Міністерство освіти і науки України
Черкаський національний університет ім. Б. Хмельницького
Факультет інформаційних технологій та біомедичної кібернетики
з дисципліни: “Об'єктно - орієнтовне програмування ”
на тему: “ Архівація файлів та створення архіватора текстових файлів ”
по спеціальності: 6.080403 Програмне забезпечення автоматизованих систем
УКР.ЧНУ. 00051015-08
Виконав:
Студент 2 курсу група
КС-061
Голубченко Ю.С.
Керівник:
Бодрих Р.С.
___________________
дата
___________________
оцінка
___________________
підпис
Черкаси 2008
Зміст
Зміст. 2
Спосіб представлення інформації на ПК.. 3
Ідея кодування з стисненням. 4
Алгоритм Хаффмана. 6
Список використаних джерел. 10
Додатки. 11
Спосіб представлення інформації на ПК
Для початку слід сказати, що в пам'яті машини (на дискові чи в ОЗУ) данні зберігаються в вигляді послідовності нулів та одиниць. Кожна мінімальна комірка файлу зберігає нуль або одиницю. Давайте спробуємо розібратись, що нам, користувачам, може казати ця нескінченна послідовність цифр?
З самого початку вся інформація користувача обмежувалась лише текстами. Тексти складаються з символів. Підрахуємо кількість символів, необхідних для того, щоб писати різні тексти. Насамперед, наш національний алфавіт(кирилиця). Додамо латиницю, знаки пунктуації, цифри, знаки математичних операцій, символи №, #, @, %, і інші. А також символи псевдографіки, потрібні для малювання таблиць в тексті і деякі інші. Ми отримаємо "віртуальний алфавіт", який складається приблизно з 200 елементів.
Але як зберегти текст, написаний в такому великому алфавіті, якщо комп’ютер може зберігати лише нулі та одиниці? Мінімальна комірка (біт) може приймати два значення – 0 та 1. Якщо взяти дві такі комірки, які йдуть одна за одною то така пара може приймати 4 значення: "00", "01", "10", "11". Можливо ви вже здогадались, що якщо брати набори з n мінімальних комірок (біт), то число можливих значень такого набору збільшується і буде дорівнювати степені двійки з показником n. Тобто якщо групуємо 2 біта, то число можливих варіантів 2^2=4; якщо три біта, то варіантів значень цієї групи (2^3): "000", "001", "010", "011", "100", "101", "110", "111" і так для кожної кількості біт в групі.
Реклама

Ми хочемо підібрати таку кількість біт, група з яких може приймати як мінімум близько 200 значень (кожне значення ми ототожнюємо з символом нашого алфавіту). Мінімальна степінь двійки, яка перебільшує кількість символів віртуального алфавіту – восьма (2^8= 256). Іншими словам, згрупувавши біти по вісім штук, ми зможемо кожному значенню такого набору біт (всього 256 таких значень) спів ставити свою букву, як і було зроблено в стандарті ASCII. Саме тому вся пам'ять ПК розділена на байти – групи по 8 біт. До речі саме тому перші масові процесори були восьми розрядні (кар’єра Біла Гейтса почалась з впровадження інтерпретатора мови Basic для систем, побудованих на базі восьми розрядного процесора 8080).
Тепер давайте поміркуємо як же і на чому можливо економити місце при стисненні файлів. В деяких файлах зустрічаються досить довгі ланцюги однакових байтів.
Уявіть собі такий файл:
aaaaabbbccccccccccccccadddddddddddddddd {endoffile}.
Файл займає на диску 39 байт. Зрозуміло, що інформація в файлі дещо надлишкова і зберігання файлу в такому вигляді недоцільне. Зовсім інша справа, якщо файл буде мати такий вигляд:
5a3b14ca16d {endoffile}.
В такому випадку файл буде займати лише 11 байт. Слідуючи з цього файл можна записати більш економічно 39/11= 3.5 разів. На цьому ж прикладі можна описати ще один спосіб економії дискового місця. Як видно файл складається всього з чотирьох символів. Якщо спів ставити кожному з них пару бітів, то отримаємо:
a – "00",
b – "01",
c – "10",
d – "11".
Іншими словами файл можна закодувати таким чином, що кожен символ буде кодуватися не вісьмома, а двома бітами. І тоді економія буде чотирикратною (8/2=4). Слід зауважити, що цей варіант буде спільний і однаково ефективний навіть якщо в файлі немає жодного однакового ланцюга. Зауважте, що для застосування такого алгоритму кількісний склад представлений в файлі байт повинен бути неповним. Наприклад, якщо в файлі представлені 200 різних символів, то для однозначної ідентифікації кожного з них доведеться використати всі вісім біт ( семи не вистачить, так як комбінації з семи біт можуть приймати лише 128 значень), що не дозволить досягнути ніяких результатів при використанні цього способу стиснення.
