Контрольная работа
По предмету: Эконометрическое моделирование
Некоторые вопросы эконометрического моделирования
Вопрос 1. Назовите некоторые основные проблемы эконометрического моделирования
Рассмотрим некоторые основные проблемы эконометрического моделирования:
Постоянство механизмов:
Одно из условий, на которое опирается эконометрическое моделирование, состоит в том, что функциональное соотношение не меняется в течение рассматриваемого периода. Однако это условие часто нереалистично, особенно в случае, когда приходится иметь дело с переходной экономикой. Это обычная проблема, с которой экономист сталкивается при исследовании экономических процессов с изменчивой структурой. Как бы то ни было, приходится делать предположение о неизменности формы модели, иначе моделирование не было бы возможно.
Один из возможных способов учета структурных сдвигов состоит в использовании различного рода сконструированных
переменных, таких как, фиктивные переменные и тренды. Включение в эконометрическую модель трендов позволяет учитывать изменения во всех коэффициентах регрессионного уравнения: свободном члене и коэффициентах при «экономических» переменных. Фиктивные переменные (принимающие только два значения — 0 и 1) позволяют учесть резкие структурные скачки.
Кроме того, использование фиктивных переменных и гармонических трендов (синусов и косинусов) позволяет учесть в модели сезонные колебания. Если предположить, что сезонность имеет детерминированный характер, то ее можно смоделировать, добавив в уравнение регрессии компоненту следующего вида:
1
M
1
+ ... + 12
M
12
.
Здесь M
1
, ..., M
12
— сезонные месячные переменные.
Все же эти методы не позволяют адекватно учесть изменения, если неизвестен их характер или момент изменения (в случае скачка). Особенно большие проблемы создают структурные сдвиги для прогнозирования. Если резкое изменение в параметрах экономического процесса произошло в течение исследуемого периода, то это изменение можно заметить и учесть в модели. Если же неожиданное изменение произойдет после исследуемого периода, то сделанные прогнозы окажутся неверными.
Недостаточный набор данных:
Имеющихся данных может быть недостаточно для того, чтобы определить функциональную связь между переменными, либо они недостаточно варьируются, чтобы можно было отличить влияние одного фактора от влияния другого. Последняя проблема получила в эконометрическом моделировании название «мультиколлинеарности». В отличие от экспериментальных наук, у отдельного исследователя, изучающего экономические процессы, как правило, нет возможности сколько-нибудь заметно на них повлиять. Обычно за него это делает правительство. Чтобы восполнить недостаток данных, исследователю приходится делать некоторые априорные допущения, зачастую недостаточно обоснованные.
Реклама

Как правило, функциональная форма модели заранее неизвестна. В этом случае хорошим выходом из положения было бы использование непараметрических методов оценивания. Однако для применения таких методов необходим довольно значительный набор данных. Поэтому на практике, как правило, предполагают, что зависимость между двумя переменными линейна. Часто линейная зависимость дает хорошую аппроксимацию гладкой зависимости в некоторой небольшой окрестности, но вообще говоря, нет никакой гарантии, что «истинная» зависимость не окажется сильно нелинейной как раз в том интервале, к которому относятся данные.
При применении статистических методов следует помнить, что постулируемые свойства как правило носят асимптотический характер, то есть проявляются в пределе, при стремлении количества наблюдений к бесконечности. В частности, если в линейной регрессии в качестве регрессоров используются лаги зависимой переменной, то, даже если выполнены стандартные предположения регрессионного анализа, полученные оценки будут состоятельными, но смещенными.
Проблема ложной регрессии
:
Для того, чтобы получить высокий коэффициент детерминации, достаточно, чтобы в зависимой переменной и в регрессоре имелся тренд и динамика трендов до некоторой степени совпала. Коэффициент детерминации, как правило, бывает, высок в регрессии одного растущего показателя по другому растущему показателю.
С другой стороны, коэффициент детерминации, как правило, бывает низким в регрессии одного процесса типа «белый шум» по другому такому же процессу.
Двумя основными причинами наличия «тренда» во временных рядах являются
· детерминированная составляющая (тогда говорят о детерминированном тренде),
· нестационарность (тогда говорят о стохастическом тренде).
Наличие детерминированного тренда может приводить к появлению ложной регрессии.
Реклама

Пусть, например Yt
и Xt
порождаются процессами
Yt
= a
+ bt
+ t
, Xt
= c
+ dt
+ t
,
где t
, t
— независимые, одинаково распределенные ошибки. Регрессия Yt
по константе и Xt
может иметь высокий коэффициент детерминации и этот эффект только усиливается с ростом размера выборки. К счастью, с «детерминированным» вариантом ложной регрессии достаточно легко бороться. В рассматриваемом случае достаточно добавить в уравнение тренд в качестве регрессора, и эффект ложной регрессии исчезает.
Если существует стационарная линейная комбинация нестационарных случайных процессов, то эти процессы называют коинтегрированными. Коинтегрированность гарантирует (по крайней мере, асимптотически, то есть для больших выборок), что не возникнет ложная регрессия. Теория коинтеграции — быстро развивающийся раздел современной эконометрики.
