| Методы математической статистики
1. Введение
Математической статистикой называется наука, занимающаяся разработкой методов получения, описания и обработки опытных данных с целью изучения закономерностей случайных массовых явлений.
В математической статистике можно выделить два направления: описательную статистику и индуктивную статистику (статистический вывод). Описательная статистика занимается накоплением, систематизацией и представлением опытных данных в удобной форме. Индуктивная статистика на основе этих данных позволяет сделать определенные выводы относительно объектов, о которых собраны данные, или оценки их параметров.
Типичными направлениями математической статистики являются:
1) теория выборок;
2) теория оценок;
3) проверка статистических гипотез;
4) регрессионный анализ;
5) дисперсионный анализ.
В основе математической статистики лежит ряд исходных понятий без которых невозможно изучение современных методов обработки опытных данных. В ряд первых из них можно поставить понятие генеральной совокупности и выборки.
При массовом промышленном производстве часто нужно без проверки каждого выпускаемого изделия установить, соответствует ли качество продукции стандартам. Так как количество выпускаемой продукции очень велико или проверка продукции связана с приведением ее в негодность, то проверяется небольшое количество изделий. На основе этой проверки нужно дать заключение о всей серии изделий. Конечно нельзя утверждать, что все транзисторы из партии в 1 млн. штук годны или негодны, проверив один из них. С другой стороны, поскольку процесс отбора образцов для испытаний и сами испытания могут оказаться длительными по времени и привести к большим затратам, то объем проверки изделий должен быть таким, чтобы он смог дать достоверное представление о всей партии изделий, будучи минимальных размеров. С этой целью введем ряд понятий.
Вся совокупность изучаемых объектов или экспериментальных данных называется генеральной совокупностью. Будем обозначать через N число объектов или количество данных, составляющих генеральную совокупность. Величину N называют объемом генеральной совокупности. Если N>>1, то есть N очень велико, то обычно считают N = ¥.
Реклама

Случайной выборкой или просто выборкой называют часть генеральной совокупности, наугад отобранную из нее. Слово "наугад" означает, что вероятности выбора любого объекта из генеральной совокупности одинакова. Это важное предположение, однако, часто трудно это проверить на практике.
Объемом выборки называют число объектов или количество данных, составляющих выборку, и обозначают n
. В дальнейшем будем считать, что элементам выборки можно приписать соответственно числовые значения х1
, х2
, ... хn
. Например, в процессе контроля качества производимых биполярных транзисторов это могут быть измерения их коэффициента усиления по постоянному току.
2. Числовые характеристики выборки
2.1 Выборочное среднее
Для конкретной выборки объема n ее выборочное среднее 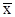 определяется соотношением определяется соотношением
где хi
– значение элементов выборки. Обычно требуется описать статистические свойства произвольных случайных выборок, а не одной из них. Это значит, что рассматривается математическая модель, которая предполагает достаточно большое количество выборок объема n. В этом случае элементы выборки рассматриваются как случайные величины Хi
, принимающие значения хi
с плотностью вероятностей f(x), являющейся плотностью вероятностей генеральной совокупности. Тогда выборочное среднее также является случайной величиной 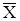 равной равной
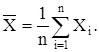
Как и ранее будем обозначать случайные величины прописными буквами, а значения случайных величин – строчными.
