| Федеральное государственное образовательное учреждение
высшего профессионального образования
Академия Бюджета и Казначейства
Министерства финансов Российской Федерации
Калужский филиал
РЕФЕРАТ
по дисциплине:
Эконометрика
Тема:
Эконометрический метод и использование стохастических зависимостей в эконометрике
Факультет учетный
Специальность
бухучет, анализ и аудит
Отделение очно-заочное
Научный руководитель
Швецова С.Т.
Калуга 2007
Содержание
Введение
1.
Анализ различных подходов к определению вероятности: априорный подход, апостериорно-частотный подход, апостериорно-модельный подход
2.
Примеры стохастических зависимостей в экономике, их особенности и теоретико-вероятностные способы их изучения
3.
Проверка ряда гипотез о свойствах распределения вероятностей для случайной компоненты как один из этапов эконометрического исследования
Заключение
Список литературы
Введение
Становление и развитие эконометрического метода происходили на основе так называемой высшей статистики – на методах парной и множественной регрессии, парной, частной и множественной корреляции, выделения тренда и других компонент временного ряда, на статистическом оценивании. Р. Фишер писал: «Статистические методы являются существенным элементом в социальных науках, и в основном именно с помощью этих методов социальные учения могут подняться до уровня наук» [3].
Целью данного реферата послужило изучение эконометрического метода и использования стохастических зависимостей в эконометрике.
Задачами данного реферата является проанализировать различные подходы к определению вероятности, привести примеры стохастических зависимостей в экономике, выявить их особенности и привести теоретико-вероятностные способы их изучения, проанализировать этапы эконометрического исследования.
1. Анализ различных подходов к определению вероятности: априорный подход, апостериорно-частотный подход, апостериорно-модельный подход
Для полного описания механизма исследуемого случайного эксперимента недостаточно задать лишь пространство элементарных событий. Очевидно, наряду с перечислением всех возможных исходов исследуемого случайного эксперимента мы должны также знать, как часто в длинной серии таких экспериментов могут происходить те или другие элементарные события.
Реклама

Для построения (в дискретном случае) полной и законченной математической теории случайного эксперимента – теории вероятностей –
помимо исходных понятий случайного эксперимента, элементарного исхода
и случайного события
необходимо запастись еще одним исходным допущением (аксиомой),
постулирующим существование вероятностей элементарных событий (удовлетворяющих определенной нормировке), и определением
вероятности любого случайного события.
Аксиома.
Каждому элементу w
i
пространства элементарных событий Ω соответствует некоторая неотрицательная числовая характеристика p
i
шансов его появления, называемая вероятностью события w
i
, причем
p
1
+
p
2
+ . . . +
pn
+ . . . = ∑
pi
= 1 (1.1)
(отсюда, в частности, следует, что 0 ≤ р
i
≤ 1 для всех i
).
Определение вероятности события.
Вероятность любого события А
определяется как сумма вероятностей всех элементарных событий, составляющих событие А,
т.е. если использовать символику Р{А} для обозначения «вероятности события А
»,
то
Р{А} = ∑ Р{
wi
} = ∑
pi
(1.2)
Отсюда и из (1.1) непосредственно следует, что всегда 0 ≤ Р{A} ≤ 1, причем вероятность достоверного события равна единице, а вероятность невозможного события равна нулю. Все остальные понятия и правила действий с вероятностями и событиями будут уже производными от введенных выше четырех исходных определений (случайного эксперимента, элементарного исхода, случайного события и его вероятности) и одной аксиомы.
Таким образом, для исчерпывающего описания механизма исследуемого случайного эксперимента (в дискретном случае) необходимо задать конечное или счетное множество всех возможных элементарных исходов Ω и каждому элементарному исходу w
i
поставить в соответствие некоторую неотрицательную (не превосходящую единицы) числовую характеристику pi
,
интерпретируемую как вероятность появления исхода w
i
(будем обозначать эту вероятность символами Р{w
i
}), причем установленное соответствие типа w
i
↔ pi
должно удовлетворять требованию нормировки (1.1).
Вероятностное пространство
как раз и является понятием, формализующим такое описание механизма случайного эксперимента. Задать вероятностное пространство – это значит задать пространство элементарных событий Ω и определить в нем вышеуказанное соответствие типа
Реклама

w
i
↔
pi
= Р {
w
i
}.