Для оценивания моделей с нестационарными, но коинтегрированными переменными, вообще говоря, следует использовать специальные методы. К сожалению, методы оценивания коинтеграционных регрессий сложны с точки зрения реализации, и способы проверки их спецификации плохо разработаны. Поэтому, несмотря на указанные недостатки, обычный метод наименьших квадратов остается наиболее мощным инструментом эконометрики.
Вопрос 2. Как называется метод, который наиболее часто используется при оценке параметров линейной модели в эконометрике?
Метод, который наиболее часто используется при оценке параметров линейной модели в эконометрике называется методом наименьших квадратов.
Вопрос 3. Как называются показатели, которые характеризуют степень разброса случайной величины вокруг ее среднего значения?
Показатели, которые характеризуют степень разброса случайной величины вокруг ее среднего значения называются выборочной дисперсией и выборочной ковариацией.
Вопрос 4. Какой физический смысл несет коэффициент детерминации в эконометрической линейной модели связи двух переменных, таких как расходы и доходы, цена и спрос, число занятых и уровень безработицы и т.д.
Коэффициент детерминации изменяется в пределах от 0 до 1. Чем выше коэффициент детерминации в эконометрической линейной модели связи двух переменных, тем больше линейная связь (зависимость) между переменными. Т.е. если рассматривать эконометрические линейные модели связи двух переменных, таких как расходы и доходы, цена и спрос, число занятых и уровень безработицы и т.д., то приближение коэффициента детерминации к 1 говорит о наибольшей зависимости доходов от расходов, спроса от цены, уровень безработицы от числа занятых и т.д. И наоборот, чем ниже коэффициент детерминации, тем меньше связь между указанными переменными.
Вопрос 5. Что обозначает и как рассчитывается функция эластичности η(Х) в линейной эконометрической модели
Y
= ά +β
X
?
Функция эластичности рассчитывается следующим образом:
- найти процентное изменение У;
- найти процентное изменение Х;
- найти отношение процентного изменения У к процентному изменению Х;
- найти предел отношения процентного изменения У к процентному изменению Х, когда последнее стремится к нулю.
Значение функции эластичности равно угловому коэффициенту касательной к графику зависимости lnY от lnX.
Вопрос 6. Что мы подразумеваем под свойствами линейной модели
Yi
=λ+β
i
+ε
i
,
i
=1,…,
n
., если считаем, что ошибки ε1
,…,ε
n
?
Существует (теоретическая, объективная или в виде тенденции) линейная зависимость значений переменной у от значений переменной х с вполне определенными, хотя обычно и не известными исследователю, значениями параметров λ и β;
Эта линейная связь для реальных статистических данных не является строгой: наблюдаемые значения Yi
переменной У отклоняются от значений 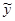 I
, указываемых моделью линейной связиI
= λ+βi
+εi
, i=1,…,n; I
, указываемых моделью линейной связиI
= λ+βi
+εi
, i=1,…,n;
При заданных (известных) значениях хi
конкретные значения отклонений εi
=уi
-I
, i=1,…,n, не могут быть точно предсказаны до наблюдения значений уi
даже если значения параметров λ и β известны точно;
Для каждого z, -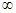 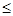 z, определена вероятность F(z) того, что наблюдаемое значение отклонения εi
не превзойдет z, причем эта вероятность не зависит от номера наблюдения; z, определена вероятность F(z) того, что наблюдаемое значение отклонения εi
не превзойдет z, причем эта вероятность не зависит от номера наблюдения;
Вероятность того, что наблюдаемое значение отклонения εi
в i-ом наблюдении не превзойдет z, не зависит от того, какие именно значения принимают отклонения в остальных n-1 наблюдениях.
Вопрос 7. В каких пределах будет заключена случайная ошибка с вероятностью 0,95, если она имеет Гауссовское распределение с параметром
σ
?
Если случайная ошибка имеет гауссовское распределение с параметром σ, то с вероятностью 0,95 ее значение будет заключено в пределах от -1,96σ до +1,96σ.
Вопрос 8. При каких значениях статистики Фишера нулевая гипотеза отвергается, и какова вероятность того, что мы отвергнем верную гипотезу?
Нулевая гипотеза отвергается, если выполняется неравенство
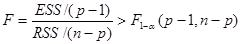
При этом вероятность ошибочного отвержения гипотезы Ho
равна 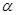
Вопрос 9. Какая из трех нулевых гипотез
Ho
: θ2
=-1,
HA
: θ2
>-1,
Ho
: θ2
≠-1 является простой, а какая сложной?
Ho
является сложной гипотезой, если гипотеза допускает более одного значения параметра, т.е. Ho
: θ2
=-1 является простой, а HA
: θ2
>-1 и Ho
: θ2
≠-1 – сложные гипотезы.
Вопрос 10. Что такое гетероскедастичность и автокоррелированность ошибок?
Гетероскедастичность ошибок – это неоднородность дисперсий ошибок. Этот вид нарушений стандартных предположений характерен для статистических данных, относящихся к одному моменту времени, но собранных по различным регионам, различным предприятиям, различным социальным группам. Автокоррелированность ошибок – это вид нарушений стандартных предположений, характерный для статистических данных, развернутых во времени.
|