Среднее значение генеральной совокупности, из которой производится выборка, будем называть генеральным средним и обозначать mx
. Можно ожидать, что если объем выборки значителен, то выборочное среднее не будет заметно отличаться от генерального среднего. Поскольку выборочное среднее является случайной величиной, для нее можно найти математическое ожидание:
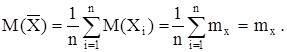
Таким образом, математическое ожидание выборочного среднего равно генеральному среднему. В этом случае говорят, что выборочное среднее является несмещенной оценкой генерального среднего. В дальнейшем мы вернемся к этому термину. Так как выборочное среднее является случайной величиной, флуктуирующей вокруг генерального среднего, то желательно оценить эту флуктуацию с помощью дисперсии выборочного среднего. Рассмотрим выборку, объем которой n значительно меньше объема генеральной совокупности N (n << N). Предположим, что при формировании выборки характеристики генеральной совокупности не меняются, что эквивалентно предположению N = ¥. Тогда
Реклама

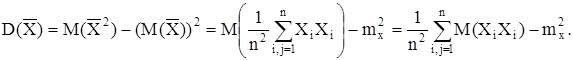
Случайные величины Хi
и Xj
(i¹j) можно считать независимыми, следовательно,
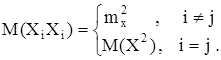
Подставим полученный результат в формулу для дисперсии:
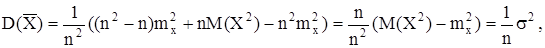
где s2
– дисперсия генеральной совокупности.
Из этой формулы следует, что с увеличением объема выборки флуктуации среднего выборочного около среднего генерального уменьшаются как s2
/n. Проиллюстрируем сказанное примером. Пусть имеется случайный сигнал с математическим ожиданием и дисперсией соответственно равными mx
= 10, s2
= 9.
Отсчеты сигнала берутся в равноотстоящие моменты времени t1
, t2
, ... ,
   X(t) X(t)
  X1 X1

t1
t2
. . . tn
t
Так как отсчеты являются случайными величинами, то будем их обозначать X(t1
), X(t2
), . . . , X(tn
).
Определим количество отсчетов, чтобы среднее квадратическое отклонение оценки математического ожидания сигнала не превысило 1% его математического ожидания. Поскольку mx
= 10, то нужно, чтобы 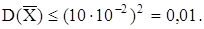 С другой стороны С другой стороны 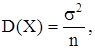 поэтому поэтому 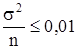 или или 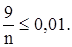 Отсюда получаем, что n ³ 900 отсчетов. Отсюда получаем, что n ³ 900 отсчетов.
2.2
Выборочная дисперсия
По выборочным данным важно знать не только выборочное среднее, но и разброс выборочных значений около выборочного среднего. Если выборочное среднее является оценкой генерального среднего, то выборочная дисперсия должна быть оценкой генеральной дисперсии. Выборочная дисперсия 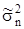 для выборки, состоящей из случайных величин для выборки, состоящей из случайных величин 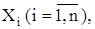 определяется следующим образом определяется следующим образом
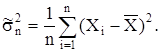
Используя это представление выборочной дисперсии, найдем ее математическое ожидание
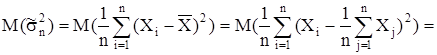
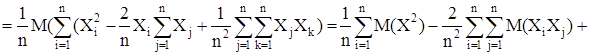 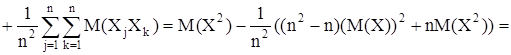

Таким образом мы получили, что 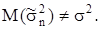 Это значит, что выборочная дисперсия является смещенной оценкой генеральной дисперсии. Чтобы получить несмещенную оценку, нужно величину умножить на Это значит, что выборочная дисперсия является смещенной оценкой генеральной дисперсии. Чтобы получить несмещенную оценку, нужно величину умножить на 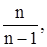 тогда выборочная дисперсия имеет вид тогда выборочная дисперсия имеет вид
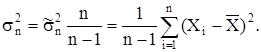
Итак мы получили следующий результат. Если в результате n независимых измерений случайной величины Х с неизвестным математическим ожиданием и дисперсией нам нужно по полученным данным определить эти параметры, то следует пользоваться следующими приближенными оценками
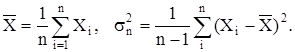
В случае, если известно математическое ожидание генеральной совокупности mx
, то выборочную дисперсию следует вычислять по формуле
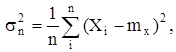
которая также является несмещенной оценкой.
3.
