С.Ю. Матвеев, В.А. Курочкин, И.С. Щвецов, С.И. Кемайкин
В статье рассматривается технология хранения и обработки цифровых карт в современных геоинформационных системах. Обсуждаются проблемы, связанные с использованием существующих подходов при создании сложных информационных систем, оперирующих с картографической информацией.
Одновременно предлагаются принципиально новый подход организации цифровой карты, основанный на объединении топологической, объектной и атрибутивной информации, а также методика хранения полученной таким образом цифровой модели местности в реляционных базах данных.
Сегодня программное обеспечение выходит на совершенно новый этап своего развития. Если раньше мы относились к программе или программному комплексу как к средству решения какого-то конкретного, зачастую ограниченного набора задач, то сейчас можно расценивать программные средства как часть более сложного программно-аппаратного комплекса, служащего для решения достаточно широкого спектра отраслевых задач. Характерным примером этой эволюции являются офисные приложения. Если раньше «электронный офис» представлял собой лишь набор отдельных средств создания и качественного оформления текста, таблиц, ведения примитивных баз данных, то теперь любой комплекс, предназначенный для серьезной автоматизации делопроизводства, включает в себя набор интегрированных друг с другом продуктов, развитые средства обмена информацией, управления расписанием и многое другое. Заметно, что практически во все программные комплексы вливаются средства для совместного ведения проектов и совместной работы с документами.
Одновременно с этим процессом мы начинаем совершенно по-новому смотреть на ряд, казалось бы, привычных понятий. Для примера возьмем понятие документа. Сегодня документ может вообще не существовать на бумаге, и тем не менее он будет подписан, получит все визы согласования, поступит во все необходимые подразделения организации. Реализация нового подхода к документообороту невозможна без дополнения понятия «документ» новыми свойствами. Вне сомнения, подобная эволюция представляет собой совершенно естественный и неизбежный процесс развития компьютерной индустрии. Следствием этого процесса является то, что многие «классические» понятия и объекты, будучи переведены в электронную форму, постепенно оказались частично, а зачастую и радикально, трансформированы.
Реклама

Конечно, подобные трансформации не могли не затронуть геоинформатику, призванную упростить управление сложными территориальными инфраструктурами, хотя изначально ГИС (геоинформационная система) родились как средство создания и актуализации карт. Естественно, что электронные средства, предназначенные для издания карт, очень быстро вытеснили классические пластики, карандаши, перья. Несколько позже ГИС стали расценивать как средство интеграции атрибутивных и пространственных характеристик самых разнородных объектов, тем самым построив «мостик» между ГИС и СУБД (система управления базами данных). Поддержка проекций, построение тематических карт и, наконец, появившиеся средства поддержки топологии – все это следствие процесса осознания того, что ГИС представляет собой серьезное и, пожалуй, единственное средство управления все усложняющейся системой жизнеобеспечения человека.
Несмотря на эволюцию подходов и идеологии построения ГИС, понятие электронной карты почему-то оказалось слабо трансформировано. Карта как совокупность объектов каким-либо образом сгруппированных по слоям, вместе с присоединенными базами данных об атрибутике объектов остается неизменной достаточно долго. В то же время именно такая структура цифровых карт порождает множество проблем.
Современные ГИС: проблемы создания цифровых основ
Классическое представление карты в виде совокупности объектов неизбежно влечет к нарушению топологической целостности модели территории, отражаемой картографическими материалами. Объекты так или иначе имеют общие границы, и естественно, что при изменении какого-либо из соприкасающихся объектов необходимо производить модификацию объектов-«соседей», что в целом усложняет процедуру создания и модификации карты. В большинстве случаев ошибки редактирования карт влекут за собой сложно устранимые дефекты топологической структуры. Конечно, возникающие ошибки в топологии были бы несущественны в случае, если бы нас интересовала только распечатанная на бумаге или пластике картографическая основа, но поскольку современные ГИС предоставляют средства измерений, развитые средства топологического и пространственного анализа, то любая ошибка такого рода повлечет за собой ошибки функционирования множества подсистем ГИС. Изменить ситуацию можно посредством «отщепления» от объектной модели карты информации о границах объектов в отдельный слой – слой топологии. При этом каждый из объектов сохраняет ссылки на свои границы. Редактирование карты в этом случае сводится к редактированию слоя топологии. Слой топологии часто называют дуго-узловой моделью, а к каждому из объектов, по сути дела, привязаны правила «сборки» объекта на этой дуго-узловой модели. Следует заметить, что такой подход, к сожалению, до сих пор остается нереализованным в большинстве геоинформационных систем.
