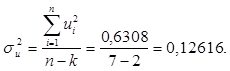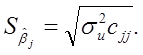ЗМІСТ
1. Основні параметри проведення економетричного аналізу
2. Метод найменших квадратів
3. Оцінка параметрів лінійної регресії за методом найменших квадратів
4. Властивості простої лінійної регресії
5. Коефіцієнти кореляції та детермінації
6. Ступені вільності, аналіз дисперсій.
7. Перевірка простої регресійної моделі на адекватність.
8. F - критерій Фішера
Задача
Література
1. Основні параметри проведення економетричного аналізу
Багато явищ у природі і суспільстві взаємозалежні. Якщо узимку багато снігу - навесні чекай повеней. Якщо погана екологія - це до хвороб. Якщо перед курортний сезон - росте попит (і ціни) на купальники. Практично будь-яке явище зв'язане з багатьма факторами (причинами), що приведе до складності і неоднозначності аналізу.
Серед різних типів зв'язку нас буде цікавити так називаний статистичний (стохастичний) зв'язок між масовими явищами. Коли досліджується вплив якогось фактора на цікавлячий нас результат, то говорять про причинно-наслідковий зв'язок між фактором Х і результатом Y. Статистика успадковує з цього зв'язку лише термінологію (фактор і результат), суть же статистичного зв'язку принципово відрізняється від причинно-наслідкового.
Розрізняють функціональний (детерминированний) і статистичний зв'язок. Під функціональним зв'язком розуміють залежність у = у(х) при якому кожному значенню аргументу х (фактора) ставиться у відповідність відоме (детерминироване) значення функції (мал. 1, а). Наприклад, закон Ньютона а = F/m (прискорення тіла а прямо пропорціонально силі F і обратнопропорціонально масі m) являє приклад прямої функціональної залежності між а (функцією) і F (аргументом). Зв'язок називають статистичним, якщо для кожного фіксованого значення х€X існує безліч можливих значень показника Y (мал. 1, б). Звичайно Y розглядається як випадкова величина, що має для кожного фіксованого значення х
0
розподіл умовних імовірностей P{Y= yk
|х
0
} чи щільність імовірності р(у|х0
). Якщо при зміні фактора х істотно змінюється і розподіл показника Y, то говорять про наявність істотного статистичного зв'язку між Х і Y. Про такий зв'язок можна в першому наближенні судити вже по зміні середнього значення показника Y - умовного математичного чекання: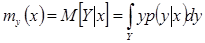
Реклама

який тут записано для безупинної випадкової величини Y. Умовне математичне чекання M[Y | х] має сенс середнього значення показника Y при деякім відомому значенні фактора х. Цю залежність як функцію аргументу х
у теорії ймовірностей називають лінією регресії. Вона зображена як приклад на мал. 1,6.

Рис. 1.
У літературі по эконометрике немає однозначної термінології у відношенні X і Y. Зокрема, зустрічаються такі пари термінів, як регрессор (X) і регрессант (Y), що пояснює X (незалежна, екзогенна) і що пояснюється Y (залежна, ендогенна) перемінні й ін. Ми будемо дотримувати найбільш розповсюджених і лаконічних термінів: Х- фактор, Y- показник.
Відмінність статистичного зв'язку від причинно-наслідкової полягає в наступному. У теорії імовірностей (і математичній статистиці) для випадкових величин X і Y доведено, що якщо Y залежить від X, те і X залежить від Y. Скажемо, пропозиція Y залежить від попиту X, споживання морозива - від сезона. Це причинно-наслідкові залежності. Навряд чи можна погодиться, що сезон залежить від споживання морозива. Це буде правдою лише наполовину (з погляду причинно-наслідкового зв'язку). Тим часом сезон (статистично) залежить від рівня споживання морозива. Інакше кажучи, за результатом ми можемо судити про причину на основі статистичного досвіду. Якщо хладо-комбинат працює на граничних потужностях, напевно в розпалі літо. Якщо случився неврожай, то була посуха. Якщо літак розбився, комісія досліджує найбільш ймовірні причини катастрофи (на основі наблюдання і статистики) і зробить висновок.
У эконометриці (як і у статистикі) приходиться мати справу з вибірками обмеженого обсягу п
і замість імовірностей (плотностей імовірності) оперувати їх оцінками -частостями (чи відносними частотами). При цьому на основі вибірки можна побудувати апроксимацію (наближену функцію) лінії регресії. Такі лінії регресії описують функціональну складову математичних моделей статистичної залежності між фактором X і показником Y. Вони використовуються для оцінок і прогнозів в економічних і фінансових розрахунках, при плануванні бізнесу і розподілі інвестиційних потоків.