Статистический ряд. Статистическая функция распределения
Пусть имеются результаты измерения случайной величины Х с неизвестным законом распределения, которые представлены в виде таблицы:
| i
|
1
|
2
|
. . .
|
n
|
| xi
|
x1
|
x2
|
. . .
|
xn
|
Такую таблицу называют статистическим рядом. Статистический ряд представляет собой первичную форму записи статистического материала и он может быть обработан различными способами. Одним из таких способов обработки является построение статистической функции распределения случайной величины Х.
Статистической (эмпирической) функцией распределения F*(x) называется закон изменения частоты события X < x в данном статистическом материале, то есть
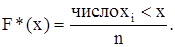
Для того, чтобы найти значение статистической функции распределения при данном х, надо подсчитать число опытов, в которых случайная величина Х приняла значения меньше, чем х, и разделить на общее число произведенных опытов. Полученная таким образом статистическая функция распределения является очень грубым приближением функции распределения F(x) случайной величины Х и в таком виде не используется на практике. Она носит в каком-то смысле качественный характер, из которого можно выдвинуть гипотезу о законе распределения случайной величины Х. При увеличении числа опытов (n ®¥) F*(x) по вероятности сходится к F(x). Однако, с увеличением n построение F*(x) становится очень трудоемкой операцией. Поэтому на практике часто бывает удобно пользоваться статистической характеристикой, которая приближается к плотности распределения.
4.
Статистическая совокупность. Гистограмма
При большом числе наблюдений представление данных в виде статистического ряда бывает затруднительным, а при решении ряда задач и нецелесообразным. В таких случаях производится подсчет результатов наблюдения по группам и составляют таблицу, в которой указываются группы и частоты полученные в результате наблюдения в каждой группе. Совокупность групп, на которые разбиваются результаты наблюдений и частоты, полученные в каждой группе, составляют статистическую совокупность, которая представлена ниже.
| Группа DХ
|
DХ1
|
DХ2
|
. . .
|
DХn
|
| Частота относительная
|
w1
|
w2
|
. . .
|
wn
|
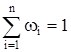
|
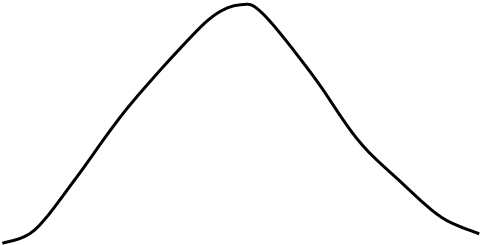
Графическое представление статистической совокупности носит название гистограммы. Гистограмма строится следующим образом. По оси абсцисс откладываются интервалы, соответствующие группам совокупности, и на каждой из них строится прямоугольник, площадь которого равна частоте данной группы. Из построения следует, что площадь суммы всех прямоугольников равна единице. Очевидно, что если плавно соединить точки гистограммы, то эта кривая будет первым приближением к плотности распределения случайной величине Х.
Если число опытов увеличивать и выбирать более мелкие группы (на рисунке маленькие интервалы) в статистической совокупности, то полученная гистограмма все более будет приближаться к плотности распределения случайной величины Х. Статистическую совокупность можно использовать и для построения приближенной функции распределения F*(x), выбрав в качестве значений случайной величины граничные значения групп.
Pi
*
X
DX1
DX2
. . . DXn
5. Метод наибольшего правдоподобия для нахождения оценок параметров плотности распределения
Метод наибольшего правдоподобия основывается на представлении выборки объема n как n-мерной случайной величине (Х1
, Х2
, ..., Хn
), где 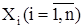 рассматриваются как независимые случайные величины с одинаковой плотностью распределения f(x). Плотность распределения такой n-мерной случайной величины называется функцией правдоподобия L(x1
, x2
, ..., xn
), которая в силу независимости случайных величин рассматриваются как независимые случайные величины с одинаковой плотностью распределения f(x). Плотность распределения такой n-мерной случайной величины называется функцией правдоподобия L(x1
, x2
, ..., xn
), которая в силу независимости случайных величин 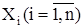 равна произведению плотностей распределения случайных величин Х1
, Х2
, ..., Хn
: равна произведению плотностей распределения случайных величин Х1
, Х2
, ..., Хn
:
L(x1
, x2
, ..., xn
) = f(x1
) f(x2
)... f(xn
).