Реклама

Другой интересный аспект создания современных цифровых карт связан с хранением атрибутивной информации об объектах. Естественно, что атрибутивная информация в силу сложившейся системы управления территориальными инфраструктурами требуется более часто, чем пространственная. Здесь следует упомянуть различные формы, отчеты, сводные ведомости, строящиеся на основе атрибутивной информации. Фактически все управленческие задачи так или иначе опираются на СУБД. Именно по этой причине атрибутивная информация сосредоточена, как правило, в интенсивно используемой базе данных. А связь с пространственной информацией реализована посредством назначения индекса каждому из объектов карты.
Представим ситуацию, когда нескольким городским службам необходимо привязать к одному объекту карты свои базы данных. Какая из служб должна назначить индекс объекту? В соответствии с какими правилами должен быть назначен этот идентификатор, если каждая из служб имеет, как правило, собственную систему классификации и кодирования объектов? Кроме того, в каком из тематических слоев карты должен располагаться объект? Ведь практически каждая служба группирует объекты по-своему, зачастую используя не послойную, а более общую, иерархическую модель группировки.
Карта как модель территориальной инфраструктуры
Взглянув несколько критически на общепринятые в области цифровой картографии модели, можно подвести следующие итоги. Любая служба или отрасль работает в первую очередь с совокупностью каким-либо образом классифицируемых и проиндексированных объектов (к которым добавляются атрибутивные и пространственные характеристики). Пространственное расположение объекта должно в идеале представляться совокупностью его границ, взятых из дуго-узловой модели местности. Это приводит к тому, что для каждой конкретной области возможно и, более того, необходимо расщепление цифровой карты на объектную и пространственную модели местности. Объектная модель местности может быть представлена в виде иерархии, которая продуцирует способы кодирования объектов. Конечно, можно было бы говорить о более общей форме иерархии – многосвязном графе, но в силу, вероятнее всего, ограниченности человеческого мышления такое представление лишь усложнит манипулирование информацией и сделает невозможным построение столь удобных в обращении иерархических цифровых кодов объектов. Кроме того, применяемые на практике отраслевые классификаторы всегда однозначны. Объектная модель местности должна быть тесно связана с пространственной моделью, определяя этими связями четкое расположение объектов в пространстве. Схематически такую тополого-объектную цифровую карту можно представить в следующем виде (рис. 1.).
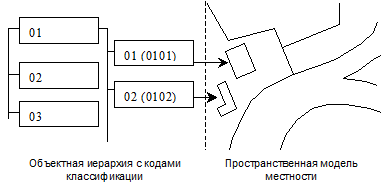
Рис. 1.
Однако мы совершенно упустили из виду атрибутивные характеристики объектов. А ведь именно они несут отраслевую специфику. Несложно представить, что таблица обычной реляционной базы данных может быть введена в эту схему совершенно безболезненно и логично (рис. 2).
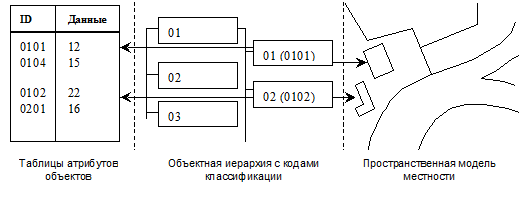
Рис. 2.
По сути дела, то, что изображено на рис. 2, отражает необходимую и достаточную информационную схему для успешного управления находящейся в распоряжении какой-либо службы территориальной инфраструктурой. Естественно, что такая схема является упрощенной, поскольку она получается путем абстрагирования от тех характеристик объектов, которые с точки зрения данного вида профессиональной деятельности просто не рассматриваются, то есть эта схема представляет собой модель, а точнее, цифровую модель местности, с точки зрения определенной службы, отрасли, предприятия.
