера (Dopplerinvariance). Угол фазы первого коэффициента отражения принимается равным доплеровской частоте сигнала радара. Соответственно для всех коэффициентов выполняется нормировка относительно доплеровской частоты, устраняющая влияние сдвига доплеровской частоты. Для этого определяется новое множество коэффициентов отражения кm, связанных с множеством исходных коэффициентов отражения Кm следующим соотношением:
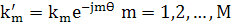 (1.2) (1.2)
где q — фазовый угол первого коэффициента отражения. Операция, описанная выражением (1.2), называется гетеродинированием (heterodyning). Исходя из этого, набор инвариантных к смещению Доплера признаков (Doppler-invariantradarfeature) представляется нормированными коэффициентами отражения к'1,к'2, ..., 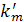 -где -где 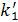 — единственный коэффициент этого множества с вещественным значением. Как уже отмечалось, основными категориями объектов, выделяемых радарной установкой, являются стаи птиц, самолеты, погодные явления и поверхность земли. Первые три категории объектов являются движущимися, в то время как последняя — нет Гетеродинные спектральные параметры эха радара от земли аналогичны соответствующим параметрам эха от самолета. Отличить эти два сигнала можно по наличию у эха от самолета небольшого смещения Доплера. Следовательно, классификатор радара должен содержать постпроцессор. Он обрабатывает результаты классификации с целью идентификации класса земли. Препроцессор (preprocessor) обеспечивает инвариантность признаков по отношению к смещению Доплера, в то время как постпроцессор использует смещение Доплера для разделения объектов "самолет" и "земля" в выходном сигнале. — единственный коэффициент этого множества с вещественным значением. Как уже отмечалось, основными категориями объектов, выделяемых радарной установкой, являются стаи птиц, самолеты, погодные явления и поверхность земли. Первые три категории объектов являются движущимися, в то время как последняя — нет Гетеродинные спектральные параметры эха радара от земли аналогичны соответствующим параметрам эха от самолета. Отличить эти два сигнала можно по наличию у эха от самолета небольшого смещения Доплера. Следовательно, классификатор радара должен содержать постпроцессор. Он обрабатывает результаты классификации с целью идентификации класса земли. Препроцессор (preprocessor) обеспечивает инвариантность признаков по отношению к смещению Доплера, в то время как постпроцессор использует смещение Доплера для разделения объектов "самолет" и "земля" в выходном сигнале.
1.5 Анализ главных компонентов алгоритмами самообучения нейронных сетей
Главной задачей в статистическом распознавании является выделение признаков (featureselection) или извлечение признаков (featureextraction). Под выделением признаков понимается процесс, в котором пространство данных (dataspace) преобразуется в пространство признаков (featurespace), теоретически имеющее ту же размерность, что и исходное пространство. Однако обычно преобразования выполняются таким образом, чтобы пространство данных могло быть представлено сокращенным количеством "эффективных" признаков. Таким образом, остается только существенная часть информации, содержащейся в данных. Другими словами, множество данных подвергается сокращению размерности (dimensionalityreduction). Для большей конкретизации предположим, что существует некоторый вектор х размерности т, который мы хотим передать с помощью iчисел, где i< т. Если мы просто обрежем вектор х, это приведет к тому, что среднеквадратическая ошибка будет равна сумме дисперсий элементов, "вырезанных" из вектора х. Поэтому возникает вопрос: "Существует ли такое обратимое линейное преобразование Т, для которого обрезание вектора Тх будет оптимальным в смысле среднеквадратической ошибки?" Естественно, при этом преобразование Т должно иметь свойство маленькой дисперсии своих отдельных компонентов. Анализ главных компонентов (в теорий информации он называется преобразование Карунена—Лоева (Karhunen-Loevetransformation)) максимизирует скорость уменьшения дисперсии и, таким образом, вероятность правильного выбора. В этой главе описываются алгоритмы обучения, основанные на принципах Хебба, которые осуществляют анализ главных компонентов интересующего вектора данных.
Пусть X — m-мерный случайный вектор, представляющий интересующую нас среду. Предполагается, что он имеет нулевое среднее значение
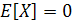 , ,
гдеE — оператор статистического ожидания. Если X имеет ненулевое среднее, можно вычесть это значение еще до начала анализа. Пусть q—единичный вектор (unitvector) размерности т, на который проектируется вектор X. Эта проекция определяется как скалярное произведение векторов X и q:
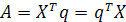 (1.3) (1.3)
при ограничении
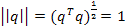 (1.4) (1.4)
Проекция А представляет собой случайную переменную со средним значением и с дисперсией, связанными со статистикой случайного вектора X. В предположении, что случайный вектор X имеет нулевое среднее значение, среднее значение его проекции А также будет нулевым:
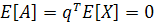
Таким образом, дисперсия А равна
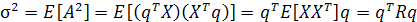 (1.5) (1.5)
Матрица R размерности т х т является матрицей корреляции случайного вектора X. определяемой как ожидание произведения случайного вектора X самого на себя:
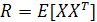 (1.6) (1.6)
Матрица R является симметричной, т.е.
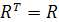 (1.7) (1.7)
Из этого следует, что если а и b — произвольные векторы размерности т х 1, то
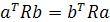 (1.8) (1.8)
Из выражения (1.5) видно, что дисперсия  2 проекции А является функцией единичного вектора q. Таким образом, можно записать: 2 проекции А является функцией единичного вектора q. Таким образом, можно записать:
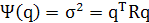 (1.9) (1.9)
на основании чего ψ(q) можно представить как дисперсионный зонд (varianceprobe).
1.5.1 Структура анализа главных компонентов
Следующим вопросом, подлежащим рассмотрению, является поиск тех единичных векторов q, для которых функция ψ(q) имеет экстремальные или стационарные значения (локальные максимумы и минимумы) при ограниченной Евклидовой норме вектора q. Решение этой задачи лежит в собственной структуре матрицы корреляции R. Если q — единичный вектор, такой, что дисперсионный зонд ψ(q) имеет экстремальное значение, то для любого возмущения 6q единичного вектора q выполняется!
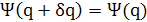 (1.10) (1.10)
Из определения дисперсионного зонда можем вывести следующее соотношение:
 , ,
где во второй строке использовалось выражение (1.8). Игнорируя слагаемое второго порядка (δq)TRδq и используя определение (1.9), можно записать следующее:
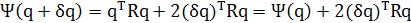 (1.11) (1.11)
Отсюда, подставляя (1.10) в (1.11), получим:
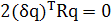 , (1.12) , (1.12)
Естественно, любые возмущения δq вектора q нежелательны; ограничим их только теми возмущениями, для которых норма возмущенного вектора q+δq остается равной единице, т.е.
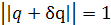
или, что эквивалентно,
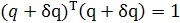 , ,
Исходя из этого, в свете равенства (1.4) требуется, чтобы для возмущения первого порядка δq выполнялось соотношение
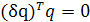 (1.13) (1.13)
Это значит, что возмущения δq должны быть ортогональны вектору q и, таким образом, допускаются только изменения в направлении вектора q.
Согласно соглашению, элементы единичного вектора q являются безразмерными в физическом смысле. Таким образом, можно скомбинировать (1.12) и (1.13), введя дополнительный масштабирующий множитель l, в последнее равенство с той же размерностью, что и вхождение в матрицу корреляции R. После этого можно записать следующее:
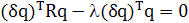 , ,
или, эквивалентно,
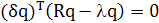 , (1.14) , (1.14)
Для того чтобы выполнялось условие (1.14), необходимо и достаточно, чтобы
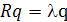 (1.15) (1.15)
Это — уравнение определения таких единичных векторов q, для которых дисперсионный зонд ψ (q) принимает экстремальные значения.
В уравнении (1.15) можно легко узнать задачу определения собственных значений (eigenvalue: problem) из области линейной алгебры. Эта задача имеет нетривиальные решения (т.е. q≠ 0) только для некоторых значений l, которые называются собственными значениями (eigenvalue) матрицы корреляции R. При этом соответствующие векторы q называют собственными векторами (eigenvector). Матрица корреляции характеризуется действительными, неотрицательными собственными значениями. Соответствующие собственные векторы являются единичными (если все собственные значения различны). Обозначим собственные значения матрицы R размерности т х т как l1, l2,,.., lm, а соответствующие им собственные векторы -q1, q2,...,qmсоответственно. Тогда можно записать следующее:
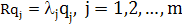 (1.16) (1.16)
Пусть соответствующие собственные значения упорядочены следующим образом:
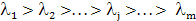 , (1.17) , (1.17)
При этом l1 будет равно lmax. Пусть из соответствующих собственных векторов построена следующая матрица размерности т х т:
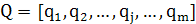 (1.18) (1.18)
Тогда систему т уравнений (1.16) можно объединить в одно матричное уравнение:
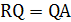 (1.19) (1.19)
где А — диагональная матрица, состоящая из собственных значений матрицы R:
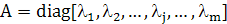 (1.20) (1.20)
Матрица Q является ортогональной (унитарной) в том смысле, что векторы-столбцы (т.е. собственные векторы матрицы R) удовлетворяют условию ортогональности:
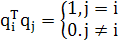 (1.21) (1.21)
Выражение (1.21) предполагает, что собственные значения различны. Эквивалентно, можно записать:
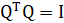
из чего можно заключить, что обращение матрицы Q эквивалентно ее транспонированию:
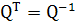 (1.22) (1.22)
Это значит, что выражение (8.17) можно переписать в форме, называемой ортогональным преобразованием подобия (orthogonalsimilaritytransformation):
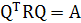 (1.23) (1.23)
или в расширенной форме:
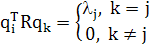 (1.24) (1.24)
Ортогональное преобразование подобия (1.23) трансформирует матрицу корреляции R в диагональную матрицу, состоящую из собственных значений. Сама матрица корреляции может быть выражена в терминах своих собственных векторов и собственных значений следующим образом:
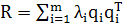 (1.25) (1.25)
Это выражение называют спектральной теоремой (spectraltheorem). Произведение векторов 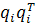 имеет ранг 1 для всех i. имеет ранг 1 для всех i.