Часткою случаємо статистичного зв'язку є кореляційний зв'язок. Вона оцінюється коефіцієнтом кореляції, що характеризує ступінь лінійного статистичного зв'язку.
При вивченні взаємозв'язків між економічними явищами зважуються наступні задачі:
Реклама

- вибір типу моделі регресії;
- побудова моделі обраного типу (визначення параметрів моделі);
- прогнозування середнього значення показника для заданого значення фактора;
- оцінка помилок моделювання і прогнозу;
- оцінка впливу факторних ознак на значення показника (імітаційне моделювання);
- дисперсійно-кореляційний аналіз моделі і встановлення істотності (значимості) статистичного зв'язку між фактором і показником;
- оцінка адекватності результатів моделювання явищам, що спостерігаються.
Дані є вихідним матеріалом при побудові моделей. Показники в послідовно узяті моменти часу називають тимчасовими рядами (рядами динаміки). Це можуть бути показники інфляції, курсів валют, цін і т.д. через визначені інтервали часу. Такі дані часто є коррелированными тим більше, чим менше тимчасові інтервали. Температура на вулиці через годину менше зміниться (більше коррелирована з попередньої), чим через день чи місяць.
Дані, що не є тимчасовими, прийнято називати просторовими. Звичайно вони збираються з рознесених просторово точок і є крапками вибірки обсягу п
і розмірності до к
= т
+ 1 (число к
на 1 більше числа факторів т
). Вимоги репрезентативності вибірки припускають випадковість добору і достатній обсяг вибірки з виконанням умови п
>> к
. Це завжди варто пам'ятати при побудові моделей, І інакше можливе одержання зміщених оцінок. Про середній курс долара в місті, наприклад, не можна судити по обмінних пунктах у районі міського вокзалу. Прикладами просторових даних є дані по виробництву, продажу, споживанню, цінам у різних точках міста (країни) у визначений момент часу. На макроекономічному рівні це можуть бути дані по розподілі трудових і матеріальних ресурсів по регіонах країни.
2. Метод найменших квадратів
Модель парної лінійної регресії є власне кажучи лінійною апроксимацією (наближенням) реальної лінії регресії у(х) як умовного математичного чекання випадкового показника Y. Специфікація моделі може бути записана як: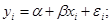 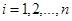
Тут передбачається, що α і β - точні значення параметрів моделі; хі
- відомі вибіркові значення фактора; εі
- випадкові помилки моделі в і-й точці з імовірностними властивостями генеральної сукупності. Очевидно, випадкові значення показника yі
при цих умовах мають той же розподіл, що і помилки εі
(зі зсувом 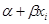 ). Для спрощення запису ми позначаємо параметри моделі β0
=α, β1
=β. ). Для спрощення запису ми позначаємо параметри моделі β0
=α, β1
=β.
Оскільки на практиці замість генеральної сукупності приходиться мати справу з вибіркою обмеженого обсягу п
, вдається одержати засноване на вибіркових даних наближення:yi
=
a
+
bxi
+
ei
;
i
=1,2,…,
n
де параметри а і b моделі є лише деякими оцінками точних значень параметрів α і β. Теоретична залежність (ТЗ) двомірної МЛР (чи апроксимуюча функція f(X, β)) описується рівнянням прямої лінії: у = а+ bх.
Тут множник b називається коефіцієнтом регресії, а величина а - постійної складової лінії регресії.
Коефіцієнт регресії 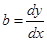 характеризує збільшення показника при збільшенні фактора на 1 (dx = 1) і має відповідну розмірність. При зміні постійна складової а
пряма коллинеарно переміщається, а її розмірність збігається з розмірністю у. Пряма лінія у = а+ bх повинна проходити так, щоб стосовно точок вибірки обсягу п характеризує збільшення показника при збільшенні фактора на 1 (dx = 1) і має відповідну розмірність. При зміні постійна складової а
пряма коллинеарно переміщається, а її розмірність збігається з розмірністю у. Пряма лінія у = а+ bх повинна проходити так, щоб стосовно точок вибірки обсягу п
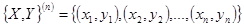
забезпечити мінімальну середньоквадратичну помилку (СКП). Метод визначення параметрів моделі з мінімальної СКП називається методом найменших квадратів (МНК чи LSM- Least Squares Method в англомовній літературі).
Безліч точок вибірки 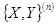 на графіку рис. 1 у декартовых координатах х,у називають діаграмою розсіювання. на графіку рис. 1 у декартовых координатах х,у називають діаграмою розсіювання.