(1.3)
Для определения из конкретных условий решаемой задачи вероятности P
{
w
i
}
отдельных элементарных событий используется один из следующих трех подходов.
Априорный подход
к вычислению вероятностей P
{
w
i
}
заключается в теоретическом, умозрительном анализе специфических условий данного конкретного случайного эксперимента (до проведения самого эксперимента). В ряде ситуаций этот предопытный анализ позволяет теоретически обосновать способ определения искомых вероятностей. Например, возможен случай, когда пространство всех возможных элементарных исходов состоит из конечного числа N
элементов, причем условия производства исследуемого случайного эксперимента таковы, что вероятности осуществления каждого из этих N
элементарных исходов нам представляются равными (именно в такой ситуации мы находимся при подбрасывании симметричной монеты, бросании правильной игральной кости, случайном извлечении игральной карты из хорошо перемешанной колоды и т. п.). В силу аксиомы (1.1) вероятность каждого элементарного события равна в этом случае 1/
N
.
Это позволяет получить простой рецепт и для подсчета вероятности любого события: если событие А
содержит NA
элементарных событий, то в соответствии с определением (1.2)
Р {А}
=
NA
/
N
. (1.2')
Смысл формулы (1.2’) состоит в том, что вероятность события в данном классе ситуаций
может быть определена как отношение числа благоприятных исходов (т. е. элементарных исходов, входящих в это событие) к числу всех возможных исходов (так называемое классическое определение вероятности).
В современной трактовке формула (1.2’) не является определением вероятности: она применима лишь в том частном случае, когда все элементарные исходы равновероятны.
Апостериорно-частотный
подход к вычислению вероятностей Р {
w
i
}
отталкивается, по существу, от определения вероятности, принятого так называемой частотной концепцией вероятности. В соответствии с этой концепцией вероятность P
{
w
i
}
определяется как предел относительной частоты появления исхода w
i
в процессе неограниченного увеличения общего числа случайных экспериментов n
, т.е.
pi
= P {
wi
} = lim mn
(wi
) / n (1.4)
где mn
(
wi
) – число случайных экспериментов (из общего числа n
произведенных случайных экспериментов), в которых зарегистрировано появление элементарного события w
i
. Соответственно для практического (приближенного) определения вероятностей pi
предлагается брать относительные частоты появления события w
i
в достаточно длинном ряду случайных экспериментов.
Разными в этих двух концепциях оказываются определения вероятностей: в соответствии с частотной концепцией вероятность не является объективным, существующим до опыта,
свойством изучаемого явления, а появляется только в связи с проведением опыта
или наблюдения; это приводит к смешению теоретических (истинных, обусловленных реальным комплексом условий «существования» исследуемого явления) вероятностных характеристик и их эмпирических (выборочных) аналогов.
Апостериорно-моделъный подход к
заданию вероятностей P
{
wi
}
, отвечающему конкретно исследуемому реальному комплексу условий, является в настоящее время, пожалуй, наиболее распространенным и наиболее практически удобным. Логика этого подхода следующая. С одной стороны, в рамках априорного подхода, т. е. в рамках теоретического, умозрительного анализа возможных вариантов специфики гипотетичных реальных комплексов условий разработан и исследован набор модельных вероятностных
пространств (биномиальное, пуассоновское, нормальное, показательное и т. п.). С другой стороны, исследователь располагает результатами ограниченного ряда случайных экспериментов.
Далее, с помощью специальных математико-статистических приемов исследователь как бы прилаживает гипотетичные модели вероятностных пространств к имеющимся у него результатам наблюдения и оставляет для дальнейшего использования лишь ту модель или те модели, которые не противоречат этим результатам и в некотором смысле наилучшим образом им соответствуют.
2. Примеры стохастических зависимостей в экономике, их особенности и теоретико-вероятностные способы их изучения
Накопленный опыт практического использования аппарата статистического исследования зависимостей позволяет выделить те типы основных прикладных направлений исследований, в которых этот аппарат работает особенно часто и плодотворно.
Остановимся кратко на роли методов статистического исследования зависимостей в разработке каждого из следующих направлений.
I
.