Уравнения (1.23) и (1.25) являются двумя эквивалентными представлениями разложения по собственным векторам (eigencomposition) матрицы корреляции R.
Анализ главных компонентов и разложение по собственным векторам матрицы R являются в сущности одним и тем же; различается только подход к задаче. Эта эквивалентность следует из уравнений (1.9) и (1.25), из которых ясно видно равенство собственных значений и дисперсионного зонда, т.е.
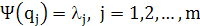 (1.26) (1.26)
Теперь можно сделать выводы, касающиеся анализа главных компонентов.
• Собственные векторы матрицы корреляции R принадлежат случайному вектору X с нулевым средним значением и определяют единичные векторы qj, представляющие основные направления, вдоль которых дисперсионный зонд Ψ(qj) принимает экстремальные значения.
• Соответствующие собственные значения определяют экстремальные значения дисперсионного зонда Ψ(uj)
1.5.2 Основные представления данных
Пусть вектор данных х является реализацией случайного вектора X.
При наличии т возможных значений единичного вектора q следует рассмотреть т возможных проекций вектора данных х. В частности, согласно формуле (1.3)
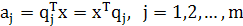 (1.27) (1.27)
где aj— проекции вектора х на основные направления, представленные единичными векторами qj. Эти проекции aj- называют главными компонентами (principalcomponent). Их количество соответствует размерности вектора данных х
. При этом формулу (1.27) можно рассматривать как процедуру анализа (analysis).
Для того чтобы восстановить вектор исходных данных х
непосредственно из проекций aj, выполним следующее. Прежде всего объединим множество проекций { aj | j= 1,2,..., m} в единый вектор:
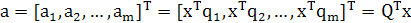 (1.28) (1.28)
Затем перемножим обе части уравнения (1.28) на матрицу Q, после чего используем соотношение (1.22). В результате исходный вектор данных х будет реконструирован в следующем виде:
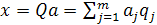 (1.29) (1.29)
который можно рассматривать как формулу синтеза. В этом контексте единичные векторы qjбудут представлять собой пространства данных. И в самом деле, выражение (1.29) является не чем иным, как преобразованием координат, в соответствии с которым точки х пространства данных преобразуются в соответствующие точки а пространства признаков.
1.5.3 Матричная формулировка алгоритма
самообучения
Для удобства выкладок введем следующие обозначения:
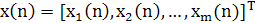 (1.30) (1.30)
и
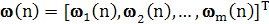 (1.31) (1.31)
Входной вектор x(n) и вектор синаптических весов w
(n) обычно являются реализациями случайных векторов. Используя это векторное представление, выражение (1.26) можно переписать в форме скалярного произведения:
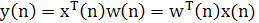 (1.32) (1.32)
Аналогично, выражение (1.30) можно переписать в следующем виде:
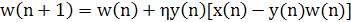 (1.33) (1.33)
Подставляя (1.32) в (1.33), получим:
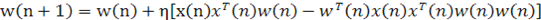 (1.34) (1.34)
Алгоритм обучения (1.34) представляет собой нелинейное стохастическое разностное уравнение (nonlinearstochasticс differenceequation), которое делает анализ сходимости этого алгоритма сложным с математической точки зрения. Для того чтобы обеспечить базис для анализа сходимости, немного отвлечемся от поставленной задачи и обратимся к общим методам анализа сходимости стохастических алгоритмов аппроксимации.
1.5.4 Анализ главных компонентов на основе фильтра Хебба
Описанный в предыдущем разделе фильтр Хебба извлекает первый главный компонент из входного сигнала. Линейная модель с одним нейроном может быть расширена до сети прямого распространения с одним слоем линейных нейронов с целью анализа главных компонентов для входного сигнала произвольной размерности.
Для большей конкретизации рассмотрим сеть прямого распространения, показанную на рис. 8.6. В ней сделаны следующие допущения относительно структуры:
1.Все нейроны выходного слоя сети являются линейными.
2.Сеть имеет т
входов и Iвыходов. Более того, количество выходов меньше количества входов (т.е. I <т).
Обучению подлежит только множество синаптических. весов {wji}, соединяющих узлы i
входного слоя с вычислительными узлами jвыходного слоя, где i = l,2,...,m; j= 1,2,..., l.
Выходной сигнал уi, (п) нейрона jв момент времени п, являющийся откликом на множество входных воздействий {xi(п) i = 1,2,..., m}, определяется по следующей формуле (рис. 8.7, а):
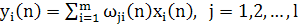 (1.35) (1.35)
Синаптический вес wji(n) настраивается в соответствии с обобщенной формой правила обучения Хебба:
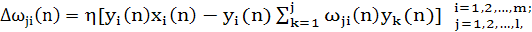 (1.36) (1.36)
где wji(n) — коррекция, применяемая к синаптическому весу wji(n) в момент времени n; η — параметр скорости обучения. Обобщенный алгоритм обучения Хеббa(generalizedHebbianalgorithm — GHA) (1.36) для слоя из lнейронов включает в себе алгоритм (8.39) для одного нейрона в качестве частного случая, т.е. для l = 1.
Для того чтобы заглянуть вглубь обобщенного алгоритма обучения Хебба, перепишем уравнение (8.80) в следующем виде:
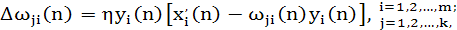 (1.37) (1.37)
где х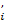 (п) — модифицированная версия i-го элемента входного вектора х(n), являющаяся функцией индекса j, т.е. (п) — модифицированная версия i-го элемента входного вектора х(n), являющаяся функцией индекса j, т.е.
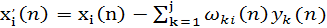 (1.38) (1.38)
Для конкретного нейрона jалгоритм, описанный выражением (1.37), имеет ту же математическую форму, что и (8.39), за исключением того факта, что в (1.38) входной сигнал xi(n) заменен его модифицированным значением х(n). Теперь можно сделать следующий шаг и переписать выражение (1.37) в форме, соответствующей постулату обучения Хебба:
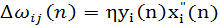 (1.39) (1.39)
где
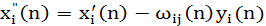 (1.40) (1.40)
Таким образом, принимая во внимание
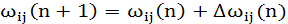 (1.41) (1.41)
и
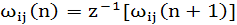 (1.42) (1.42)
где z-1 — оператор единичной задержки, можно построить граф передачи сигнала показанный на рис. 1.4, б, для обобщенного алгоритма Хебба. Из этого графа видно,
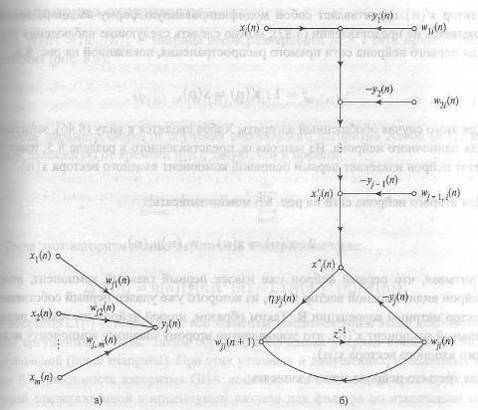
Рисунок 1.4 - Представление обобщенного алгоритма Хебба в виде графа передачи сигнала: граф уравнения (1.35) (а); граф выражений (1.36), (1.37) (б)
что сам алгоритм (согласно его формулировке в (1.41)) базируется на локальной форме реализации. Учтем также, что выход уi(n), отвечающий за обратную связь на графе передачи сигнала (см. рис. 1.4, б), определяется по формуле (1.35). Представление Для эвристического понимания того, как обобщенный алгоритм Хебба работает на самом деле, в первую очередь запишем версию алгоритма (1.37) в матричном представлении:
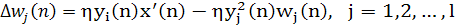 (1.43) (1.43)
где
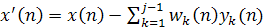 (1.44) (1.44)
Вектор х'(п) представляет собой модифицированную форму входного вектора. Основываясь на представлении (1.43), можно сделать следующие наблюдения. Для первого нейрона сети прямого распространения:
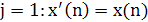
Для этого случая обобщенный алгоритм Хебба сводится к виду (1.33), записанному для одиночного нейрона. Из материала, представленного в разделе 1.5.4, известно, что этот нейрон извлекает первый основной компонент входного вектора х(п).