Отже, якщо ви зрозуміли суть приведених прикладів, то вам в повинні бути зрозумілі ідеї, згідно яким проходить стиснення файлів. Зауважте, що знаючи, яким саме правилом користувались при стисненні, архіви можна буде розпаковувати і отримувати початкові файли. Це варіанти архівації без втрати якості.
Реклама

З деяких пір користувачу стало недостатньо тільки текстів. І користувачі отримали можливість зберігати на своїх жорстких дисках музику, зображення, відео. Всі ці файли також зберігаються в вигляді послідовності байтів. І якщо в тексті втрата хоча б одної букви або знака може мати фатальні наслідки, то в зображенні чи в відео кліпі інформація інколи наскільки надлишкова, що неминуче видалення частини інформації ніяким чином не вплине на сприйняття людини (за рахунок обмежень, які накладаються зором и слухом). Звідси і ряд методів стиснення з втратою якості.
Це алгоритм архівації без втрати якості. В розглянутих вище прикладах передбачувалось, що, або ж початковий файл складається в основному з однорідних ланцюгів байтів, або ж кількість використовуваних символів достатньо мала ( тобто файл складається з невеликої кількості елементів таблиці ASCII). Уявимо собі самий простий випадок, коли в файлі представлена більша частина таблиці ASCII і майже немає однорідних послідовностей. В такому випадку припустимий результат можливо отримати тільки якщо різні байти (символи) зустрічаються в даному файлі з різною частотою. Тоді найбільш часто трапляючись символи можуть бути закодовані меншим числом біт, а ті що зустрічаються досить рідко навпаки більшим числом біт. В результаті отриманий після кодування файл с більшою вірогідністю буде меншого об'єму, ніж початковий.
Перш ніж описати алгоритм перекодування, який дозволяє найбільш часто зустрічаємі символи (байти) кодувати не вісьмома, а набагато меншим числом біт, потрібно вказати на обмеження, який має кожен, навіть самий ефективний алгоритм без втрати якості.
Можна уявити, що всі файли – це тексти, написані на алфавіті, який складається з 256 літер (так воно власне і є). Розглянемо всю множину файлів, розмір не перевищує n байт (де n будь – яке число). І припустимо, що існує деякий алгоритм кодування, який любий файл стискує з "додатною" ефективністю. Тоді множина всіх їх архівів які входять в склад всіх файлів, розмір яких менше n байт. Згідно нашому припущенню існує відповідність між двома закінченими множинами, кількість елементів яких не співпадає. Звідси можливо зробити досить вагомі висновки: 1) не існує архіватора, який би однаково добре пакував будь-які файли, 2) для будь-якого архіватора знайдуться файли, в результаті стиснення яких будуть отримані архіви в кращому випадку не меншого розміру чим початкові файли.
Тепер почнемо описання алгоритму Хаффмана. Розглянемо його на прикладі наступного файлу:
cccacbcdaaabdcdcddcddccccccccccc {endoffile}
Розпишемо частоти кожного з символів:
a – 4,
b – 2,
c – 19,
d – 7.
Весь файл займає 32 байта. Кожен з символів в початковому файлі кодується згідно таблиці ASCII вісьмома бітами:
a – 01100001,
b – 01100010,
c – 01100011,
d – 01100100,
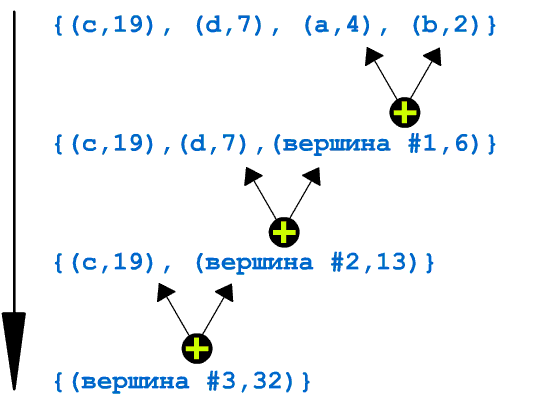
Крок №1. Розмістимо ці чотири символи в порядку зменшення їх частот:
{(c,19),(d,7),(a,4),(b,2)}
Крок №2. На наступному рядку запишемо набір, отриманий з попереднього наступним чином:
замість двох останніх символів з їх частотами запишемо новий елемент, котрий замість назви символу буде мати запис "Вершина #n", а замість частоти – сума частот останніх двох елементів попереднього набору;
відсортуємо отриманий набір по спаданню.