Нормирование
Общая схема формирования нормативов с использованием методов статистического исследования зависимостей может быть представлена следующим образом. Нормативный показатель играет в моделях типа
η =
f
(
x
) + ε (2.1)
роль результирующей (объясняемой) переменной у,
а факторы, участвующие в расчете нормативного показателя, - роль объясняющих переменных x
(1)
,
x
(2)
, . . . ,
x
(
p
)
. Предполагается, что привлечение для расчета норматива у
полной системы определяющих его факторов, т.е. такой системы, с помощью которой возможно детерминированное (однозначное) определение величины у,
либо принципиально невозможно, либо нецелесообразно из-за чрезмерного усложнения расчетных формул. Поэтому анализируется связь между у
и (
x
(1)
,
x
(2)
, . . . ,
x
(
p
)
)
вида
y
=
f
x
(1)
,
x
(2)
, . . . ,
x
(
p
)
;
θ
) + ε, (2.2)
где ε – остаточная компонента, обуславливающая возможную погрешность в определении норматива y
по известным значениям факторов X
= (
x
(1)
,
x
(2)
, . . . ,
x
(
p
)
)
T
, а
f
(
X
; θ) –
функция их некоторого известного параметрического семейства F
= {
f
(
X
; θ)}, θ €
A
,
однако численное значение входящего в ее уравнение параметра θ
неизвестно. Для подбора «подходящего» значения θ проводится контрольный эксперимент (наблюдение), в результате которого исследователь получает исходные статистические данные.
Далее на основании этих данных проводится необходимый статистический анализ модели 2.2 с целью получения оценки θ неизвестного параметра θ и анализа точности полученной расчетной формулы Ycp
(
X
) =
f
(
X
; θ),
в которой величина условной (экспериментальной) средней Ycp
(
X
)
интерпретируется как средний нормативный показатель при значениях определяющих факторов, равных Х
.
Данный подход использовался, в частности, при разработке методик численности служащих (по различным их функциям) на промышленном предприятии.
II
. Прогноз, планирование, диагностика.
Определим в качестве результирующей переменной у
интересующий нас прогнозируемый (планируемый, диагностируемый) показатель, а в качестве объясняющих переменных x
(1)
,
x
(2)
, . . . ,
x
(
p
)
— сопутствующие факторы, значения которых содержат основную информацию о величине этого показателя. Наличие остаточной случайной компоненты ε,
как и прежде, отражает тот факт, что переменные x
(1)
,
x
(2)
, . . . ,
x
(
p
)
содержат не всю информацию об у
, и обусловливает неизбежность погрешности в определении прогнозируемого (планируемого, диагностируемого) показателя по известным значениям объясняющих факторов x
(1)
,
x
(2)
, . . . ,
x
(
p
)
. Исходные статистические данные вида (2.2) исследователь получает, регистрируя одновременно значения у
и (
x
(1)
,
x
(2)
, . . . ,
x
(
p
)
)
на анализируемых объектах в прошлом (в базовом периоде) или на других объектах, но однородных с анализируемыми.
III
. Оценка труднодоступных для непосредственного наблюдения и измерения параметров системы.
Восстановление возраста археологической находки по ряду косвенных признаков; прочности бетона
с помощью косвенных (неразрушающих) методов контроля; денежных сбережений семьи
по ее доходу (в среднедушевом исчислении) — во всех этих ситуациях исследователь вынужден иметь дело с показателями, труднодоступными для непосредственного измерения. Очевидно, для того чтобы иметь принципиальную возможность статистически выявить связь, существующую между труднодоступным показателей у
и косвенно связанными с ним, но легко поддающимися наблюдению и измерению признаками x
(1)
,
x
(2)
, . . . ,
x
(
p
)
, исследователю необходимо располагать исходными статистическими данными, которые получают с помощью специально организованного контрольного эксперимента или наблюдения. После того как эта связь выявлена (и оценена степень ее точности), она используется для косвенного определения значений труднодоступных показателей лишь по значениям объясняющих переменных x
(1)
,
x
(2)
, . . . ,
x
(
p
)
.
IV
. Оценка эффективности функционировании (или качества) анализируемой системы.
Пытаясь оценить (в целом) эффективность деятельности отдельного специалиста, подразделения или предприятия, проранжировать страны по некоторому интегральному качеству, мы каждый раз по существу решаем одну и ту же задачу: отправляясь в своем анализе от набора частных показателей x
(1)
,
x
(2)
, . . . ,
x
(
p
)
, каждый из которых может быть измерен и характеризует какую-нибудь одну частную сторону понятия «эффективность», мы их как бы взвешиваем и выходим на некоторый скалярный агрегированный показатель эффективности у.