1. Для второго нейрона сети можно записать:
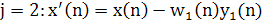
Учитывая, что первый нейрон уже извлек первый главный компонент, второй нейрон видит входной вектор x'(n), из которого уже удален первый собственный вектор матрицы корреляции R. Таким образом, второй нейрон извлекает первый главный компонент х'(n), что эквивалентно второму главному компоненту исходного входного вектора х(n).
2. Для третьего нейрона можно записать:
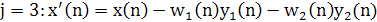
Предположим, что первые два нейрона уже сошлись к первому и второму главным компонентам. Значит, третий нейрон видит входной вектор x'(n), из которого удалены первый и второй собственные векторы. Таким образом, он извлекает первый главный компонент вектора х'(n), что эквивалентно третьему главному компоненту исходного входного вектора х(n).
3. Продолжая эту процедуру для оставшихся нейронов сети прямого распространения, получим, что каждый из выходов сети, обученный с помощью обобщенного алгоритма Хебба (1.37), представляет собой отклик на конкретный собственный вектор матрицы корреляции входного вектора, причем отдельные выходы упорядочены по убыванию ее собственных значений.
Этот метод вычисления собственных векторов аналогичен методу, получившему название процесса исчерпания. Он использует процедуру, аналогичную ортогонализации Грама-Шмидта.
Представленное здесь описание "от нейрона к следующему нейрону" было приведено для упрощения изложения. На практике все нейроны в обобщенном алгоритм Хебба совместно работают на обеспечение сходимости.
1.5.5 Исследование сходимости
при решении главной компоненты сигнала
Пусть W(n) ={wji(n)} — матрица весов размерности т х lсети прямого распространения:
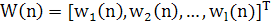 (1.45) (1.45)
Пусть параметр скорости обучения обобщенного алгоритма Хебба (1.45) имеет форму, зависящую от времени η(n), такую, что в пределе
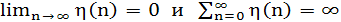 (1.46) (1.46)
Тогда этот алгоритм можно переписать в матричном виде:
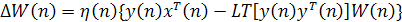 (1.47) (1.47)
где оператор LT[-] устанавливает все элементы, расположенные выше диагонали матрицы аргументов, в нуль. Таким образом, полученная матрица становится нижней треугольной (lowertriangular). При этих условиях и допущениях, изложенных в разделе 8.4, сходимость алгоритма GHAдоказывается с помощью процедуры, аналогичной представленной в предыдущем разделе для фильтра по извлечению максимального собственного значения. В связи с этим можно сформулировать следующую теорему.
Если элементы матрицы синоптических весов W
(n) на шаге п = 0 принимают случайные значения, то с вероятностью 1 обобщенный алгоритм Хебба (8.91) будет сходиться к фиксированной точке, aW
T(n) достигнет матрицы, столбцы которой являются первыми l собственными векторами матрицы корреляции R
размерности т х т входных векторов размерности mxl, упорядоченных по убыванию собственных значений.
Практическое значение этой теоремы состоит в том, что она гарантирует нахождение обобщенным алгоритмом Хебба первых lсобственных векторов матрицы корреляции R
, в предположении, что соответствующие собственные значения отличны друг от друга. При этом важен и тот факт, что в данном случае не требуется вычислять саму матрицу корреляции R
: ее первые lсобственных векторов вычисляются непосредственно на основании входных данных. Полученная экономия вычислительных ресурсов может быть особенно большой, если размерность входного пространства т достаточно велика, а требуемое количество собственных векторов, связанных с lнаибольшими собственными значениями матрицы корреляции R
, является лишь небольшой частью размерности т.
Данная теорема о сходимости сформулирована в терминах зависящего от времени параметра скорости обучения x(n). На практике этот параметр обычно принимает значение некоторой малой константы Т. В этом случае сходимость гарантируется в смысле среднеквадратической ошибки синаптических весов порядка т|.
В исследовались свойства сходимости алгоритма GHA (1.47). Проведенный в работе анализ показал, что увеличение параметра т) ведет к более быстрой сходимости и увеличению асимптотической среднеквадратической ошибки (что интуитивно предполагалось). Среди прочего в этой работе точно показана обратная зависимость между точностью вычислений и скоростью обучения.
1.5.6 Оптимальность обобщенного алгоритма Хебба
Предположим, что в пределе можно записать:
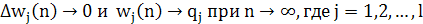 (1.48) (1.48)
и
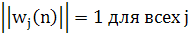 (1.49) (1.49)
Тогда предельные значения q1,q2,...,qi; векторов синаптических весов нейронов сети прямого распространения (см. рис. 8.5) представляют собой нормированные собственные векторы (normalizedeigenvector), ассоциированные с lдоминирующими собственными значениями матрицы корреляции R
, упорядоченными по убыванию собственных значений. Таким образом, для точки равновесия можно записать следующее:
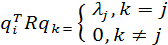 (1.50) (1.50)
где l1 > l2 > ... > li .
Для выхода нейрона jполучим предельное значение:
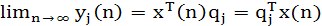 (1.51) (1.51)
Пусть Yj(n) — случайная переменная с реализацией yj(n). Взаимная корреляция (cross-correlation) между случайными переменными Yj(n) и Yk(n) в равновесном состоянии записывается в виде
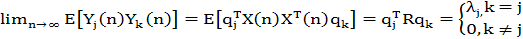 (1.52) (1.52)
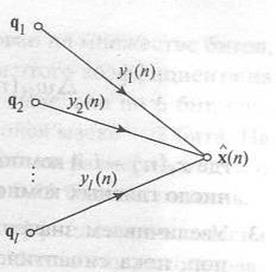
Рисунок 1.5 - Представление в виде графа передачи сигнала процесса восстановления вектора
Следовательно, можно утверждать, что в точке равновесия обобщенный алгоритм Хебба (1.47) выступает в роли средства собственных значений (eigen-analyzer) входных данных.
Пусть х^(n) — частное значение входного вектора х(n), для которого предельные условия (1.48) удовлетворяются при j = l — 1. Тогда из матричной формы (8.80) можно получить, что в пределе
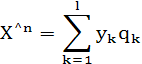
Это значит, что для заданных двух множеств величин — предельных значений q1,q2,…,ql векторов синаптических весов нейронов сети прямого распространения и соответствующих выходных сигналов y1 ,у2,…,yl — можно построить линейную оценку по методу наименьших квадратов (linearleast-squaresestimate) значения х^(n) входного вектора х(n), В результате формулу (1.52) можно рассматривать как одну из форм восстановления данных (datareconstruction) (рис. 1.4). Обратите внимание, что в свете дискуссии, этот метод восстановления данных имеет вектор ошибки аппроксимации, ортогональный оценке х^(n).
1.5.7 Алгоритм
GHA
в сжатом виде
Вычисления, выполняемые обобщённым алгоритмом Хебба (GHA), являются простыми, и их можно описать следующей последовательностью действий.
1. В момент времени n= 1 инициализируем синаптические веса ωjiсети случайными малыми значениями. Назначаем параметру скорости обучения Ш] некоторое малое положительное значение.
2. Для 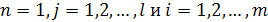 вычислим:. вычислим:.
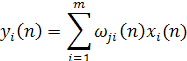
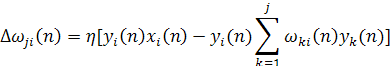
где xi(n) — i-й компонент входного вектора х(п) размерности т х 1; l- требуемое число главных компонентов.
3.Увеличиваем значение nна единицу, переходим к шагу 2 и продолжаем до пор, пока синаптические веса wjiне достигнут своих установившихся (steady-state) значений. Для больших п синаптические веса wji нейрона jсходятся к i-му компоненту собственного вектора, связанного с j-м собственным значением матрицы корреляции входного вектора х(n).
2. Оценка параметров регрессионных уравнений при аппроксимации дисперсионных распределений методом АГК
2.1 Организация наблюдений и регрессионные методы оценки параметров
2.1.1 Оценивание по конечному числу наблюдений
До сих пор предполагалось, что все математические ожидания могут быть вычислены, т. е. известна совместная плотность распределения р (х1,, . . ., хт, у). Так бывает довольно редко. Обычно необходимо оценивать параметры, используя конечное число наблюдений, а именно выборочные значения. Таким образом, оценка должна быть функцией этих выборочных значений, которые фактически представляют собой наблюдаемые значения реализаций случайных величин. Это означает, что оценка тоже случайная величина и может быть охарактеризована плотностью вероятности. Качество оценки зависит от этой функции и, в частности, от среднего значения и дисперсии.