Для кожної крапки вибірки помилка результату вибірки (залишок регресії) дорівнюєеі
= уі
- уі
*
= уі
– а -
b
і
Ця помилка для і-й точки представлена на рис. 2.
Рис. 2.
Середній квадрат помилок апроксимації пропорційний сумі квадратів помилок: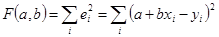
Цю згортку називають функціоналом помилок. Визначимо оцінки а і b параметрів моделі за допомогою методу найменших квадратів (МНК). Його суть складається в мінімізації функціонала помилок при варіаціях параметрів моделі. Тому що а і b поки невідомі, замінимо їх перемінними а→α і b→β. Варіації перемінних α і β дозволять знайти оптимальні за заданим критерієм оцінки.
Функціонал помилок як функція α і β має вид:
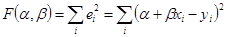
У тривимірному просторі з координатами підстави α і βця функція являє собою поверхню з параболічними перетинами, мал. 3. Абсолютний мінімум параболічної функції при варіації лепеха має місце в точці нульових часток похідних. Для точки абсолютного мінімуму функції 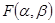 одержимо систему двох лінійних відносно α і β рівнянь: одержимо систему двох лінійних відносно α і β рівнянь:
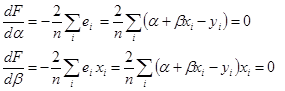
Рішення цієї системи лінійних відносно α і β рівнянь дає оцінки МНК а і b значень параметрів моделі. На мал. 3 вони показані як проекції крапки мінімуму функцій F(a, b) на координатні осі а і bпідстави. Ці оцінки можуть тим більше відрізнятися від точних значень а і b в специфікації моделі, чим менше обсяг вибірки п
у порівнянні обсягом генеральної сукупності N. Абсолютна точність оцінок досягається в граничному випадку (п→N, при цьому а→α і b→β). Відзначимо, що за умовами аналізу специфікації моделі а і b- фіксовані параметри, але у функції ми їх розглядаємо варїруємими перемінними для перебування оптимальних вибіркових оцінок а і b.

Рис. 3
З попереднього рівняння , зокрема , випливає, що сумарна помилка апроксимації (сума залишків регресії)
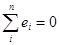
Крім того, це рівняння дає співвідношення між вибірковими середніми арифметичними значеннями фактора X
і показника у
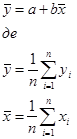
Звідси ясно, що теоретична залежність ТЗ моделі лінійної регресії у = а+ bх, побудована згідно МНК, проходить через точку середніх значень (х,у).
Рішення системи рівнянь щодо α і βмає вид:
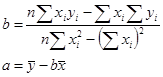
Для різних вибірок параметри а і b можуть приймати різні значення, що концентруються поблизу точних значень α і β. Тому при статистичному аналізі оцінки параметрів a і b розглядаються як випадкові величини При цьому обмовляється, за яким критерієм оптимізації отримана дана оцінка. Ми, як відзначалося, користаємося оцінками МНК із найменшим значенням функціонала помилок.
Наочне представлення вирішеної задачі побудови моделі парної лінійної регресії дає графік моделі на тілі діаграми розсіювання.
3. Оцінка параметрів лінійної регресії за методом найменших квадратів
Як відзначалося, по обмеженим даним вибірки обсягу п
можна побудувати модель лише з деякою точністю. Її параметри а і b є оцінками щирих значень α і β які визначаються генеральною сукупністю обсягу N >> п
. Останньої приписуються імовірностні властивості з застосуванням аксіом теорії імовірності, визначень випадкової величини, імовірності, щільності імовірності, оператора усереднення і т.д. У рамках властивостей генеральної сукупності обсягу N розглядається специфікація моделі лінійної регресії
у якій α, β, хі
- детерміновані (фіксовані чи відомі) величини, а значення показника yі
і помилки моделі εі
- випадкові величини (ВВ) із заданим розподілом (наприклад, щільності імовірності). Часто уі
, εі
вважаються нормальними ВВ (НВВ), тоді модель називають нормальною. Обмежені дані вибірки обсягу п
<< N дозволяють замість точної моделі з параметрами α і βпобудувати наближену модель:
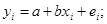
Тут еі
- залишки регресії, вероятностные властивості яких вважаються аналогічними помилкам 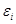 , а а,
b
- деякі оцінки (наближені значення) параметрів моделі. , а а,
b
- деякі оцінки (наближені значення) параметрів моделі.