Предпосылки хранения цифровой модели местности в реляционных базах данных
После того как мы представили все компоненты и структурные взаимодействия внутри цифровой модели местности, возникает резонный вопрос о том, каким образом осуществить техническую реализацию такого подхода? Каким образом хранить объектные иерархии, связанные с ними атрибутивные данные и пространственную модель территории? Ответ на этот вопрос не вполне однозначен. В классическом подходе ГИС отвечает за хранение пространственной и объектной модели, присоединенные базы данных – за хранение атрибутивной информации.
Представим на мгновение, что мы при решении своих задач отказались от карты. Естественно, что этот шаг ограничит спектр решаемых задач, но в то же время большинство задач можно будет решить, опираясь только на объектную модель и атрибутивную информацию. Множество предприятий и организаций в своей ежедневной работе просто не используют карту и ГИС-подход. Таким образом, если анализировать, что является основой для построения треугольника объектная модель – атрибутивные характеристики – пространственная модель (рис. 3), следует признать, что именно объектная модель, явно или неявно, является основой функционирования любой системы. Но такой выбор приводит к другому важному вопросу: чем отличается пространственная модель от атрибутивных характеристик объектов? Мы изначально разделили эти модели, более того, мы разделили средства хранения и обработки атрибутивной и пространственной информации. Все атрибутивные характеристики объектов лежат, как правило, в таблицах реляционных баз данных, в то время как пространственные характеристики – внутри геоинформационной системы, которая традиционно для их хранения использует обычные файлы. Существующее расщепление моделей не отличается особой логикой, в гораздо большей степени оно обусловлено историческими причинами развития ГИС. Это приводит, в свою очередь, к тому, что при обращении к атрибутивным данным обычно поддерживается механизм блокировок и транзакций – то есть многопользовательский доступ, в то время как для пространственных характеристик используются гораздо менее мощные механизмы обработки данных.
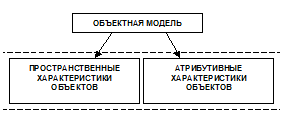
Рис. 3.
Все это не может не приводить к серьезным проблемам. Во-первых, существенно усложняется программное обеспечение для совместной обработки и анализа пространственных и атрибутивных характеристик объектов. Во-вторых, множество ГИС используют совершенно разные форматы хранения пространственных данных, зачастую принципиально несовместимые друг с другом. В-третьих, осложняется проблема многопользовательского доступа к пространственной информации, то есть сетевая многопользовательская ГИС за невысокую цену остается мифом.
Для решения проблемы достаточно взглянуть на пространственную модель местности немного с иной точки зрения. По сути дела, пространственная модель содержит границы объектов. Каждый объект имеет атрибутивные характеристики. Вполне разумным кажется интерпретация набора границ как дополнительных атрибутивных характеристик объекта. В этом случае представленная выше схема (рис. 2, 3) может существенно упроститься. Каждый объект характеризуется некоторым набором атрибутивных характеристик, в том числе и своими пространственными границами, которые также хранятся в таблицах реляционной базы данных.
Подобное объединение имеет ряд преимуществ, в том числе может решить проблему многопользовательского доступа, причем как для пространственных, так и для атрибутивных данных; появляется возможность создания единых средств пространственного анализа с привлечением атрибутики объектов; наконец, появляется возможность создания единой системы безопасности, регламентация прав доступа пользователей к данным цифровой модели местности. Также решается проблема совмещения форматов (в случае, если для представления цифровой модели местности в реляционных базах данных используются одинаковые правила). Более того, возможен переход к объемной модели, поскольку ничто не запрещает топологической (пространственной) модели представлять трехмерные границы объектов. В то же время при создании цифровой карты появляется возможность внесения в базу огромного количества характеристик, причем то, что окажется несущественным для решения каких-либо специальных задач, может быть отброшено тривиальным запросом.