Излагаемые методы имеют длинную историю. Уже в 1795 г. Гаусс использовал их при исследовании движения планет. В наши дни они применяются, например, при определении параметров орбит спутников. Следует отметить что, помимо обычных регрессионных моделей
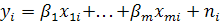
где ni — случайная величина, в литературе рассматриваются также авторегрессионная модель
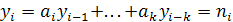
и обобщенная регрессионная модель

Обозначения. Теперь посмотрим, как получаются оценки. Пусть наблюдается выходной сигнал объекта у, который состоит из отклика на входное воздействие и, шума объекта и ошибок измерений. В момент j-го измерения выходной сигнал имеет вид
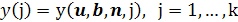 (2.1) (2.1)
Вектором b
обозначена зависимость выборочных значений от компонент вектора параметров объекта b
0,
b
1: . .
.,
b
т
. Определим
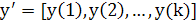 (2.2) (2.2)
Шум зададим его математическим ожиданием и ковариационной матрицей:
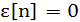 (2.3) (2.3)
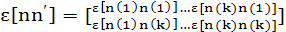 (2.4) (2.4)
Задача состоит в том, чтобы определить оценку β
вектора параметров Ь
. Для этого используется теоретически предсказываемый выходной сигнал w
, т. е. выход модели, который зависит от вектора коэффициентов β = (β0, βi,...,β m). Эта функциональная зависимость может быть выбрана различными способами. Простейшей является линейная функциональная связь между w и J (линейная по параметрам модель)
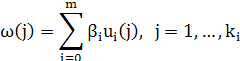
где ui(j)— известные линейно независимые функции. Запишем w в виде
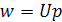 (2.5) (2.5)
где
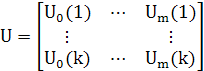 (2.6) (2.6)
Снова заметим, что такой выбор линейной связи между w и Р не означает того, что связь между входом и выходом модели должна быть линейной, Предполагается, что матрица U полностью известна, т. е. может быть измерена без ошибок. Кроме того, предполагается, что число наблюдений к
превышает число т + 1 неизвестных параметров.
Класс линейных несмещенных оценок определяется следующими свойствами:
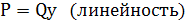 (2.7) (2.7)
где Q — (т + 1) xk-матрица, и
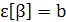 (2.8) (2.8)
Предполагается, что равенство (2.5) может дать полное описание объекта, т.е.
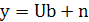 (2.9) (2.9)
Допустим сначала, что U и n статистически независимы. Теперь вектор ошибки е
можно определить как
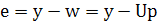 (2.10) (2.10)
В качестве функции ошибок или функции потерь можно выбрать положительно определенную форму
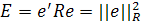 (2.11) (2.11)
где R- матрица весовых коэффициентов rij. Без потери общности можно предположить, что эта матрица симметрична. Функция ошибок может быть записана в виде
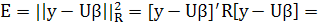
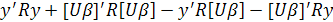 (2.12) (2.12)
Так как [Uβ]' —β'U', aR — симметричная матрица, то
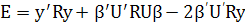 (2.13) (2.13)
Дифференцирование этого выражения по р дает (см. приложение В)
 (2.14) (2.14)
Последнее выражение можно записать в виде -2U'R[y-Uβ]= — 2U'Re.
При некотором р выражение (2.14) обращается в нуль. Отсюда находим р, обеспечивающее экстремум функции ошибок Е:
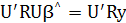 (2.15) (2.15)
Эту систему называют системой нормальных уравнений. Если U'RU — невырожденная матрица, то
 (2.16) (2.16)
Нетрудно показать, что при β = β^ функций ошибок Е принимает минимальное значение. Это значение Е (β^) называется остаточной ошибкой (основанной на k наблюдениях).
Здесь уместно сделать несколько замечаний:
1) Конечно, уравнение (2.16) можно решить методами
вариационного исчисления:
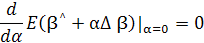
или
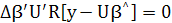
при произвольном ∆β (принцип ортогональности).
2) Прямое доказательство того, что Е достигает минимума, может быть основано на стандартном приеме анализа членов второго порядка по р. Из формулы (2.12) имеем

Очевидно, что при p, удовлетворяющем уравнению (2.16), Е достигает минимума.
3) В качестве мнемонического правила может оказаться удобным использовать то, что
умножается на U'R:
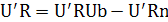
Так как второе слагаемое неизвестно, не измеряется и предполагается, что U и n статистически независимы, то это слагаемое отбрасывается. В результате получается оценка Р истинного значения b [см. формулу (2.15)]. Естественно, такой способ вывода уравнения (2.16) не показывает, в каком смысле оценка оптимальна.
Эта оценка обладает свойством линейности, поскольку
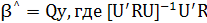 (2.17) (2.17)
Из формул (6.31) и (6.24) следует, что
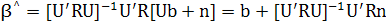
Поскольку входной сигнал и шум статистически независимы,
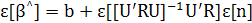 (2.18) (2.18)
А так как уже предполагалось, что ε[n] = 0, то оценка является и несмещенной:
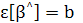 Отсюда следует, что Отсюда следует, что
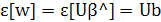
т. е. математическое ожидание выхода модели равно выходу объекта без аддитивного шума.
Желательно определить еще одну характеристику оценки β [формула (2.16)] — ее дисперсию. Интересно также оценить корреляцию между компонентами вектора 3. Все эти характеристики можно определить с помощью ковариационной матрицы
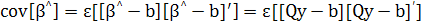 (2.19) (2.19)
По-прежнему предполагается, что справедливо соотношение (6.24) и U и n статистически независимы. Тогда, используя формулу (6.32), находим
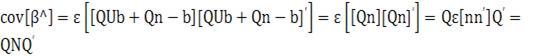
(2.20)
Следовательно,
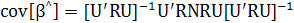
Будет показано, что в нескольких практически интересных случаях это выражение можно существенно упростить. Главная диагональ матрицы состоит из оценок дисперсий оцениваемых параметров.
2.1.2 Оценки по методу наименьших квадратов
При использовании метода наименьших квадратов минимизируется выражение
 (2.21) (2.21)
Таким образом, в уравнении (2.11) и вытекающих из него уравнениях
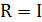 , ,
и из формул (2.15), (2.16) и (2.20) получаем
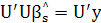 (2.22) (2.22)
или
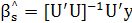 (2.23) (2.23)
и 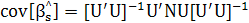 (2.24) (2.24)
Если U — квадратная матрица, т. е. если размер выборки равен числу оцениваемых параметров, и если матрица U имеет обратную, то
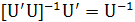 (2.25) (2.25)
и 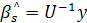 (2.26) (2.26)
С инженерной точки зрения этот случай не представляет особого интереса, поскольку случайные возмущения не учитываются. Для уменьшения влияния шумов размер выборки должен быть гораздо больше числа параметров. Если в уравнении (2.22) выразить все величины через Ui(j), то нетрудно получить
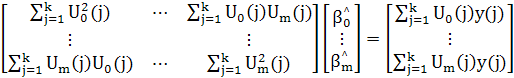 (2.27) (2.27)
Ортогональность или ортонормальность пробных сигналов может привести к существенным упрощениям. В случае ортонормальности
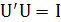 — единичная матрица — единичная матрица
и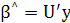 ,
или ,
или
Можно дать простую геометрическую интерпретацию оценок метода наименьших квадратов для случая двумерного вектора параметров β(рис. 2.1). Необходимо минимизировать длину вектора
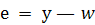 . .
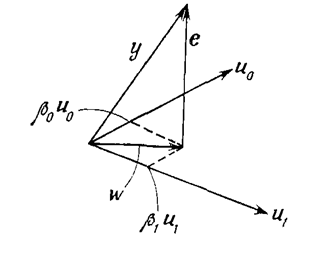
Рисунок 2.1 - Геометрическая интерпретация оценок метода наименьших квадратов для случая двумерного вектора параметров β
Если вектор е
ортогонален к u1 и u2
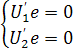 или или 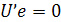
Следовательно,

или
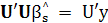 , ,
т. е. имеем уравнение (2.22).
2.2 Нейронные сети и статические характеристики
Поскольку в настоящее время нейронные сети с успехом используются для анализа данных, уместно сопоставить их со старыми хорошо разработанными статистическими методами. В литературе по статистике иногда можно встретить утверждение, что наиболее часто применяемые нейросетевые подходы являются ни чем иным, как неэффективными регрессионными и дискриминантными моделями. Мы уже отмечали прежде, что многослойные нейронные сети действительно могут решать задачи типа регрессии и классификации. Однако, во-первых, обработка данных нейронными сетями носит значительно более многообразный характер - вспомним, например, активную классификацию сетями Хопфилда или карты признаков Кохонена, не имеющие статистических аналогов. Во-вторых, многие исследования, касающиеся применения нейросетей в финансах и бизнесе, выявили их преимущества перед ранее разработанными статистическими методами. Рассмотрим подробнее результаты сравнения методов нейросетей и математической статистики.
2.3 Различие нейронных сетей и статистики
В чем же заключается сходство и различие языков нейрокомпьютинга и статистики в анализе данных. Рассмотрим простейший пример.