Этот показатель — латентный (скрытый), так как он принципиально не поддается непосредственному измерению. Но он с некоторой точностью восстанавливается по значениям частных показателей эффективности x
(1)
,
x
(2)
, . . . ,
x
(
p
)
. Это значит, что между латентным агрегированный показателем у
и набором частных критериев эффективности x
(1)
,
x
(2)
, . . . ,
x
(
p
)
существует статистическая связь типа (2.2).
V
. Оптимальное регулирование параметров функционирования анализируемой системы, ситуационный анализ.
Рассмотрим пример. При анализе производительности мартеновских печей на одном из заводов исследовалась, в частности, зависимость между производительностью в тонно/часах и процентным содержанием углерода в металле по расплавлении ванны (пробу брали через час после первого скачивания шлака). Очевидно, величины производительности (
yi
)
и процентного содержания углерода (xi
) подвержены некоторому неконтролируемому разбросу, обусловленному влиянием множества не поддающихся строгому учету и контролю факторов.
Другими словами, последовательность пар чисел (xi
, yi
), i = 1, 2, . . . , 130, представляет в данном случае результаты 130 независимых наблюдений двумерной случайной величины (ξ, η). Здесь просматривается вполне определенная закономерность зависимости условного среднего значения производительности ycp
(
x
) =
E
(η | ξ =
x
)
от величины процентного содержания углерода х.
Поэтому, мы можем дать рекомендации технологу по оптимальному (с точки зрения максимизации производительности) управлению процессом выплавки: поддерживать процентное содержание углерода в пределах 0,6-1,0 %.
Основные типы зависимостей между количественными переменными:
Зависимость между неслучайными переменными. В этом случае результирующий показатель у
детерминировано (однозначно) восстанавливается по значениям неслучайных объясняющих переменных Х = (
x
(1)
,
x
(2)
, . . . ,
x
(
p
)
)Т
,
т. е. значения у
зависят только от соответствующих значений Х
и полностью ими определяются. Это – обычная схема чисто функциональной зависимости
между неслучайными переменными, когда у
является некоторой функцией от р
переменных Х (т. е. y = f (X)), что является вырожденным случаем зависимостей вида 2.2, когда остаточная случайная компонента ε равна нулю (с вероятностью единица).
Регрессионная зависимость случайного результирующего показателя η от неслучайных объясняющих переменных Х
. Природа такой связи может носить двойственный характер:
а) регистрация результирующего показателя η неизбежно связана с некоторыми ошибками измерения ε, в то время как предикторные (объясняющие) переменные Х = (
x
(1)
,
x
(2)
, . . . ,
x
(
p
)
)Т
измеряются без ошибок
б) значения результирующего показателя η зависят не только от соответствующих значений Х,
но и еще от ряда неконтролируемых факторов, поэтому при каждом фиксированном значении Х’ соответствующие значения результирующего показателя η (Х’) = (η | X = X’) неизбежно подвержены некоторому случайному разбросу.
В этом случае объясняющие переменные Х играют роль неслучайного (векторного при р > 1) параметра, от которого зависит закон распределения вероятностей (в частности, среднее значение и дисперсия) исследуемого результирующего показателя η. Удобной математической моделью такого рода является разложение вида
η (Х) =
f
(
X
) +
ε
(
X
). (2.4)
Корреляционно-регрессионная зависимость между случайными векторами η – результирующим показателем и ξ – объясняющей переменной. Зависимости такого типа вообще характерны для описания хода технологических процессов, реальные значения параметров которых ξ = (ξ(1)
, ξ(2)
, . . . , ξ(р)
)Т
, равно как и характеризующие их результирующие показатели η = (η(1)
, η2)
, . . . , η(
m
)
)Т
, как правило, флюктуируют случайным (но взаимосвязанным) образом около установленных номиналов.
Зависимости структурного типа, или зависимости по схеме конфлюэнтного анализа. Конфлюэнтный анализ предоставляет совокупность методов математико-статистической обработки данных, относящихся к анализу априори постулируемых функциональных связей между количественными (случайными или неслучайными) переменными Y
=
(
y
(1)
,
y
(2)
, . . . ,
y
(
m
)
)
T
и X
= (
x
(1)
,
x
(2)
, . . . ,
x
(
p
)
)
T
в условиях, когда наблюдаются не сами переменные, а случайные величины
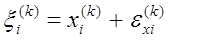 ,
k
= 1, 2, . . . ,
p
;
(2.5)
,
k
= 1, 2, . . . ,
p
;
(2.5)
где 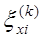 и
и 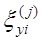 - случайные ошибки измерений соответственно переменных х(
k
)
и
y
(
i
)
в
i-м наблюдении, a n - общее число наблюдений. [1].