Представление данных о цифровой модели местности в рамках реляционных СУБД
Какой должна быть структура базы данных для хранения данных о цифровой модели местности? Естественно, что реляционная база данных накладывает существенные ограничения на представление данных. Двумерные таблицы серьезно ограничивают средства структуризации данных о цифровой модели местности. Традиционно информация об объектах, представленная в виде таблицы, выглядит следующим образом: запись в целом содержит информацию об объекте, а поля записи – атрибутивные характеристики объекта. Пример «классического» подхода показан в следующей таблице:
| ID |
Attr1 |
Attr2 |
Attr3 |
| 0101 |
12 |
11.12.1999 |
Comment |
| 0104 |
15 |
25.11.1987 |
Comment |
Однако подобное представление не может быть использовано для хранения информации о цифровой модели местности. Основная причина – «плавающее» количество атрибутов объектов. В первую очередь это обусловлено интерпретацией пространственных характеристик как атрибутивных. Вполне естественно, что различные объекты могут иметь различное количество атрибутов. Более того, при модификации карты количество атрибутивных характеристик объекта может существенно изменяться. Существуют подходы, кода изменению количества атрибутов соответствует динамическое изменение количества столбцов в таблице (прекрасным примером реализации такого подхода служит пространственный картридж ORACLE). Тем не менее этот способ приемлем отнюдь не для всех СУБД, более того, он неизбежно порождает ограничение максимального количества характеристик объектов. Преодоление ограничения возможно путем разбиения данных на две и более строки, но при этом неизбежно возникают сложности с типизацией полей таблиц и обработкой данных.
Выходом из сложившейся ситуации является подход, когда каждой атрибутивной характеристике соответствует только одна запись. В этом случае может использоваться таблица следующей структуры (в дальнейшем мы будем использовать термин «обменная таблица», смысл которого станет очевидным несколько позже):
| HOI |
HDC |
DATA |
VAL |
| 0104 |
050723 |
11.12.1999 |
27 |
| 0104 |
050721 |
08.11.1999 |
45.5 |
| 0104 |
096782 |
21.10.1999 |
Текст |
| 0105 |
050723 |
15.10.1999 |
97 |
HOI – Hierarchy Object Identification (иерархический идентификатор объекта)
HDC – Hierarchy Data Classification (иерархический классификатор данных)
DATA – дата/время внесения характеристики
VAL – величина
Единственной технической сложностью реализации такого представления данных является хранение значения атрибута, поскольку разные атрибуты могут быть представлены различными типами данных. Можно предложить несколько возможных вариантов решения проблемы. Например, использовать в качестве типа данных поля [VAL] тип BINARY или создать в таблице поля, соответствующие всем возможным используемым типам данных (фактически расщепление поля [VAL] на [VAL_INTEGER], [VAL_DOUBLE], [VAL_STRING], [VAL_DATA], [VAL_BINARY] и т.д.). Корректность информации, помещаемой в базу данных, может в этом случае обеспечиваться программным обеспечением.
Существует возможность простого преобразования таблицы подобной структуры в «традиционный» вариант. Для этого достаточно в названии или комментарии к полям «классической» таблицы указывать иерархический классификатор данных (HDC) (рис. 4).
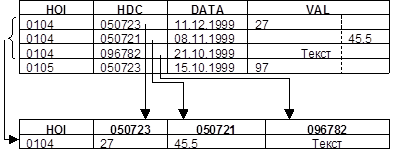
Рис. 4.
Сама возможность таких преобразований данных чрезвычайно важна, поскольку позволяет использовать стандартные, традиционные методы построения форм и отчетов, базирующихся именно на «классическом» представлении данных. В то же время благодаря обменному формату открывается возможность унифицированного межотраслевого обмена любыми данными.
Ранее уже упоминалась проблема «восприятия» разными службами и отраслями одного и того же объекта. Каждая из служб отстраивает свою модель объекта, несущую только те характеристики и атрибутивные данные, которые необходимы для решения специализированных, отраслевых задач. Однако проблема заключается не в разнообразии возникающих моделей, а в том, что ряд характеристик объекта дублируется в различных отраслевых базах. Более того, различные отрасли для одних и тех же объектов применяют различные способы классификации и кодирования информации. Таким образом, проблема сводится к тому, каким образом осуществить обмен смежными характеристиками объекта, если имеются две различные базы данных, между которыми необходимо совершить частичную репликацию информации так, как показано на рис. 5.