Предположим, что мы провели наблюдения и экспериментально измерили N пар точек, представляющих функциональную зависимость
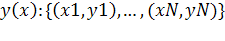
Если попытаться провести через эти точки наилучшую прямую, что на языке статистики будет означать использование для описания неизвестной зависимости линейной модели 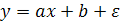 (где ε обозначает шум при проведении наблюдения), то решение соответствующей проблемы линейной регрессии сведется к нахождению оценочных значений параметров a,b минимизирующих сумму квадратичных невязок. (где ε обозначает шум при проведении наблюдения), то решение соответствующей проблемы линейной регрессии сведется к нахождению оценочных значений параметров a,b минимизирующих сумму квадратичных невязок.
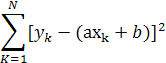
Если параметры aи bнайдены, то можно оценить значение y для любого значения x, то есть осуществить интерполяцию и экстраполяцию данных.
Та же самая задача может быть решена с использованием однослойной сети с единственным входным и единственным линейным выходным нейроном. Вес связи a и порог b могут быть получены путем минимизации той же величины невязки (которая в данном случае будет называться среднеквадратичной ошибкой) в ходе обучения сети, например методом backpropagation. Свойство нейронной сети к обобщению будет при этом использоваться для предсказания выходной величины по значению входа.
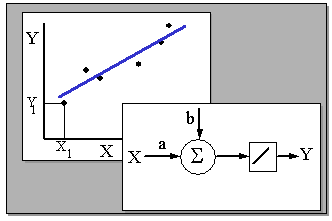
Рисунок. 2.2 - Линейная регрессия и реализующий ее однослойный персептрон
При сравнении этих двух подходов сразу бросается в глаза то, что при описании своих методов статистика апеллирует к формулам и уравнениям, а нейрокомпьютинг к графическому описанию нейронных архитектур.
Еще одним существенным различием является то, что для методов статистики не имеет значения, каким образом будет минимизироваться невязка - в любом случае модель остается той же самой, в то время как для нейрокомпьютинга главную роль играет именно метод обучения. Иными словами, в отличие от нейросетевого подхода, оценка параметров модели для статистических методов не зависит от метода минимизации. В то же время статистики будут рассматривать изменения вида невязки, скажем как фундаментальное изменение модели
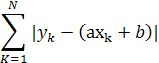
В отличие от нейросетевого подхода, в котором основное время забирает обучение сетей, при статистическом подходе это время тратится на тщательный анализ задачи. При этом опыт статистиков используется для выбора модели на основе анализа данных и информации, специфичной для данной области. Использование нейронных сетей - этих универсальных аппроксиматоров - обычно проводится без использования априорных знаний, хотя в ряде случаев оно весьма полезно. Например, для рассматриваемой линейной модели использование именно среднеквадратичной ошибки ведет к получению оптимальной оценки ее параметров, когда величина шума имеет нормальное распределение с одинаковой дисперсией для всех обучающих пар. В то же время если известно, что эти дисперсии различны, то использование взвешенной функции ошибки может дать значительно лучшие значения параметров.
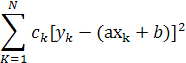
Факторный анализ используется для изучения структуры данных. Основной его посылкой является предположение о существовании таких признаков - факторов, которые невозможно наблюдать непосредственно, но можно оценить по нескольким наблюдаемым первичным признакам. Так, например, такие признаки, как объем производства и стоимость основных фондов, могут определять такой фактор, как масштаб производства. В отличие от нейронных сетей, требующих обучения, факторный анализ может работать лишь с определенным числом наблюдений. Хотя в принципе число таких наблюдений должно лишь на единицу превосходить число переменных рекомендуется использовать хотя бы втрое большее число значение. Это все равно считается меньшим, чем объем обучающей выборки для нейронной сети. Поэтому статистики указывают на преимущество факторного анализа, заключающееся в использовании меньшего числа данных и, следовательно, приводящего к более быстрой генерации модели. Кроме того, это означает, что реализация методов факторного анализа требует менее мощных вычислительных средств. Другим преимуществом факторного анализа считается то, что он является методом типа white-box, т.е. полностью открыт и понятен - пользователь может легко осознавать, почему модель дает тот или иной результат. Связь факторного анализа с моделью Хопфилда можно увидеть, вспомнив векторы минимального базиса для набора наблюдений. Именно эти векторы являются аналогами факторов, объединяющих различные компоненты векторов памяти - первичные признаки.
Логистическая регрессия является методом бинарной классификации, широко применяемом при принятии решений в финансовой сфере. Она позволяет оценивать вероятность реализации (или нереализации) некоторого события в зависимости от значений некоторых независимых переменных - предикторов: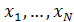 В модели логистической регресии такая вероятность имеет аналитическую форму: В модели логистической регресии такая вероятность имеет аналитическую форму:
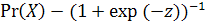 , где , где 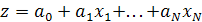
Нейросетевым аналогом ее очевидно является однослойный персептрон с нелинейным выходным нейроном. В финансовых приложениях логистическую регрессию по ряду причин предпочитают многопараметрической линейной регрессии и дискриминантному анализу. В частности, она автоматически обеспечивает принадлежность вероятности интервалу [0,1], накладывает меньше ограничений на распределение значений предикторов. Последнее очень существенно, поскольку распределение значений финансовых показателей, имеющих форму отношений, обычно не является нормальным и "сильно перекошено". Достоинством нейронных сетей является то, что такая ситуация не представляет для них проблемы. Кроме того, нейросети нечувствительны к корреляции значений предикторов, в то время как методы оценки параметров регрессионной модели в этом случае часто дают неточные значения. В то же время многие нейронные парадигмы, такие как сети Кохонена или машина Больцмана не имеют прямых аналогов среди статистических методов.
2.4
Нейронные сети и статистические экспертные системы
Рассмотрим теперь отношения нейрокомпьютинга и экспертных систем. Обе эти технологии
иногда относят к направлению Искусственный Интеллект, хотя строго говоря, термин искусственный интеллект появился в 70-е годы в связи с экспертными системами, как направления альтернативного нейронным сетям.
Его основатели - Марвин Минский и Эдвард Фейгенбаум посчитали излишней апелляцию к архитектуре мозга, его нейронным структурам, и декларировали необходимость моделирования работы человека со знаниями. Тем самым, поставив в центр внимания операции с формально-логическими языковыми структурами, они заведомо выбрали ориентацию на имитацию обработки информации
левым полушарием мозга человека. Системы обработки таких формализованных знаний были названы экспертными, поскольку они должны были воспроизводить ход логических рассуждений эксперта (высокопрофессионального специалиста) в конкретной предметной области. Эти рассуждения проводятся с использованием правил вывода, которые инженер знаний должен извлечь у эксперта.
Заметим, что в настоящее время распространено более широкое толкование систем искусственного интеллекта. К ним относят не только экспертные , но и нечеткие системы, нейронные сети и всевозможные комбинации, такие как нечеткие экспертные системы или нечеткие нейронные системы. Отдельным направлениями, выделяются также эвристический поиск, в рамках которого в 80-е годы Ньюэллом и Саймоном был разработан Общий Решатель Задач (GPS - General Problem Solver), а также обучающиеся машины (Ленат, Холланд). И если GPS не мог решать практические задачи, то машинная обучающаяся система EURISCO внесла значительный вклад в создание СБИС, изобретя трехмерный узел типа И/ИЛИ.
Однако, экспертные системы претендовали именно на решение важных прикладных задач прежде всего в таких областях, как медицина и геология. При этом соответствующая технология в сочетании с нечеткими системами была в 1978 году положена японцами в основу программы создания компьютеров 5-го поколения.
Парадокс искусственного интеллекта заключается в том, что как только некоторая, кажущаяся интеллектуальной, деятельность оказывается искусственно реализованной, она перестает считаться интеллектуальной. В этом смысле наибольшие шансы остаться интелелктуальными имеют как раз нейронные сети, из которых еще не извлечены артикулированные знания.
Сопоставление экспертных систем и нейрокомпьютинга выявляет различия, многие из которых характерны для уже отмечавшихся в первой лекции различий обычных компьютеров (а экспертные системы реализуются именно на традиционных машинах, главным образом на языке ЛИСП и Пролог) и нейрокомпьютеров
Таблица 1. Сравнение методов нейронных сетей и экспертных систем
| Нейронные сети |
Экспертные системы |
| Аналогия |
правое полушарие |
левое полушарие |
| Объект |
данные |
знания |
| Вывод |
отображение сетью |
правила вывода |
Важным преимуществом нейронных сетей является то, что разработка экспертных систем, основанных на правилах требует 12-18 месяцев, а нейросетевых - от нескольких недель до месяцев.
Рассматривая извлечение знаний из обученных нейронных сетей мы уже показали, что представление о них, как о черных ящиках, не способных объяснить полученное решение (это представление иногда рассматривается как аргумент в пользу преимущества экспертных систем перед нейросетями), неверно. В то же время, очевидно, что, как и в случае мозга, в котором левое и правое полушарие действуют сообща, естественно и объединение экспертных систем с искусственными нейронными сетями. Подобные синтетические системы могут быть названы нейронными экспертными системами - этот термин использовал Иржи Шима, указавший на необходимость интеграции достоинств обоих типов систем. Такая интеграция может осуществляться двояким образом. Если известна только часть правил, то можно либо инициализировать веса нейронной сети исходя из явных правил, либо инкорпорировать правила в уже обученные нейронные сети. Шима предложил использовать и чисто коннекционистский методику построения нейронных эксперных систем, которая обладает таким достоинством, как возможность работы с неполными данными (ситуация типичная для реальных баз данных). Такой возможностью обладают введенные им сети интервальных нейронов.