Ми будемо оцінювати дисперсії і середньоквадратичні помилки (СКП) для оцінок параметрів моделі і величини ε:
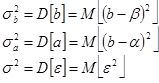
де М[X], D[X] - математичне чекання і дисперсія випадкової величини X.
Для безупинної випадкової величини X із щільністю імовірності р(х) вони визначаються як:
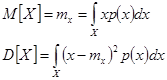
Отже, для точного визначення того чи іншого параметра випадкової величини досить знати (чи задати) її розподіл щільності імовірності.
4. Властивості простої лінійної регресії
Якщо дано сукупність показників y, що залежать від факторів х, то постає завдання знайти таку економетричну модель, яка б найкраще описувала існуючу залежність. Одним з методів є лінійна регресія. Лінійна регресія передбачає побудову такої прямої лінії, при якій значення показників, що лежать на ній будуть максимально наближені до фактичних, і продовжуючи цю пряму одержуємо значення прогнозу. Процес продовження прямої називається екстраполяцією. Відповідно до цього постає задача визначити цю пряму, тобто рівняння цієї прямої. В загальному вигляді рівняння прямої виглядає:
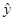 =а+bх, =а+bх,
де - вирівняне значення у для відповідного значення х.
Константи а і b - константи, які передбачають зменшення суми квадратів відхилень між фактичним значенням у і вирівняним значенням .
S(у
- )2
® min
Коефіцієнт а характеризує точку перетину прямої регресії з лінією координат.
Коефіцієнт b характеризує кут нахилу цієї прямої до осі абсцис, а також на яку величину зміниться при зміні х на одиницю.
Коефіцієнти а і b знаходять із системи рівнянь, що випливає з формули.
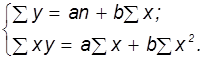
Знайшовши значення параметрів розраховують ряд вирівняних значень для відповідних факторів і проводять дослідження знайденої економетричної моделі.
5. Коефіцієнти кореляції та детермінації
Кореляційний аналіз має на меті встановлення істотності (статистичної значимості) кореляційного зв'язку між фактором і результатом (показником). Основним і досить зручним параметром для цього є коефіцієнт детермінації R2
.
Розкладемо вибіркову дисперсію показника Sу
2
на дві некорельовані складові:

Остання сума в цьому розкладанні дорівнює 0 і, отже, випадкові величини еі
, і 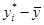 некорельовані. Тому некорельовані. Тому

Таким чином, загальна дисперсія показника TSS (total sum of squares - загальна сума квадратів) складається з двох складових, що характеризують різні властивості кореляційного полючи даних. Складова ESS (error sum of squares - сума квадратів помилок) характеризує ступінь розкиду точок у, щодо теоретичної прямої і, отже, виражає властивість випадковості вибіркової сукупності. Складова RSS (regressіon sum of squares - сума квадратів регресії), навпроти, пропорційна квадрату різниці між лінією регресії і постійної середній, тобто характеризує властивість закономірності зв'язку. Її частка в загальній дисперсії, обумовлена як коефіцієнт детермінації
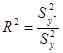
є параметром, що визначає значимість лінійного статистичного зв'язку між фактором і показником. З цього випливає, що
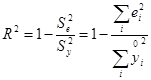
Ця формула зручна при розрахунках, якщо за результатами моделювання обчислені залишки регресії еі
, і їхні квадрати.
Коефіцієнт детермінації можна також виразити через коефіцієнт регресії b
, якщо врахувати, що зведення в квадрат і усереднення дає
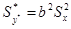
Тоді
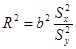
або
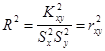
Таким чином, коефіцієнт детермінації дорівнює квадрату коефіцієнта кореляції

Коефіцієнт кореляції можна виразити через коефіцієнт регресії як:
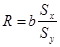
Таким чином, знак коефіцієнта кореляції збігається зі знаком коефіцієнта регресії b
. Останній, однак, відрізняється тим, що може мати розмірність [у/х], тоді як коефіцієнт кореляції R- величина безрозмірна.
Коефіцієнт кореляції характеризує ступінь лінійного статистичного зв'язку. Він приймає значення в інтервалі
- 1 < R < 1.
У крайніх точках R = ± 1 статистичний зв'язок стає лінійним функціональним, позитивним (R = 1) чи негативним (R = - 1). В області R є (0, 1] регресія позитивна (b
> 0), а в області rху
є [- 1, 0) - негативна (b
< 0). При R = 0 говорять, що величини Х і Y некорельовані. У теорії імовірності доводиться, що незалежні випадкові величини завжди некорельовані (зворотне твердження вірне лише в окремих випадках, наприклад, для нормальних випадкових величин X і Y). Звичайно думають, що при | R | < 0,3 кореляційний зв'язок слабкий, при | R | - (0,3..0,7) - середній, а при | R | > 0,7 - сильний.