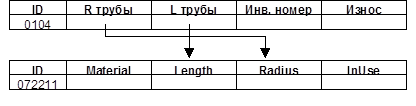
Рис. 5.
Ответить на поставленный вопрос достаточно просто, если использовать обменные базы данных. Экспортируя информацию из первой таблицы в обменную, можно простым импортом из обменной таблицы заполнить вторую базу необходимыми данными. Непременным условием такого обмена информацией является одинаковая классификация типов данных. Таким образом, мы приходим к тому, что для успешного обмена межотраслевой информацией необходима одинаковая классификация типов данных. Наличие единого классификатора типов данных не является с практической точки зрения серьезным ограничением, особенно в силу того, что такого рода классификатор должен иметь иерархическую структуру. Всегда существует возможность кроме введения различных общих типов данных, например, геометрических характеристик объектов, вводить в этот классификатор специализированные отраслевые ветви, не нарушая при этом целостности системы.
Следует заметить, что если межотраслевой классификатор типов данных является вполне приемлемым решением, то с объектным классификатором возникают серьезные проблемы. Каждая отрасль производит свое деление объектов на группы и подгруппы, а как следствие – проводит свою «политику» индексации (кодирования) объектов. В результате этого два различных кода могут описывать один и тот же объект (пример показан на рис. 5, кода с точки зрения одной отрасли объект идентифицируется как 0104, а с точки зрения другой как 072211). Естественно, что для того чтобы произвести обмен данными между этими таблицами, необходимо, чтобы система импорта-экспорта могла выполнять переиндексацию информации, то есть необходимо определенным способом «уравнять» различные варианты индексации одного и того же объекта.
Для решения проблемы достаточно завести таблицу уравнивания объектов, которая содержала бы всего две колонки, в первой из которых был бы первый идентификатор объекта, а во второй – второй идентификатор. Такая таблица позволила бы в случае операции импорта из обменной таблицы производить межотраслевой обмен информации. Необходимым условием индексации объектов в этом случае является уникальность отраслевых идентификаторов объектов. Этого несложно добиться, вводя в первых разрядах идентификатора объекта код отрасли.
Однако построение таблицы уравнивания объектов приводит к проблеме, связанной с необходимостью выполнения условия транзитивности. Если [код А] = [код B], а [код B] = [код C], отсюда следует, что [код А] = [код С]. Вне сомнения, поиск всевозможных транзитивных пар кодов объектов вызовет существенные проблемы при интерпретации содержимого таблиц. Решением проблемы является введение в систему некоторого системного кода, посредством которого и происходит уравнивание объектов. В этом случае в первой колонке таблицы уравнивания содержится отраслевой код объекта, во второй – его системный идентификатор. При этом у всех отраслевых «ипостасей» объекта системный идентификатор общий. Если мы производим уравнивание объектов двух отраслей впервые, то при вставке их идентификаторов в таблицу уравнивания генерируется любое произвольное уникальное число – системный ключ. Если код одного из объектов уже присутствует в базе данных, то вновь добавляемому объекту присваивается уже существующий системный идентификатор. Это простое правило позволяет полностью избежать возможных коллизий, поскольку выбор системного ключа произволен и его можно изменять и регенерировать в любой момент. Несложно также представить объединение нескольких таблиц уравнивания в единую таблицу.
Следует отметить, что если отраслевые классификаторы типов данных велись изолировано и как следствие одна и та же характеристика имеет разные коды в разных областях, можно ввести таблицу уравнивания и для классификационных кодов типов данных. Однако это решение не является лучшим, поскольку в дальнейшем будет показано, как именно межотраслевая таблица классификаторов данных может быть использована для разрешения проблемы параллелизма информации.
Таким образом, обменная таблица и таблица уравнивания объектов, а в худшем случае и таблица уравнивания типов данных, могут являться основой обмена и интеграции информации между любыми отраслями; более того, они являются уникальным способом разрешения коллизий, порожденных несовершенством способов ведения хозяйственной деятельности и существующей системой межотраслевого документооборота.