2.5 Сети интервальных нейронов
Ситуация, в которой некоторые данные не известны или не точны, встречается достаточно часто. Например, при оценке возможностей той или иной фирмы, можно учитывать ее официально декларируемый капитал, скажем в 100 миллионов, но лучше всего считать, что в действительности его величина является несколько большей и меняется в интервале от 100 до 300 млн. Удобно ввести в данном случае специальные нейроны, состояния которых кодируют не бинарные или непрерывные значения, а интервалы значений. В случае, если нижняя и верхняя граница интервала совпадают, то состояния таких нейронов становятся аналогичными состояниям обычных нейронов.
Для интервального нейрона iна каждый его вход jподается не одно 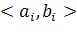 , а пара значений, определяющая границы интервала, в котором лежит величина воздействия j-го нейрона. Воздействие, оказываемое на i-й нейрон со стороны всех связанных с ним нейронов само лежит в интервале , а пара значений, определяющая границы интервала, в котором лежит величина воздействия j-го нейрона. Воздействие, оказываемое на i-й нейрон со стороны всех связанных с ним нейронов само лежит в интервале  , где , где
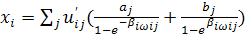 , ,
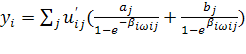 , ,
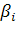 - обратная температура. - обратная температура.
Интервальное значение, которое принимает i-й нейрон при данном воздействии, равно
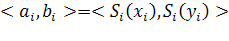 , ,
где
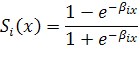
Передаточная функция интервального нейрона приблизительно отражает идею монотонности по отношению к операции интервального включения. Это означает, что при 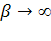 , если вход j-го нейрона лежит в интервале , если вход j-го нейрона лежит в интервале 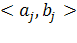 , то выход i- го нейрона, определенный по классической функции Ферми, обязательно попадет в интервал , то выход i- го нейрона, определенный по классической функции Ферми, обязательно попадет в интервал 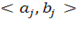 . Интервальные нейроны могут являться элементами многослойных персептронов. В этом случае их состояния вычисляются последовательно, начиная от входного слоя к выходному. Для сетей интервальных нейронов может быть построено обобщение метода обратного распространения ошибки, описание которого выходит за рамки нашего курса. . Интервальные нейроны могут являться элементами многослойных персептронов. В этом случае их состояния вычисляются последовательно, начиная от входного слоя к выходному. Для сетей интервальных нейронов может быть построено обобщение метода обратного распространения ошибки, описание которого выходит за рамки нашего курса.
2.6 Сети и свойства численных структур регрессионного анализа
Простой итерационный алгоритм сингулярного разложения матриц допускает простую высокопараллельную (в том числе, нейросетевую) реализацию. Сингулярное разложение матриц (англ. Singular value decomposition) необходимо для решения многих задач анализа данных. В том числе, анализ главных компонент сводится к сингулярному разложению матрицы центрированных данных.
2.6.1 Идея сингулярного разложения матрицы данных
Если 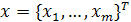 — матрица, составленная из векторов-строк центрированных данных, то выборочная ковариационная матрица — матрица, составленная из векторов-строк центрированных данных, то выборочная ковариационная матрица
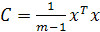 и задача о спектральном разложении ковариационной матрицы и задача о спектральном разложении ковариационной матрицы  превращается в задачу о сингулярном разложении матрицы данных X. превращается в задачу о сингулярном разложении матрицы данных X.
Число σ³0 называется сингулярным числом матрицы 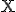 тогда и только тогда, когда существуют правый и левый сингулярные векторы: такие тогда и только тогда, когда существуют правый и левый сингулярные векторы: такие 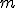 -мерный вектор-строка -мерный вектор-строка 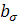 и и 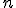 -мерный вектор-столбец -мерный вектор-столбец 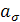 (оба единичной длины), что выполнено два равенства: (оба единичной длины), что выполнено два равенства:
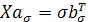 ; ; 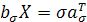
Пусть 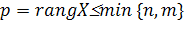 — ранг матрицы данных. Сингулярное разложение матрицы данных X— это её представление в виде — ранг матрицы данных. Сингулярное разложение матрицы данных X— это её представление в виде
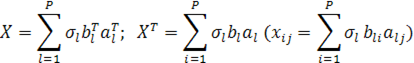
где 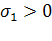 — сингулярное число, — сингулярное число, 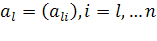 — соответствующий правый сингулярный вектор-столбец, а — соответствующий правый сингулярный вектор-столбец, а 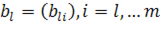 — соответствующий левый сингулярный вектор-строка ( — соответствующий левый сингулярный вектор-строка ( ). Правые сингулярные векторы-столбцы ). Правые сингулярные векторы-столбцы 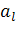 , участвующие в этом разложении, являются векторами главных компонент и собственными векторами эмпирической ковариационной матрицы , участвующие в этом разложении, являются векторами главных компонент и собственными векторами эмпирической ковариационной матрицы 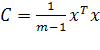 , отвечающими положительным собственным числам , отвечающими положительным собственным числам 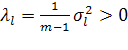 . .
Хотя формально задачи сингулярного разложения матрицы данных и спектрального разложения ковариационной матрицы совпадают, алгоритмы вычисления сингулярного разложения напрямую, без вычисления спектра ковариационной матрицы, более эффективны и устойчивы. Это следует из того, что задача сингулярного разложения матрицы лучше обусловлена, чем задача разложения матрицы : для ненулевых собственных и сингулярных чисел

Простой итерационный алгоритм сингулярного разложения
Основная процедура — поиск наилучшего приближения произвольной mxnматрицы 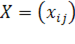 матрицей вида матрицей вида 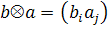 (где b— m-мерный вектор, а a— n-мерный вектор) методом наименьших квадратов: (где b— m-мерный вектор, а a— n-мерный вектор) методом наименьших квадратов:
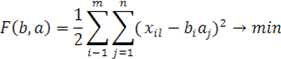
Решение этой задачи дается последовательными итерациями по явным формулам. При фиксированном векторе 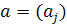 значения значения 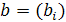 , доставляющие минимум форме F(b,a), однозначно и явно определяются из равенств , доставляющие минимум форме F(b,a), однозначно и явно определяются из равенств
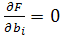
Аналогично, при фиксированном векторе определяются значения:
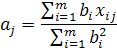
B качестве начального приближения вектора  возьмем случайный вектор единичной длины, вычисляем вектор b, далее для этого вектора возьмем случайный вектор единичной длины, вычисляем вектор b, далее для этого вектора 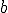 вычисляем вектор и т. д. Каждый шаг уменьшает значение F(b,a). В качестве критерия остановки используется малость относительного уменьшения значения минимизируемого функционала F(b,a)за шаг итерации (∆F/F) или малость самого значения F. вычисляем вектор и т. д. Каждый шаг уменьшает значение F(b,a). В качестве критерия остановки используется малость относительного уменьшения значения минимизируемого функционала F(b,a)за шаг итерации (∆F/F) или малость самого значения F.
В результате для матрицы X=(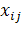 )получили наилучшее приближение матрицей )получили наилучшее приближение матрицей 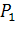 вида вида 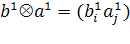 (здесь верхним индексом обозначен номер итерации). Далее, из матрицы (здесь верхним индексом обозначен номер итерации). Далее, из матрицы  вычитаем полученную матрицу , и для полученной матрицы уклонений вычитаем полученную матрицу , и для полученной матрицы уклонений  вновь ищем наилучшее приближение вновь ищем наилучшее приближение 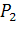 этого же вида и т. д., пока, например, норма этого же вида и т. д., пока, например, норма 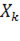 не станет достаточно малой. В результате получили итерационную процедуру разложения матрицы X в виде суммы матриц ранга 1, то есть не станет достаточно малой. В результате получили итерационную процедуру разложения матрицы X в виде суммы матриц ранга 1, то есть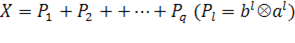 . Полагаем . Полагаем  и нормируем векторы и нормируем векторы 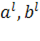 : : 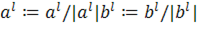 В результате получена аппроксимация сингулярных чисел В результате получена аппроксимация сингулярных чисел 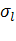 и сингулярных векторов (правых — и сингулярных векторов (правых — 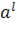 и левых — и левых — 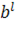 ). ).
К достоинствам этого алгоритма относится его исключительная простота и возможность почти без изменений перенести его на данные с пробелами, а также взвешенные данные.
Существуют различные модификации базового алгоритма, улучшающие точность и устойчивость. Например, векторы главных компонент 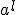 при разных lдолжны быть ортогональны «по построению», однако при большом числе итерации (большая размерность, много компонент) малые отклонения от ортогональности накапливаются и может потребоваться специальная коррекция на каждом шаге, обеспечивающая его ортогональность ранее найденным главным компонентам. при разных lдолжны быть ортогональны «по построению», однако при большом числе итерации (большая размерность, много компонент) малые отклонения от ортогональности накапливаются и может потребоваться специальная коррекция на каждом шаге, обеспечивающая его ортогональность ранее найденным главным компонентам.