- случайные ошибки измерений соответственно переменных х(
k
)
и
y
(
i
)
в
i-м наблюдении, a n - общее число наблюдений. [1].
3. Проверка ряда гипотез о свойствах распределения вероятностей для случайной компоненты как один из этапов эконометрического исследования
Описанные ниже критерии проверки справедливости сделанного выбора общего вида искомой функции регрессии подтверждают факт непротиворечивости проверяемого вида функции регрессии имеющимся у исследователя исходным данным (2.3) либо отвергают обсуждаемую гипотетичную форму зависимости как не соответствующую этим данным.
1. Общий приближенный критерий, основанный на группированных данных
(или при наличии нескольких наблюдений при каждом фиксированном значении аргумента). Пусть высказана гипотеза об общем виде функции регрессии Но
: Е(
h
|
x
=
X
) =
f
а
(Х;
q
1
,
q
2
, . . .
q
k
) (
fa
(
X
;
q
) –
известная функция, (
q
1
,
q
2
, . . .
q
k
)
=
q
- неизвестные числовые параметры) и пусть вычислены оценки q
1
,
q
2
, . . . ,
q
k
неизвестных параметров, входящих в описание уравнения регрессии. При группировке данных (или при проведении эксперимента) мы должны соблюдать требование, в соответствии с которым число интервалов группирования (или число различных значении аргумента, в которых производилась наблюдения) s должно обязательно превосходить число неизвестных параметров k
, т. е.
s
–
k
≥ 1
.
2. Общий приближенный критерий, основанный на негруппированных данных
(при известной величине дисперсии остаточной случайной компоненты).
Встречаются ситуации, когда в результате предварительных исследований или из других каких-либо соображений нам удается заранее определить величину дисперсии σ2
остаточной случайной компоненты ε (например, когда ε – ошибка измерения и нам известны характеристики точности используемого измерительного прибора). В этом случае можно отказаться от стеснительного требования группированности данных и для проверки гипотезы об общем виде функции регрессии воспользоваться фактом χ2
(n – k) – распределенности статистики.
Заключение
Подведем краткие итоги проделанной работы:
1. Аппарат статистического исследования зависимостей — составная часть многомерного статистического анализа — нацелен на решение основной проблемы естествознания: как на основании частных результатов статистического наблюдения за анализируемыми событиями или показателями выявить и описать существующие между ними стохастические взаимосвязи.
2. Центральным математическим объектом в процессе статистического исследования зависимостей является функция f
(
X
)
, называемая функцией регрессии Y
по
X
и описывающая изменение условного среднего значения Ycp
(
X
)
результирующего показателя Y
(вычисленного при фиксированных на уровне X
значениях объясняющих переменных) в зависимости от изменения значений объясняющих переменных X
.
3. К основным типовым задачам практики следует отнести задачи: 1) нормирования; 2) прогноза, планирования и диагностики; 3) оценки труднодоступных (для непосредственного наблюдения и измерения) характеристик исследуемой системы; 4) оценки эффективности функционирования (или качества) анализируемой системы; 5) регулирования параметров функционирования анализируемой системы.
4. По своей природе исследуемые зависимости могут быть разделены на: 1) детерминированные, когда исследуется функциональная зависимость между неслучайными переменными; 2) регрессионные, когда исследуется зависимость случайного результирующего показателя от неслучайных объясняющих переменных — параметров системы; 3) корреляционные, когда исследуется зависимость между случайными переменными, причем объясняющие переменные могут быть измерены без искажений; 4) конфлюэнтные, когда исследуется функциональная зависимость между случайными или неслучайными переменными в ситуации, когда те и другие могут быть измерены только с некоторой случайной ошибкой.
Список литературы
1. Айвазян С.А., Мхитарян В.С. Прикладная статистика и основы эконометрики. – М.: ЮНИТИ, 1998
2. Вентцель Е.С. Теория вероятностей. – М.: Высшая школа, 1998.
3. Эконометрика. / Под ред. Елисеевой И.И. – М.: Финансы и статистика, 2001.
|