Коефіцієнт кореляції є більш інформативним параметром у порівнянні з коефіцієнтом детермінації, тому що його знак дозволяє судити про позитивну чи негативну кореляцію (і, тим самим, регресії). Відповідно область значень коефіцієнта детермінації
0≤R2
≤1.
Важливою властивістю коефіцієнтів кореляції і детермінації є їхня незалежність від зміни розмірності величин X і (чи) Y, а також від їхньої пропорційної зміни. Скажемо, ми вивчаємо залежність товарообігу Y торгового підприємства від торгової площі X [м2
]. Коефіцієнт регресії b
при цьому виміряється в ден. од./м2
, наприклад, грн./м2
, чи євро/м2
. Перехід від однієї одиниці до іншої супроводжується пропорційною зміною коефіцієнта регресії b
(а також і постійної складовий а, якщо змінюється показник Y). Разом з тим на коефіцієнти R2
і R такі перерахування не впливають, вони є безрозмірними відносними показниками (коефіцієнт R2
можна, наприклад, виразити в %).
6. Ступені вільності, аналіз дисперсій
Завжди варто пам'ятати, що однієї з основних задач моделювання є в остаточному підсумку одержати результат прогнозу показника Y для якогось цікавлячого економіста значення фактора хр
(у точці прогнозу). Скажемо, при побудові моделі сімейних витрат на харчування в залежності від числа членів родини у вибірку ввійшли родини до 5 чоловік, а ми хочемо спрогнозувати ці витрати для родини з 7 чоловік (хр
= 7). Середнє значення прогнозу показника в точці прогнозу хр
легко визначається з рівняння моделі:
М[ур
] = М[а + b
хр
+ εp
] = а + b
хр = ур
.
Таким чином, середнє значення прогнозу лежить на прямій, що визначає теоретичну залежність моделі.
Після перебування середнього значення прогнозу завжди виникає традиційне питання: яка точність прогнозу, яка ступінь його надійності. Звичайно для цього залучаються интервальні оцінки помилок моделювання (довірчий інтервал разом з довірчою імовірністю). Для кожного значення прогнозу помилки виявляються різними. Це природно, якщо згадати, що помилки, наприклад, у прогнозі погоди ростуть зі збільшенням часу до точки прогнозу (прогноз на завтра більш точний, чим на тиждень уперед).
Визначимо дисперсію і середньоквадратичну помилку прогнозу показника ур
. У специфікації моделі для відхилень замінимо точку спостереження х, на прогнозну крапку хр
:

Вхідні в останнє вираження випадкові величини некорельовані, тому дисперсія показника складається з дисперсій доданків і дорівнює
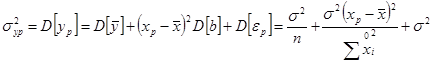
Як і раніше, замість точного значення дисперсії помилок σ2
(яке невідомо в рамках вибіркового спостереження) варто підставити її оцінку, тоді стандартна помилка прогнозу показника стає рівною
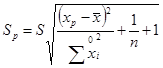
Ця середньоквадратична помилка (чи стандартна помилка), як і випливало очікувати, пропорційна стандартній помилці регресії S і росте зі збільшенням різниці між прогнозним і середнім значеннями фактора 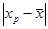 . Гранична помилка для визначення довірчого інтервалу дорівнює . Гранична помилка для визначення довірчого інтервалу дорівнює
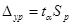
а границі довірчого інтервалу прогнозованого показника 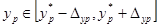 розширюються пропорційно квантилю tα
(n - 2) розподілу Стьюдента з (п
- 2) ступенями вільності і рівнем значимості α. розширюються пропорційно квантилю tα
(n - 2) розподілу Стьюдента з (п
- 2) ступенями вільності і рівнем значимості α.
Очевидно, з видаленням крапки прогнозного фактора хр від середнього зона довірчого інтервалу розширюється (рис.4). Це відповідає інтуїтивному сприйняттю помилок прогнозу, що звичайно зростають при видаленні від середніх показників. Максимальна точність прогнозу досягається в крапці х – х*
.

Рис. 4
7. Перевірка простої регресійної моделі на адекватність
Для оцінки знайденої економетричної моделі на адекватність порівнюють розрахункове значення критерію Фішера із табличним.