Отсюда следует, что всякую функцию у=у(x1
, x2
, ..., xn
) выборочных значений x1
, x2
, ..., xn
, называемую статистикой, можно представить как случайную величину, распределение которой однозначно определяется функцией правдоподобия.
Рассмотрим метод отыскания оценок параметров по опытным данным, который использует функцию правдоподобия.
Пусть f(x;а) – плотность распределения случайной величины Х (генеральной совокупности), зависящей от параметра а. Функция правдоподобия также будет зависеть от параметра а и иметь вид
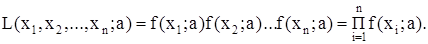
Сущность метода наибольшего правдоподобия заключается в том, чтобы найти такое значение параметра а, при котором функция правдоподобия L(x1
, x2
, ..., xn
, а) была бы максимальной. Для этого необходимо решить уравнение
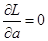
и найти то значение а, при котором функция L(x1
, x2
, ..., xn
, а) достигает максимума. С целью упрощения вычисления обычно максимизируют натуральный логарифм функции правдоподобия, пользуясь тем, что
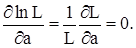
Если неизвестными являются несколько параметров а1
, а2
, ... , аm
, то функция правдоподобия зависит от m переменных L = L(x1
, x2
, ..., xn
; а1
, а2
, ... , аm
) и решаются m уравнений
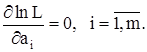
Пример. Пусть на вход приемного устройства поступает сумма двух сигналов: Y(t) = X + Z(t), где Х – неизвестный не зависящий от времени сигнал, а Z(t) – случайная помеха. В моменты времени t1
, t2
, ... , tn
производятся измерения величины Y(t). На основании опытных данных (выборки) y1
= y(t1
), y2 =
y(t2
), ... , yn
=y(tn
) нужно найти приближенное значение сигнала Х.
Решение. Пусть Z(t1
), Z(t2
), ... , Z(tn
) – независимые случайные величины распределены по нормальному закону с математическим ожиданием mZ
= 0 и дисперсией D(Z) = s2
. Тогда случайные величины 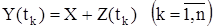 также независимы, нормально распределены с неизвестным математическим ожиданием а и с той же дисперсией s2
. Плотность распределения случайных величин Y(t1
), Y(t2
), ... , Y(tn
) имеет, таким образом, вид также независимы, нормально распределены с неизвестным математическим ожиданием а и с той же дисперсией s2
. Плотность распределения случайных величин Y(t1
), Y(t2
), ... , Y(tn
) имеет, таким образом, вид
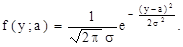
Запишем функцию правдоподобия для n-мерной случайной величины (Y1
, Y2
, ... , Yn
):
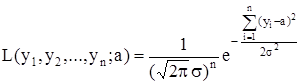
Tак как
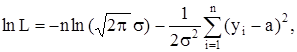
то из уравнения
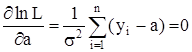
Имеем 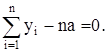
Значит
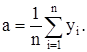
Нетрудно показать, что функция правдоподобия L = L(y1
, y2
, ..., yn
; а) при этом а достигает своего максимума. Таким образом мы показали, что оценка математического ожидания неизвестного сигнала Х по методу наибольшего правдоподобия в предположении нормального распределения аддитивной помехи является средним арифметическим измерений y1
, y2
, ..., yn
:
Метод наибольшего правдоподобия обладает важным свойством: он всегда приводит к состоятельным, хотя иногда и к смещенным, и эффективным оценкам.
На практике использование метода наибольшего правдоподобия часто приводит к необходимости решать достаточно сложные системы уравнений.
6.
Метод наименьших квадратов
математическая статистика метод распределение выборка
Применим метод наибольшего правдоподобия для обработки экспериментальных данных. Предположим, что между физической величиной t (например, временем) и измеряемой y (сигналом) существует функциональная зависимость: y = j (t).