{(c,19),(d,7),( "Вершина #1", 6)}
Крок №3. Переходимо на крок №2до тих пір, поки набір не буде складатися тільки з одного елемента: ("Вершина #last_number", summa_vseh_chastot):
{(c,19),("Вершина #2", 13)}
{( "Вершина #3", 32)} (візуальна ілюстрація див. Малюнок №1)
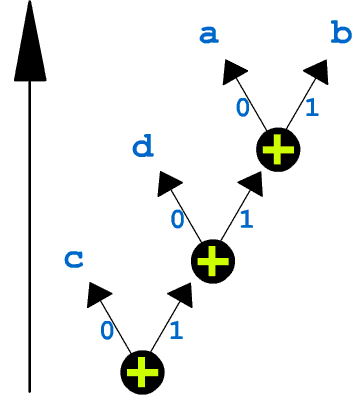
Що ж отримали? Розгляньте малюнок. Ви бачите дерево, яке росте з листків! Якщо з'єднати лінією кожен з елементів "вершина #x" з тими елементами попередніх наборів, сума частот яких зберігається в другій частині елемента "вершина #x", то ми отримаємо так би мовити дерево(в програмуванні подібні структури називаються бінарними деревами).
Суть цієї деревовидної структури в тому, щоб кожному з символів спів ставити різне число біт в залежності від його частоти (як вже казалося, в нетиснутому файлі символи зберігаються в виді груп по вісім біт). Якщо уважно придивитись в цей малюнок, ви побачите, що кожна з гілок відмічена або нулем або одиницею. Таким чином, якщо уявно пройтись по дереву від кореня до якої-небудь вершини, маючої символ, то послідовність нулів та одиниць, які зустрічаються на вашому шляху, буде комбінацією біт для цього символу. Наприклад, символ "с" як найбільш часто зустрічаємий буде кодуватися одним бітом "0", символ "d" двома бітами "10" і т.д. (див. Малюнок №2)
Давайте розглянемо ще один приклад файлу, власне дерево якого має вигляд більш складний, ніж в попередньому випадку.
Буває так, що частоти окремих символів однакові або майже однакові, це призводить до того, що такі символи кодуються одним і тим же числом біт. Однак алгоритм побудови дерева від цього незмінюєтся:
ddddddaaaaaabbbbbbccccdffffffffffdddd{37 byte, end of file}
В двійковому вигляді файл буде мати вигляд такий:
01100100 01100100 01100100 01100100 01100100 01100100 01100001 01100001 01100001 01100001 01100001 01100001 01100010 01100010 01100010 01100010 01100010 01100010 01100011 01100011 01100011 01100011 01100100 01100110 01100110 01100110 01100110 01100110 01100110 01100110 01100110 01100110 01100110 01100100 01100100 01100100 01100100{296 bit, end of file}
Розпишемо частоти кожного з символів:
a - 6
b - 6
c - 4
d - 11
f - 10
Весь файл займає 37 байт. Кожен з символів в початковому файлі кодується згідно таблиці ASCII вісьмома бітами. Поглянемо, як будуть кодуватись ці символи в стиснутому файлі. Для цього побудуємо відповідне дерево (не забуваємо сортувати отриманий набір):
1. {(d,11), (f,10), (a,6), (b,6), (c,4)};
2. {(d,11), (f,10), (вершина #1, 10), (a,6)} (зауважте, що сортування по спаданню частот є обов'язковим!);
3. {(вершина #2, 16), (d,11), (f,10)};
4. {(вершина #3, 21), (вершина #2, 16)};
5. {(вершина #4, 37)}
Аналізуючи отримане дерево, розпишемо, як буде кодуватися кожен з символів після стиснення:
a - "11"
b - "100"
c - "101"
d - "00"
f - "01".
В двійковому вигляді файл буде мати такий вигляд:
00000000 00001111 11111111 10010010 01001001 00101101 10110100 01010101 01010101 01010000 0000хххх{88 bit, end of file}
Стиснутий файл зайняв 11 байт (останні чотири біта хххх записуються будь-які, тому що весь файл насправді вміщується в 84 біта, що не кратно восьми). Коефіцієнт стиснення при такому кодуванні дорівнює 3,5.
1) Д. Ватолин, А. Ратушняк, М. Смирнов, В. Юкин. Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео. Диалог-МИФИ, 2003 г. 384 стр.
2) Сэломон Д. Сжатие данных, изображений и звука: Перевод с английского. Техносфера. 2004г.
Додатки
Малюнок №1:
Малюнок №2:
|