Розрахункове значення критерію Фішера знаходиться за формулою:
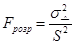 , ,
де 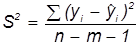 , ,
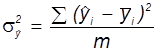 , ,
n – число спостережень,
m – число включених у регресію факторів, які чинять суттєвий вплив на показник.
Для даної надійної ймовірності р (а=1-р рівня значущості) і числа ступенів вільності k1
=m, k2
=n-m-1 знаходиться табличне значення F(a, k1
, k2
). Отримане розрахункове значення порівнюється з табличним. При цьому, якщо Fроз
> F(a, k1
, k2
), то з надійністю р = 1-а можна вважати, що розглянута економетрична модель адекватна вихідним даним. У протилежному випадку з надійністю р розглянуту лінійну регресію не можна вважати адекватною.
8.
F
- критерій Фішера
Теорія статистичної перевірки гіпотез у додатку до регресійного аналізу розроблена англійським математиком Фишером.
Нехай Н0
- гіпотеза про те, що статистичного зв'язку між X і Y немає (чи вона не істотна, статистично не значима), а Н1
- гіпотеза про те, що зв'язок є (чи вона істотна, статистично значима). Припустимо, що виконується основна гіпотеза про відсутність зв'язку. У цьому випадку щире значення коефіцієнта регресії β = 0 і F-статистика стає рівною
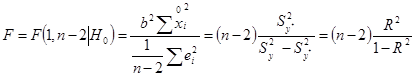
Очевидно, що з ростом значення F (чи коефіцієнта детермінації R2
) збільшується ступінь статистичного зв'язку між фактором і показником (тому що вона прямо пропорційна коефіцієнту регресії і назад пропорційна випадковим помилкам моделі). Задамо імовірність:
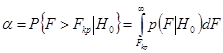
як імовірність того, що при перевищенні розрахунковим значенням F (2.47) деякого критичного значення FKp
гіпотеза про відсутність зв'язку Н0
вірна. Очевидно, з імовірністю (1 - α) вона при тім же умові невірна. Закритичну область F > FKp
будемо вважати областю дії гіпотези Н1
, а докритичну F < FKp
- областю дії гіпотези Н0
. Тоді імовірність є імовірність помилки першого роду: α=P(H0
|H1
), тобто імовірність прийняття основної гіпотези H0
, тоді як насправді справедлива альтернативна гіпотеза Н1
. Графічно ця імовірність визначається як площа під щільністю імовірності p(F) при F > Fk
p
. Імовірність α (її іноді називають коефіцієнтом значимості) звичайно вибирають малої (рівної 0,05 чи 0,01), після чого для заданих значень імовірності а розраховуються чисельно критичні значення FKp
відповідно з урахуванням залежності. Ці значення табулюються, тобто заносяться в таблиці критичних коефіцієнтів чи детермінації критичних значень F-статистики.

Рис. 5
Визначення значимості статистичного зв'язку для моделі лінійної регресії здійснюється по наступної методики. На основі вибіркових даних будується модель і визначається коефіцієнт детермінації R2
, що потім порівнюється з критичним коефіцієнтом детермінації R2
Kp
. Останній знаходять по таблиці критичних значень коефіцієнта детермінації. Вхідними даними таблиці є коефіцієнт значимості α = 0,05 (чи 0,01), номер стовпця таблиці к1
= п
- 1, номер рядка к2=
п
-к, де к - число параметрів моделі (для двовимірної моделі до = 2 і використовується перший стовпчик таблиці). Нагадаємо, що параметр к1
- це число ступенів волі чисельника F-статистики, к2
- число ступенів волі знаменника F-статистики. Коефіцієнт детермінації можна перерахувати в F-статистику (критерій Фишера), у загальному випадку по формулі:
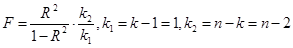
Розраховане для моделі значення F порівнюється з критичним. При F > FKp
(чи R2
> R2
кр
) робиться висновок, що з імовірністю, рівної (1 - α), зв'язок істотний (статистично значимий). У противному випадку говорять, що лінійний зв'язок незначимий (чи більш загальний статистичний зв'язок не встановлений).