Для квадратных симметричных положительно определённых матриц описанный алгоритм превращается в метод прямых итераций для поиска собственных векторов.
2.6.2 Линейный МНК
Задача аппроксимации линейным МНК в матричной форме записывается, как
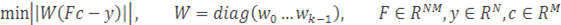
Иногда к задаче добавляются ограничения:
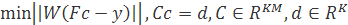
Здесь c обозначает искомый вектор коэффициентов. Столбцы матрицы F соответствуют базисным функциям (всего M столбцов), строки - экспериментальным точкам (всего N строк), Fij содержит значение j-ой базисной функции в i-ой точке набора данных. Вектор y содержит значения аппроксимируемой функции в точках, соответствующих строкам матрицы F. Матрица W является диагональной матрицей весовых коэффициентов, элементы которой соответствуют важности той или иной точки. Матрица C задает дополнительные ограничения, которым должна удовлетворять аппроксимируемая функция - минимум ошибки ищется среди функций, точно удовлетворяющих заданным ограничениям. В такой формулировке задача сводится к решению системы линейных уравнений. Полученная система линейных уравнений, как правило, является переопределенной - число уравнений намного больше числа неизвестных. Для решения используется основанный на QR-разложении солвер. Сначала матрица A представляется в виде произведения прямоугольной ортогональной матрицы Q и квадратной верхнетреугольной матрицы R. Затем решается система уравнений Rx = Q Tb. Если матрица R вырождена, алгоритм использует SVD-разложение, которое позволяет добиться решения независимо от свойств матрицы коэффициентов. Трудоемкость решения такой задачи составляет O(N·M 2).
Модуль lsfit содержит четыре подпрограммы для линейной аппроксимации: LSFitLinear (простейшая задача - нет ограничений, W - единичная матрица), LSFitLinearW (взвешенная аппроксимация без ограничений), LSFitLinearC (аппроксимация с ограничениями, без весовых коэффициентов) и LSFitLinearWC (аппроксимация с индивидуальными весовыми коэффициентами и ограничениями).
2.7 Нелинейные решения проблем стандартного
МНК
2.7.1 Аппроксимация линейным или нелинейным МНК
Метод наименьших квадратов (часто называемый МНК) обычно упоминается в двух контекстах. Во-первых, широко известно его применение в регрессионном анализе, как метода построения моделей на основе зашумленных экспериментальных данных. При этом помимо собственно построения модели обычно осуществляется оценка погрешности, с которой были вычислены её параметры, иногда решаются и некоторые другие задачи. Во-вторых, МНК часто применяется просто как метод аппроксимации, без какой-либо привязки к статистике. На этой странице МНК рассматривается как метод аппроксимации. Также следует отметить, что модуль lsfit
, рассматриваемый на этой странице, решает задачи общего вида. Модули для работы с полиномами, сплайнами, рациональными функциями содержат подпрограммы схожей функциональности, позволяющие осуществлять аппроксимацию этими функциями.
2.7.2 Нелинейный МНК: с использованием гессиана или без него
Нелинейная задача МНК значительно сложнее линейной: аппроксимант уже не представляется в виде линейной комбинации базисных функций. Для аппроксимации используется функция общего вида, зависящая от M аргументов и K параметров:
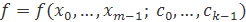
Нам известны значения аргументов x в N точках, требуется найти значения параметров c, при которых отличие f от заданных значений y будет минимально. Задача при этом имеет следующую формулировку:
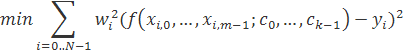
Для решения используется метод Левенберга-Марквардта, реализованный в модуле minlm. Алгоритм использует ту же схему обратной коммуникации для вычисления значения функции, что и модуль minlm - вам необходимо ознакомиться с ней перед использованием алгоритма. Как и в модуле minlm, пользователь может выбирать несколько схем оптимизации: FG (использование функции f и её градиента) и FGH (использование функции, градиента и гессиана). Пользователь может задать индивидуальные весовые коэффициенты (на что указывает суффикс W) или решать задачу без них. Итого имеем четыре версии подпрограмм для оптимизации: LSFitNonlinearWFG, LSFitNonlinearFG, LSFitNonlinearWFGH, LSFitNonlinearFGH.
В случае оптимизации с использованием схемы FG (градиент известен, гессиан неизвестен) возможны две ситуации: "дорогой" градиент, трудоемкость вычисления которого равна O((M+K) 2), и "дешевый" градиент, трудоемкость вычисления которого существенно ниже, чем O((M+K) 2). Первый вариант - это градиент, вычисленный при помощи разностной схемы, либо аналитический градиент сложной функции. Второй вариант - аналитический градиент функции с регулярной структурой, допускающей ускоренное вычисление градиента (пример: обучение нейронных сетей). Во втором случае можно использовать гибридный вариант алгоритма Левенберга-Марквардта, входящий в состав ALGLIB - этот вариант позволяет значительно ускорить решение задач с "дешевыми" градиентами. "Стоимость" градиента обозначается параметром CheapFG подпрограмм LSFitNonlinearWFG и LSFitNonlinearFG.
Замечание 1
Если для оптимизации используется гессиан, то всегда используется гибридный алгоритм - в таких задачах его применение всегда оправдано.
Замечание 2
Предпочтительным вариантом является использование аналитического градиента. Из-за возможных проблем с низкой точностью не рекомендуется использовать для вычисления градиента разностную схему. Если вы все же используете её, ни в коем случае не используйте двухточечную схему - используйте как минимум четырехточечную схему.
2.7.3 Нелинейный МНК
как
обратная коммуникация
Алгоритм аппроксимации в ходе своей работы должен получать значения функции/градиента/... в выбранных им точках. В большинстве программных пакетов эта проблема решается путем передачи указателя на функцию (C++, Delphi) или делегата (C#), который осуществляет эту операцию.
Пакет ALGLIB, в отличие от других библиотек, использует для решения этой задачи обратную коммуникацию. Когда требуется вычислить значение функции (или её производных), состояние алгоритма сохраняется в специальной структуре, после чего управление возвращается в вызвавшую программу, которая осуществляет все вычисления и снова вызывает вычислительную подпрограмму.
Таким образом, работа с алгоритмом аппроксимации осуществляется в следующей последовательности:
1. Подготовка структуры данных LSFitState при помощи одной из подпрограмм инициализации алгоритма (LSFitNonlinearWFG, LSFitNonlinearFG, LSFitNonlinearWFGH, LSFitNonlinearFGH).
2. Вызов подпрограммы LSFitNonlinearIteration.
3. Если подпрограмма вернула False, работа алгоритма завершена и минимум найден (сам минимум может быть получен при помощи подпрограммы LSFitNonlinearResults).
4. Если подпрограмма вернула True, подпрограмма требует информацию о функции. В зависимости от того, какие поля структуры LSFitState установлены в True (ниже этот вопрос рассмотрен более подробно), вычислите функцию/градиент/гессиан.
5. После того, как вся требуемая информация загружена в структуру LSFitState, требуется повторно вызвать подпрограмму LSFitNonlinearIteration.
Для обмена информацией с пользователем используются следующие поля структуры LSFitState:
· LSFitState.X[0..M-1] – массив, хранящий координаты точки, информация о которой запрашивается алгоритмом
· LSFitState.C[0..K-1] – массив, хранящий значение параметров функции
· LSFitState.F – в это поле следует поместить значение функции F (если оно было запрошено)
· LSFitState.G[0..K-1] – в это поле следует поместить градиент df(x,c)/dci (если он был запрошен)
· LSFitState.H[0..K-1,0..K-1] – в это поле следует поместить гессиан d 2f(x,c)/dcij ^2 (если он был запрошен)
В зависимости от того, что именно требуется вычислить, подпрограмма LSFitNonlinearIteration может устанавливать в True одно и только одно из следующих полей:
· NeedF – сигнализирует о том, что требуется вычислить значение функции F
· NeedFG – сигнализирует о том, что требуется вычислить значения функции F и градиента F
· NeedFGH – сигнализирует о том, что требуется вычислить значение функции F, градиент F и гессиан F
2.8 Решение параметров регрессионного уравнения с использованием аппроксимации ковариационной матрицы по данным ГК при обучении НС
Актуальность работы определяется проблемой регрессионных методов, когда оценка параметров затруднена дефицитом априорной информации о помехах или обратная автоковариационная матрица входных регрессоров является вырожденной. Целевое направление работы – создание алгоритма оценки параметров регрессионной модели измерений при аппроксимации дисперсионных характеристика методом главных компонентов. Основная решаемая задача заключается в нахождении соотношения характеристик главных компонентов и регрессионных уравнений. Эффективность достигается за счет решения главных компонентов средствами нейронных сетей на основе фильтра Хебба.