Вид этой зависимости необходимо определить из опыта. Положим, что в результате опыта мы получили ряд экспериментальных точек и построили график зависимости у от t. Экспериментальные точки всегда имеют ошибки измерения. Возникает вопрос, как по экспериментальным данным наилучшим образом воспроизвести зависимость у от t? Если провести интерполяционную кривую, то есть кривую, точно проходящую через экспериментальные точки, то это в силу ошибок измерения будет не самым лучшим решением. В случае, когда известна тенденция этой зависимости, другими словами вид кривой, то задача упрощается. Тогда возникает задача сглаживания - построение кривой таким образом, чтобы уклонение(в каком-то смысле) от экспериментальных точек кривой было минимальным.
Очень часто бывает так, что, зная вид кривой, из опыта требуется установить только некоторые параметры зависимости. Например, известно, что зависимость есть линейная y = at + b, а неизвестные величины а и b надлежит определить из экспериментальных данных y1
= y(t1
), y2
= y(t2
), ... ,yn
= y(tn
). В общем случае функция у = j (t, a, b, ...) может содержать много параметров (а,b, ...). Требуется выбрать эти параметры так, чтобы кривая у = j (t, a, b, ...) в каком-то смысле наилучшим образом отображала зависимость, полученную опытным путем. Для этого рассмотрим следующую модель.
Имеются наблюдения (экспериментальные данные) y1
, y2
, ... ,yn
точных величин j (t1
, a, b, ...) j (t2
, a, b, ...), ... , j (tn
, a, b, ...). Тогда величина Di
= yi
- j (ti
, a, b, ...) 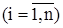 является ошибкой наблюдения. Относительно ошибок будем полагать, что Di является ошибкой наблюдения. Относительно ошибок будем полагать, что Di
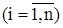 - независимые случайные величины с математическим ожиданием равным нулю (центрированные) и одинаковой дисперсией s2
подчинены нормальному закону распределения. Функция правдоподобия в этом случае будет иметь вид - независимые случайные величины с математическим ожиданием равным нулю (центрированные) и одинаковой дисперсией s2
подчинены нормальному закону распределения. Функция правдоподобия в этом случае будет иметь вид
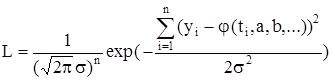
и достигает своего максимального значения путем выбора параметров а, b ... лишь тогда, когда функция
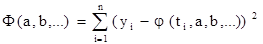
достигнет минимального значения. Если измерения неравноценны, что эквивалентно наличию разных дисперсий si
2
ошибок Di
, то, исходя из функции правдоподобия, необходимо минимизировать функцию
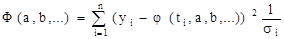 . .
Величина 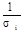 здесь играет роль весовых множителей. Этот метод отыскания параметров носит название метода наименьших квадратов. здесь играет роль весовых множителей. Этот метод отыскания параметров носит название метода наименьших квадратов.
Для нахождения минимального значения последней функции нужно решить систему уравнений
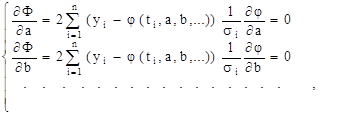
количество уравнений которой равно количеству параметров а, b, ... . В качестве примера рассмотрим упомянутую линейную зависимость при равноценных измерениях:
у = аt + b (j (ti
;a, b) = at + b).
В этом случае нам нужно минимизировать функцию
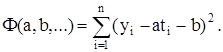
Беря частные производные от этой функции по а и b и приравнивая их нулю, получаем систему двух уравнений с двумя неизвестными
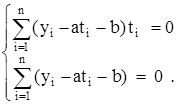
Решая эту систему относительно а и b, после простых преобразований получим следующую линейную зависимость
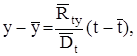
где
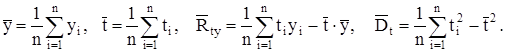
|