Задача
Побудувати економетричну модель за наведеними даними. Оцінити параметри моделі. Зробити економічні висновки. Оцінити тісноту та значимість зв’язку між змінними.
| Номер підприємства |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| Випуск продукції, тис. шт. |
9,33 |
8,31 |
8,25 |
7,50 |
6,90 |
6,15 |
5,66 |
| Витрати матеріалу на од., г. од. |
19,66 |
20,53 |
21,31 |
22,59 |
23,27 |
24,44 |
25,85 |
Рішення
:
| Номер підприємства |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
Σ |
| Випуск продукції, тис. шт. х |
9,33 |
8,31 |
8,25 |
7,50 |
6,90 |
6,15 |
5,66 |
52,10 |
| Витрати матеріалу на од., г. од. у |
19,66 |
20,53 |
21,31 |
22,59 |
23,27 |
24,44 |
25,85 |
157,65 |
 |
87,0489 |
69,0561 |
68,0625 |
56,25 |
47,61 |
37,8225 |
32,0356 |
397,8856 |
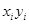 |
183,4278 |
170,6043 |
175,8075 |
169,425 |
160,563 |
150,306 |
146,311 |
1156,4446 |
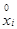 |
1,8871 |
0,8671 |
0,8071 |
0,0571 |
-0,5429 |
-1,2929 |
-1,7829 |
0 |
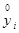 |
-2,8614 |
-1,9914 |
-1,2114 |
0,0686 |
0,7486 |
1,9186 |
3,3286 |
0 |
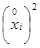 |
3,5611 |
0,7519 |
0,6514 |
0,0033 |
0,2947 |
1,6716 |
3,1787 |
10,1127 |
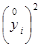 |
8,1876 |
3,9657 |
1,4674 |
0,0047 |
0,5604 |
3,681 |
11,0796 |
28,9464 |
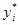 |
19,3639 |
21,0706 |
21,171 |
22,4259 |
23,4298 |
24,6847 |
25,5046 |
157,6505 |
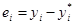 |
0,2961 |
-0,5406 |
0,139 |
0,1641 |
-0,1598 |
-0,2447 |
0,3454 |
0 |
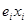 |
2,7626 |
-4,4924 |
1,1468 |
1,2308 |
-1,1026 |
-1,5049 |
1,955 |
0 |
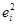 |
0,0877 |
0,2922 |
0,0193 |
0,0269 |
0,0255 |
0,0599 |
0,1193 |
0,6308 |
Середні арифметичні показника і фактора:

Рівняння моделі лінійної регресії має вигляд: у = а+
b
х
.
Знайдемо коефіцієнти а і b:
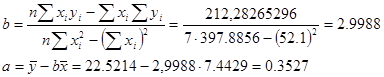
Таким чином, рівняння моделі лінійної регресії має вигляд:
у
=0,3527+2,9988×х
Коефіцієнт кореляції характеризує ступень лінійного статистичного зв’язку:
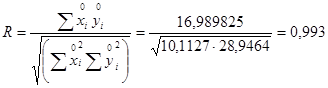
Тобто зв'язок між випуском продукції та витратами матеріалів на одиницю дуже щільний.
Маємо визначені середні значення величин - Xcp
= 7,4429, Ycp
= 22,5214, слідові можна визначити середній коефіцієнт еластичності для цієї моделі:
A
=
b
*
Xcp
/
Ycp
= 2,9988*7,4429/22,5214 = 0,991,
тобто при зростанні показника 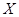 (випуск продукції) на 1% показник Y (витрати матеріалів на одиницю продукції) зростає на 0,99%. (випуск продукції) на 1% показник Y (витрати матеріалів на одиницю продукції) зростає на 0,99%.
Можна зробити попередні висновки:
В результаті розрахунків отримано модель у^
= 0,3527+2,9988×х.
Аналізуючи параметри моделі можливо зробити наступні висновки, що оскільки коефіцієнт регресії додатний a1
=2,9988, то це свідчить про те, що напрямок зв’язку між X і Y прямий (це підтверджує й графік моделі, рис.1), тобто при зростанні Х значення Y теж будуть збільшуватись. При збільшенні Х на 1 значення Y зросте на 0,99.

Рис.1.
Коефіцієнт еластичності свідчить, на скільки відсотків гранично змінюється залежна змінна, якщо відповідна незалежна змінна змінюється на 1%, а інші - постійні.
Коефіцієнт детермінації визначає значимість лінійного статистичного зв’язку між фактором та показником:
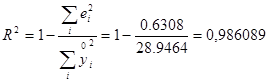 , чи , чи
R2
= 0,9932
= 0,986
По вихідним даним к1
=к-1=2-1=1 і к2
=п
-к=7-2=5 знаходимо критичне значення коефіцієнта детермінації: R2
кр
=0,569.
Так як R2
>R2
кр
, то можна зробити висновок, що зв'язок між випуском продукції та витратами матеріалів на одиницю статистично значимий з імовірністю 0,95.