пространственный стохастический адаптивный алгоритм регрессионный

Рисунок 2.3 - Алгебраические компоненты модели ГК и регрессионного анализа
Конкретно в текущей работе было выполнены следующие этапы построения представляемого метода (рис. 2.3):
– рассмотрение алгебраической модели данных метода главных компонентов для выявления структурных соотношений с регрессионным анализом;
– анализ структуры и метода обучения нейронных сетей для решения аппроксимации ковариации входного сигнала методом главных компонент;
– поиск оптимального параметра отклика регрессионными методами и по данным анализа главных компонентов;
– решение поверхности отклика по данным АГК, в условиях, когда обратная матрица автоковариации входных регрессоров вырождена.

Рисунок 2.4 - Отношения ГК и входного пространства
В основе метода главных компонентов находится задача наилучшей аппроксимации конечного множества точек линейными многообразиями типа прямых и плоскостей (рис. 2.4). Эти линейные многообразия определяются ортонормированным набором векторов, линейных по параметрам. По входным координатам, относительно каждого базиса многообразия, рассчитывается минимальная квадратичная сумма до их проекции. Таким образом, формируется главная компонента, связанная с максимальной дисперсией проекции входа относительно элемента базиса. Совокупность проекций отдельного направления и их главная компонента в свою очередь образуют собственные подпространства, ортогональные по отношению друг к другу.
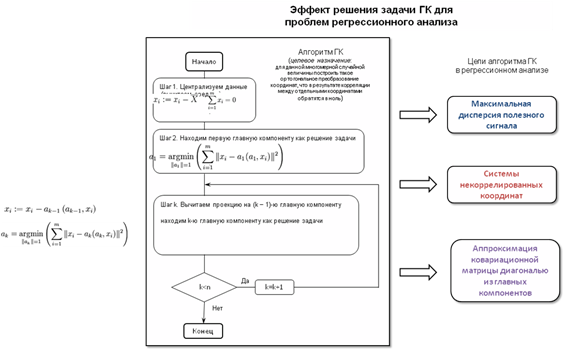
Рисунок 2.5 - Эффект решения задачи ГК для проблем регрессионного анализа
Таким образом, формируется распределение максимальных дисперсий аппроксимируемых точек в пространстве компонент (рис. 2.5). Проекция искажений, или помех, ортогональна и не коррелированны с данными. То есть дисперсия помех минимальна, что соответствует задачам регрессионного анализа. Но расчет всех главных компонентов – аналитически сложная задача оптимизации. Эффект ее решения это нахождение:
- максимальной дисперсии полезного сигнала;
- системы некоррелированных координат;
- аппроксимация ковариационной матрицы диагональю из дисперсий проекций по данным ГК.
При этом ортонормированный базис для собственных векторов существует всегда. Даже если спектр ковариационной матрицы вырожден, то есть когда она является сингулярной и не решает оценки параметров регрессионной модели.

Рисунок 2.6 - Алгоритм анализа главных компонентов обучением НС на основе фильтра Хебба
С целью анализа главных компонентов для входного сигнала произвольной размерности возможно применение технологии обучения нейронных сетей (рис. 2.6). Сеть прямого распространения с одним слоем линейных нейронов, модифицируемая по обобщенному правиле Хебба, образует устройство - фильтр Хебба. Фильтр извлекает главные компоненты из входного сигнала в пространстве собственных векторов, которыми являются веса нейронов. Число компонент соответствует числу ортосистем, то есть числу весовых систем и соответственно равно числу нейронов сети. Таким образом, всегда будет достижима задача аппроксимации ковариационной матрицы входного случайного сигнала заданной размерности.
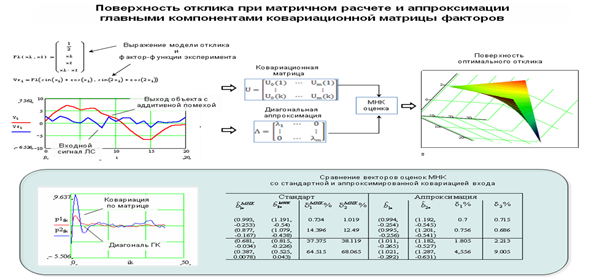
Рисунок 2.7 - Поверхность отклика при матричном расчете и аппроксимации главными компонентами ковариационной матрицы факторов
В качестве практического эксперимента была выбрана аппроксимация квадратичным полиномом выхода линейной системы с нормально распределенной аддитивной помехой (рис. 2.7). Дисперсия помехи менялась в пределах 3-10% от дисперсии сигнала. Решение определялось в фактор-пространстве поверхности оптимального отклика. Входными данными являлись факторы регрессионного выражения отклика. Оптимальное значение отклика рассчитывалось при оценке параметров МНК. В расчетах использовалась стандартная матрица ковариации и ее аппроксимация диагональным оператором главных компонент. Компоненты получены по результатам настройки весов нейронной сети алгоритмом Хебба с использованием пакета Matlab. Отклонение параметров модели отклика на данных диагональной матрицы главных компонент от стандартных расчетов составило в среднем 2.2%.
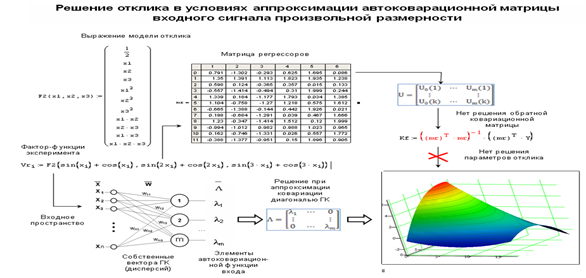
Рисунок 2.8 - Решение отклика в условиях аппроксимации автоковарационной матрицы входного сигнала произвольной размерности
Далее был сделан переход к квадратичному полиному размерностью в три входных фактора. В этих условиях были смоделированы значения факторов, когда обратная ковариационная матрица входа становится вырожденной и решение регрессии по МНК не выполнимо (рис. 2.8). После чего матрица аппроксимировалась алгоритмом Хебба на модели НС. Графическая демонстрация отклика производится при стабилизированном третьем факторе, что позволяет наблюдать поверхность отклика по данным главных компонентов.
Итак, в результате исследования и апробации решения главных компонентов на модели НС, практически получен метод содействия регрессионному анализу измерений. Метод позволяет оценивать параметры на отношении дисперсий ковариации и аппроксимированной главными компонентами автоковариации входного сигнала произвольной размерности. Подобное применение современных технологий на алгоритмах обучения нейронных сетей выполняет достижение цели, определенной в дипломной работе.
Заключение
Произведенная теоретическая и практическая часть (в виде алгоритмического программирования) работы достигает цели, поставленной при дипломном проектировании. В качестве объекта проектирования выступали регрессионные среды измерений, где параметрическая идентификация на принципах минимизации дисперсионных распределений матричного функционала ошибки затруднена стандартными регрессионными методами.
Новизной результата стали применение формулы самообучающейся нейронной сети к регрессионным средам; альтернатива методам поиска стационарных значений (минимальных) функционала (скаляра) ошибки в векторном пространстве данных как метод поиска экстремальных дисперсий в векторном пространстве признаков (при той же ограниченной Евклидовой норме вектора помех).
В дипломной работе была разработана схему адаптации метода анализа главных компонентов, решаемого на основе нейронных сетей, к регрессионному анализу стохастических сред, где корреляционные методы оценок затруднены из-за плохой обусловленности ортогональной матрицы автоковариаций. В результате выполнения дипломной работы были получены алгоритмы на основе метода анализа главных компонентов для получения дисперсионных распределений стохастических сред моделируемых сигналов и систем, позволяющие с помощью принципов спектрального анализа содействовать оценке параметров регрессионных моделей.
Библиографический список использованной литературы
1. Саймон Хайкин. Нейронные сети. Москва, Вильямс, 2006.
2. Эйкхофф П. Основы идентификации систем управления. Москва, Мир. 1975.
3. Бокс Дж., Дженкинс Г. Анализ временных рядов, прогноз и управление. - М.: Мир, 1974. - 193 с.
4. Кацюба О.А., Гущин А.В. О состоятельности оценок параметров многомерной линейной регрессии на основе нелинейного метода наименьших квадратов // Труды IV Международной конференции «Идентификация систем и задачи управления» SICPRO’05 . Статья – Москва, 25-28 января 2005 г. Институт проблем управления им. В.А. Трапезникова РАН, 2005, с. 279-284.
5. Кацюба О.А., Гущин А.В. Оценивание параметров многомерной линейной авторегрессии // XI международная конференция «Математика, компьютер, образование». Дубна, 26-31 января 2004 г. МГУ, Пущинский центр биологических исследований РАН, институт прикладной математики им.М.В. Келдыша РАН: Тез. докл. – Москва-Ижевск, 2004. Выпуск № 11, с.-107.
6. Кацюба О.А., Гущин А.В. Численные методы определения оценок параметров многомерного линейного разностного уравнения // XVIII Международная научная конференция «Математические методы в технике и технологиях». Статья – Казань, 31 мая - 2 июня 2005г. Казанский государственный технологический университет, 2005, с.156-159.
|