Представление пространственной модели в рамках реляционной СУБД
Последняя проблема, решение которой приводит нас к возможности реализации полноценной цифровой модели местности, заключается в способе приведения топологической пространственной модели местности к предлагаемой выше структуре баз данных. Основой формирования любой карты являются точки. Но что такое точки в контексте проведенной выше формализации? Точки создают топографы, геодезисты, которые представляют отрасль, по сути дела, вводящую в единую цифровую модель местности новые объекты. Эти объекты имеют свои отраслевые идентификаторы и, естественно, свойства, которые выражаются координатами X, Y, Z. Геометрические характеристики точки, конечно же, являются типами данных, которые, в свою очередь, имеют классификационный код. Таким образом, цифровая модель местности фактически поглощает точки как совершенно обычные объекты. Более того, зачастую нет необходимости вводить объекты-точки, а можно сразу назначить свойства X, Y и Z для любого объекта, например трубы, моста, столба и т.д. Механизмы синхронизации, которые детально обсуждались выше, позволят избежать дублирования или недостоверности информации внутри базы данных, содержащей модель местности. Можно даже предусмотреть механизм приоритетов в случае, если, например, координата X появилась у объекта дважды со стороны разных служб. Если различным службам назначить коды, которые появляются как в идентификаторе объекта, так и в идентификаторе типа данных, то координаты объекта разумно ввести как тип данных, принадлежащих, например, геодезической службе. Если какая-либо другая организация продублирует координату в своей базе с ошибкой, то выбор правильных данных допустимо произвести автоматически, следуя правилу, что наиболее достоверные данные поставляет та служба, код которой в идентификаторе объекта и идентификаторе класса данных совпадает. Это автоматически позволит избежать возникающего параллелизма в сборе информации.
Однако конечная цель – ввод в таблицы, хранящие информацию о цифровой модели местности, топологической пространственной структуры. В этом случае точки являются только средством построения межобъектных границ. Сами границы, в свою очередь, являются атрибутами объектов. В этом случае границу можно также интерпретировать как объект, свойствами которого являются идентификаторы точек.

Рис. 6.
Подобная структура базы позволяет вводить любые виды границ, в том числе использовать в качестве границ трехмерные поверхности. При этом программное обеспечение, «не воспринимающее» Z-координату, будет отстраивать обычную двумерную карту, но в то же время допустимо строить и трехмерные модели. Кроме того, для точки или границы можно ввести дополнительную атрибутику, тем самым дополняя карту элементами картины (например, нечеткие границы). Аналогичным образом можно ввести в модель местности ссылки объектов на их пространственные границы. Единственной сохранившейся проблемой является упорядочение ссылок границ на точки и объектов на границы. Ведь выбрав из базы всю информацию о точках линии, мы тем не менее не решаем проблему построения самой линии. Это является следствием нерешенной проблемы приоритета атрибутов. В принципе, среди атрибутов объекта, относящихся к одному классу (в приведенном выше примере все атрибуты линии относятся к классу точек), может возникнуть необходимость в расстановке приоритетов для одинаковых атрибутов. Выход из ситуации достаточно прост – достаточно лишь ввести необязательное для заполнения поле приоритета атрибута объекта. Для равноправных атрибутов (например, диаметр и длина трубы) поле не используется, в то время как в других случаях оно может заполняться, и при запросе к базе цифровой модели местности по нему может производиться сортировка.
В результате мы приходим к простейшей структуре базы данных, когда полная информация о цифровой модели местности может храниться в таблице, состоящей всего из пяти обязательных полей, причем при добавлении таблицы уравнивания объектов цифровая модель может служить централизованным хранилищем для обмена межотраслевыми данными. Благодаря обязательному полю дата/время появляется возможность хранения и накопления архивной информации и, что особенно важно, архивной картографической информации. В этом случае, используя фильтр по дате, мы можем увидеть, каким образом изменялась местность, когда появлялись новые дома, объекты инженерной инфраструктуры, а при необходимости можно отследить даже сезонные изменения границ объектов, например рек и болот.
Таким образом, единая цифровая модель местности является принципиально новым подходом к хранению данных в геоинформационных системах, открывающим возможность построения распределенных многопользовательских хранилищ и архивов данных, с возможностью обеспечения целостности, непротиворечивости и корректности как топологической структуры модели, так и атрибутивных данных объектов.
|