Визначимо спостережуване значення критерію Фишера
F = R2
*(n - 2)/(1 – R2
) = 0,986*(5)/(1 – 0,986) = 352,14.
Табличне значення критерію при надійності Р=0,95 (a = 0,05) і степенях свободи k1
= 1, k2
= 7 – 2 = 5 дорівнює 5,59, оскільки спостережуване значення більше критичного, то лінійна модель є адекватною.
Використовуючи t-статистику, з надійністю Р=0,95 оцінимо значущість коефіцієнта кореляції. Обчислимо спостережуване значення t-статистики
t = |R|*√(n - 2)/(1 – R2
) = 0,993*√(7 - 2)/(1 – 0,986) = 18,766.
Табличне значення 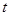 -критерію при -критерію при 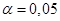 і кількості ступенів свободи n – 2 = 5, t = 2,57. Оскільки розрахункове значення -критерію більше за табличне, то лінійний коефіцієнт кореляції є статистично значущим. і кількості ступенів свободи n – 2 = 5, t = 2,57. Оскільки розрахункове значення -критерію більше за табличне, то лінійний коефіцієнт кореляції є статистично значущим.
Стандартні похибки оцінок параметрів з урахуванням дисперсії залишків:
Обчислимо t-статистики:
t1
= b/ S(b) = 2,9988/0,1454 = 20,623; t2
= a/ S(a) = 0,3527/2,868 = 0,123.
Оскільки отримані значення більше табличного тільки для коефіцієнту b, то параметр «випуск продукції»є значимим з надійністю Р=0,95.
Висновки
1.В результаті розрахунків отримано модель 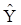 = 55,384 + 0,9617 ×Х. у
=0,3527+2,9988×х
Аналізуючи параметри моделі можливо зробити наступні висновки, що оскільки коефіцієнт регресії додатний a1
=2,9988, то це свідчить про те, що напрямок зв’язку між X і Y прямий (це підтверджує й графік моделі, рис.1), тобто при зростанні Х значення Y теж будуть збільшуватись. При збільшенні Х на 1 значення Y зросте на 0,99. = 55,384 + 0,9617 ×Х. у
=0,3527+2,9988×х
Аналізуючи параметри моделі можливо зробити наступні висновки, що оскільки коефіцієнт регресії додатний a1
=2,9988, то це свідчить про те, що напрямок зв’язку між X і Y прямий (це підтверджує й графік моделі, рис.1), тобто при зростанні Х значення Y теж будуть збільшуватись. При збільшенні Х на 1 значення Y зросте на 0,99.
2. Лінійний коефіцієнт кореляції 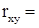 0,993 і коефіцієнт детермінації R2
=0,986. Значення коефіцієнту кореляції свідчить про те, що між факторами існує дуже сильний прямий зв’язок. Значення коефіцієнту детермінації показує, що на 98,6% варіація Y (витрати матеріалу на одиницю) залежить від X (випуск продукції) і на 1,4% від факторів, які не увійшли у модель. 0,993 і коефіцієнт детермінації R2
=0,986. Значення коефіцієнту кореляції свідчить про те, що між факторами існує дуже сильний прямий зв’язок. Значення коефіцієнту детермінації показує, що на 98,6% варіація Y (витрати матеріалу на одиницю) залежить від X (випуск продукції) і на 1,4% від факторів, які не увійшли у модель.
3. Розрахунки за критерієм Фішера F=352,14 і Fкр.
=5,59 підтвердили адекватність моделі даним задачі.
4. За критерієм Стьюдента, була проведена перевірка значимості параметрів моделі з надійністю 95%. Оскільки отримані значення більше табличного тільки для коефіцієнту b, то параметр «випуск продукції»є значимим з надійністю Р=0,95, то можна зробити висновок, що отриманий параметр випуск продукції є значимими і для генеральної сукупності цей параметри рівняння лінії регресії відрізняється від 0.
5. За критерієм Стьюдента була проведена перевірка значимості лінійного коефіцієнта кореляції з надійністю 95%. Оскільки значення tr
– статистики більші ніж критичне значення, то можна зробити висновок, що в генеральній сукупності між факторами існує зв’язок, тобто ρ≠0 і коефіцієнт регресії статистично значущий, слідові модель є адекватною.
Література
1. Абакумов С.А. Економетрика К.: 2004
2. Висловский В.Р. Эконометрия М.: 2005
3. Колесников Н.А. Математические методы в экономике М.: 2006
4. Породін М.О. Економетрика Харків 2007
|